Streams are slow: Why 120x faster primitives matter
Benchmarks show alternative stream implementations running up to 120x faster than the current Web Streams API across substantial runtimes.
The Web Streams API, standardized by WHATWG between 2014 and 2016, now creates critical bottlenecks in modern server-first architecture demanding efficient data handling. As Figma reports, the 2026 industry shift toward React Server Components and default Server-Side Rendering places unsustainable pressure on these legacy primitives. James M Snell argues that design decisions made a decade ago, specifically before async iteration existed in JavaScript, resulted in fundamental usability and performance flaws that incremental patches cannot.
This analysis dissects why the original specification fails to map efficiently to today's low-level I/O requirements despite adoption by Node. Js, Cloudflare Workers, Deno, and Bun. (Cloudflare's nodejs workers 2025) Readers will examine the specific role of Web Streams in current JavaScript infrastructure and how stream locking mechanisms introduce unnecessary promise overhead. Finally, we quantify the massive performance gaps between these standardized APIs and optimized Node. Js pipelines, proving that a primitive-based alternative theoretical but immediately necessary for high-throughput environments.
The Role of Web Streams in Modern JavaScript Infrastructure
WHATWG Streams Standard Origins and Browser Adoption
Three primitives called `ReadableStream`, `WritableStream`, and `TransformStream` comprise the WHATWG Streams Standard to unify data handling across browsers and servers. The WHATWG officially adopted the "Streams" project in October 2014 after more than a year of prior development on GitHub. Standardization efforts concluded between 2014 and 2016, establishing the technical foundation for the modern `fetch()` API before async iteration existed in JavaScript.
Node. Js, Deno, and Bun later integrated these core primitives to ensure cross-platform compatibility with browser environments. Server-side implementation occurred years after the initial spec finalization because edge computing platforms like Cloudflare Workers required standardized I/O. The timing mismatch between the 2016 standard completion and the 2018 arrival of `for await... Of` syntax forced the specification to adopt a complex reader-locking model rather than native language iteration.
Developers must now manage explicit lock acquisition and release manually due to this historical constraint. The design prioritizes low-level I/O mapping over developer ergonomics, resulting in verbose boilerplate for simple consumption tasks. Modern server architectures bear the computational cost of these legacy browser-centric decisions. The Streams Standard remains the mandatory interface for `fetch()` despite these usability gaps.
BYOB reads require the consumer to supply an `ArrayBuffer`, yet the specification mandates immediate rejection of buffers backed by WebAssembly memory. This constraint exists because the buffer detachment model invalidates shared memory views upon transfer, breaking the zero-copy guarantee necessary for high-performance computing. Operators implementing video pipelines must validate buffer sources before invoking read operations to prevent runtime exceptions that halt data flow.
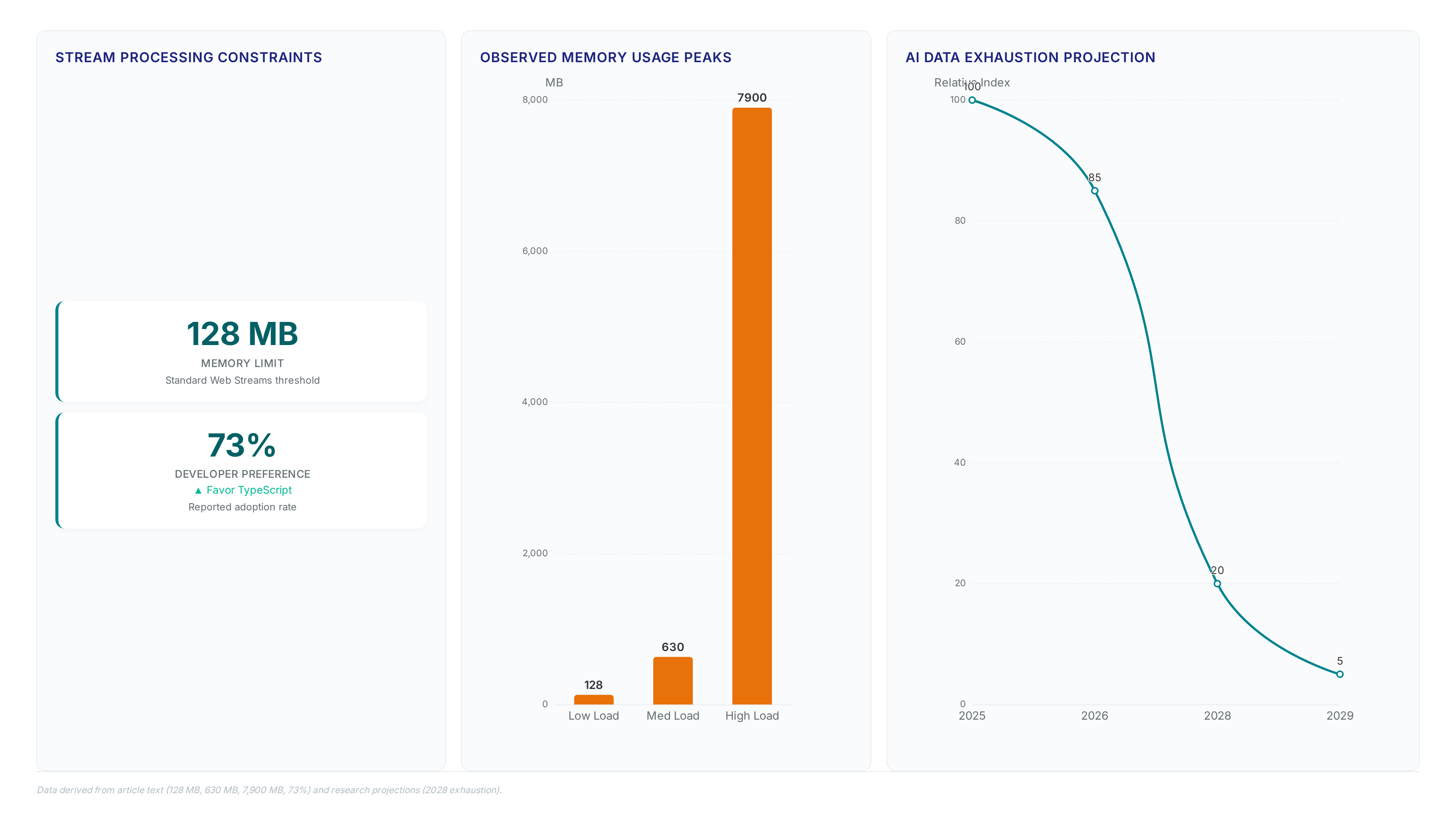
Managing these exclusions creates significant usability pitfalls for developers attempting to optimize memory usage in constrained environments. Cloudflare Workers enforce a strict 128 MB memory limit, making efficient buffer management mandatory to avoid out-of-memory errors during large file processing. Failure to handle WebAssembly rejection correctly forces fallback allocations that double memory pressure, directly impacting infrastructure costs.
