Block storage beats S3 for fast AI training jobs
With I/O rates on EBS reaching 20 times quicker than S3, storage architecture dictates AI success. Your current cloud storage configuration is likely the primary bottleneck preventing scalable AI performance and cost efficiency.
You will learn why block storage often outperforms file storage for high-velocity workloads and how to map specific data pipelines to the most efficient cloud provider solutions.
Omdia reports that enterprise cloud storage spending will surge from $57 billion in 2023 to $128 billion by 2028, yet blind investment yields diminishing returns without architectural precision. As cloud-native AI becomes the default deployment model by 2027, organizations ignoring the nuance between Amazon S3 latency and Azure Disk Storage throughput will face unsustainable operational costs. We provide concrete steps to optimize these data storage decisions, ensuring your infrastructure supports rather than stifles your AI strategy.
The Role of Specialized Storage Architectures in Modern AI Infrastructure
Object vs Block vs File Storage Architectures for AI
Object storage manages unstructured datasets where AWS S3 Express One Zone delivers single-digit millisecond latency. This architecture contrasts sharply with standard tiers exhibiting 20-100ms delays during high-concurrency reads. Google Cloud's Rapid Storage pushes performance further with sub-millisecond access and throughput reaching 15 TB/s. Block storage serves a different function by hosting server file systems via persistent volumes. These solutions prioritize consistent I/O over the massive scalability found in object repositories. File storage sits between these extremes, offering shared namespaces that often introduce higher overhead. Training speed varies drastically because I/O rates on block devices can exceed object store speeds notably. Cost structures also diverge; the Azure Blob Storage Hot tier undercuts equivalent AWS pricing by roughly 20%. Operators must weigh these variables against specific workload requirements for data structure and access patterns. High-performance object stores now apply internal key-value architectures to support production AI concurrency. Selecting the wrong tier creates bottlenecks that negate GPU compute advantages during model ingestion phases.
Align storage tiers with data temperature to optimize total cost of ownership. Cold data migration after training prevents unnecessary expenditure on high-speed access layers. Ignoring this segmentation leads to inflated operational bills without corresponding performance gains.
Mapping Training Data and Model Artifacts to Storage Tiers
Block storage hosts active file systems for training nodes where latency determines GPU utilization rates. Active datasets require high-speed access that object repositories cannot sustain during iterative model updates. Operators assign Azure Premium Block Blobs at $0.15/GB to ensure consistent I/O throughput for running jobs. This configuration prevents compute stalls caused by storage bottlenecks during massive parallel processing. Archival strategies shift dramatically once training concludes and artifacts become static references. Moving finished models to S3 Glacier Deep Archive reduces costs to $0.00099/GB The price differential creates a 150x economic incentive to tier data aggressively based on access frequency.
Performance Trade-offs: S3 Express One Zone vs EBS for I/O
Block storage delivers 20x faster I/O rates than standard object tiers, forcing a hard choice between latency and scale. Training pipelines often stall when data ingestion cannot match GPU compute cycles, making raw throughput the primary bottleneck. Standard Object storage architectures prioritize capacity over speed, creating significant delays during iterative model updates. New high-performance variants built on internal key-value architectures now bridge this gap by optimizing for concurrency rather than just cost. The price penalty for this speed is steep, as AWS S3 Express One Zone costs $0.16/GB per month. This rate represents a seven-fold increase over standard tiers, limiting economic viability to specific hot-data workloads. Operators must decide if single-digit millisecond access justifies replacing persistent volumes for inference bottlenecks. Google Cloud's Rapid Storage offers an alternative with sub-millisecond latency and 20x faster access than competitors. The table below outlines the operational constraints for each architecture.
| Feature | Block Storage | S3 Express One Zone |
|---|---|---|
| Primary Use | File Systems | Hot Data Lakes |
| Latency Profile | Consistent Low | Single-Digit Ms |
| Cost Driver | Volume + IOPS | Storage Volume Only |
| Scalability | Fixed Limits | Virtually Unlimited |
Migration to high-performance object tiers eliminates the need for complex data staging between cold storage and compute nodes. However, the lack of file system semantics in Object storage requires application-level refactoring for some legacy training frameworks. Reserve block devices strictly for stateful OS disks while shifting datasets to accelerated object tiers. This separation prevents over-provisioning expensive block capacity for data that only requires high-throughput sequential reads. The constraint shifts from pure performance to architectural compatibility with modern data loaders.
