
Zero egress fees: Why CoreWeave's $1M offer matters
CoreWeave covers egress fees to save teams up to $1 million per transfer, removing financial gravity from legacy cloud providers.

CoreWeave covers egress fees to save teams up to $1 million per transfer, removing financial gravity from legacy cloud providers.

The k8scsis3 driver relies on FUSE, requiring privileged containers and shared mounts. Learn why this architectural choice demands specific systemd flags...

Learn how S3 achieves 99.999999999% data durability via cross-zone redundancy. Rabata.io applies these same principles for cost-effective AI storage.

Learn how randomized prefixes prevent hotspots when handling 150 million requests per second on massive object storage systems.

Learn how scaleout repositories separate performance from capacity tiers to handle growth without migrating data or disrupting active workflows.
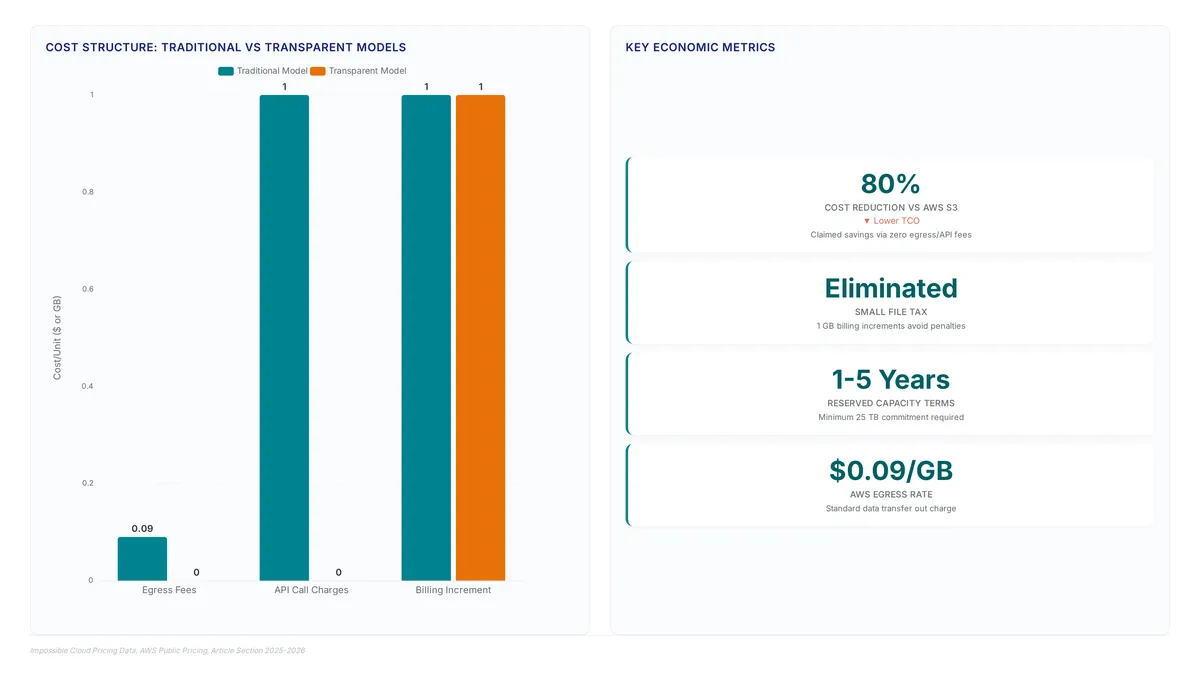
Claimed savings below AWS S3 costs drive urgent scrutiny into European object storage economics.

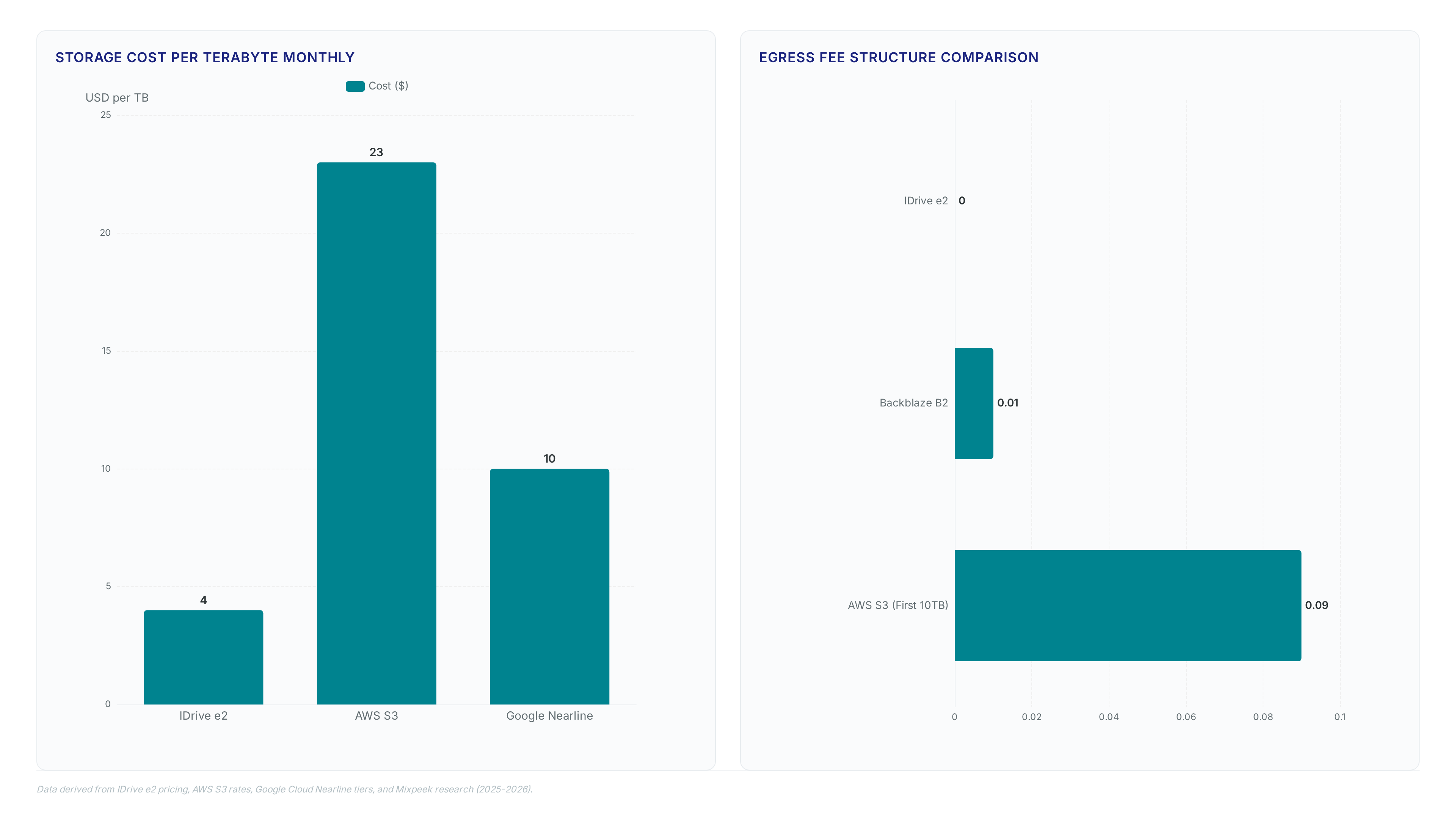
Egress fees hit $0.12 per GB, often exceeding base storage costs. Learn how hidden charges distort cloud budgets and where real savings hide.

Amazon S3 Annotations support 1,000 entries per object, eliminating synchronization lag by integrating directly with Iceberg tables for instant SQL analysis.

Mountpoint for Amazon S3 CSI driver v2 cuts large-scale financial simulation job times by up to 2x according to AWS data.

Egress fees cost 4, 6× more than storage on AWS, Azure, and GCP. This isn't an accident; it's a deliberate pricing asymmetry designed to penalize data...

Analyze AWS S3 Glacier's 11-nines durability and retrieval windows to enforce cost discipline without sacrificing compliance or data integrity.

Request fees per 1,000 operations often exceed storage rates. Learn why manual math fails on API volumes and how to fix bill spikes.

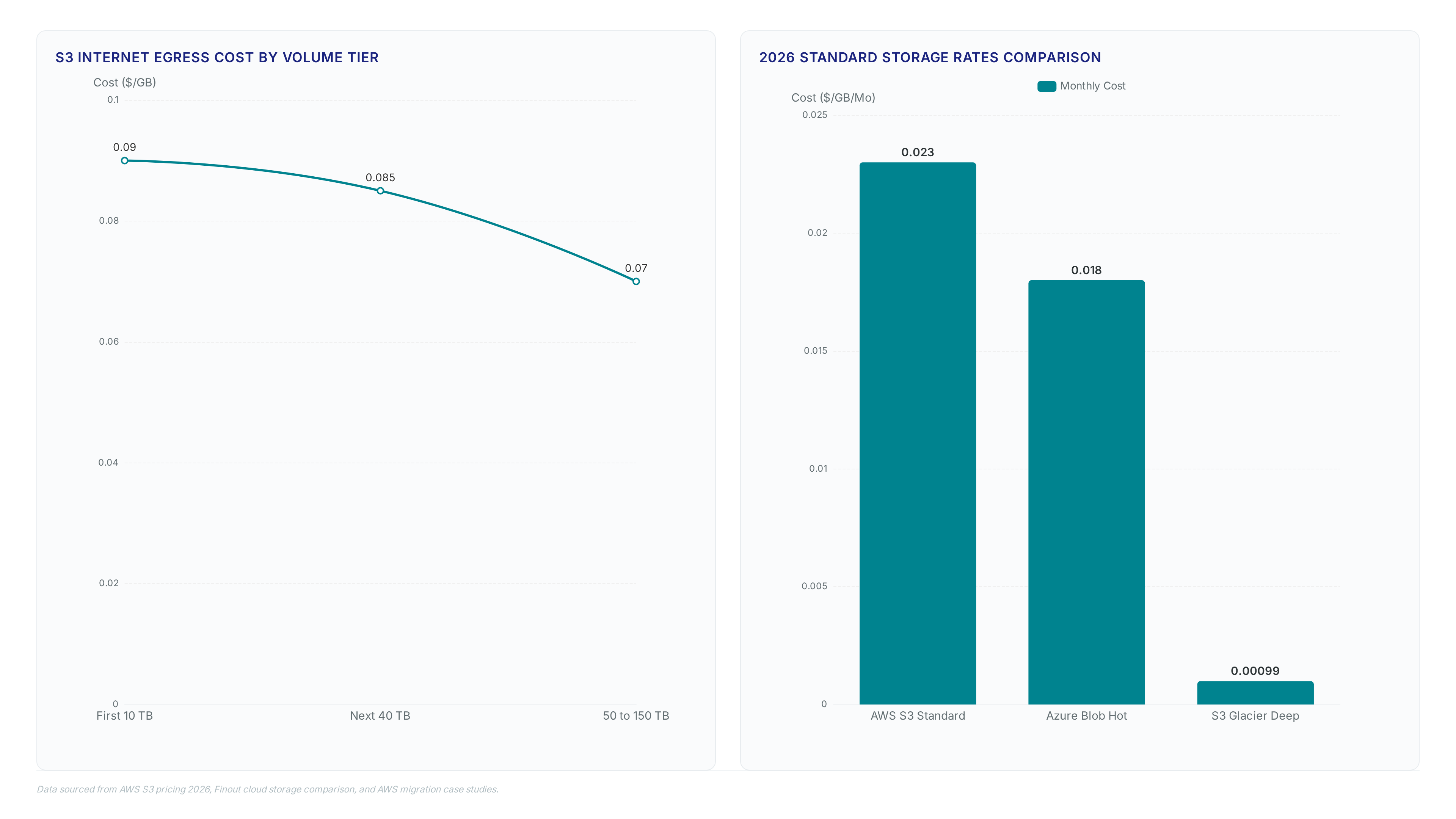
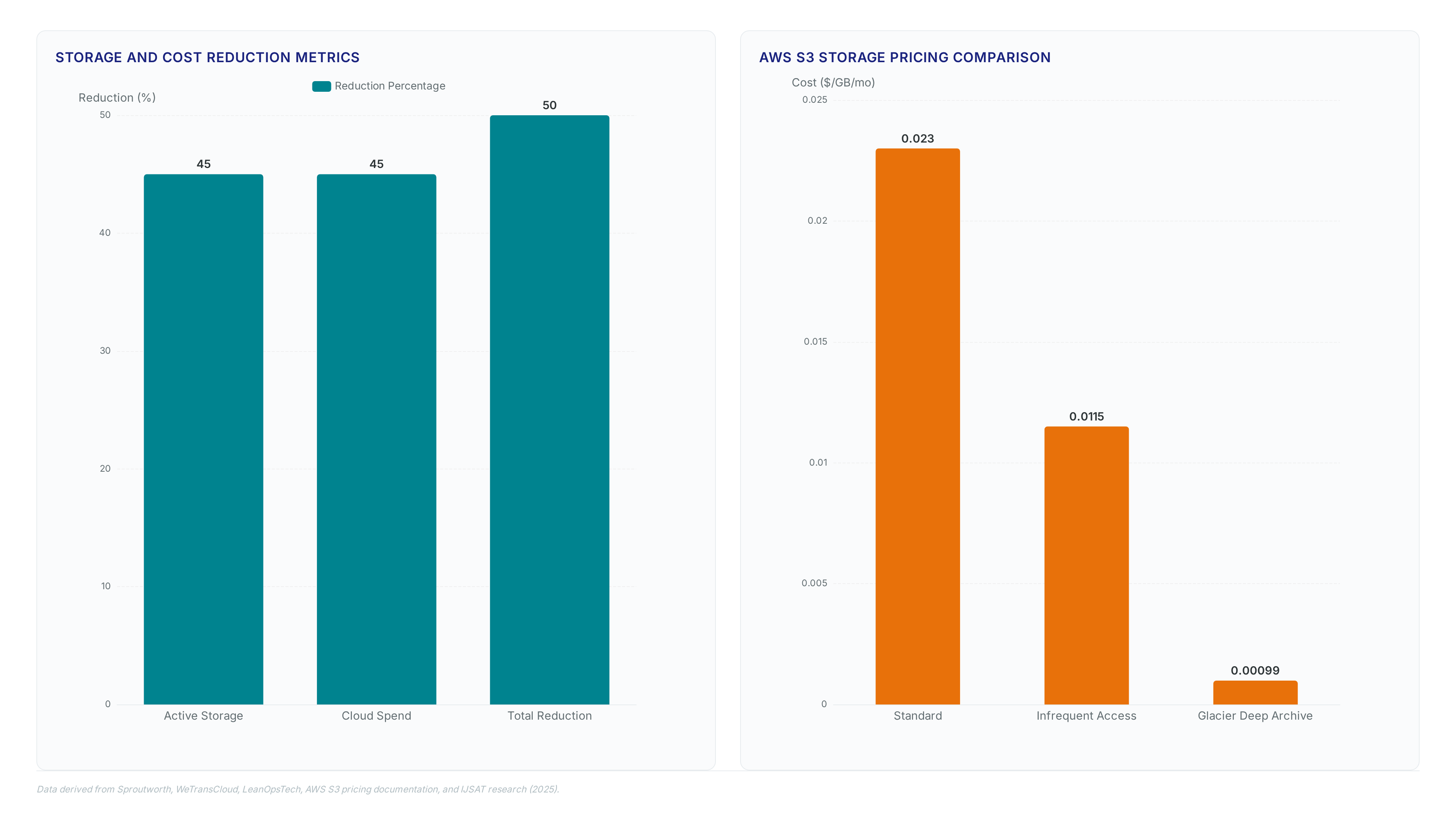
Amazon S3 Standard costs $0.023 per GB in us-east-1, yet this base rate masks the true expense drivers.
Google charges $0.12 per GB for egress, inflating budgets. Discover how zero-fee models eliminate this hidden tax on your data portability.

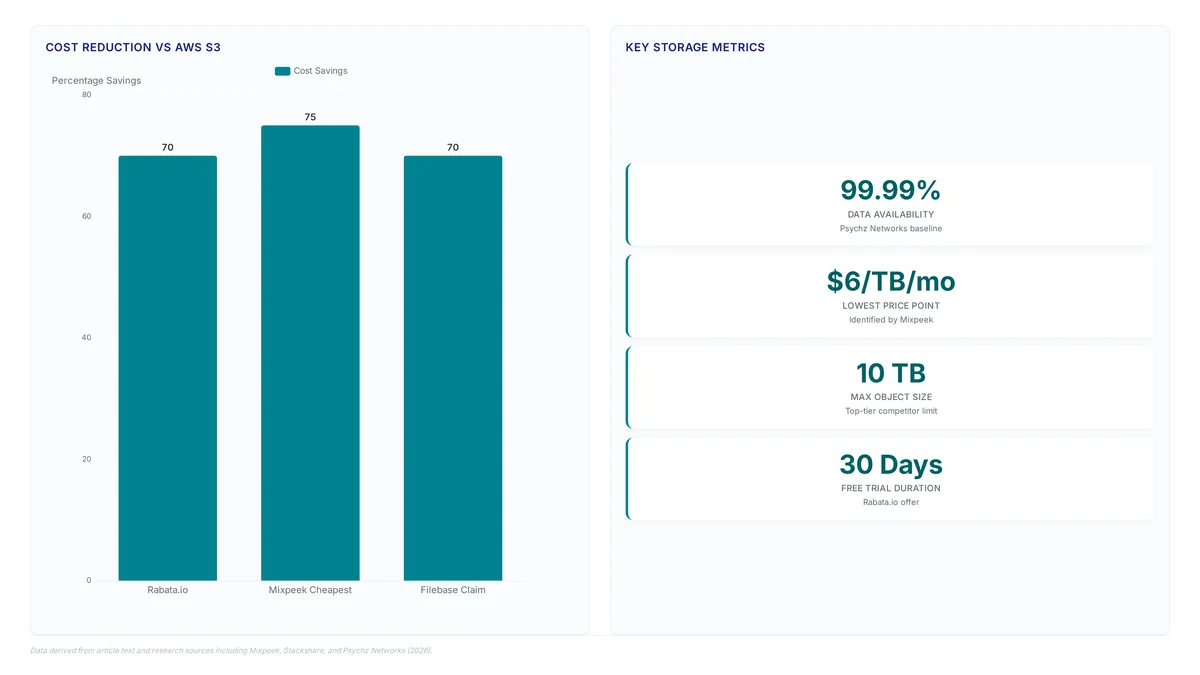
Discover how AWS S3 alternatives reduce enterprise storage costs by 70%. Eliminate unpredictable egress fees with Rabata.io's zero-egress platform.

Flat storage architectures scale well, but default configs create debt. Learn how automated governance and IntelligentTiering reduce human error in...

Cloud.gov S3 plans like basicpublic expose data instantly. Learn why sandbox variants delete storage and how Rabata.io enforces strict governance policies.

Synology offers object storage at $7.99 per TB with free retrieval, eliminating hidden API fees for large-scale archives and data lakes.

Unify fragmented storage ecosystems by mapping distinct bucket terms into a single object standard, eliminating the technical debt of bespoke integrations.

Discover how Rabata.io delivers 2.3x faster mixed workloads than AWS S3 while cutting storage costs by 70% for AI and media teams.

Enable live S3 operations with 1 GB of mutable context per object using the Model Context Protocol for secure AI integration.

Cloudflare R2 pricing sets the mid-range benchmark for base storage costs per GB monthly. This isn't just a price cut; it's a structural shift.
Cloud storage can cost as little as $0.006 per GiB monthly, drastically undercutting legacy hyperscaler rates.

