Data gravity fixes: Stop moving datasets today
With 42% of leaders prioritizing workflow optimization over new use cases in 2026, NVIDIA's State of AI Report confirms that fixing data gravity is now the primary spend. Enterprises currently waste millions moving data to the cloud, a flaw MinIO addresses by embedding the Delta Sharing protocol directly into its object store. Unlike previous methods requiring complex pipelines and duplicate datasets, this architecture allows organizations to govern and share live tables where they physically reside. The solution uses Iceberg V3 catalogs to unify structured and unstructured data without architectural sprawl or operational overhead.
Readers will discover how federated analytics solves the data sovereignty crisis while cutting latency for real-time intelligence. We dissect the specific AIStor architecture that enables this secure hybrid access without data movement. Finally, a technical walkthrough demonstrates connecting Databricks to on-prem MinIO storage, proving that enterprises no longer need to relocate massive datasets to analyze them effectively.
The Role of Federated Analytics in Solving Data Gravity for Enterprise AI
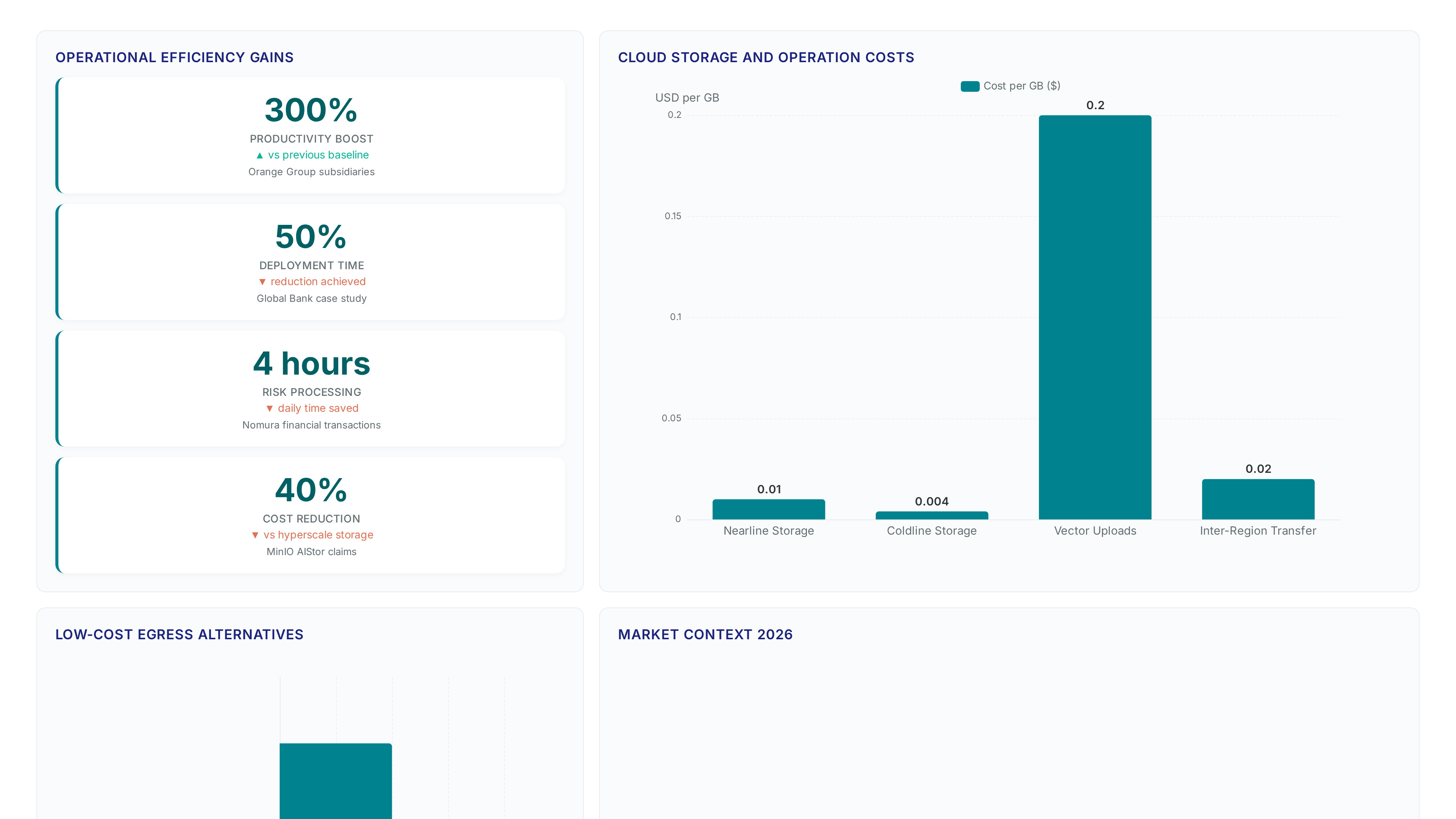
Data gravity pins massive datasets to their current location because moving them costs too much. Public cloud vector storage prices hitting $0.06 per GB per month on AWS S3 Vectors create immediate budget pressure for AI workloads needing high-performance indexing. Inter-region transfer fees at $0.02 per GB make this burden worse. Traditional migration strategies become financially impossible for petabyte-scale archives under these conditions. Federated analytics resolves the issue by letting compute engines query data where it sits instead of copying it. This approach removes the need for expensive vector uploads that trigger extra PUT operation charges alongside standard storage billing.
