S3 storage at 500 trillion: Why 2006 code still runs
S3 now stores over 500 trillion objects, a figure AWS confirmed while celebrating the service's 20th anniversary on March 16, 2026. This isn't just scale; it's a strategic moat built on strict API backward compatibility that on-premise solutions and competitors cannot replicate without accruing massive technical debt.
Principal developer advocate Sébastien Stormacq describes a scale that defies intuition: S3 serves more than 200 million requests per second across 123 Availability Zones. AWS notes that stacking the tens of millions of hard drives powering this fleet would reach the International Space Station and almost return to Earth. Unlike transient compute resources, this storage layer anchors the global data economy, which TechTarget identifies as being driven in 2026 by AI workloads and hybrid multi-cloud durability.
Rivals like Backblaze attempt to mark the occasion with stunts involving 130TB Pi downloads, but they lack the two-decade operational history guaranteeing your 2006 code still functions unchanged today. The following sections dissect how AWS maintained this consistency while migrating through multiple generations of storage systems, effectively rendering traditional on-premise archives obsolete for enterprises demanding both scale and permanence.
The Role of S3 as the Universal Data Foundation for Cloud Infrastructure
AWS S3 Object Storage and API Backward Compatibility Since 2006
Amazon Simple Storage Service (S3) defines cloud object storage through two decades of strict API backward compatibility since its launch on Pi Day 2006. The service originally launched on March 14th, 2006, a date known as "Pi Day" (3/14), marking the beginning of AWS's public cloud services. Initial capacity totaled one petabyte across 400 nodes, yet Sébastien Stormacq confirmed that code written in 2006 still functions today without modification. This persistence allows operators to avoid refactoring legacy applications while the underlying infrastructure undergoes complete rewrites for performance gains.
AWS S3 now manages 500 trillion objects as of 2026, a massive increase from the 2 trillion objects recorded in 2013. This scale underpins modern data lakes where strong read-after-write consistency became mandatory for all operations in December 2020. The mechanism enforces immediate visibility of new writes across all availability zones, eliminating the historical race conditions that plagued eventual consistency models. Engineers building real-time analytics pipelines rely on this guarantee to process streaming data without complex reconciliation logic.
Strict ordering introduces latency overhead during cross-region replication events. Write throughput may dip during partition splits while the system verifies global state synchronization. Operators must weigh this trade-off when designing high-frequency trading systems versus archival storage tiers. For long-term storage decisions, the durability guarantees outweigh the minor performance penalty in most enterprise scenarios. Using the S3 API ensures compatibility with future tooling while using the proven scalability demonstrated by the 250x growth in object count over thirteen years.
| Feature | Pre-2020 Behavior | Post-2020 Behavior |
|---|---|---|
| Read Consistency | Eventual | Strong |
| Write Visibility | Delayed | Immediate |
| Data Lake Reliability | Low | High |
Validate application logic against strong consistency requirements before migrating legacy workloads.
S3 API as Industry Reference Point Versus Vendor Compatible Storage Tools
The native AWS interface processes 200 million requests per second, establishing a performance baseline that third-party tools must emulate to claim compatibility. This API reference point dictates industry behavior because operators prioritize code portability over vendor lock-in fears. Multiple storage providers now implement identical HTTP verbs and error codes to capture workloads designed for Amazon infrastructure.
| Feature | Native AWS Implementation | Third-Party Compatible Tools |
|---|---|---|
| Analytics Integration | Deep hooks into Glue and Athena | Limited or requires data movement |
| Egress Cost Model | Free transfers to CloudFront within region | Often charges standard bandwidth rates |
| Archive Tier Pricing | $0.00099/GB for Deep Archive | Varies; some match at $0.00099/GB |
| Consistency Guarantee | Strong read-after-write since 2020 | Implementation dependent on backend |
Backblaze B2 offers pay-as-you-go storage at $6/TB with free egress up to three times the stored amount, undercutting AWS on raw capacity costs. However, the system integration gap remains the primary friction point for migration. Moving data to a cheaper tier often breaks dependencies on specific analytics tools like Redshift Spectrum that expect native S3 metadata behaviors. The cost savings from alternative vendors frequently vanish when engineering teams rebuild pipelines lost during the switch. Operators must weigh per-gigabyte savings against the operational debt of maintaining non-native storage paths. True compatibility extends beyond API syntax to include the surrounding management plane.