Discover S3-compatible storage delivering 2.3x higher performance than AWS while eliminating hidden egress fees for heavy data workflows.
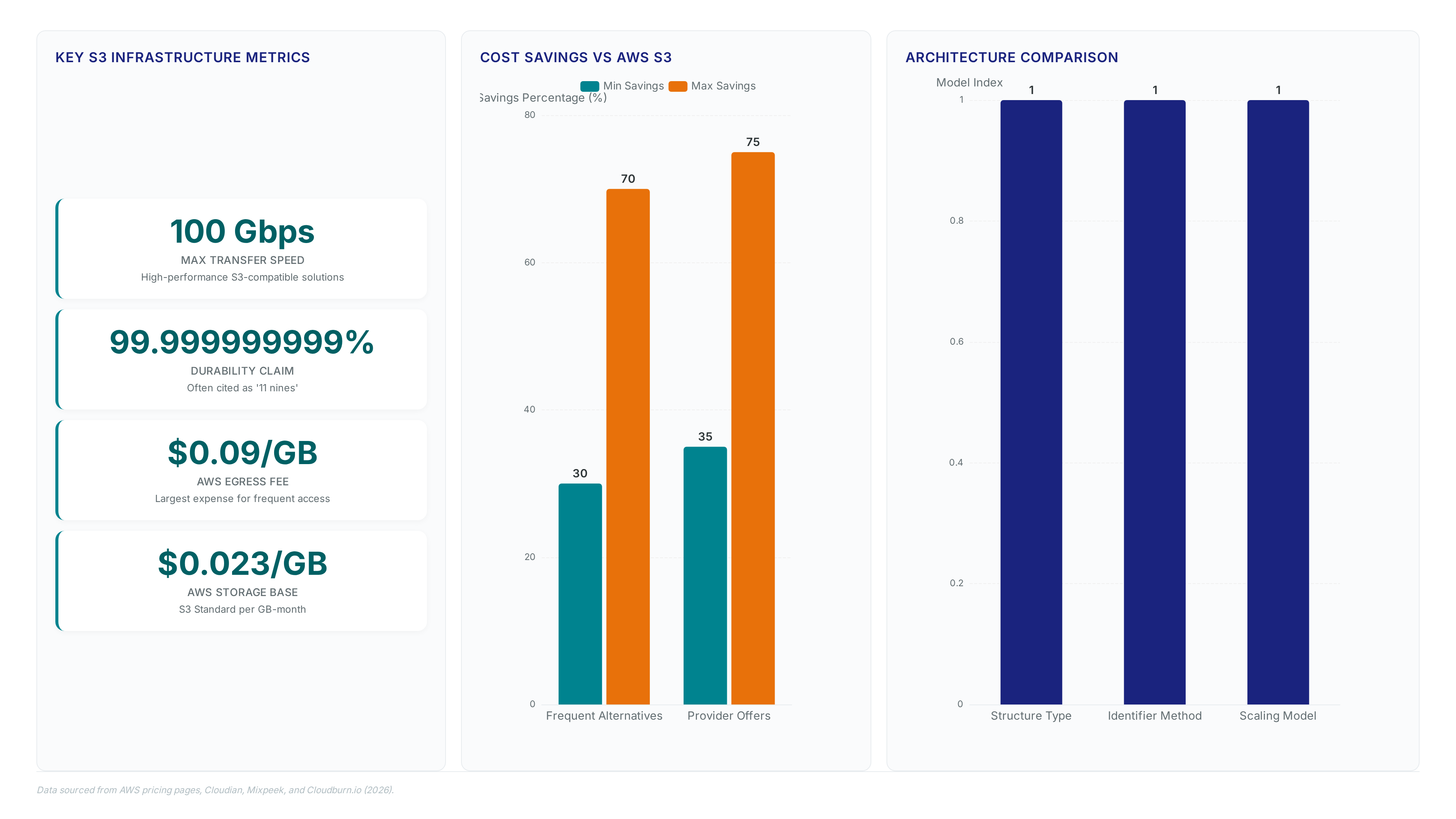
Run Amazon S3 workloads outside AWS without rewriting code. Learn how erasure coding ensures durability while scaling unstructured data to petabytes.

Cut storage costs by 70% with S3 compatible systems. Learn how decoupling the API reduces latency for AI workloads without code changes.

Cut data transfer expenses by 70% using S3 compatible storage. Learn how erasure coding ensures durability while avoiding proprietary vendor lock-in fees.

Cloudflare R2 storage costs $0.015 per GB monthly, yet hidden API charges often exceed base fees.
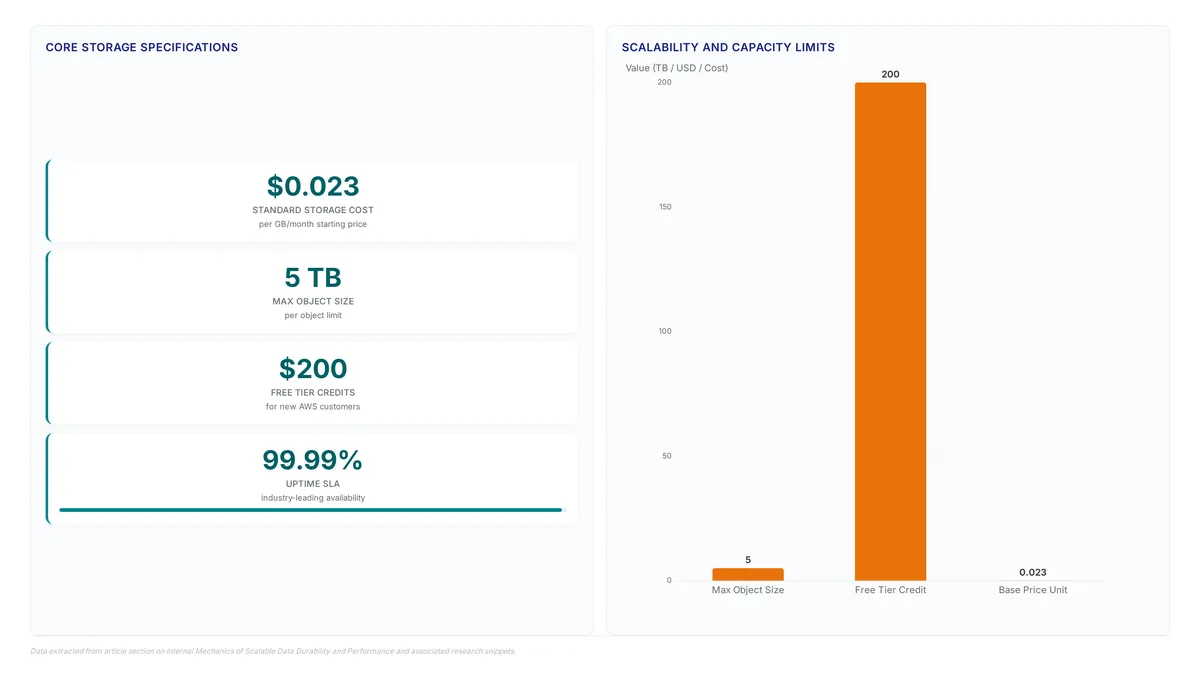
Learn how object storage supports individual files up to five terabytes, enabling limitless scale for modern AI data foundations without capacity planning.

Stop looking at the per-gigabyte sticker price. In 2026, that number is a decoy. The real bill arrives later, buried in egress fees and API request...

Port 9000 serves as the default access point for the server and its embedded web-based object browser.
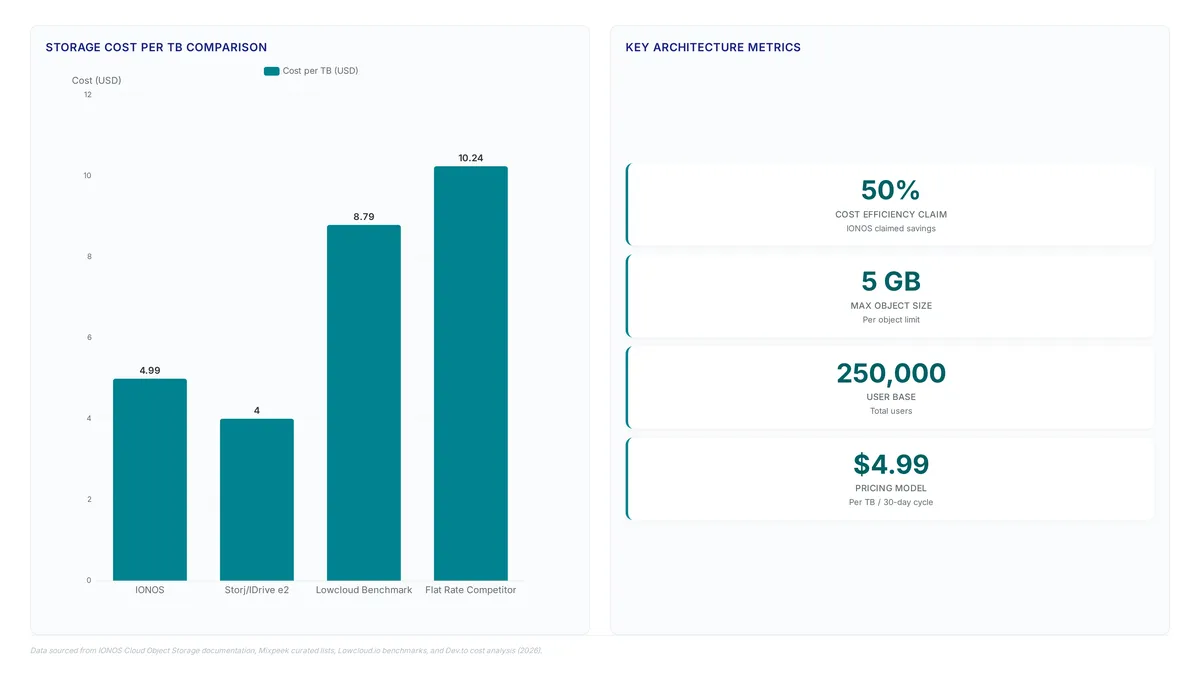
Storing 350 TB costs just $1,747 with IONOS CLOUD. Competitors charge up to $8,138 for the same capacity. That gap defines the modern storage market.

Switch to Frankfurt-based object storage to reduce expenditures by up to 90% and eliminate opaque egress charges from hyperscalers.

Discover how erasure coding delivers 11 nines of durability while slashing costs compared to legacy replication methods for enterprise data.

Market rates for object storage have collapsed. The going rate now sits at $0.006 per GB monthly, a figure that renders legacy enterprise expectations...

Legacy arrays choke on exabyte-scale workloads. Discover why 10 TB/s throughput is now essential for modern AI training pipelines.

Azure Blob Hot lists at $0.018 per GB, but retrieval fees often drive the real bill. Learn how architecture choices impact total cloud costs.

Global data creation has surged from two zettabytes to over one hundred and eighty-one zettabytes.
S3 API support shifts across v0.24.0 and v1.0.0 releases. Learn why Bucket Replication remains unplanned and how to verify true compatibility.
Discover how Cloudflare R2 delivers 20x faster response times than S3 at the 95th percentile while eliminating egress fees for global data.

Analyze how zero-egress models shift storage economics. Learn why 21 providers were evaluated for true S3 API parity and cost efficiency.

Fix broken integrations by routing traffic through the /storage/v1/s3 path. Isolate your protocol layer from the physical storage backend today.

MinIO MemKV targets sub-10ms latency to slash AI inference delays. Learn how zerocopy architecture eliminates recompute tax in GPU clusters.

No specific storage limits or throughput figures exist for Amazon S3 buckets, only qualitative claims of industry leadership per AWS documentation.

Discover how object storage delivers "11 nines" durability for massive AI training sets while scaling to billions of data points efficiently.

S3 versioning triggers a 15-minute propagation window where CDNs serve stale 404 errors. Learn how HeadObject checks amplify timing gaps.
Stop manual data dumping. Use intelligent lifecycle mechanisms to shift unstructured data between performance tiers automatically for better cost control.

Achieve up to 14 nines of data durability with a unified architecture that eliminates silos and accelerates modern AI training cycles.

Object storage bills rarely match spreadsheets. Learn how retrieval fees and tiering impact your total cost beyond raw capacity numbers.

S3 pricing varies 23× between tiers. Learn how minimum duration charges and retrieval fees impact total cost for trillions of objects.
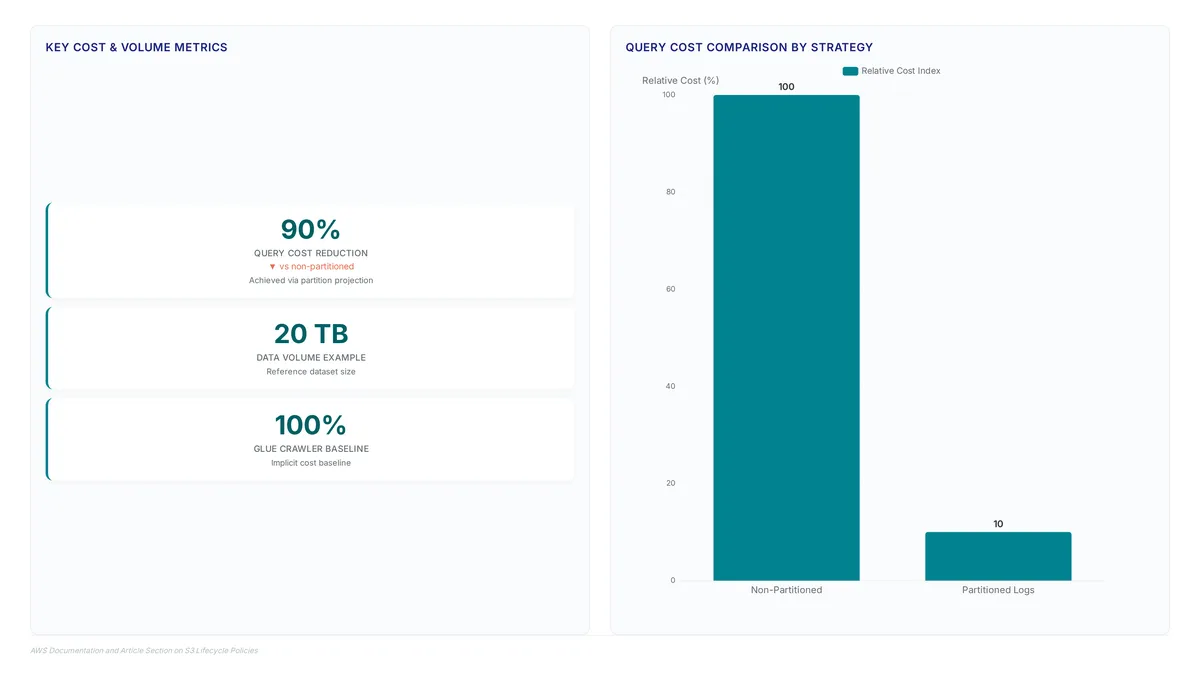
Raw S3 logs arrive with a 2 to 4 hour delay, breaking real-time monitoring. Learn to structure queries that satisfy SOX rules without high costs.
Testing seven solutions reveals that self-hosted S3 storage offers developers full control over data access and stability.

Achieve 70% cost savings versus AWS S3 using always-hot object storage architectures that remove retrieval penalties and vendor lock-in risks.
S3-compatible object storage lets applications use the same commands as AWS to slash migration timelines.

Learn how a single 4U chassis stores 1.5PB using S3-compatible tech. Secure REST endpoints and manage signatures for BackBlaze or Wasabi safely.
Resolve Kubernetes data bottlenecks with exabyte scalability. This analysis details how S3-compatible patterns eliminate latency in private cloud deployments.
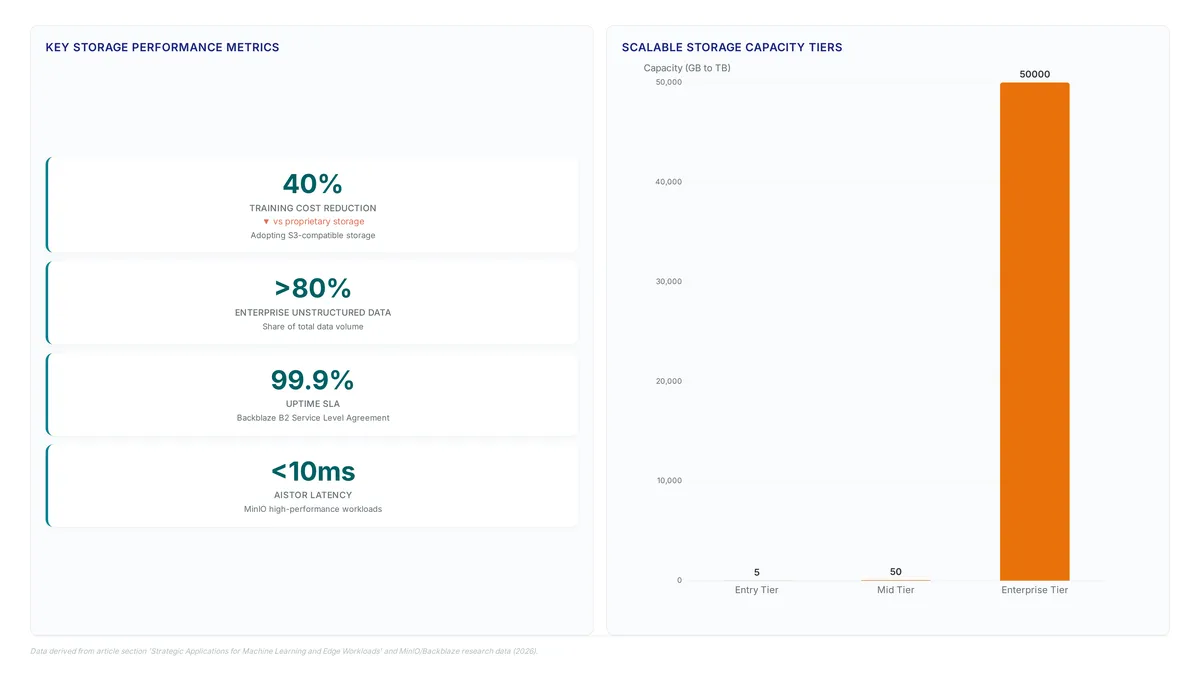
Over 80% of enterprise unstructured data now relies on S3-compatible interfaces. Learn how zero egress fees alter total cost of ownership.

Cut Kubernetes total cost of ownership by 60% with S3-compatible private storage. Achieve 8 TiB/s throughput while avoiding public cloud egress penalties.

Stop paying per-request fees. This S3-compatible storage offers zero API charges and 2.3x faster throughput for heavy AI training workloads.
Blimp by Züs Network delivers 99.99% data uptime alongside zero recovery objectives to redefine reliability standards.

