S3 Files stop copy pipelines for huge genomes
With over 40 petabytes in the Sequence Read Archive, genomic data volume now overwhelms traditional transfer mechanics. S3 Files eliminate this bottleneck by replacing fragile copy operations with direct, scalable compute access.
Researchers at UBC previously wasted absurd amounts of time managing data movement rather than analyzing results, a friction point Andy Warfield identified while studying sunflower genomes. The Cancer Genome Atlas alone exceeds 2.5 PB, proving that manual data shuffling is unsustainable for modern cohorts involving over one million individuals. You will learn how S3 Files architecture removes data friction by allowing compute engines to operate directly on stored objects. We examine the specific mechanics enabling genomics workflows to use Apache Iceberg tables without costly data duplication. Finally, we dissect real-world implementations where scientists bypassed legacy transfer protocols to accelerate analysis of massive sequencing data sets.
The Role of S3 Files in Eliminating Data Friction
Data friction describes the mechanical overhead of copying and managing inconsistent copies across storage boundaries. Andy Warfield observed researchers at UBC spending an absurd amount of time on the mechanics of getting data where it needed to be instead of analyzing results. This inefficiency stems from tools like the GATK4 analytics framework expecting a local Linux filesystem while data resides in object storage. The scale of this mismatch grows as the Sequence Read Archive hosted on AWS contains over 40 petabytes of genomic data. Operators face a tension between durability and access semantics; moving data to compute introduces latency and version drift.
- Manual copy pipelines create multiple inconsistent copies that invalidate analysis reproducibility. - Burst parallel computing patterns fail when storage I/O cannot match transient compute scaling. - Local hardware sits idle during data transfer phases, wasting capital expenditure on unused cycles.
The cost of maintaining separate storage tiers for active and archived genomes reaches $302.40 for a single dataset over ten years in standard classes. Eliminating the copy step allows direct access to durable objects without sacrificing the POSIX semantics required by legacy bioinformatics tools. This unification removes the primary bottleneck in large-scale sequencing projects where data volume outpaces transfer bandwidth.
Scaling Cohort Studies Beyond One Million Individuals
Genomic cohort studies now involve more than one million individuals, creating unprecedented demand for computational resources that traditional filesystems cannot satisfy. The Cancer Genome Atlas exceeds 2.5 PB, while the Human Cell Atlas contributes approximately 300 terabytes (TB) of complex biological data. Operators attempting to analyze these datasets face a binary choice: incur massive data-copying latency or adopt filesystem semantics directly on object storage. Standard analytics frameworks like GATK4 traditionally expect a local Linux filesystem, forcing researchers to stage petabytes of data before computation begins. This staging process introduces failure modes where inconsistent copies corrupt downstream analysis results. S3 Files resolves this tension by streaming large static reference files directly into processes, eliminating the need for repeated file staging. The cost of maintaining duplicate copies for a dataset of this magnitude becomes prohibitive compared to unified access patterns. Reference data streaming allows Nextflow processes on AWS Batch to access terabytes of static files without local disk constraints. Adoption requires re-architecting workflows to treat storage as a network-mounted volume rather than a local disk primitive. The limitation remains that legacy tools lacking POSIX compliance may still require containerization wrappers to function correctly.
Object Storage Interfaces Versus Filesystem Expectations
The disconnect between object storage interfaces and traditional filesystem expectations forces engineers to manage multiple inconsistent copies. Applications like the GATK4 analytics framework typically require a local Linux filesystem, creating friction when data resides in S3. This architectural mismatch compels teams to copy data back and forth rather than accessing it directly. The cost of this friction grows as datasets expand beyond manageable local limits.
| Feature | Object Storage | Traditional Filesystem |
|---|---|---|
| Access Pattern | HTTP API calls | POSIX system calls |
| Consistency Model | Eventual or strong per object | Strong file locking |
| Latency Profile | Higher initial handshake | Low persistent mount |
| Scalability | Elastic without provisioning | Limited by inode count |
Operators often choose Amazon S3 Files to bridge this gap without incurring EFS throughput fees. This approach separates the storage layer from the file interface, translating standard operations into S3 requests automatically. However, this translation adds a processing layer that may not suit low-latency transactional workloads requiring multi-AZ parallel writes. The limitation is clear: while durability scales infinitely, semantic compatibility requires an abstraction layer that introduces potential latency overhead.
