Amazon S3 consistency: What 2006 tape libraries taught us
Amazon S3 now holds an immense number of objects across hundreds of exabytes, a scale unimaginable at its 2006 launch.
The trajectory from fragile tape libraries to resilient cloud data lakes proves that Amazon S3 has fundamentally rewritten the economics of enterprise storage. We need to look past the marketing slides and examine the internal mechanics enabling 11 nines of durability while maintaining API compatibility for data stored two decades ago. The shift from brittle NFS targets to reliable SMB capabilities within the S3 File Gateway eliminated the downtime that once plagued SQL environments. Today, Intelligent Tiering and Terraform automation drive hybrid cloud strategies, allowing organizations to archive data for fractions of a penny without manual intervention. AWS reports that while early adopters like SmugMug struggled with limited tooling in 2006, modern engineers use Rust-optimized code paths to manage vast datasets effortlessly. The cloud storage frontier is now fully automated.
The Evolution of Cloud Storage from Tape Libraries to S3 Data Lakes
2010 Tape Library Replacement Economics and S3 Evaluation
On March 14, 2006, AWS launched Amazon S3 This release replaced physical tape libraries with a scalable object storage architecture. Drive capacities had previously grown from tens of gigabytes to tens of terabytes. Media handling remained a manual bottleneck for operators managing backup windows. The shift eliminated mechanical seek times and offline media retrieval. A new baseline for data durability emerged without human intervention.
Early economic models favored tape for long retention. Internal validation occurred when Amazon.com switched its Oracle database backups from tape to S3 in 2011. This migration proved cloud primitives could handle enterprise transactional loads previously reserved for dedicated hardware. However, a 2010 evaluation of a 30 terabyte tape library revealed S3 pricing misaligned with strict backup budgets for long retention data. Operators faced a steep learning curve without prior cloud experience. Economic modeling replaced immediate deployment in the decision matrix. Tape media offered the lowest cost per gigabyte at that specific juncture. Direct migration proved financially unviable for many enterprises. The decision matrix prioritized capital expenditure avoidance over operational toil reduction despite the allure of eliminating physical media handling.
S3 vs Tape Backup: Cost Alignment and Operational Trade-offs
Physical tape requires manual intervention for retrieval. Amazon S3 provides immediate remote access without site visits. Cloud storage did not align with strict backup budgets during that era. This flexible shifted when Amazon.com internally verified the model by migrating Oracle database backups from tape to S3 in 2011 The operational benefit eliminated the need for administrators to drive through snowstorms to fix offline drives. Mechanical latency gave way to API-driven availability. Modern FinOps maturity accelerates this transition. The share of organizations with the cost programs has nearly doubled alongside rising chargeback adoption rates. Five distinct advantages now define the modern storage environment.
Organizations like Harman reversed increasing expenditure trends by migrating long-term backups to Glacier Instant Retrieval. The cost is the loss of air-gapped physical isolation inherent to removed media. Cloud cost optimization now demands analyzing access patterns rather than just media price per gigabyte. Operators must weigh the operational toil of hardware maintenance against the complexity of managing lifecycle policies. Two competing factors dictate the final architecture choice for most teams.
Inside S3 Architecture: Strong Consistency and Intelligent Tiering Mechanics
Strong Consistency Mechanics in Amazon S3 Object Operations
Amazon S3 now guarantees read-after-write consistency for all PUT and DELETE requests across its vast number of stored objects. This architectural shift eliminates the race conditions where applications previously polled for object existence before triggering downstream workflows. The mechanism operates by synchronizing metadata index updates with data plane writes, ensuring the namespace state reflects the latest operation immediately upon handler acknowledgment. Operators no longer require exponential backoff logic or version-id polling loops to validate data presence. The transition occurred entirely behind the scenes, mirroring the quiet transformation observed in late 2025 where storage evolved into a data operations layer. Implementing this model simplifies codebases by removing conditional checks that once accounted for propagation delays.
| Legacy Eventual Model | Modern Strong Model |
|---|---|
| Requires retry loops | Single request suffices |
| Risk of stale reads | Immediate data visibility |
| Complex state validation | Deterministic behavior |
Instant data visibility does not remove the requirement for optimal access patterns. Bynder demonstrates that cost efficiency still demands coupling consistency with intelligent storage classes to manage 175 million assets. Physical distance to the region endpoint remains the primary determinant of round-trip time rather than index synchronization delays. Applications must still optimize TCP window sizes and connection pooling to fully apply the guaranteed consistency model without incurring throughput penalties. Continuous monitoring shifts data to lower-cost tiers without operational overhead or retrieval latency penalties. Bynder achieved a 65% cost reduction by deploying this storage class for fluctuating workloads, proving that automated tiering outperforms static rules for unpredictable access.
