
S3 annotations: Fixing the 1,000-item discovery gap
AWS S3 Annotations support 1,000 mutable items per object, yet most teams lack the query tools to find them without heavy SQL.
AWS S3 Annotations support 1,000 mutable items per object, yet most teams lack the query tools to find them without heavy SQL.
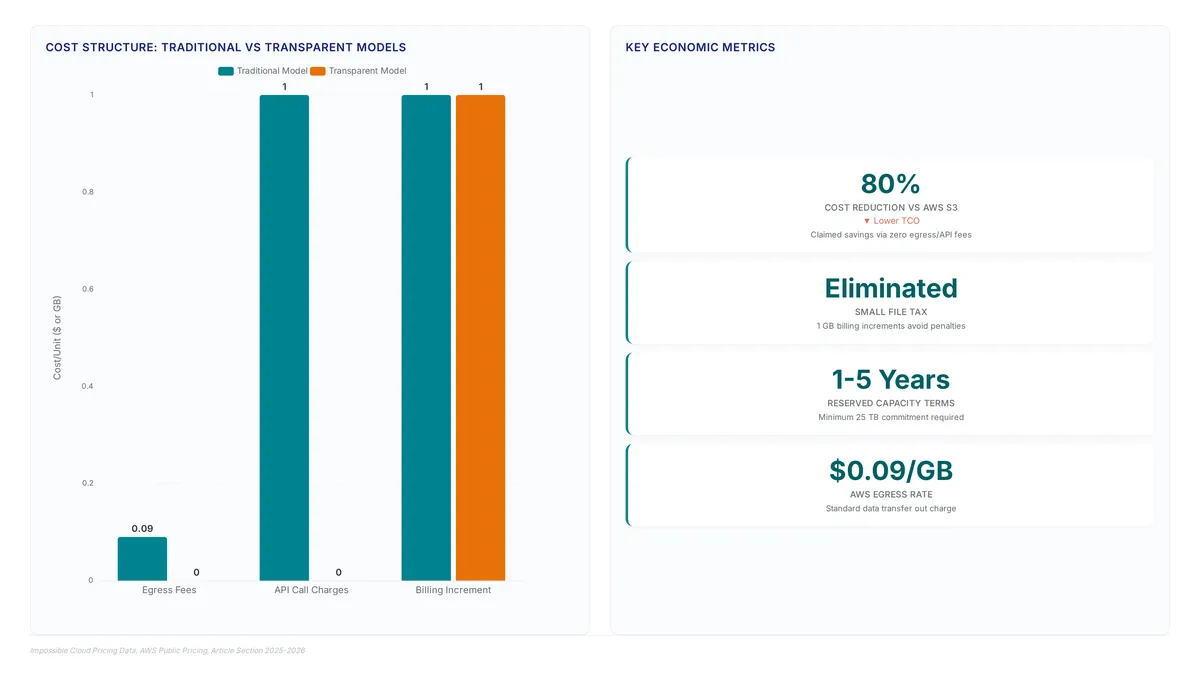
Claimed savings below AWS S3 costs drive urgent scrutiny into European object storage economics.

Amazon S3 Annotations support 1,000 entries per object, eliminating synchronization lag by integrating directly with Iceberg tables for instant SQL analysis.

S3 targets 99.999999999% durability, yet human error deletes data instantly. Discover why independent backups are essential for true protection.

Engineering GDPR-compliant data architectures typically demands 200, 400 hours of dedicated work, a massive drain on growth-stage SaaS resources.
The EU GDPR entered into force on 25 May 2018. That date set the floor, not the ceiling, for storage compliance.

Learn how S3 objects reach 5TB while navigating flat architecture. Discover strategies to manage storage classes and reduce retrieval latency effectively.

Flat storage architectures scale well, but default configs create debt. Learn how automated governance and IntelligentTiering reduce human error in...

Synology offers object storage at $7.99 per TB with free retrieval, eliminating hidden API fees for large-scale archives and data lakes.

Unify fragmented storage ecosystems by mapping distinct bucket terms into a single object standard, eliminating the technical debt of bespoke integrations.

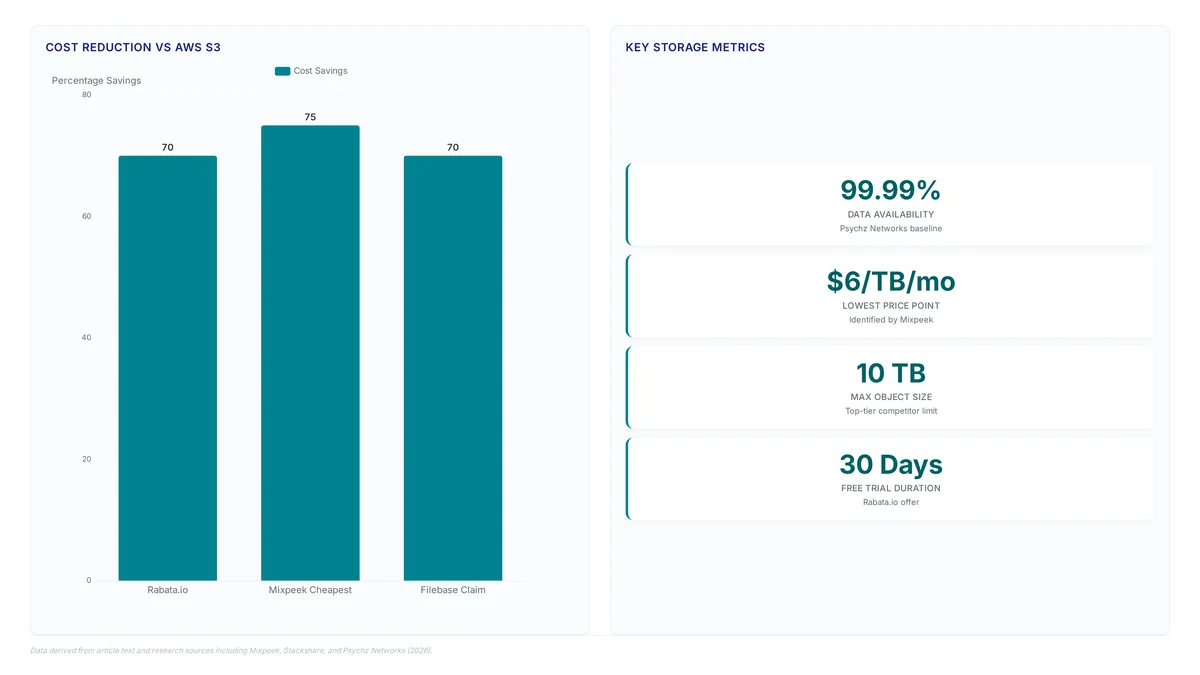
Discover how Rabata.io delivers 2.3x faster mixed workloads than AWS S3 while cutting storage costs by 70% for AI and media teams.

Object storage stores data as objects instead of files or blocks, creating a flat structure for unstructured data...

Cloudflare R2 pricing sets the mid-range benchmark for base storage costs per GB monthly. This isn't just a price cut; it's a structural shift.
Run Amazon S3 workloads outside AWS without rewriting code. Learn how erasure coding ensures durability while scaling unstructured data to petabytes.

Explore S3 alternatives like Ceph and MinIO for self-hosted storage. Learn why managed solutions offer better value than unpredictable hardware costs.

Cut storage costs by 70% with S3 compatible systems. Learn how decoupling the API reduces latency for AI workloads without code changes.

Cut data transfer expenses by 70% using S3 compatible storage. Learn how erasure coding ensures durability while avoiding proprietary vendor lock-in fees.
Sevalla cuts cloud spend by up to 88% while eliminating egress fees entirely. A direct response to financial bleeding from hidden transfer costs.

OVHcloud removes egress fees by 2026. Teams can now use a $200 credit to test S3-compatible tiers without hidden transit taxes on data.
OVHcloud delivers 11 nines data durability across three geographical zones without charging for API calls or traffic.
Verified benchmarks show 2.3x faster speeds than legacy systems. Discover how Rabata.io delivers high-performance, S3-compatible storage without vendor lock-in.
Object storage systems now support scaling to 100 petabytes within a single hybrid namespace.
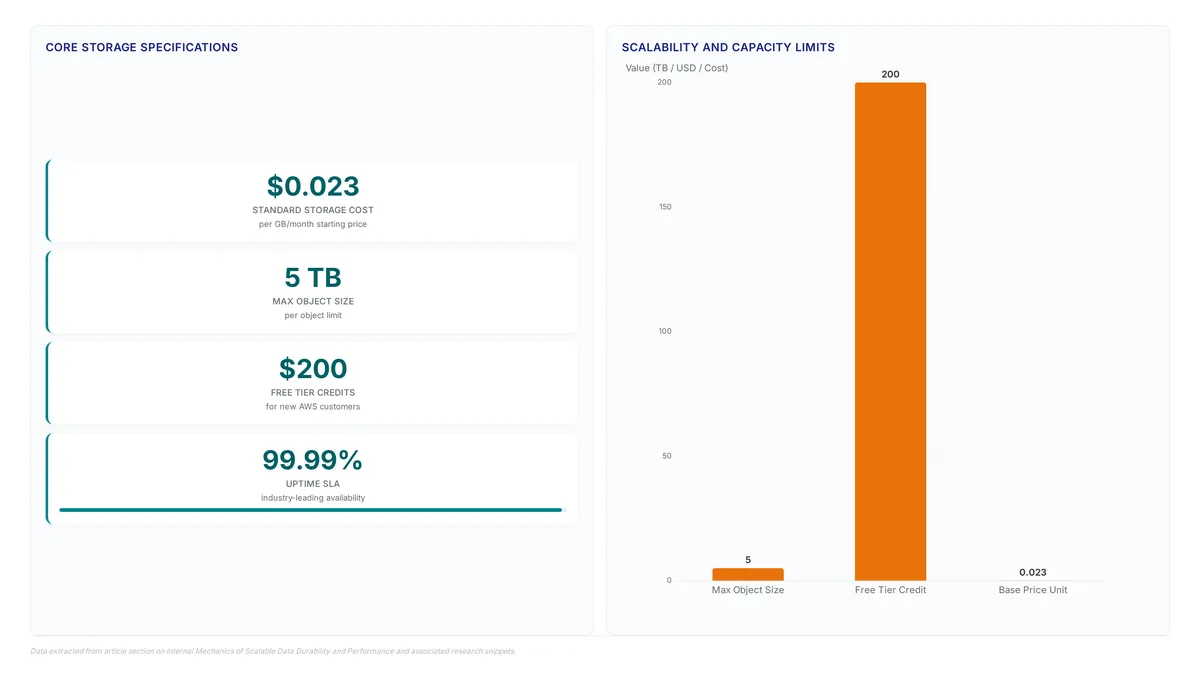
Learn how object storage supports individual files up to five terabytes, enabling limitless scale for modern AI data foundations without capacity planning.
Storing 1 TB costs $5.72 on Rabata versus $24.63 on hyperscalers. Discover how flat-rate pricing eliminates egress traps for AI workloads.

