Data readiness bottlenecks: Why AI stalls now
Server DRAM prices surged 90–95% quarter-over-quarter. Storage just displaced compute as the primary economic constraint in enterprise AI. Data readiness now dictates production viability. As Jim O'Dorisio notes in this HPE partner analysis, organizations moving from experimental pilots to steady-state operations find model capability matters less than the architectural mechanics of accessing governed, long-lived data.
Hybrid computing paradigms are becoming mandatory. Gartner predicts 40% of leading enterprises will adopt them by 2028 to manage these complex workflows. (Gartner's cisco systems vs hewlett packard enterprise hpe) This article dissects the architectural mechanics required to support Retrieval-Augmented Generation (RAG) without incurring prohibitive data movement taxes or creating unsafe duplicates. It details operational strategies for optimizing pipelines where data spans multiple generations of object, file, and block systems under strict regulatory regimes.
Stop obsessing over raw GPU power. Focus on the unglamorous reality of storage systems that determine whether data can be trusted and accessed at the right performance tier. Early assumptions that data could be treated as local, curated, and disposable have collapsed under the weight of enterprise scale. Inefficient data preparation is no longer just a delay; it is a systemic liability that renders massive AI investments useless.
Data Readiness as the Primary Constraint in Enterprise AI
Data readiness defines the state where distributed, governed, and long-lived enterprise data sits immediately accessible for inference without costly movement. Model capability rarely limits AI progress today. Data readiness does. Seventy-one percent of organizations regularly using generative AI see no measurable EBIT impact because storage remains an afterthought. Research labs operate differently than enterprise environments. Data spans object, file, and block systems across multiple regulatory regimes. Duplication becomes a financial liability rather than a convenience in this context. Historical budget allocation favored compute heavily. Storage received leftover funding. This approach fails when data movement acts as a persistent tax on production pipelines.
Operationalizing Data Across Silos and Governance Regimes
