Kappa metadata stops 90% of AI project failures
Unstructured data makes up 90% of enterprise holdings, a statistic that renders most generative AI initiatives dead on arrival. Komprise's new KAPPA service attacks the root cause: the missing metadata layer.
The math is unforgiving. Without a unified metadata repository, distributed file silos remain invisible to AI models, regardless of available compute. Komprise launched KAPPA (Komprise AI Preparation & Process Automation) to automate tagging across fragmented storage, from on-prem filers to cloud SaaS buckets. Athento projects unstructured data volumes will triple between 2023 and 2026. Traditional indexing cannot keep pace with this explosion.
This architecture leverages serverless architecture to run custom enrichment workflows without infrastructure overhead. It feeds tagged datasets directly into agentic AI environments, allowing autonomous agents to query previously hidden contexts. IT teams define logic to convert raw bytes into searchable assets within the Komprise Global Metadatabase.
The Role of KAPPA in Unifying Enterprise Data Silos
KAPPA as Komprise AI Preparation and Process Automation
Launched on Fri 20 Feb 2026, KAPPA is a serverless compute framework designed to automate metadata collection across fragmented silos. Nearly 90% of enterprise data sits as unstructured files without a central namespace, blocking proven AI training. This system executes custom Python functions directly on files, eliminating the need to provision underlying infrastructure. Traditional approaches demand proprietary agents or specific hardware appliances; KAPPA runs logic in place against filers, cloud stores, and SaaS services.
Agentic AI environments demand searchable metadata tags that current silos lack. Without a central repository, agents guess at data relevance. Organizations close this gap by specifying and invoking KAPPA functions. Users insert Python code into a data operation field, enabling the software to tag files without provisioning infrastructure. This contrasts with traditional models requiring proprietary agents or hardware appliances for similar data movement tasks. Market analysis indicates a majority of initiatives will be abandoned without AI-ready data.
Mission and Vision recommends deploying these functions specifically where regulatory tags or project contexts vary by file type.
Abandoning AI Projects Due to Fragmented Data Silos
Fragmented storage silos lacking an overall namespace force AI initiatives to fail before model training begins. Unstructured data sprawls across filers, cloud stores, and SaaS services, creating a disjointed environment where centralized metadata management fails. This architectural gap prevents agents from discovering datasets, directly triggering the projected abandonment rate for unsupported projects. Operators attempting to bridge this divide often confront distributed metadata challenges that scale poorly without serverless intervention.
Data volume clashes with accessibility. Organizations store massive quantities of information, yet the lack of a central repository renders these assets invisible to automated workflows. Custom Python code insertion into a data operation field solves the discovery problem. The cost of inaction manifests as wasted compute cycles on irrelevant data subsets.
| Failure Mode | Root Cause | Operational Impact |
|---|---|---|
| Model Hallucination | Missing context tags | Poor inference quality |
| Training Delays | Manual data hunting | Extended time-to-value |
| Project Cancellation | Unsearchable assets | Total budget loss |
Without immediate metadata enrichment, the gap between stored bytes and usable intelligence widens irreversibly. Mission and Vision recommends deploying serverless functions to establish a unified view before initiating agentic workflows.
Serverless Architecture Driving Custom Metadata Workflows
Serverless Compute Framework for Petabyte-Scale Metadata Tagging
Static agents crumble when facing petabytes of unstructured files scattered across diverse silos. The KAPPA architecture removes infrastructure provisioning headaches by spinning up parallel cloud capacity exactly when needed. Users place custom Python functions into a data operation field. This method bypasses the need for physical data movement while processing billions of items. Traditional models often demand proprietary hardware appliances to handle similar serverless compute.
Tags extracted by these transient functions flow directly into the Komprise Global Metadatabase Service, building a searchable index for distributed sources. Speed conflicts with cost control. Unlimited parallelism generates unexpected cloud charges if workflows lack precise dataset filters. Operators must code strict boundaries to prevent runaway expenses during massive scans. The Deep Analytics component consumes this enriched metadata to feed orchestrated AI workflows efficiently. Unlike fixed agents, this serverless approach decommissions cloud services immediately after processing finishes. Idle resources vanish before they consume budgets. Mission and Vision suggests validating Python logic against small subsets before launching petabyte-scale jobs to catch execution errors early.