Monitoring I/O wait states prevents GPU starvation, a condition costing a substantial amount per node annually when unaddressed. Visibility into these mechanical bottlenecks links storage tier selection directly to system health metrics. Operators track data movement between cold archives and active compute layers to maintain efficiency. A significant challenge involves the 72% of organizations estimating that a notable portion of their capacity comprises dark data, which obscures true performance baselines. Differentiating signal from noise demands precise instrumentation of the data path. Architectural throughput limits clarify the mechanical link between tiering and monitoring. Standard object stores often introduce latency that starves accelerators, whereas specialized tiers eliminate this gap. NVIDIA introduced the STX tier at GTC 2026 to standardize the data path between storage and GPUs, simplifying metric correlation. This standardization allows operators to isolate whether delays stem from network transit or disk seek times. Teams distinguish between application logic errors and infrastructure constraints with such granularity. Proven observability transforms raw telemetry into actionable alerts before training jobs stall.
Mapping Hot and Cold Tiers to Model Training Speeds
CoreWeave claims to double performance by removing geographical boundaries for clients like Meta Moving training data from cold archives to hot tiers directly reduces iteration latency, whereas keeping datasets in deep freeze starves GPU pipelines. Operators balance the 160x cost variance between archive and high-performance layers against the risk of wasted compute cycles. Standard object repositories introduce unacceptable delays during massive parallel reads, forcing a shift toward specialized architectures for active learning phases. Backblaze B2 Overdrive offers networking capacity reaching up to 1 Tbps throughput to sustain these demanding workloads without congestion. Data egress charges act as a hidden tax when migrating large datasets between tiers, often eroding the savings gained from archival pricing strategies. The mechanical bottleneck shifts from disk seek time to network saturation as concurrency increases across distributed training clusters.
Selecting the wrong tier creates a false economy where cheap storage inflates total project costs through extended training durations. Align storage tiers strictly with the access patterns of each pipeline stage to avoid these inefficiencies. High-throughput requirements demand that active datasets reside exclusively on mediums capable of sustaining continuous streaming rates. Archival logic applies only after model convergence, ensuring that historical weights do not impede current computational velocity. Keeping frequent-access data in deep archive storage starves GPU pipelines, creating expensive compute idle time. This clutter obscures performance baselines and forces expensive high-performance tiers to serve low-value assets. The mechanical bottleneck arises when standard object stores cannot sustain the 1.5 GB/s per GPU throughput NVIDIA recommends. Block storage delivers notably quicker rates than object repositories, yet many architectures default to cheap capacity over speed. A stark pricing disparity exists between archive layers and active storage, validating the premium for hot data placement. Isolate active workloads to prevent latency spikes from contaminating the entire cluster. Failure to segregate these tiers results in wasted capital as GPUs wait for bytes to arrive from slow disks. Selecting the wrong tier transforms a storage decision into a direct compute loss.
Strategic Implementation Steps for Optimizing AI Data Storage Costs and Efficiency
Defining Dark Data Removal for AI Cost Reduction
Deleting inaccurate, redundant, or low-quality datasets removes dark data that inflates storage bills without improving model accuracy. Cleaning operations must precede tier migration because moving garbage to cold storage merely defers costs rather than eliminating them.
- Identify redundant training samples using hash-based deduplication tools.
- Flag low-quality entries that introduce noise into gradient calculations.
- Quarantine inaccurate records that skew inference results.
- Purge verified useless assets to free up capacity immediately.
Financial impact extends beyond simple capacity savings since reducing total volume lowers data egress charges Treat data quality as a storage architecture constraint rather than a post-processing task. High-performance tiers waste premium I/O budgets on noise when forced to serve low-value content. Retaining potential retraining data conflicts with the immediate cost of housing it. Keeping everything guarantees inefficiency. Eliminating this clutter reveals true performance baselines and prevents expensive hardware from stalling on useless reads.
Implementing Observability to Monitor Pipeline Bottlenecks
Tracking specific file types that delay AI ingestion requires deploying agents that measure transit time from storage buckets to GPU memory. Operators must instrument the data path to reveal which assets trigger latency spikes because generic volume metrics hide these mechanical failures. A mid-market e-commerce platform managing 3 million products utilized intelligent tiering to automate this detection without manual engineering analysis. Blindly migrating data ignores the access frequency pricing models that drive unexpected bills alongside performance degradation. Observability tools correlate storage class transitions with job completion times to identify misaligned tiers.