Inside S3 Files Architecture and Burst Parallel Computing
The Stage and Commit Model Replacing EFS3 Compromises
The Christmas of 2024 pivot abandoned the failed EFS3 prototype because presenting both file and object interfaces as a single unified system resulted in the lowest common denominator. This architectural split defines burst parallel computing by separating mutable metadata from immutable data payloads. The design attaches an EFS namespace to mirror S3 requests while changes accumulate locally before a collective push.
- Applications write to the local EFS mount using standard POSIX calls.
- The system buffers mutations to avoid immediate object immutability conflicts.
- A commit operation flushes the batch to S3 as complete objects.
This model resolves the problem with slow S3 access for Spark by eliminating per-byte network latency during active computation. Operators avoid the high-performance cache access charge penalties associated with unbuffered small writes. Unlike the previous unified attempt, this approach respects the boundary where files support fine-grained mutations and objects rely on content hashes.
| Attribute | EFS3 Unified Attempt | Stage and Commit Model |
|---|---|---|
| Consistency | Broken by merge conflicts | Atomic per-commit batch |
| Write Granularity | Byte-level (failed) | Object-level (committed) |
| Namespace | Single shared view | Mirrored metadata layer |
Meanwhile, the limitation remains that data is not visible to external S3 consumers until the commit phase completes. Mission and Vision dictates that engineers must treat the staging area as a transient workspace rather than a persistent record. This tension forces a choice between real-time global visibility and local write performance. ### Resolving Spark Slow Access via Burst Concurrent Computing Patterns
Slow Spark access stems from copying terabytes to local disks before analysis can begin. Burst coordinated computing patterns eliminate this latency by staging data in a high-performance cache layer rather than forcing full dataset migration. Historical research into burst buffers established that temporary high-speed storage is necessary for data-intensive scientific workflows to avoid I/O bottlenecks. The architecture separates mutable metadata from immutable payloads, allowing Apache Spark executors to read files via POSIX calls while the system handles backend translation. Data inconsistency in cloud workflows frequently arises when multiple jobs modify overlapping file ranges without atomic guarantees. The stage-and-commit model resolves this by accumulating changes locally before pushing complete objects to storage. This approach prevents partial writes from corrupting the source of truth during parallel execution phases. Operators configure Slurm job queues to right-size compute nodes, ensuring that burst capacity matches the ephemeral nature of genomic analysis tasks.
| Constraint | Traditional Copy | S3 Files Burst Pattern |
|---|---|---|
| Data Location | Local NVMe only | Unified namespace |
| Consistency | Manual sync required | Atomic commit |
| Idle Cost | High (stored twice) | Zero (single copy) |
The cost of maintaining dual storage copies vanishes when the filesystem interface mirrors the object store directly. However, the new high-performance cache access charge applies specifically to NFS interface operations, altering total cost calculations for write-heavy pipelines. Teams must balance the speed of local mutations against the cache access charge incurred during flush operations. Small-file writes benefit significantly from batched commits, whereas streaming large blobs may incur higher per-request fees if not optimized. Mission and Vision recommends tuning flush intervals to match Spark stage boundaries rather than individual task completion. This alignment minimizes metadata churn while preserving the durability guarantees inherent to object storage systems.
Avoiding Unpalatable Compromises in File and Object Presentations
Merging file and object interfaces without abstraction creates a battle of unpalatable compromises where either presentation sacrifices functionality. Early attempts to combine EFS and S3 internally failed because presenting both interfaces as a single unified system resulted in the lowest common denominator. Files support fine-grained mutations and `mmap()` calls, whereas objects rely on immutability and whole-object creation events.
| Capability | File System Expectation | Object Storage Reality |
|---|---|---|
| Mutation Model | Byte-range overwrites | Full object replacement |
| Path Semantics | First-class separators | Key prefix suggestions |
| Consistency | Immediate atomic rename | Eventual propagation |
Forcing POSIX semantics onto immutable buckets breaks agentic workflows that expect rapid iteration without copy delays. The architecture separates the object storage layer from the file system interface to prevent these conflicts. Applications read and write files using standard operations while the system translates requests backend. This split avoids the friction observed when researchers managed multiple inconsistent copies across hybrid environments. Burst alongside computing requires this distinction to maintain performance during massive scale-outs. The cost of ignoring this boundary is measurable in lost compute cycles during data staging phases. Operators must accept that namespace semantics differ fundamentally between the two models.