Manual lifecycle policies introduce risk when retention schedules mismatch actual usage, often leaving hot data in expensive tiers or forcing costly restorations. Storing 500 TB entirely in S3 Standard incurs $11,500 monthly, whereas proper classification drives progressive cost evolution toward optimal spend. Operators who skip automation face $138,000 annual bills instead of using flexible optimization. Upstox avoided these pitfalls entirely, securing a 96% cost reduction within five months by replacing rigid policies with intelligent monitoring. Small objects under a minimal size threshold do not qualify for auto-tiering, requiring separate governance. Mission and Vision recommend auditing object size distributions before enabling automation to maximize savings potential. Failure to validate object metadata results in suboptimal tier placement despite enabled features. Operators must verify bucket settings match workload profiles to prevent unnecessary monitoring charges on cold data.
Hidden Egress Fees and Data Duplication Risks in S3 Files Architecture
Bridging object and file storage via the new S3 Files capability incurs $0.09/GB egress charges that accumulate rapidly during legacy NFS migration. Extracting one petabyte of duplicate data generates between a substantial fee and a higher fee in transfer fees before applications even process the bytes.
Hybrid Cloud Integration via S3 File Gateway and Terraform Automation
SMB Protocol Advantages Over Brittle NFS in S3 File Gateway
Windows database servers previously crashed during NFS gateway updates, forcing full SQL environment reboots that shattered uptime SLAs.
- Replace the brittle NFS target with an SMB-enabled S3 File Gateway to eliminate protocol translation failures on Windows clients.
- Configure the gateway to present a native SMB share, allowing Apollo Tyres and similar enterprises to resolve NAS capacity constraints without application refactoring.
- Automate the deployment using Terraform to enforce consistent security policies across hybrid boundaries.
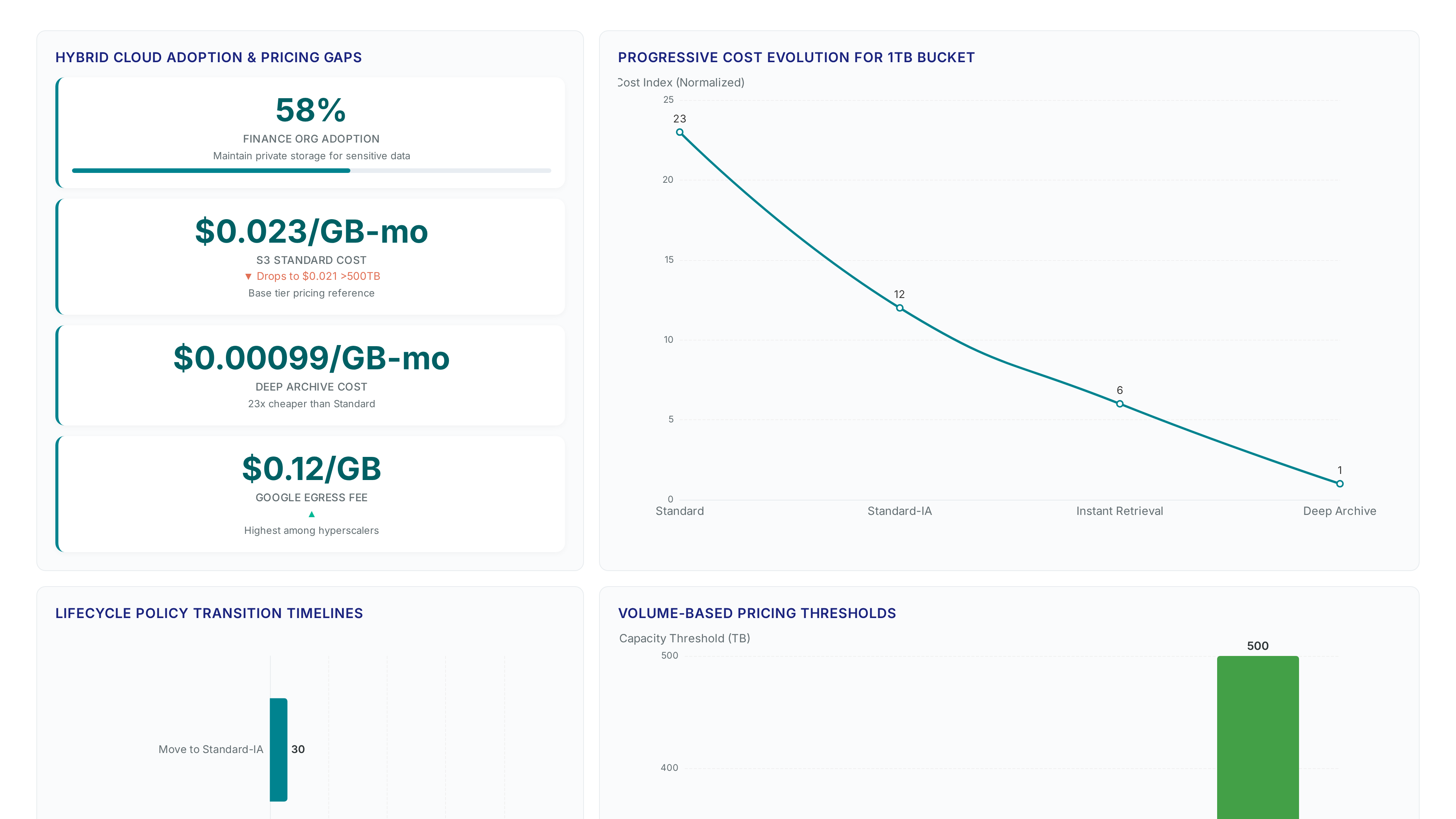
The shift to SMB removes the maintenance window previously required for EC2 host patching, directly improving data security posture. Hybrid cloud adoption now allows 58% of finance organizations to keep sensitive data private while using public cloud scale. Unlike the eventual consistency models of early object stores, this architecture supports active database workloads requiring immediate read-after-write guarantees. The limitation remains that SMB introduces latency overhead compared to native S3 API calls, making it unsuitable for high-throughput analytics pipelines. Operators must balance the need for legacy application compatibility against the performance penalty of file protocol encapsulation. Mission and Vision recommends validating throughput requirements before migrating petabyte-scale active datasets.
Automating S3 File Gateway Deployments with Terraform to Prevent Drift
Terraform definitions lock the SMB protocol configuration to prevent manual edits that previously forced SQL environment reboots.
- Define the `aws_storagegateway_gateway` resource with a specific activation key and region to establish the hybrid boundary.
- Attach an `aws_storagegateway_nfs_file_share` block configured for SMB only, eliminating the brittle NFS behavior observed in legacy Windows deployments.
- Apply the plan to provision the gateway on Amazon EC2, replicating the architecture standardized and presented at AWS re:Invent in 2018.4. Enable versioning on the backend bucket to support the strong consistency model required for immediate metadata visibility.
