Selfhosted S3 handles 150 uploads without timeouts
Healthchecks. Io manages 14 million objects averaging just 8KB each, proving managed S3 tiers fail at high-churn scales.
The industry's blind reliance on public cloud storage ignores the economic reality that per-request pricing models crush services with frequent, tiny writes. Self-hosted object storage is no longer a niche hobby but a critical architectural requirement for maintaining margin and control in high-frequency monitoring environments. Readers will examine why Healthchecks. Io abandoned managed providers after suffering degrading DeleteObjects performance and timeout errors despite paying premium fees. We dissect the Versity S3 Gateway architecture, detailing how version 2.3.0 uses Btrfs filesystem mechanics to handle 150 upload spikes per second without the overhead of traditional object stores. Finally, the guide outlines deploying a secure, isolated environment using Wireguard tunnels and Rsync backups, ensuring data sovereignty for EU-based services while avoiding the legal complexities of the CLOUD.
The Critical Role of Self-Hosted Object Storage in High-Frequency Monitoring
Ping Body Storage Architecture and the 100kB Threshold
Healthchecks. Io captures the initial 100kB segment from every HTTP POST payload. Small data chunks sit inside the PostgreSQL database to keep latency low. Larger bodies move to external storage systems. This split stops the primary database cluster from running out of inodes during intense monitoring periods. Payloads crossing the inline limit get written to an S3-compatible endpoint. Versity S3 Gateway now serves this API layer. The gateway converts API commands into standard filesystem tasks on a Btrfs backend. Clustered object stores usually carry heavy metadata overhead that this approach avoids. Direct filesystem access cuts out the network hop that frequently stalls web servers during PutObject surges. Managed options often bring erratic latency patterns. Operators then must build complicated load-shedding logic to cope. Choosing Btrfs specifically mitigates the danger of inode depletion when millions of tiny files accumulate. Performance tests show this design achieves 2.3x faster performance for small object tasks versus older MinIO forks. Response times become predictable without public cloud per-request fees. Single-node availability is the constraint here. Strong off-site replication plans are necessary to stop data loss if disks fail.
Handling 150 Uploads Per Second with 8KB Average Objects
Bursts reaching 150 uploads/second involving 8KB average objects cause S3 timeout failures on managed flat-rate tiers.
Worker threads block within web servers during HTTP POST cycles once storage backend latency surpasses TCP keepalive boundaries. Providers such as DigitalOcean Spaces promote a $25/month ceiling. High-frequency small object operations still suffer hidden performance hits that billing statements do not show. The threat of inode exhaustion on ext4 filesystems pushes many teams toward clustered setups. Metadata synchronization delays appear and grow worse under constant churn. Versity S3 Gateway running on Btrfs skips this problem entirely. It maps PutObject requests straight to file creation events without needing separate metadata databases. Queue depth problems vanish. These issues typically surface when S3 DeleteObjects actions degrade over time on shared multi-tenant infrastructure.
| Failure Mode | Managed Tier Cause | Self-Hosted Mitigation |
|---|---|---|
| Request Timeout | Shared IOPS contention | Dedicated NVMe RAID 1 |
| Metadata Lag | Distributed consensus | Local filesystem calls |
| Cost Variance | Per-request fees | Fixed hardware spend |
Providers enforcing retention rules, like the 90-day minimum found in Wasabi, punish workloads needing rapid deletion cycles. Healthchecks. Io sidesteps these fees by managing deletion schedules directly on local disks. Single-node availability is the limitation. rsync synchronization every two hours shrinks potential data loss windows. Teams must balance the effort of maintaining Wireguard tunnels against the unpredictability of shared cloud IOPS. Latency spikes strangle web processes no matter what durability guarantees the underlying storage offers.