Automated Lifecycle Management of Cloud AI Services in Workflows
Pre- and post-processing steps occur automatically as the system spins up cloud AI services right before execution starts. Decommissioning follows instantly upon task completion. This serverless framework brings cloud infrastructure under tight control. Operators define these lifecycles by inserting Python logic into a data operation field, which triggers parallel compute resources without manual intervention. Scaling complexities remain internal to the platform. Expensive GPU instances run only during active metadata enrichment tasks, then disappear.
A US-based workwear manufacturer demonstrated this efficiency by reducing Azure storage expenses from $1.00 per gigabyte to $0.25 per gigabyte through intelligent data management policies. Architectural shifts avoid the fixed overhead of always-on agents. A dependency on transient network connectivity emerges during the brief service window though. Decommissioning happens immediately after the data service completes, preventing budget leakage from forgotten instances. Competitor models frequently require specific hardware appliances for similar tasks, locking organizations into rigid setups. Mission and Vision recommend configuring these workflows to align with peak processing windows to maximize the benefit of automatic resource reclamation.
Agent-Free Serverless Functions vs Proprietary Hardware Appliances
Proprietary agents vanish from the equation as KAPPA executes custom Python functions directly on files without hardware appliances. Traditional competitors often mandate specific hardware or installed agents to perform similar metadata operations, creating rigid infrastructure dependencies. Operational burdens shift from maintaining physical boxes to managing logical code snippets.
The serverless compute model changes the economics. Operators define actions by inserting Python code into a data operation field. Legacy models require upfront capital expenditure on fixed-capacity devices, a stark contrast to this flexible approach. Market reception reflects this shift, as the platform holds a 4.8-star rating in the File Analysis Software category based on 33 reviews.
Serverless abstraction introduces a dependency on the vendor's control plane for execution scheduling. Teams lose direct visibility into the underlying compute nodes handling their specific functions. Operational overhead drops notably. Reliance on external scaling algorithms during peak loads remains a constraint. Mission and Vision recommends validating function timeout thresholds before deploying across billions of files.
Practical Applications of KAPPA in Agentic AI Environments
KAPPA Function Invocation for Agentic AI Tagging
Agentic AI systems invoke KAPPA functions by embedding custom Python logic into a data operation field to tag files with context like reservation numbers. An airline customer service agent applies a process-specific reservation ID across distributed silos, transforming raw storage into queryable assets for immediate retrieval. This serverless model contrasts sharply with legacy approaches requiring proprietary agents or dedicated hardware appliances that struggle to scale across petabytes.
The mechanism relies on Komprise automatically spinning up cloud AI services prior to processing and decommissioning them instantly upon completion. Operators avoid the financial drain of idle GPU instances while ensuring metadata enrichment occurs only during active workflow execution. However, this flexible scaling introduces a latency trade-off; cold starts for cloud resources may delay time-sensitive tagging operations compared to always-on agent architectures.
| Invocation Pattern | Infrastructure Overhead | Context Scope |
|---|---|---|
| Static Agent | High ( | Local filesystem only |
| Hardware Appliance | Critical (dedicated box) | Network-attached storage |
| KAPPA Serverless | None (on-demand) | Global hybrid namespace |
Failure to implement such flexible tagging directly contributes to the projected abandonment of unsupported AI initiatives lacking ready data. Applying ERP project tags or masking PII requires this granular, file-level intervention rather than coarse directory-based rules.