AIStor Table Sharing embeds the Delta Sharing 1.0 protocol directly into the object store to enable zero-copy data access. This architecture removes the separate sharing server layer usually needed for cross-platform federation. Operators adopt this model when complex pipelines and duplicate datasets create unacceptable latency or governance risk. The system uses Policy-Based Access Control compatible with AWS IAM syntax to govern read-only table exposure without external metadata services. Eliminating data movement cuts deployment time by 50% compared to traditional ETL-based integration patterns. Storage costs drop up to 40% by avoiding hyperscaler-controlled table service fees while maintaining sub-millisecond metadata operations. Network stability between on-premises storage and cloud compute acts as a hard limit. Intermittent connectivity breaks the live table link rather than buffering results. The constraint shifts operational burden from data engineering teams managing sync jobs to network teams ensuring consistent low-latency paths. Zero-copy mechanisms fundamentally alter the cost structure of hybrid AI by removing egress charges entirely. Mission and Vision recommends this pattern for enterprises retaining petabyte-scale archives due to regulatory constraints.
Historical Data Pipelines Versus Native Delta Sharing Access
Legacy architectures mandate complex ETL pipelines and duplicate datasets to bridge on-premises storage with cloud analytics. Traditional federation requires moving data into separate governance layers, introducing latency and operational risk. Native integration contrasts sharply with this old approach because the storage system itself hosts the sharing protocol. Operators embedding Delta Sharing directly into the object store eliminate the external sharing server entirely. Data moves zero-copy, allowing compute engines to query live tables in place without replication. The shift to open formats resolves the conflict between data sovereignty and analytical speed. Relying on Policy-Based Access Control Fine-grained control over read-only table exposure replaces broad network-level trust, demanding stricter policy definition upfront. The cost benefit remains significant even without specific new metrics since removing duplicate datasets eliminates both storage bloat and transfer fees. Enterprises adopting this model avoid the overhead of maintaining parallel metadata catalogs like AWS Glue or Hive Metastore. Mission and Vision recommends validating IAM syntax compatibility before decommissioning legacy export jobs.