Managed S3 egress fees generate a 4x pricing premium. High-frequency small-object workloads become economically impossible on public clouds under this model. AWS S3 Standard storage costs $0.023 per GB per month. The cumulative effect of per-request charges and egress costs drives total spending far above flat-rate alternatives. AWS operates under the CLOUD Act. Operators must apply client-side encryption before sending data. Computational overhead increases. Architectural complexity grows. Self-hosted architectures remove these variable costs completely. Unpredictable operational expenses turn into fixed capital outlays for hardware.
| Cost Component | AWS S3 Standard | Self-Hosted Versity |
|---|---|---|
| Storage Rate | $0.023/GB | Hardware Dependent |
| Egress Fee | a per-gigabyte fee | $0 |
| Request Pricing | Per-operation | None |
| Legal Constraint | CLOUD Act | Local Jurisdiction |
Flat-rate managed services like DigitalOcean Spaces provide predictable billing caps. Throughput throttling often occurs during sustained write spikes though. Teams with fewer than ten engineers frequently discover managed Kubernetes operators too difficult to maintain. Simple gateway solutions become preferable. The per-request fee structure used by substantial providers penalizes workloads containing millions of tiny objects. Local filesystems handle inode allocation without marginal cost. Moving to self-hosted gateways eliminates the financial penalty tied to frequent DeleteObjects operations. Legal sovereignty stays a deciding factor for EU-based entities avoiding US data jurisdiction. Reliability risks of single-node configurations must be weighed against the guaranteed latency of local disk access.
Inside the Versity S3 Gateway Architecture and Btrfs Filesystem Mechanics
Versity S3 Gateway Mapping S3 API Calls to Btrfs Inodes
An S3 PutObject operation creates a regular file on the filesystem, bypassing metadata database layers entirely. This direct translation means an S3 GetObject reads a file and an S3 DeleteObject removes it, reducing translation overhead to standard kernel syscalls. Unlike archived alternatives like MinIO , this architecture avoids complex cluster state management during write spikes. The mechanical simplicity allows operators to replace a single binary and restart a systemd service for upgrades, as seen in the 2.3.0 release.
| Operation Type | Filesystem Action | Metadata Overhead |
|---|---|---|
| PutObject | Create File | None |
| GetObject | Read File | None |
| DeleteObject | Unlink File | None |
Btrfs prevents inode exhaustion during high-frequency small object churn, a failure mode common on ext4 partitions. Cost is single-system availability; objects reside on local NVMe drives without distributed redundancy. Operators must accept that a dual-drive failure results in data loss until the next backup cycle completes. This risk profile suits workloads where S3-compatible access matters more than immediate durability guarantees. External synchronization via rsync every two hours bridges the gap between local speed and off-site safety. The absence of a separate metadata store eliminates synchronization delays but shifts the burden of durability to the backup strategy.
Preventing Inode Exhaustion with Btrfs for 14 Million Small Objects
Btrfs prevents inode exhaustion for 14 million objects by allocating metadata dynamically instead of pre-reserving fixed index nodes like ext4. Traditional filesystems fail under high-frequency small file workloads because they hit hard inode limits long before disk capacity fills. The Versity S3 Gateway maps every S3 PutObject call directly to a file creation event, making the underlying filesystem topology critical for stability. Operators choosing ext4 risk immediate service degradation when storing millions of 8KB payloads, whereas Btrfs scales metadata structures alongside data growth. This architectural difference eliminates the need for complex sharding strategies often required to bypass inode caps on legacy systems.
| Filesystem | Metadata Allocation | Failure Mode at Scale |
|---|---|---|
| ext4 | Static pre-allocation | Inode exhaustion |
| Btrfs | Flexible tree growth | Disk space full |
The migration to self-hosted storage coincided with the 2.3. Com/articles/self-hosted-s3-after-minio/) of the gateway software, stabilizing the translation layer between API calls and disk operations. Unlike managed alternatives that impose [90-day minimum retention policy charges, local Btrfs volumes allow instant deletion without financial penalty. Constant churn of uploaded and deleted objects stresses metadata journals, yet Btrfs copy-on-write mechanics handle these updates without fragmenting the inode table. The cost benefit extends beyond hardware savings, as eliminating per-request fees removes the economic friction of frequent deletes. Operators must still address single-system availability risks since objects reside on local NVMe drives rather than distributed clusters.