Inside the Architecture Delivering 11 Nines Durability and Exabyte Scale
The near-perfect durability target mathematically permits only one object loss per 10,000 years across billions of stored items. Such a metric relies on a distributed architecture replicating data across multiple Availability Zones to survive single data center failures without operator intervention. Continuous byte inspection drives this reliability through a specific microservice workflow.
- Auditor services scan every single byte across the entire storage fleet sequentially.
- The system compares checksums against known good states to detect silent degradation.
- Repair triggers activate immediately upon finding bit rot, rebuilding copies before data becomes unreadable.
Legacy storage systems often sample random sectors for health checks, leaving gaps where corruption festers until a read failure occurs. S3 eliminates this gap by inspecting the complete dataset rather than relying on probabilistic sampling. Significant compute overhead is required to validate hundreds of exabytes continuously. True lossless operations demand full fleet visibility rather than spot checks.
Mai-Lan Tomsen Bukovec oversees the engineering scale ensuring these auditor services keep pace with exponential growth. The mechanism transforms storage from a passive disk array into an active self-healing organism. Operators gain confidence that bit rot detection happens automatically before applications request corrupted blocks. This proactive stance distinguishes enterprise-grade durability from simple replication strategies used by cheaper competitors.
A physical stack of 276 million hard drives reaches the International Space Station and almost returns to Earth. This magnitude supports hundreds of exabytes. Geographic dispersion creates a specific tension between durability and latency during regional outages.
| Failure Scope | Impact on Data Availability | Recovery Mechanism |
|---|---|---|
| Single Rack | Negligible | Immediate local rebuild |
| Entire Zone | Minimal | Cross-zone replication sync |
| Full Region | Significant | Manual failover to secondary region |
Strategies ensuring such massive fleets maintain integrity without manual intervention fall under Mai-Lan Tomsen Bukovec's oversight. The sheer count of drives implies that even a 0.1 percent simultaneous failure rate would overwhelm traditional repair queues, necessitating automated bit rot detection at the byte level. An outage in one zone forces traffic redirection, yet the system continues serving requests because copies exist elsewhere. Fixing an S3 outage impact requires no data restoration from tape, only routing table updates. Higher storage overhead compared to single-site arrays represents the constraint, but this design eliminates catastrophic loss scenarios. Organizations like Mercado Libre use this distribution to handle continuous traffic spikes without provisioning new hardware racks. Physical drive replacement becomes a constant background process rather than an emergency event.
Automated Repair Triggers and Rust Rewrites in the S3 Request Path
Auditor services examine data and automatically trigger repair systems the moment they detect signs of degradation without human intervention. This continuous byte inspection mechanism scans the entire fleet sequentially, comparing checksums to identify silent bit rot before it causes data loss. Coverage for every stored object is guaranteed by this approach, unlike sampling-based health checks used by legacy vendors.
Rigorous validation performance costs drove AWS to progressively rewrite performance-critical code in the S3 request path using Rust over the last eight years. Blob movement and disk storage modules now use Rust's memory safety guarantees to eliminate entire classes of concurrency bugs while maintaining throughput. Teams managing distributed microservices architecture migrations observe that this language shift reduces garbage collection pauses common in managed runtime environments.
| Metric | Legacy Implementation | Rust-Based Rewrite |
|---|---|---|
| Memory Safety | Runtime garbage collection | Compile-time guarantees |
| Concurrency Model | Mutex-heavy locking | Async/await patterns |
| Failure Mode | Stop-the-world pauses | Graceful degradation |
Latency introduced by background repair triggers during peak ingestion windows must be accounted for by operators implementing event-driven architectures via S3 Event Notifications. Immediate write availability conflicts with the background CPU cycles consumed by constant integrity verification. High-traffic deployments supporting continuous traffic increases often see repair operations throttle automatically to preserve foreground request latency. Durability targets are met without starving active client connections of compute resources through this balancing.