Real-World Genomics Workflows Using S3 Files and Iceberg
Apache Iceberg Table Structures for Genomic Datasets

Apache Iceberg organizes petabyte-scale sequencing data into manageable tables stored directly on S3 without file movement. This open table format replaces brittle directory listings with a hidden metadata layer that tracks snapshots, schema evolution, and partition changes atomically. Researchers managing the 2 million tables in S3 Tables gain ACID compliance for concurrent writes, eliminating the inconsistent copies that previously plagued GATK4 workflows. The architecture decouples compute from storage, allowing Werner Vogels vision of serverless scale to function without POSIX filesystem dependencies.
| Component | Function | Genomics Benefit |
|---|---|---|
| Snapshot Model | Time-travel queries | Reproduce exact variant calls |
| Schema Evolution | Safe column adds | Append new clinical annotations |
| Hidden Partitioning | Automatic file grouping | Optimize query pruning |
Adoption becomes mandatory when cohort studies exceed local disk capacity yet require SQL analytics. The limitation involves strict consistency requirements; writers must serialize commits to avoid metadata conflicts during high-velocity ingestion. Operators gain the ability to run variant annotation pipelines directly against cold storage tiers. This structure transforms raw base pairs into queryable assets while maintaining the durability of object storage. Mission and Vision dictate that data friction must vanish for agentic workflows to succeed at this scale.
Executing GATK4 Workflows with Spark on S3 Storage
GATK4 fails on raw S3 because the framework expects a local Linux filesystem for random access patterns. Deployments resolve this friction by mounting S3 Files to present object data as POSIX-compliant paths for Apache Spark executors. This architecture eliminates the manual copy pipeline that previously consumed researcher time at UBC. Operators configure AWS Batch to apply Spot Instances, reducing compute spend while maintaining parallel throughput for variant calling. The system handles data restoration automatically before job initiation. Workflows processing archival data trigger a Lambda function to write restore request IDs to Amazon DynamoDB. Compute nodes remain idle until the status updates to READY, preventing premature job failures. Orchestration layers manage this complexity without operator intervention. AWS Step Functions coordinate the entire sequence, attaching file-share access and spinning up instances only after the filesystem builds. This approach avoids the unpalatable compromises of earlier hybrid storage models.
| Workflow Stage | Traditional Block Storage | S3 Files Architecture |
|---|---|---|
| Data Ingest | Manual rsync to EBS | Direct mount from S3 |
| Compute Launch | Wait for copy completion | Immediate start |
| Cost Model | Fixed provisioned IOPS | Pay-per-request |
The limitation remains latency for small random reads compared to local NVMe. Network throughput becomes the bottleneck rather than disk I/O. Mission and Vision recommends testing batch sizes to maximize sequential read efficiency. Operators must tune Spark partition counts to match available network bandwidth.
Adoption Checklist for Iceberg Tables on S3
Validate event notification capacity against the 300 billion daily S3 event notifications limit before enabling catalog updates. Operators must confirm infrastructure handles this scale to prevent metadata lag during high-throughput ingestion.
- Configure orchestration
- Enable parallel variant annotation
- Verify throughput sustains 25 million S3 requests/sec for parquet reads during concurrent analysis.
- Implement snapshot isolation to prevent write conflicts across distributed compute nodes.
| Requirement | Legacy Hybrid Approach | S3 Files with Iceberg |
|---|---|---|
| Data Movement | Manual copy pipelines | Zero-copy access |
| Metadata Locking | File-system level | Table-level ACID |
| Scale Limit | Single filer bandwidth | Object storage limits |
Skipping the notification scale check causes silent catalog divergence when batch sizes exceed system thresholds. This failure mode forces manual reconciliation of table states, negating the benefits of atomic commits. Teams adopting open table formats now avoid the latency penalties inherent in earlier hybrid storage designs. Mission and Vision recommends validating these constraints prior to production deployment.