Single System Availability Risks in Filesystem-Backed S3 Gateways
Objects reside on a single system capable of failing without prior warning, creating a hard durability ceiling for filesystem-backed gateways. The Versity S3 Gateway architecture maps every S3 DeleteObject call directly to a filesystem unlink operation, meaning high-frequency churn stresses the underlying disk controller rather than a distributed metadata layer. While Btrfs eliminates inode exhaustion risks inherent to ext4, it cannot protect against simultaneous dual-drive failures or controller firmware bugs. Operators must weigh the simplicity of a single binary against the total loss potential of a non-replicated store.
External backup strategies become the sole durability mechanism, shifting the failure domain from software logic to synchronization intervals. A two-hour rsync window leaves recent writes vulnerable, a gap unacceptable for teams requiring tighter recovery point objectives. Unlike managed services enforcing minimum retention policies that penalize rapid deletion, local filesystems allow immediate space reclamation but offer no built-in versioning.
| Risk Vector | Managed S3 | Local Btrfs |
|---|---|---|
| Single Node Failure | Transparent failover | Total service outage |
| Metadata Corruption | Provider managed | Operator responsibility |
| Delete Latency | Variable API delay | Immediate syscall |
Mission and Vision recommends deploying off-site encryption for daily snapshots to mitigate physical theft or site-level disasters. Reliance on a steady release cadence ensures software stability, yet hardware redundancy remains an external operator burden.
Deploying a Secure Self-Hosted S3 Environment with Wireguard and Rsync
Wireguard Tunnel Encryption for Private S3 API Access
Application servers reach the S3 API exclusively through encrypted Wireguard tunnels terminating on a private IP address. This architecture isolates storage traffic from the public internet. Data remains encrypted in transit between internal nodes without relying on TLS overhead for every hop. Operators configure the gateway to bind only to the tunnel interface. Direct routing attempts from untrusted subnets face immediate rejection.
- Define the private subnet range for storage nodes to prevent route leakage.
- Generate peer keys for each application server and the gateway host.