Strategic Advantages of S3 Over On-Premise and Competitor Storage Solutions
S3 Standard Pricing Structure and Egress Fee Mechanics
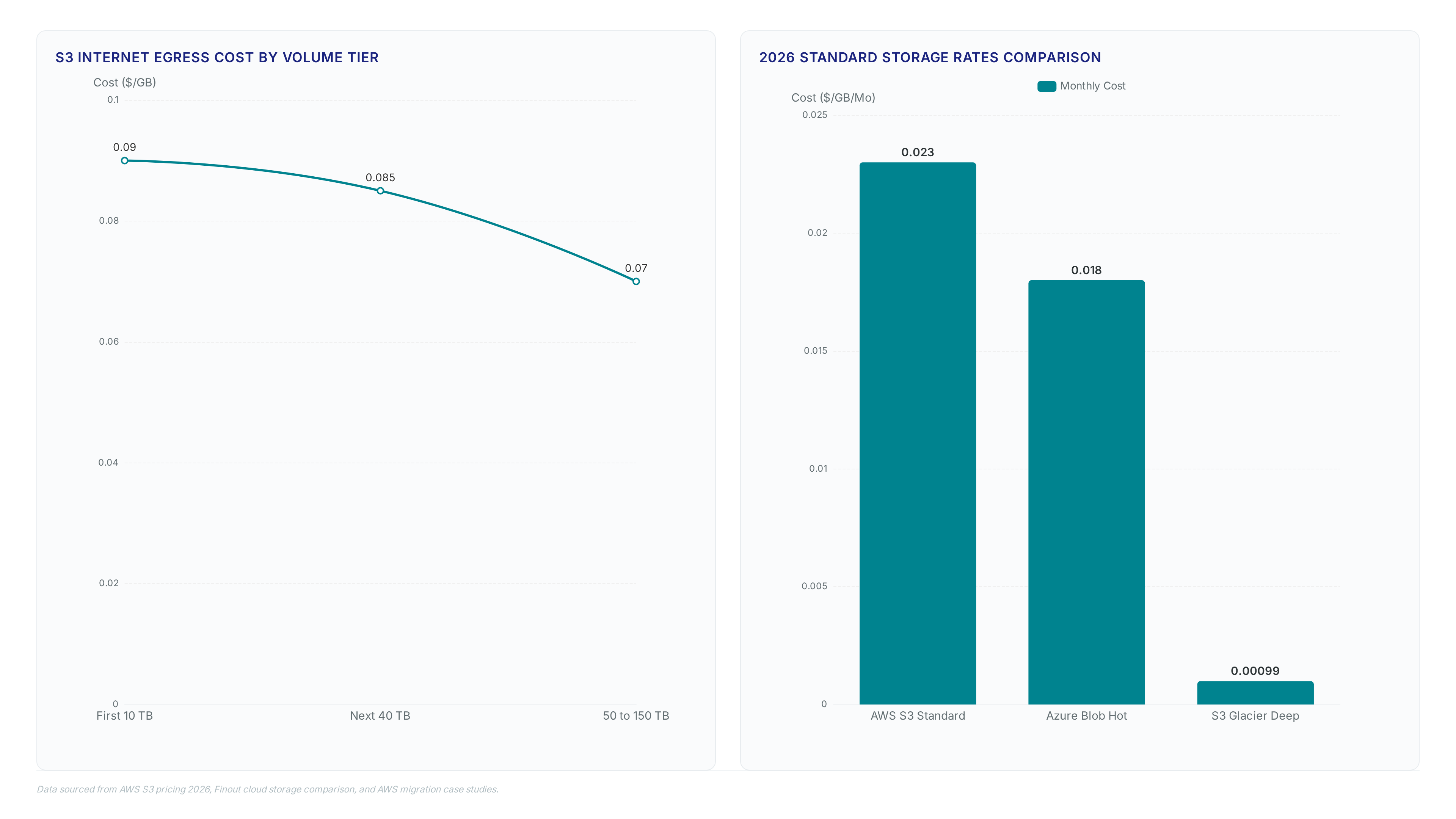
Amazon S3 Standard storage costs $0.023/GB/month in the us-east-1 region as of 2026, establishing a baseline for cloud vs local backup economic modeling. This rate undercuts many on-premise capital expenditures yet introduces variable operational costs through tiered data transfer fees. Egress from S3 to the internet costs $0.09/GB for the first 10 TB per month, creating a steep initial penalty for small-scale data retrieval. The pricing structure descends gradually, with data transfer OUT from Amazon S3 to the internet costing $0.085/GB for the next 40 TB per month before reaching deeper discounts at higher volumes.