Inside AIStor Architecture: How Delta Sharing and Iceberg V3 Enable Secure Hybrid Access
AIStor Tables as the Iceberg V3-Native Foundation for Hybrid Data
AIStor Tables unifies MinIO object storage with a native Apache Iceberg V3 Catalog to serve structured data without external metastore dependencies. This architecture embeds table metadata, REST APIs, and sharing standards directly into the storage binary, eliminating the need for separate services like Hive Metastore or AWS Glue. Operators gain atomic multi-table transactions and schema evolution capabilities within a single control plane. The system executes zero-copy sharing by storing pointers to unstructured assets inside structured tables rather than replicating datasets. This zero-copy mechanism ensures Databricks computes access live on-premises files instantly while preserving data sovereignty. Unlike public cloud-native services, the deployment model targets sovereign and hybrid environments where data cannot leave the facility.
| Component | Legacy Approach | AIStor Tables |
|---|---|---|
| Catalog Service | External (Glue/Hive) | Native REST API |
| Data Movement | Replication Required | Zero-Copy Pointers |
| Protocol Stack | Separate Sharing Server | Embedded Delta Sharing |
Recoverable Write-Ahead Log entries guarantee consistency during concurrent writes across distributed nodes. The trade-off involves strict adherence to open formats; proprietary extensions break compatibility with the native Delta Sharing integration. Mission and Vision recommends validating schema evolution paths before production rollout to prevent locking operators into rigid data structures. MinIO announced AIStor Table Sharing on 9 Mar 2026 as an industry-first feature allowing enterprises to securely share on-premises data directly with the Databricks platform. This integration enables instant access to fresh data for real-time analytics and intelligence without moving bytes across network boundaries. The architecture embeds the Delta Sharing 0 protocol directly into the storage layer, eliminating the need for separate sharing servers or export layers. Operators define table shares via REST API, where pointers to unstructured assets reside within structured Iceberg tables for direct access. Min.
| Legacy Pipeline | Native Table Sharing |
|---|---|
| Requires duplicate datasets | Maintains single source of truth |
| Introduces replication latency | Provides instant data freshness |
| Demands external governance | Enforces Policy-Based Access Control locally |
The cost is operational complexity in managing read-only exposure at the storage layer rather than the application tier. Unlike traditional ETL flows that duplicate metadata, this approach relies on atomic multi-table transactions to maintain consistency during concurrent reads. Enterprises fix data access delays in hybrid AI by removing the physical movement requirement entirely. Unifying hybrid data for AI becomes a configuration task rather than a data migration project. The limitation remains that all participating nodes must trust the underlying Iceberg V3 catalog integrity implicitly.
Deployment Requirements Following the April 25, 2026 Repository Archival
Adoption now mandates migration to commercial AIStor tiers after MinIO archived its open-source community edition repository on April 25, 2026. Operators must upgrade from the discontinued codebase to AIStor Free or Enterprise tiers to access the native Delta Sharing 1.0 protocol required for federated analytics. This shift eliminates the separate sharing server layer but introduces a licensing dependency absent in previous iterations.
- Validate that storage nodes run the post-archival AIStor binary supporting Iceberg V3 catalogs.
- Configure Policy-Centered Access Control rules to govern read-only table exposure without external metadata services.
- Align client connectors with the embedded sharing standard to enable zero-copy mechanism operations.
| Requirement | Pre-Archival State | Post-Archival Mandate |
|---|---|---|
| Code Source | Community Git Repository | Commercial AIStor Tiers |
| Sharing Layer | External Server Optional | Embedded Storage Protocol |
| Governance | Separate Policy Engine | Native PBAC Integration |
| Update Path | Manual Pull Requests | Licensed Entitlements |
Data governance complexities increase if operators attempt to bridge legacy open-source installs with modern Databricks workloads. The architectural tension lies between maintaining historical infrastructure investments and achieving the low-latency access promised by native integration. Failure to align versions results in protocol mismatches that block cross-platform queries entirely. Mission and Vision recommends immediate binary replacement to avoid fragmentation in hybrid data environments.
Step-by-Step Implementation Guide for Connecting Databricks to On-Prem MinIO Data
Defining the AIStor Table Sharing Workflow for On-Prem Data

MinIO announced AIStor Table Sharing on 9 Mar 2026 to embed the Delta Sharing protocol directly into the storage layer. This architecture removes the external sharing server requirement found in legacy federation models. Operators define shares by storing pointers to unstructured assets within structured Iceberg tables rather than replicating datasets. The workflow relies on a zero-copy mechanism that maintains data locality while granting Databricks compute engines read-only access.
