NetApp EF50 storage hits 110 GBps read speed
NetApp's new EF50 and EF80 systems deliver 100GBps read throughput, a 250% improvement over previous generations announced at NVIDIA GTC 2026. Legacy block storage architectures still dominate the AI data pipeline when engineered for extreme density and raw speed. With 76% of large companies now actively deploying AI according to Nvidia's 2026 State of AI Report, the bottleneck has shifted from compute availability to feeding GPUs fast enough to prevent starvation.
The EF-Series architecture eliminates latency bottlenecks for HPC simulations and GenAI model training by packing 1.5PB of storage into a mere 2U rack space. Strategic positioning against competitor arrays reveals how simplified management reduces operational overhead without sacrificing the performance needed for transactional databases.
Global AI infrastructure spending hit $98 billion in 2026. Organizations cannot afford storage tiers that throttle GPU utilization. High-performance scratch space remains the critical differentiator for enterprises scaling data-intensive workloads.
The Role of EF-Series Storage in Modern AI and HPC Infrastructure
EF50 and EF80 Architecture for Sovereign AI Clouds
Dedicated block storage defines the NetApp EF-Series, stripping file protocol overhead to maximize GPU feed rates. NetApp announced the EF50 and EF80 models on 17 Mar 2026 at NVIDIA GTC 2026. These systems target sovereign AI clouds requiring strict data residency alongside extreme performance. Read throughput reaches 110 Gb/s, a figure critical for preventing tensor core starvation during large model training. Global AI infrastructure spending hit $98 billion in 2026, yet hyperscale providers control over 60% of this capital, forcing national initiatives to seek efficient, dense alternatives. The EF-Series addresses this gap by offering 1.5PB capacity in a 2U footprint, enabling localized clusters to compete with distributed hyperscale architectures.
Accelerating AI Data Pipelines with 110 GBps Read Throughput
Temporary, high-speed storage layers feeding GPU clusters during model training cycles define scratch space in HPC. The EF50 and EF80 models sustain 110 GBps read throughput to prevent tensor core starvation. Speed eliminates the latency bottleneck where fast compute waits on slow disk I/O. Write operations reach 55 GBps, allowing rapid checkpointing of massive neural network states. NetApp positions this hardware to handle every phase from raw data ingestion to GenAI model output. Traditional file protocols introduce overhead that stifles block-only workloads requiring pure speed. Removing ONTAP layers reduces CPU cycles spent on metadata management rather than data transfer. The result is a dedicated pipeline optimized for throughput rather than general-purpose flexibility.
Dell PowerStore holds a 16.8% mindshare in all-flash arrays, yet EF-Series targets specific block performance niches. Scaling beyond single-rack limits often forces costly architecture changes with competing vendors. NetApp systems expand to 1.8 PB within 2U building blocks to maintain density. Operators must weigh the cost of specialized block arrays against the complexity of hybrid file systems. Low-latency storage definitions vary, but sub-millisecond response times remain the non-negotiable baseline for inferencing. Isolating training datasets on dedicated block volumes guarantees consistent feed rates. This disparity highlights a market preference for multi-protocol flexibility over the EF-Series block-only specialization.
Inside EF50 and EF80 Architecture for Maximum Throughput and Density
Block-Only Architecture Eliminating ONTAP Overhead
Previous generations delivered approximately 31.4 GBps of read throughput, a ceiling broken by stripping ONTAP overhead entirely. The EF50 and EF80 enforce a strict block-only design that removes multi-protocol processing and NAND flash translation layers. This architectural choice dedicates all controller CPU cycles to raw I/O movement rather than file system logic or data tiering. HPC simulations frequently stall when storage latency exceeds compute cycle times, causing expensive GPU clusters to idle. The block-only storage path eliminates this variance by bypassing the software stacks required for mixed-workload flexibility. Operators gain deterministic latency at the cost of универсальность; these arrays cannot serve NFS or SMB shares without external gateways.
Coupling EF80 with Lustre and BeeGFS for GPU Utilization
Lustre and BeeGFS configurations fail to saturate GPU clusters when backend block devices cannot sustain parallel stripe widths during checkpointing. The EF80 architecture eliminates this bottleneck by dedicating controller cycles exclusively to raw I/O movement rather than file logic. Operators configure these systems as high-performance scratch space, ensuring tensor cores receive data streams fast enough to prevent idle cycles. Integration requires mapping specific Object Storage Targets (OSTs) to physical spindles to maximize aggregate bandwidth. A single misaligned stripe count can reduce proven throughput by forcing serial access patterns on parallel hardware.