Operators comparing S3 vs on-prem storage must track how these marginal costs accumulate during large-scale migrations or disaster recovery drills.
Enterprise Migration Case Studies: 3M and Snap Cost Optimization
3M Company migrated 2,200 applications to the cloud in 24 months using AWS Application Migration Service to eliminate aging data center dependencies. This rapid timeline compressed a 30-month deadline, forcing parallel application refactoring rather than sequential lift-and-shift tactics. Legacy coupling created the primary constraint; monolithic apps required containerization before transfer, adding engineering overhead that smaller firms often underestimate. Operators planning similar moves must audit inter-service dependencies first, or face stalled cutover events.
Snap executed a strategic exit from a competing cloud provider to optimize costs and offload regionalization work via S3 data migration. Engineering leader Manoharan directed this shift to meet quarterly cost-optimization goals while freeing teams for feature development. Moving petabytes inward reduces future negotiating use against egress fees, deepening vendor lock-in. Teams implementing S3 for AI workloads gain direct compute access but sacrifice multi-cloud portability.
| Dimension | 3M Approach | Snap Strategy | Operator Implication |
|---|---|---|---|
| Primary Driver | Deadline compliance | Expense reduction | Align migration trigger to business KPI |
| Tooling | Automated replatforming | Custom data pipelines | Select tools based on app complexity |
| Risk Profile | Schedule slippage | Data transfer latency | Buffer timelines for network saturation |
Validate egress economics before committing to single-provider AI architectures. High-volume training jobs generate massive intermediate datasets that incur transfer penalties if moved later. The 3M case proves speed is achievable with strict tooling, while Snap demonstrates that cost savings require painful provider separation. Both paths demand upfront architectural analysis to avoid technical debt accumulation.
Executing Secure Migration and Operational Best Practices for Enterprise S3
Default SSE-C Disable and Public Access Risks in S3 Buckets
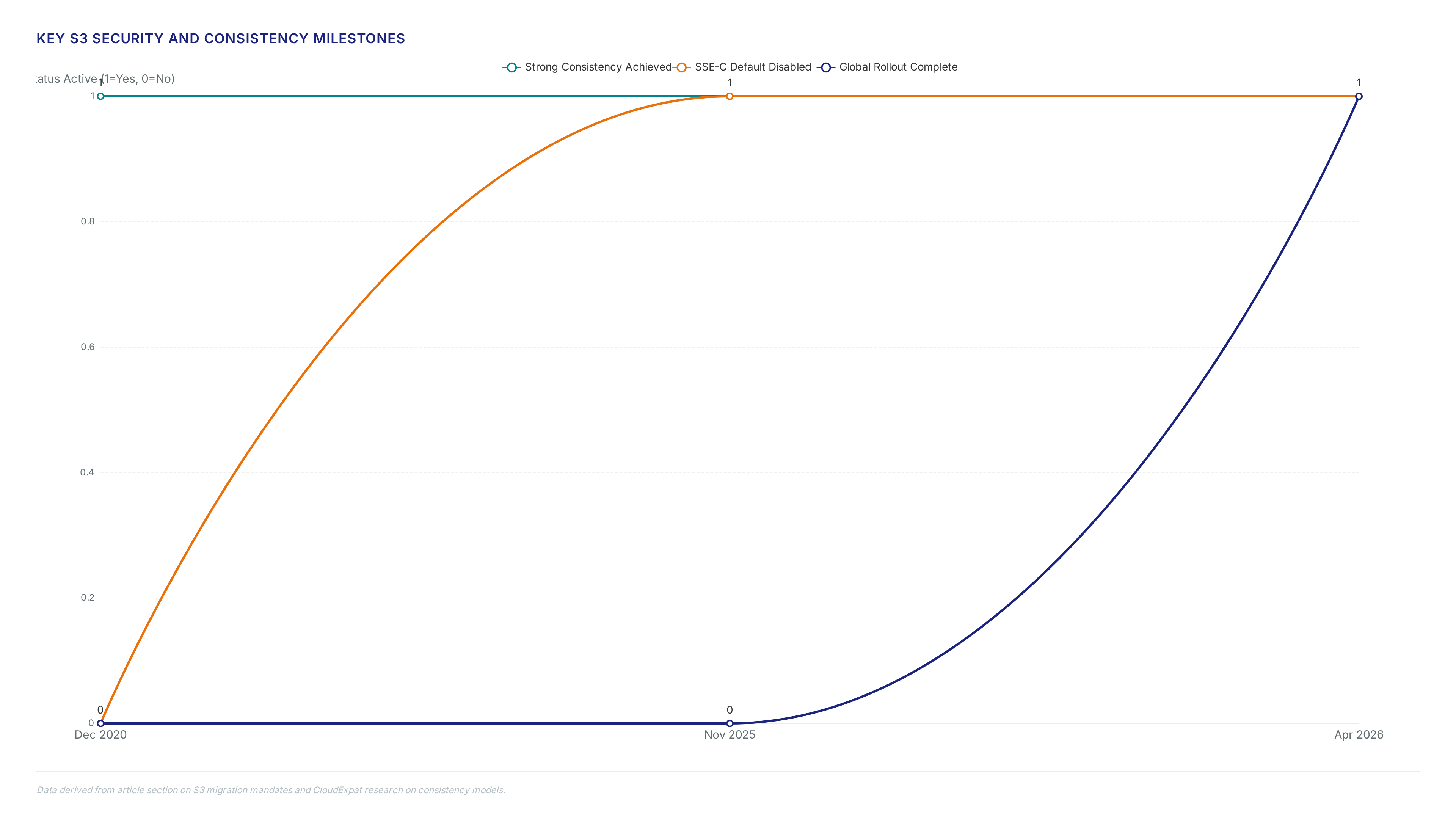