AWS S3 Standard charges a flat monthly fee per TB, yet storage classes within the same ecosystem diverge by 23x according to go-cloud.io data.
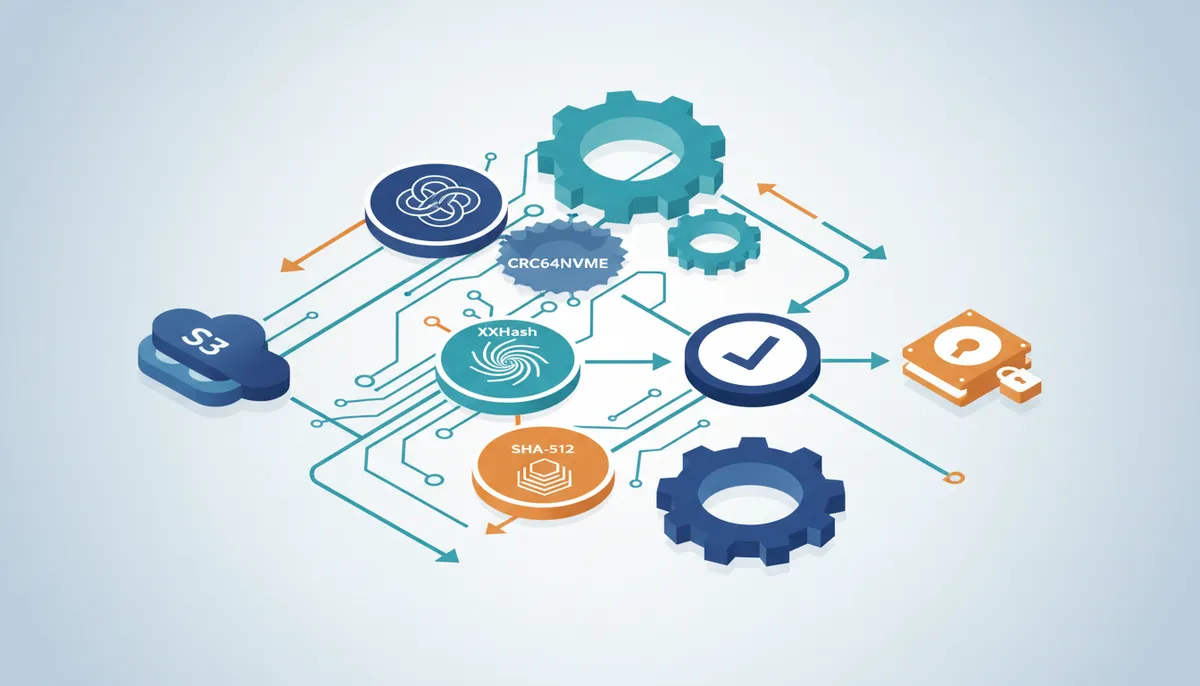
Attach up to 1000 annotations per object to create a mutable context layer, eliminating costly re-uploads during iterative AI model training.

Amazon S3 Files caches actively used data to deliver low-latency access without promising specific speed percentages.

Amazon S3 Files launched across 34 regions, ending the compromise between object and file storage for high-performance AI workloads.
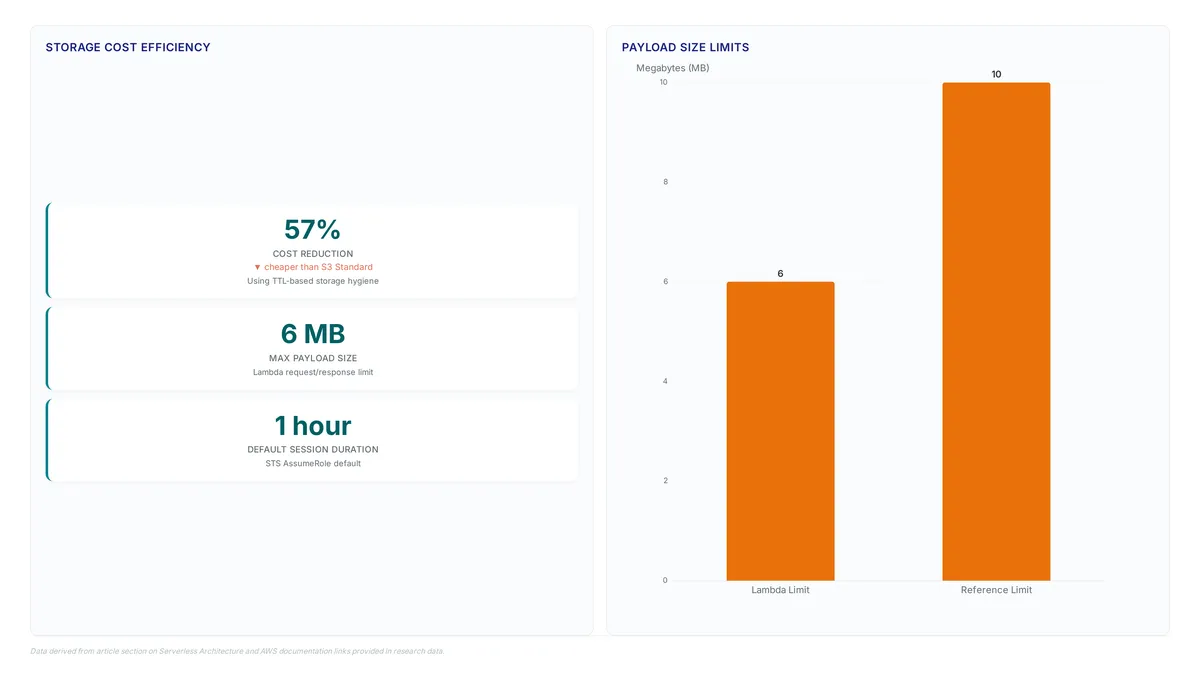
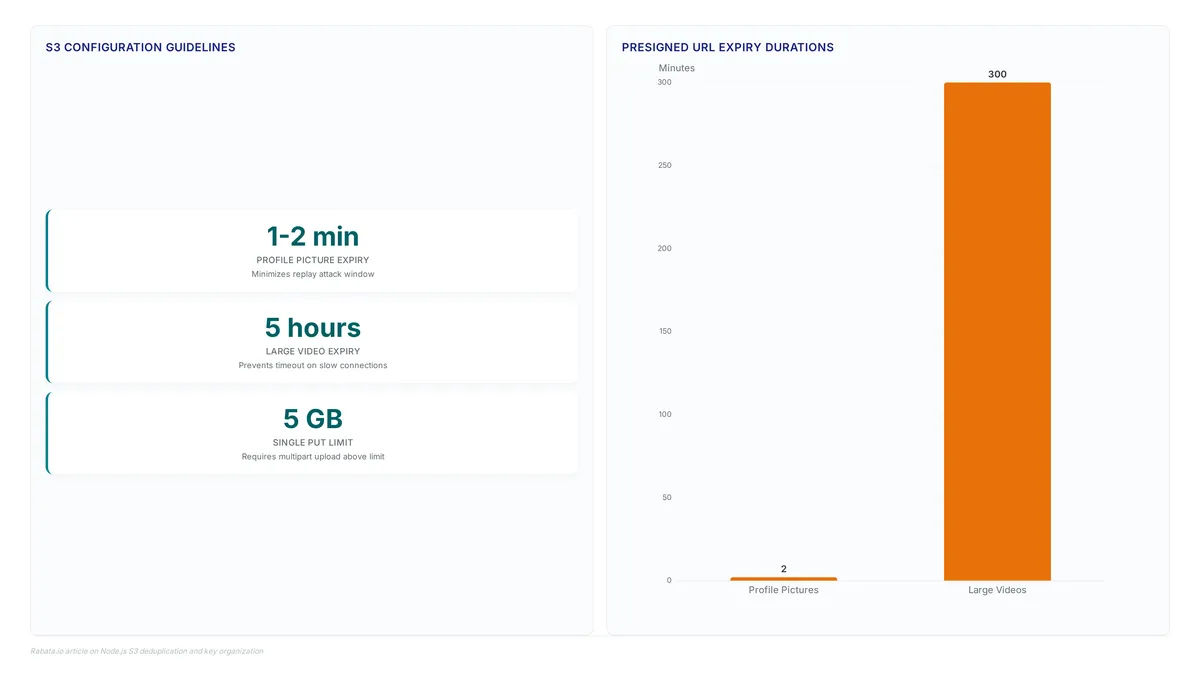
Standard presigned URLs last up to 7 days, creating replay risks. Learn to enforce single-use access using DynamoDB conditional writes and serverless tokens.
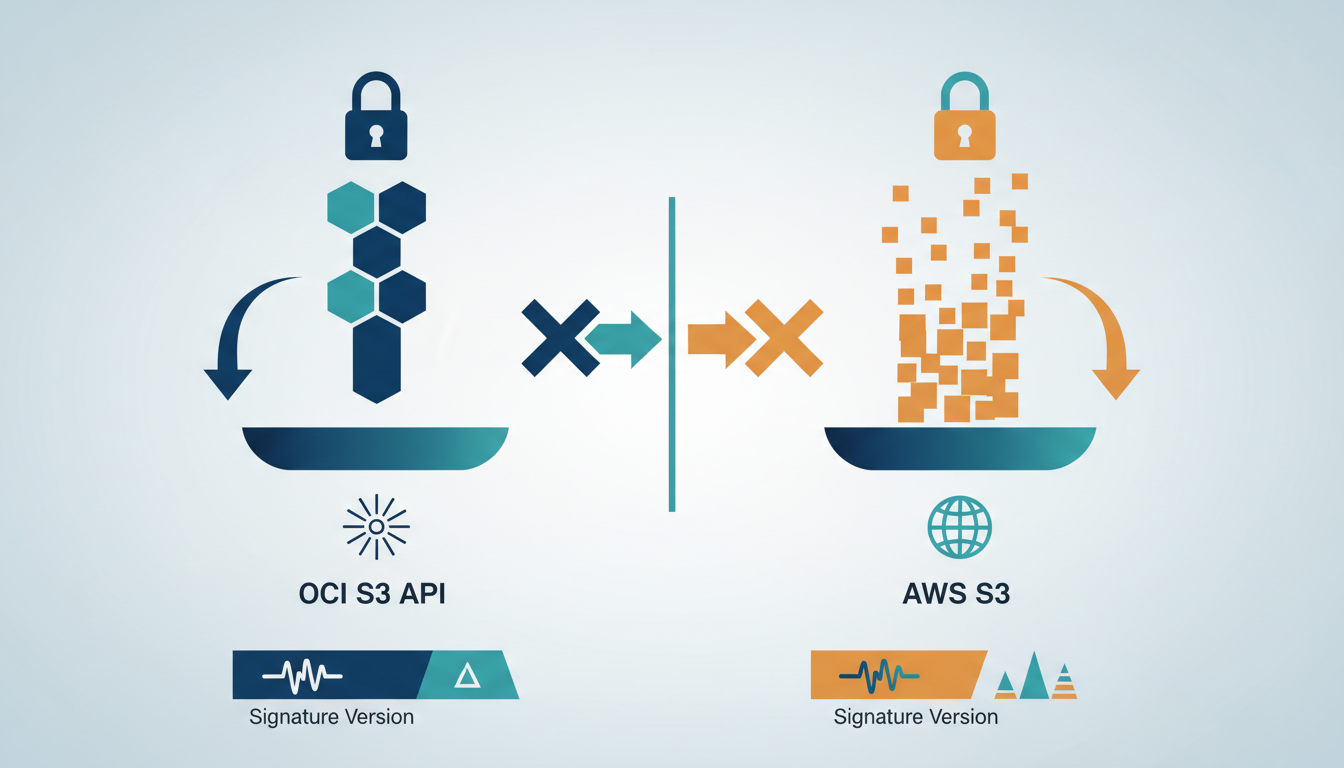
Oracle assigns exactly one immutable namespace per tenant, forcing a shift from global bucket names to compartment-based security policies.
With over a vast number of objects stored as of March 2026, Amazon S3 dominates the environment, yet on-premise S3 storage offers a necessary escape...
Compare 5 providers offering S3-compatible storage. See how Sliplane's €5 flat rate eliminates egress fees for 250 GB of data.

See how decentralized object storage hits 400 ms optimistic finality, proving new architectures can outrun legacy file systems on speed.
Avoid Azure's 180-day retention trap. Learn how object storage repositories optimize backup tiers and cut total cost of ownership.

Avoid egress penalties that destroy budgets during model retraining. Learn how erasure coding impacts latency for 2026 AI workloads.
Object storage solutions cut US data center power consumption by 22 percent according to recent efficiency data.

QNAP Labs tests show QuObjects hitting 2990 MB/s read speeds, dwarfing cloud equivalents. Stop paying for bandwidth you already own.
Learn how the Mountpoint CSI driver v2 uses pod sharing to optimize Kubernetes storage. Discover rootless execution and CSI 1.9.0 support.

Amazon S3 Lifecycle Management slashes costs by automating data movement after 30, 60, or 180 days based on access patterns.

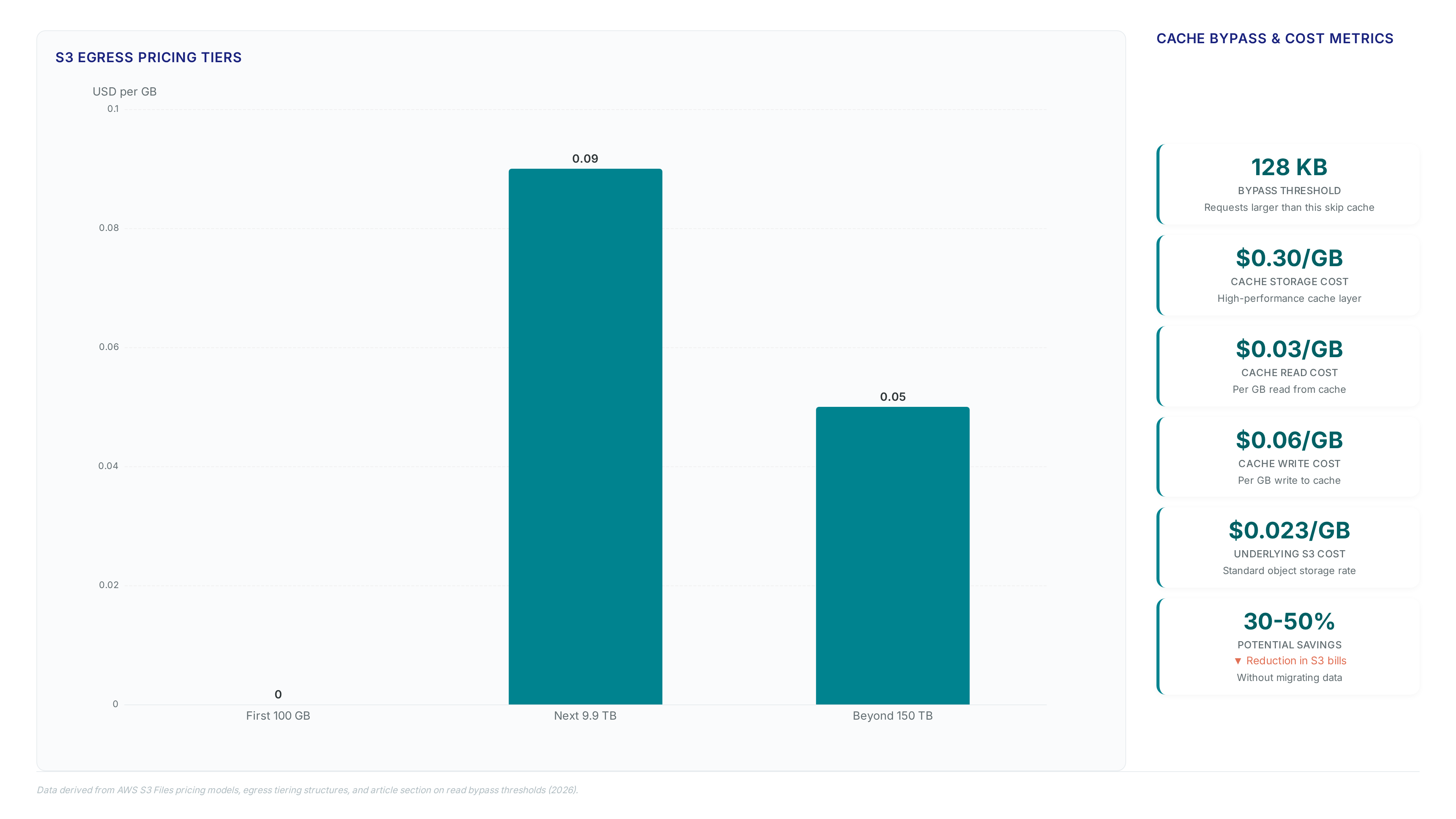
Blind transitions trigger a $0.03 fee per 1,000 requests. Learn why metadata overhead on small objects erodes savings before they materialize.
Egress fees often exceed storage costs, breaking budgets for data-heavy workflows. Learn how EU sovereignty mandates and zero-fee architectures fix this.

Achieve sub10ms latency in diskless Kafka by separating compute from storage, enabling 80% cost reductions versus traditional disk-based systems.
Persistent storage drains Kubernetes budgets faster than compute. Object storage offers a escape hatch: significantly cheaper per GB, infinitely...

COSI fixes object storage gaps that CSI cannot address in Kubernetes. The Container Object Storage Interface exists because CSI primitives like...
Content addressed storage kills S3 data drift by swapping mutable keys for immutable content identifiers.
Reduce payload size by filtering specific keys instead of returning the complete resource tree. Learn syntax to cut network overhead.

No single verified statistic in the provided research corpus quantifies market dominance or failure rates for cloud object storage alternatives.

Idle resources cause 30% of cloud waste. Learn how rightsizing and automated governance reclaim budget without sacrificing performance.
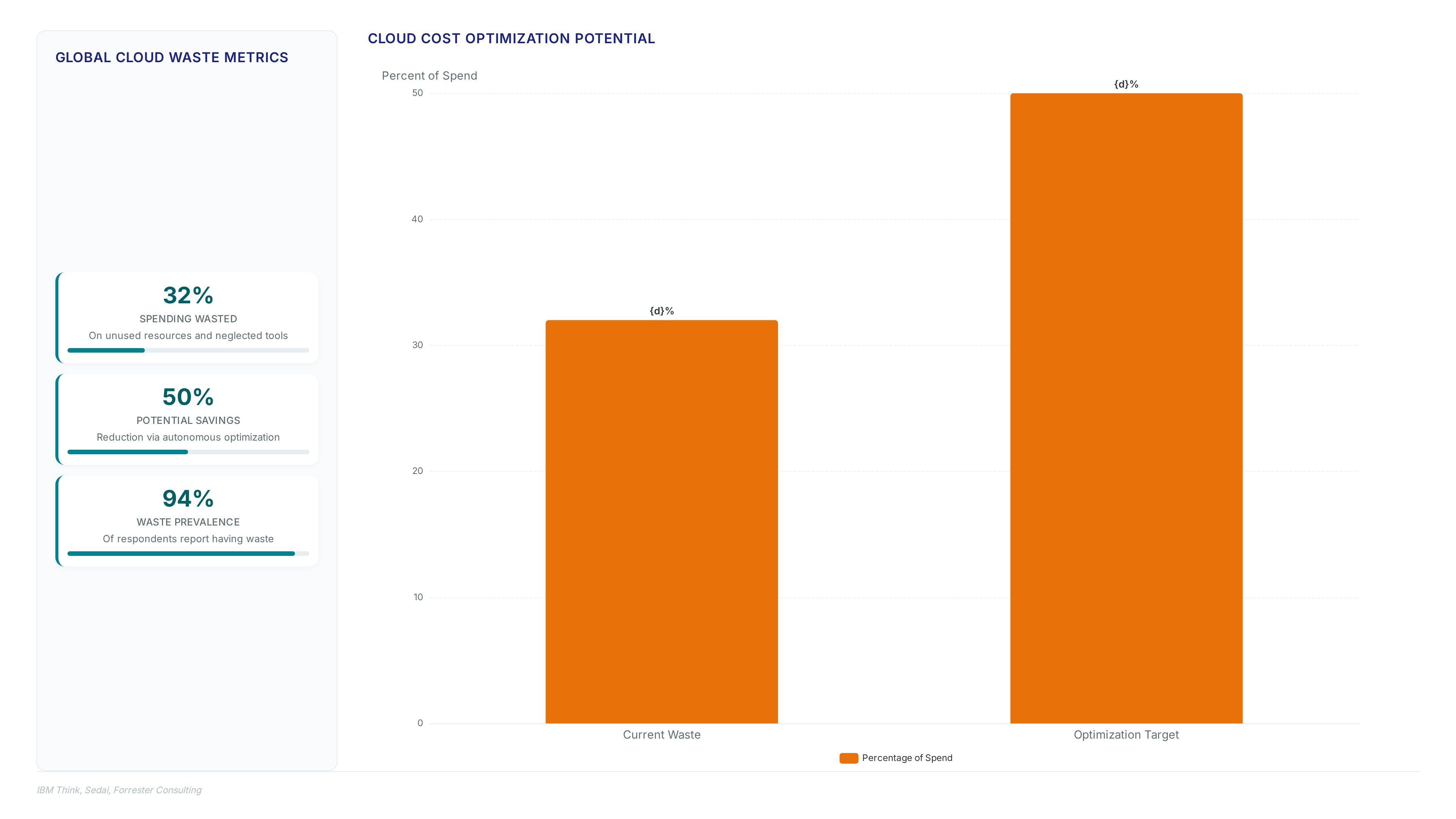
IBM reports organizations waste significant cloud spending. Discover how autonomous scaling cuts costs by 50% while boosting app performance by 75%.