Validating 1.8 PB Capacity Within 37 kW Power Envelope
Rack validation begins by confirming modular 2U building blocks aggregate to 1.8 PB raw capacity without exceeding thermal limits. Operators must calculate power density against the strict <37 kW per rack ceiling to prevent circuit breaker trips during peak I/O bursts. This constraint forces a trade-off between maximum drive population and headroom for cooling redundancy in high-density rows.
| Capacity Aggregation | 1.8 PB total | Incomplete shelf population |
|---|---|---|
| Power Draw | <37 kW envelope | PDU overload at full spin-up |
| Throughput Verification | 2.35 TB/s read | GPU starvation during training |
Achieving 2.35 TB/s read throughput within this power budget requires disabling non-necessary controller services. The EF50 and EF80 deliver this bandwidth by stripping software layers that consume CPU cycles unrelated to block transfer. Facilities planning must account for the physical footprint reduction, as fewer racks are needed to reach petabyte scales compared to legacy architectures. However, concentrating this much storage in a single power domain increases blast radius risks during electrical faults. Deploying redundant power feeds per rack mitigates single-point failures in these dense configurations.
Strategic Advantages of NetApp EF-Series Over Competitor Storage Arrays
Defining the Niche: EF-Series Block-Only Architecture for AI Workloads
Sandeep Singh identifies data as the underpinning component for performance-hungry AI workloads requiring speed without added complexity. The EF-Series enforces a block-only design that strips away ONTAP. This architectural choice dedicates controller cycles strictly to raw I/O movement rather than file system logic or NAND flash translation. General-purpose arrays often reserve CPU resources for NAS functions if enabled, introducing latency variance absent in this specialized path. Operators implementing secure block storage must recognize that this niche sacrifices file-level flexibility for deterministic throughput.
| Architecture Feature | EF-Series Specialization | General-Purpose Array |
|---|---|---|
| Protocol Support | Block only | Multi-protocol (NAS/SAN) |
| CPU Allocation | Entirely I/O movement | Shared with file processes |
| Flash Management | No translation layer | NAND flash tiering |
| Primary Use Case | GPU scratch space | Mixed enterprise workloads |
Parallel file systems like Lustre require backend devices capable of sustaining wide stripe widths during checkpointing to prevent GPU starvation. The removal of file logic allows the hardware to act as a high-speed foundation for these distributed layers. However, this specialized role limits viability in environments demanding mixed protocol access or complex data management features. Enterprises must deploy parallel file systems separately when metadata handling or POSIX compliance becomes necessary. The trade-off yields maximum feed rates for training clusters but demands external software for broader data services.
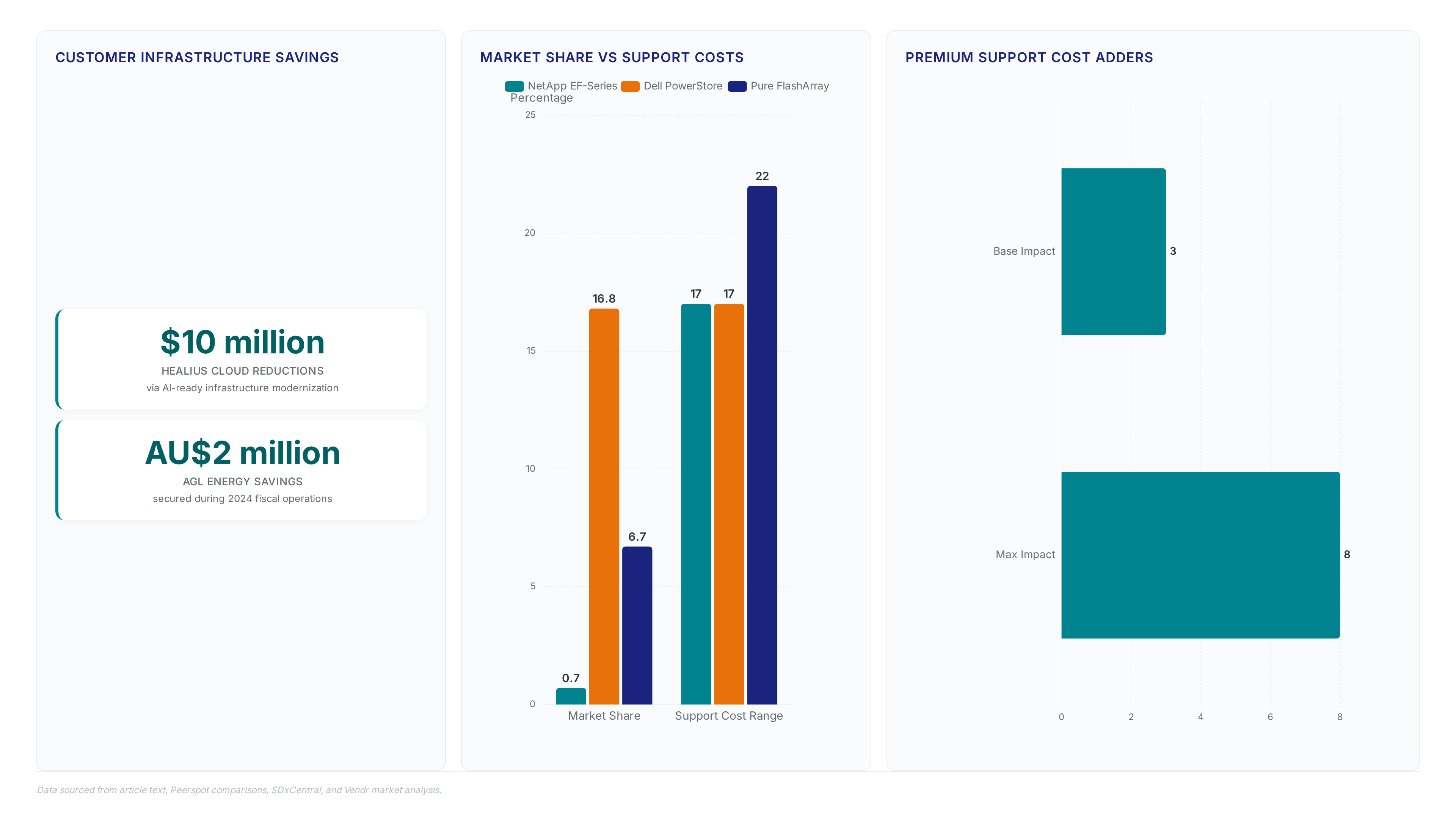
Real-World Cost Savings: Healius, AGL Energy, and Atlassian Case Studies