Integrating Electronic Lab Notebooks with File Metadata
Research directors read custom DICOM headers to tag medical images while importing project context from Electronic Lab Notebooks. Benjamin Henry outlines healthcare scenarios processing over 2 petabytes where siloed data blocks AI visibility without central metadata repositories. Operators insert Python logic into a data operation field. This workflow enables zero-move ingestion, enriching files for AI pipelines without physically relocating terabytes of sensitive research data from original locations.
| Integration Step | Action Performed | Output Destination |
|---|---|---|
| Context Import | Pulls project IDs from ELN APIs | Temporary Memory Buffer |
| Header Parsing | Reads modality and patient tags | Global Metadatabase |
| Correlation | Matches ELN ID to file path | Searchable Index Entry |
The serverless framework executes these custom functions across distributed datasets without requiring proprietary agents or specific hardware appliances for similar tasks. Traditional approaches often mandate dedicated infrastructure that cannot scale elastically when processing bursts occur during large study uploads. KAPPA uses a serverless compute model to handle the load.
Dependency on external ELN API availability introduces a single point of failure if network partitions occur during batch processing windows. Operators must implement retry logic within their Python snippets to handle transient connectivity losses without corrupting metadata associations. The cost of maintaining custom parsing scripts falls entirely on the customer IT team rather than the platform vendor. Mission and Vision recommend validating ELN schema changes before deploying new enrichment functions to production environments.
Preventing Accidental AI Ingestion via PII Masking
Komprise featured PII masking as a specific update in January 2025 to stop sensitive data from entering AI models. This capability addresses the risk where unstructured data volume growth triples the probability of accidental exposure without strict controls. Operators define Python logic within a data operation field to scan files for patterns like social security numbers before any indexing occurs. The system executes these scans across distributed silos, applying redaction rules that strip personally identifiable information while preserving file utility for downstream tasks.
| Risk Scenario | Traditional Mitigation | KAPPA Approach |
|---|---|---|
| Accidental Ingestion | Manual file review | Automated PII masking |
| Data Location | Physical movement required | Zero-move ingestion |
| Scale Limit | Single node processing | Parallel serverless execution |
Masking irreversibly alters source content if not configured with a separate archive target. Teams must balance immediate AI readiness against long-term audit requirements for raw data retention. Importing sensitive data labels alongside masking rules creates a dual-layer defense that tags files for human review while blocking automated pipelines. This approach prevents the scenario where increased data volume directly correlates to higher AI failure rates due to privacy violations. Mission and Vision recommends validating mask patterns against current regulatory standards before deploying functions at scale.
Strategic Advantages of KAPPA Over Traditional ETL Tools
Comparison: Serverless Compute Framework vs Proprietary Hardware Appliances
KAPPA eliminates proprietary agent dependencies by executing custom Python functions directly on files without provisioning hardware. Traditional ETL tools often mandate specific appliances or installed agents to perform metadata operations, creating rigid infrastructure locks that hinder scaling across petabytes. This architectural divergence shifts the operational burden from maintaining physical boxes to managing logical code snippets within a serverless compute charter.
| Dimension | Proprietary Appliance | KAPPA Serverless |
|---|---|---|
| Infrastructure Footprint | Dedicated hardware units | Zero local footprint |
| Scaling Mechanism | Manual capacity upgrades | Automatic parallel elasticity |
| Deployment Latency | Weeks for procurement | Seconds for invocation |
Operators avoid the capital expense of dedicated units by using on-demand cloud resources that spin up only during processing windows. The limitation remains that serverless execution depends entirely on network connectivity to the central orchestration engine, unlike local agents that function during outages. Komprise handles the complexities of scaling. This model enables rapid iteration on metadata logic without hardware refresh cycles. Mission and Vision recommends this approach for organizations seeking to avoid vendor lock-in while maintaining agility in AI data preparation workflows.
