Tokyo region cuts AI latency for S3 workloads
IDrive e2's new Tokyo region targets the millions of customers already backing up over 1 exabyte of data globally.
Physical proximity is the only reliable way to slash API latency for AI workloads in East Asia. Distributed nodes satisfy data sovereignty mandates, but the real win comes from routing traffic through local endpoints. Small and medium businesses are abandoning legacy providers because the financial reality of Asian operations no longer favors hyperscalers. IDrive Inc. 's expansion to 14 global locations accelerates this shift. By anchoring data in Tokyo, developers gain enhanced performance without managing private hardware. This move secures service reliability and geo-redundancy in a market where milliseconds dictate competitive advantage.
The Role of S3-Compatible Object Storage in Global Cloud Infrastructure
IDrive e2 S3-Compatible Storage and Geo-Redundancy Set
IDrive e2 functions as an S3-compatible object storage service using standard APIs for smooth tool integration. The term S3-compatible indicates full interoperability with Amazon S3 protocols, enabling existing applications to run without code refactoring. This design supports multipart uploads and versioning across a global network. API Compatibility stands as a key differentiator since rivals often falter with filesystem mounting reliability. The recent addition of a Tokyo region on April 24, 2026, brings this capability to East Asia for lower latency. Geo-redundancy here means spreading data copies across separate physical sites to stop single-point failures. The platform achieves 99.999999999% durability through triple replication of every stored object. Parent company IDrive Inc. Now secures data for over 5 million customers while managing more than 1 exabyte of collective backup volume.
Scale brings operational tension. Local regions boost access speed. Keeping consistency across distributed nodes demands careful bucket policy setup. Operators must balance the latency gains from the new Japan endpoint against the complexity of multi-region sync logic.
Optimizing AI Workloads with Tokyo Region Endpoints
The April 24, 2026 launch creates a dedicated Tokyo data center to cut latency for Asian AI workloads. Keeping vector databases local shrinks round-trip time for model inference versus trans-Pacific hops. Proximity matters because training pipelines stall when network I/O bottlenecks GPU utilization. Teams gain performance and isolation via region-specific endpoints instead of global access keys. Unique credentials per location stop cross-region credential leakage during auto-scaling events. The architecture enforces strict data sovereignty boundaries needed for local compliance rules.
| Metric | IDrive e2 Tokyo | Hyperscaler Avg |
|---|---|---|
| Storage Cost | $4/TB/month | $23/TB |
| Unit Price | a minimal rate per GB | ~a standard rate per GB |
| Egress Fees | $0 | Variable |
Affordable object storage options at $4/TB/month allow cost-effective checkpointing for large language models. Staff can keep more historical model versions without blowing budgets on premium tiers. Moving existing datasets needs app config updates to hit the new endpoint directly. Skipping traffic redirection kills latency benefits completely. Security isolation gets improved when access keys stay scoped to the Tokyo region only. Compromised keys in other zones cannot touch Japanese production buckets. Segmentation limits blast radius during security incidents involving automated scripts. The cost involves handling multiple key sets across various geographic zones. Admins must update secret rotation policies for distinct regional credentials.
How Local Data Proximity Optimizes API Performance and Latency
Physical Network Hops and S3 API Latency Reduction Mechanics
Storing objects in the April 24, 2026 Tokyo region physically truncates the AS path for East Asian clients, eliminating trans-Pacific circuit latency. Traffic routed through distant US endpoints traverses multiple undersea cables, adding propagation delay to every S3 API call. Localizing storage reduces the network hop count, directly lowering round-trip time for metadata operations like `HEAD` and `LIST`. This mechanical shift prevents GPU starvation during AI training pipelines that stall on slow object retrieval. Operators using self-hosted integration tools note that while raw throughput varies, proximity consistently improves request serialization speed compared to intercontinental paths.
Minimizing hops introduces a dependency on local peering quality rather than global backbone redundancy. A single regional outage affects all local clients unless applications implement cross-region failover logic. The cost is reduced geographic diversity for maximum speed.
| Failure Domain | Latency | Path |
|---|---|---|
| TransPacific | High 100ms | Global Backbone |
| Local Tokyo | Low <10ms | Regional Peering |
Configuring client SDKs to prioritize the nearest region-specific endpoint dynamically balances performance gains against the risk of localized network congestion.
