S3 Express Inventory: Fixing Directory Bucket Blind Spots
Amazon S3 Express One Zone now delivers inventory reports for buckets costing $0.16 per GB, according to Amazon Web Services, Inc.
Raw speed means nothing if you cannot see your data. S3 Inventory finally lands on this high-performance tier, closing the gap between single-digit millisecond access and actionable metadata visibility. Before this update, engineers building generative AI pipelines faced a brutal choice: accept blind spots in directory buckets or kill performance with inefficient polling. That era is over. Teams can now verify compliance and optimize data pipelines without sacrificing the throughput required for real-time analytics.
This update transforms directory buckets from black boxes into auditable assets. We will dissect how asynchronous metadata reporting reshapes storage economics for latency-sensitive applications. A step-by-step configuration guide follows, detailing how to route daily reports to destination buckets so your big data jobs consume accurate object states rather than stale snapshots. Amazon Web Services, Inc. Confirms this feature is live across all regions where the storage class exists, marking a critical maturity point for premium cloud storage architectures.
The Role of S3 Inventory in High-Performance Storage Architectures
Stop using synchronous List API calls for large-scale object enumeration. S3 Inventory replaces them with a scheduled metadata reporting mechanism that eliminates latency penalties in high-throughput environments. The service generates daily or weekly reports detailing object attributes and encryption status within an S3 directory bucket. Operators configure these jobs to output data in CSV, ORC, or Parquet formats without consuming the request quota of the source bucket. This separation ensures that metadata analysis does not compete with application traffic for the 2 million GET TPS capacity available per directory bucket.
Align inventory frequency with the specific SLA requirements of downstream analytics pipelines. Do not default to maximum cadence. The cost of listing objects remains fixed at $0.0025 per million entries regardless of the storage class performance tier. Operators validate encryption status in S3 directory bucket environments by parsing scheduled metadata reports instead of executing high-latency List API calls. Amazon S3 Express One Zone serves as a high-performance storage tier designed for latency-sensitive workloads requiring single-digit millisecond access speeds.
Amazon S3 Express One Zone delivers single-digit millisecond latency, enabling data access speeds 10x faster than standard tiers for latency-sensitive workloads. This performance jump stems from co-locating compute and storage within a single Availability Zone a design pattern that eliminates cross-zone network hops. Operators gain consistent throughput for high-frequency transactions, yet face a premium storage rate compared to general-purpose classes. The architectural shift prioritizes speed over the multi-AZ redundancy found in legacy configurations.
S3 Inventory mitigates metadata costs by replacing expensive synchronous List operations with asynchronous reporting. While request costs drop by up to 50% compared to S3 Standard, the storage price per gigabyte remains significantly higher. Scheduled reports allow teams to audit encryption status without consuming the high-speed request quota needed for application traffic. This separation prevents metadata polling from degrading the single-digit milliseconds responsiveness required by real-time analytics. Teams must architect applications to handle localized outages rather than relying on implicit multi-region durability. High-performance computing clusters benefit most when the storage class aligns with ephemeral processing needs. This approach balances the financial cost of premium storage against the operational necessity of rapid data retrieval.
Internal Mechanics of Asynchronous Metadata Reporting and File Formats
Configuring S3 Inventory Schedules and Metadata Fields via AWS CLI
Define daily or weekly reporting cycles for specific object prefixes using the AWS CLI `put-bucket-inventory-configuration` command. This process requires selecting a destination S3 bucket and choosing an output format like Parquet to optimize downstream analytics performance. Configuration scripts must explicitly declare which metadata attributes to include, such as object name, size, last modified date, storage class, multipart upload flag, and encryption status.
The setup procedure follows a strict sequence to ensure valid job submission:
- Define the source scope by specifying the directory bucket or shared prefix.
- Select the report frequency, limiting generation to daily or weekly intervals.
- Assign the destination bucket where the system writes the finished manifests.
- Enable specific fields like encryption status to satisfy compliance audits without real-time scanning.
| Metadata Field | Use Case |
|---|---|
| Storage class | Cost allocation tagging |
| Multipart upload flag | Incomplete transfer detection |
| Encryption status | Regulatory compliance verification |
| Last modified date | Data lifecycle policy enforcement |
Selecting SSE-KMS for source objects introduces a dependency on key availability during report generation, unlike SSE_S3 which operates transparently. Reports listing objects with SSE-KMS encryption require the calling principal to possess decrypt permissions on the associated customer managed keys. Failure to grant these rights results in incomplete metadata rows rather than total job failure, creating silent data gaps in audit logs. This behavior contrasts with standard List API calls that return access denied errors immediately upon permission failure. Operators must validate IAM policies against both the source bucket and the KMS key policy before scheduling production jobs.