Stop looking at the per-gigabyte sticker price. In 2026, that number is a decoy. The real bill arrives later, buried in egress fees and API request...

Port 9000 serves as the default access point for the server and its embedded web-based object browser.
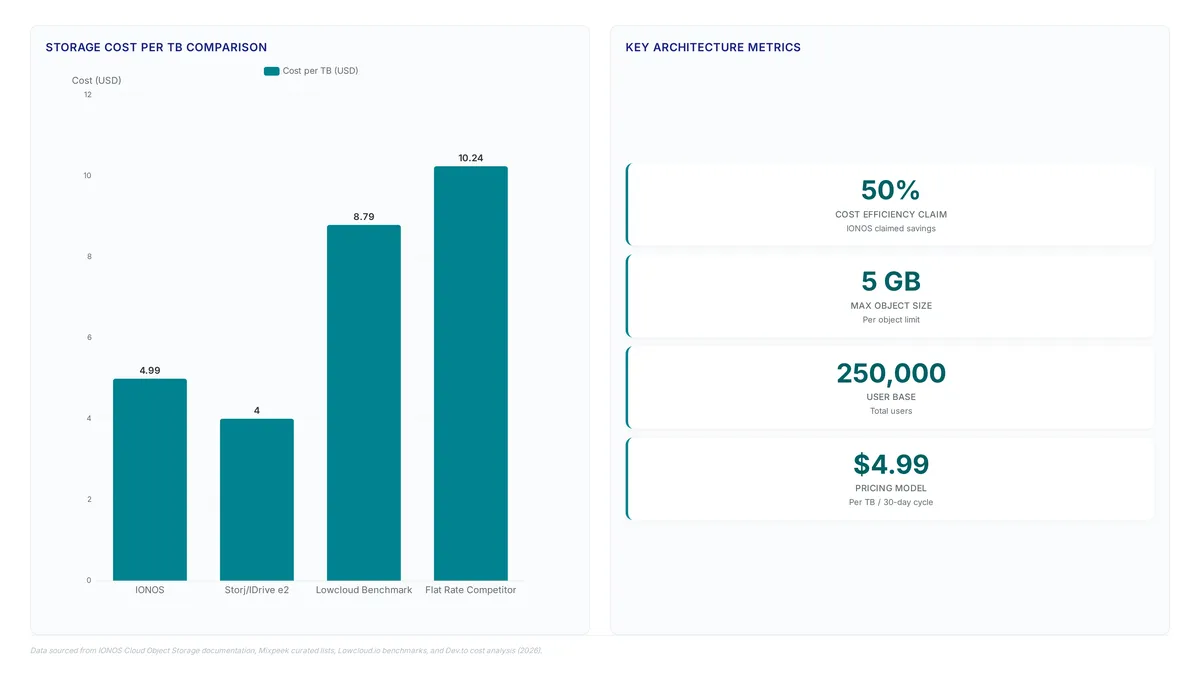
Storing 350 TB costs just $1,747 with IONOS CLOUD. Competitors charge up to $8,138 for the same capacity. That gap defines the modern storage market.

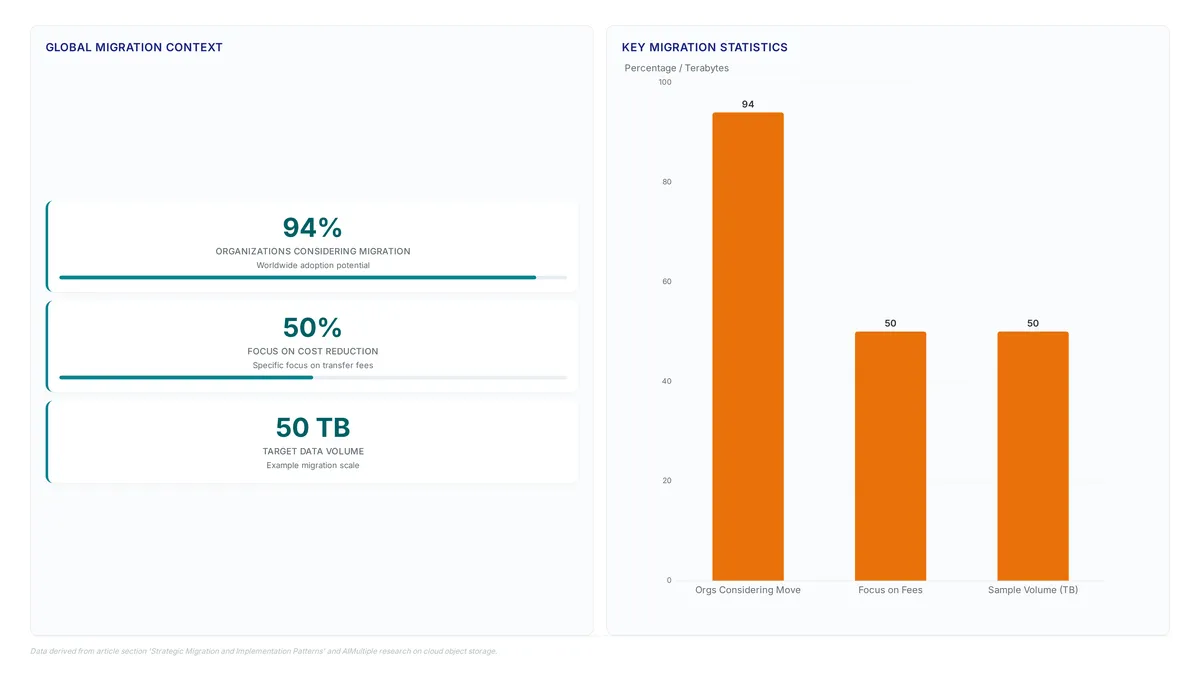
Switch to Frankfurt-based object storage to reduce expenditures by up to 90% and eliminate opaque egress charges from hyperscalers.

Discover how erasure coding delivers 11 nines of durability while slashing costs compared to legacy replication methods for enterprise data.

Market rates for object storage have collapsed. The going rate now sits at $0.006 per GB monthly, a figure that renders legacy enterprise expectations...

Object storage now manages an immense number of objects globally according to Wikipedia data.

Azure Blob Hot lists at $0.018 per GB, but retrieval fees often drive the real bill. Learn how architecture choices impact total cloud costs.