Migrating from Amazon S3 eliminates egress fees that often dominate cloud budgets. The business case for shifting object storage providers hinges on...

Idle GPUs waste 70% of compute capacity when storage cannot feed data fast enough. Discover how unified access patterns resolve these bottlenecks.

An S3 access denied error returns HTTP 403, but the root cause rarely sits in a single log line.

Stop AI projects from stalling due to data entanglement. Learn how flat namespaces solve logistics for massive volumes without legacy costs.
Handle files up to five terabytes without server strain. Rabata.io delivers S3-compatible object storage built for massive, unstructured data.
S3 object storage decouples files from servers, a sharp departure from EBS disks chained to specific EC2 instances.

Cloudflare R2 hit 171.58 ms latency, proving S3 compatible storage varies. Discover why API gaps break automation and inflate enterprise costs.

Tests show thread count drives read performance up, with 256KiB objects revealing wild speed variances across providers like Wasabi and R2.
Stop storing binary blobs in Postgres. Learn the 3 critical S3 variables LobeHub needs to prevent database bloat and speed up AI instances.

Amazon S3 handles individual files up to five terabytes. Moving that much static data demands more than a simple storage bucket; it requires a...

Twenty-one distinct S3-compatible providers have faced evaluation in recent studies, yet COSBench stands as the primary open-source utility for...
MEGA Cloud hands out 20 GB of free space, the largest entry-level capacity for privacy-focused users.

Avoid bill shock by mastering the 3 pillars of Amazon S3 pricing: storage, requests, and data transfers that drive unexpected costs.
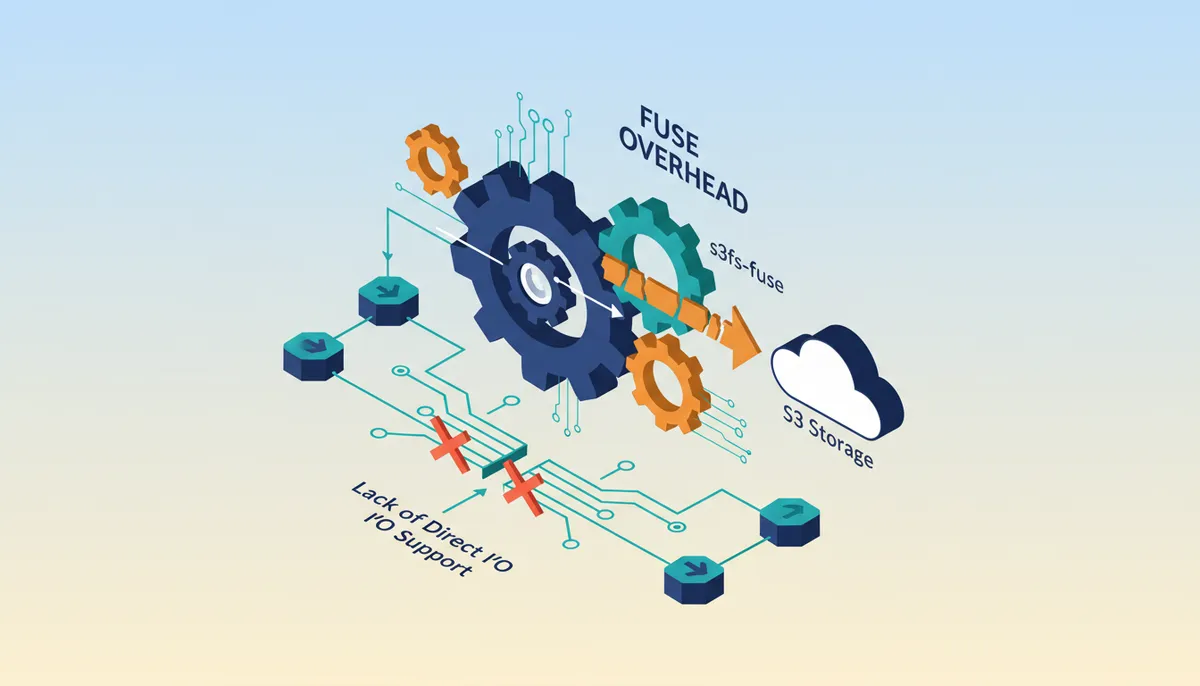
Paradigma Digital measured 5 sequential ops to prove NFS mounts cut context switching. See why removing the FUSE layer boosts throughput.

OVHcloud's OpenIO shift delivers 1,360 MB/s read speeds by replacing static hashing with AI-driven data placement for modern workloads.
The Rabata.io S3 provider performance benchmark was strictly executed over a two-day period on September 18-19, 2025.

Supabase Storage added S3 protocol support in April 2024, enabling standard object storage compatibility.

Zero egress fee storage eliminates the monthly penalty that traditional providers charge for data retrieval.
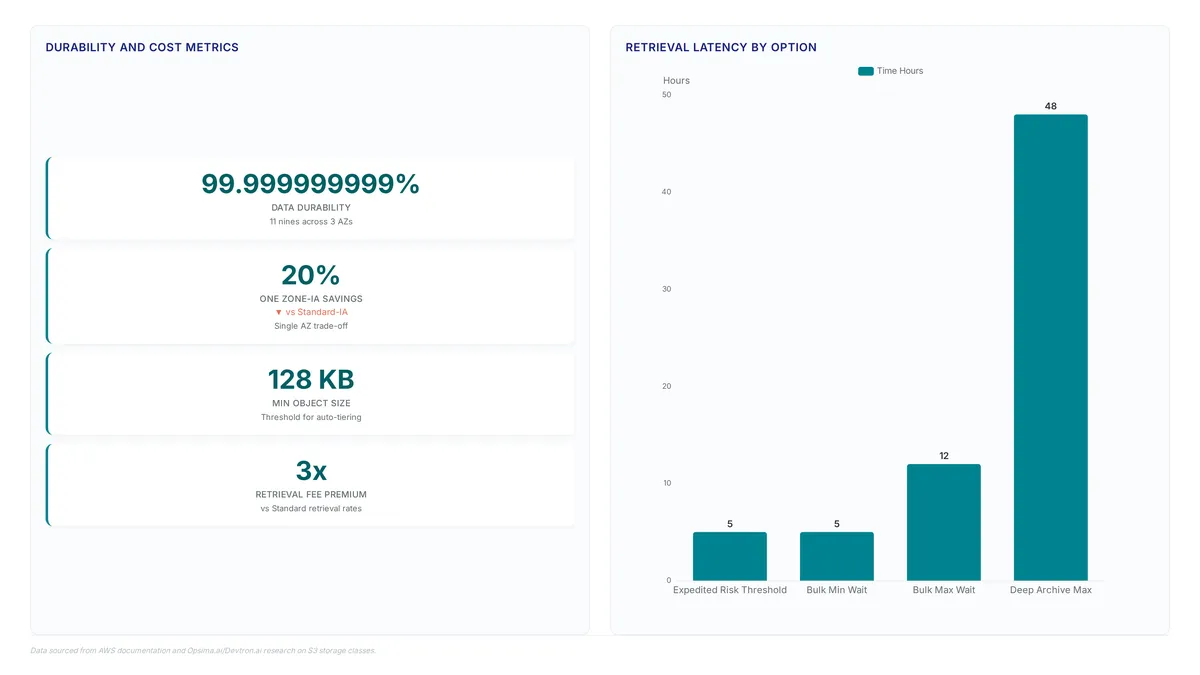
All S3 tiers offer 11 nines durability, but SingleAZ classes drop availability to 99.5%. Learn why redundancy models matter for your data.
Learn how April 2024 S3 protocol changes let SQL policies govern file access, preventing unauthorized data exposure better than firewalls.

Test files from 1KB to 1GB reveal why theoretical docs fail. Learn to measure throughput and latency before users hit bottlenecks.

Eliminate GPU idle time by serving data faster than standard object stores. Learn how zonal colocation prevents costly compute waste during training.
Discover how presigned URLs divide large objects into independent parts to maximize efficiency without backend latency or credential risks.

Kubernetes has a blind spot: it lacks native object storage support. You cannot request a bucket the way you request a block volume without external...

Process massive token volumes safely by transforming standard APIs into governed MCP servers that prevent unauthorized access risks.

Cloudflare R2 removes egress fees entirely, offering $0 outbound transfers. This shifts budget forecasting for media-heavy apps away from opaque network...

Deploy S3-compatible object storage to save 70% on cloud bills compared to AWS S3, featuring true API compatibility and no egress fees.

Cloudflare R2 lacks object locking, stalling migrations. Discover specific S3 API gaps breaking legacy workflows before you switch storage providers.
Discover where partial support for PutBucketVersioning reveals fragility in cloud storage. Learn why strict behavioral mechanics matter for true...
Learn why April 2024 S3 changes trigger Parquet memory leaks in Postgres and how to tune foreign wrappers for stable object storage queries.

Stop single-stream bottlenecks. Split large files into parts and tune concurrency to maximize bandwidth for faster AWS CLI uploads.

Fix Cloudflare R2 endpoint errors causing inaccessible files. Learn how Class A operations trigger unexpected charges despite zero egress claims.
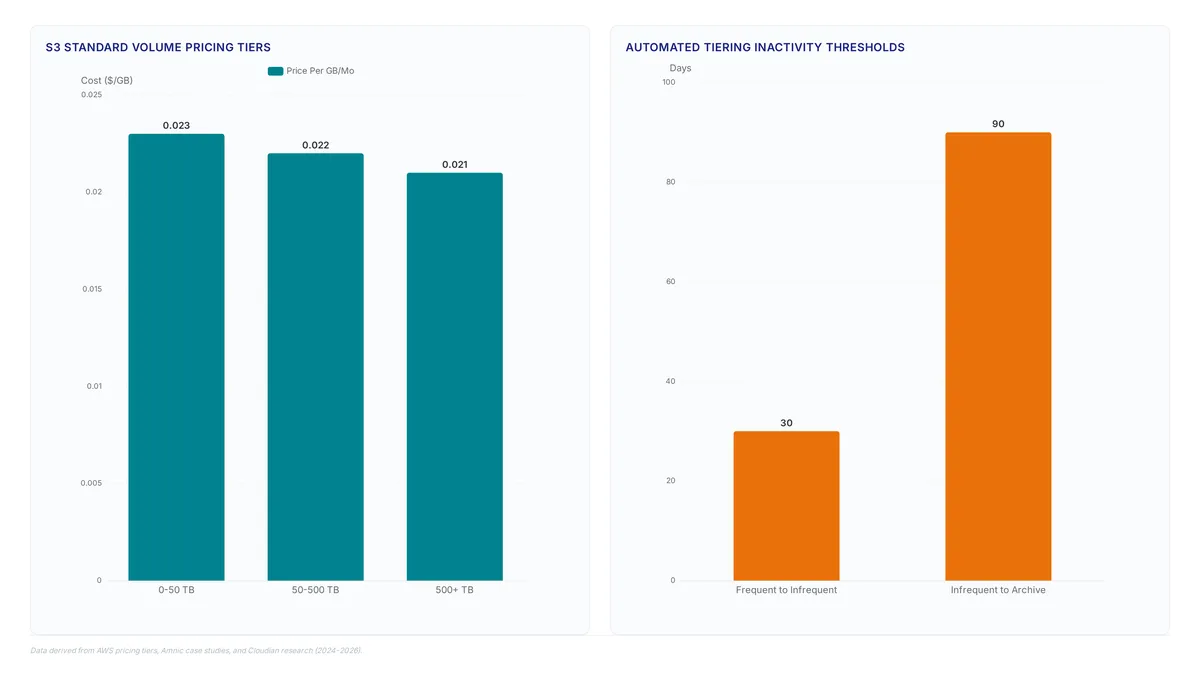
Learn how S3 buckets deliver 99.999999999% durability while avoiding the hidden costs of misconfigured containers and small file overhead.

S3 billing spans six dimensions, creating a 23x price gap. Learn why storage class selection alone rarely stops bill shock in production.

Discover why cloud providers charge $0.09 per gigabyte for egress and how this asymmetry inflates migration bills despite free ingress offers.

With object limits now at 50 TB, traditional partitioning is obsolete. Learn how to adapt storage classes and bucket types for massive datasets.

Learn how S3 Transfer Acceleration uses CloudFront edge locations to deliver up to 300% faster uploads for cross-continent data transfers.

Compare Cloudflare R2 and AWS S3 costs where Class A operations drive high-frequency write workflows. Learn why zero egress changes total ownership.

Glacier retrieval spans milliseconds to 12 hours. Learn how Deep Archive's $0.00099/GB pricing fits long-term retention strategies.

Move petabytes safely by mapping S3 Object Lock to retention policies and using parallel transfers for zero downtime during your cloud migration.
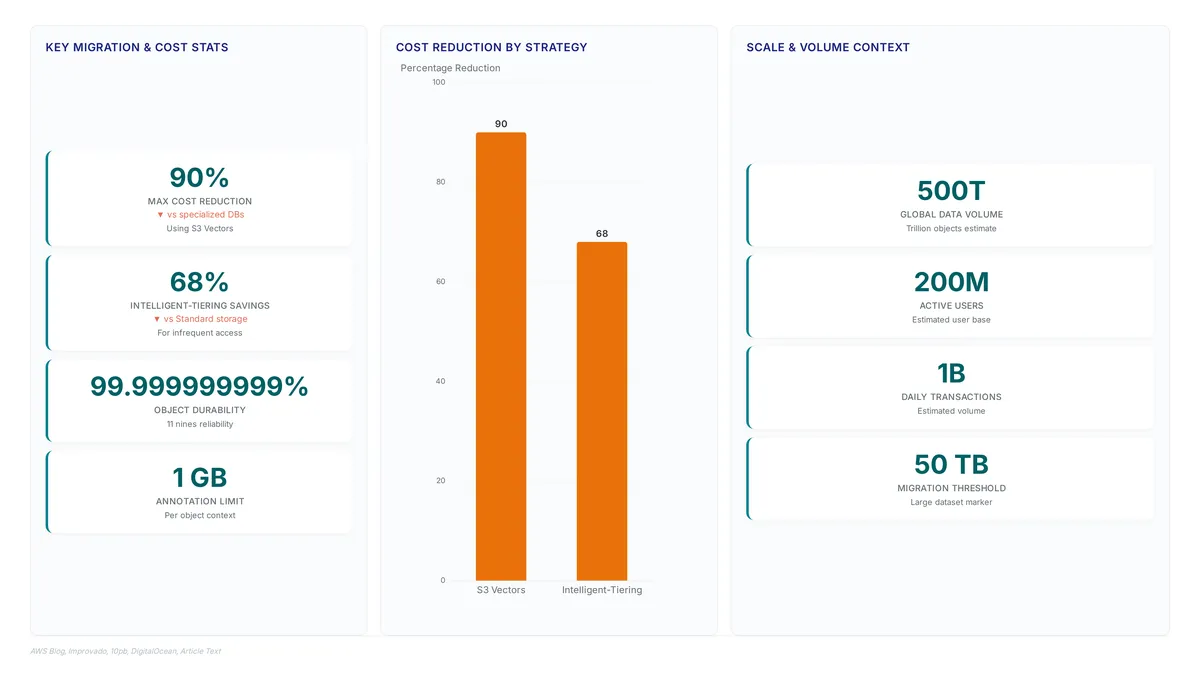
Amazon S3 currently stores a vast number of objects, yet its dominance no longer guarantees optimal value.

Cut storage expenditures by 70% while maintaining full application interoperability with true S3 API compatibility for enterprise data.

Avoid configuration drift during AL2023 migration by automating disk swaps and Active Directory rejoins instead of relying on manual coordination.
Avoid hidden fees with transparent pricing starting at $10/TB. Discover S3-compatible storage built for massive scale and predictable budgets today.

Early cloud strategies treated regions as checkboxes, creating a sovereignty gap. Learn how decoupling storage enforces legal authority by design in 2026.

Global sovereign cloud spending will hit billions in 2026 as regulators force data localization.

Explore how 500 trillion objects define modern scale and why Rabata.io offers a faster, S3-compatible alternative for enterprise data.

Discover how rigid 5 GB upload limits and $0.12/GB egress fees inflate cloud bills. Learn to audit storage services and cut costs by 70%.

Moving 100TB of data triggers massive egress fees. Learn how egress-free storage eliminates these penalties and unlocks true multicloud flexibility.

Learn how geofencing on a country level blocks cross-border flows while S3 Object Lock satisfies NIS2 ransomware recovery standards effectively.
Stop risking total data loss. Learn why the APPKEY file matters and how to execute a full Coolify backup and restore in just 12 minutes.

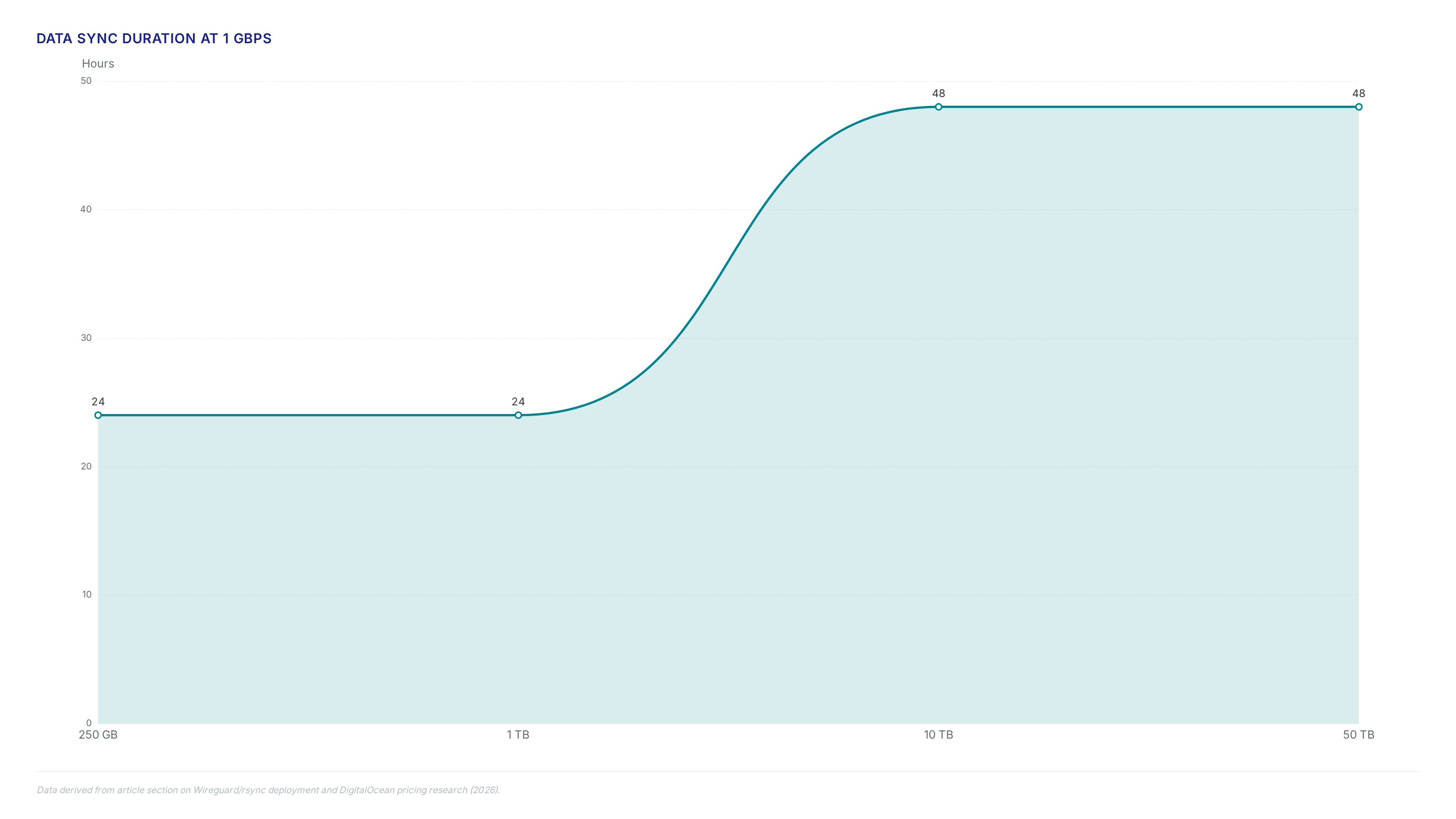
Stop forcing CLI scripts on petabyte moves. Learn why 54% of firms choose physical Snowball devices when bandwidth fails during cloud migration.