Mechanics: Deploying AI Workloads on Tokyo Endpoints for Local Speed
Selecting local storage for Asian AI clusters eliminates trans-Pacific latency by anchoring S3 API calls to the new Tokyo region. Operators fix slow data access in Asia by routing training data through this dedicated endpoint rather than distant US buckets. Truncating the physical network path prevents GPU starvation during high-throughput model ingestion. Raghu Kulkarni notes that managing massive datasets with local speed and cloud economics addresses the surge in regional data generation. This approach supports object storage solutions that handle large ML checkpoints without the 5 GB caps found on competitor platforms.
Data sovereignty requirements force this architectural shift, as evidenced by recent global expansion trends in technology sectors. Operational complexity increases because teams must reconfigure application manifests to target region-specific credentials instead of global defaults. Isolating access keys per location prevents cross-region credential leakage during automated scaling events. Validate endpoint latency before migrating petabyte-scale archives to ensure pipeline stability.
Validating Compliance and Security Isolation in Japan
Regulatory adherence in Japan demands strict processing of personal data within regional boundaries using specific cryptographic controls. Storage architectures must enforce isolation through unique credentials rather than relying on global access patterns. Unlike systems using worldwide keys, this platform assigns region-specific endpoints to prevent cross-border credential leakage during automated workflows.
- Enable server-side encryption for all objects at rest to meet data protection mandates.
- Enforce multi-factor authentication (MFA) on all console and API access points.
- Activate object-level immutability to guard against unauthorized modification or deletion.
- Audit bucket policies to ensure no public read permissions exist on sensitive datasets.
The following table compares security isolation mechanisms between global and regional configurations:
| Feature | Global Access Model | Tokyo Regional Model |
|---|---|---|
| Credential Scope | Worldwide validity | Location-bound validity |
| Latency Impact | High for Asian clients | Minimal for local users |
| Compliance Risk | Elevated for sovereign data | Aligned with local laws |
| Attack Surface | Broad exposure | Reduced perimeter |
Demand for ransomware-resilient designs drives the necessity for immutable storage tiers that lock data against encryption attacks. Operators skipping MFA enforcement on service accounts create a single point of failure despite regional data placement. Keeping data in East Asia satisfies sovereignty requirements that forbid trans-Pacific data transit for certain government contracts. Incorrect configuration of these isolation features negates the compliance advantages of the physical location.
IDrive e2 Versus AWS S3 for Cost-Effective Asian Operations
Comparison: IDrive e2 Flat-Rate Pricing Versus AWS S3 Tiered Cost Structure