Data operationalization requires identifying distributed assets across silos and transforming them without creating duplicate liabilities. Moving from experimental setups to production pipelines demands strict governance. Data movement becomes a persistent tax on latency and budget. Organizations must enforce security constraints while enabling high-bandwidth access for inference engines. Early deployments often miss this balance. The Enterprise Network Infrastructure market is expanding rapidly to support these complex requirements. Many architects still underestimate the cost of fragmented storage layers. Duplicate data strands increase storage costs. Consistency errors appear during model retraining. Teams frequently rebuild pipelines for each project.
From 80 Percent Compute Spend to Strategic Storage Investment
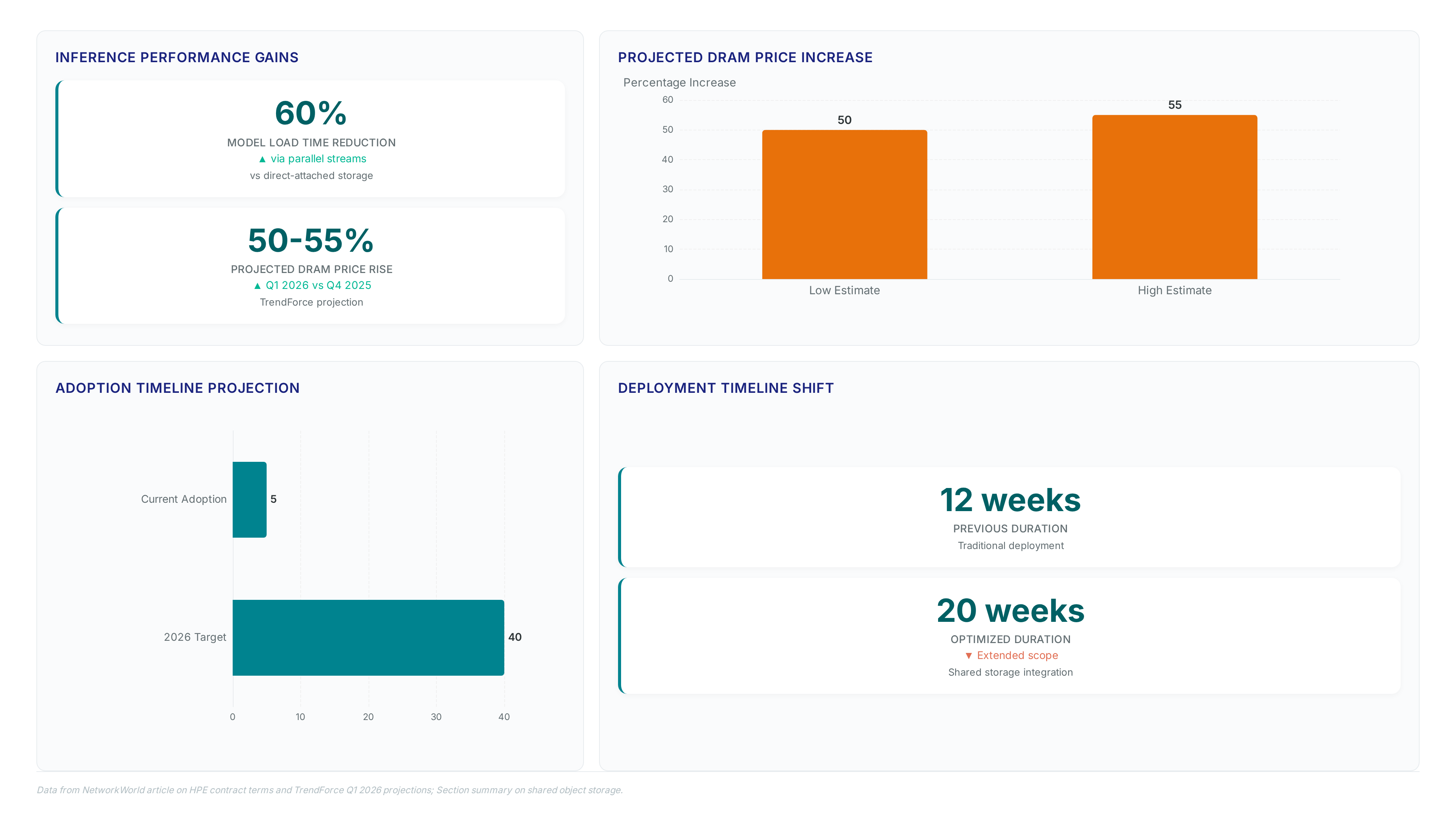
Historical AI budgets allocated 80 percent to compute. Storage became a residual line item funded only after GPU and network requirements were satisfied. This model assumed data was local and disposable. That premise collapses when server DRAM contract prices surge by 90–95% quarter-over-quarter. Memory costs now dominate total ownership. The "leftover" funding approach is financially impossible. Vendors like HPE have amended terms to allow price adjustments between quoting and shipment. Fixed infrastructure bids no longer reflect market volatility. Operators must invest in data preparation infrastructure before scaling accelerators. Margin compression awaits those who delay. Global spending on data center systems is projected to exceed $787 million in 2026. Naive architectures will waste capital on idle compute waiting for data. Rapid model deployment conflicts with latency penalties from unoptimized storage tiers. Memory price hikes become a direct tax on inference throughput when this shift is ignored. Strategic storage investment is no longer optional. It is a prerequisite for avoiding pilot purgatory.
Architectural Mechanics of Object Storage for RAG and Inference
RAG Data Scale and Continuous Inference Access Patterns
RAG systems commonly operate over datasets ranging from terabytes to tens of terabytes, demanding persistent concurrency rather than static staging. Unlike traditional analytics, this data is stored, reused, and refreshed continuously by inference engines expected to run without interruption. The shift from experimental pilots to production requires architectures that eliminate data movement taxes while supporting simultaneous access across distributed nodes. Enterprise generative AI applications with task-specific AI agents are projected to jump from less than 5% to 40% adoption within 2026, exponentially expanding the volume of unstructured documents and embeddings requiring immediate availability.