Learn why Mountpoint for S3 on EKS requires static provisioning and manual PersistentVolume mapping instead of dynamic allocation.

Rising cloud costs and unpredictable billing are driving enterprises away from Amazon S3 toward flexible alternatives.
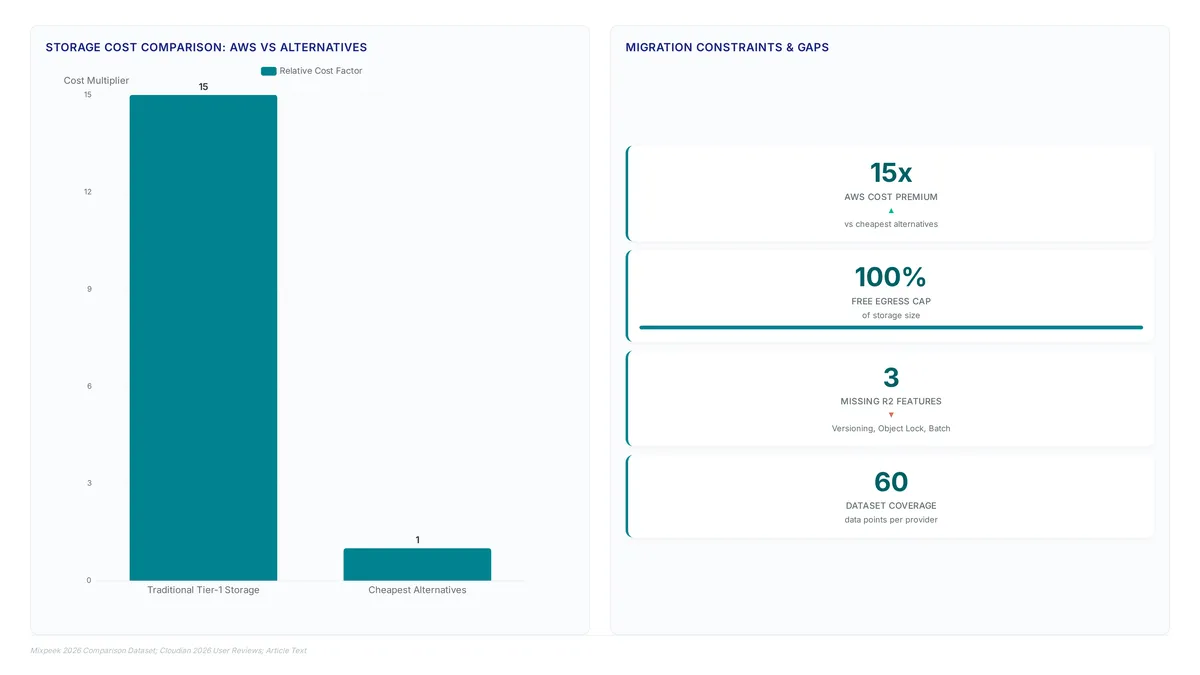
S3 compatibility is a spectrum, not a binary switch. Learn why API edge cases break tooling and how flat-rate models contrast with tiered pricing.

Managed S3-compatible providers can price storage as low as $0.006/GB per month, undercutting standard hyperscaler rates. Compare cost, licensing, and GDPR trad

Discover why teams migrate to S3-compatible storage to cut expenses by 40-80% and eliminate unpredictable egress bills today.
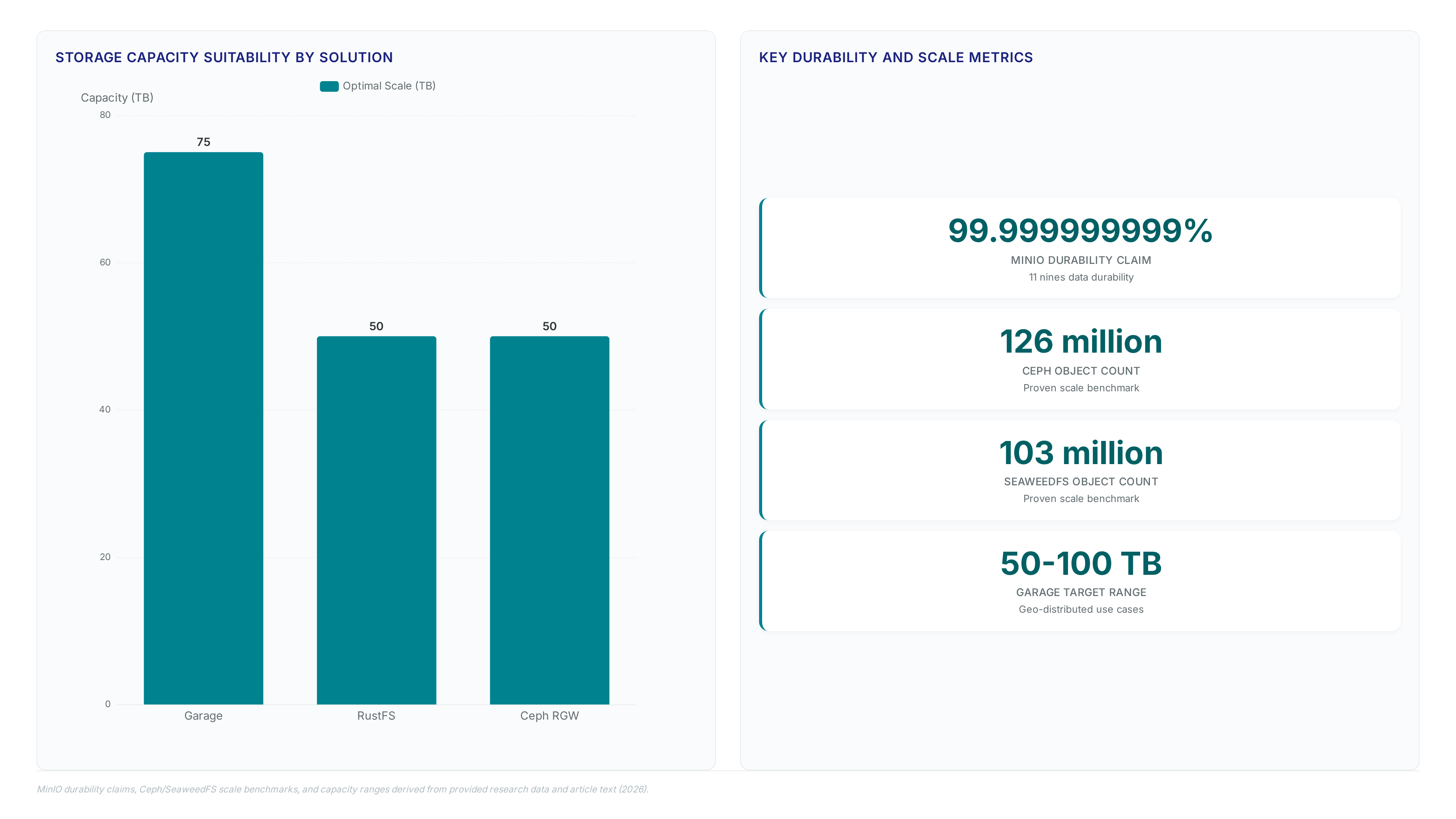
MinIO archived its community edition in late 2025. That decision forced self-hosted teams to scramble for a new home for every Parquet file and...
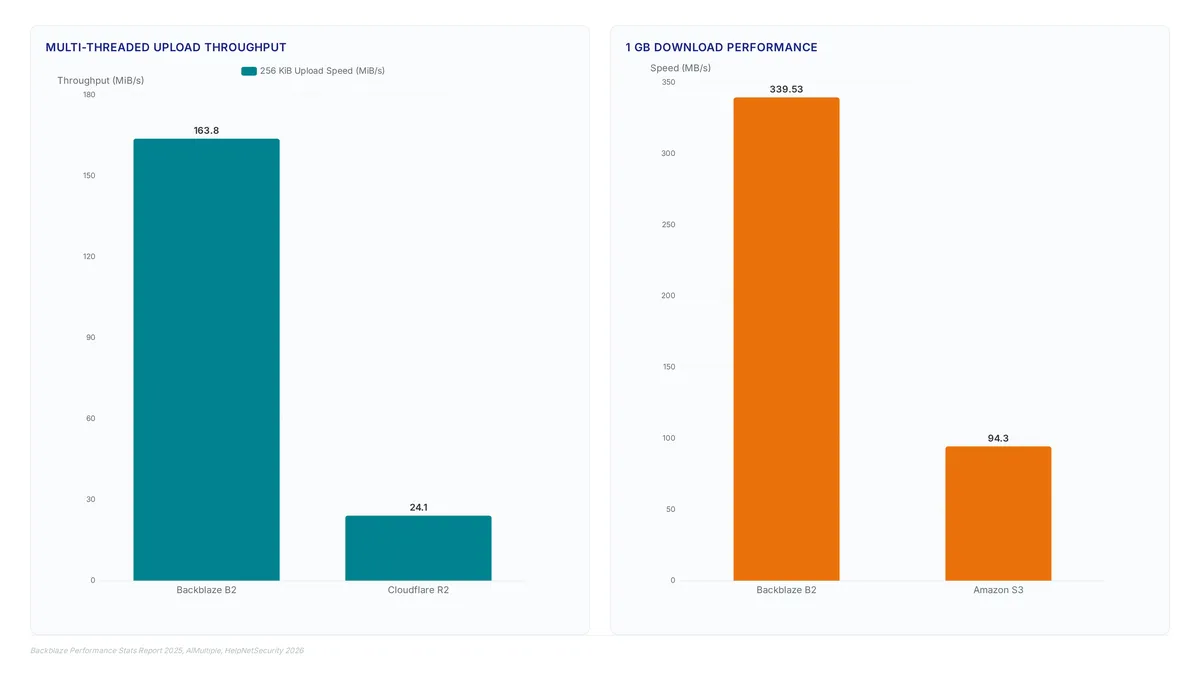
S3 latency traps stall pipelines. Benchmarks show 163.80 MiB/s vs 24.10 MiB/s gaps. Discover how Rabata delivers verified speed.
Fix xamz headers immediately to avoid access rejection. Learn why XML ACLs fail and how to map complex trees to simplified policies.

Sedai research shows autonomous systems cut storage costs 30% by managing complexity human operators cannot sustain across thousands of buckets.

The Amazon S3 API enforces a hard 5 terabyte ceiling on single objects, proving its 2006 architecture remains rigidly set by strict limits today.

With over 2 Zettabytes under management, firms reject total cloud migration. Discover how hybrid governance solves egress costs without moving data.

HDD tiers now underpin exabyte-scale AI where flash costs fail. See how a 5-year contract validates this economic model for massive datasets.
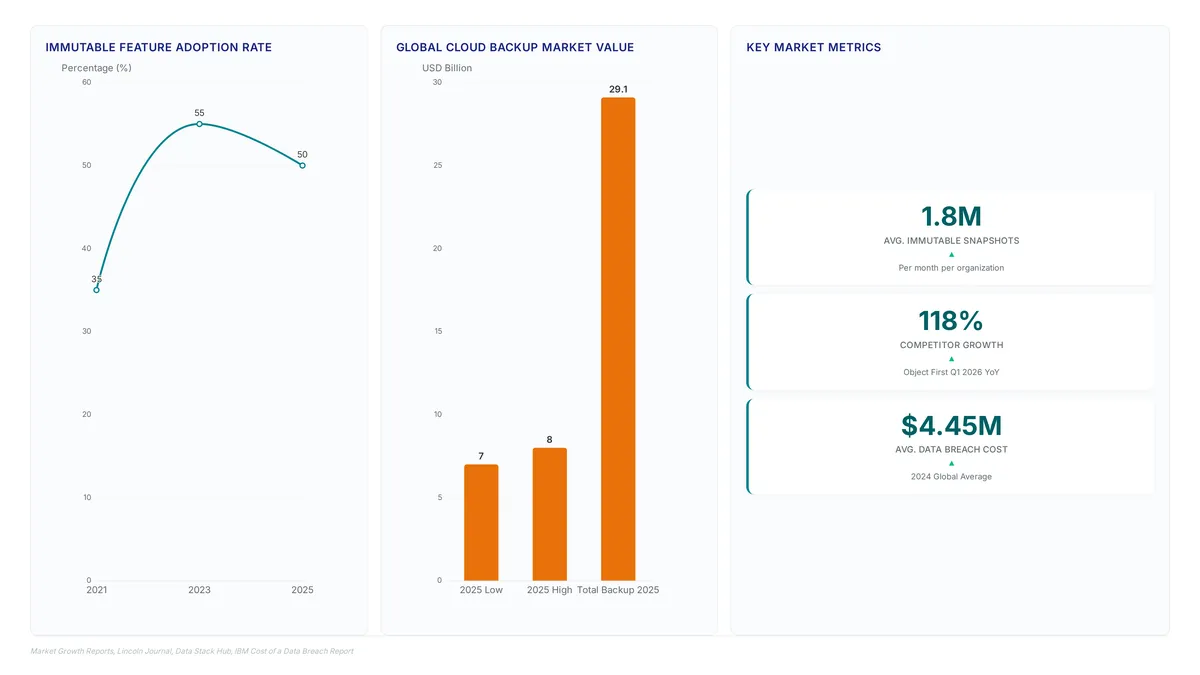
MSP360 Backup 8.6 closes critical immutability gaps by extending Object Lock to SQL Server and Legacy Backup formats.
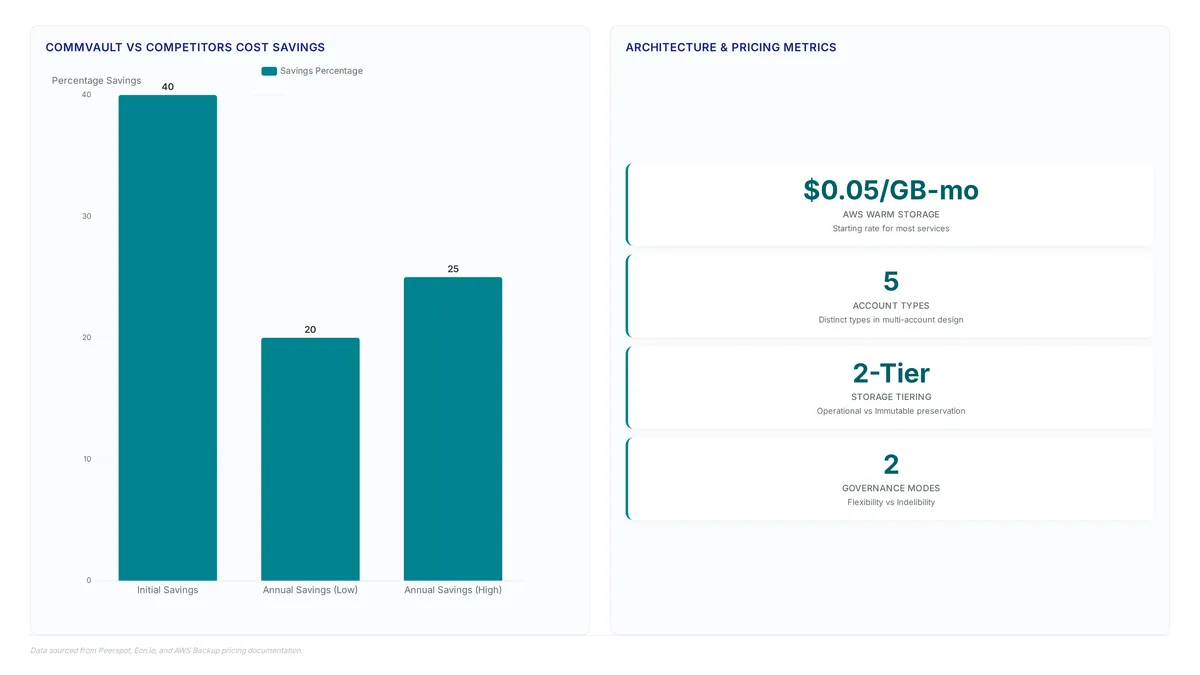
Immutability costs pennies, yet most enterprises fail. Learn why a two-tiered architecture with isolated recovery is vital for ransomware survival.

Query metadata to find 429 errors before they stall AI training. Turn passive inventory into active cost control with precise access data.

Raw 4.9x speed gains drain budgets via management fees. Discover how architectural efficiency delivers 9x improvements without inflating cloud costs.

Filebase's $15/TB S3-compatible object storage with free egress: when free egress actually cuts your bill, the 100 RPS limit, and a pre-migration checklist.

GKE Inference Gateway uses prefix caching to cut time-to-first-token latency by over 70%, eliminating redundant computation in AI pipelines.

Most AI pilots fail due to fragmented storage. Learn why unified access beats raw compute for scaling beyond the pilot phase.

Scality launched ADI on 12 May 2026 to manage data tiers. This analysis explores why human oversight remains vital for safe AI storage.
Cut AI inference time by routing traffic through our new Tokyo endpoint. We support 1 exabyte of data with local S3 compatibility.

Cyberattacks rose 71%. See how Synology ActiveProtect and Wasabi enforce immutable storage to kill egress fees and secure your data.

Benchmarks reveal Web Streams run 120x slower than optimized Node.js pipelines. See why legacy locking breaks modern server-first architectures.

Stop guessing at capacity. Learn how lifecycle policies cut storage bills by 23x using Glacier Deep Archive vs Standard tiers.

Fewer than 10 percent of enterprises scale AI due to fragmented storage. Learn how unifying vector and graph data fixes the bottleneck.
See how Btrfs handles 150 uploads per second. Managed S3 fails at this scale, but selfhosted storage keeps latency predictable.
AWS S3 now holds 500 trillion objects. See how strict API backward compatibility lets your 2006 code run unchanged in 2026.

AWS S3 now handles 200 million requests. I break down the architecture keeping 500 trillion objects durable after two decades.

Stop wasting time on copy mechanics. Learn how S3 Files let compute access 40 PB of genomic data directly, skipping fragile transfers.
We tested S3 Files on April 7, 2026. Updates hit in 1.8s, but new files still lag 30s. Here is the sync math for your ML pipelines.