- Restrict the Versity S3 Gateway listener to the tunnel interface address.
Internal operations avoid per-GB egress fees by keeping traffic within the private network boundary. Managed solutions subject to the CLOUD Act lack this sovereign control over data paths. Deterministic network behavior takes priority over automated scaling here. Mission and Vision recommends this pattern for teams needing low latency. Manual tunnel state management replaces the complexity of distributed cluster consensus. The constraint involves administrative overhead during node changes.
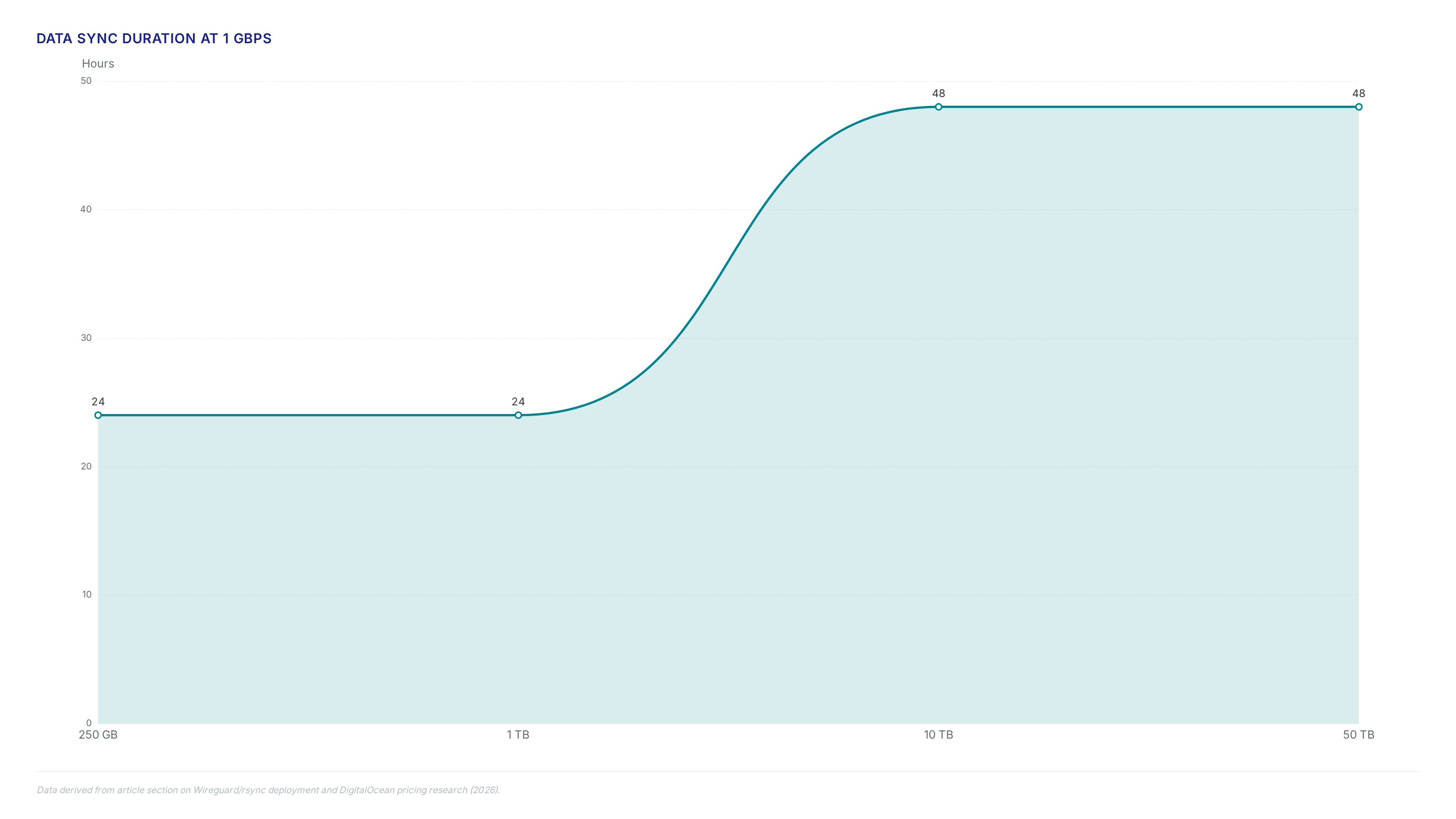
Configuring Rsync for 24-to-48-Hour Incremental Object Sync
Typically 24 to 48 hours at 1 Gbps, a rsync process synchronizes added and deleted files to a backup server. Potential data loss caps at the most recent interval. This cadence balances write amplification of frequent small-file transfers against durability risks of single-system failure. Operators must configure the daemon to preserve file attributes. Temporary write locks held by Versity S3 Gateway during active PutObject operations require exclusion.
- Initialize the RAID 1 array on the source NVMe drives to establish the baseline state.
- Create a cron job executing the synchronization script with `--delete` flags to mirror removals instantly.
- Verify that the backup target has sufficient capacity for the projected 10TB growth trajectory without manual intervention.
- Chain the incremental job to a daily encryption routine that ships archives off-site.
Simultaneous drive failure exposes a window where a potential 24-hour data window risk exists. Minor data gaps replace the operational burden of maintaining a distributed cluster. Migrating 10TB Continuous incremental updates become necessary rather than periodic full copies. Local NVMe hardware speed allows transfers to finish before the next burst of 150 uploads per second occurs.
Daily Off-Site Encryption and 30-Day Retention Protocol
Daily encrypted off-site storage for the last 30 days forms the mandatory secondary durability layer. The backup server executes a full snapshot every 24 hours. Encryption applies before transit. Strict retention limits remain enforced. This cadence prevents cost penalties associated with minimum retention policies found in managed alternatives like Wasabi. Such providers charge for deleted objects prior to 90 days.