The November 19, 2025 mandate disabling SSE-C by default eliminates customer key management failures while shifting burden to bucket policy configuration. Criminals previously exploited open defaults to locate thousands of insecure setups, forcing a structural change in how AWS handles new bucket creation. This update rolls out across all regions by April 2026 and requires operators to explicitly enable customer-provided keys rather than inheriting them automatically.
- Audit existing buckets for public read permissions before the April 2026 rollout completes to prevent accidental exposure.
- Apply the new default bucket security setting via Terraform or CloudFormation to enforce encryption at rest for all new objects.
- Monitor the 5,500 GET requests per second limit per prefix when enabling aggressive logging to detect unauthorized access patterns early.
Disabling SSE-C by default breaks legacy applications expecting automatic customer-key wrapping. Immediate write failures occur until code updates deploy. Operators must choose between maintaining backward compatibility for older tools or enforcing stricter security posture immediately. Treat this change as a forced migration event rather than a passive configuration update.
Executing Migration Steps with Strong Read-After-Write Consistency
AWS achieved strong read-after-write consistency for all operations in December 2020, eliminating historical eventual consistency issues during data transfer. Operators must use this guarantee to prevent application errors when migrating active workloads.
- Enable versioning on the destination bucket before initiating any write operations to preserve object history.
- Configure the migration tool to verify ETag matches immediately after every PUT request completes.
- Execute a validation read against the new object key within milliseconds of the write confirmation.
- Redirect application traffic only after confirming zero latency discrepancies between source and destination reads.
This sequence ensures the migration pipeline detects corruption before downstream systems consume stale data. The 3M Company case study demonstrates that compressing a 30-month deadline into 24 months required parallel application refactoring. Skipping immediate read validation introduces a hidden failure mode where applications process outdated files despite successful write logs.
