Account namespace fixes S3 collision headaches
After 18 years of global collisions, AWS finally scopes S3 names to your specific account and region.
This shift replaces the fragile requirement for globally unique identifiers with a deterministic, isolated naming model. Amazon Web Services, Inc. Confirmed on Mar 12, 2026, that this update applies immediately across 37 AWS Regions, including AWS China and AWS GovCloud (US), effectively retiring the risk of external actors hijacking deleted bucket names. The new immutable naming convention enforces a strict `{bucket-name}-{account-id}-{region}-an` format, ensuring that once a resource is purged, its identifier cannot be reclaimed by any other entity.
You no longer need to generate random suffixes for multi-tenant workloads. Engineering teams can now mandate these patterns via service control policies and AWS CloudFormation templates. This is a necessary correction to a design flaw that has persisted since S3's 2006 launch.
The Role of Account Regional Namespaces in Modern S3 Architecture
Defining the Account Regional Namespace Format
The account regional namespace moves S3 bucket uniqueness from a global pool to an account-region scope using the `{bucket-name}-{account-id}-{region}-an` format. Amazon Web Services, Inc. Announced on Mar 12, 2026, that users can now create Amazon S3 general purpose buckets within their own reserved namespace, effectively ending 18 years of potential global bucket name collisions since S3's original launch in 2006. Operators must append the account identifier and region code to every bucket request. This transforms naming from a competitive search into a deterministic allocation. The control plane routes creation requests to the local account index rather than the global directory, but only if the suffix pattern is strict.
| Attribute | Legacy Global Namespace | Account Regional Namespace |
|---|---|---|
| Uniqueness Scope | Global across all AWS accounts | Specific to Account ID and AWS Region |
| Collision Risk | High during initial creation | Eliminated for owning account |
| Naming Predictability | Low ( | High (deterministic construction) |
Update automation scripts to inject the account regional suffix dynamically. Static names will fail validation in enabled regions. While this simplifies infrastructure-as-code deployments, it introduces a rigid dependency on account ID stability; migrating resources between accounts now requires renaming buckets rather than just updating policies. The namespace scope removes the need for complex prefix coordination but locks bucket identities to specific billing entities. Verify that your CloudFormation templates apply the `BucketNamespace` parameter to use this capability without manual intervention.
Building Multi-Tenant Workloads with Predictable Bucket Names
Deterministic bucket naming for multi-tenant architectures is now possible by scoping uniqueness to the account and region. This account local namespace eliminates global collisions, allowing operators to deploy bucket-per-customer patterns where desired names remain available across all 37 AWS Regions. Infrastructure-as-code templates generate consistent identifiers without querying global state, reducing deployment latency for large-scale tenancy models. The feature incurs no additional cost compared to standard general purpose buckets, preserving existing budget allocations for storage tiers.
Deleted names cannot be recycled. Operators must implement strict lifecycle governance before resource termination.
How Regional Namespace Validation Processes Bucket Creation Requests
The `CreateBucket` API rejects requests missing the `x-amz-bucket-namespace: account-regional` request header when operators attempt to use reserved naming formats. Validation logic shifts uniqueness checks from the global pool to the specific account and region scope, preventing cross-tenant collisions without requiring complex name generation algorithms. This mechanism enforces a strict boundary where the `{bucket-name}-{account-id}-{region}-an` format becomes mandatory for namespace reservation, unlike legacy global buckets that accept arbitrary strings.
| Validation Scope | Uniqueness Constraint | Collision Risk |
|---|---|---|
| Global Namespace | Worldwide across all accounts | High |
| Account Regional | Single account within one region | None |
Inject the header explicitly or update AWS CloudFormation templates to include the unique suffix to fix bucket creation failures. URLs and access methods for these buckets remain identical to standard S3 buckets, meaning validation occurs strictly at the API ingestion layer rather than the data plane. Legacy assets face a specific tension: bucket names ending with the `-an` suffix face restricted creation rules if they predate this update. Ignoring this header causes immediate request failure, forcing infrastructure-as-code pipelines to adopt explicit namespace declarations. Audit existing Terraform or CloudFormation stacks for missing header parameters before deploying to the 37 supported AWS Regions.