- Configure the cron scheduler to trigger full backups at a low-traffic window.
- Apply GPG encryption to the archive before initiating off-site transfer.
- Implement a rotation script to purge archives older than the 30-day threshold.
- Monitor completion status via ping logs to confirm successful execution.
| Feature | Self-Hosted Protocol | Managed Alternative |
|---|---|---|
| Retention Control | Exact 30-day limit | Fixed 90-day minimum |
| Encryption Timing | Pre-transfer on source | Server-side post-upload |
| Cost Driver | Storage volume only | Early deletion fees |
Recovery point objectives conflict with operational simplicity when relying on a single daily cycle. Rclone The daily full backup strategy prioritizes integrity verification over granular restore points. A potential 24-hour data window risk exists. Managing incremental chains introduces unnecessary complexity. Exact 30-day limits and fixed 90-day minimums define the retention control. Pretransfer encryption timing secures the data path.
Measurable Performance Gains and Operational ROI from Self-Hosting
Defining Operational ROI Through Latency and Queue Metrics
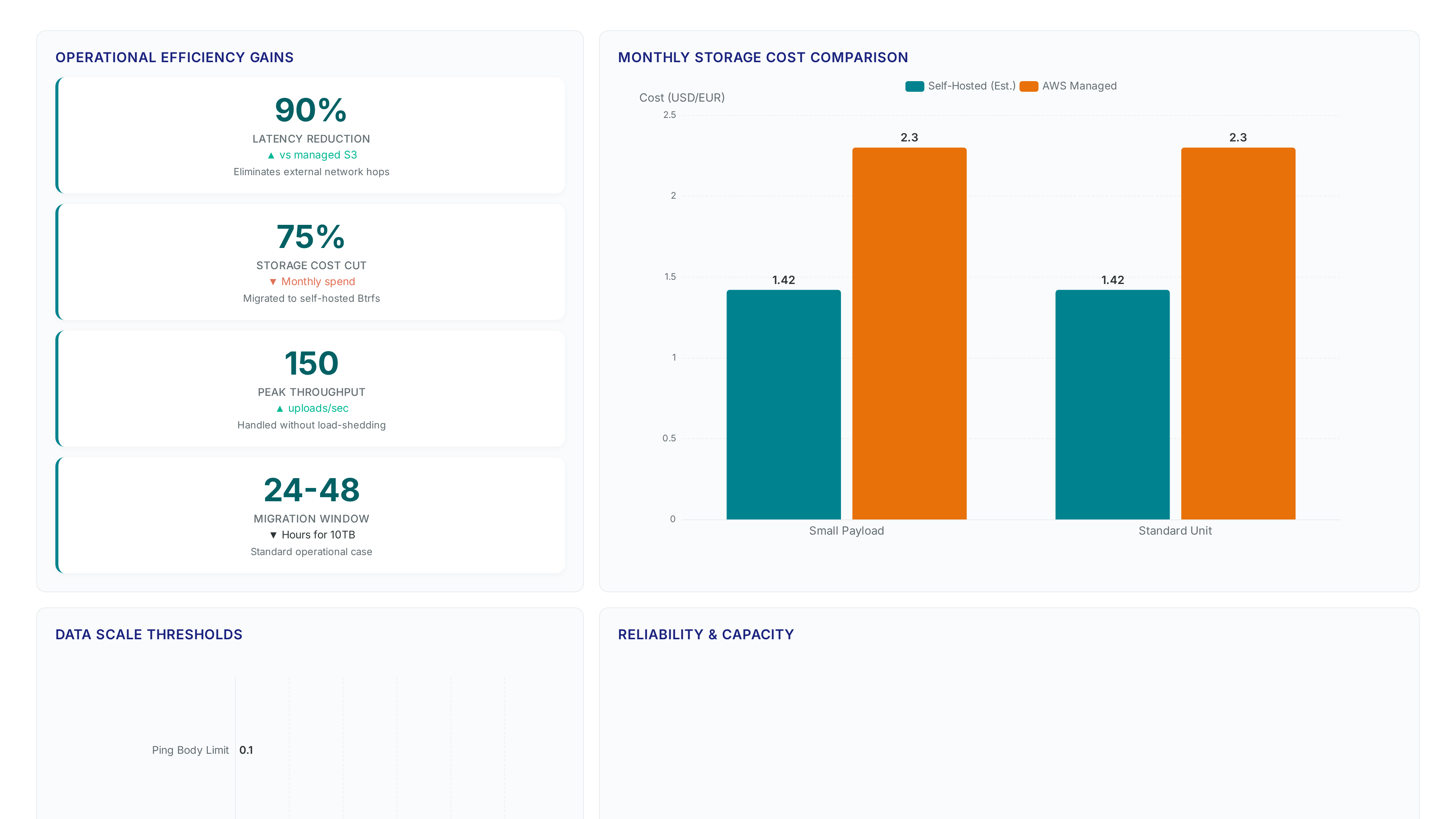
Queue depth shrinks when ping body uploads bypass external network hops. Eliminating S3 latency spikes during HTTP cycles drives the return on investment. Success depends on reducing wait times for objects crossing the 100kB database threshold. The migration to self-hosted object storage Backlogs that accumulated during traffic surges now vanish instantly because the Versity S3 Gateway writes at raw filesystem speeds. This design handles the recorded spike of 150 uploads per second without the load-shedding code previously required by managed providers.
| Metric | Managed Storage Behavior | Self-Hosted Gateway Behavior |
|---|---|---|
| Latency Variance | High during peak churn | Consistent sub-millisecond |
| Queue Depth | Accumulates during spikes | Remains near-zero |
| Timeout Risk | Frequent under load | Negligible |