Global data creation has surged from two zettabytes to over one hundred and eighty-one zettabytes.
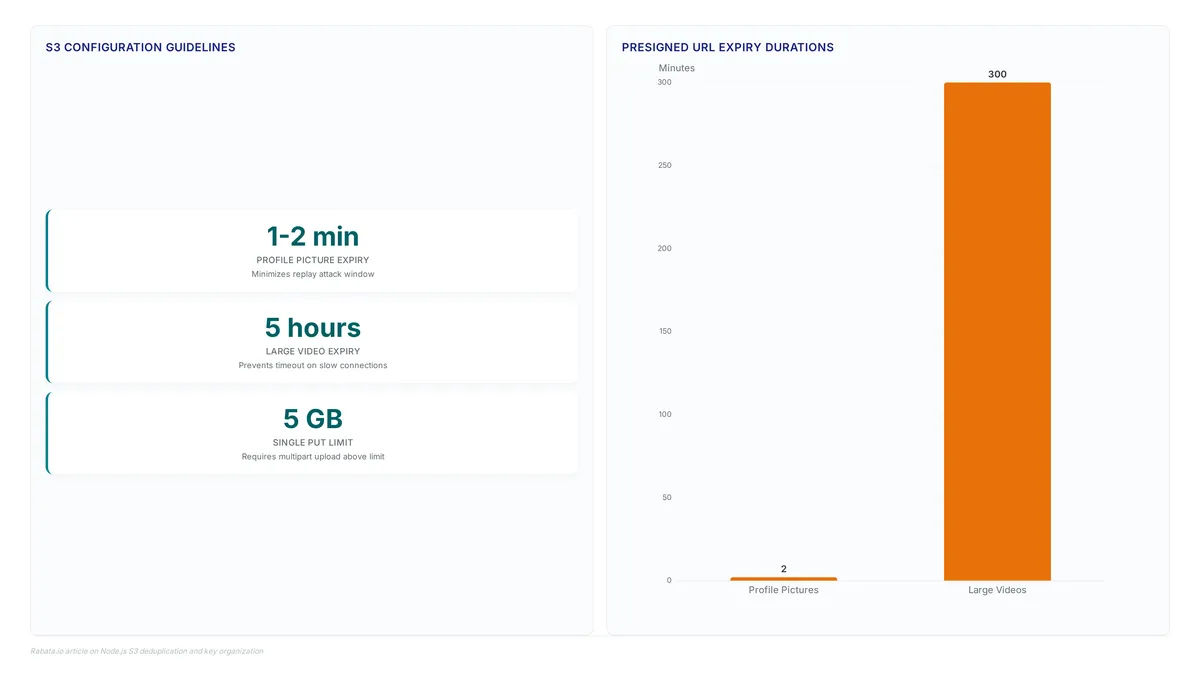
Learn how PutObject ensures atomic uploads where success means the full 63-character object is stored, preventing partial data corruption.
Cloudflare R2 hit 171.58 ms latency, yet AWS S3 remains six times quicker. See why consistent benchmark settings matter for real performance.
DigitalOcean Spaces enforces a strict 1,500 requests per second limit per IP. Learn how to architect around this ceiling for stable AI workloads.
Surface-level feature lists fail during migration. Discover why architectural mechanics matter more than theoretical flexibility for your data.
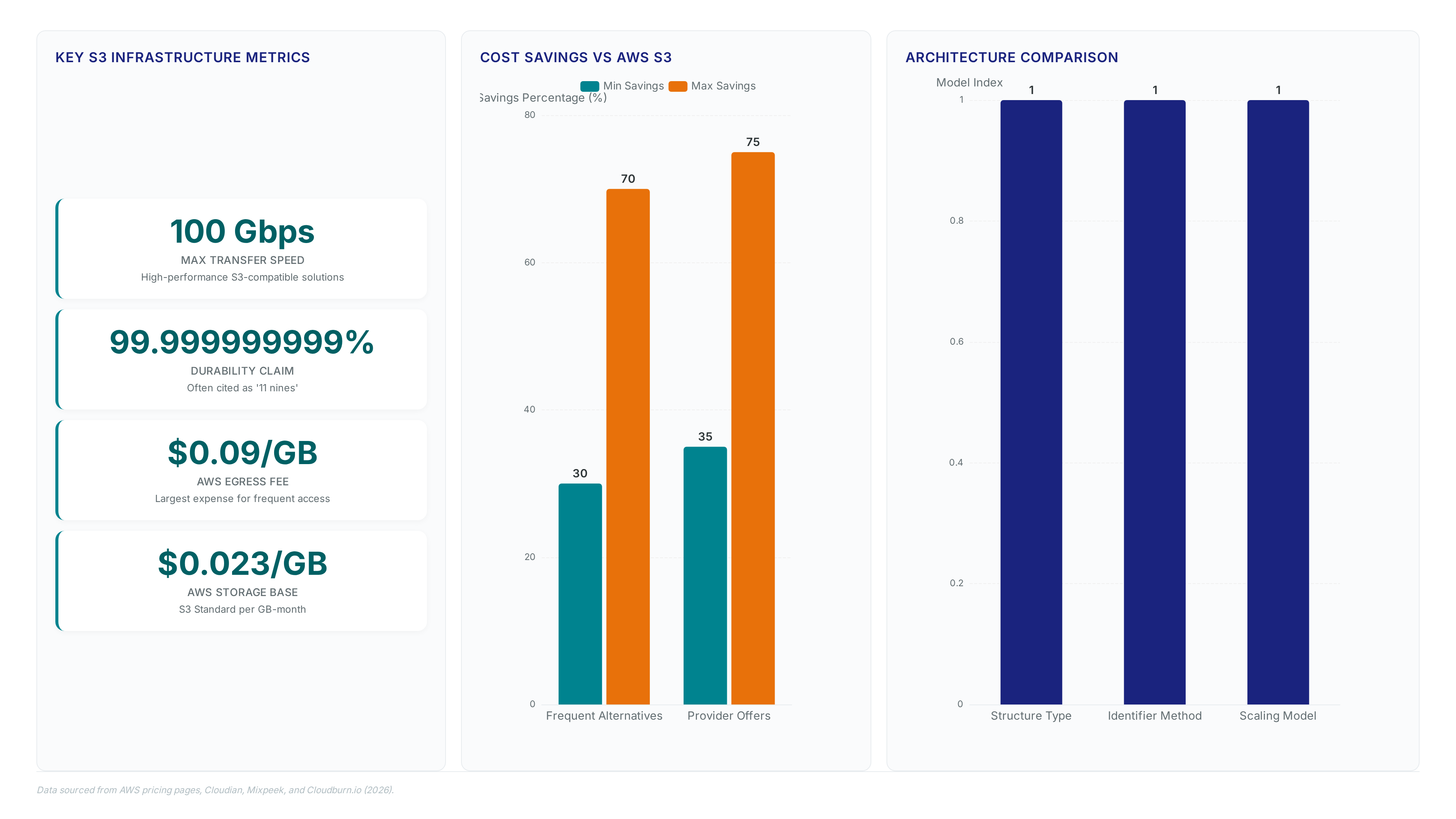
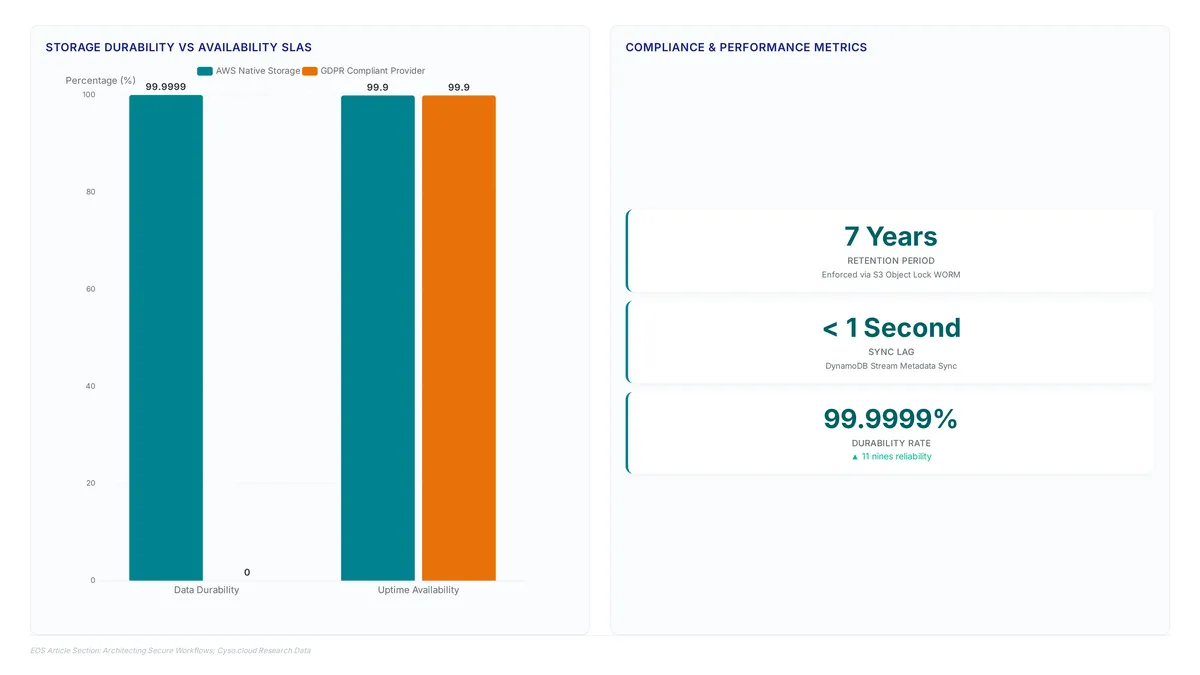
Amazon S3 delivers 99.999999999% durability for objects stored within its infrastructure. This isn't magic; it is the result of aggressive data...

Amazon S3 now allows 50 TB objects. See how flat metadata structures eliminate directory depth risks for massive data workloads.

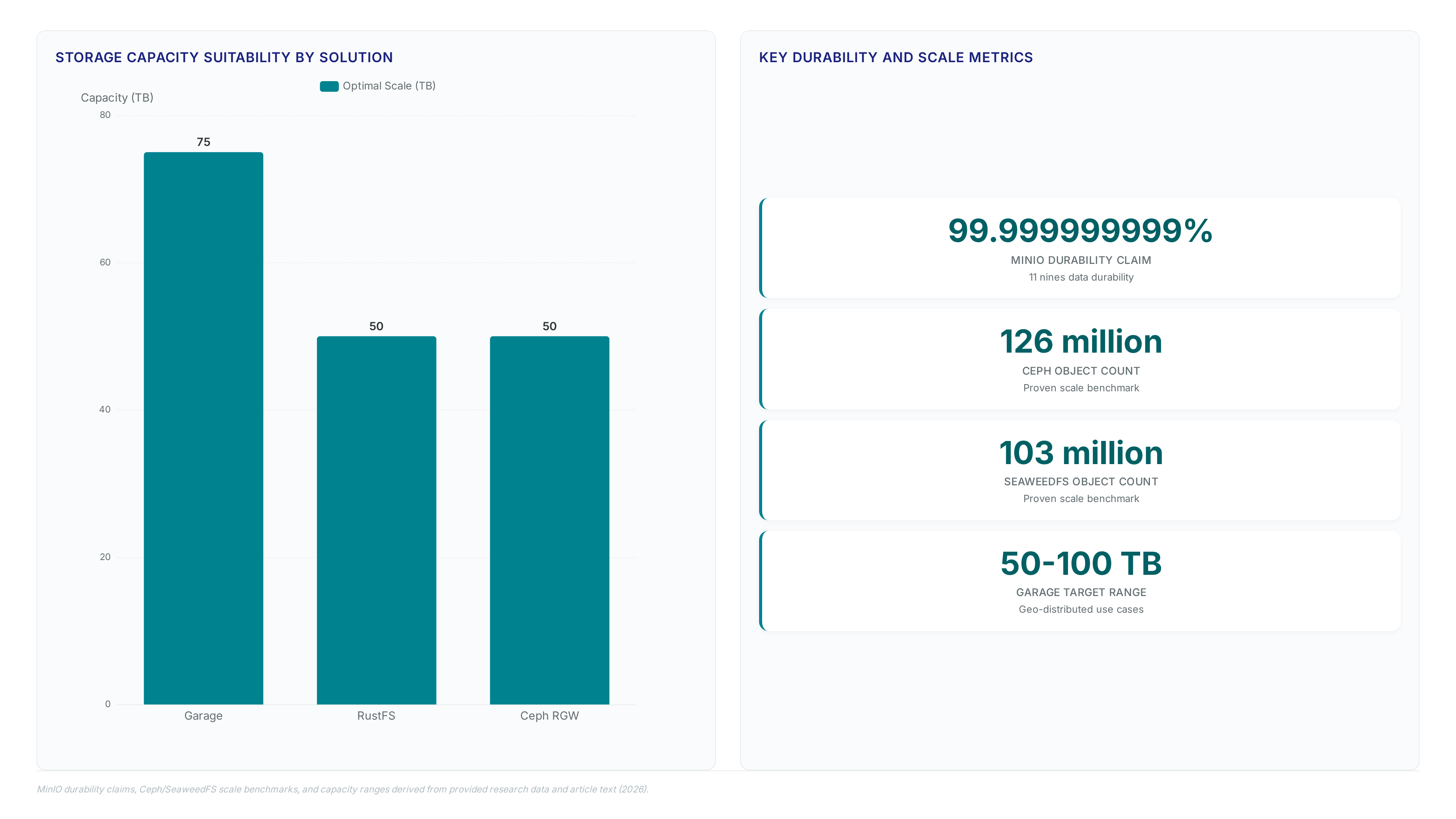
Discover how object storage delivers "11 nines" durability for massive AI training sets while scaling to billions of data points efficiently.