Mechanics: Constructing Predictable Bucket Names for Multi-Region Workloads
Developers construct identical bucket names across regions by appending the account ID and region code to a base string, scoped strictly to the local AWS Region. This deterministic pattern removes global collision checks, allowing infrastructure-as-code templates to define `data-lake-{account}-{region}-an` without querying external state. The API enforces this scope only when the caller includes the specific `x-amz-bucket-namespace`. URLs and access methods for these buckets remain the same as standard S3 buckets, preserving existing application logic while shifting validation to the API level. Avoid the `-an` suffix in legacy names.
| Constraint Type | Legacy Global Bucket | Account Regional Bucket |
|---|---|---|
| Uniqueness Scope | Worldwide across all accounts | Single account within one region |
| Name Format | Arbitrary unique string | `{name}-{account}-{region}-an` |
| Collision Risk | High during initial creation | Zero within owning account |
Naming costs remain flat, though moving data out of the region to the internet incurs $0.09 per GB for egress. Security teams enforce this naming discipline by attaching IAM policies with the `s3:x-amz-bucket-namespace` condition key to block non-compliant requests. Predictable naming simplifies deployment but hardens the architecture against accidental cross-region data sharing if policies are too restrictive.
Deployment Failures in Excluded Middle East Regions
Bucket creation requests fail immediately in Middle East (Bahrain) and Middle East (UAE) when operators include the `x-amz-bucket-namespace` header. The account territorial namespace feature explicitly excludes these two geographies, forcing API validation logic to reject reserved naming formats that function elsewhere. Infrastructure-as-code templates targeting these zones must omit the request header. Identical Terraform modules produce divergent outcomes based solely on target region selection.
Teams managing multi-region architectures face a hard constraint: conditional logic becomes mandatory to switch between deterministic naming and legacy global scanning. The CreateBucket API offers no graceful fallback, returning hard errors rather than defaulting to global scope when the header is present in excluded zones. Audit deployment pipelines to ensure the 2 excluded regions trigger a distinct code path that strips namespace parameters before transmission. Failure to implement this geographic branching results in consistent provisioning failures for any workload attempting to span the full set of available AWS Regions.
Implementing Account Regional Namespaces Across CLI and CloudFormation
Implementation: Mandatory x-amz-bucket-namespace Header for CreateBucket API

Activating this capability demands the `x-amz-bucket-namespace: account-regional` header inside the CreateBucket API payload. Shifting uniqueness validation from the global pool to the local account scope requires appending this specific field. The AWS CLI eases this burden by accepting the `--bucket-namespace account-regional` flag, which automatically injects the necessary HTTP header during execution. Python scripts using Boto3 retrieve caller identity dynamically to construct valid names without hardcoding account.
- Define the base bucket name in the infrastructure template.
- Add the `x-amz-bucket-namespace` parameter to the request configuration.
- Execute the creation call against one of the 37 supported regions.
Security teams enforce this pattern via IAM policies checking the `s3:x-amz-bucket-namespace` condition key. Such controls stop accidental fallback to legacy global naming conventions that risk collisions. Operating at no additional cost relative to standard general purpose buckets removes financial barriers. Omitting the header while using a reserved name format triggers immediate API rejection. Consistent naming hygiene across enterprise deployments now depends on updating all existing automation pipelines.
CLI Flag Usage and Boto3 Flexible Account ID Generation
Appending the `--bucket-namespace account-regional` flag to every AWS CLI creation command activates the reserved scope.
- Execute the create command with the explicit namespace flag and target region.
- Verify the response includes the account-specific suffix rather than a global identifier.
- Integrate this flag into all automation scripts to prevent legacy global bucket provisioning.