Healius recorded $10 million in cloud cost reductions by modernizing operations with AI-ready infrastructure. AGL Energy secured AU$2 million in infrastructure savings during 2024 fiscal operations. These figures validate total cost of ownership models against competitors holding larger market mindshare. The financial application of EF-Series upgrades depends on eliminating idle GPU cycles rather than raw capacity alone. Users report pricing structures appear costlier initially compared to Dell equivalents due to modular licensing requirements. Pure Storage operates on a subscription-like model that may hide advanced feature costs over time.
Deploying EF-Series Systems for Scalable AI Workloads and Parallel File Integration
EF50 and EF80 as High-Performance Scratch Space for Alongside File Systems
Lustre and BeeGFS metadata servers require block-only storage to bypass file protocol translation layers entirely. The EF50 and EF80 models strip ONTAP. This architectural choice eliminates the CPU reservation seen in general-purpose arrays where NAS functions introduce latency variance. Operators coupling these systems with simultaneous file systems gain a direct path that keeps GPUs fully utilized during HPC simulations.
The removal of NAND flash translation further stabilizes write patterns for temporary scratch data. A tangible consequence involves the elimination of garbage collection pauses that typically alter bursty AI training loads. However, this specialization limits the system to block protocols, forcing operators to manage file namespaces externally via compute nodes.
| Integration Point | Benefit | Constraint |
|---|---|---|
| Metadata Server | Sub-millisecond latency | No native file sharing |
| Data Stripe | Linear throughput scaling | External namespace management |
| GPU Cluster | Zero idle cycles | Strict block-only access |
Deployment requires configuring the storage array explicitly as a raw device target for the parallel file system layer. Isolating scratch volumes from persistent datasets maximizes the performance advantage of this stripped-down design.
Scaling Sovereign AI Clouds with 100 Million IOPS at Rack Scale
Rack-scale deployments achieve over 100 million IOPS by stacking modular 2U building blocks within a strict 37 kW power envelope. Operators targeting sovereign AI clouds must configure EF50 or EF80 units as dedicated scratch space for Lustre or BeeGFS metadata servers to eliminate protocol translation latency. This block-only architecture bypasses ONTAP overhead, ensuring controller cycles focus exclusively on raw I/O movement rather than file system logic. The cost of this specialization is visible in capacity planning; while individual arrays scale to 1.8 PB, exceeding per-rack power limits forces horizontal expansion that increases cabling complexity.
| Deployment Phase | Configuration Action | Performance Target |
|---|---|---|
| Initial Build | Pair 2U units with GPU clusters | 5 million IOPS per array |
| Parallel Integration | Mount as backend for BeeGFS | Sub-millisecond metadata access |
| Rack Scaling | Add nodes until <37 kW limit | 2.35 TB/s aggregate throughput |
Neocloud providers face a tension between density and thermal headroom when pushing for maximum rack scale throughput. Aggressive packing maximizes IOPS per square foot but reduces margin for burst cooling during AI training spikes. Staging expansion in four-unit increments validates thermal dissipation before committing full rack capacity. This measured approach prevents throttling events that would otherwise negate the benefits of NVMe over Fibre Channel backends.
