ADI: Why Humans Still Matter in AI Storage
The AI-powered storage market hit billions in 2025, yet autonomous data infrastructure still requires human oversight.
Growth here is undeniable, but speed without safety is just an outage waiting to happen. The real value sits in cyber-resilient data storage architectures that balance throughput with control. We are looking at how S3 over RDMA protocols accelerate data movement without surrendering command, and why multi-tier object storage strategies must evolve past simple automation scripts.
This isn't about removing administrators; it's about changing their job description. We examine the specific workflows where AI storage management agents interact with human operators to optimize data lifecycle management. The analysis covers the technical reality of GPU-accelerated storage clusters and the hard necessity of maintaining data sovereignty compliance through hybrid oversight. Fully automated systems risk catastrophic errors when policies drift. This approach ensures power-efficient storage outcomes stay aligned with business logic. We skip the hype to focus on the mechanics of enterprise storage solutions that actually function at scale.
The Role of Autonomous Data Infrastructure in Modern AI Storage
ADI Definition and Policy-Driven AI Agent Workers
The provider introduced ADI (Autonomous Data Infrastructure) on 12 May 2026 to swap static storage setups for flexible management. This isn't just a software update; it's a shift in who drives the car. The system employs AI-powered agents that handle expansion, healing, rebalancing, upgrades, and lifecycle workflows within a multi-tier but single namespace storage environment. The provider ADI autonomously matches performance, protection, and economics to every workload at each stage of the data lifecycle.
Software agents continuously analyze telemetry, evaluating data access patterns against set policies to execute tiering actions without human intervention. They don't wait for a ticket. They react.
| Feature | Traditional Management | the provider ADI Approach |
|---|---|---|
| Placement | Manual migration scripts | Autonomous agent decisions |
| Scaling | Human-limited coordination | Real-time telemetry response |
| Optimization | Static tier assignment | Flexible policy enforcement |
Such a storage environment adapts to AI workflow demands instantly rather than reacting days later.
Aligning AI Workloads Like RAG and KV Cache to Storage Tiers
Retrieval-augmented generation and distributed KV cache operations require distinct throughput and latency profiles that static storage configurations cannot satisfy. Agent-driven tiering dynamically aligns data placement with these shifting requirements by evaluating access patterns against policy constraints.
Traditional models force administrators to manually migrate datasets. That doesn't work when workloads spike. Autonomous agents place hot inference data on high-performance tiers while archiving cold training sets to cost-optimized layers. GPU productivity remains high even as workload intensity fluctuates across exabyte-scale environments.
| Workload Type | Primary Constraint | Storage Response |
|---|---|---|
| RAG Queries | Low Latency | Immediate hot-tier access |
| KV Cache | High Throughput | Managed via lifecycle and compression |
| Training Data | Capacity | Deep archive with governance |
Clear rules defining data sovereignty and retention prevent autonomous systems from optimizing for cost at the expense of compliance.
ADI Versus Standard Storage Array Control Software
Legacy architectures crumble under the demand for flexible infrastructures. The provider ADI replaces such manual complexity with self-governing data infrastructure that dynamically aligns resources. Standard controllers require explicit LUN provisioning, yet ADI uses policy-driven agents to place data across distinct tiers based on real-time access patterns. This approach eliminates the operational overhead of managing separate silos for different data temperatures.
| Management Model | Data Placement | Operational Overhead |
|---|---|---|
| Standard Array | Static, manual tiering | High, requires constant intervention |
| the provider ADI | Flexible, agent-driven | Low, policy-automated |
ADI resolves this by continuously evaluating telemetry to shift data automatically. Evaluating current storage fragmentation helps determine if autonomous tiering offers sufficient ROI over manual management.
Inside Agent-Driven Tiering and S3 over RDMA Architecture
S3 over RDMA and GPU-Direct in Extreme Performance Tiers
AI storage enables quick retrieval and writing of large volumes of data, supporting parallel processing with GPUs to ensure models train quicker and infer accurately. This architecture relies on S3 over RDMA to bypass operating system kernel overhead, moving data directly between application memory and storage controllers. By eliminating CPU interrupt handling during transfer operations, the system preserves host cycles for model computation rather than I/O processing. The integration of GPU-Direct further reduces latency by enabling direct memory access between storage devices and GPU memory, avoiding extra copies through system RAM.