S3 versioning triggers a 15-minute propagation window where CDNs serve stale 404 errors. Learn how HeadObject checks amplify timing gaps.
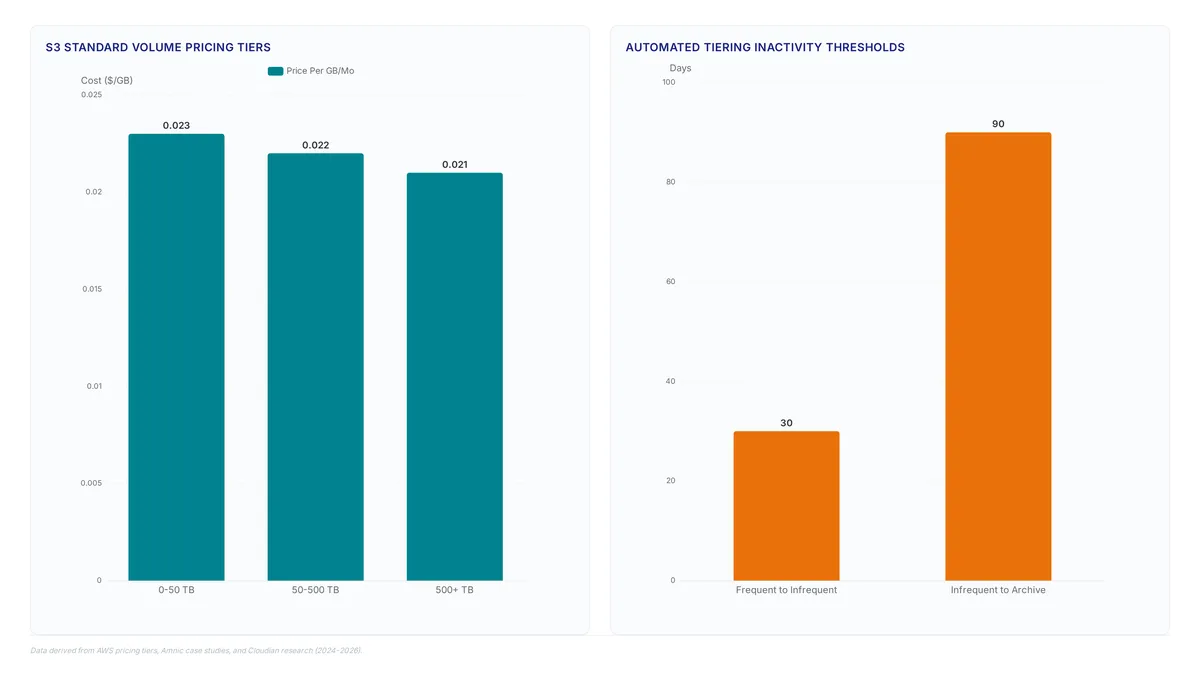
Stop manual data dumping. Use intelligent lifecycle mechanisms to shift unstructured data between performance tiers automatically for better cost control.

Achieve up to 14 nines of data durability with a unified architecture that eliminates silos and accelerates modern AI training cycles.
Hit the 50 Storage Lens groups limit? Learn to use object age filtering and tag rules to isolate transition candidates without hitting the cap.

S3 pricing varies 23× between tiers. Learn how minimum duration charges and retrieval fees impact total cost for trillions of objects.
Migrate legacy docs with full audit trails. Learn how serverless patterns manage millions of files while keeping records accessible for decades.

See how s3benchmark uses 60-second iterations to log raw speed and operations per second, replacing marketing claims with empirical data.
S3-compatible object storage lets applications use the same commands as AWS to slash migration timelines.
Resolve Kubernetes data bottlenecks with exabyte scalability. This analysis details how S3-compatible patterns eliminate latency in private cloud deployments.
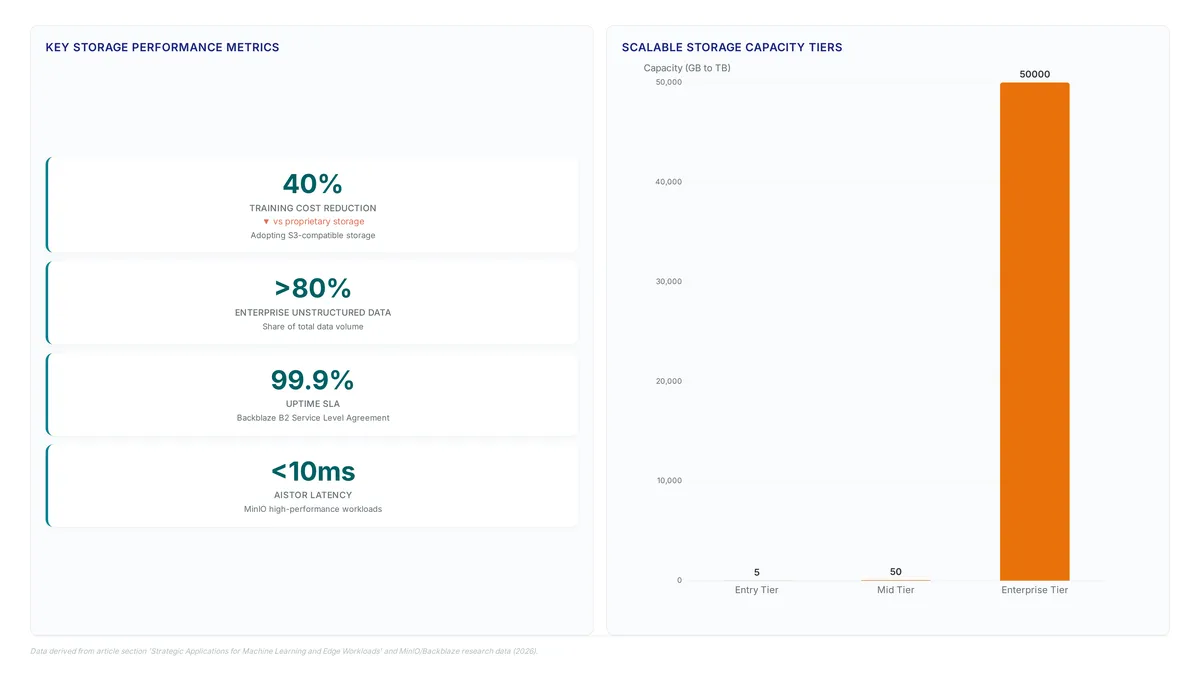
Over 80% of enterprise unstructured data now relies on S3-compatible interfaces. Learn how zero egress fees alter total cost of ownership.

Stop paying per-request fees. This S3-compatible storage offers zero API charges and 2.3x faster throughput for heavy AI training workloads.

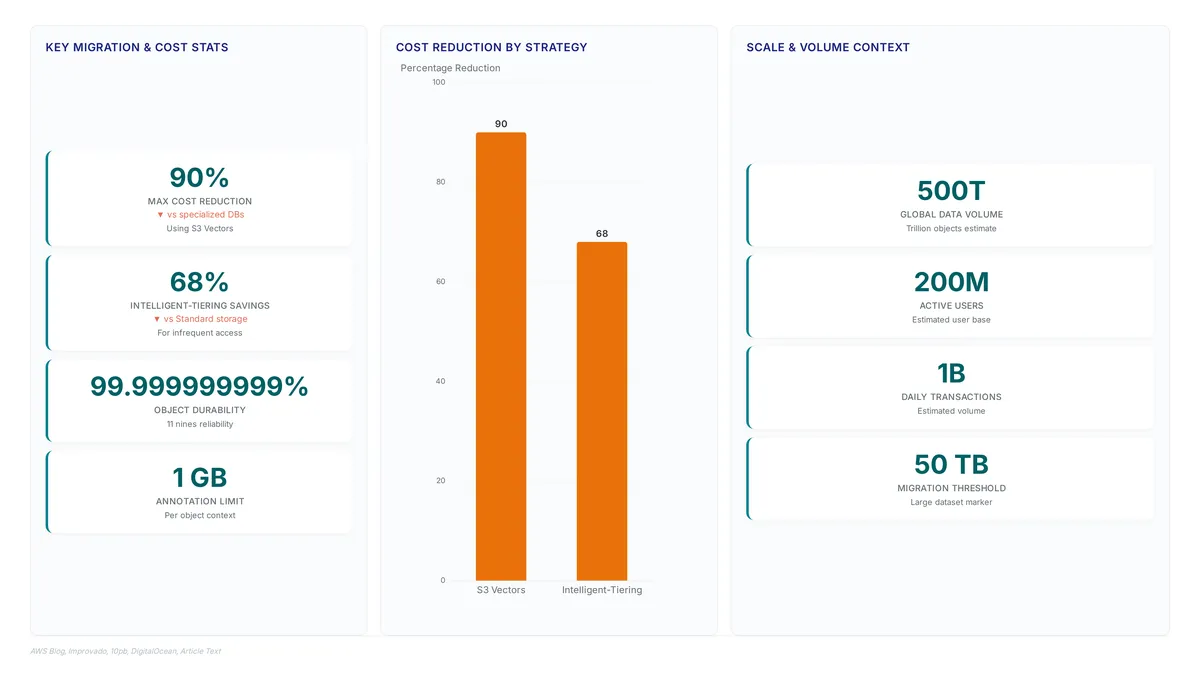
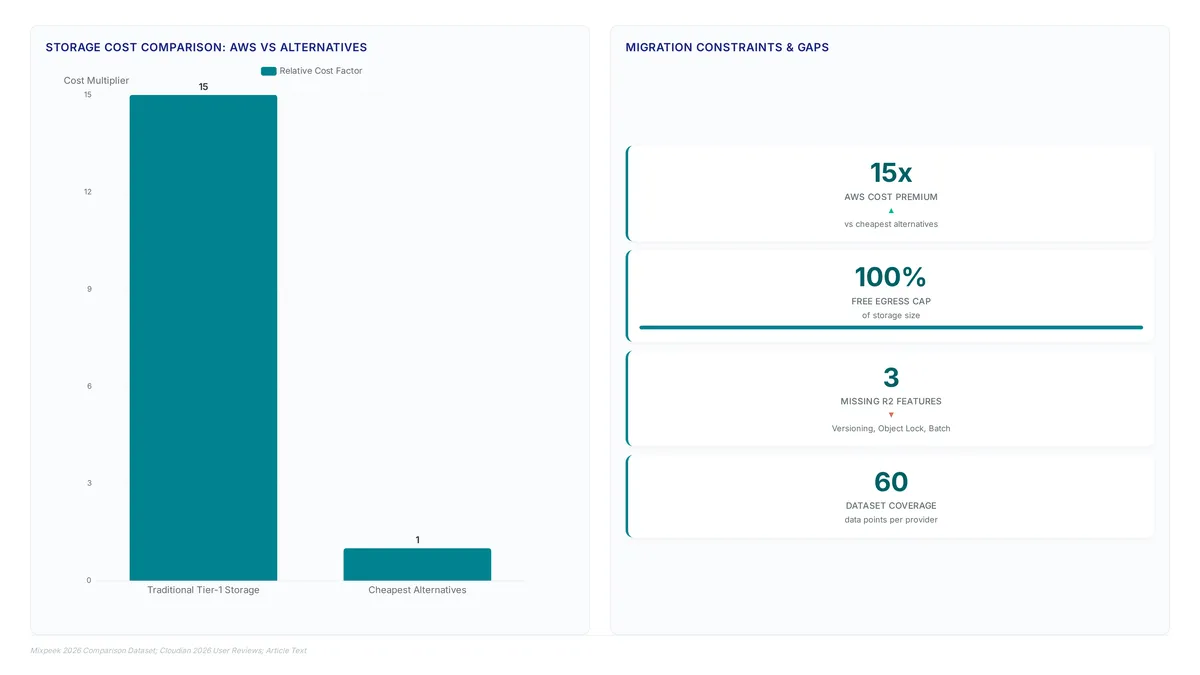
AWS S3 costs 15 times more than cheaper alternatives for identical AI workloads according to Mixpeek data.