AWS S3 Files now serve NFS v4.2 directly, letting 54% of multi-cloud users consolidate storage without duplicating data or paying gateway fees.
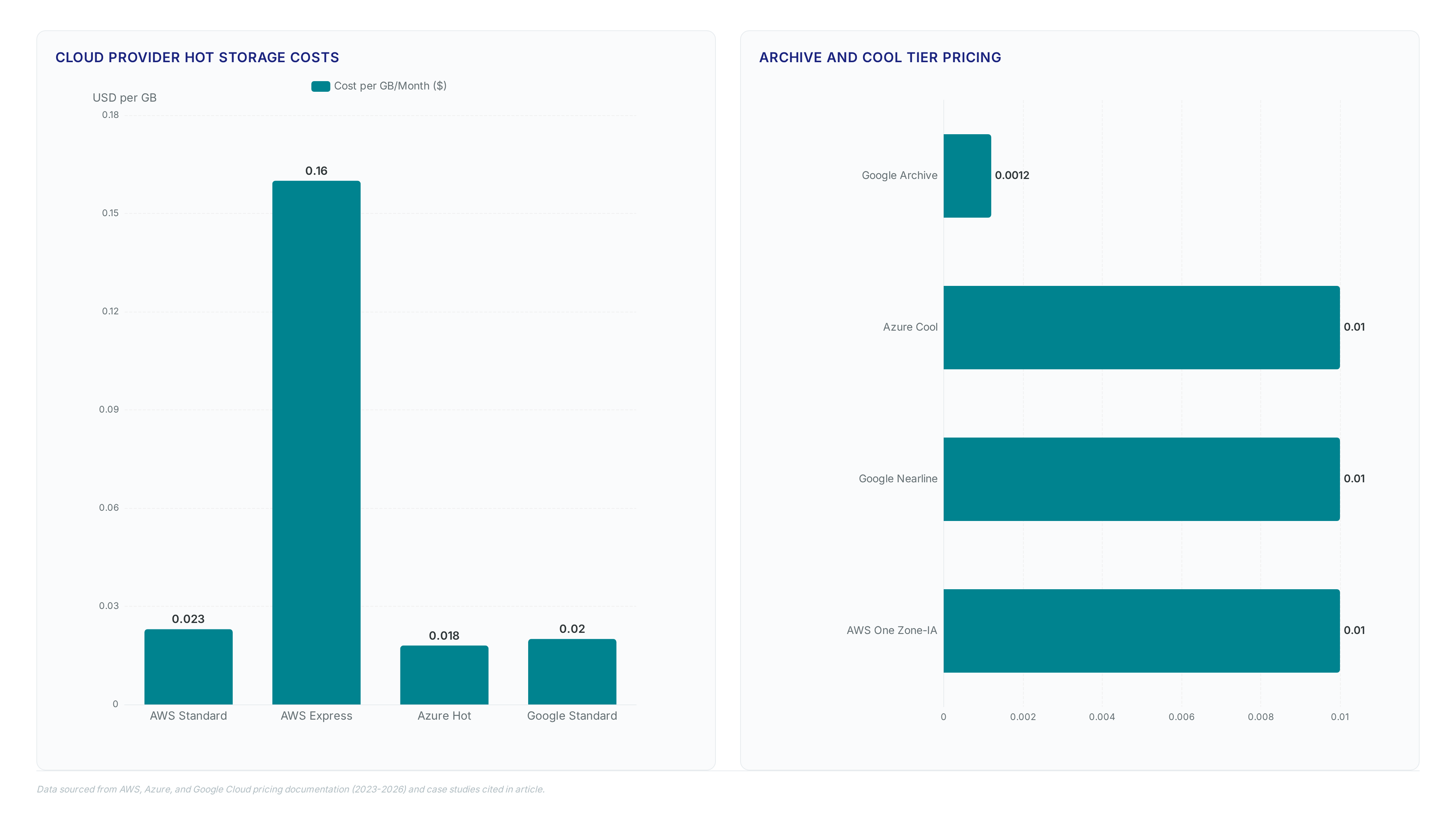
S3 Express now supports inventory reports at $0.16 per GB. Stop using slow List API calls and get daily CSV metadata for your directory buckets.

PostgreSQL's durability math forces a 23x cost variance. Learn why WAL flushes demand local NVMe, not object storage, to prevent stalling.
NetApp's new EF50 delivers 110 GBps read throughput to stop GPU starvation during large-scale AI model training cycles.

See how Manchester scanned 3.5 billion files to find cold data, avoiding a costly hardware refresh by moving archives to tape.
Wasabi acquires Lyve as Seagate stock rises. With 63% cloud adoption, independent storage must scale to survive hyperscaler pressure.
Stop risking single points of failure. Laravel Backup v2.0 enables parallel uploads to S3 and Google Drive, securing your data across multiple clouds instantly.
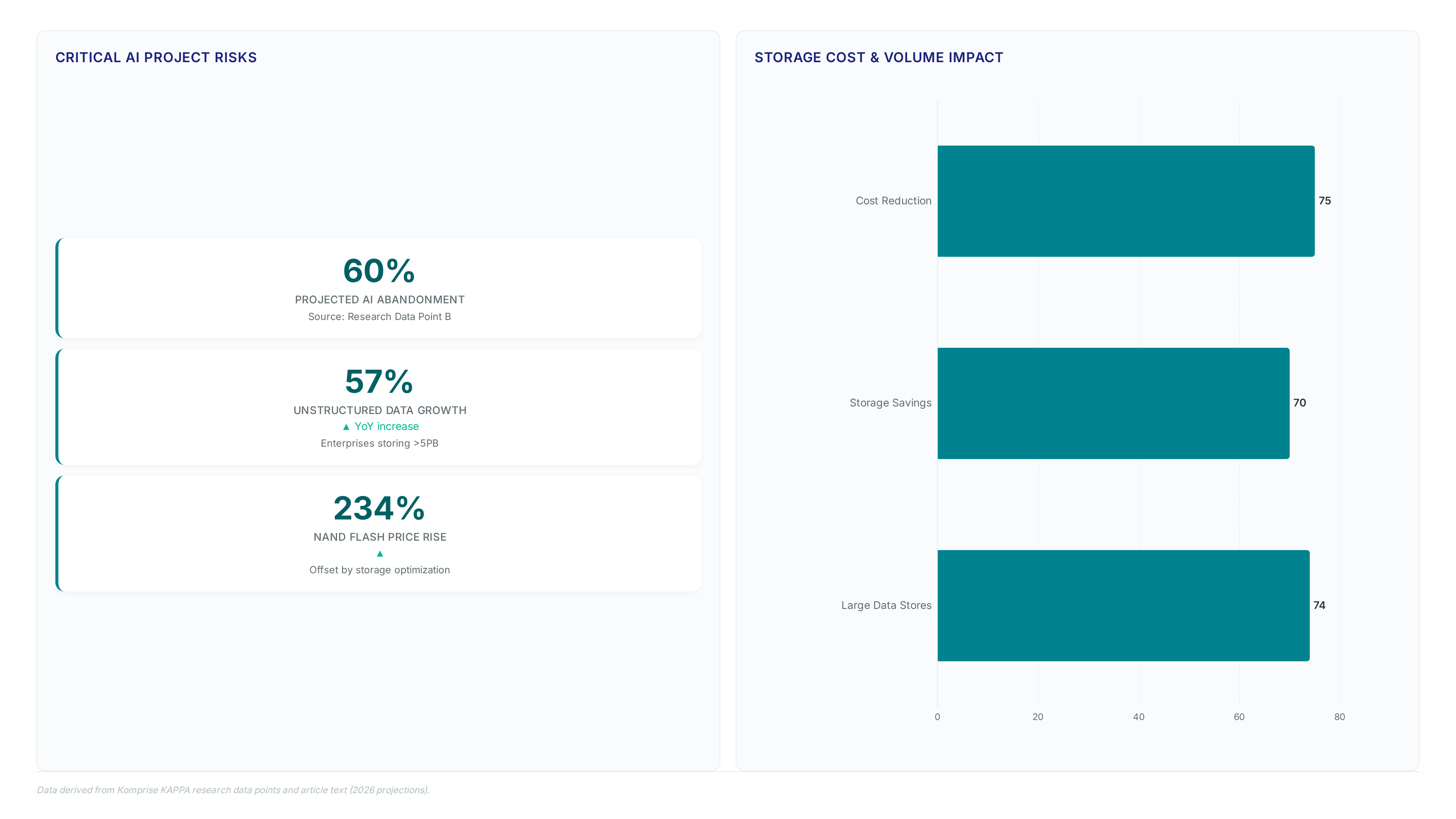
Komprise Kappa automates tagging across silos so agents can query the 90% of unstructured data blocking your AI training today.
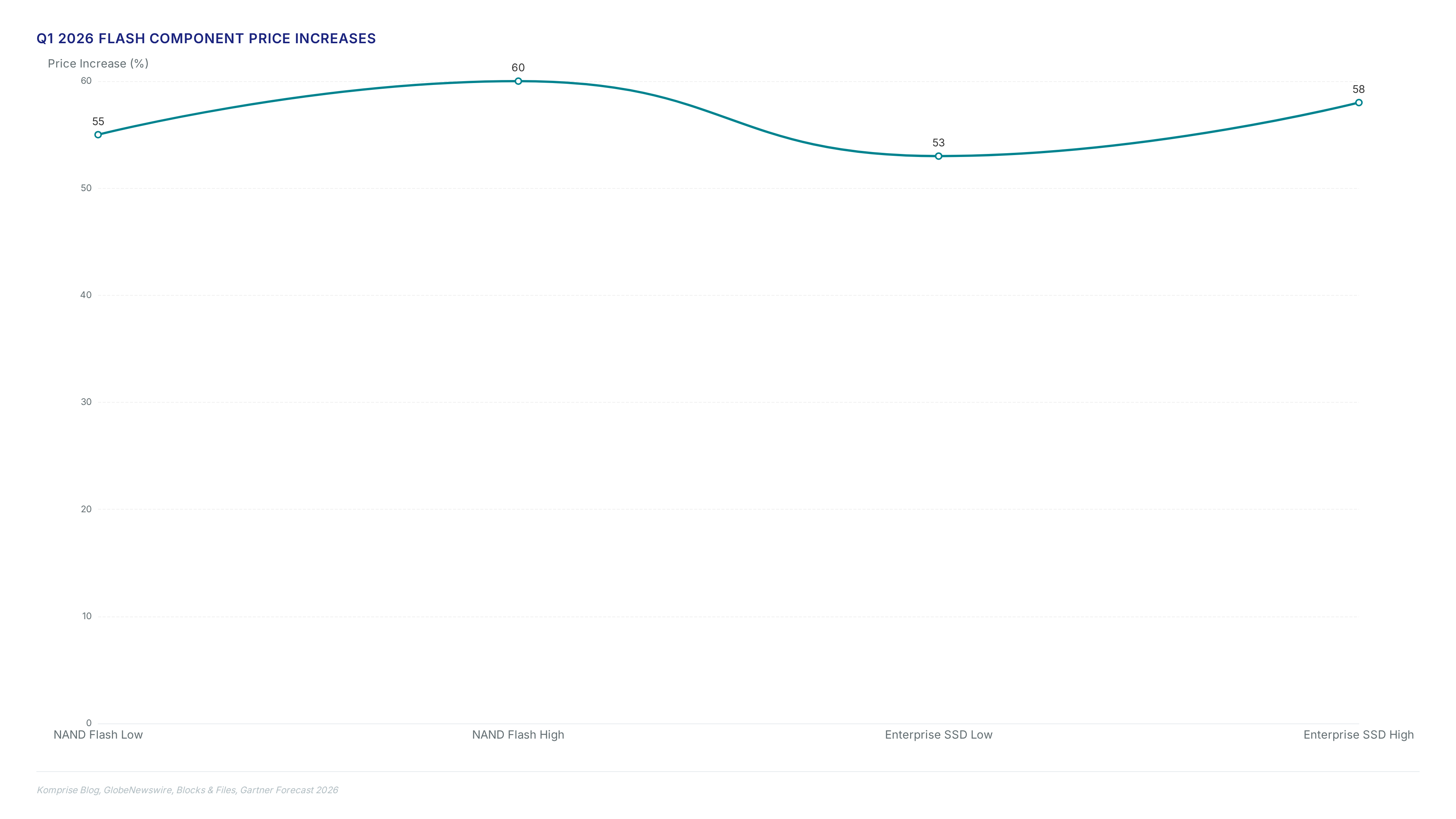
NAND prices jumped 234% in 2026. I show how Flash Stretch finds the 70% of cold data clogging your expensive primary arrays.
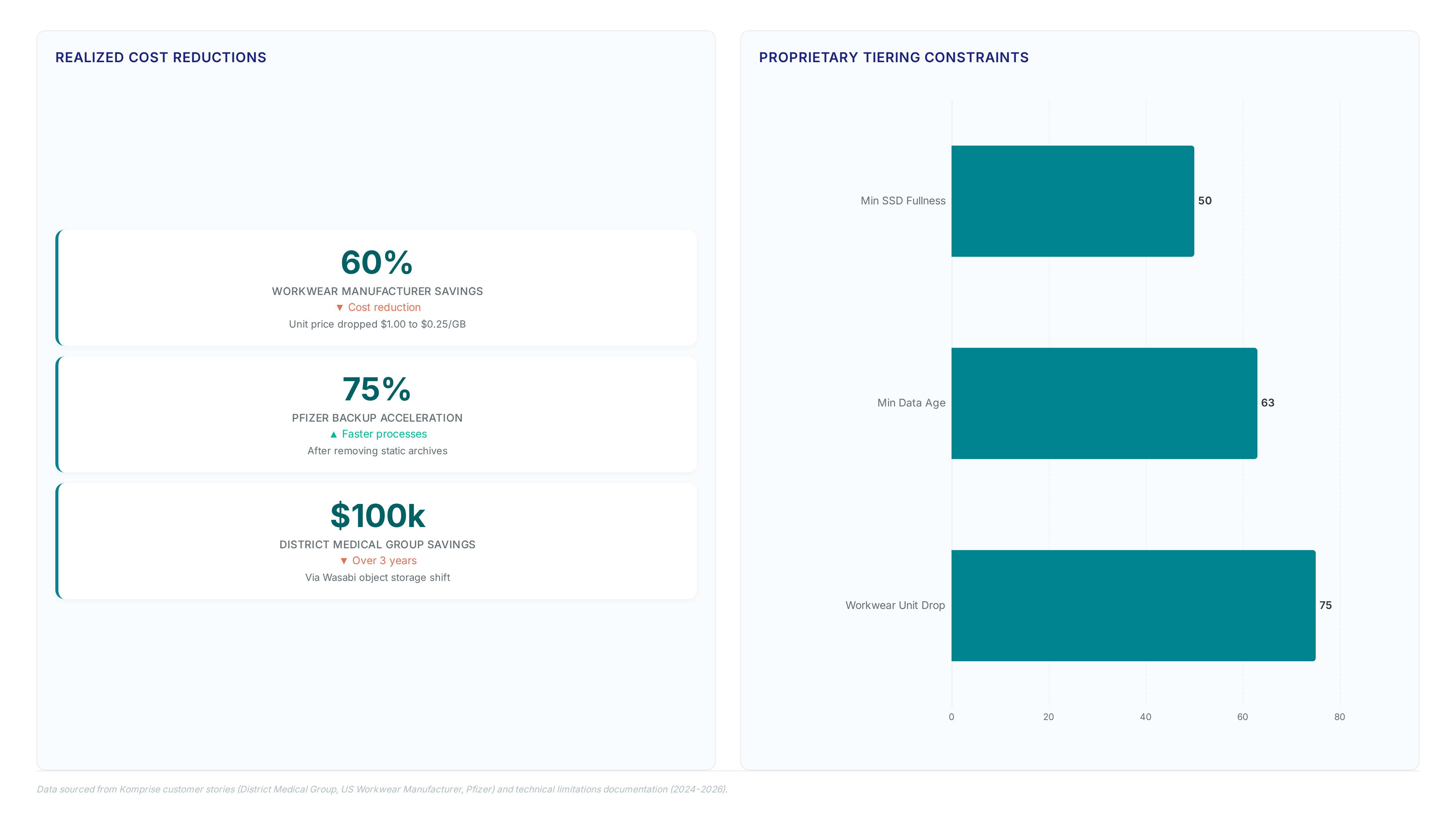
NAND flash prices jumped 234% in 2026. I show how analytics reclaim 70% of your primary storage without costly vendor lock-in.

See how FastAPI type hints cut debugging time by 40% while enforcing strict data contracts without extra code.

Stop guessing at S3 performance. My analysis of the new minute-level data shows exactly where single-digit ms variance impacts your bill.

Hidden egress fees consumed 48% of total cloud spend last year. Learn how to audit dark data and stop the financial bleed before scaling AI.