Decoupling KV Cache from GPU Locality for Cost Efficiency
Persisting KV cache in object storage reduces GPU recomputation overhead, enabling shared access across distributed inference nodes. Large language models generate key-value pairs to avoid reprocessing context tokens during sequential generation. Local GPU memory limits this cache to single-host boundaries, forcing expensive recalculation when sessions migrate or scale. Object storage breaks this locality constraint by acting as a shared persistent layer for intermediate artifacts. Multiple inference engines read the same cached state without duplication, turning a compute-bound problem into a storage access challenge. This architectural shift lowers overall GPU utilization by eliminating redundant mathematical operations on static context windows.
Energy Consumption Risks in Data Movement Heavy Architectures
Global data center electricity consumption will reach 1,050 TWh by 2027, driven largely by inefficient data shuffling in AI pipelines. Ad hoc copying solutions create redundant I/O streams that spike power draw without adding model accuracy. Teams deploy temporary scripts that multiply energy waste across clusters when storage fails to match access patterns. Local storage forces data duplication at every inference node, while shared object architectures enable single-copy access.
| Architecture Type | Data Copies Required | Power Efficiency | Scalability Limit |
|---|---|---|---|
| Local NVMe | One per node | Low | Memory capacity |
| Shared Object | Single master copy | High | Network bandwidth |
Persisting KV cache on shared systems reduces redundant compute cycles, directly lowering the thermal load on GPU racks. Naive implementation of shared storage can introduce latency spikes if network fabric bandwidth saturates during peak retrieval. Operators must balance proximity against consolidation to avoid trading electricity costs for inference delays. Small delays in data retrieval force GPUs into idle-wait states, consuming power while performing no useful work. This phenomenon turns storage architecture into a primary determinant of total cost of ownership. Ignoring data intelligence nodes as acceleration layers results in linear energy growth relative to dataset size. Mission and Vision recommends auditing data paths before scaling inference fleets to prevent irreversible efficiency debt.
Operational Strategies for Optimizing AI Data Pipelines
Defining Data Intelligence Nodes for Shared Object Access
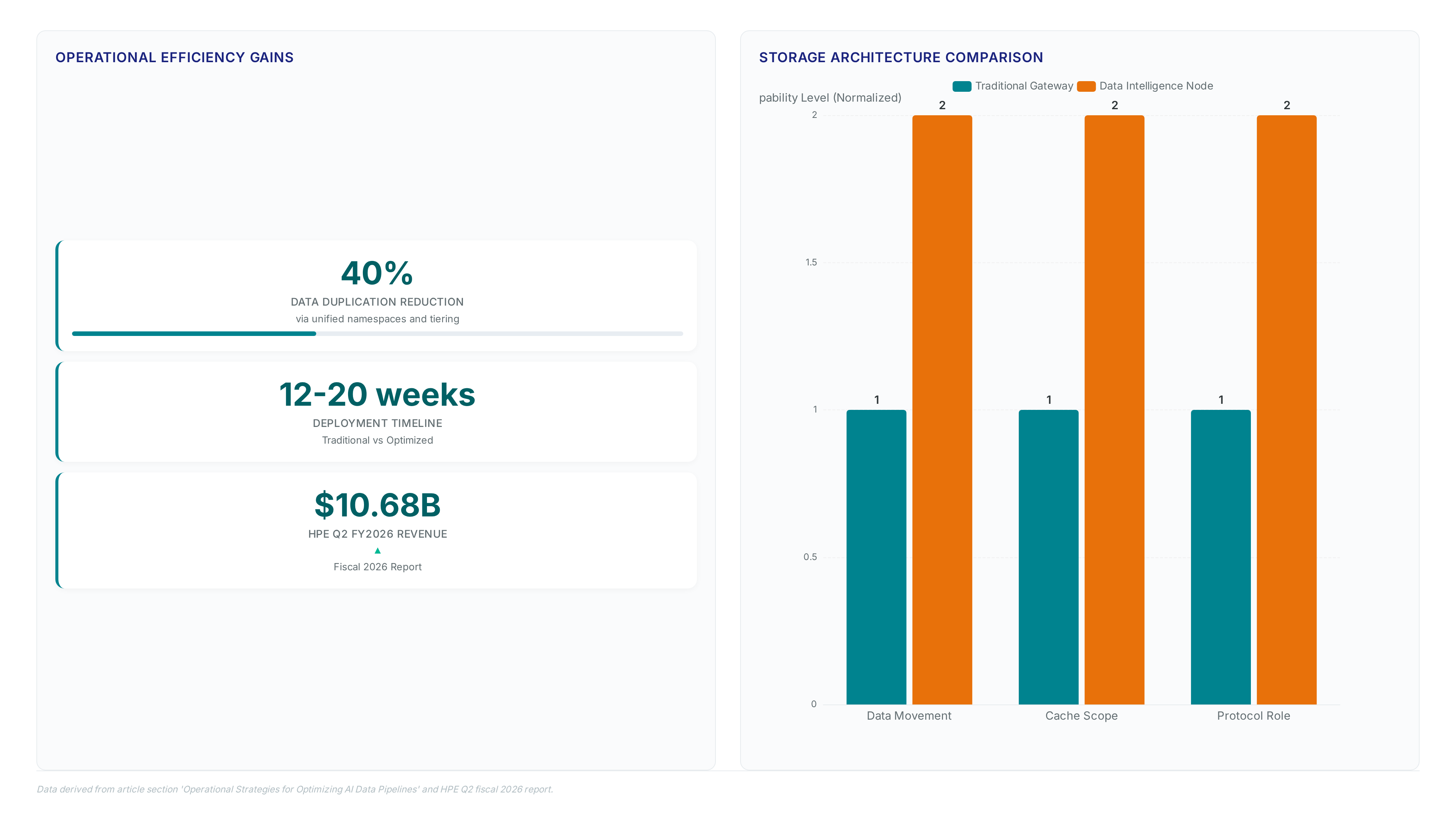