Strict consistency checks increase total migration duration by adding round-trip latency for every object. Teams balancing speed against accuracy often disable immediate reads for static archives. They accept a small window of potential inconsistency. This constraint suits cold storage but fails for active databases requiring strict ordering. Operators must classify data temperature before selecting a validation strategy. Uniform policies rarely optimize both cost and reliability. Prioritize data integrity over raw throughput when financial records are involved.
Validation Checklist for CRC32 Integrity and 2017 Outage Mitigation
CRC32 validation at the part-level prevents corrupted uploads from becoming permanent storage artifacts.
- Calculate local checksums before initiating multipart transfers to match server-side integrity algorithms.
- Verify trailer-based signed chunked uploads using the documented S3 limitations to ensure end-to-end data fidelity.
- Distribute replicas across distinct regions to mitigate single-zone failures reminiscent of the 2017 US-EAST-1 outage.
The 2017 incident demonstrated that regional dependency creates a single point of failure for dependent web services. Multi-region redundancy remains the only operational control that survives zone-wide control plane degradation. Operators ignoring this architectural constraint risk total data unavailability during localized infrastructure collapses.
| Validation Scope | Algorithm | Failure Mode Mitigated |
|---|---|---|
| Whole Object | CRC32 | Complete file corruption during transit |
| Individual Part | CRC32 | Silent data loss in multipart uploads |
| Cross-Region | Replication | Regional control plane outage |
Enabling versioning alongside checksum verification provides a rollback path if integrity checks fail post-write. This dual-layer approach addresses both transmission errors and logical corruption introduced by application bugs.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible object storage and AI/ML data infrastructure. His deep technical background makes him uniquely qualified to analyze the evolution of Amazon S3, having previously engineered storage solutions at Wasabi Technologies and Kubernetes-native startups. Chen's daily work involves optimizing cloud storage architecture for enterprises seeking alternatives to vendor lock-in, directly connecting his practical experience to the historical milestones of S3. As Rabata. Io builds the fastest cost-effective alternative to AWS with GDPR-compliant data centers, Chen uses his expertise to help organizations navigate the complexities of scalable storage. His insights bridge the gap between S3's twenty-year legacy and the modern demand for transparent pricing and high-performance mixed operations required by today's AI-driven workflows.
Conclusion
Storage economics fracture when data volume crosses the zettabyte threshold, rendering static pricing models obsolete regardless of provider promises. The narrow margin between standard tiers and deep archive options disappears once egress fees compound with retrieval latency during large-scale recovery operations. Organizations relying on single-region architectures for critical assets face unacceptable operational risk as global data density increases. You must treat storage selection as a flexible financial instrument rather than a fixed infrastructure utility.
Implement a strict data temperature audit by next Friday to identify cold assets currently residing in expensive standard tiers. Move any object untouched for 180 days to Deep Archive or a compatible low-cost alternative immediately. This single action reduces baseline spend while forcing a review of retrieval patterns before they become emergencies. Do not wait for the next billing cycle shock to address inefficiency.
Commit to a multi-cloud egress strategy within six months to prevent vendor lock-in from dictating your recovery budget. Negotiate private link agreements now to bypass public internet rates for predictable workloads. Teams that delay this architectural shift will find their disaster recovery plans financially unexecutable when scale demands it. Prioritize checksum validation on all inbound traffic before expanding footprint, ensuring you do not pay to store corrupted data.
Frequently Asked Questions
S3 now stores over 500 trillion objects globally as of 2026. This represents a massive increase from the 2 trillion objects recorded in the system during 2013.
The service serves more than 200 million requests per second across all regions. This traffic flows through 123 Availability Zones supporting hundreds of exabytes of data.
Analysts estimate AWS uses about 276 million hard drives to power this massive storage fleet. Stacking these drives would reach the International Space Station and almost return.
Backblaze posted a downloadable archive recording Pi to 314 trillion digits for users. The total download exceeds 130TB, so they broke it into 200GB objects.
Such stability drives adoption, with 82% of organizations now relying on hybrid cloud storage models. These integrate public S3 APIs with private hardware for resilience.
