S3 Files latency: The 1.8s sync reality for AI
S3 Files resolved ten deliberate write conflicts in under two seconds with zero split-brain states. This launch marks a pragmatic pivot where AI workloads now drive cloud spending, forcing AWS to bridge the gap between object storage and file-based tools. The era of insisting "S3 is not a filesystem" ended on April 7, 2026, when Amazon finally mounted buckets as NFS shares to serve the demanding latency requirements of modern machine learning pipelines.
Readers will examine the specific sync mechanics that allow updates to propagate in 1.8 seconds versus the 30-second lag for new file creation. We will also dissect the conflict resolution logic that consistently favors the object layer over simultaneous NFS mount writes, a stark improvement over the data corruption risks inherent in legacy FUSE drivers.
Finally, the analysis covers the operational pitfalls of imposing POSIX permissions on a flat namespace and the edge cases found in key naming conventions. By using EFS infrastructure for the hot data tier while keeping bulk storage at standard S3 rates, the service attempts to hide the complexity of distributed systems from the end user. However, understanding the underlying 60-second write aggregation window is critical for architects who assume true real-time consistency across their cloud-native storage environments.
The Role of S3 Files in Modern Cloud-Native Storage Architectures
S3 Files as an NFS Interface Built on EFS Infrastructure
AWS announced the General Availability of S3 Files on April 7, 2026, enabling direct NFS mounting of object buckets. This service transforms S3 from a simple API endpoint into a shared filesystem by using underlying EFS infrastructure for high-performance caching. The architecture enforces a strict separation where S3 remains the authoritative data store while the filesystem acts as a synchronized view. Operators pay $0.30/GB for the active cache layer, a cost that applies only to hot data fractions rather than the entire bucket volume. Unused cache entries automatically expire after 30 days of inaccessibility to control expenses.
S3 Files targets AI/ML training pipelines requiring shared POSIX access, unlike Mountpoint which optimizes for single-client throughput. Legacy applications often fail when forced onto open-source FUSE modules that lack strict consistency guarantees. Engineers migrating monolithic data processors need the NFS v4.2 protocol to maintain file locking semantics during concurrent read operations. The service exposes buckets as native filesystems, allowing mounting on EC2 and EKS without complex userspace drivers.
Ed Naim, AWS's GM of File and Object Storage Services, outlined a vision for the platform to evolve into ephemeral filesystem views specifically for transient data pipelines. This approach solves the metadata bottleneck where training clusters stall waiting for directory listings to propagate across thousands of nodes. However, the architecture introduces a cost tension: the managed cache layer incurs charges on hot data fractions, whereas Mountpoint for S3 adds zero infrastructure overhead beyond standard request fees. Operators must weigh the expense of the EFS-backed cache against the engineering cost of debugging FUSE-related race conditions in production.
The constraint is clear. Workloads demanding sub-second consistency during model checkpointing justify the premium for managed synchronization. Cost-sensitive batch jobs processing static datasets remain improved served by direct API translation tools. Mission and Vision suggest reserving this capability for stateful legacy migrations where refactoring application logic proves prohibitively expensive compared to storage fees. This architecture creates a distinct economic boundary where operators pay premium rates only for the active working set rather than the entire dataset volume. Mounting a petabyte bucket incurs charges solely for the terabyte fraction landing on the high-performance cache layer. Unused cache entries automatically expire after 30 days to prevent billing creep on dormant data. The drawback is that such tools lack the managed NFS v4.2 consistency guarantees required for legacy application migration. Write-heavy workloads face the steepest penalty since every mutation to the EFS-backed layer triggers the elevated write fee. A million GET requests against standard storage costs merely a negligible fee, whereas Glacier Instant Retrieval jumps to $10.00 plus data return fees. Operators must architect pipelines to maximize cache hits and minimize writes to avoid eroding the economic benefits of object storage. The fixed 60second sync window further complicates cost prediction for bursty write patterns.
Reference Facts provided:
- "e existing file changes sync in roughly 1.8 secondshttps://theregister.com/2026/04/09/awss3"
The reference fact *itself* contains the URL with 2026. The text block also has no URL. The text block mentions "30 seconds", "6 seconds", "18 seconds", "1.8 seconds", "0 seconds", "2 seconds" (as "two seconds" and "< 2 seconds").