State file locking prevents concurrent modifications that cause configuration drift during multi-admin migrations. This discipline mirrors the approach taken by Apollo Tyres to resolve NAS capacity constraints without application refactoring. Market consolidation drives vendors to fill gaps in analytics, yet manual gateway tuning remains a primary failure point for global data mobility. The limitation of this automation is the initial learning curve for operators accustomed to console-based clicks. Infrastructure-as-Code shifts the operational burden from reactive patching to proactive version control. Mission and Vision recommends treating the Terraform state as the single source of truth for all gateway parameters.
S3 Standard vs Glacier Deep Archive Pricing for Migration Tiers
S3 Glacier Deep Archive costs $0.00099 per GB-month, creating a 23x price gap against S3 Standard at $0.023 per GB-month. Operators must evaluate this differential before moving petabytes, as misclassification locks data behind high retrieval fees and latency penalties. The lowest cost tier targets retention periods exceeding seven years, whereas frequent access patterns demand the performance of standard storage. A rigid migration strategy often ignores access velocity, forcing expensive restorations that erase initial savings.
- Tag incoming objects with a `retention_period` key to identify long-term candidates immediately.
- Apply a lifecycle policy transitioning data to Standard-IA after 30 days of inactivity.
- Shift eligible objects to Deep Archive only after 365 days to avoid premature archival charges.
- Monitor the progressive cost evolution of a 1TB bucket to validate tiering efficiency monthly.
The storage class selection dictates the operational budget more than raw capacity alone. Choosing the wrong archive tier early in a migration project creates technical debt that compounds over time. Mission and Vision recommends validating access logs for six months before committing large datasets to cold storage.
Real-World ROI from S3 Adoption in Enterprise Data Operations
S3 as the Foundation for Modern Data Lakes and Vector Stores

January 2026 brought General Availability for Amazon S3 Vectors, pushing per-index capacity to 2 billion vectors for native AI workloads. Object storage now functions as an active data operations layer rather than a passive archive, a shift detailed in this quiet transformation The Storage-First architecture separates compute from storage resources. This separation potentially reduces Total Cost of Ownership by 90% for large-scale Retrieval-Augmented Generation tasks. Global cloud object storage markets are projected to grow from 15.5 billion USD to 45.2 billion USD by 2033 due to unstructured data demands. Native vector integration complicates index management in ways legacy backup strategies never faced. Operators must weigh index capacity limits against query latency needs, a constraint missing from simple put/get object models. Poorly configured tiering policies trigger expensive restorations that wipe out theoretical savings from intelligent storage classes. Storage design now defines application performance envelopes instead of just meeting capacity targets. Vector stores demand predictable network paths to maintain inference speeds, making storage topology a decisive factor in AI deployment success. Network bandwidth misaligned with vector index density creates bottlenecks that additional compute scaling cannot.
