Data plane fixes: Why 2026 AI needs trusted access
Hammerspace reports 2026 bookings are already 14 times greater than their entire 2025 total. Compute is no longer the bottleneck; data access is. The industry must discard legacy storage management for a Trusted Data Plane that unifies distributed unstructured data into a single, secure global namespace. This shift is mandatory. With JLL projecting AI workloads will constitute half of all data center traffic by 2030, organizations failing to implement continuous classification and policy-controlled access face catastrophic governance failures.
AI initiatives stall because of fragmented data sprawl across edge sites, legacy NAS, and multi-cloud environments, not GPU shortages. Hammerspace addresses this data gravity by mobilizing assets in place. Secuvy overlays continuous discovery to ensure sensitive information never enters a pipeline without proper tagging. Together, they transform static repositories into flexible, AI-ready sources where security attributes travel inherently with the data rather than relying on external, brittle perimeter defenses.
This article details the mechanics of establishing a global namespace that eliminates I/O stalls in high-performance GPU clusters. Managing storage volumes is dead. The only viable path forward treats performance and security as intrinsic attributes of the data itself.
Defining the Data-First AI Approach Through a Trusted Data Plane
Defining the Data-First AI Approach via Hammerspace and Secuvy Partnership
A Trusted Data Plane merges scattered storage systems into one namespace while applying constant classification rules. This design tackles the friction caused by fragmented data that stops GPUs from working at full capacity, a point Hammerspace VP Sam Newnam made during the partnership announcement on 17 Mar 2026. Older models keep intelligence separate from the data layer, forcing expensive copies that break governance chains. The Hammerspace and Secuvy integration places security attributes directly inside the global namespace, letting policies move with the data instead of sitting in static silos.
Pure Storage depends on proprietary hardware extensions for similar goals. Hammerspace uses a software-first architecture to operate on commodity infrastructure without vendor locks. This difference removes the need for costly, static high-cost tiers by allowing flexible, workload-aware placement. Organizations save money by avoiding premium prices for performance they do not always use.
Deploying this model demands consistent metadata tagging across legacy systems. Many operators skip this step during initial migration. Skipping source tagging makes the continuous discovery engine useless. Sensitive information stays exposed inside AI pipelines. Governance becomes an afterthought instead of an inherent attribute of the data itself.
Mobilizing Data Gravity for Meta's 49,152 Nvidia H100 GPUs
Data gravity in AI refers to the latency penalty when massive datasets sit still while compute resources must travel to reach them. Hammerspace fights this by unifying access across edge, data center, and cloud to keep GPUs fed without stalling pipelines. The deployment at Meta shows how this works. The platform supports 49,152 Nvidia H100 GPUs by enabling thousands of units to save and load checkpoints in a synchronized fashion. This parallel NFS solution removes the I/O bottlenecks that usually plague AGI training workloads.
Idle GPU time equals direct financial loss. AWS P5 instances featuring H100 GPUs run approximately $3.90 to $7.57 per GPU hour. The cost of waiting for data movement outweighs the overhead of maintaining a global namespace. Rapid mobilization requires rigorous policy enforcement to stop sensitive data from entering unsecured pipelines. Network engineers must shift storage architecture from static silos to intent-based data movement. This approach delivers just-in-time content to available compute. Underutilized hardware and inflated cloud bills result from failing to mobilize data. Treating data location as a flexible variable rather than a fixed constraint is necessary for success.