Python automation avoids hardcoding account identifiers by calling the STS `GetCallerIdentity` API within Boto3 workflows. Developers retrieve the caller ARN dynamically, parse the account ID, and concatenate it with the region code to form the required bucket name string before issuing the request. This approach eliminates configuration drift when deploying across multiple accounts because the script self-discovers the correct suffix at runtime rather than relying on static environment variables. The `GetCallerIdentity` method guarantees the generated name always matches the credentials executing the deployment.
Cloud formation templates need the `BucketNamespace` property set to `account-regional` alongside the `BucketNamePrefix` parameter to function correctly.
CloudFormation Template Updates and Region Flag Verification
Existing AWS CloudFormation stacks require the `BucketNamespace` parameter to activate the reserved naming scope.
- Add `BucketNamespace` and `BucketNamePrefix` properties to resource definitions using the official syntax.
- Verify the `--bucket-namespace` flag presence in associated CLI deployment scripts.
- Attach an SCP denying creation requests that omit the `s3:x-amz-bucket-namespace` condition key.
- Exclude templates targeting Bahrain or UAE regions from this specific update path.
Validation logic rejects any stack attempting to reserve names ending in `-an` without proper header configuration. Operators must audit legacy assets because restricted suffixes. Comparing enforcement methods reveals distinct operational impacts.
| Method | Scope | Failure Mode |
|---|---|---|
| SCP | Organization-wide | Hard deny on API call |
| IAM Policy | User-specific | Silent fallback to global |
| Template Param | Resource-level | Stack rollback event |
Relying solely on template parameters leaves gaps where manual CLI users bypass guards entirely. Misconfiguration carries no financial penalty since the feature carries no premium charge compared to standard tiers. Adoption timelines stretch into 2026 as teams adjust workflows. The 03 release cycle introduced these changes. Reference number 11212539 tracks the specific update documentation.
Strategic Advantages of Adopting Regional Namespaces for Enterprise Teams
Application: Account Area-based Namespace Mechanics for Simplified Management
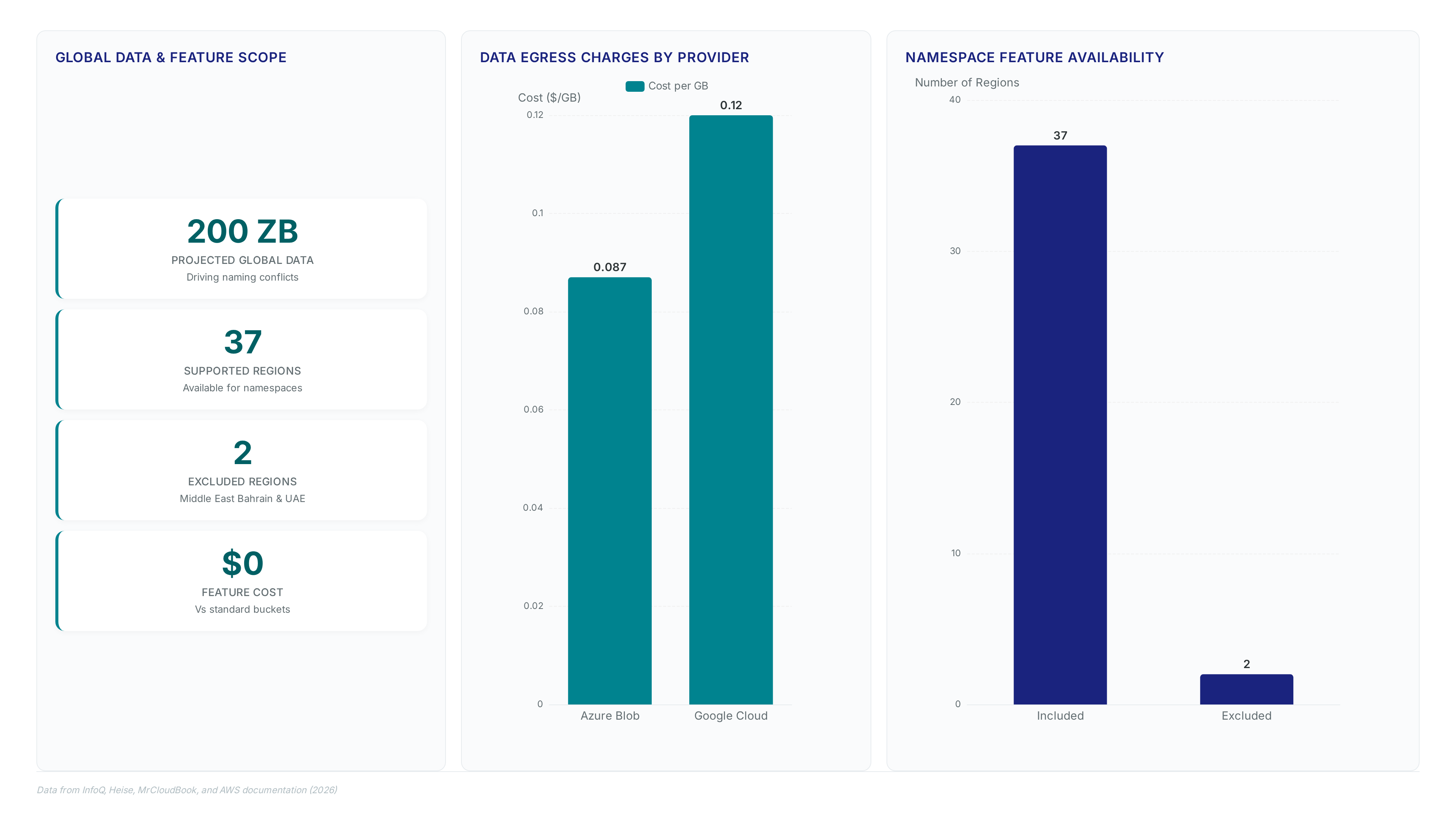