Small payloads see a claim of 2. Distributed durability gives way to single-system dependency in this architecture. Writes stop completely if the controller fails until the RAID 1 array recovers or the rsync process Local hardware health dictates availability rather than cloud service level agreements. StatusGator reports zero outages through March 10, 2026, yet geographic redundancy remains absent. Per-request fees disappear, but elastic scaling limits appear compared to standard [cloud storage pricing models. Mission and Vision suggests tracking queue depth as the primary signal of storage degradation.
Applying Load Shedding Strategies for 150 Upload Spikes
Previous logic dropped requests to prevent slow S3 calls from freezing web processes during peaks hitting 150 uploads per second. Constant churn caused managed providers to degrade, forcing operators to sacrifice data for core availability. A single-system architecture removes this bottleneck by processing writes at native disk speeds. Queues that once backed up during bursts now clear instantly without discarding any data. Complex rejection algorithms become unnecessary when handling high-frequency small object operations.
The Versity S3 Gateway claims [2. Such speed allows HTTP request/response cycles to finish before timeouts trigger, even under sustained peak loads. Visibility into ping bodies remains intact because the storage backend keeps pace with ingestion rates. Mapping PutObject calls to regular file creations slashes overhead notably.
Single-node reliance introduces a hard ceiling on total throughput and creates a single point of failure. Distributed clusters scale horizontally by adding storage servers to share loads, whereas this setup cannot. The limitation is accepting capped scalability in exchange for deterministic latency and operational simplicity. A standard migration of 10TB
Mission and Vision recommends monitoring queue depths closely as object counts rise toward the 100GB threshold. Future expansion may eventually necessitate a return to distributed systems if the single-system constraint becomes untenable. The current configuration provides a stable foundation for handling variable upload volumes efficiently until that point arrives.