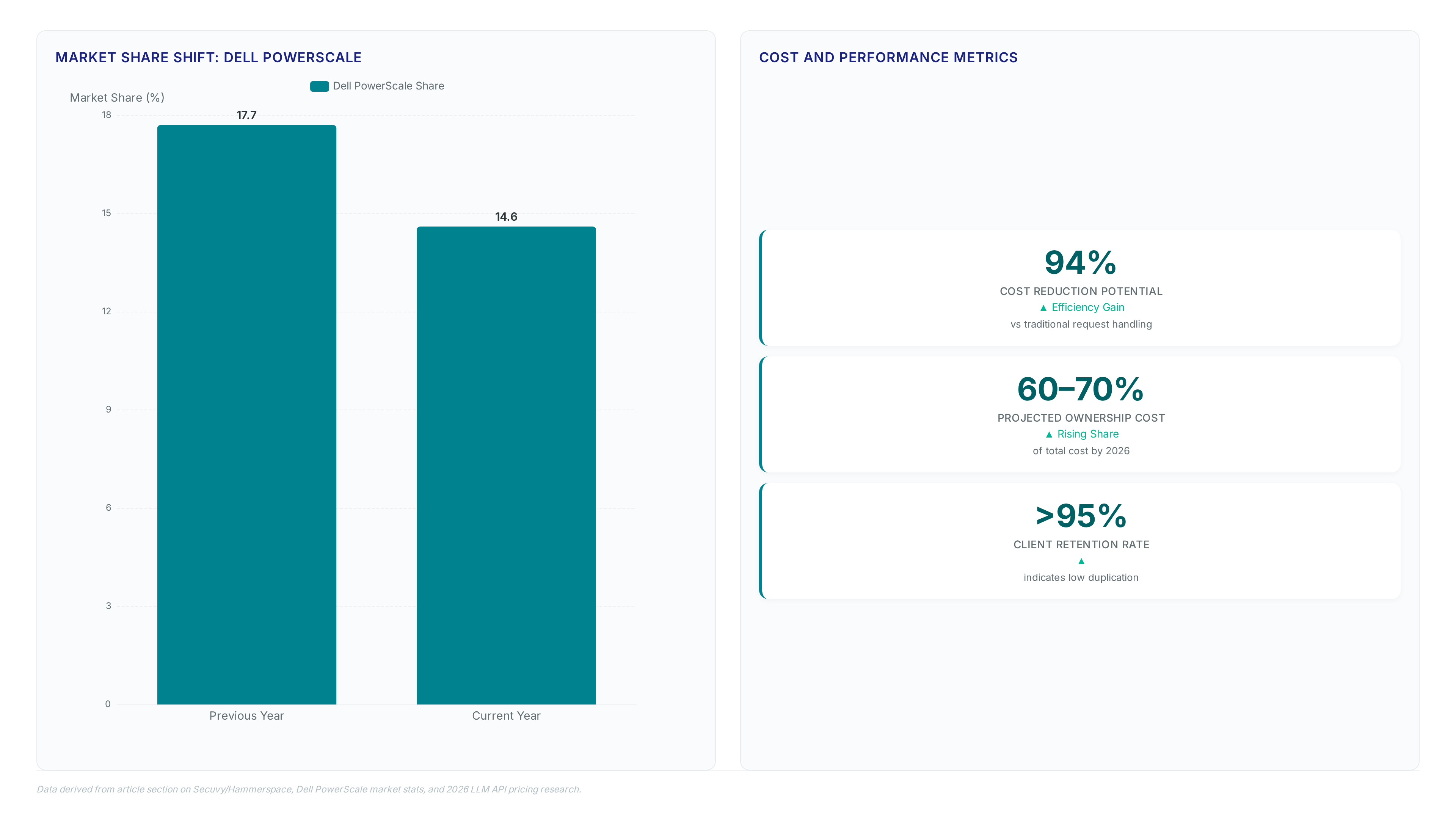
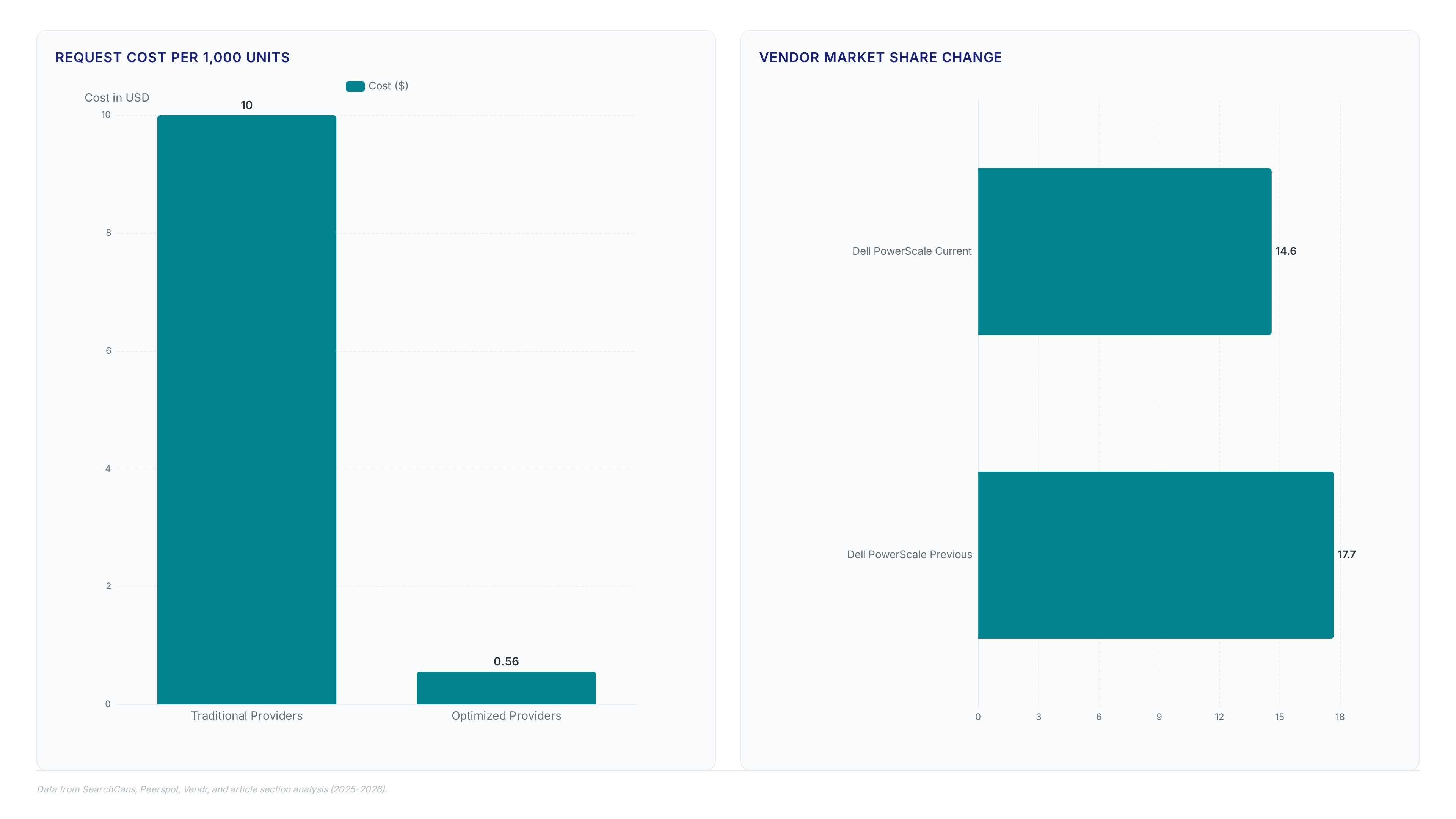
Compute-first architectures fail because fragmented storage prevents GPUs from accessing training data fast enough. A data-first strategy flips this model by creating a unified namespace that moves information to the processor instead of forcing compute to migrate. This architectural shift drives measurable market adoption. Recent booking volumes reached 14 times greater than the previous annual total. Traditional NAS vendors lose relevance as their siloed designs fail to support parallel AI workloads. Dell PowerScale NAS mindshare dropped to 14.6% by mid-2026, reflecting operator frustration with legacy file systems that cannot decouple metadata from physical disks.
Copying data for security scanning creates unacceptable latency in production pipelines. Hammerspace avoids this penalty by assimilating metadata to address data gravity challenges that trap datasets in static locations. NetApp relies on inexpensive hard drives that introduce parity calculation delays incompatible with GPU feed rates. Operators adopting this approach eliminate the friction of moving terabytes for every policy check. Complexity remains the limitation when migrating away from entrenched vendor locks. Evaluate namespace unification before purchasing additional accelerator hardware.