Global data volumes approach 200 zettabytes by 2027, making global uniqueness constraints unmanageable for enterprise scale. The mechanism shifts validation scope from the worldwide pool to the specific account and region, allowing predictable naming without collision checks. Operators enable this by passing the `x-amz-bucket-namespace` header in the CreateBucket API or using the `--bucket-namespace` flag in the AWS CLI. Security teams enforce compliance via SCPs using the `s3:x-amz-bucket-namespace` condition key to block legacy global requests, preventing accidental namespace.
Permanent name immutability defines the constraint. Deleting a bucket releases the name only within that specific account, blocking external takeover attempts but also preventing reuse across different organizational units. This design choice eliminates a class of security vulnerabilities while introducing a strict lifecycle constraint on identifier recycling. Infrastructure architects must account for this permanence when designing ephemeral test environments that previously relied on name recycling.
Automation scripts using Boto3 should dynamically fetch account IDs to construct valid suffixes, ensuring consistency across the 37 supported regions. The feature carries no premium cost, yet the operational shift requires updating all AWS CloudFormation templates to include the new parameter. Failure to update these definitions results in deployment failures as the default behavior reverts to the legacy global model.
Enforcing Namespace Adoption via SCP and CloudFormation Templates
Security teams must deploy Service Control Policies using the `s3:x-amz-bucket-namespace` condition key to block legacy global bucket creation attempts immediately. This policy acts as a hard guardrail, forcing all new storage resources into the account-specific scope regardless of developer intent. Operators link this enforcement mechanism to IAM policies. The cost of non-compliance manifests in fragmented automation pipelines where scripts fail against unpredictable naming collisions.
Updating infrastructure code requires adding `BucketNamespace` and `BucketNamePrefix` parameters to existing AWS CloudFormation definitions. Template authors can reference the official syntax to ensure stacks provision buckets with the correct `-an` suffix automatically. This shift prevents the operational debt of maintaining dual naming conventions during migration phases. Teams should consolidate to a single namespace model to avoid split-brain configuration states that complicate IAM policy enforcement.