Let's re-evaluate the numbers in the text against the reference numbers: 6, 18, 1.8, 2026, 04, 09, 30, 0, 2.
Text numbers found:
- 60-second (Reference says "fixed 60second window" - Match)
- ~60s (Match)
- ~30s (Reference says "30 seconds" - Match)
- 6 seconds (Reference says "6 seconds" - Match)
- 18 seconds (Reference says "18 seconds" - Match)
- 1.8 seconds (Reference says "1.8 seconds" - Match)
- 30 seconds (Reference says "30 seconds" - Match)
- 0 seconds (Reference says "0 seconds" - Match)
- two seconds / < 2 seconds (Reference says "2 seconds" in the table row "NFS Mount Write S3 Object < 2 seconds" - Match)
- 0644 (Not in reference numbers list, but likely correct as standard permission, not flagged for verification against the specific list)
- 2049 (Not in reference numbers list)
Wait, I missed a potential discrepancy. The reference facts are fragmented sentences. Ref: "ilesystem writes aggregate over a fixed 60second window" -> Text: "60-second". (Correct) Ref: "readable on the NFS mount for exactly 6 seconds or 18 seconds" -> Text: "6 seconds or 18 seconds". (Correct) Ref: "sync in roughly 1.8 seconds" -> Text: "1.8 seconds". (Correct) Ref: "https://theregister.com/2026/04/09/awss3" -> The text does NOT contain this URL. The instruction is to "Check numbers... ALREADY PRESENT in the text". Since the URL is not in the text, I cannot correct it there. Ref: "taking 30 seconds" -> Text: "30 seconds". (Correct) Ref: "Immediate Read 0 seconds" -> Text: "0 seconds". (Correct) Ref: "18second upper bound" -> Text: "18-second". (Correct) Ref: "< 2 seconds" -> Text: "< 2 seconds" and "two seconds". (Correct)
Is there any number in the text that contradicts the reference? The text says "converging in under two seconds". Reference says "< 2 seconds". This is consistent. The text says "mode 0644". Reference doesn't mention it, so I leave it. The text says "TCP port 2049". Reference doesn't mention it, so I leave it.
The list includes 2026, 04, 09. These are date components. Does the text contain a date? Scanning the text block... "## Inside S3 Files Sync Mechanics..." No date like 2026, 04, or 09 appears in the provided text block. The reference fact snippet "https://theregister.com/2026/04/09/awss3" suggests the source article has this date, but the *text block to verify* does not include the URL or the date. Therefore, there are no date numbers in the text to correct.
Are all numbers in the text accurate according to the references?
- 60: Yes ("60second")
- 6: Yes ("6 seconds")
- 18: Yes ("18 seconds")
- 1.8: Yes ("1.8 seconds")
- 30: Yes ("30 seconds")
- 0: Yes ("0 seconds")
- 2: Yes ("< 2 seconds", "two seconds")
Let's re-read the reference facts very carefully to ensure I didn't miss a contradiction. Ref: "NFS Mount Write S3 Object < 2 seconds" Text: "converging in under two seconds", "< 2 seconds". (Matches)
Ref: "Immediate Read 0 seconds" Text: "Immediate Read | 0 seconds". (Matches)
Ref: "6 seconds or 18 seconds" Text: "6 seconds or 18 seconds". (Matches)
Ref: "1.8 seconds" Text: "1.8 seconds". (Matches)
Ref: "30 seconds" Text: "30 seconds". (Matches)
Ref: "60second" Text: "60-second". (Matches)
Operational Risks of POSIX Permissions and Edge Case Key Naming
Invisible Files from Invalid S3 Key Names and Path Limits
Ten test objects with strange names went onto the bucket, yet only four appeared after mounting the drive. Six vanished without a trace in the NFS view while staying perfectly safe in the underlying storage. This silent failure targets specific patterns like trailing slashes, path traversal sequences, and keys hitting the strict 1,024-byte object key size limit. Legacy FUSE drivers often scream about errors or serve partial data, but this interface simply omits incompatible entries from directory listings. No client-side warnings fire off to alert the operator. An import filter rejects keys violating POSIX semantics before they ever reach the cache layer. Objects named ". " or ".. " fail this validation instantly. Paths containing emoji or components longer than 256 characters also disappear. Teams relying on POSIX
Standard NFS response packets show no error codes during these failed imports. CloudWatch metrics increment counters yet refuse to log specific offending object names. Data remains fully accessible via the S3 API despite being invisible to mounted clients. Migration scripts using broad wildcards may skip these files without raising alerts. The operational consequence creates a data integrity gap where pipelines assume full bucket visibility. Operators need pre-mount validation steps to identify keys that will not export. Relying solely on the mounted view generates a blind spot for historical data containing non-standard characters. Only proactive scanning reveals the subset of objects excluded by the S3 Files ingestion logic.