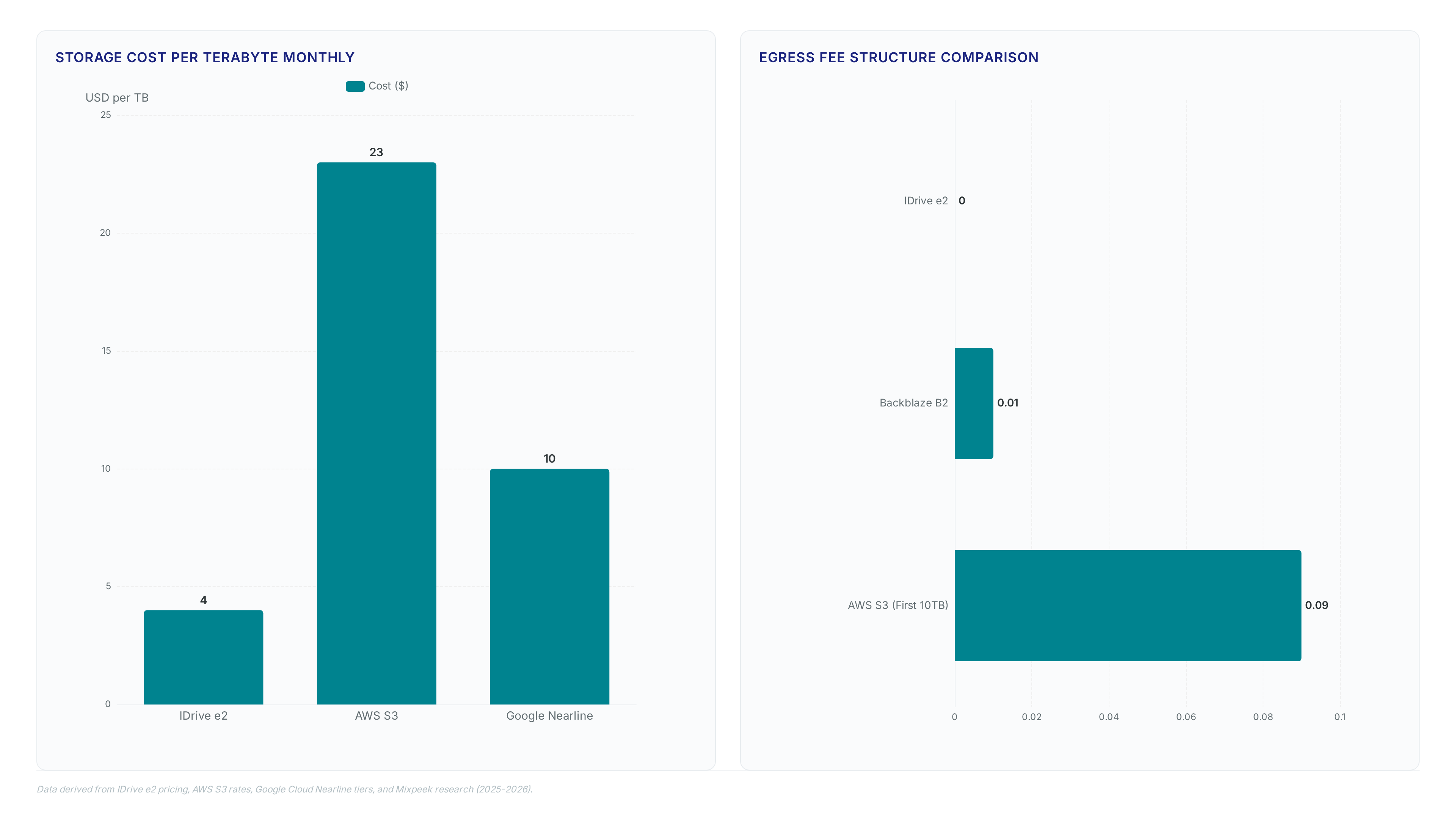
IDrive e2 charges a flat $4 per terabyte monthly, eliminating the variable egress fees that inflate AWS bills. AWS layers additional charges for API calls and data retrieval whereas the competitor offers free downloads up to three times the stored volume. High-retrieval workflows avoid the standard egress rates typical of cloud providers because of this structural difference. Operators must also consider retention policies since Wasabi enforces a strict 90-day minimum. IDrive e2 imposes no such retention constraints on object deletion. A flat-rate model stabilizes operational expenditure by decoupling storage costs from retrieval frequency. Organizations running AI training loops or frequent backup restores benefit most from this predictability. Audit actual retrieval patterns before committing to hyperscaler tiers.
Deploying AI Workloads in Tokyo to Eliminate Cross-Border Egress Fees
Training clusters in Tokyo avoid trans-Pacific latency by anchoring S3 API calls to the local Tokyo region. Operators feeding GPU farms require immediate data access yet pulling terabytes from US endpoints introduces measurable propagation delay. Localizing storage truncates the physical network path to prevent pipeline stalls during model ingestion. This architectural shift eliminates the standard egress rates that penalize high-volume retrieval on competitor platforms. The cost advantage becomes stark when comparing flat-rate billing against tiered hyperscaler models. The pay-as-you-go option at a modest fee/TB/month removes minimum retention penalties found elsewhere. A $6/month minimum charge may outweigh benefits for negligible datasets under 1 TB.
Deploying the Tokyo Region for Multi-Region Data Strategies
Implementation: Configuring S3 API Endpoints for the Tokyo Region

Operators replace global access patterns with the specific Tokyo endpoint URL to activate low-latency data paths. This platform assigns region-specific endpoints that isolate traffic within Japan instead of relying on worldwide keys. Security isolation requires generating unique access keys bound strictly to this location rather than reusing credentials from other zones.
- Update the application configuration file to point the `endpoint_url` parameter to the Tokyo address.
- Generate new access credentials via the dashboard, ensuring the region selector matches Tokyo.
- Validate connectivity by executing a `ListBuckets` command against the new endpoint.
Such a mechanical shift prevents cross-border credential leakage during automated workflows. The official launch on April 24, 2026, established this first presence in the country, enabling compliant data residency. Ignoring this segregation risks violating local sovereignty mandates despite using compatible APIs. Surges in data generation across Asia necessitate such local compliance needs to avoid regulatory penalties. Audit all bucket policies to confirm they reference the correct regional host before migrating production traffic.