Discover how modern S3 architecture supports individual files up to 50 TB, eliminating sharding complexity for large-scale AI and seismic datasets.
Attach up to 1000 annotations per object to create a mutable context layer, eliminating costly re-uploads during iterative AI model training.

Amazon S3 Files launched across 34 regions, ending the compromise between object and file storage for high-performance AI workloads.

Cut storage costs by 70% with S3 compatible clouds. Eliminate egress fees while maintaining full API compatibility for seamless hybrid deployments.

Cut storage costs by 15x and eliminate egress fees with AlwaysHot architecture designed for predictable enterprise budgets and zero latency.

Explore RustFS, a 94.3% Rust object storage system offering bitrot protection and S3 compatibility for AI workloads without GC pauses.
Stop trusting brochures. With 189 commits, OSBenchmark exposes raw API latency and multipart download timing that generic tools hide.
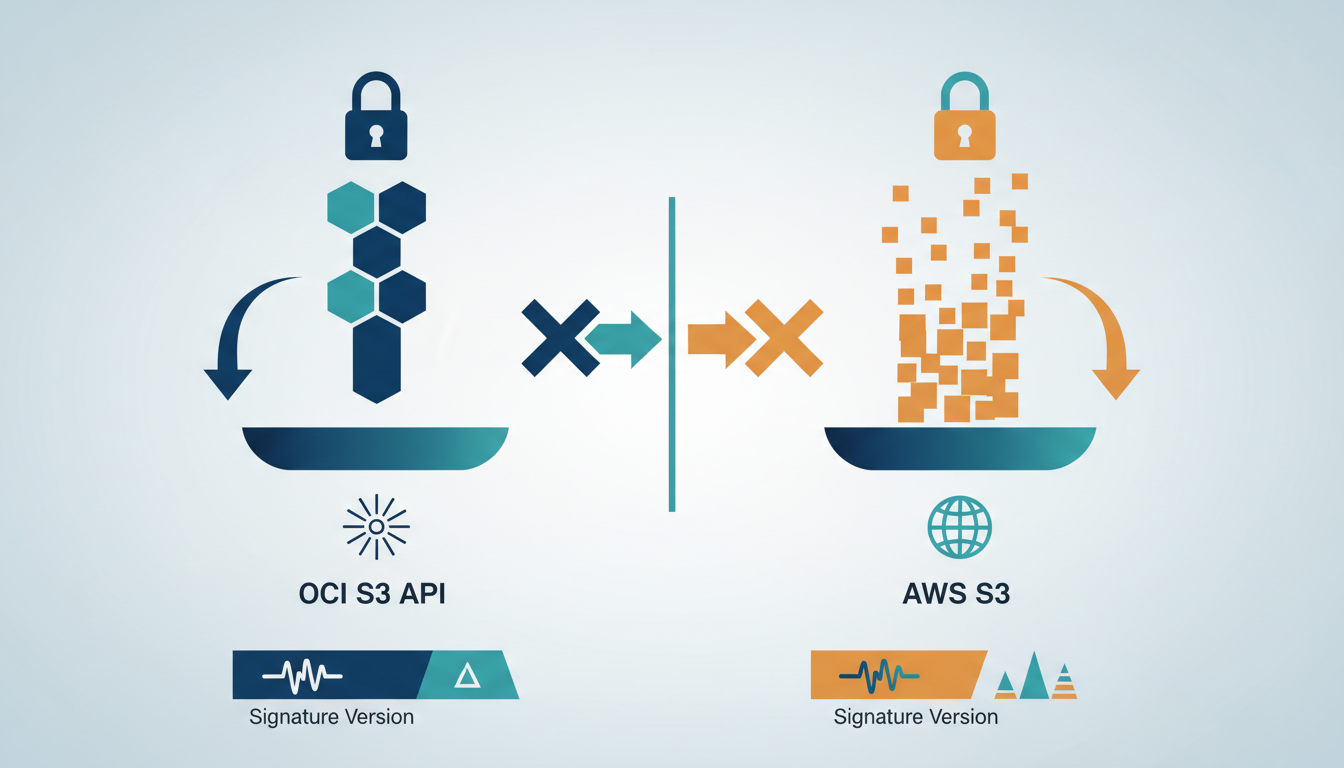
Oracle assigns exactly one immutable namespace per tenant, forcing a shift from global bucket names to compartment-based security policies.
Achieve 550+MB/s per node with kernel-mode caching. This POSIX filesystem mounts directly to S3, removing metadata bottlenecks for true scale.
Compare 5 providers offering S3-compatible storage. See how Sliplane's €5 flat rate eliminates egress fees for 250 GB of data.

Standard cloud storage lists at a modest monthly rate per TB, a baseline that dictates modern AI infrastructure economics.
Discover why S3-compatible storage now drives exabyte-scale ML pipelines, enabling 7 GB/s throughput to keep GPUs fully saturated.

See how decentralized object storage hits 400 ms optimistic finality, proving new architectures can outrun legacy file systems on speed.
Avoid Azure's 180-day retention trap. Learn how object storage repositories optimize backup tiers and cut total cost of ownership.

Veeam Backup for Microsoft 365 isolates metadata in a PersistentCache database on a PostgreSQL instance, separating it from bulk S3 data.

Cut AI training data costs by 90% using immutable object storage with eleven 9s durability to protect datasets from corruption.

Avoid egress penalties that destroy budgets during model retraining. Learn how erasure coding impacts latency for 2026 AI workloads.
Object storage solutions cut US data center power consumption by 22 percent according to recent efficiency data.

QNAP Labs tests show QuObjects hitting 2990 MB/s read speeds, dwarfing cloud equivalents. Stop paying for bandwidth you already own.

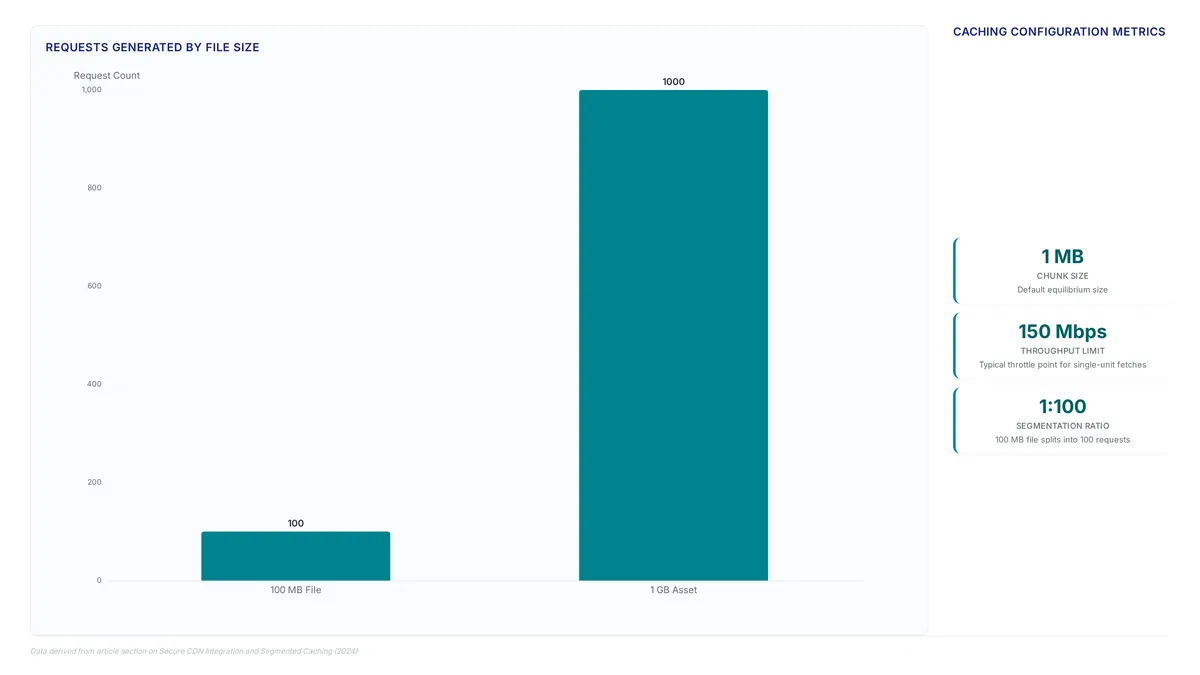
Blind transitions trigger a $0.03 fee per 1,000 requests. Learn why metadata overhead on small objects erodes savings before they materialize.

Achieve sub10ms latency in diskless Kafka by separating compute from storage, enabling 80% cost reductions versus traditional disk-based systems.
Persistent storage drains Kubernetes budgets faster than compute. Object storage offers a escape hatch: significantly cheaper per GB, infinitely...

COSI fixes object storage gaps that CSI cannot address in Kubernetes. The Container Object Storage Interface exists because CSI primitives like...
Content addressed storage kills S3 data drift by swapping mutable keys for immutable content identifiers.

No single verified statistic in the provided research corpus quantifies market dominance or failure rates for cloud object storage alternatives.
Map CDN77's 3 cluster locations and learn how zero transfer fees between storage and CDN cut costs for high-volume workflows.

Amazon S3 stores a vast number of objects as of 2025, a statistic that proves scale often masks the brutality of modern cloud pricing mechanics.

Stop AI projects from stalling due to data entanglement. Learn how flat namespaces solve logistics for massive volumes without legacy costs.
Handle files up to five terabytes without server strain. Rabata.io delivers S3-compatible object storage built for massive, unstructured data.
Twenty-one S3-compatible providers now compete in a fragmented 2026 market, proving Amazon S3 is no longer the sole option for cloud storage.
S3 object storage decouples files from servers, a sharp departure from EBS disks chained to specific EC2 instances.