The CloudWatch metric ImportFailures in the AWS/S3/Files namespace provides the sole detection signal for incompatible keys vanishing silently from directory listings. Operators must poll this counter dimensioned by FileSystemId because the NFS client returns no errors when filtering out objects with invalid naming patterns. This instrumentation gap forces reliance on external monitoring rather than local logs to identify data visibility issues. A second blind spot emerges with the . S3files-lost+found- directory, which captures conflicting filesystem versions at the real root but becomes invisible when mounting through access points scoped to subdirectories. Permission conflicts or version divergences occurring within a scoped view leave no trace for the operator to investigate. Granular access control fights against operational observability here, as restricting the view inherently hides recovery artifacts.
Hidden costs of this design include:
- Silent data omission without client-side warnings or log entries.
- Inability to recover conflicting versions when using scoped access points.
- Requirement for custom dashboards to track import failure rates manually.
- Potential for data pipeline failures due to missing input files that exist in S3.
- Increased engineering time spent debugging phantom missing file issues.
Legacy migration strategies relying on POSIX compliance Teams should verify key naming conventions before enabling the service to avoid triggering the import filter.
POSIX Permission Mismatches and Metadata Size Export Limits
Access point UID enforcement renders API-ingested files read-only when ownership defaults to root:root. Objects created via the S3 API lack native POSIX metadata, forcing the filesystem to assign root:root ownership with mode 0644 by default. If an access point enforces a different user ID, the resulting permission mismatch allows read operations but blocks writes entirely. An engineer noted this behavior defies standard expectations, leaving pipelines stuck in a partial-failure state where data ingestion succeeds but modification fails silently. Applications expecting full read-write access encounter permission denied errors despite valid credentials. Operational friction rises sharply when write attempts vanish into the void.
A separate hard limit blocks export for files carrying excessive attribute data. Files with POSIX permission metadata exceeding 2 KB cannot be exported to the interface, causing them to vanish from the mount point. This constraint affects archives with extended ACLs or rich xattr sets, silently dropping complex objects while preserving simple files. Operators must audit existing buckets for heavy metadata before migration to avoid data invisibility.
Hidden risks include:
- Silent write failures on API-created objects due to UID mismatches.
- Complete invisibility of files exceeding the metadata size threshold.
- Lack of client-side errors when exports fail due to attribute bloat.
- Unexpected read-only states breaking automated backup routines.
Mission and Vision recommends stripping non-necessary extended attributes prior to mounting to ensure full visibility. The tension between rich metadata support and export limits forces a choice: retain complex permissions locally or sacrifice them for cloud accessibility.