Generating Parquet and ORC Reports for Prefix-Filtered Directories
Emit Parquet files restricted to a shared prefix to eliminate full-bucket scans for analytics pipelines. Configure S3 Inventory using the AWS CLI to target specific directories rather than entire buckets. This filtering reduces downstream processing load by excluding irrelevant object metadata from the generated report. The system supports daily or weekly execution cycles without consuming the request quota of the source S3 directory bucket. Columnar formats like ORC and Parquet enable predicate pushdown, allowing query engines to skip entire data blocks during encryption compliance checks.
| Feature | CSV Output | Parquet/ORC Output |
|---|---|---|
| Query Efficiency | Low (full scan) | High (column pruning) |
| Storage Footprint | Large | Compressed |
| Analytics Integration | Manual parsing | Native support |
Big data workloads driven by generative AI demand this granular metadata access to validate training set integrity efficiently. Prefix filtering introduces operational rigidity. Changing the filter scope requires reconfiguring the job rather than querying ad hoc. Teams must balance the storage savings of narrow prefixes against the risk of missing objects outside the set path. Validate prefix patterns against flexible namespace growth before committing to weekly schedules. The cost benefit remains clear when excluding non-necessary data from high-volume analytics platforms.
Configuring the destination S3 bucket requires cross-region validation to avoid ingestion failures during high-volume report generation. Audit prefix filters monthly to align reporting scope with actual data growth patterns.
Step-by-Step Configuration for Daily Reports and Destination Buckets
S3 Inventory Configuration Parameters and Supported Metadata Fields
Daily S3 Inventory jobs require explicit definition of the source directory bucket and a valid destination S3 bucket for report storage. Operators initiate this via the AWS CLI, specifying a shared prefix to limit scope rather than scanning the entire namespace. The service supports CSV, ORC, or Parquet formats, with columnar options enabling efficient query filtering downstream.
Configuration demands precise selection of metadata fields to avoid bloating report size unnecessarily. Available attributes include object name, size, last modified date, storage class, multipart upload flag, and encryption status. Selecting only required fields reduces parsing overhead during compliance audits.
| Parameter | Required Value | Constraint |
|---|---|---|
| Source Type | Directory Bucket | General-purpose buckets unsupported |
| Frequency | Daily or Weekly | No hourly intervals available |
| Format | CSV, ORC, Parquet | Must match downstream analyzer |
| Scope | Full Bucket or Prefix | Prefix filtering reduces cost |
Reports generate without consuming the request quota of the source bucket, preserving throughput for active applications. However, accessing the destination bucket from a different Availability Zone introduces latency penalties that delay report availability. Teams must align compute resources within the same zone to maintain single-digit milliseconds consistency during ingestion. Validate cross-zone network paths before scheduling production jobs.
Implementing Daily Reports with CSV, ORC, and Parquet Output Formats
Daily S3 Inventory jobs for S3 Express One Zone require explicit configuration of output formats and destination buckets via the AWS CLI.
- Specify the source scope using a shared prefix to limit the object set.
- Designate a destination S3 bucket with valid write permissions for the reporting service.
- Select Parquet, ORC, or CSV as the serialization format for downstream analytics.
- Filter metadata fields to include only encryption status and object size.
Columnar formats like Parquet enable predicate pushdown, allowing query engines to skip data blocks during compliance scans. This optimization reduces compute costs significantly compared to parsing row-based CSV files for large datasets. However, selecting Parquet introduces a dependency on specific reader versions; older big data frameworks may fail to decode the latest columnar encoding without upgrades. The migration feasibility demonstrated by a technical demonstration costing approximately $20 suggests that testing format compatibility incurs minimal financial risk before production rollout.
Destination bucket policies must explicitly trust the inventory service principal to prevent silent delivery failures. Validate cross-account permissions prior to enabling daily schedules to avoid gaps in encryption visibility.
Troubleshooting Missing Reports and Destination Bucket Permission Errors
Missing S3 Inventory files usually stem from destination S3 bucket policies that block the reporting service principal.
- Validate that the target bucket policy explicitly grants `s3:PutObject` to the inventory service account.
- Confirm the source is a directory bucket rather than a general-purpose bucket, as cross-type configurations fail silently.
- Ensure compute resources generating validation scripts reside in the same Availability Zone to avoid latency-induced timeouts during verification.
Accessing directory buckets from outside their home zone introduces avoidable delay that mimics configuration failure (same Availability Zone). The service emits reports in Parquet, ORC, or CSV without impacting the source bucket request quota (request rate). A malformed policy prevents the weekly cycle from completing, leaving encryption audits incomplete.