Deploy RustFS with a practical Docker quick start. This guide details how memory-safe code eliminates runtime errors in high-throughput data lakes.

Tests show thread count drives read performance up, with 256KiB objects revealing wild speed variances across providers like Wasabi and R2.

Most S3 failures stem from missing bucket ARNs for ListBucket. Learn why you need two distinct resource formats to fix AccessDenied errors.
The csis3 repo is archived with 93.2% Go code. Learn why forcing POSIX on S3 backends risks data loss in production clusters.
The Rabata.io S3 provider performance benchmark was strictly executed over a two-day period on September 18-19, 2025.
Fastly Object Storage eliminates egress fees when connected as an origin to a CDN service, fundamentally changing cost structures for edge delivery.

Zero egress fee storage eliminates the monthly penalty that traditional providers charge for data retrieval.

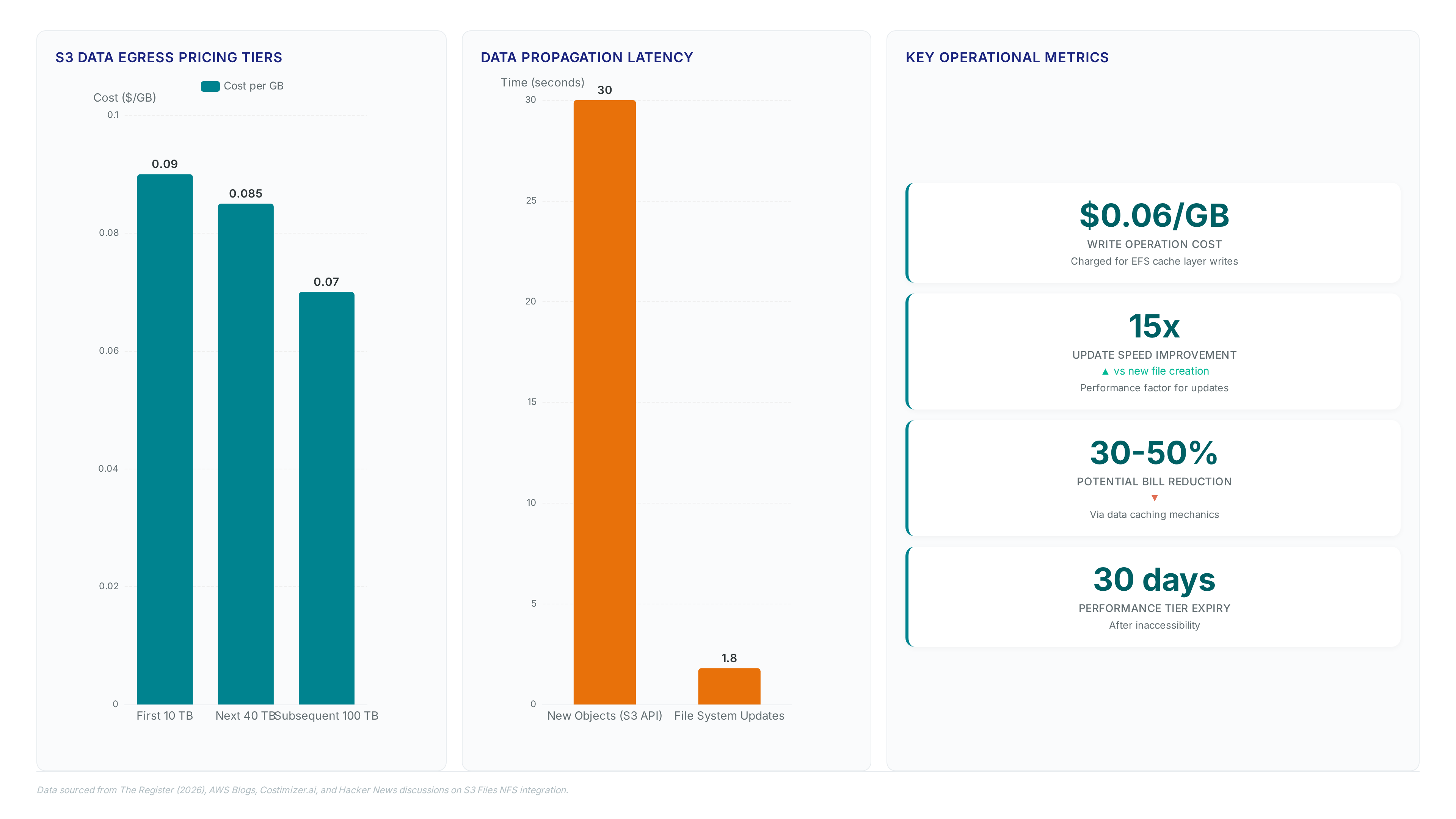
AWS S3 Files launches with NFS 4.2 support, replacing legacy FUSE tools. Note the 32 KB minimum charge per read operation before deploying.

Kubernetes has a blind spot: it lacks native object storage support. You cannot request a bucket the way you request a block volume without external...

Cloudflare R2 removes egress fees entirely, offering $0 outbound transfers. This shifts budget forecasting for media-heavy apps away from opaque network...

Deploy S3-compatible object storage to save 70% on cloud bills compared to AWS S3, featuring true API compatibility and no egress fees.

Cloudflare R2 lacks object locking, stalling migrations. Discover specific S3 API gaps breaking legacy workflows before you switch storage providers.
Discover where partial support for PutBucketVersioning reveals fragility in cloud storage. Learn why strict behavioral mechanics matter for true...

The AWS S3 API is the universal standard for object storage. Period. Countless providers, from Cloudflare R2 to Backblaze B2, now emulate its commands...

Fix Cloudflare R2 endpoint errors causing inaccessible files. Learn how Class A operations trigger unexpected charges despite zero egress claims.
Learn how S3 buckets deliver 99.999999999% durability while avoiding the hidden costs of misconfigured containers and small file overhead.

Cut object storage costs by 70% versus AWS S3. Eliminate hidden egress fees and migrate your data lake with true S3 API compatibility today.

With object limits now at 50 TB, traditional partitioning is obsolete. Learn how to adapt storage classes and bucket types for massive datasets.

Compare Cloudflare R2 and AWS S3 costs where Class A operations drive high-frequency write workflows. Learn why zero egress changes total ownership.

Test S3-compatible storage with mixed workloads to reveal true latency. Learn how version 4 tools expose bottlenecks single metrics miss entirely.
Combining multipart upload with transfer acceleration cuts large file transfer time by 61 percent.

Move petabytes safely by mapping S3 Object Lock to retention policies and using parallel transfers for zero downtime during your cloud migration.
Amazon S3 currently stores a vast number of objects, yet its dominance no longer guarantees optimal value.

Discover why S3 CSI fails on writes for Kubernetes workloads like Airflow and Jenkins. Learn about static provisioning limits, non-root UID/GID config, and on-p
Fastly Object Storage eliminates egress fees, solving the issue where users pay as much for transfer as storage to unlock data-heavy innovation.

StorageGRID 12.1 delivers a 400% throughput boost, turning object storage into an active engine for your generative AI factories.
Avoid hidden fees with transparent pricing starting at $10/TB. Discover S3-compatible storage built for massive scale and predictable budgets today.

Global sovereign cloud spending will hit billions in 2026 as regulators force data localization.

Explore how 500 trillion objects define modern scale and why Rabata.io offers a faster, S3-compatible alternative for enterprise data.

Discover how rigid 5 GB upload limits and $0.12/GB egress fees inflate cloud bills. Learn to audit storage services and cut costs by 70%.

Stop overpaying for block storage. I cut costs 70% using the CSI S3 driver to translate HTTP APIs into mountable volumes for AI workloads.

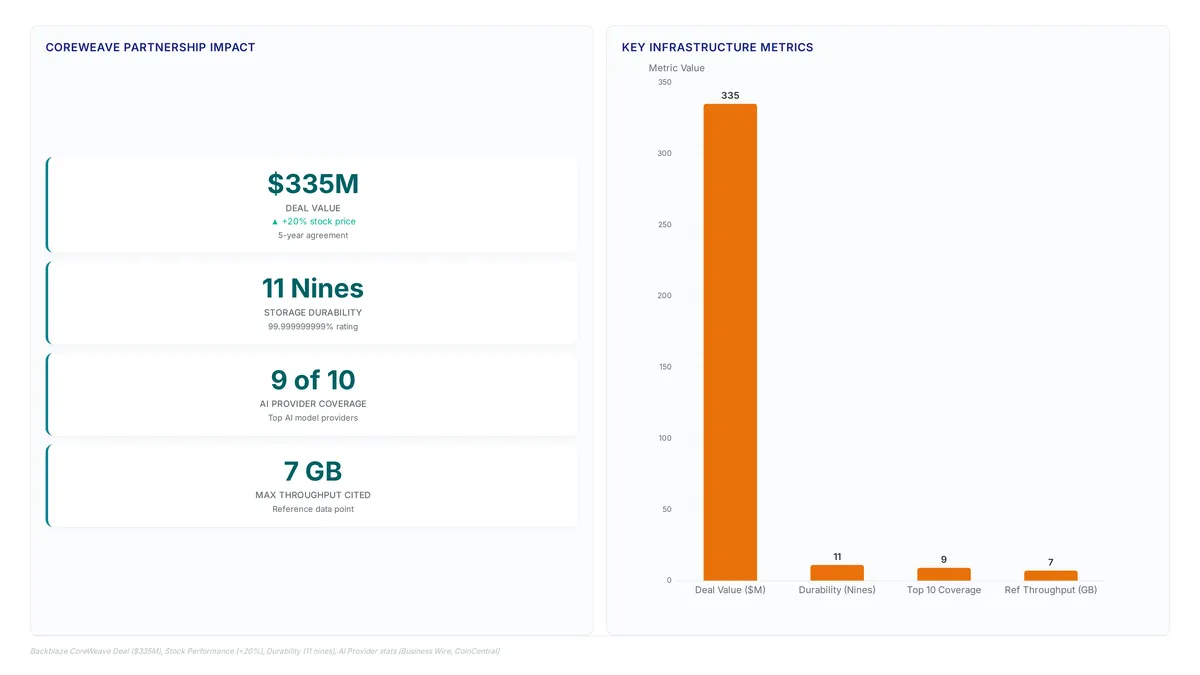
CoreWeave achieves 7 GB/s per GPU by pairing Backblaze HDD capacity with smart caching, proving flash isn't always needed for AI scale.