| Feature | Standard S3 over TCP | S3 over RDMA |
|---|---|---|
| Data Path | OS Kernel Stack | User Space Bypass |
| CPU Overhead | High | Minimal |
| Latency Profile | Variable | Optimized |
| Bandwidth Scaling | Limited by Socket Ops | Linear with NIC Count |
Deploying RDMA isn't plug-and-play. It requires careful network configuration to manage flow control and prevent packet loss from degrading throughput. Operators must balance the complexity of RoCEv2 deployment against the raw performance gains for specific GPU-bound workloads. Network validation remains a critical step for production use to ensure deterministic low-latency access patterns required by generative AI pipelines. The architectural trade-off involves exchanging simplified Ethernet management for the accelerated computing and networking integration needed for hyperscale efficiency.
Configuring Real-Time Power Telemetry Across Node and Workload Levels
Modern data infrastructure platforms address rising pressure on data centre power use by introducing capabilities designed for power-efficient storage. This visibility addresses the chronic problem of opaque storage power usage, where static allocation masks inefficient GPU idle states. The mechanism relies on agent-driven collection to tag energy draw to specific S3 buckets or active training jobs. Adhering to these ratios ensures high-energy flash media hosts only active datasets while colder data resides on efficient capacity drives.
| Metric Level | Visibility Scope | Optimization Target |
|---|---|---|
| System | Total Facility Draw | PUE Reduction |
| Node | Rack Unit Consumption | Thermal Throttling |
| Workload | Per-Job Energy Cost | AI Model ROI |
The cost of this granularity is the overhead of continuous metric aggregation across the cluster fabric. Without careful tuning, the telemetry stream itself can consume network bandwidth intended for model weights. Isolating telemetry traffic on a dedicated management network helps prevent interference with S3 over RDMA data paths. This separation preserves low-latency performance while maintaining an uninterrupted audit trail for carbon reporting. The limitation remains that achieving fine-grained sensors for workload-level attribution requires modern infrastructure designed for exabyte-scale data management.
Guardian Agent Operational Workflows for Healing and Upgrades
Autonomous operations engines operationalize AI storage management by using AI-powered agents to handle expansion, healing, rebalancing, upgrades, and lifecycle workflows. Guardian provides AI agent-assisted operational intelligence that observes system state and surfaces workload-aligned insights. The mechanism relies on agent-driven observation to detect system state deviations, then proposes corrective workflows within strict policy bounds. Humans or external AI tooling review these suggestions, ensuring the platform executes actions only after auditable validation. This human-in-the-loop design prevents autonomous drift while dramatically reducing the administrative burden on infrastructure teams handling complex GPU data latency issues.
However, the reliance on manual sign-off introduces a latency trade-off; recovery timelines depend on operator response time rather than pure machine speed. For enterprises fixing GPU data latency in AI workflows, this means balancing safety against the urgency of model training schedules.
- Agents observe system state and surface specific insights.
- Operators or tooling approve proposed actions against policy.
- The platform executes healing, rebalancing, or upgrades.
Configuring these guards tightly helps maintain sovereignty without stifling throughput. The consequence of this architecture is that storage operations become traceable transactions rather than invisible background processes, aligning the right performance, protection, and economics to every workload at every stage of the data lifecycle.
Comparing ADI Agent Workflows to Traditional Storage Management
ADI as a Data Management Infrastructure Layer
Independent Data Infrastructure functions as an AI-powered layer overseeing a multi-tier but single namespace storage environment. Unlike legacy controllers that rely on static policies, this architecture uses active agents to align media, protection, and performance dynamically for every workload. The system resolves the tension between GPU acceleration needs and power efficiency without forcing a choice between them.
| Feature | Traditional Storage | ADI Agent Model |
|---|---|---|
| Tiering Logic | Static rules | Real-time AI agents |
| Namespace Scope | Siloed per tier | Single global namespace |
| Workload Match | Manual configuration | Automatic alignment |
Operators deploying this model shift from managing hardware capacity to defining business outcomes for their data. The single namespace abstraction eliminates the manual migration tasks typical of hierarchical storage management systems. However, this autonomy introduces a dependency on accurate telemetry; agents cannot optimize placement if input metrics regarding data sovereignty or access patterns are incomplete. This constraint means initial policy definitions require precise human input to guide the AI agents effectively.