Migrating Legacy Storage to Cloud-Native S3 Environments
Implementation: The Stage and Commit Model Replacing EFS3 Compromises
Deployments fail when operators attempt to merge mutable file semantics with immutable object storage into a single interface. The initial "EFS3" concept collapsed because presenting both interfaces as one forced a lowest-common-denominator outcome where either file or object functionality suffered unavoidable sacrifice. Files require fine-grained byte-range overwrites and `mmap()` support, while objects depend on whole-object replacement and content hashing. This architectural conflict created unresolvable tension for engineers attempting to satisfy both modalities simultaneously. The solution establishes an explicit boundary through a stage-and-commit workflow rather than hiding the distinction.
- Mount an EFS namespace to mirror metadata from the target S3 bucket prefix. 2.
Migrating legacy pipelines requires replacing local disk paths with mounted S3 Files prefixes to eliminate manual data copying.
- Define the compute environment using AWS ParallelCluster
- Configure job definitions in AWS Batch
- Mount the storage prefix inside the container entry script to expose object data as standard POSIX files.
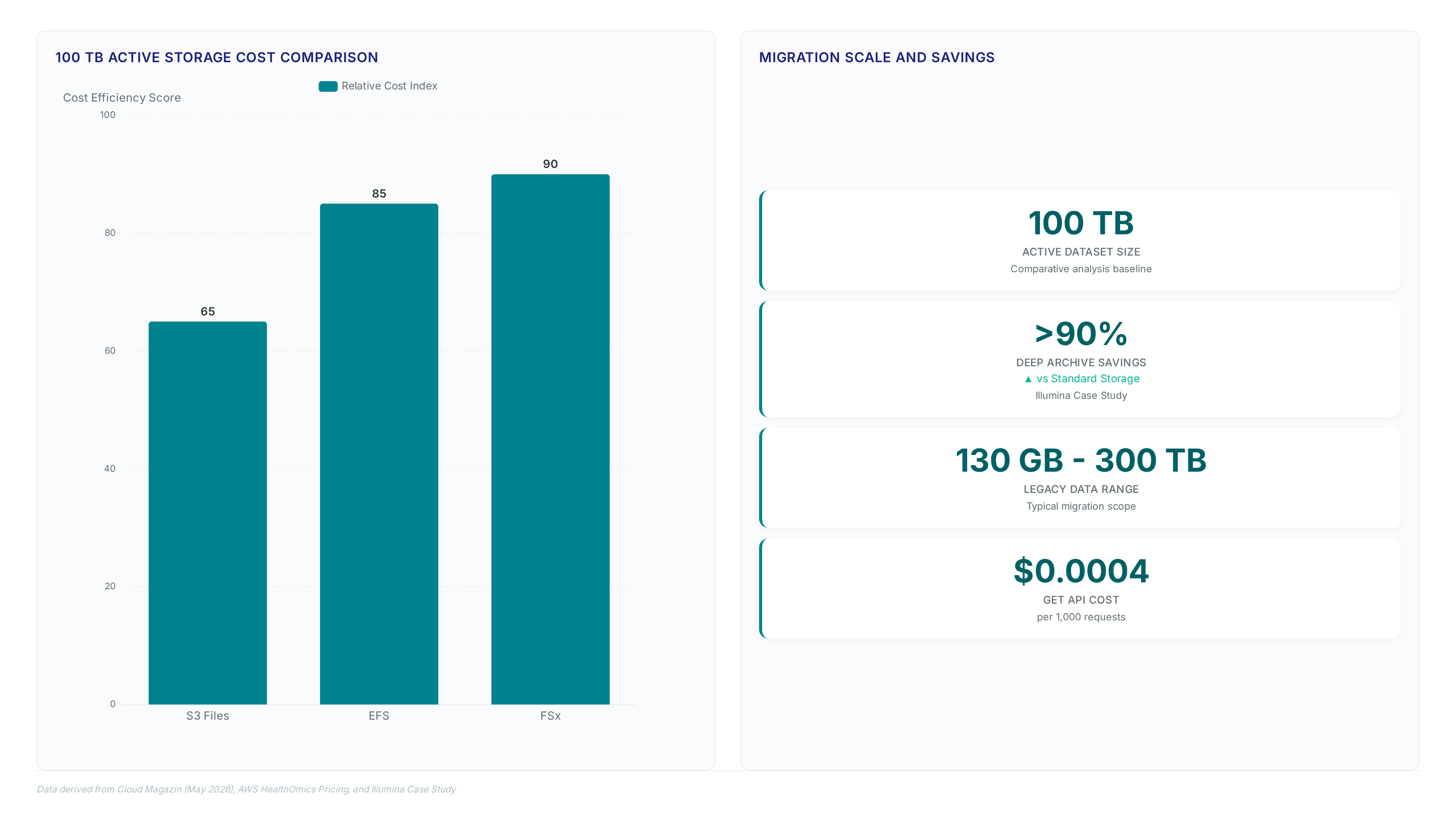
Operators must select the orchestration tool based on workload consistency rather than defaulting to on-premises habits. Slurm suits long-running simulations requiring strict queue control, whereas Batch optimizes sporadic burst parallelism common in genomics. The cost differential becomes stark at scale; a comparative analysis for 100 TB of active storage reveals significant savings when avoiding EFS throughput fees for batch jobs.