Application: Validating 1.8 PB Raw Capacity Deployment Within Modular 2U Constraints
Validating the 1.8 PB raw capacity target requires confirming that modular 2U building blocks fit within strict 37 kW rack power envelopes before integrating Lustre metadata servers. Operators must verify drive density plans against physical constraints, as adding sets of higher-capacity drives allows footprint growth without service disruption or new power provisioning.
| Validation Step | Technical Constraint | Risk if Ignored |
|---|---|---|
| Power Envelope Check | Max 37 kW per rack | Thermal throttling of NVMe drives |
| Drive Mix Verification | QLC vs NVMe ratio | Unbalanced I/O latency for scratch space |
| Cabling Density | 12Gb backend ports | Blocked airflow in high-density stacks |
The EF50 and EF80 models deliver block-only performance, yet over-provisioning capacity in a single rack creates thermal hotspots that degrade sustained throughput. Planners often overlook that scaling density requires staggered drive installation to manage heat dissipation rather than immediate full-population. Pre-deployment thermal modeling is essential for any configuration exceeding 80% drive slot utilization. Failure to align physical power limits with logical capacity goals forces costly rack redistribution after hardware arrival.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in designing scalable data infrastructure for AI and machine learning workloads. His deep expertise in S3-compatible object storage and Kubernetes persistent storage makes him uniquely qualified to analyze the evolution of high-performance systems like the new NetApp EF-Series. In his daily role, Chen architects solutions that bridge the gap between raw storage performance and the demanding throughput required by AI training clusters and HPC applications. By evaluating how on-premises innovations from companies like NetApp integrate with cloud-native environments, he helps enterprises optimize their data pipelines without vendor lock-in. His background in DevOps and previous experience with substantial cloud storage providers allow him to critically assess how next-generation hardware supports the massive scale needed for sovereign AI clouds and modern transactional databases.
Conclusion
Scaling EF-Series density beyond 80% slot utilization invites thermal throttling that silently erodes the 110 GB/s throughput advantage, turning high-performance assets into bottlenecks during sustained tensor operations. As AI workloads approach 50% of total data center growth by 2030, the operational penalty shifts from capital expenditure to continuous cooling overhead, where unchecked heat dissipation forces expensive rack redistribution rather than smooth expansion. Organizations must stop treating storage density as a purely logical exercise and recognize that physical power envelopes dictate actual sustained performance.
Deploy EF-Series arrays in staggered four-unit increments only after validating thermal models against your specific 37 kW rack limits, delaying full population until baseline dissipation rates are confirmed. This disciplined pacing prevents the immediate degradation of NVMe endurance that occurs when burst cooling fails during training spikes. Do not commit to full-rack saturation before Q3 2026, allowing time to refine airflow dynamics alongside capacity growth.
Start by auditing current rack power headroom against proposed drive mix ratios this week, specifically calculating the thermal impact of replacing QLC tiers with high-density NVMe before placing any new hardware orders. This immediate verification ensures your infrastructure supports sustained AI velocity rather than collapsing into intermittent latency under load.
Frequently Asked Questions
Users describe EF-Series as costlier than Dell equivalents due to separate license purchases. Dell PowerStore currently holds a 16.8% mindshare in the all-flash array market, signaling strong competitor adoption despite lower raw throughput capabilities.
Annual support contracts are effectively mandatory and typically range from 17% to 22% of the hardware list price. Premium tiers add extra percentage points, but multi-year commitments often unlock better hardware discounting for customers.
No, the block-only architecture eliminates multiprotocol flexibility, requiring separate parallel file systems like Lustre. This specialization removes ONTAP processing latency but means teams must deploy metadata servers for mixed-workload environments.
The EF-Series addresses density gaps by offering 1.5PB capacity in a mere 2U footprint. This allows localized clusters to compete with distributed hyperscale architectures while maintaining sub-millisecond response times for AI workloads.
Write operations reach 55 GBps, allowing rapid checkpointing of massive neural network states during training. This speed complements the 110 GBps read throughput to prevent tensor core starvation in GPU clusters.