Migrating Data to Tokyo Using rclone and Cyberduck
Direct the `endpoint_url` parameter to the specific Tokyo address to truncate cross-Pacific latency during bulk transfers. Operators initiate migration by configuring rclone with the region-specific endpoint, bypassing global routing bottlenecks. The command `rclone config` creates a new remote where `endpoint` matches the Tokyo node rather than a generic gateway. This setup uses the unlimited bandwidth provision for cloud-to-cloud moves, eliminating ingress throttling common in hyperscaler environments. Cyberduck users must manually select the custom S3 profile and input the Tokyo URI to activate local path optimization.
Data integrity checks run locally before transmission, preventing corrupt object propagation across the Global Footprint. Enabling object versioning retains up to 30 previous file iterations, providing a rollback buffer against accidental overwrites during the shift. The cost involves managing distinct credential sets for each region, as security isolation prevents cross-region key reuse. Script these configurations to standardize deployment across distributed teams. Expanding to Japan addresses data sovereignty requirements that mandate local processing for Asian customer records. Future expansions into India and South Korea will require similar endpoint updates to maintain compliance boundaries. Latency reductions are immediate. Operators must verify application logic handles region-specific DNS resolution correctly. Failure to update the endpoint string results in traffic defaulting to US containers, negating the performance benefit entirely. This configuration supports the Google Classroom Backup pricing model used by educational institutions for localized archival. Validate egress limits allow downloads up to three times the stored volume annually without triggering overage charges. The table below contrasts the pay-as-you-go rate against annual commitments for budget forecasting.
Failure to bind the region-specific endpoint forces traffic through global gateways, negating the latency benefits promised in the official launch announcement. Audit these parameters weekly to maintain cost predictability.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible storage and AI/ML data infrastructure. His deep technical background makes him uniquely qualified to analyze the strategic impact of new storage regions like Tokyo. Having previously engineered solutions at Wasabi Technologies, Marcus understands the critical latency challenges global enterprises face when deploying AI workloads across borders. His daily work involves optimizing Kubernetes persistent storage and ensuring low-latency data access for international clients, directly mirroring the benefits IDrive e2 aims to provide with this expansion. While writing about IDrive Inc. 's growth, Marcus uses his experience at Rabata. Io, a provider dedicated to democratizing enterprise-grade object storage without vendor lock-in. This perspective allows him to objectively evaluate how new geographic endpoints enhance performance for cost-conscious enterprises and startups navigating the complexities of modern data pipelines in the Asia-Pacific market.
Conclusion
Scaling storage across the Pacific introduces a hidden operational tax: credential fragmentation multiplies administrative overhead as teams manage isolated security contexts for each zone. While triple replication guarantees durability, it locks capital into static assets that cannot dynamically shift during regional outages without manual intervention. The real breakage point occurs when application logic assumes uniform latency, causing timeouts during trans-Pacific failover events that local benchmarks never reveal. Organizations must treat region selection as a temporary tactical advantage rather than a permanent architectural fix, knowing that data gravity will eventually make migration prohibitively expensive as volumes swell beyond massive scales.
Deploy a multi-region strategy only if your recovery time objective demands sub-100ms access for Asian users; otherwise, consolidate workloads to a single hub to minimize management friction. Commit to this architecture for a maximum of 18 months before re-evaluating against emerging edge computing alternatives that decouple compute from storage entirely. Start by auditing your current DNS resolution policies this week to ensure traffic explicitly targets the Tokyo endpoint rather than defaulting to US gateways, verifying that no legacy configurations silently route Asian user data across the ocean.
Frequently Asked Questions
IDrive e2 charges $4 per TB monthly, significantly less than competitors. Amazon S3 Standard costs approximately $23 per TB, making it roughly 5.75 times more expensive than the affordable IDrive e2 rate.
The platform ensures extreme data safety through triple replication of every stored object. This architecture achieves 99.999999999% durability, protecting over 1 exabyte of data for more than 5 million global customers.
Users pay $0 for egress fees, allowing free data retrieval up to three times stored volume. This contrasts sharply with other providers that charge variable rates for outbound traffic and API calls.
The service offers a pay-as-you-go option starting at $5 per TB monthly. Alternatively, users can choose an annual plan priced at $49.50 per TB to secure consistent budgeting for operations.
IDrive e2 lists a unit price of $0.004 per GB for hot storage access. Hyperscaler averages sit near $0.023 per GB, confirming the significant cost advantage for Asian AI workloads.