Rabata.io emphasizes that the true value lies in this operational shift rather than mere throughput gains. The infrastructure absorbs the complexity of exabyte-scale management, allowing engineering teams to focus on application logic instead of storage plumbing. Such a approach ensures critical data receives appropriate cyber-durability while maintaining the economics required for sustainable scaling.
Mapping Sovereign State Data and GPU Caches to Storage Hierarchies
Policy definitions explicitly map sovereign state data to on-premises the provider RING instances while relegating inactive archives to tape. This mechanism enforces strict geographic boundaries for compliance without fragmenting the global namespace. The architecture supports customers using on-premises object storage alongside AWS, Azure, and GCP clouds to satisfy these diverse residency rules. A critical tension exists between maintaining low-latency access for active training sets and minimizing the power footprint of idle capacity. Agents resolve this by caching hot vectors in CPU DRAM limits while pushing cold partitions to cheaper tiers.
| Data Class | Primary Tier | Overflow Target | Compliance Mode |
|---|---|---|---|
| Sovereign State | On-prem RING | Private Cloud | Strict Geo-fence |
| GPU Cache | HBM/DRAM | NVMe Flash | Low Latency |
| Cold Archive | Tape | Public Cloud | WORM Locking |
Operators must recognize that agent-driven placement introduces a dependency on telemetry freshness; stale metrics cause misalignment during burst events. The system manages data hierarchies including high-speed GPU data and less-accessed data on tape dynamically. This approach ensures cyber-resilient workflows where immutable copies remain isolated from network threats. The limitation is that initial policy formulation requires precise knowledge of workload access patterns to avoid thrashing. Without accurate heatmaps, the AI agents may oscillate data between tiers unnecessarily. Strategic configuration transforms static buckets into intelligent repositories that adapt to shifting computational demands automatically.
Legacy Array Limitations Versus Multi-Tier AI Workload Demands
Static storage controllers fail because they force diverse AI workloads into expensive single-tier flash configurations. Traditional arrays treat Training Inference Multimodal agentic workflows and Retrieval-augmented generation (RAG) identically, ignoring distinct latency requirements. This uniformity drives unnecessary capital expenditure on high-performance media for cold data paths. Operators often lack visibility into how specific tasks like KV cache for distributed inference compete for bandwidth against bulk ingestion jobs. The result is a fragmented stack where performance tuning requires manual intervention across siloed systems.
| Capability | Legacy Array | ADI Approach |
|---|---|---|
| Workload Isolation | None | Flexible policy enforcement |
| Media Utilization | Fixed tiering | Agent-driven placement |
| Namespace View | Per-array silos | Single global space |
The provider's architecture addresses this by deploying agents that oversee a multi-tier but single namespace environment. These intelligent controllers automatically align protection levels and performance characteristics to each specific stage of the data lifecycle. A hidden tension exists between maximizing GPU utilization and maintaining strict data sovereignty boundaries for sovereign state data. While legacy systems might replicate data globally for speed, violating compliance rules, the agent model enforces geographic constraints without sacrificing local access speeds. This distinction matters for organizations balancing regulatory mandates with the need for rapid model iteration.rabata.io emphasizes that ignoring these architectural differences leads to bloated operational costs and inefficient resource allocation. The cost of maintaining static policies grows linearly with data volume, whereas autonomous scaling decouples storage growth from management overhead. Enterprises must evaluate whether their current infrastructure can support the chaotic I/O patterns of modern agentic workflows without manual sharding.
Implementing Policy-Driven Tiering and Cyber-Resilient Workflows
Policy-Driven Data Tiering Mechanics in ADI

Administrators define auditable policy bounds that map specific data hierarchies to optimal storage media based on access patterns. The system manages data hierarchies including sovereign state data, high-speed GPU data, caches for HBM and CPU DRAM limits, and less-accessed data on tape or in the cloud. This mechanism ensures GPU workflows receive low-latency access while archiving cold datasets to reduce power consumption.
The operational tension lies between maximizing performance for active training sets and minimizing costs for archival data. Operators must configure policies that balance these competing goals without manual intervention. A misconfigured rule could inadvertently move active datasets to slower tiers, degrading model training speeds.
| Data Type | Target Media | Policy Driver |
|---|---|---|
| Sovereign State Data | Local Object Store | Compliance |
| GPU Training Sets | NVMe Flash | Latency |
| HBM/CPU Caches | DRAM | Throughput |
| Archival Logs | Tape or Cloud | Cost |
The limitation of this approach is its reliance on accurate initial classification; erroneous tags propagate errors across the single namespace environment. Unlike static tiering, the AI agents continuously re-evaluate placement, yet they remain bound by the initial sovereign or performance constraints set by the administrator. This creates a system where human intent governs autonomous action, preventing drift from compliance requirements.