Operators must distinguish between permission denials and format incompatibilities when reports do not appear. Audit IAM trust relationships before assuming service outages. Scheduled S3 Inventory reports replace synchronous List API calls to verify encryption status across a vast number of objects stored in the system without impacting live workloads. Compliance teams rely on this mechanism to audit metadata for millions of items, ensuring regulatory adherence while avoiding the latency penalties inherent in real-time enumeration. The service generates output in Parquet format, enabling efficient columnar querying of encryption flags and storage classes downstream. Operational success depends on isolating report generation from production traffic patterns.
- Configure daily jobs to export encryption status and object names to a dedicated audit bucket.
- Restrict scope using shared prefixes to minimize processing time for specific regulatory domains.
- Validate that destination policies grant write access to the inventory service principal explicitly.
- Archive historical reports to meet long-term legal hold requirements.
ChaosSearch utilized S3 Express One Zone to enhance serverless compute architecture, proving that decoupling metadata analysis from hot paths accelerates time-to-results for analytics. Running daily scans on massive directories accumulates charges quicker than weekly cycles, yet delays detection of non-compliant objects. Operators must balance audit immediacy against budget constraints when defining schedules. The limitation of this approach surfaces when organizations neglect to align report retention policies with legal hold requirements. Missing a single weekly cycle creates a gap in the compliance chain that automated tools cannot reconstruct retroactively. Strategic planning requires treating these reports as immutable evidence rather than transient logs.
Real-World Cost and Latency Wins for AI Workloads
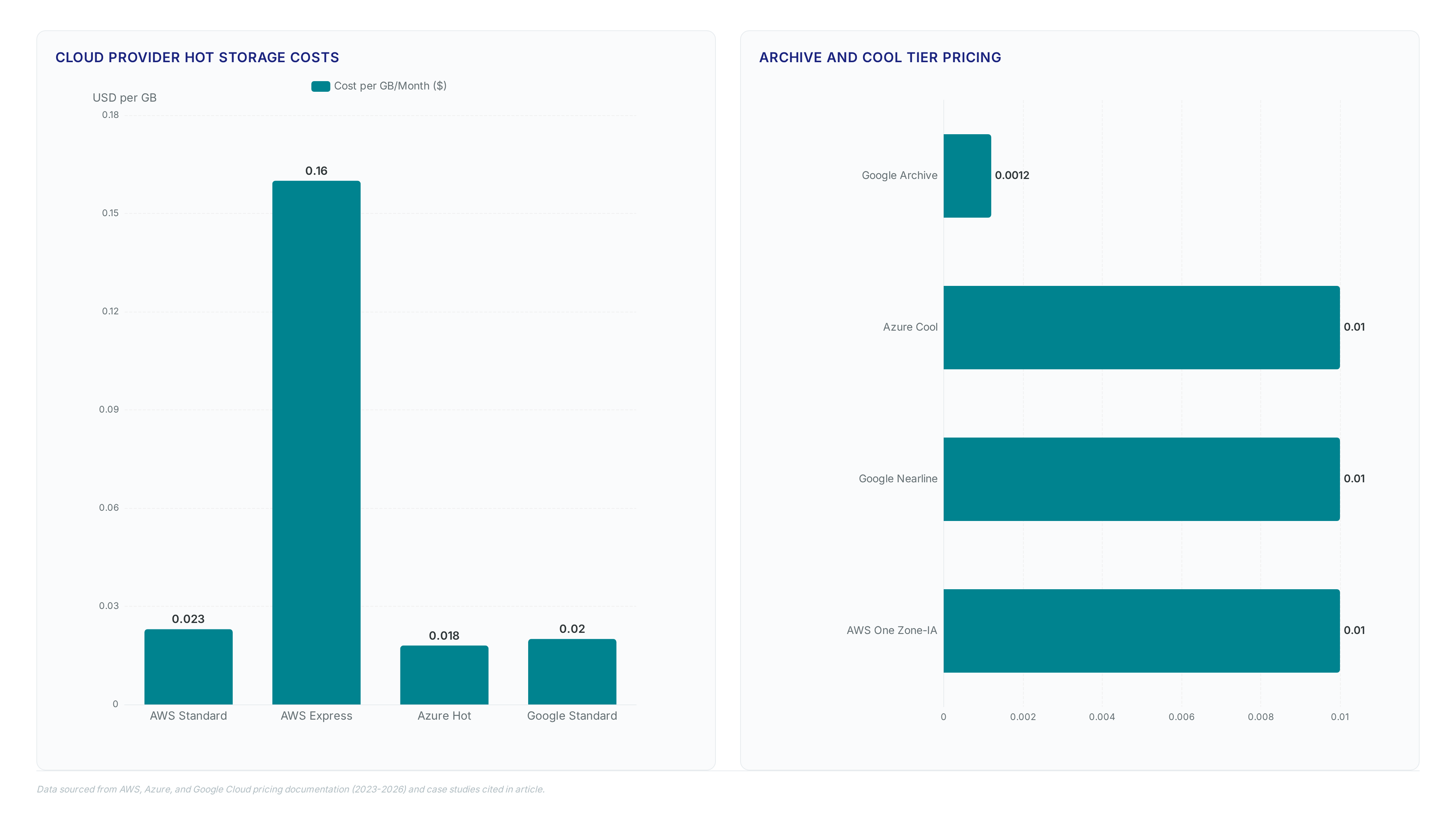
Tavily cut caching costs by 95% after moving AI search layers to S3 Express One Zone, eliminating latency spikes entirely. Generative AI pipelines demand consistent single-digit millisecond access that standard storage classes cannot guarantee during burst periods. Lyrebird Studios adopted the architecture for image-to-image processing, projecting an 18% reduction in Total Cost of Ownership through optimized throughput. Strategic co-location of compute resources within the same Availability Zone drives further savings, with potential TCO decreases reaching 60%. This geometry minimizes data transfer charges while maximizing IOPS availability for training clusters. Operators must weigh the $0.16/GB monthly rate against the operational expense of synchronous List API calls on large datasets.