Verify April 2026 General Availability readiness by calculating checksum compute expenses at a minimal per-gigabyte rate before ingesting petabyte-scale cohorts.
- Compare active versus archive tier pricing using a comparative cost analysis
- Validate that the NFS interface supports required POSIX semantics without triggering excessive cache access charges described in the pricing model.
- Confirm IAM policies align with inode permissions to prevent authorization failures during the stage-and-commit phase.
- Test metadata throughput against the limits of the mounted namespace before migrating large directory structures. Mission and Vision recommends running a pilot workload to measure actual flush intervals before committing full datasets.
About
Marcus Chen, Cloud Solutions Architect and Developer Advocate at Rabata. Io, brings deep practical expertise to the evolving environment of S3 files. Having previously engineered storage solutions at Wasabi Technologies and optimized Kubernetes-native infrastructure, Chen directly addresses the data movement bottlenecks described in this article. His daily work involves designing S3-compatible architectures that eliminate the inefficient copying and management struggles faced by genomics researchers and AI teams. At Rabata. Io, a specialized provider focused on democratizing enterprise-grade object storage, Chen uses his background to build systems that offer superior performance without vendor lock-in. This experience uniquely qualifies him to analyze how modern object storage must adapt to handle massive datasets like the Sequence Read Archive. By connecting real-world engineering challenges with Rabata's mission to provide cost-effective, high-speed alternatives to AWS, Chen offers actionable insights for builders navigating the changing face of cloud storage.
Conclusion
Scaling genomic repositories beyond 100 TB exposes a critical fracture in metadata consistency that simple cost calculations miss. As datasets approach petabyte magnitudes, the latency inherent in S3 Files' stage-and-commit model creates silent race conditions in legacy dependency chains, forcing a fundamental rewrite of orchestration logic. The operational burden shifts from managing storage capacity to engineering explicit synchronization barriers that prevent data corruption during high-concurrency writes. Organizations ignoring this asynchrony will face escalating debugging costs that quickly erode initial infrastructure savings.
Adopt S3 Files only for batch-oriented genomic pipelines where immediate global visibility is not a hard requirement, and defer migration for interactive analysis workloads until Q4 2026 when metadata throughput limits are expected to stabilize. Do not attempt a lift-and-shift strategy for applications relying on instant POSIX semantics without first refactoring the job scheduler. Start by auditing your current Makefiles this week to identify any steps assuming immediate file propagation, then insert manual wait states or event-driven triggers to validate stability before moving even a single terabyte of production data.
Frequently Asked Questions
Maintaining separate storage tiers for active and archived genomes reaches $302.40 for a single dataset over ten years. Eliminating copy steps removes this prohibitive expense while preserving durable object access for analysis.
Sunflowers possess 10 times more genetic variation between individuals compared to the 99.9% similarity found in human DNA. This massive diversity requires burst parallel computing patterns that traditional local hardware cannot satisfy efficiently.
Applications like GATK4 traditionally expect a local Linux filesystem rather than object storage interfaces. This mismatch forces researchers to stage petabytes of data manually, creating inconsistent copies that corrupt downstream analysis results.
Sunflower genomes contain about 3.6 billion base pairs, which is larger than the human standard of 3 billion base pairs. Analyzing these larger datasets requires scalable compute access without fragile copy operations.
Genomic analysis exhibits burst parallel computing patterns where massive tasks run for short periods then idle. Local hardware sits unused during inactive phases, wasting capital expenditure on cycles that could scale to zero.