Mechanics of Unifying Distributed Data with Global Namespace and Continuous Classification
The Hidden Costs and Audit Failures of Duplicating Data for AI Training
Anvil metadata servers replicate state bi-directionally across up to 32 tested sites to construct a single logical view. This architecture uses an eventually consistent model for the global namespace, allowing distributed file and object data to appear local without moving payload bytes. Standard protocols like NFS and SMB access this unified layer through standard file/object protocols without requiring proprietary client software installation on compute nodes. The system decouples metadata operations from storage backends, enabling high-speed NVMe SSDs to cache directory structures while bulk data remains stationary.
| Metadata Scope | Local to appliance | Global across 32 sites |
|---|---|---|
| Consistency Model | Strong (local only) | Eventually consistent (global) |
| Client Requirement | Proprietary agents | Native OS drivers |
| Data Movement | Copy-heavy | Metadata-only replication |
Continuous data classification functions as a metadata attribute attached to files rather than a separate scan process. Secuvy integrates with this stream to tag sensitive content instantly as the bi-directional replication synchronizes changes between edges. Operators gain a global view of unstructured assets without proliferating copies that break governance chains. The limitation of eventual consistency introduces brief latency windows where policy updates at one site may not reflect immediately at another distant node. This cost favors availability over immediate strict consistency, which suits AI training workloads needing massive parallel read access more than transactional banking systems.
The cost of duplication extends beyond storage fees; it introduces unmanageable risk where auditing becomes impossible. However, relying on eventual consistency for the global namespace introduces a brief window where policy updates might lag behind rapid file changes. Network engineers must accept this latency constraint to achieve the scale required for modern GPU clusters. The drawback is clear: real-time policy enforcement across 32 tested sites requires tolerating minor synchronization delays. Deploy this stack where data sovereignty rules prohibit cross-border replication entirely.
Data duplication fractures governance, allowing sensitive information to enter AI pipelines without clear lineage or policy enforcement. Copying datasets for training creates siloed versions that evade central auditing tools, making it impossible to track where PII or financial IP resides once scattered across multiple storage tiers. This fragmentation forces operators to pay premium prices for static high-cost tiers rather than using a flexible, workload-aware approach. Projected cloud costs for on-prem equivalents consume 60–70% of total TCO when redundant copies bloat the estate. Without a single multi-protocol global namespace, teams cannot apply consistent FIPS 140-3 validated cryptography across edge and cloud locations simultaneously. Continuous classification fails when the source of truth diverges from the training input. Operators must reject copy-first architectures because governance breakdown occurs immediately upon the first unauthorized duplicate. Secuvy integration enforces policy before movement, ensuring no unclassified data reaches the training cluster. This prevents the common failure mode where sensitive data slips into models simply because an old copy existed outside the security perimeter.
Implementing Policy-Controlled Access and Continuous Compliance for AI Pipelines
Configuring Secuvy Intelligence for Continuous Sensitive Data Identification
Operators deploy the Secuvy intelligence layer to continuously identify sensitive data risks without moving underlying files. This process begins by mapping classification tags for PII, PHI, and financial IP directly to Hammerspace mobility policies. The integration creates a Trusted Data.
- Enable continuous discovery across file and object stores before data enters AI workflows.
- Apply privacy controls based on attribute risk rather than static directory paths.
- Trigger intent-based movement only when Secuvy flags specific compliance requirements.
The Nvidia GTC 2026 Continuous scanning prevents governance breakdowns where duplicated datasets evade central auditing tools. A significant limitation exists: operators must tune scan frequency to avoid I/O contention on legacy NAS backends during peak training windows. Excessive metadata polling can degrade throughput for small-file workloads if not throttled correctly. The implication is clear: successful deployment requires balancing scan depth with performance SLAs to maintain GPU utilization rates. Validate policy logic against a subset of production data before global enforcement.
Deploying Hammerspace Global Namespace on Standard Linux Servers for Multi-Cloud AI
Install the orchestration layer on commodity Linux hardware to unify distributed storage across edge and cloud environments without proprietary client software.
- Provision standard servers with NVMe SSDs to host Anvil metadata servers.
- Configure export points for NFS and SMB protocols, creating a single multi-protocol global namespace accessible by all AI compute nodes.
- Map Secuvy classification tags to mobility policies, ensuring data moves only when risk profiles permit transfer.