| Workload Type | Storage Class | Latency Profile | Cost Driver |
|---|---|---|---|
| GenAI Training | S3 Express One Zone | Single-digit ms | Compute idle time |
| Compliance Audit | S3 Standard | Variable seconds | API request volume |
| Cold Archive | S3 Glacier | Minutes to hours | Retrieval fees |
Should teams use S3 Inventory for compliance checks on these high-performance buckets? Yes, because scheduled reporting avoids throttling live inference endpoints during metadata enumeration. The alternative involves blocking production traffic to run recursive listings, a pattern that fails at scale. Pair daily inventory jobs with Parquet outputs to accelerate encryption verification without impacting model serving. Architectures requiring cross-region redundancy must replicate directory buckets manually, adding operational complexity. High-frequency transaction processing benefits most, yet batch analytics jobs see diminishing returns if network egress dominates the bill.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in optimizing S3-compatible storage for AI/ML workloads. His deep expertise in cloud storage architecture makes him uniquely qualified to analyze the new S3 Inventory support for Amazon S3 Express One Zone. In his daily role, Chen helps enterprises migrate from proprietary systems to open standards, directly addressing the challenges of managing massive object lists without incurring high API costs. This article connects his practical experience with Rabata. Io's mission to provide transparent, high-performance storage alternatives. As organizations scale their data lakes, understanding scheduled inventory reporting becomes critical for governance and cost control. Chen uses his background in DevOps and Kubernetes infrastructure to explain how these updates simplify metadata management. By bridging technical implementation with strategic business value, he demonstrates how Rabata. Io's GDPR-compliant regions offer a viable, vendor-neutral path for companies seeking efficient object storage solutions.
Conclusion
Scaling S3 Inventory for compliance on high-performance buckets reveals a critical breaking point: metadata enumeration latency spikes when concurrent inference requests compete for directory bucket throughput. While inventory jobs prevent production throttling, the operational overhead of manually replicating these configurations across regions creates a hidden tax on engineering time that often exceeds the storage premium itself. As generative AI workloads shift toward real-time analytics, the current model of decoupled reporting fails to keep pace with flexible data mutations, requiring a move toward continuous metadata streaming rather than batch snapshots. Teams should adopt S3 Express One Zone only if their application consistently saturates the I/O path; otherwise, the cost per gigabyte remains unjustified. Commit to this architecture within the next two quarters if your latency SLAs demand single-digit millisecond access, but plan an exit strategy if workload intensity drops below 80% utilization. Start by auditing your current List API call volume against compute idle time metrics this week to determine if the performance gain actually offsets the operational complexity of managing directory buckets.
Frequently Asked Questions
No, inventory jobs run asynchronously and do not consume the source bucket request quota. This separation ensures production traffic maintains the full 2 million TPS capacity available per directory bucket without interference.
The cost for listing objects remains fixed regardless of the storage class performance tier used. Operators pay exactly $0.0025 per million entries when generating these scheduled metadata reports for their buckets.
Express One Zone costs $0.16 per GB monthly, which is significantly higher than standard tiers. In contrast, standard storage costs approximately $0.023 per GB for the first 50 TB in US East regions.
Yes, you can configure the service to generate reports on either a daily or weekly basis. This flexibility allows teams to align metadata freshness with specific SLA requirements for downstream analytics pipelines.
You can specify CSV, ORC, or Parquet as the output file format for your inventory reports. These formats allow big data jobs to process metadata asynchronously while production traffic maintains maximum throughput.