- Deploy agents at the storage gateway to log read latency per file extension.
- Tag datasets exceeding threshold delays for immediate migration to hotter tiers.
- Cross-reference access logs against billing reports to isolate cost drivers.
- Automate policy updates that move cold assets out of high-performance zones.
Media firms running video processing benefit from distributed file systems like WEKA and VAST which enable simultaneous shared access across multiple GPUs. Operators cannot distinguish between network congestion and slow storage backends without this granularity. Constant monitoring costs compete against the expense of idle compute resources waiting on data. Treat observability as a control plane requirement rather than an optional diagnostic layer.
Checklist for Migrating AI Data to Cold Storage Tiers
Migrate AI data to cold storage only after confirming retrieval windows exceed 12 hours and access frequency drops below monthly thresholds. Operators must first execute data cleaning routines to eliminate redundant artifacts. Only valid model versions should occupy expensive tiers before migration begins. Moving garbage to deep archive merely defers costs rather than solving the underlying storage bloat problem. Validate the financial threshold where egress charges
| Metric | Hot Tier Access | Cold Archive Access |
|---|---|---|
| Cost Basis | High per-GB rate | Minimal per-GB rate |
| Retrieval Latency | Single-digit milliseconds | Hours to restore |
| Best Use Case | Active training loops | Compliance retention |
Apply a strict retention policy using lifecycle configuration rules to automate the transition process. Verify that backup immutability settings remain intact post-migration to prevent accidental deletion during the freeze period. Solutions like Veeam's DataAI Command Platform provide specific controls for these AI trust infrastructure needs. Testing restoration speeds on sample datasets prevents unacceptable delays when retraining becomes necessary. Audit access logs quarterly to ensure no active jobs reference archived objects.
Critical Risks and Protection Strategies for Enterprise AI Data Assets
Defining Accidental Deletion Vectors in AI Data Lakes
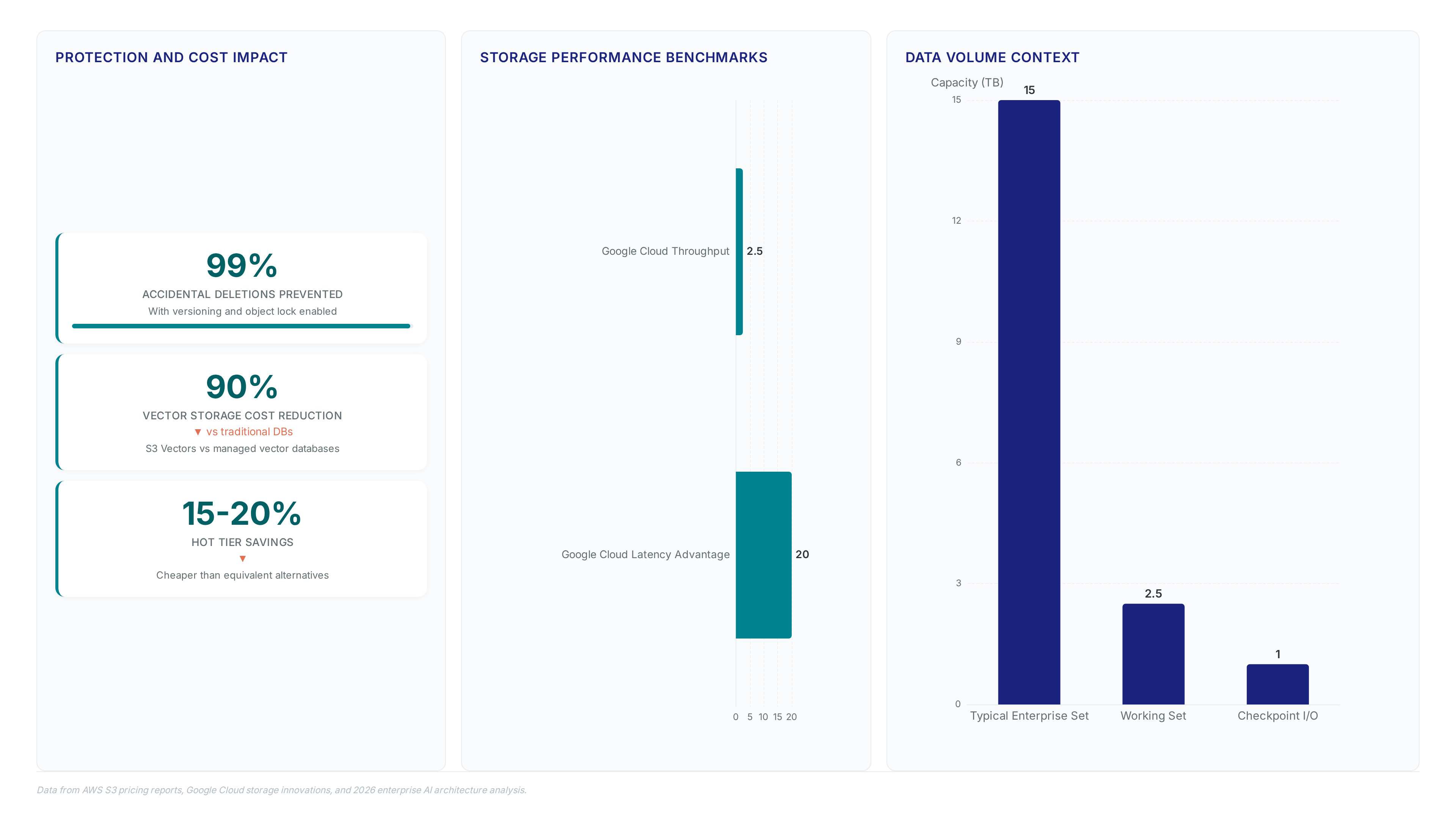
Human console mistakes and automated pipeline bugs stand as the leading causes of permanent AI asset loss in 2026. Operators often confuse aggressive data cleaning scripts with optimization tools, accidentally cutting active training sets during deduplication runs. This mechanical failure mode differs from simple user error because it executes at scale before human intervention becomes possible. A typical enterprise AI architecture in 2026 often involves three silos: S3 object storage for cheap capacity, NAS for the training-time working set, and SAN for checkpoint I/O, creating protocol boundaries that obscure deletion risks. Misconfigured lifecycle policies worsen the problem by archiving hot data based on access timestamps rather than model dependency graphs. The hidden costs of these vectors extend beyond storage bills to include massive GPU idle time.