Data intelligence nodes function as specialized acceleration layers that serve shared object data without enforcing single-purpose architectural constraints. Unlike traditional gateways that merely translate protocols, these components actively manage data locality and cache coherence to support high-bandwidth AI access patterns. The HPE Alletra Storage MP X10000 platform exemplifies this design by native support for object access and shared data services required by modern inference clusters. Implementation requires decoupling the control plane from the data path to allow parallel agent workflows while maintaining strict access controls.
| Component | Traditional Gateway | Data Intelligence Node |
|---|---|---|
| Data Movement | Copy-on-read | Zero-copy shared access |
| Cache Scope | Local host only | Cluster-wide coherence |
| Protocol Role | Translation layer | Acceleration engine |
Deployments ignoring this distinction face reconciliation costs that exceed initial build expenses due to fragmented data pipelines. A critical tension exists between maximizing throughput for training batches and minimizing latency for real-time inference queries. Nodes must dynamically prioritize traffic based on workload SLAs rather than static queue depths. Failure to implement this logic results in ad hoc scripts that increase operational risk when storage cannot match demand. Mission and Vision recommends integrating these nodes directly into the HPE's Data Fabric Software layer to eliminate manual data staging. This approach ensures data readiness scales with the explosion of task-specific AI agents across the enterprise.
Aligning Storage Architectures to Eliminate Data Duplication Liabilities
Proven storage systems must serve multiple access methods without copying data to prevent pipeline stalls. Preparing data for AI requires identifying the assets across silos and transforming them without creating redundant copies. Fragmented deployments lacking a clear Generative AI Reference Architecture incur reconciliation costs that exceed initial build expenses. Teams often compensate with ad hoc scripts when storage fails to perform, introducing operational risk and hidden latency. The HPE Alletra Storage MP X10000 platform addresses this by supporting high-performance object access and shared data services natively. This design enables reuse across teams while reducing friction between data location and AI consumption points. Rising component prices complicate infrastructure planning for these shared architectures. HPE amended contract terms to allow price adjustments on orders due to memory costs driven by market volatility. TrendForce projected average DRAM prices would rise significantly in Q1 2026, forcing operators to reconsider static capacity planning. Financial pressure validates the shift toward storage-centric designs; HPE reported Q2 fiscal 2026 revenue of billions of dollars, reflecting strong demand for networks supporting AI workloads.