- Upgrade nodes to the commercial AIStor binary following the April 25, 2026 repository archival.
- Configure Policy-Focused Access Control rules to govern table visibility via the REST API.
- Publish the share endpoint to the Databricks platform using the native Delta Sharing 1.0 specification.
Embedding the protocol creates a single point of failure if the storage cluster loses connectivity since no cached copy exists on the consumer side. This tight coupling reduces operational overhead but increases dependency on the on-premises network uptime. Mission and Vision recommends validating WAN stability before enabling real-time shares for critical analytics workloads.
Executing Real-Time Analytics Connections Between Databricks and MinIO
Operators establish live Databricks sessions by configuring the REST API to expose Iceberg V3 catalogs without data movement.
- Define Policy-Oriented Access Control rules restricting external compute to read-only operations at the storage layer.
- Publish table pointers via the embedded Delta Sharing endpoint to eliminate separate sharing servers.
- Mount the remote share in Databricks using the standard `delta-sharing` connector string.
Min. Financial firms face acute budget pressure, with average spending on AI-native apps rising 108% year-over-year in 2026. Eliminating replication pipelines directly addresses this cost surge by removing egress fees and duplicate storage requirements. The security model enforces access controls at the object store level rather than relying on external IAM policies that might permit data exfiltration. Wide-area links between on-prem storage and cloud compute can throttle query performance compared to co-located datasets. Mission and Vision recommend validating bandwidth capacity before scaling federated queries across geographic regions.
Pre-Deployment Validation Checklist for Iceberg V3 and WAL Configuration
Verify atomic multi-table transactions succeed before exposing catalogs to external compute engines.
- Confirm the storage binary supports Iceberg V3
- Test Write-Ahead Log recovery by simulating node failure during an active commit.
- Validate that zero-copy data sharing prevents replication traffic during Databricks queries.
| Validation Target | Success Criteria | Failure Mode |
|---|---|---|
| Transaction Atomicity | All tables commit or roll back together | Partial writes corrupt state |
| WAL Durability | Logs replay fully after crash | Metadata drift occurs |
| Share Governance | Read-only access enforced at source | Unauthorized write attempts |
Skipping WAL verification risks metadata divergence that breaks time travel features. Operators often assume storage durability equals transaction safety, yet the recoverable Write-Ahead Log operates independently of disk redundancy. Mission and Vision recommends failing the deployment if log replay exceeds thirty seconds under load.
Measurable ROI from Hybrid Data Architectures in Financial and Telecom Sectors
Hybrid Data Lakehouse Economics and Market Scale
Firms retain on-premises assets for sovereignty as the data integration market reaches a substantial valuation in 2026. Large enterprises generate massive volumes of local data for regulatory compliance while seeking cloud analytics. This tension drives adoption of Three-Tier Hybrid Models that balance edge latency with elastic compute. Organizations avoid replicating datasets by applying AIStor Table Sharing directly to existing storage silos. Moving exabytes of historical records incurs prohibitive egress fees and latency penalties. MinIO serves this demand with high efficiency, generating an estimated substantial revenue per employee. Such operational use allows vendors to support massive scale without proportional headcount growth. Financial institutions like Nomura demonstrate the viability of this approach by cutting risk processing times notably. Teams accustomed to cloud-native workflows must adapt to hybrid governance models. Regulatory constraints often forbid data movement entirely, making in-place analytics the only compliant option. Delta Sharing protocols enable this access without violating sovereignty boundaries. Hybrid architectures now represent the default posture for sectors facing strict data residency laws.