Integrating Custom AI Tools via MCP and Guardian Workflows
Enterprises integrate proprietary AI stacks into ADI operational loops using the Model Context Protocol (MCP). This mechanism allows external intelligence to drive storage decisions rather than relying solely on vendor-set heuristics. Operators connect their custom models to the provider Guardian, the autonomous engine that executes physical data movements. The AI-powered agents within this engine handle expansion, healing, rebalancing, upgrades, and lifecycle workflows based on inputs from the connected customer stack.
The critical tension exists between full autonomy and administrative oversight. While agents manage routine tasks like rebalancing and healing, the system mandates human approval for significant lifecycle changes or policy shifts. This design prevents runaway automation from corrupting cyber-resilient archives during anomalous AI behavior. A misconfigured external model cannot unilaterally delete immutable backups or alter sovereign data boundaries without explicit confirmation.
| Workflow Type | Agent Action | Human Role |
|---|---|---|
| Expansion | Provisioning nodes | Policy definition |
| Healing | Data reconstruction | Alert monitoring |
| Lifecycle | Tier migration | Approval gate |
The limitation of this approach is latency; round-trip validation for every decision adds overhead compared to fully internal loops. However, this trade-off secures the data sovereignty required for regulated industries. The system ensures that customer-owned AI drives efficiency while the platform enforces structural integrity. This separation allows organizations to use specialized machine learning for placement logic without surrendering control over the underlying storage media.
Validating CORE5 Immutability and Outcome-Based SLAs
Operators verify the provider's CORE5 cyber durability offering by confirming data remains immutable, recoverable, and auditable at every level. The mechanism relies on strict write-once-read-many locks that prevent deletion or modification even by administrators. Evidence suggests this approach satisfies rigorous compliance mandates without sacrificing accessibility for authorized recovery operations. However, enabling these protections introduces latency during high-velocity write bursts if the underlying disk subsystem cannot sustain the required IOPS. Teams must balance strict immutability windows against the throughput needs of active AI training pipelines.
Rabata.io recommends validating configuration against outcome-based SLAs spanning availability, performance, protection posture, power consumption, and operational efficiency.
| Validation Target | Configuration Check | Outcome Metric |
|---|---|---|
| Immutability | Retention lock enabled | Zero deletion events |
| Recoverability | Point-in-time restore test | RTO under SLA limit |
| Audibility | Log ingestion verified | Complete chain of custody |
| Efficiency | Power capping active | Watts per TB within bound |
The critical tension exists between maximizing protection posture and minimizing power draw during idle periods. Overly aggressive power saving can delay the activation of cold storage nodes needed for rapid disaster recovery. Enterprises should test failover scenarios under peak load to ensure the system meets its outcome-based SLAs before production deployment.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata.io, where he specializes in designing scalable S3-compatible storage architectures for AI/ML workloads. His direct engagement with enterprise clients facing exabyte-scale challenges uniquely positions him to analyze separate data infrastructure. At Rabata.io, Chen daily architects solutions that balance GPU-accelerated storage performance with cost-efficient tiering, directly mirroring the article's focus on agent-driven data placement. His work involves optimizing data lifecycle management strategies that align storage performance with rigorous AI training needs while ensuring data sovereignty compliance across EU and US regions. By using Rabata.io's high-performance object storage to solve real-world bottlenecks in AI storage management, Chen translates complex infrastructure requirements into actionable insights. This practical experience ensures the analysis of sovereign data infrastructure is grounded in proven architectural patterns rather than theoretical speculation, offering readers a clear path to reducing power consumption and managing cyber-resilient data storage effectively.
Conclusion
Scaling self-governing data infrastructure reveals that strict immutability often conflicts with the low-latency demands of active AI training pipelines. When write-once-read-many locks engage during high-velocity bursts, the underlying disk subsystem frequently bottlenecks, introducing unacceptable latency that standard throughput metrics miss. This operational friction proves that protection posture cannot be an abstract setting but must be dynamically tuned against real-time workload intensity. Enterprises relying on static configurations will find their disaster recovery windows expanding precisely when speed matters most.