Move 2.7 PB for just $2,000 using distributed rclone. We replaced brittle scripts with ECS and SQS to stop transfer stalls.
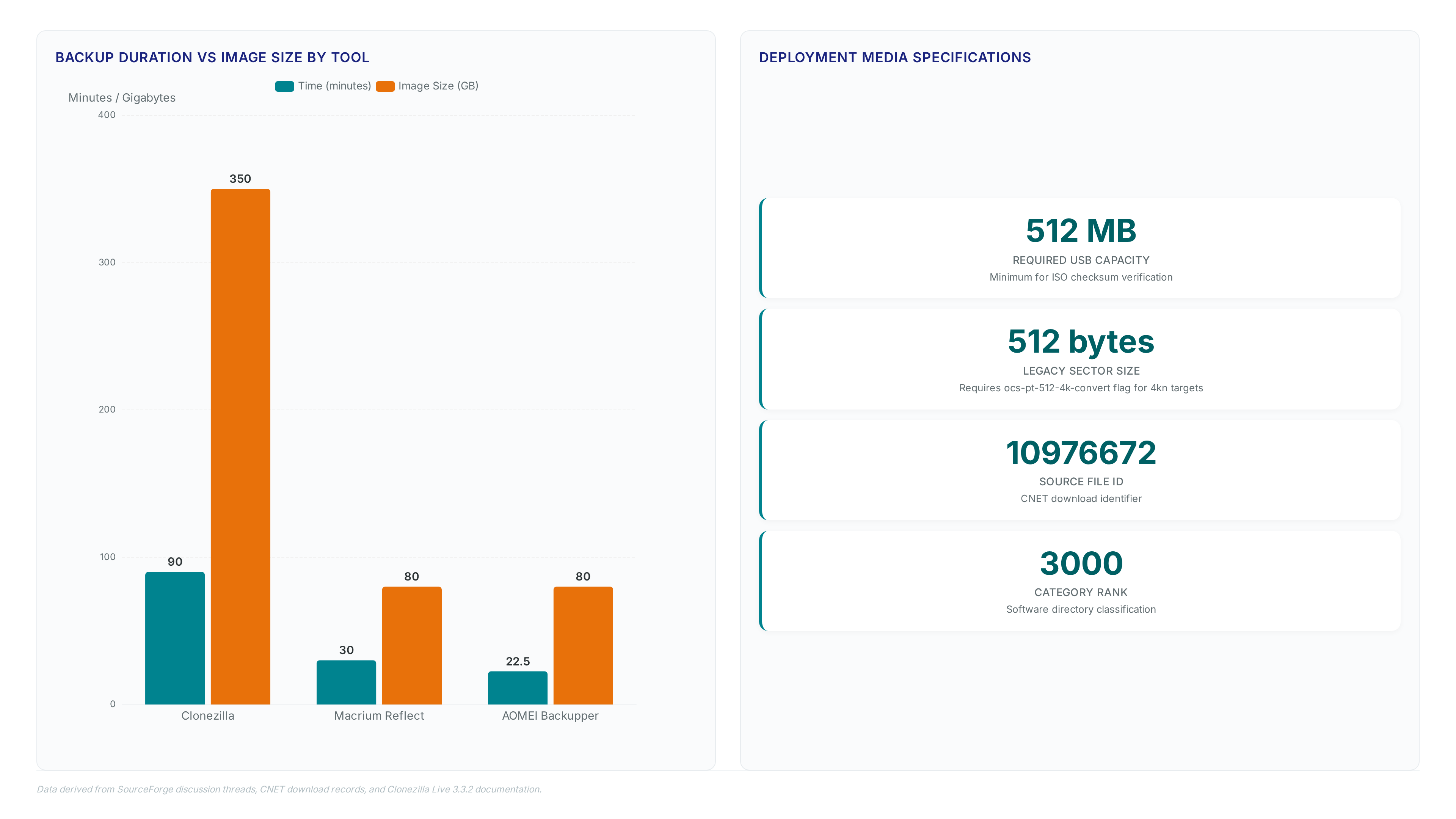
After 50+ server restores, I know disk imaging saves days. Clonezilla reads only used blocks, creating smaller images than dd for faster recovery.
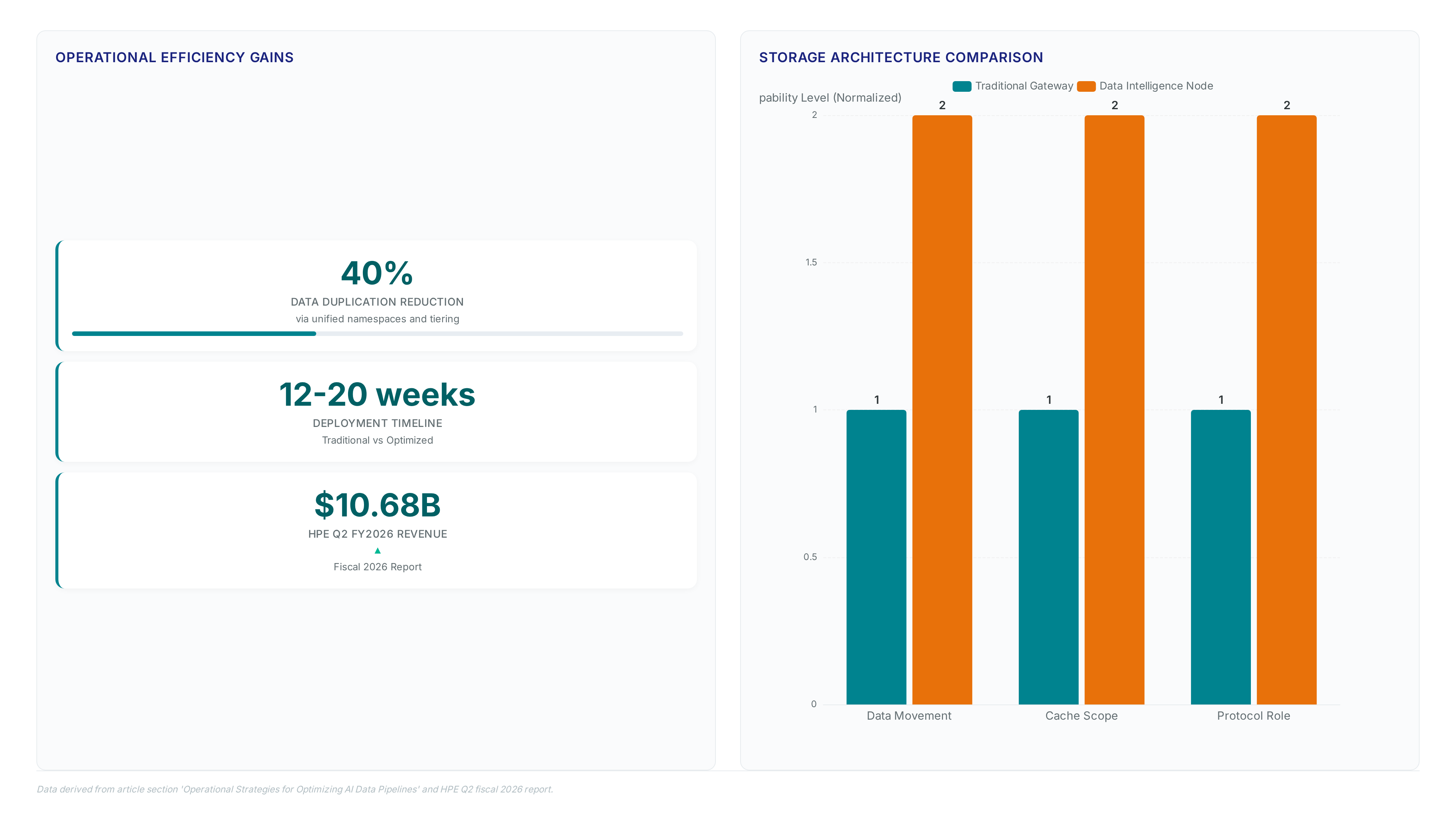
Server DRAM prices surged 95% last quarter. Learn why data readiness, not model size, is the real constraint killing enterprise AI production.
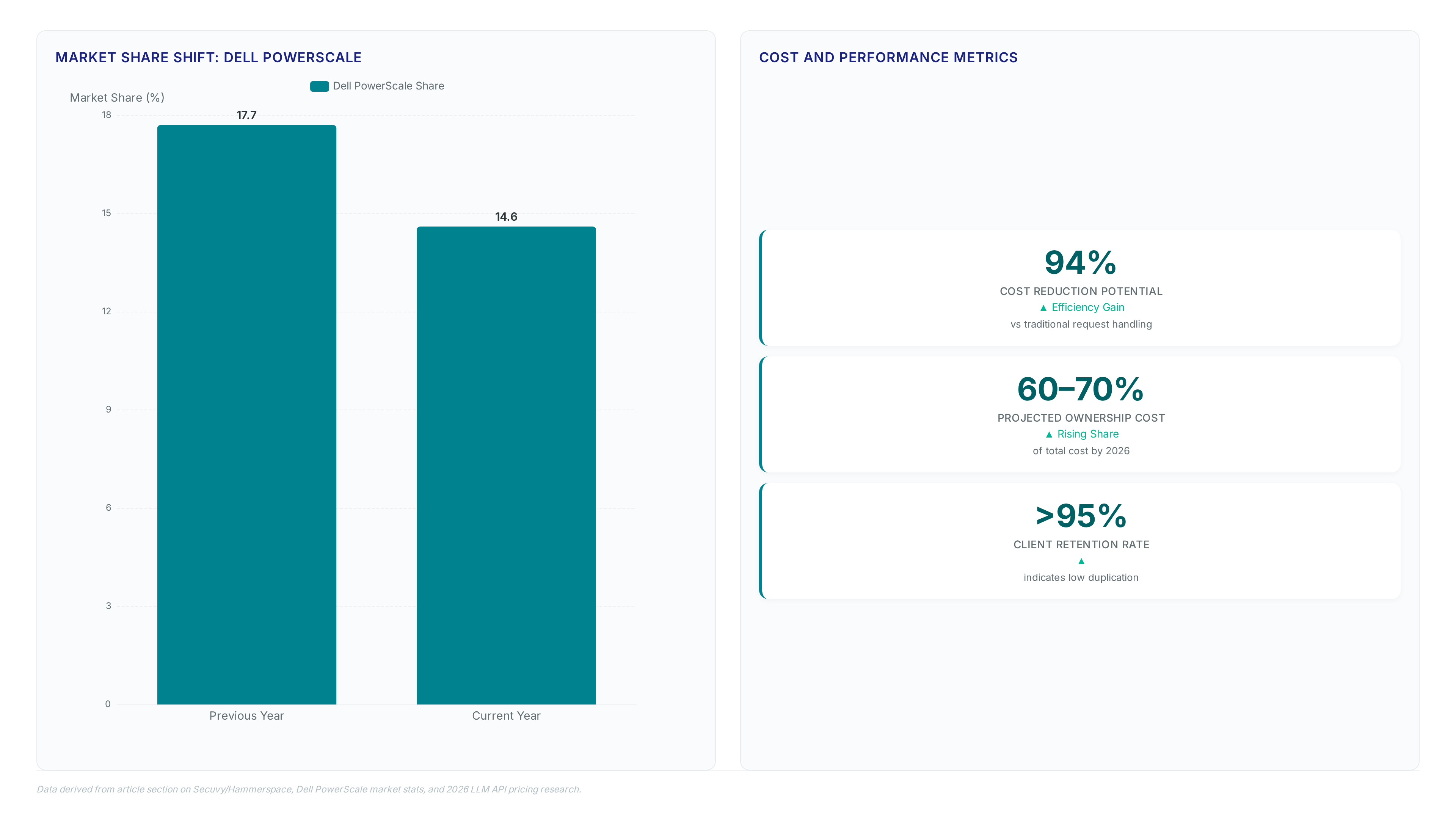
Hammerspace reports 2026 bookings are 14x higher as compute bottlenecks shift to data access. Learn why a trusted data plane is now mandatory.

Stop wasting millions moving data. Our new architecture cuts storage costs 40% by querying tables where they live without complex pipelines.

Unpredictable charges inflate cloud costs by 26%. Learn why 62% of IT leaders blow budgets and how to bypass these hidden tolls today.
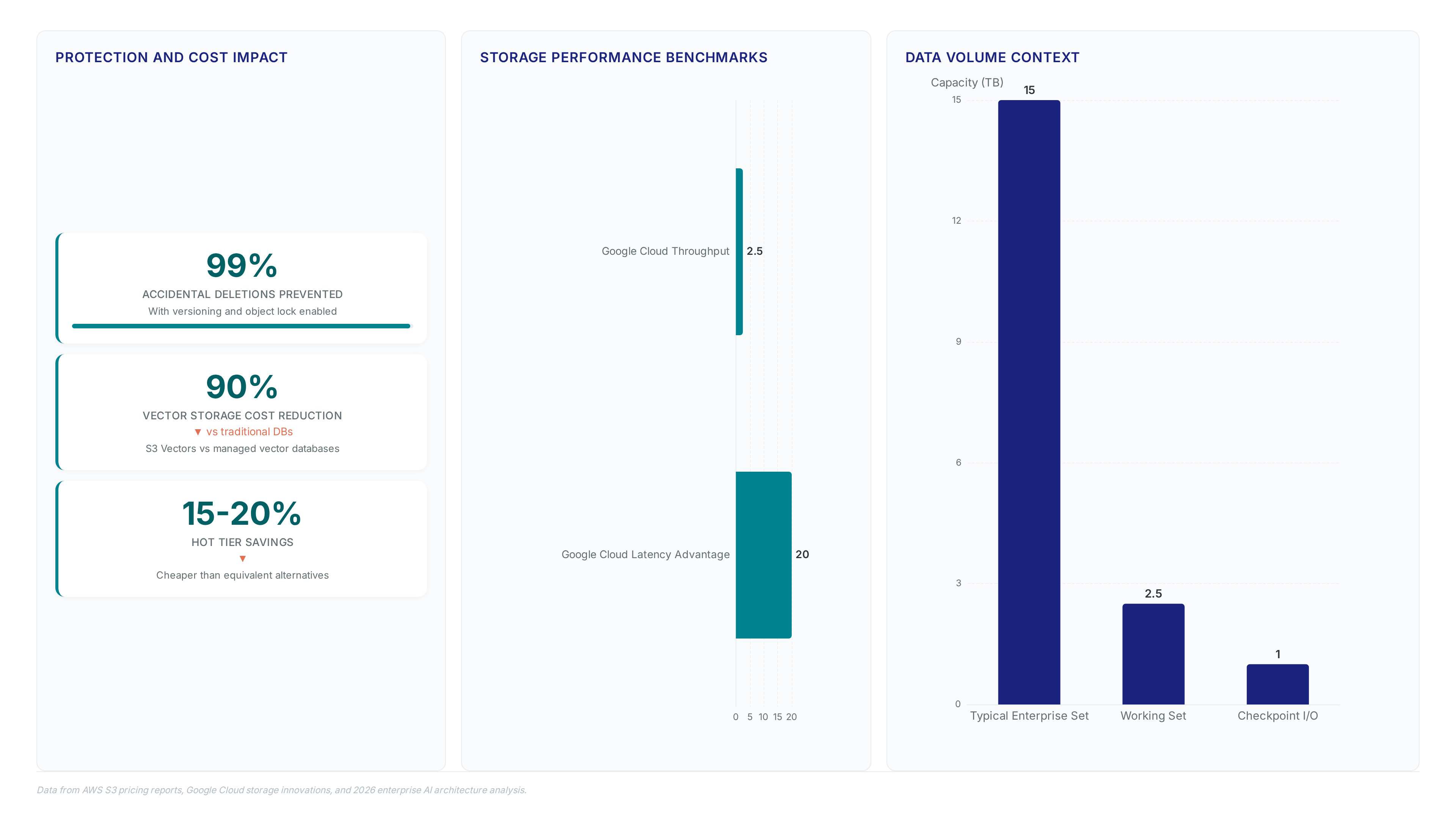
EBS hits 20x faster I/O than S3. Learn why block storage beats object stores for high-velocity AI training pipelines.

S3 now handles 200 million requests per second. I break down the engineering behind 500 trillion objects and why metadata optimization is critical.

After 18 years, S3 holds 500 trillion objects with eleven nines durability. See how simple PUT/GET primitives scaled globally without breaking apps.
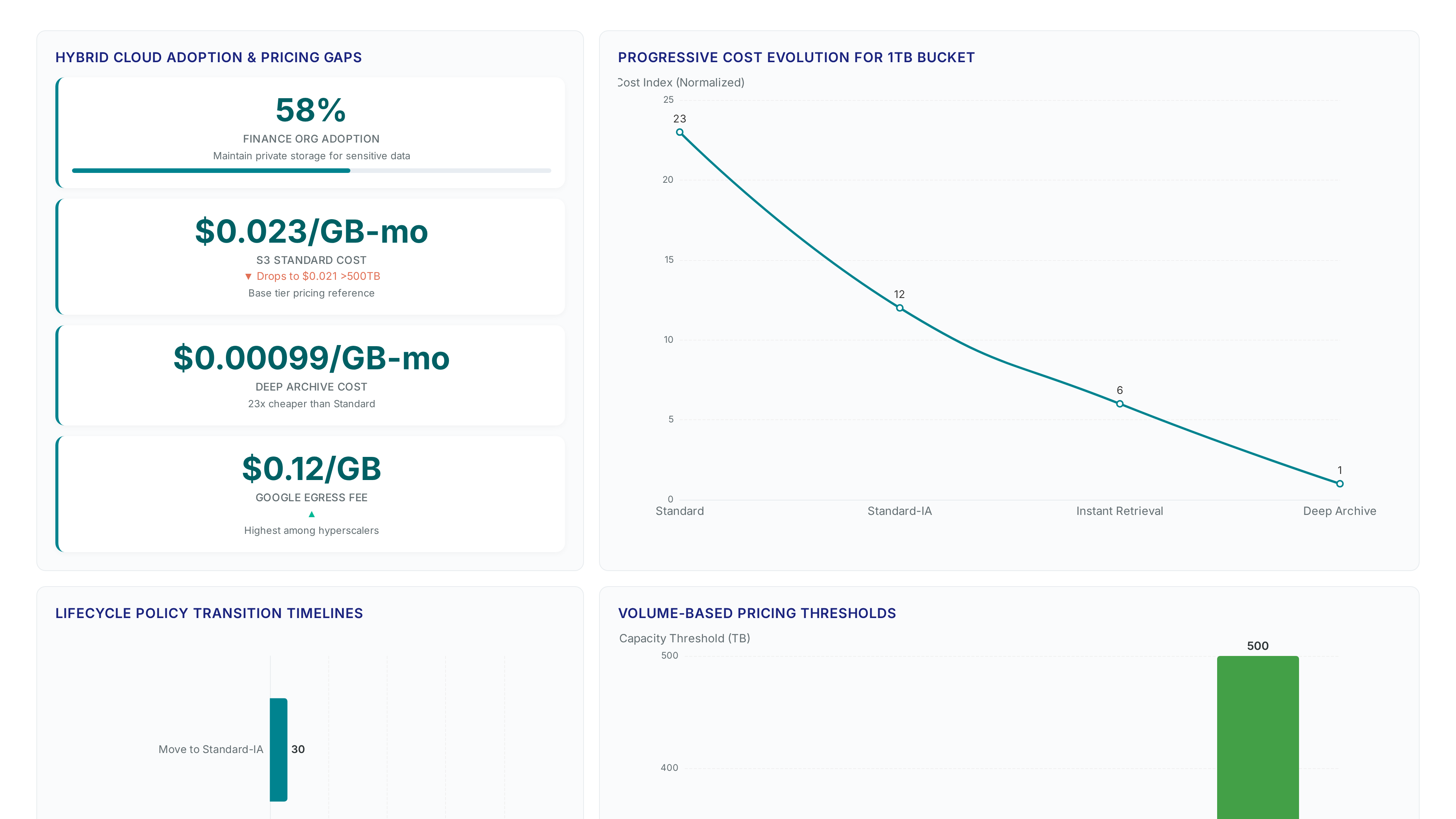
See how Amazon S3 replaced tape libraries in 2011, eliminating manual seeks and proving cloud durability for enterprise Oracle backups.
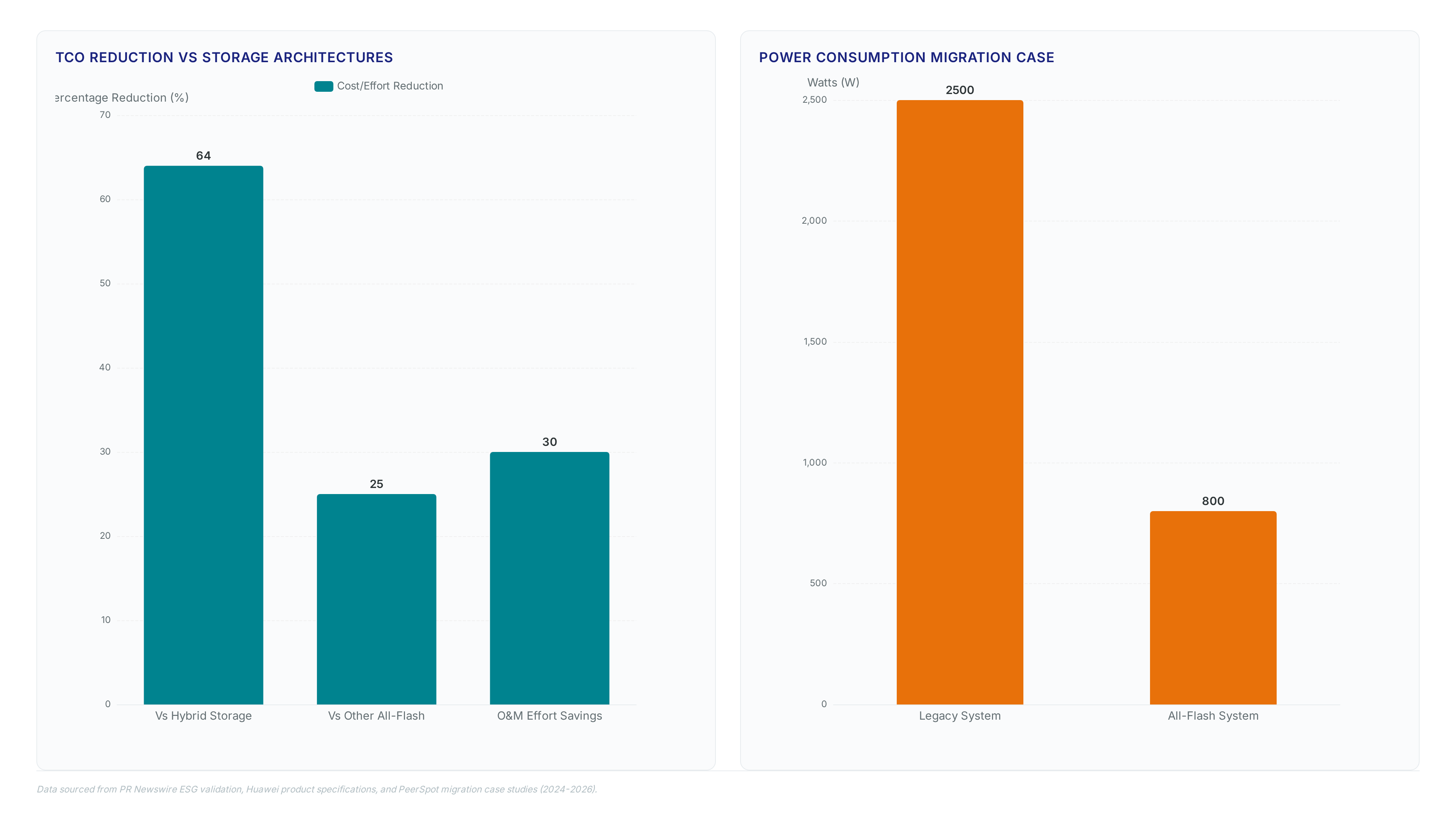
Huawei's new allflash system hits 876,256 IOPS with 32 μs latency, proving converged storage can slash TCO by 64% for AI clusters.