Nomura and Orange Group Hybrid Deployment Outcomes
Nomura cut daily risk processing times by four hours after replacing Hadoop with a hybrid cloud data lakehouse powered by MinIO. This reduction eliminates the latency penalty where market exposure calculations previously stalled overnight batches. The architectural shift removes data gravity by allowing compute engines to access on-premises assets directly. Orange Group subsidiaries achieved a 300% boost in productivity by reducing compliance query times from hours to minutes. Legacy systems forced analysts to wait for ETL pipelines to replicate datasets before running audits. Direct federation via Delta Sharing bypasses these intermediate stages entirely.
| Legacy Workflow | Federated Model | Operational Impact |
|---|---|---|
| Extract to cloud storage | Read pointers in place | Zero egress fees |
| Duplicate governance policies | Centralized access control | Reduced audit friction |
| Batch window delays | Real-time query execution | Quicker risk response |
Maintaining separate governance layers for copied data often exceeds the storage bill itself. Operators face a tension between strict data sovereignty mandates and the need for elastic cloud compute. AIStor Table Sharing resolves this by keeping bytes on-premises while granting read-only access to external engines. Firms failing to adopt this model face rising transfer fees and stale intelligence. Consistent network connectivity between the storage cluster and the analytics plane remains a requirement. Network partitions interrupt live shares immediately, unlike batch replicas that offer eventual consistency. Teams must design failover policies that gracefully degrade to cached snapshots during outages.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible storage and AI/ML data infrastructure. His deep expertise in optimizing cloud storage architectures makes him uniquely qualified to analyze the implications of MinIO's new AIStor Table Sharing feature. Having previously engineered solutions for high-performance object storage at Wasabi Technologies, Chen understands the critical challenges enterprises face when bridging on-premises data with platforms like Databricks. His daily work involves helping organizations eliminate vendor lock-in while maximizing data throughput, directly aligning with the industry's shift toward open protocols like Delta Sharing. At Rabata. Io, a provider focused on democratizing enterprise-grade storage for AI startups, Chen evaluates how innovations in on-premises data sharing enable real-time analytics without compromising security or performance. This article reflects his practical experience in building scalable, cost-effective data foundations for modern artificial intelligence workflows.
Conclusion
Scaling AIStor Table Sharing exposes a critical fragility: network partition tolerance often lags behind governance requirements. When connectivity breaks, live shares vanish instantly, forcing teams to choose between stale cached snapshots or halted analytics pipelines. This operational reality shifts the burden from simple storage management to complex failover orchestration, where monitoring Iceberg catalog health becomes more expensive than the underlying disk capacity. As organizations pivot toward optimizing production cycles in 2026, the hidden tax of micro-transaction monitoring in public clouds will erode margins quicker than base storage fees.
Deploy hybrid architectures immediately, reserving hyperscaler vectors strictly for transient development while anchoring persistent training data on-premises by Q3. This split prevents egress fees from compounding during heavy ingestion phases and stabilizes budgeting against volatile per-operation charges. Do not attempt a full migration without first establishing graceful degradation policies that define exactly how your system behaves when the analytics plane disconnects from the storage cluster.
Start this week by auditing your current vector upload logs to calculate the true cost per GB including all API transaction fees, then compare that figure against your fixed on-premises overhead. Use this specific delta to justify the capital expenditure required for a sovereign deployment before your next fiscal planning cycle begins.
Frequently Asked Questions
Native integration cuts deployment time by 50% compared to traditional ETL patterns. This efficiency gain eliminates the need for complex data movement pipelines and duplicate datasets that typically slow down hybrid AI initiatives significantly.
Organizations can reduce storage costs up to 40% by bypassing hyperscaler-controlled table service fees. This approach maintains sub-millisecond metadata operations while removing the financial burden of replicating data across different cloud environments.
Public cloud vector storage prices hitting $0.06 per GB per month create immediate budget pressure. These costs combine with inter-region transfer fees at $0.02 per GB, making traditional migration strategies financially impossible for large archives.
Network stability between on-premises storage and cloud compute becomes the primary constraint instead of egress costs. Intermittent connectivity breaks live table links, shifting operational burden to network teams ensuring consistent low-latency paths.
Exactly 42% of leaders prioritize workflow optimization over new use cases in 2026. This shift confirms that fixing data gravity is now the primary spend for enterprises seeking to optimize their existing AI investments.