Cut cloud costs by 70% with S3-compatible storage. Simplify from eight complex tiers to just two while maintaining full API compatibility.
S3 compatibility is a spectrum, not a binary switch. Learn why API edge cases break tooling and how flat-rate models contrast with tiered pricing.

Managed S3-compatible providers can price storage as low as $0.006/GB per month, undercutting standard hyperscaler rates. Compare cost, licensing, and GDPR trad

Cut storage costs with zero egress fees across 335 data centers. S3-compatible object storage eliminates per-GB retrieval traps for modern apps.
MinIO archived its community edition in late 2025. That decision forced self-hosted teams to scramble for a new home for every Parquet file and...

Learn why flat buckets replace nested folders to cut management overhead and optimize data retrieval for unstructured cloud workloads.
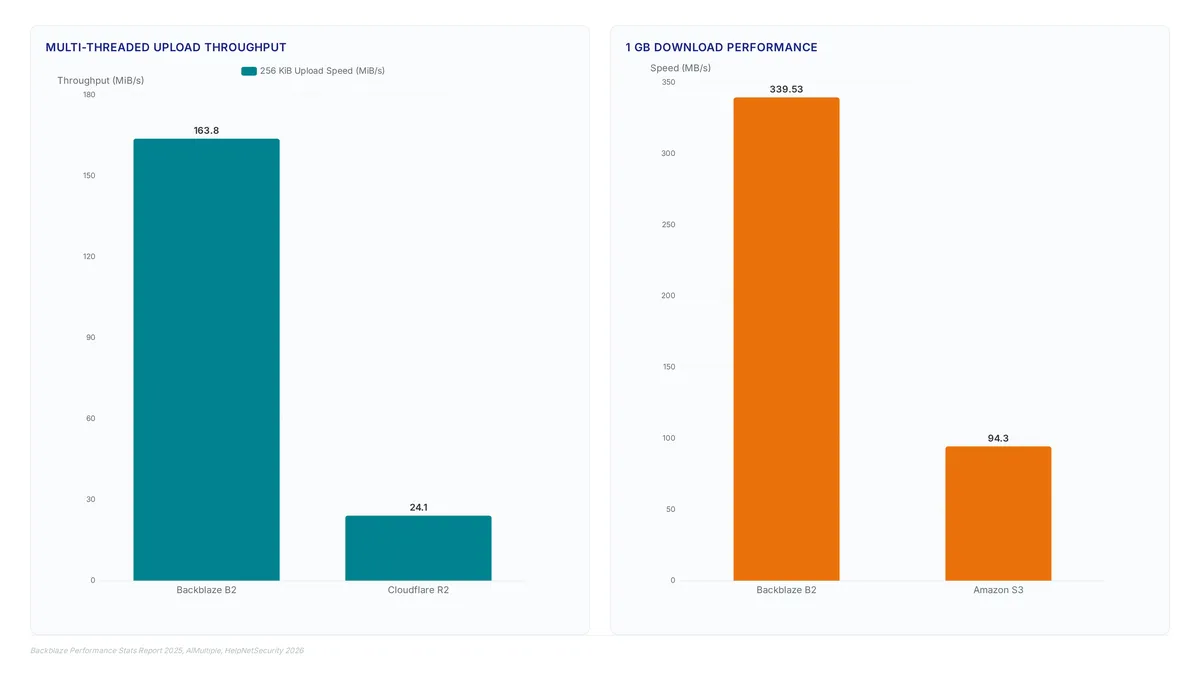
S3 latency traps stall pipelines. Benchmarks show 163.80 MiB/s vs 24.10 MiB/s gaps. Discover how Rabata delivers verified speed.

Learn how intelligent tiering delivers 7 GB/s per GPU, moving hot data to NVMe while keeping cold logs on cheaper HDDs to cut costs.

HDD tiers now underpin exabyte-scale AI where flash costs fail. See how a 5-year contract validates this economic model for massive datasets.
S3 metadata journal tables record object changes within an hour, closing the gap between event occurrence and administrator awareness for better governance.
MSP360 Backup 8.6 closes critical immutability gaps by extending Object Lock to SQL Server and Legacy Backup formats.

Filebase's $15/TB S3-compatible object storage with free egress: when free egress actually cuts your bill, the 100 RPS limit, and a pre-migration checklist.
Reddit avoids directories because S3 handles 1M+ data lakes. Learn why flat namespaces beat rigid file systems for massive scale.

Google's new Rapid Bucket cuts GPU blocked time by 50% with 15 TB/s bandwidth, solving the latency crisis in modern AI training workflows.
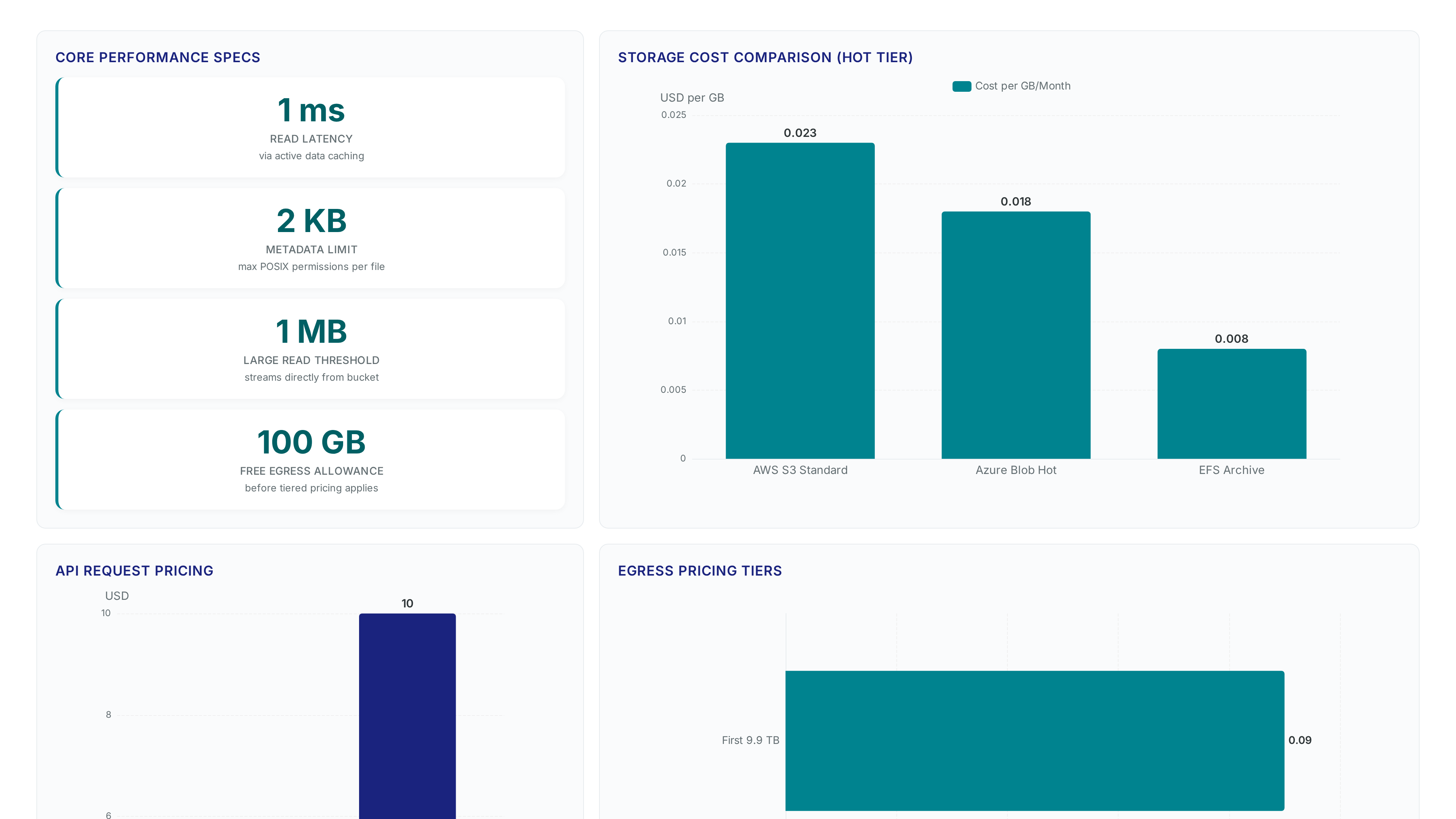
Stop paying $0.30 per GB for EFS. S3 Files brings POSIX semantics to buckets, ending the need for fragile data sync pipelines.

PostgreSQL's durability math forces a 23x cost variance. Learn why WAL flushes demand local NVMe, not object storage, to prevent stalling.

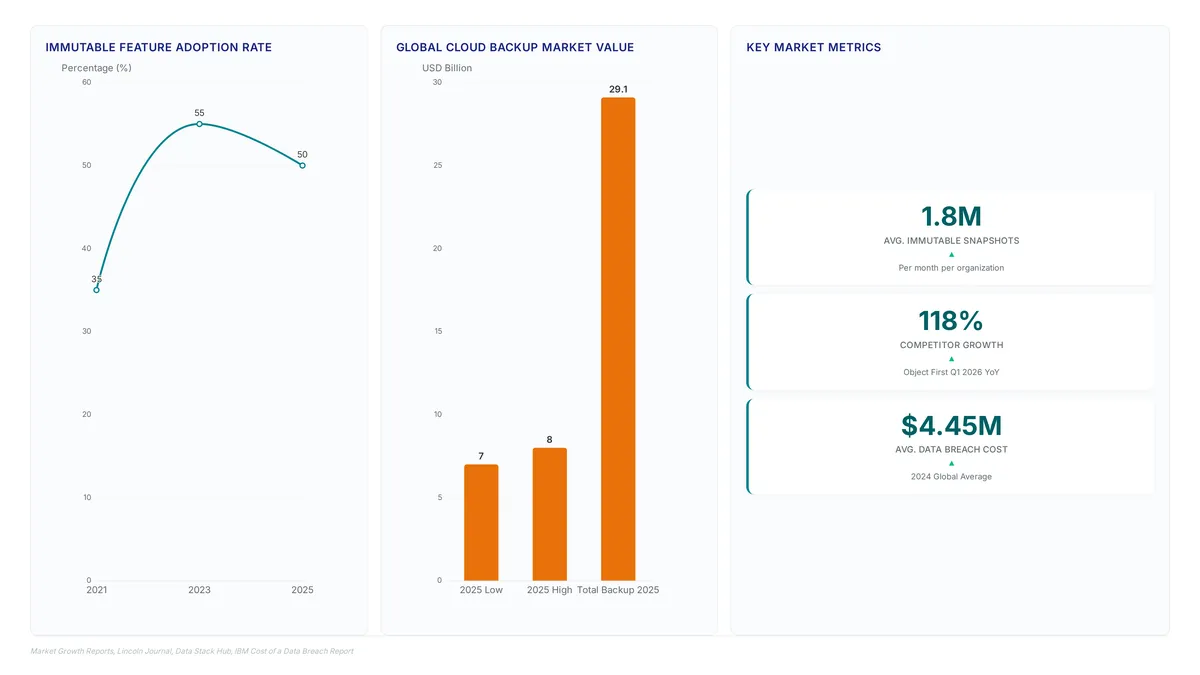
Alex tests the new S3 Files service: writes converge in under 2s, but deleted files linger for 18 seconds. Know the latency trade-offs.