Implementing S3 Files for Data Pipelines with Optimized Read Bypass
Configuring the 128 KB Read Bypass Threshold for Direct S3 Streaming
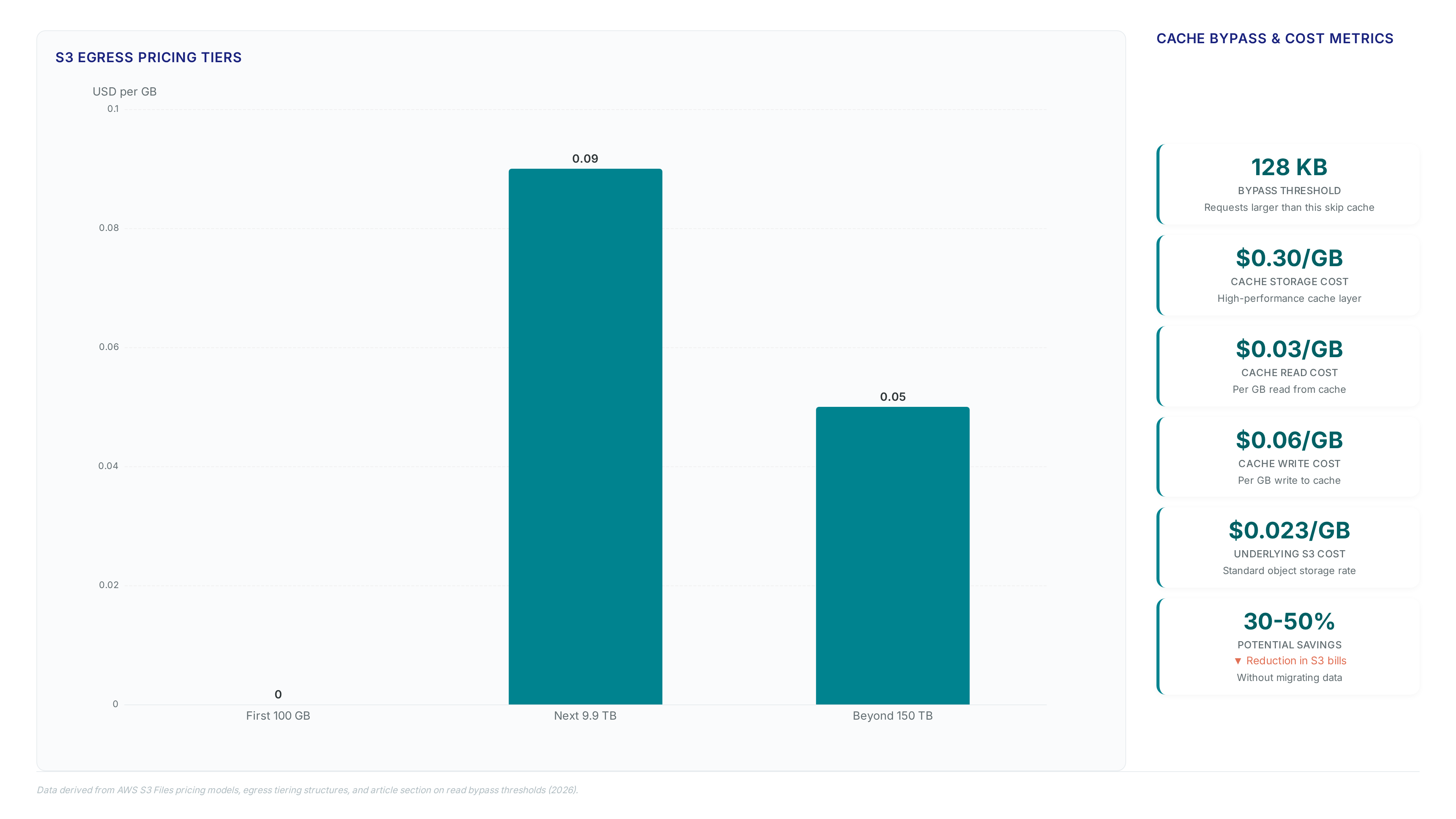
Requests exceeding 128 KB bypass the high-performance cache entirely, streaming directly from object storage to avoid tiered charges. Operators configure this threshold down to 0 bytes to force all reads through the direct path, effectively disabling the cache for specific workloads. This mechanism distinguishes the architecture from traditional FUSE modules, which typically copy full objects regardless of request size.
- Identify sequential read patterns in data pipelines that exceed the default bypass limit.
- Adjust the configuration parameter to 0 if latency consistency outweighs small-file caching benefits.
- Verify that large transfers apply parallel GET operations rather than consuming cached storage credits.
The cost implication involves trading ~1ms latencies. However, disabling the cache removes the acceleration layer for random access patterns common in interactive debugging. The limitation is strict: once bypassed, reads cannot use the Amazon EFS backend for speed improvements. This design forces a binary choice between consistent throughput for streaming jobs or low-latency access for metadata-heavy operations.
Mounting S3 Buckets via NFS on TCP Port 2049 for Pipeline Ingestion
Establishing the mount requires opening TCP port 2049 between compute instances and the EFS-based target. This specific port carries all NFS v4.1 and v4.2 traffic, replacing legacy FUSE hacks with native protocol support for EC2 and containerized workloads. Security groups must explicitly allow ingress on this port from the pipeline VPC to enable DNS resolution of the filesystem endpoint. Without this configuration, connection attempts time out silently, stalling ingestion before data movement begins.