Real-World Cost Reductions: Bynder, Upstox, and Harman Case Studies
Harman reversed rising expenditure trends by moving long-term backups to Amazon S3 Glacier Instant Retrieval This move removed the operational burden of physical media while optimizing lifecycle policies for infrequent access patterns. The mechanism monitors object access patterns to apply the most cost-effective storage class dynamically. Upstox used Amazon S3 Storage Lens to visualize usage trends, driving a drastic reduction in monthly bills within five months. These outcomes show that proper classification of cloud backup solutions yields superior financial results compared to static on-premises archives. Cost benefits depend entirely on accurate data profiling. Misclassifying hot data into cold storage triggers expensive retrieval fees that erode savings. Operators must balance immediate access requirements against long-term retention goals to avoid performance penalties. Static provisioning models fail to capture the full economic potential of object storage. Flexible tiering requires continuous monitoring rather than one-time migration events. Mission and Vision recommend auditing access logs quarterly to validate lifecycle policy effectiveness.
S3 Express One Zone Price Cuts vs Standard Storage for AI Latency
AWS slashed storage prices for S3 Express One Zone by a significant margin in 2026 to support latency-sensitive machine learning workloads. This adjustment targets the specific bottleneck of model training where standard tiers introduce unacceptable wait states during data loading. GET request costs for this tier dropped 85%, directly addressing the high-frequency read patterns inherent in AI training datasets. Standard storage remains viable for general purpose use yet lacks the single-AZ architecture Deploying Express One Zone for long-term retention invites unnecessary expense without the latency benefit. Mission and Vision recommends isolating this tier strictly to active hot paths within the data pipeline.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, bringing over two decades of hands-on experience in data storage evolution. His deep technical background makes him uniquely qualified to analyze the twenty-year path of Amazon S3, having witnessed the shift from spinning disks to modern cloud object storage firsthand. In his daily role, Chen designs scalable, S3-compatible infrastructure for AI/ML startups and enterprises, directly engaging with the same API standards established by AWS in 2006. This practical expertise allows him to critically evaluate how storage renaissance trends impact current architectural decisions. At Rabata. Io, a specialized provider focused on democratizing enterprise-grade object storage, Chen uses this historical perspective to build cost-effective, high-performance alternatives that eliminate vendor lock-in. His work bridges the gap between fundamental cloud history and the next-generation of data-intensive applications, offering readers an informed perspective grounded in real-world implementation.
Conclusion
Scale exposes the hidden tax of static storage configurations: as data volume grows, the latency penalty for misclassified assets compounds quicker than the headline storage rate declines. Operators relying on manual tiering inevitably bleed margin through unnecessary retrieval fees and idle compute cycles waiting on I/O. The economic model shifts from simple capacity planning to continuous access pattern analysis, where failing to automate lifecycle transitions creates a permanent drag on operational efficiency. You must treat storage classes as fluid compute resources rather than static buckets.
Adopt a strict policy by Q3 2026: isolate S3 Express One Zone exclusively for active model training loops and enforce automated expiration for all other workloads into Intelligent-Tiering. Do not attempt this migration without first establishing a baseline of request frequency metrics, or you will simply swap high storage costs for high retrieval bills. Start this week by enabling S3 Storage Lens metrics for your top three largest buckets and filtering specifically for objects accessed less than once every 30 days. This immediate audit reveals the exact subset of data currently inflating your bill without providing business value, allowing you to draft your first targeted lifecycle rule before the next billing cycle closes.
Frequently Asked Questions
Amazon S3 currently holds 350 trillion objects across its global infrastructure. This massive scale represents hundreds of exabytes of data stored securely since the service launched in 2006.
Organizations like Harman reduced storage costs by 50% through strategic tiering implementations. Proper classification drives significant savings compared to storing all data exclusively in the standard storage class.
Early evaluations favored tape because it offered the lowest price for long retention data at that time. S3 pricing had not yet dropped enough to align with strict backup project budgets.
SMB capabilities eliminate the brittle connections and forced reboots previously experienced with NFS targets on Windows database servers. This change significantly improves uptime and simplifies maintenance for SQL environments.
S3 Intelligent-Tiering eliminates hours of manual metadata study by automatically moving data based on access patterns. This single setting change guarantees cost efficiency without risking misconfigured lifecycle policy spikes.