Retraining models from scratch consumes engineering hours that exceed storage replacement value. Checkpoint corruption forces rollback to stale versions, degrading final model accuracy. Compliance audits fail when immutable logs vanish due to premature tier migration. AWS reports that S3 Vectors can offer up to 90% lower costs compared to traditional managed vector databases, yet this efficiency vanishes if the underlying dataset suffers accidental erasure. HPE announced new GreenLake innovations across private cloud, storage, and data protection to accelerate AI data readiness specifically targeting these deletion gaps. Implement immutable backup layers that sit outside standard lifecycle management rules to prevent irreversible loss. Machine-scale workloads demand a shift from human-scale protocols to prevent these mechanical failures in production environments. Operators must deploy agents that measure transit time from storage buckets to GPU memory rather than relying on generic volume metrics. The market now sees solutions preventing I/O starvation by enabling multiple GPUs to train models on the same files simultaneously through shared access.
Hidden costs accumulate silently beneath surface-level throughput metrics:
- Data egress charges for moving artifacts between zones.
- GPU idle time during unexpected latency spikes.
- Storage overhead from uncleaned redundant datasets.
- Engineering hours spent debugging opaque pipeline bottlenecks.
- Penalties for violating data sovereignty laws during cross-border replication.
CoreWeave demonstrates the value of removing geographical boundaries, claiming to double performance over traditional setups for clients like Meta . However, observability tools introduce their own consumption overhead, requiring careful tuning to avoid masking the very stalls they aim to detect. This tension means operators cannot simply maximize monitoring depth without risking further I/O starvation during peak training windows. Configure immutable alerts that trigger before job queues drop, ensuring data protection against both deletion and performance collapse. Proven pipeline observability correlates storage class transitions with completion times to identify misaligned tiers before they corrupt model artifacts. Ignoring these signals leaves enterprises vulnerable to the same bottlenecks that plague less mature AI storage architectures.