AWS fixes 18 years of S3 collisions with account regional namespaces. Learn how the new {bucketname}{accountid}{region} format stops hijacks today.

After 50+ server restores, I know disk imaging saves days. Clonezilla reads only used blocks, creating smaller images than dd for faster recovery.

See how Manchester scanned 3.5 billion files to find cold data, avoiding a costly hardware refresh by moving archives to tape.

Cut AI inference time by routing traffic through our new Tokyo endpoint. We support 1 exabyte of data with local S3 compatibility.

Stop risking single points of failure. Laravel Backup v2.0 enables parallel uploads to S3 and Google Drive, securing your data across multiple clouds instantly.

S3 Express now supports inventory reports at $0.16 per GB. Stop using slow List API calls and get daily CSV metadata for your directory buckets.

PostgreSQL's durability math forces a 23x cost variance. Learn why WAL flushes demand local NVMe, not object storage, to prevent stalling.

We tested S3 Files on April 7, 2026. Updates hit in 1.8s, but new files still lag 30s. Here is the sync math for your ML pipelines.
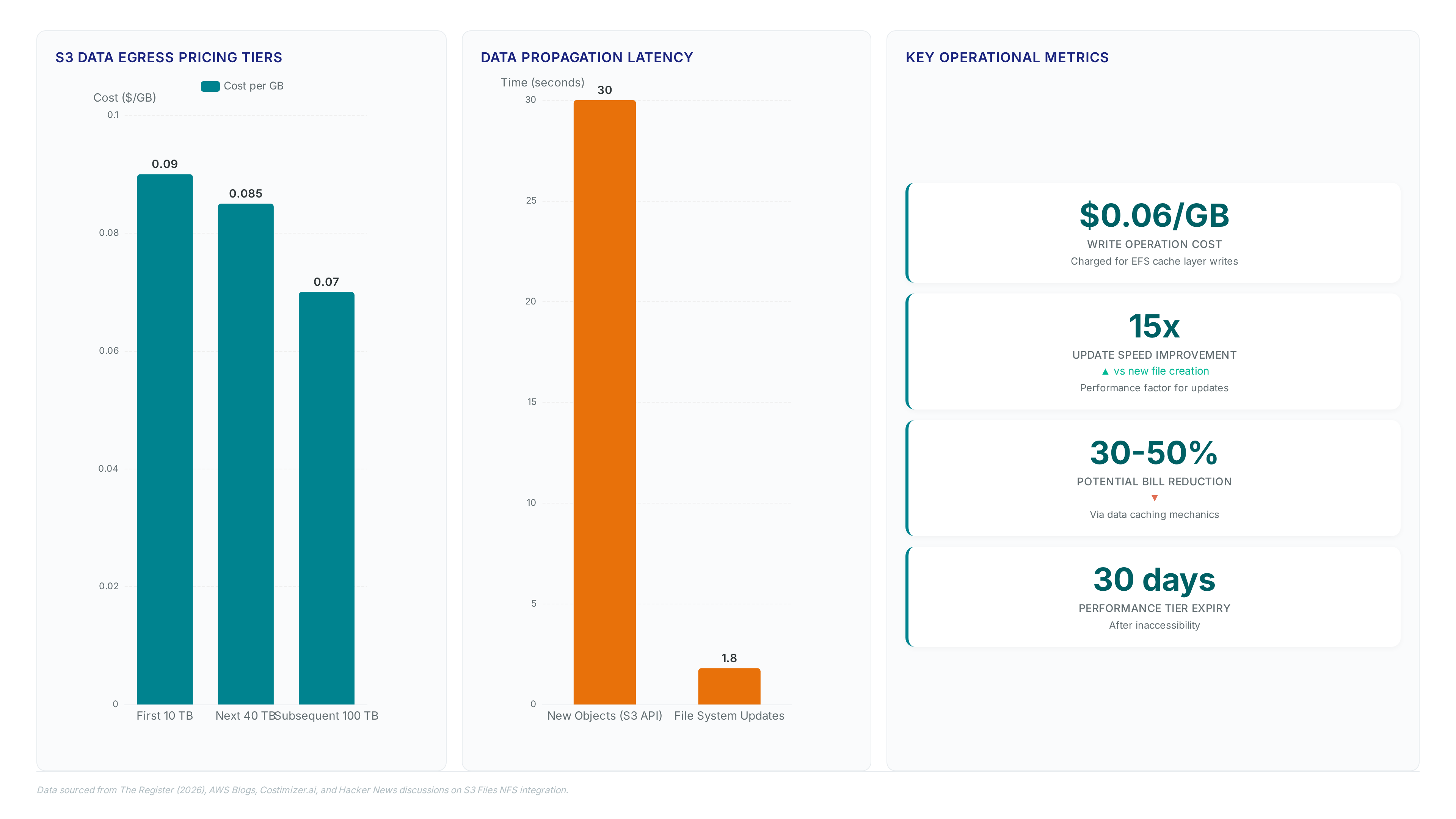
AWS S3 Files now serve NFS v4.2 directly, letting 54% of multi-cloud users consolidate storage without duplicating data or paying gateway fees.

EBS hits 20x faster I/O than S3. Learn why block storage beats object stores for high-velocity AI training pipelines.
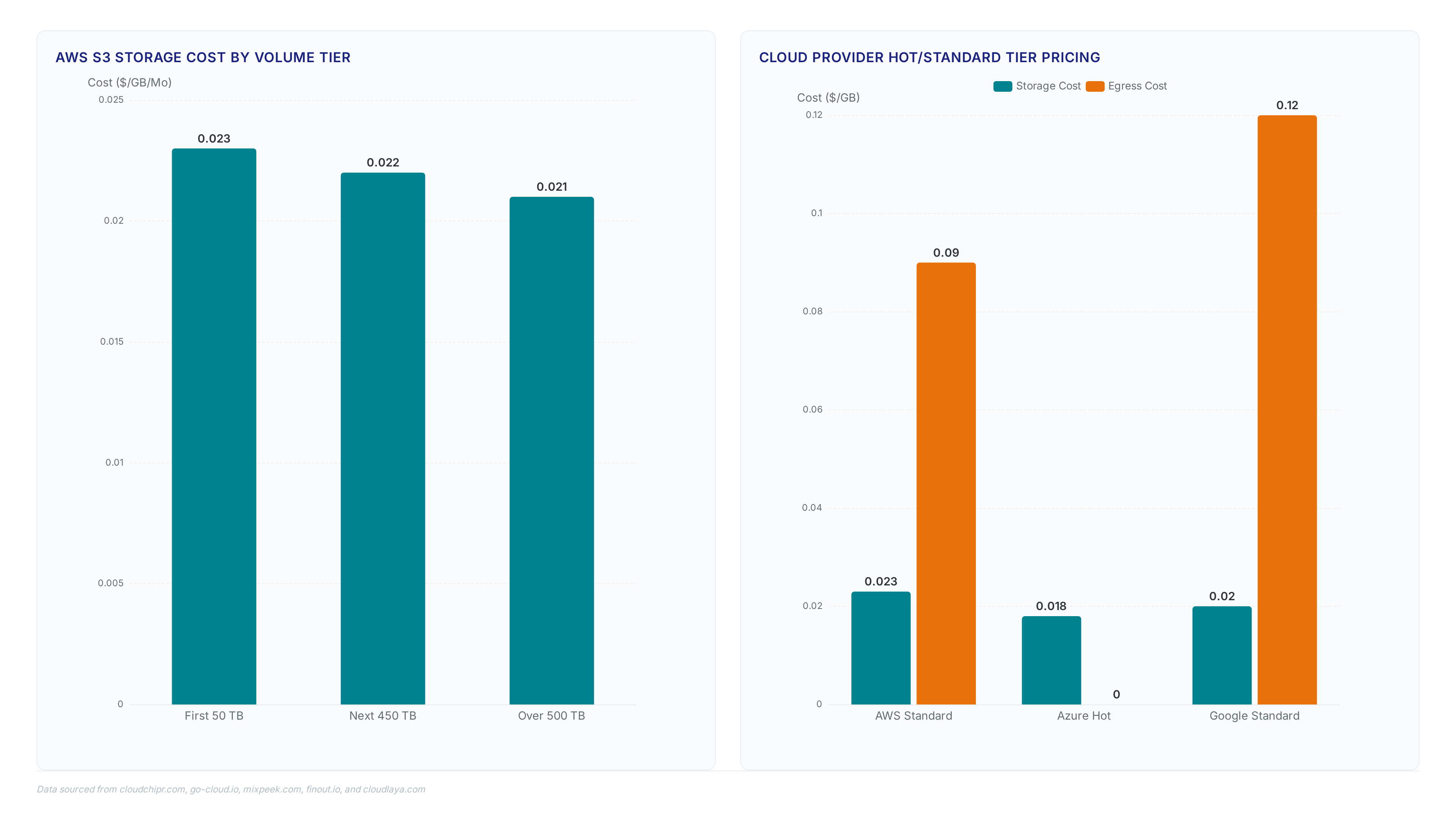
S3 now handles 200 million requests per second. I break down the engineering behind 500 trillion objects and why metadata optimization is critical.

See how Btrfs handles 150 uploads per second. Managed S3 fails at this scale, but selfhosted storage keeps latency predictable.

Stop wasting time on copy mechanics. Learn how S3 Files let compute access 40 PB of genomic data directly, skipping fragile transfers.

Stop guessing at S3 performance. My analysis of the new minute-level data shows exactly where single-digit ms variance impacts your bill.

NAND flash prices jumped 234% in 2026. I show how analytics reclaim 70% of your primary storage without costly vendor lock-in.

NAND prices jumped 234% in 2026. I show how Flash Stretch finds the 70% of cold data clogging your expensive primary arrays.
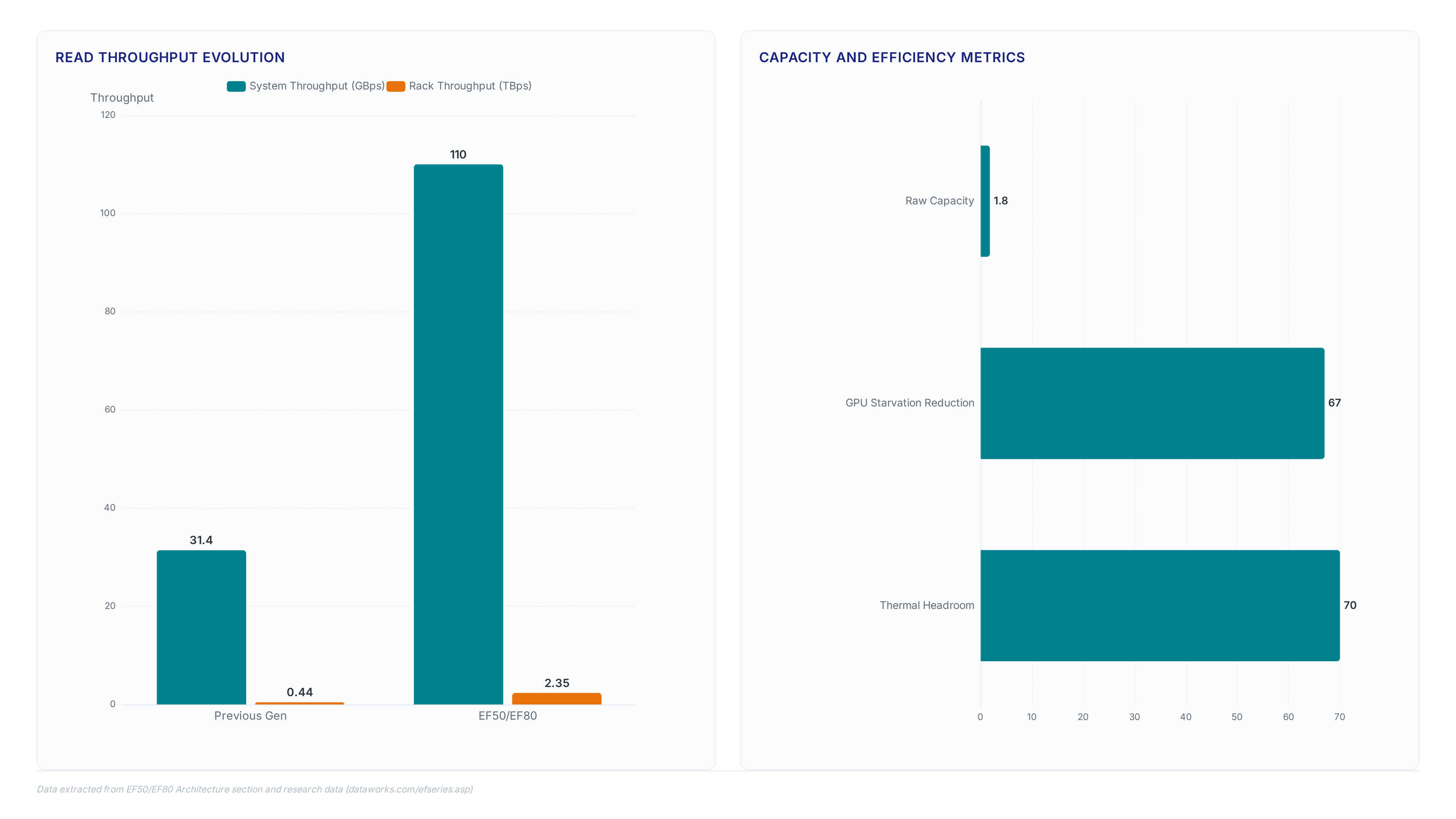
NetApp's new EF50 delivers 110 GBps read throughput to stop GPU starvation during large-scale AI model training cycles.
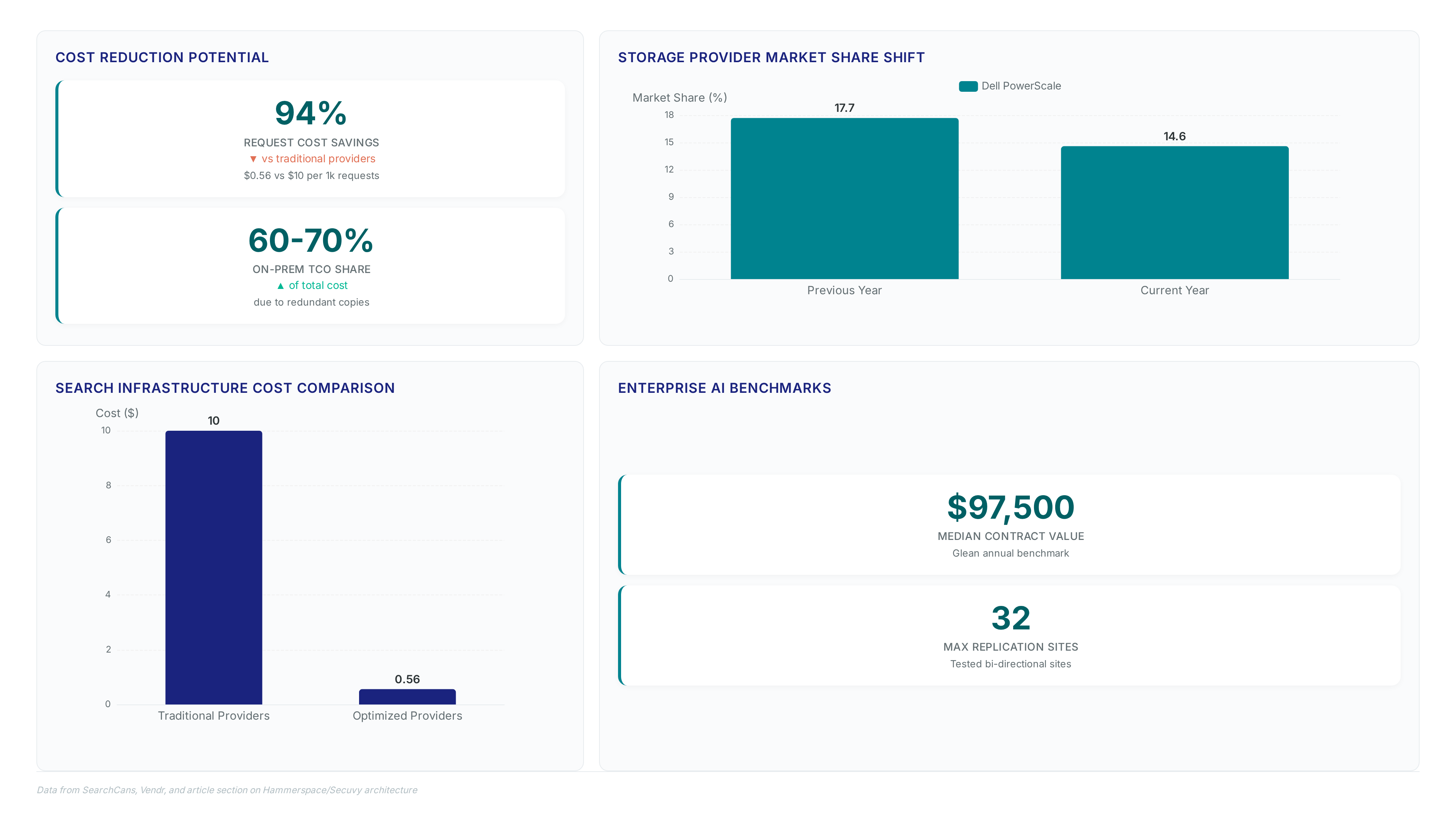
Hammerspace reports 2026 bookings are 14x higher as compute bottlenecks shift to data access. Learn why a trusted data plane is now mandatory.

After 18 years, S3 holds 500 trillion objects with eleven nines durability. See how simple PUT/GET primitives scaled globally without breaking apps.

AWS S3 now holds 500 trillion objects. See how strict API backward compatibility lets your 2006 code run unchanged in 2026.

AWS S3 now handles 200 million requests. I break down the architecture keeping 500 trillion objects durable after two decades.

See how Amazon S3 replaced tape libraries in 2011, eliminating manual seeks and proving cloud durability for enterprise Oracle backups.

AWS fixes 18 years of S3 collisions with account regional namespaces. Learn how the new {bucketname}{accountid}{region} format stops hijacks today.
Stop guessing at capacity. Learn how lifecycle policies cut storage bills by 23x using Glacier Deep Archive vs Standard tiers.

Scality's connector delivers 10x faster performance than standard S3 interfaces. Learn how hybrid tiering cuts infrastructure costs by 20% without speed loss.

Stop wasting millions moving data. Our new architecture cuts storage costs 40% by querying tables where they live without complex pipelines.

Fewer than 10 percent of enterprises scale AI due to fragmented storage. Learn how unifying vector and graph data fixes the bottleneck.

Hidden egress fees consumed 48% of total cloud spend last year. Learn how to audit dark data and stop the financial bleed before scaling AI.

Huawei's new allflash system hits 876,256 IOPS with 32 μs latency, proving converged storage can slash TCO by 64% for AI clusters.

Benchmarks reveal Web Streams run 120x slower than optimized Node.js pipelines. See why legacy locking breaks modern server-first architectures.

See how FastAPI type hints cut debugging time by 40% while enforcing strict data contracts without extra code.

Komprise Kappa automates tagging across silos so agents can query the 90% of unstructured data blocking your AI training today.

Server DRAM prices surged 95% last quarter. Learn why data readiness, not model size, is the real constraint killing enterprise AI production.

Unpredictable charges inflate cloud costs by 26%. Learn why 62% of IT leaders blow budgets and how to bypass these hidden tolls today.