Organizations should mandate that all storage deployments validate outcome-based SLAs under peak load before production use. This requirement ensures that power capping and retention locks do not silently degrade performance during critical operations. The industry shift toward standard AI integration in 2026 means administrators can no longer treat these features as optional add-ons but as core stability factors.
Start this week by running a failover simulation with retention locks enabled while sustaining maximum write throughput. Measure the resulting latency spike against your recovery time objectives to identify gaps. If the system misses its target, adjust the immutability window or upgrade the disk subsystem immediately. Only through this empirical testing can teams ensure their cyber durability strategy survives the reality of enterprise AI workloads without compromising accessibility.
Administrators must define these policies so agents can balance speed with safety while managing data lifecycle stages.
Frequently Asked Questions
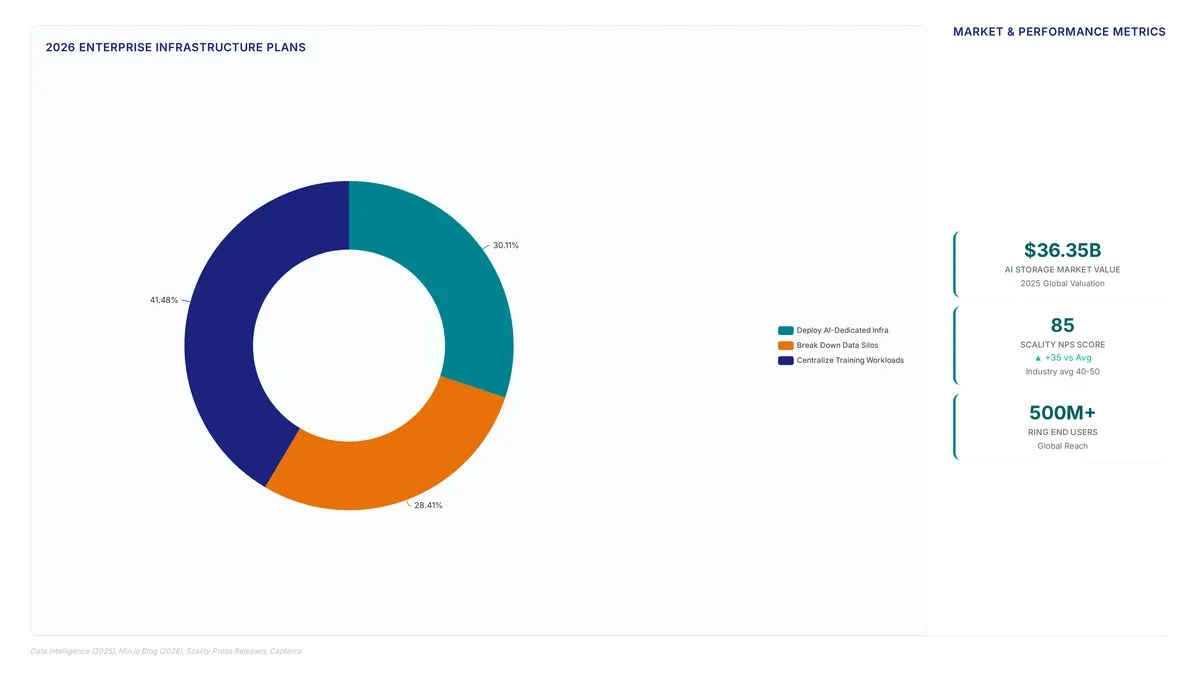
The global AI-powered storage market reached a valuation of US$ 36.35 billion in 2025. This massive scale indicates that organizations must adopt autonomous data infrastructure to manage exabyte-scale environments effectively without human bottlenecks.
True agent-driven storage succeeds by augmenting operator decisions rather than removing them entirely. While the sector grows rapidly, maintaining human oversight ensures that policy-driven data placement aligns with specific business logic and safety requirements.
S3 over RDMA bypasses operating system kernel overhead to move data directly between memory and controllers. Eliminating CPU interrupt handling during transfers allows GPU productivity to remain high even as workload intensity fluctuates across clusters.
Autonomous agents continuously analyze telemetry to execute tiering actions without human intervention. Unlike static manual scripts, this dynamic approach instantly adapts to AI workflow demands rather than reacting days later to changing access patterns.
Clear rules defining data sovereignty prevent autonomous systems from optimizing for cost at the expense of compliance. Administrators must define these policies so agents can balance speed with safety while managing data lifecycle stages.
References