Financial Exposure from Unmonitored Data Transfer Frequencies
Untracked access patterns trigger budget overruns because cloud pricing models charge heavily for frequency rather than just volume. Operators frequently overlook that data egress charges. The mechanism fails when lifecycle policies migrate data based on age instead of actual read/write frequency, forcing expensive retrievals from cold tiers. Blind optimization creates a tension between archival savings and operational agility, often resulting in premature data deletion to cap monthly spend.
Hidden financial risks include:
- Unexpected fees for cross-region replication during model retraining cycles.
- Penalties for early deletion before minimum storage duration clauses expire.
- Compounded costs from repeated failed inference attempts pulling identical assets.
- Surcharge fees for bursting beyond provisioned throughput limits.
- Premium charges for emergency data retrieval from deep archive tiers.
| Metric | Unmonitored Pipeline | Observed Pipeline |
|---|---|---|
| Cost Predictability | Low | High |
| Tier Alignment | Poor | Optimized |
| Budget Variance | Significant | Minimal |
Google Cloud's Rapid Storage architecture demonstrates that co-locating data with compute reduces these transfer frequencies entirely. Anthropic uses this Rapid Cache approach to improve workload durability by eliminating unnecessary data movement between zones. The limitation remains that most legacy observability stacks track volume metrics while ignoring the specific file types driving these transfer spikes. Implement granular pipeline monitoring to correlate storage class transitions with job completion times before costs spiral. Failure to instrument the data path forces architects into reactive compromises that degrade overall system performance.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in S3-compatible object storage and AI/ML data infrastructure. His deep technical background makes him uniquely qualified to analyze how cloud storage configurations impact AI workload performance. Having previously worked as a Solutions Engineer at Wasabi Technologies and a DevOps Engineer for Kubernetes-native startups, Marcus possesses firsthand experience optimizing data pipelines for scalable machine learning applications. At Rabata. Io, a provider focused on high-performance, cost-effective storage for enterprises and AI startups, he daily addresses the challenges of data intensity and vendor lock-in. This article connects his practical expertise in building fast, transparent storage solutions with the surging market demand for AI-ready infrastructure. By using his insights into S3 API implementation and mixed operation speeds, readers gain a clear understanding of why storage architecture is critical for navigating the projected growth in enterprise cloud spending.
Conclusion
Scaling AI workloads reveals that latency spikes during concurrency often dwarf the nominal savings of cheaper storage tiers. When inference pipelines stall waiting for data retrieval, the operational cost of idle compute rapidly erodes any margin gained from selecting lower-priced buckets. Architects must recognize that throughput starvation becomes the primary bottleneck long before capacity limits are reached, forcing a shift from price-per-gigabyte models to cost-per-access-pattern evaluations.
Organizations should mandate a quarterly storage architecture review starting next fiscal quarter, specifically targeting datasets with high read-frequency variance. Do not rely on age-based lifecycle policies alone; instead, align storage classes with actual access heatmaps derived from pipeline logs. If your current setup cannot guarantee sub-100ms access for active training sets without incurring burst charges, migrate those specific objects to premium block storage immediately, regardless of the higher unit price.
Start by auditing your top ten most expensive retrieval events from last week's billing report before Friday. Identify which jobs triggered early deletion penalties or cross-region fees, then tag those specific prefixes for exclusion from automated cold-tier migration rules. This immediate containment prevents further budget leakage while you build a more reliable, frequency-aware tiering strategy.
Frequently Asked Questions
Block storage delivers I/O rates roughly twenty times faster than object alternatives. This speed prevents GPU starvation during high-concurrency reads required for iterative model updates.
Operators assign Azure Premium Block Blobs at $0.15 per GB for running jobs. This pricing ensures consistent throughput needed to prevent compute stalls during massive parallel processing.
Moving finished models reduces costs dramatically to $0.00099 per GB each month. This strategy creates a massive economic incentive to tier data based on access frequency.
Google Cloud Rapid Storage provides sub-millisecond access with throughput reaching 15 TB per second. This performance pushes boundaries far beyond standard tiers exhibiting significant delays.
The Azure Blob Storage Hot tier undercuts equivalent AWS pricing by roughly 20%. Operators must weigh these variables against specific workload requirements for data structure.