Real-World ROI: Carhartt and District Medical Group Cost Savings
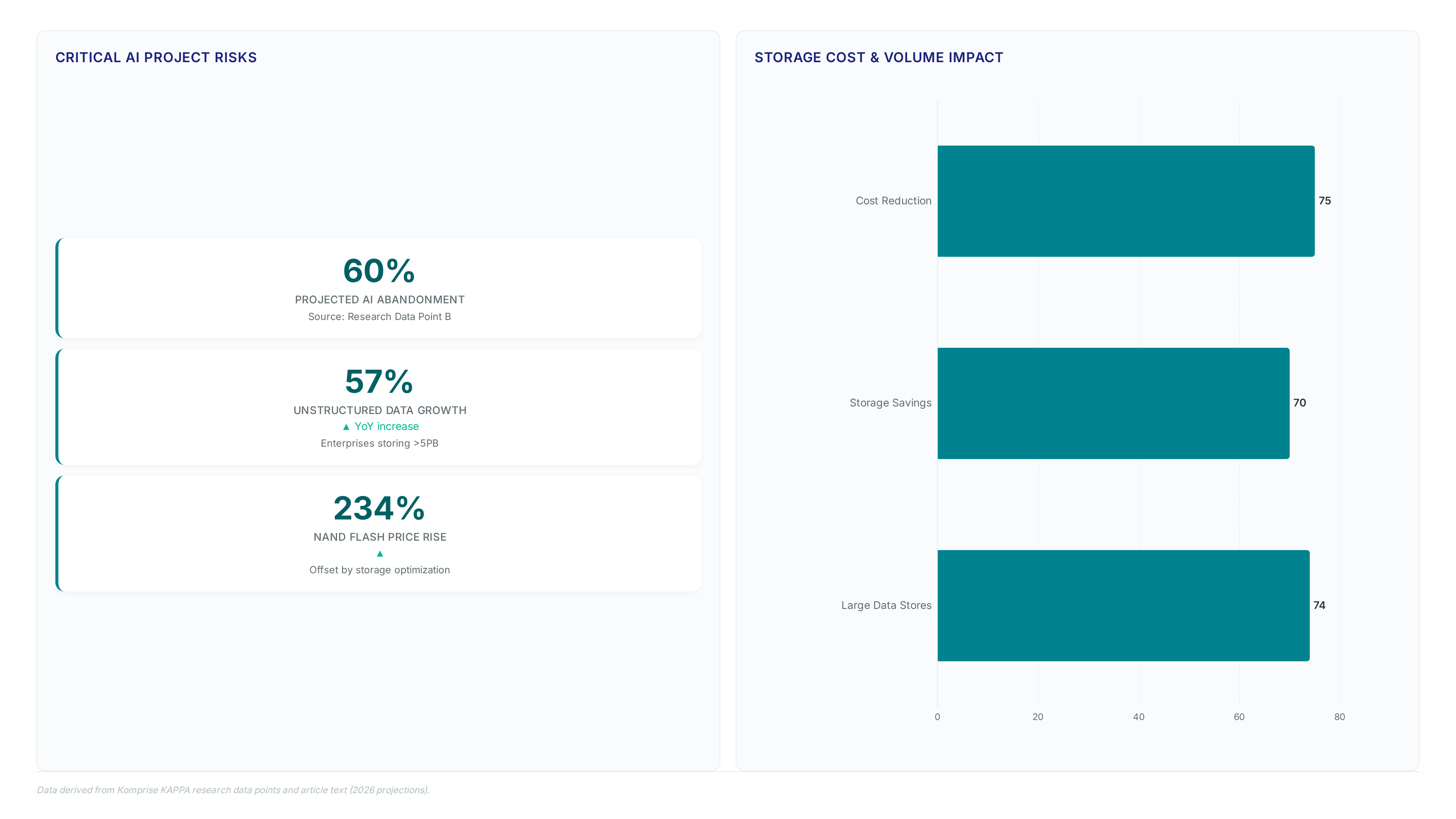
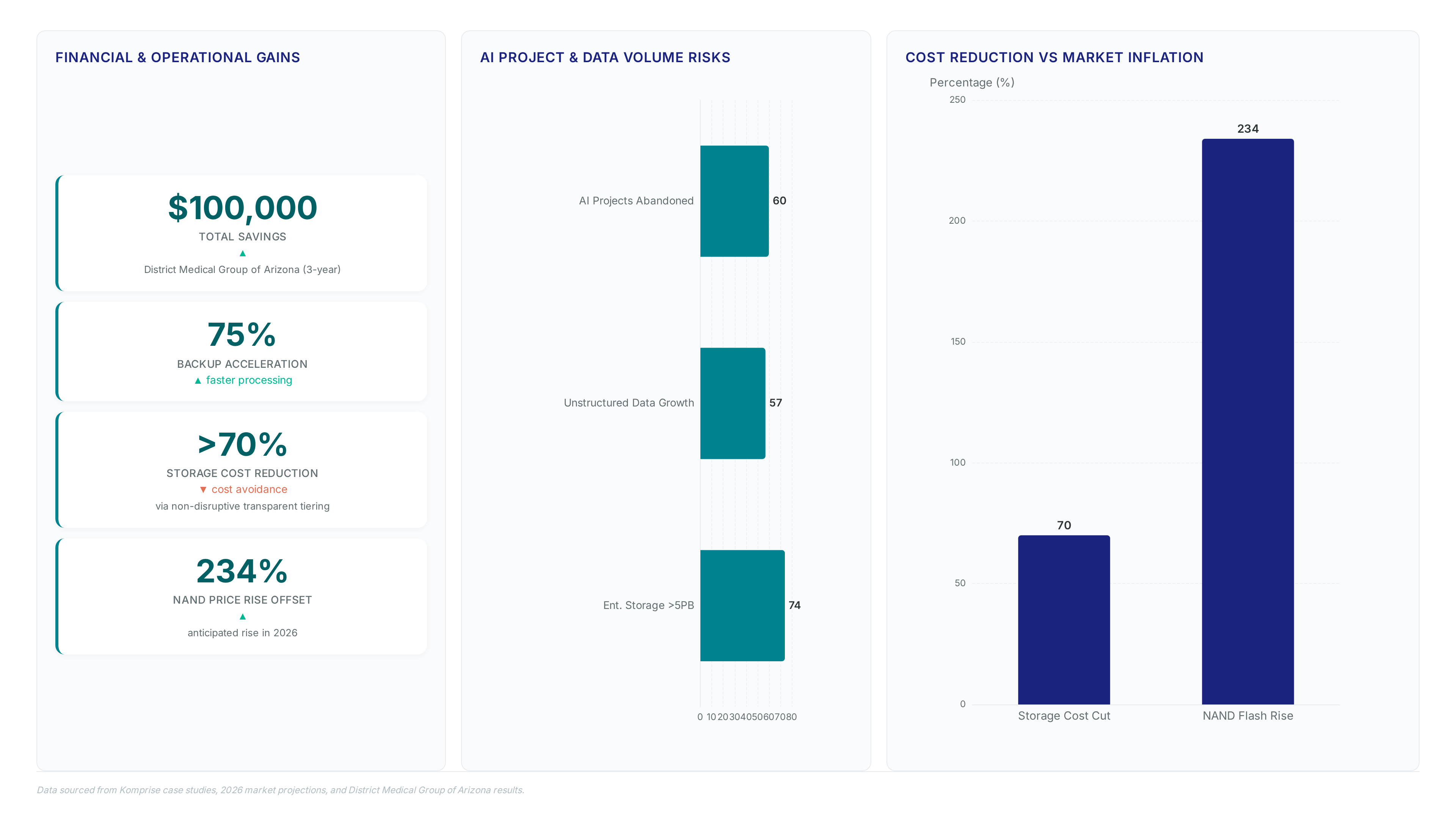
Financial justification for serverless metadata processing emerges from verified storage cost reductions in production environments. The District Medical Group of Arizona compounded these gains by securing $100,000 in total savings while accelerating backup processes by 75%. These figures indicate that cost avoidance precedes AI readiness as the primary driver for adoption. Operators should adopt serverless architectures because the marginal cost of running Python functions remains negligible against the baseline savings from eliminating cold data on primary storage. The limitation involves dependency on cloud provider pricing tiers; if egress fees rise, the net benefit shrinks regardless of processing efficiency. The operational overhead shifts from managing appliances to tuning code logic. Without this dual approach, organizations risk paying premium rates for storage that serverless functions merely index rather than optimize.