This architecture eliminates the need for specific client software on GPU workers, unlike parallel file system competitors that require protocol translation layers. The deployment creates a unified view where data remains stationary until intent-based logic triggers movement to the right compute resource. Operators avoid paying premium prices for static high-cost tiers by using a flexible approach that uses existing storage assets. A significant tension exists between latency requirements and governance depth; deep packet inspection for continuous compliance introduces processing overhead that can stall high-throughput training jobs if not offloaded to dedicated metadata planes. The Data-First model resolves this by decoupling security checks from data payload transfers, allowing governance to proceed in parallel with model training. Isolate metadata traffic on separate network interfaces to prevent classification latency from impacting model convergence rates.
Validation Checklist for Preventing Data Duplication and Governance Breakdown
Verify lineage integrity before any dataset enters the training pipeline to prevent uncontrolled sensitive data exposure.
- Scan all source repositories for PII and financial IP using continuous discovery tools prior to movement.
- Enforce policy-controlled access rules that block transfers of unclassified assets to GPU clusters.
- Audit metadata replication logs to confirm bi-directional sync across all edge and cloud sites.
- Calculate total cost of ownership against benchmark contract values like the $97,500 median for enterprise AI software.
- Validate that One Global View spans at least 8 sites without creating local copies.
| Control Point | Failure Mode | Required State |
|---|---|---|
| Data Location | Siloed copies | Unified namespace |
| Classification | Stale tags | Continuous updates |
| Movement | Bulk transfer | Intent-based flow |
Operators often overlook that fragmentation prevents accurate cost modeling, leading to budget overruns unseen in static reports. Maintain zero-trust principles even during aggressive development sprints. Retention rates exceeding 95% suggest that avoiding duplication preserves long-term architectural stability. Contract values like the $97,500 benchmark highlight the financial stakes of inefficient data handling. Teams must balance velocity with control to sustain operations through 2026 and beyond.
Comparing Data-First Platforms Against Traditional NAS for Enterprise AI Scale
Data-first architecture shifts the bottleneck from GPU availability to I/O stalls caused by fragmented access patterns. Traditional NAS models force static data copies to compute nodes, creating governance gaps where sensitive information enters pipelines without lineage. The Hammerspace and Secuvy integration replaces this with a Trusted Data Plane that classifies data in place before movement occurs. This approach eliminates the need for proprietary client software, allowing standard NFS and SMB protocols to access a single global namespace across hybrid environments.
| Dimension | Compute-First NAS | Data-First Architecture |
|---|---|---|
| Data Movement | Copy-heavy, static tiers | Intent-based, just-in-time |
| Security Scope | Perimeter-only, post-ingest | Continuous, attribute-driven |
| Hardware Lock-in | Proprietary controllers required | Commodity Linux servers |
Operators avoiding data duplication prevent the governance breakdown that typically obscures PII location during scaling. Market shifts reflect this operational reality, as legacy vendors lose mindshare while platforms enabling a flexible, workload-aware approach. The limitation remains the complexity of mapping classification tags to mobility policies without introducing latency. However, the cost of ignoring this friction exceeds the engineering overhead, as stalled GPUs consume budget without generating model improvements. Deploy this stack to unify distributed unstructured data before expanding AI workloads.
Scaling AGI Development at Meta with 49,152 Nvidia H100 GPUs
Meta co-developed a parallel NFS solution supporting 49,152 Nvidia H100 GPUs to enable synchronized checkpoint operations across two equal clusters. This parallel network file system deployment eliminates the I/O serialization bottlenecks inherent in traditional NAS architectures during massive model training. Standard file systems force sequential writes that stall GPU utilization, whereas this global namespace allows thousands of processors to save state simultaneously without locking conflicts. The limitation remains that such scale demands precise metadata orchestration; Anvil metadata servers. Without this layer, checkpoint failures would cascade, wasting expensive compute cycles on stranded training jobs.
| Feature | Traditional NAS | Hammerspace Global Namespace |
|---|---|---|
| Checkpoint Concurrency | Serialized writes cause GPU idle time | Parallel writes sustain full cluster utilization |
| Data Location | Static copies required at compute site | Data accessed in-place across hybrid sites |
| Protocol Overhead | Proprietary clients often mandatory | Standard NFS/SMB without client installs |
Operators face a tension between data locality and governance; moving data closer to compute reduces latency but fractures security policies. The Meta AGI development environment proves that unified access prevents the governance breakdowns seen when teams duplicate datasets for performance. Traditional approaches sacrifice audit trails for speed, while this architecture maintains a single source of truth. Validate checkpoint throughput under load before committing to static storage tiers for large-scale AI workloads. Legacy vendors struggle with data gravity challenges that fragment access across hybrid environments. NetApp FAS Series holdings similarly contracted to 10.6% as operators abandon static tiers for flexible orchestration. The shift reflects a broader market volatility where hardware-centric models lose relevance against software-set challengers.