| Strategy | Duplication Risk | Operational Overhead |
|---|---|---|
| Local Staging | High | Significant |
| Shared Object Access | Minimal | Low |
| Ad Hoc Scripting | Variable | Critical |
The limitation of this approach lies in the complexity of migrating legacy file systems to object-native environments. Operators must balance immediate performance gains against the technical debt of refactoring existing data pipelines. Mission and Vision recommends deploying data intelligence nodes to accelerate access to shared object data without forcing fragile, single-purpose designs. This architectural alignment turns storage from a passive bucket into an active enabler of enterprise AI scale.
Checklist for Enabling High-Bandwidth Access and KV Cache Support
KV cache persistence requires shared object storage to break single-host memory boundaries and prevent redundant token reprocessing. Operators must validate that their infrastructure supports high-bandwidth access without forcing data duplication across inference nodes. Ad hoc scripts multiply energy waste when storage fails to match the continuous I/O patterns of production RAG systems. Teams lacking structured governance often face rising operational costs as they attempt to scale beyond experimental pilots. Microsoft addressed similar accessibility challenges by implementing a structured AI infrastructure governance strategy to align business priorities with technical deployment.
| Access Pattern | Local GPU Memory | Shared Object Storage |
|---|---|---|
| Cache Locality | Single-host only | Cluster-wide |
| Data Copies | Multiple redundant | Single source |
| Scaling Limit | Memory capacity | Network throughput |
Persisting intermediate artifacts turns a compute-bound constraint into a manageable storage access challenge. HPE revised its fiscal outlook because adjusted EPS 933thedrive.com/2026/06/02/hpe-surges-29-as-ai-infrastructure-boom-boosts-server-demand/) projections exceeded original targets, signaling intense demand for servers capable of these workloads. Data intelligence nodes accelerate access to shared object data while maintaining strict coherency across distributed agents. Ignoring this architectural shift forces teams to rebuild pipelines for every new project, stalling enterprise adoption. Mission and Vision recommends decoupling the control plane from the data path to support parallel agent workflows efficiently.
Deploying Shared Object Storage for Scalable Inference
Decoupled Inference Architectures via Shared Object Storage
Decoupling inference from host-local disks requires publishing upstream provider lists to the RIR to validate the full AS path. Operators shift data access from direct-attached storage to shared object pools, allowing multiple nodes to read identical datasets without local duplication. This architecture eliminates the storage tax imposed by redundant copies across a cluster. Implementing this shift demands strict adherence to specific configuration patterns to avoid latency spikes.
- Configure the storage gateway to expose a single namespace across all inference workers.
- Enable data intelligence nodes to cache frequent embeddings closer to the GPU accelerators.
- Set retention policies that align with the lifecycle of versioned model weights.
- Validate bandwidth saturation points before scaling the number of concurrent inference streams.
The cost of this transition involves coordinating metadata consistency across distributed readers. HPE InfoSight uses full-stack telemetry to optimize these environments, yet operators must still manage the tension between global consistency and local access speed. Failure to decouple storage forces teams into fragile, single-purpose designs that cannot scale with demand. The limitation is clear: without a unified object layer, inference clusters hit capacity ceilings as data growth outpaces local disk availability.
Deploying HPE Alletra Storage MP X10000 for KV Cache Patterns
Operators must configure bucket lifecycles to match KV cache volatility, preventing stale token persistence from degrading inference accuracy.
- Instantiate the HPE Alletra Storage MP X10000 cluster with erasure coding tuned for small-object write amplification common in cache updates.
- Deploy data intelligence nodes at the rack edge to serialize local GPU memory dumps directly into the shared object namespace.