Market Ratings: Komprise File Analysis vs Varonis and NetApp
Komprise holds a 4.8-star rating in the File Analysis Software market based on 33 reviews, edging out Varonis at 4.6 stars from 310 reviews. This narrow gap in user satisfaction masks a deeper architectural divergence regarding infrastructure requirements. Traditional competitors often mandate proprietary agents or specific hardware appliances, whereas KAPPA uses a serverless compute document. The trade-off is volume of validation; Varonis benefits from a significantly larger review base that suggests broader enterprise penetration despite slightly lower scores. In the Hybrid Cloud Storage market, Komprise matches NetApp with identical 4.7-star ratings, though NetApp commands a much larger install base.
| Dimension | Komprise KAPPA | Varonis | NetApp |
|---|---|---|---|
| Market Rating | 4.8 stars | 4.6 stars | 4.7 stars |
| Review Count | 33 | 310 | 80 |
| Deployment Model | Serverless functions | Proprietary agents | Hardware appliances |
| Primary Focus | Metadata enrichment | Security governance | Storage infrastructure |
Operators prioritizing agile metadata enrichment without hardware locks find higher value in the serverless approach. Those requiring established security governance ecosystems may still lean toward incumbents with deeper market validation. Mission and Vision recommends evaluating review volume alongside star ratings to gauge long-term vendor stability.
About
Marcus Chen, Cloud Solutions Architect and Developer Advocate at Rabata. Io, brings deep expertise to the discussion of KAPPA and enterprise metadata management. His daily work designing S3-compatible object storage architectures for AI/ML startups directly intersects with the challenges Komprise aims to solve. As organizations deploy AI agents to hunt unstructured data across silos, the underlying storage layer must offer high-performance and true API compatibility to ensure smooth data retrieval. Chen's background in optimizing Kubernetes persistent storage and eliminating vendor lock-in provides a unique lens for evaluating how KAPPA automates metadata tagging without disrupting existing workflows. At Rabata. Io, where the mission is democratizing access to fast, cost-effective storage, Chen understands firsthand that successful AI preparation relies on reliable, transparent infrastructure. His insights bridge the gap between emerging automation tools like KAPPA and the practical realities of scaling data infrastructure for modern enterprise needs.
Conclusion
Unstructured data volume will triple by 2027, creating a bottleneck where metadata scarcity halts AI progress long before storage capacity runs out. While serverless architectures reduce immediate compute overhead, they introduce a hidden liability: fragmented indexing logic that becomes unmanageable as file counts reach the billions. Organizations relying solely on function-based enrichment without a unified governance layer will face escalating operational costs as they struggle to reconcile disparate metadata schemas across hybrid environments. The real risk is not storage expense, but the inability to contextualize data fast enough for emerging AI models.
Enterprises must adopt a dual-strategy approach by Q4 2027: deploy serverless tools for agile metadata tagging while simultaneously implementing a centralized catalog to prevent schema drift. Do not wait for your backup windows to expand or your AI pilots to stall due to missing context. Start by auditing your current metadata completeness across your top three storage silos this week to identify which datasets lack the semantic tags required for automated processing. This immediate baseline assessment reveals whether your existing architecture can support scaled AI workloads or if it requires a fundamental refactor before further investment. Prioritizing this audit now prevents costly re-engineering projects when data volumes inevitably surge next year.
Frequently Asked Questions
Missing unified metadata repositories cause organizations to abandon 60% of AI initiatives. This failure stems from poor data visibility rather than defects in the AI models themselves.
Nearly 90% of enterprise data exists as unstructured files lacking a central namespace. This massive volume creates a bottleneck that traditional indexing methods simply cannot resolve effectively.
Engineers must insert custom Python code into a specific data operation field. These scripts execute serverless functions to tag files without requiring any new hardware appliances.
The platform automatically manages scaling complexities and executes instructions across large datasets. Operators avoid infrastructure management while ensuring their Python scripts remain idempotent during processing retries.
Yes, agents invoke KAPPA functions to query and act upon previously invisible data contexts. This allows autonomous systems to access searchable metadata tags from distributed storage silos.