Strict SCP enforcement creates tension with legacy application compatibility since older tools may not support the new header format. Audit all CI/CD pipelines for hardcoded bucket names before enabling the deny policy. The limitation of this approach is the inability to create resources in Bahrain or UAE regions until vendor support expands. Total standardization requires excluding these specific geographic endpoints from the initial rollout wave.
Data Egress Cost Implications for Multi-Region Namespace Strategies
Predictable naming across 37 AWS Areas allows operators to deploy identical bucket names in every region, but moving that data out triggers charges of $0.087/GB on Azure Blob Storage and $0.12/GB on Google Cloud Storage. This pricing disparity creates a hidden budget risk where multi-region redundancy becomes financially unsustainable without strict traffic shaping. Security teams enforcing the `s3:x-amz-bucket-namespace` key via IAM policies face a common failure mode: syncing terabytes to backup regions without accounting for the cumulative retrieval costs during disaster recovery drills.
Implement lifecycle rules to delete stale replicas immediately after use. Architectural decisions now require dual validation: checking name availability and calculating potential egress exposure. Ignoring this balance leads to scenarios where the simplicity of account regional namespaces results in significant operational overspend.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible object storage and AI/ML data infrastructure. His deep technical background makes him uniquely qualified to analyze Amazon S3's new account zone-based namespaces, a feature that fundamentally shifts how organizations architect multi-tenant storage. Having previously engineered solutions at Wasabi Technologies and Kubernetes-native startups, Chen understands the operational friction caused by global bucket name collisions. At Rabata. Io, his daily work involves helping enterprises and AI startups build scalable, vendor-neutral storage layers that mirror AWS capabilities without the lock-in. This article connects his hands-on experience with S3 API implementations to the strategic advantages of predictable, region-scoped bucket naming. By using Rabata's high-performance, GDPR-compliant infrastructure, Chen illustrates how these namespace updates empower developers to deploy cleaner, more efficient data architectures for modern cloud workloads.
Conclusion
Scaling this namespace strategy reveals that operational friction shifts from naming collisions to cost leakage. When teams treat regional redundancy as a default setting rather than a calculated exception, egress fees compound silently during routine failover tests. The real breaking point occurs when legacy CI/CD pipelines attempt simultaneous writes across excluded geographies like Bahrain, causing deployment failures that standard monitoring often misses until revenue impact accumulates. You cannot simply overlay this architecture onto existing multi-cloud habits without rewriting your financial governance model first.
Adopt account territorial namespaces only if you can enforce strict traffic shaping policies within 90 days of migration. Do not enable global replication for non-critical datasets, and explicitly exclude unsupported regions from your initial Terraform modules to prevent silent build errors. This approach demands that finance and engineering validate every new region against actual recovery time objectives, not just theoretical availability. Treat the namespace as a logical boundary for cost centers, not a free pass for data duplication.
Start by auditing your current storage replication rules this week to identify any sync jobs targeting regions outside your primary operational zone. Disable any non-necessary cross-region transfers immediately to establish a baseline before enabling the new namespace constraints.
Frequently Asked Questions
Enabling this feature incurs no additional cost compared to standard general purpose buckets. You can deploy predictable naming across 37 AWS Regions without changing your existing storage budget allocations or tier pricing models.
Once a resource is purged, its identifier cannot be reclaimed by any other entity immediately. This immutable convention permanently retires the name, ending 18 years of potential global bucket name collisions for that specific string.
This update applies immediately across 37 AWS Regions, including AWS China and AWS GovCloud (US). Operators in these locations can now create buckets using the deterministic account and region scoping model today.
Static names will fail validation in enabled regions if they lack the required account regional suffix. You must update templates to inject the account identifier and region code dynamically for successful provisioning.
Moving data out of the region to the internet still incurs $0.09 per GB for egress. Security teams enforce this pricing regardless of whether the bucket uses the new regional namespace or legacy global naming.