- Apply tiering policies that automatically expire cache objects older than the current model context window to reclaim capacity.
This configuration decouples compute scaling from storage limits, allowing inference clusters to expand without replicating datasets.
Validation begins by measuring round-trip latency between local compute and shared pools before enabling data intelligence nodes for caching. Operators must confirm that HPE's Data Fabric Software unifies namespaces without introducing serialization delays that degrade token generation speeds.
- Benchmark raw throughput against local disk baselines to quantify the latency tax of networked access.
- Verify that cache invalidation policies align with model context window expiration to prevent stale data retrieval.
- Test failover scenarios where primary storage links drop to ensure continuous inference availability.
| Storage Pattern | Latency Impact | Data Duplication |
|---|---|---|
| Local-Only | Minimal | High |
| Shared Object | Variable | None |
| Cached Hybrid | Low | Moderate |
Teams ignoring this step risk replicating the inefficiencies seen in early deployments where software engineering productivity stalled due to data access bottlenecks. Aggressive caching improves speed but increases coherence complexity across the cluster. Mission and Vision recommends treating storage validation as a continuous gate rather than a one-time setup task. Failure to address latency sensitivity early forces expensive rip-and-replace cycles once workloads scale.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in designing scalable data infrastructure for AI and machine learning workloads. His deep expertise in S3-compatible object storage and Kubernetes persistence makes him uniquely qualified to analyze how surging AI demands are reshaping enterprise storage strategies. In his daily role, Chen helps organizations optimize data pipelines, directly witnessing the bottlenecks that occur when legacy systems fail to support high-throughput generative AI training. This practical experience allows him to articulate why storage can no longer be an afterthought in AI deployments. Representing Rabata. Io, a provider focused on cost-effective, high-performance cloud storage, Chen connects these technical challenges to real-world solutions. His insights bridge the gap between theoretical AI growth and the tangible storage architecture required to sustain it, offering a grounded perspective on navigating the current capital influx in the sector.
Conclusion
Scaling AI infrastructure reveals that DRAM scarcity will soon dictate architecture more than compute availability. As memory costs surge by over 50%, the economic model for keeping massive datasets in active RAM collapses, forcing a shift toward intelligent, tiered fabric layers. Organizations relying on static allocation strategies will face prohibitive operational expenses by late 2026 when adoption rates hit critical mass. The window to optimize before these price shocks fully materialize is narrowing rapidly. You must transition from manual tuning to autonomous policy enforcement immediately to avoid being locked into inefficient hardware contracts.
Implement a strict latency budget audit within the next seven days. Measure the precise nanosecond penalty your current networked storage adds to token generation compared to local disk baselines. If this "latency tax" exceeds 15% of your total inference time, prioritize deploying flexible caching layers before your next capacity expansion. Do not wait for performance degradation to trigger changes; proactively validate cache invalidation logic against your specific model context windows now. This specific calibration prevents the coherence errors that typically plague scaled clusters months after deployment. By anchoring your storage strategy to real-time telemetry rather than projected throughput, you secure a sustainable path forward without requiring immediate, disruptive hardware replacements.
Frequently Asked Questions
Naive architectures fail because data movement acts as a persistent tax on production pipelines. Teams forced into ad-hoc solutions see costs rise by an estimated 30% due to unpredictable workloads and inefficient data transport.
Hybrid computing paradigms are becoming mandatory to manage complex enterprise AI workflows effectively. Gartner predicts that 40% of leading enterprises will adopt these hybrid approaches by 2028 to handle data readiness constraints.
Large enterprises incur massive monthly cloud-API costs exceeding $1 million when lacking governed data access. Naive architectures cannot sustain such expenses, making strategic storage planning essential for financial viability.
Duplication becomes a financial liability rather than a convenience when data spans multiple regulatory regimes. This approach fails when workloads scale, creating consistency errors during model retraining and exhausting network bandwidth.
Storage was historically funded with whatever dollars were left over after compute and networking expenses. This passive funding approach fails today because data readiness now dictates the viability of production systems.