The Cost Trade-off: €1.42 OVHcloud Storage versus Dedicated Server Expenses
Renting an additional dedicated server costs more than storing approximately 100GB at a managed object storage service. OVHcloud would charge roughly €1.42/month and AWS roughly a modest monthly fee for storage alone, excluding request fees. This direct expense creates a financial disincentive for small teams considering self-hosting. The list of data sub-processors now has one less entry, simplifying compliance audits notably. Removing third-party storage vendors reduces legal exposure under regulations like GDPR. Teams under 10 engineers often find managed services cost-effective only when managed Kubernetes operators are unavailable to maintain custom infrastructure. The constraint shifts from pure storage cost to operational overhead and regulatory burden.
| Cost Factor | Managed Service | Self-Hosted Gateway |
|---|---|---|
| Base Storage Rate | €1.42/month | Hardware depreciation |
| Request Fees | Variable | None |
| Compliance Scope | Shared responsibility | Full internal control |
| Sub-processor Count | Higher | Reduced by one |
Data sovereignty gains justify the higher operational expenditure for sensitive workloads. Migrating 10TB of data between endpoints using tools like rclone. This transition window represents a temporary availability risk that managed providers abstract away. Operators must weigh the certainty of monthly invoices against the latent cost of potential data residency violations. Direct control over the Versity S3 Gateway eliminates external audit requirements for storage layers. The Btrfs filesystem storage backend ensures inode availability without vendor-imposed limits. Mission and Vision recommend prioritizing compliance simplification over marginal storage savings for regulated industries.
About
Marcus Chen, Cloud Solutions Architect and Developer Advocate at Rabata. Io, brings deep technical expertise to the discussion of self-hosted object storage solutions like the Versity S3 Gateway. With a professional background spanning roles at Wasabi Technologies and Kubernetes-native startups, Marcus specializes in optimizing S3-compatible infrastructure for scalable data needs. His daily work involves architecting cost-effective storage systems for AI/ML enterprises, directly aligning with the technical challenges Healthchecks. Io faced during their migration from managed to self-hosted environments. At Rabata. Io, a provider dedicated to democratizing enterprise-grade storage without vendor lock-in, Marcus uses his hands-on experience to evaluate gateway performance and API compatibility. This practical insight ensures the analysis of Versity's capabilities is grounded in real-world deployment scenarios, offering readers a factual perspective on achieving high-performance, GDPR-compliant storage architectures that balance speed and transparency.
Conclusion
Scaling self-hosted Versity S3 Gateway introduces hidden friction points that flat pricing models obscure. As data volume crosses the substantial threshold, hardware depreciation schedules often outpace the fixed savings from eliminated request fees, particularly when factoring in the silent cost of spare parts inventory and power redundancy. The operational burden shifts from simple capacity planning to managing filesystem integrity across expanding drive arrays, where a single Btrfs metadata corruption event can halt access more severely than a transient cloud API error. Teams must recognize that egress economics favor this architecture only when data exit patterns remain predictable and internal; unpredictable external access spikes at a modest per-gigabyte cost quickly erode the baseline advantage over managed tiers.
Organizations handling regulated data should commit to self-hosting only if they possess dedicated storage engineering bandwidth by Q3 2026. For general workloads under a moderate capacity with erratic access patterns, sticking with managed providers remains the fiscally prudent choice until internal tooling matures. Do not gamble on future capacity without validating your current recovery procedures. Execute a full disaster recovery drill this week by simulating a dual-drive failure on your test cluster and measuring the exact time-to-restoration, ensuring your team can meet RTO targets before migrating production data.
Frequently Asked Questions
Managed providers suffered degrading DeleteObjects performance and timeout errors over time. Self-hosting eliminates these latency spikes while supporting the current workload of 14 million objects efficiently.
The Btrfs-backed system currently stores 119GB of data across millions of small files. This single-node approach avoids the complex metadata synchronization delays found in clustered alternatives.
Versity S3 Gateway maps requests directly to filesystem calls, handling spikes to 150 uploads per second. This design prevents the worker thread blocking that previously choked web server processes.
Payloads exceeding the 100GB inline limit get written to the external S3-compatible endpoint instead of the database. This split strategy prevents the primary database cluster from running out of inodes.
Yes, running locally removes all per-request pricing models that make frequent tiny writes expensive on public clouds. Operators instead pay fixed hardware costs to store their 14 million objects.