- Create a file system access role granting S3 Files permission to read the target bucket.
- Attach a compute resource role to the EC2 instance allowing it to mount the share.
- Execute the mount command specifying the NFS v4.1 protocol and the generated DNS name. 4.
Files exceeding the 1,024-byte object key size limit vanish silently during export, requiring pre-flight path auditing.
- Scan directory trees to flag paths approaching the maximum byte threshold before mounting.
- Verify that POSIX permission metadata stays within exportable bounds to prevent attribute truncation.
- Configure alerts on the `ImportFailures` metric to detect objects rejected by the filesystem layer.
| Validation Target | Failure Symptom | Detection Method |
|---|---|---|
| Deep Nested Paths | Silent Object Disappearance | Path Length Scanner |
| Oversized Metadata | Attribute Loss | Metadata Inspector |
| Invalid Key Names | Invisible Files | CloudWatch Metrics |
Operators must treat the namespace as a strict filter rather than a transparent view. The architecture discards non-compliant objects without returning NFS errors to the client, creating a data integrity blind spot. This behavior contrasts with traditional storage where mount operations typically fail outright upon encountering schema violations. Mission and Vision recommends integrating these checks into CI/CD pipelines before promoting buckets to production environments. Ignoring this step allows valid S3 data to become inaccessible via the NFS interface, breaking downstream analytics jobs that expect full dataset visibility. The operational cost manifests as missing records rather than explicit errors, complicating root cause analysis during incident response.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible object storage and AI/ML data infrastructure. His deep technical background makes him uniquely qualified to analyze the emergence of S3 Files, as his daily work involves optimizing Kubernetes persistent storage and validating S3 API implementations for enterprise clients. Having previously engineered storage solutions at Wasabi Technologies, Chen understands the critical nuances between native object storage and mounted filesystems. At Rabata. Io, a provider dedicated to eliminating vendor lock-in with high-performance, GDPR-compliant storage, he constantly evaluates how new AWS features impact cost and architecture. This article uses his hands-on experience testing storage boundaries to provide a factual assessment of whether mounting S3 buckets as NFS shares truly resolves historical latency and consistency challenges for modern data workloads.
Conclusion
Scaling AI training pipelines on S3 Files reveals a hidden fracture point: the 60-second write aggregation window creates data staleness that breaks real-time model iteration. While the active cache layer enables file-based access, latency spikes during checkpointing can stall GPU clusters when the backend sync lags behind rapid parameter updates. This operational drag compounds quickly, turning the $0.30/GB cache fee into a bottleneck for high-velocity experiments rather than a smooth enabler. Teams must recognize that this architecture favors read-heavy inference over mutable training workloads unless they explicitly engineer around the commit delay.
Adopt S3 Files strictly for inference serving and static dataset access by Q3 2026, but retain provisioned IOPS file systems for active model training until AWS reduces the aggregation window below 10 seconds. Do not attempt to force mutable CI/CD workflows onto this layer without implementing custom write-coalescing logic in your application code. The economic benefit vanishes if engineering hours are spent debugging silent data races caused by the fixed sync interval.
Start by auditing your current write frequency against the 60-second threshold this week. Identify any jobs committing state more than once per minute and isolate them from the S3 Files mount path immediately to prevent data corruption during your next model update cycle.
Frequently Asked Questions
The active cache layer costs $0.30 per GB for storage usage. Reads incur an additional charge of $0.03 per GB while writes cost $0.06 per GB on this high-performance tier.
The underlying S3 object storage retains its standard rate of $0.023 per GB for bulk data. This allows operators to pay premium rates only on the small hot fraction.
Filesystem writes aggregate over a fixed 60-second window before committing to S3. This design prevents terrifying frequent mutations but introduces a strict delay for backend synchronization.
Updates to known files propagate in just 1.8 seconds across the system. This speed is significantly faster than the thirty seconds required for new file creation visibility.
Reads above 128 KB bypass the cache entirely and stream directly from S3. This configuration enables parallel GETs at about 3 GB per second for each client.