| Metric | Legacy NAS Vendors | Hammerspace Platform |
|---|---|---|
| Market Trajectory | Declining mindshare | 10x revenue growth |
| Architecture | Proprietary hardware locks | Commodity Linux servers |
| Data Mobility | Copy-heavy workflows | In-place access |
Meanwhile, operators face a tension between maintaining existing storage contracts and adopting agile architectures that support AI scale. Traditional systems force data duplication to reach compute nodes, inflating costs and breaking governance chains. Hammerspace decouples data from infrastructure to create a Global Data Environment. This approach eliminates the latency penalties associated with moving petabytes of training data. The cost of sticking with legacy NAS extends beyond capital expenditure to include missed AI opportunities due to stalled pipelines. Fragmented data prevents continuous classification, leaving sensitive information exposed within model training sets. Audit current storage contracts for exit clauses before Q4 2026 planning cycles begin. Failure to address data friction now locks enterprises into inefficient patterns that cannot support next-generation AGI workloads.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in designing scalable S3-compatible storage infrastructures for AI and machine learning workloads. His deep expertise in Kubernetes persistent storage and data plane optimization makes him uniquely qualified to analyze the critical need for a trusted data plane in modern hybrid environments. In his daily role, Chen architects solutions that eliminate vendor lock-in while ensuring high-performance data access across distributed clouds, directly mirroring the challenges addressed by the Hammerspace and Secuvy partnership. As Rabata. Io focuses on providing GDPR-compliant, cost-effective object storage for enterprise AI, Chen understands firsthand how unifying data governance with fast, secure access is necessary for scaling AI initiatives. His background in DevOps and cloud architecture allows him to bridge the gap between theoretical data strategies and the practical realities of deploying AI-ready data platforms globally.
Conclusion
Scaling AI clusters exposes a critical fracture: latency becomes the primary bottleneck long before compute capacity hits its ceiling. When training jobs stall waiting for petabytes to copy across fragmented silos, the operational burn rate eclipses hardware acquisition costs. Static storage tiers cannot sustain the flexible I/O patterns required by 2030 workloads, where AI tasks will dominate half the data center. Continuing to pay for redundant copies simply to bridge access gaps is financially unsustainable as model complexity grows.
Organizations must decouple data orchestration from physical hardware immediately to survive this transition. Do not wait for contract renewals; begin migrating to software-set global namespaces now if your current latency exceeds 50 milliseconds during peak training loads. This shift prevents the stagnation seen in declining legacy vendor holdings and ensures your infrastructure adapts to fluid compute demands rather than forcing data to move.
Start by auditing your top three storage contracts for early termination clauses before the end of this month. Identify exactly where data duplication inflates your TCO and map those specific workflows to a unified access layer. This single administrative step unlocks the agility needed to support next-generation models without requiring a complete rip-and-replace of your existing disk arrays.
Frequently Asked Questions
Idle GPU time causes direct financial loss during AI training workflows. AWS P5 instances featuring H100 GPUs run approximately $3.90 to $7.57 per GPU hour, making data delays incredibly expensive for enterprises.
The platform successfully supports Meta's deployment of thousands of synchronized GPUs for checkpointing. This parallel NFS solution enables 49,152 Nvidia H100 GPUs to save and load data without stalling pipelines.
Older models force expensive data copies that break governance chains and expose sensitive information. This approach creates static silos where security attributes cannot travel inherently with the data itself.
Continuous discovery engines ensure sensitive information never enters a pipeline without proper tagging first. Security attributes are placed directly inside the global namespace so policies move with the data.
Skipping source tagging makes the continuous discovery engine completely useless for identifying risks. Consequently, sensitive information stays exposed inside AI pipelines, turning governance into an afterthought.