We tested S3 Files on April 7, 2026. Updates hit in 1.8s, but new files still lag 30s. Here is the sync math for your ML pipelines.

AWS S3 Files now supports NFS v4.2, letting Lambda mount buckets directly. This ends the 20-year split between file flexibility and object durability.
AWS S3 Files now serve NFS v4.2 directly, letting 54% of multi-cloud users consolidate storage without duplicating data or paying gateway fees.

EBS hits 20x faster I/O than S3. Learn why block storage beats object stores for high-velocity AI training pipelines.

See how Btrfs handles 150 uploads per second. Managed S3 fails at this scale, but selfhosted storage keeps latency predictable.

With 91% of production AI relying on object storage, latency now dictates model success. Learn why proximity matters more than raw GPU power.

After 18 years, S3 holds 500 trillion objects with eleven nines durability. See how simple PUT/GET primitives scaled globally without breaking apps.
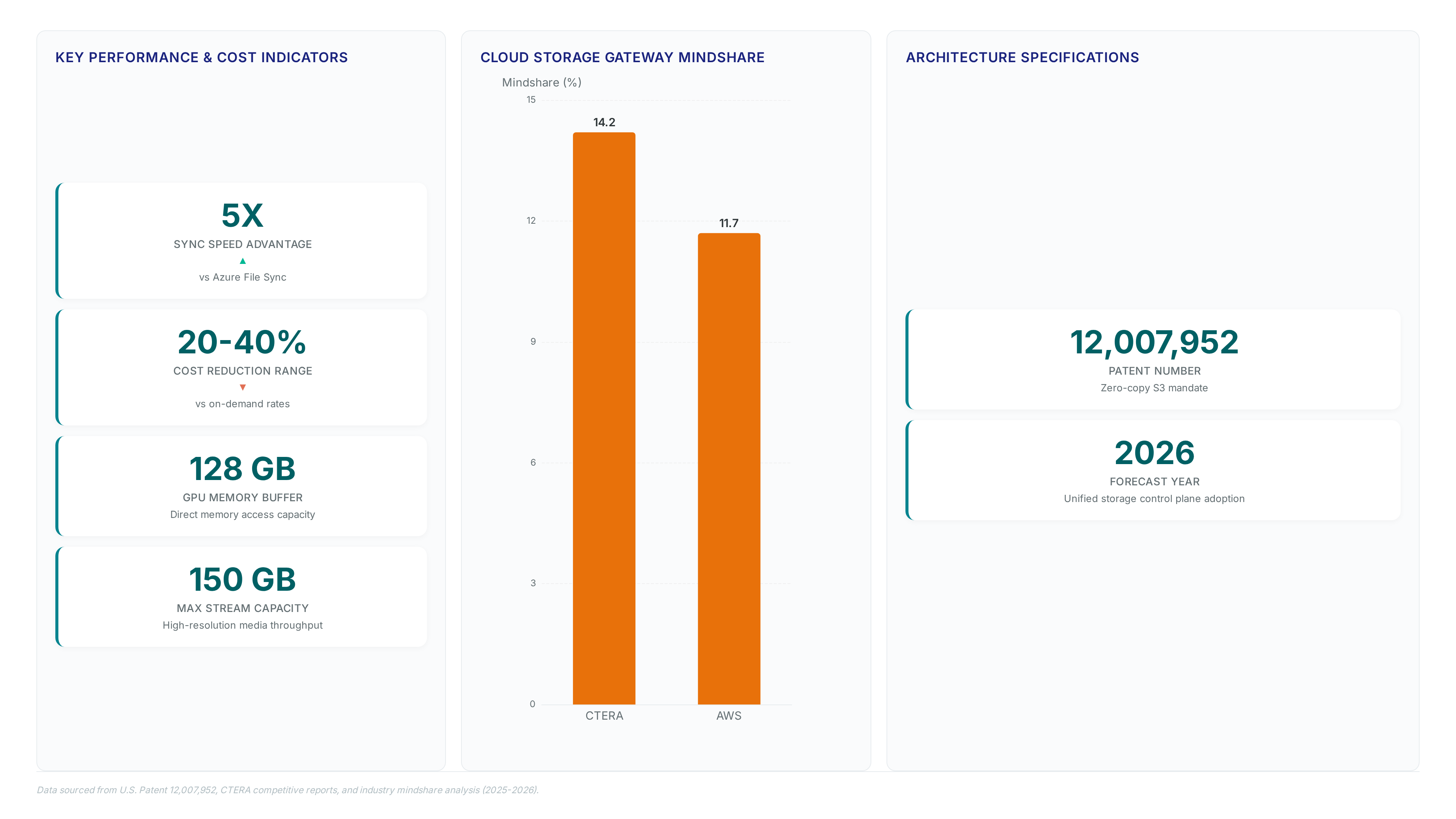
Alex breaks down how Ctera Fusion Direct enables S3 over RDMA at wire speed, eliminating the gateway latency that slows AI training.

Scality's connector delivers 10x faster performance than standard S3 interfaces. Learn how hybrid tiering cuts infrastructure costs by 20% without speed loss.

Stop GPU starvation with Scality tiering. Testing shows 10x faster performance than standard S3 interfaces on similar hardware for AI workloads.

Avoid building proprietary backends. Save 70% on storage costs while getting 1Tbps throughput for your AI training workloads today.

Stop burning 18 months building object stores. Whitelabel storage lets GPU farms launch in weeks with zero egress fees.

Neoclouds managing five exabytes can bypass years of engineering. See how integrated object storage feeds GPU clusters without scalability ceilings.
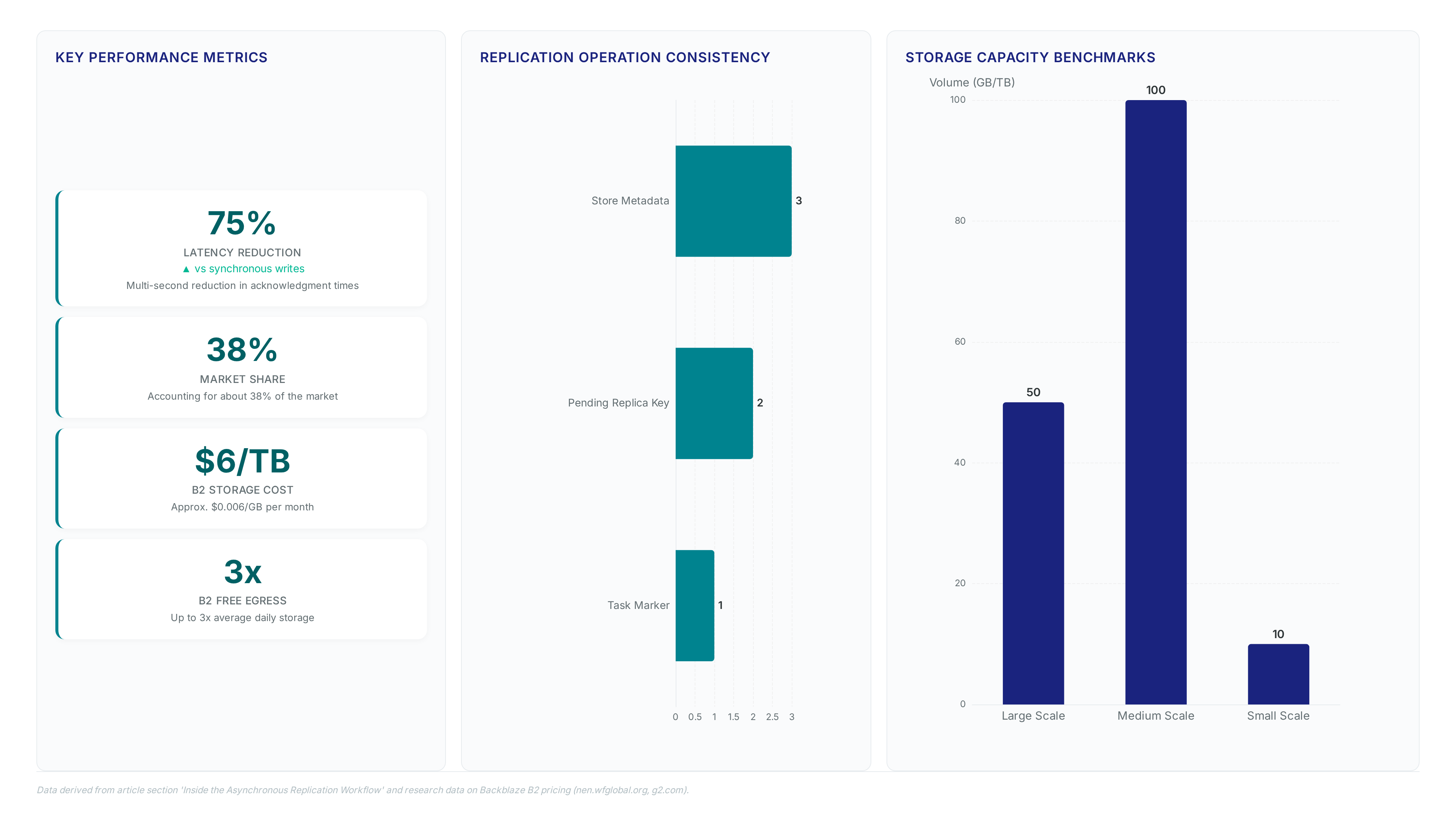
See how local uploads slash Time to Last Byte from 2s to 500ms for global AI workflows without complex pricing layers.

Moving 130 TB of Pi digits took two weeks at 2 Gbps. See why object storage beats local RAID for preserving massive computational artifacts.