Security hardening further complicates implementation because tests verify that `pipeTo()` operations do not leak internal values if `Object. Prototype. Then` is patched. This defense against prototype pollution adds another layer of validation logic that pure async iteration patterns often bypass naturally. Standard streaming code fails silently when interacting with low-level memory regions.
Native Web Stream `pipeThrough` throughput hits 630 MB/s with 1KB chunks, creating a severe bottleneck for server-side data processing. This throughput disparity forces high-volume applications to absorb unnecessary latency when moving data between transformation stages. The standard API design introduces excessive promise resolution overhead that blocks the event loop during intensive I/O operations.
| Metric | Native Web Streams | Node.js `pipeline()` |
|---|---|---|
| Throughput (1KB chunks) | 630 MB/s | 7,900 MB/s |
| Relative Performance | 1x | 12x |
| GC CPU Overhead | 50% | Minimal |
Garbage collection consumes 50% This GC pressure directly reduces the capacity available for business logic execution on shared infrastructure. Operators relying on the default implementation face inflated compute costs as horizontal scaling becomes the only remedy for single-thread starvation.
Legacy `pipeline()` functions achieve 7,900 MB/s Mission and Vision recommends auditing all data transformation layers for promise churn before adopting the standard API for bulk operations. The performance gap implies a proportional increase in infrastructure spend for services handling terabytes of daily traffic. Developers must weigh the benefit of cross-runtime compatibility against the tangible penalty in processing efficiency.
Internal Mechanics of Stream Locking and Promise Overhead
Web Stream Locking Model and TypeError Triggers
Invoking getReader() places an exclusive lock on the stream instantly. This action blocks every other read, pipe, or cancel attempt until the lock releases. Such a model stops interleaved consumption yet builds fragile state dependencies into asynchronous workflows. Neglecting to call releaseLock() breaks the stream forever. A `TypeError: Cannot obtain lock` halts any subsequent processing logic. The locked property shows status but hides the holder identity. It omits usability context too. Operators must guess at failure roots without clear data.
Internal piping operations grab these locks silently. Streams become unusable during transport in ways that confuse developers. Critics argue this locking mechanism adds unnecessary latency for single-threaded JavaScript use cases where concurrent access cannot happen. The specification requires promise creation for each read operation. This compounds overhead within the promise-heavy.
| Failure Mode | Trigger Condition | Outcome |
|---|---|---|
| Permanent Lock | Missing releaseLock() | `TypeError` on next access |
| Silent Block | Active pipeTo() call | Reader acquisition fails |
| Ambiguous State | Check locked only | Root cause remains hidden |
Manual tracking of the reader lifecycle prevents orphaned locks from crashing production pipelines. This bookkeeping burden shifts focus away from business logic toward low-level state management. Safety guarantees against race conditions impose a measurable tax on development velocity. Runtime efficiency suffers as a result.
Implementing BYOB Reads with ReadableStreamBYOBRequest
High-throughput ingestion needs the ReadableStreamBYOBReader to supply pre-allocated buffers. This mode introduces complex buffer detachment semantics that invalidate the original memory view upon transfer.
Developers must follow a strict sequence to avoid permanent stream corruption:
- Instantiate the specific ReadableStreamBYOBReader rather than the default reader.
- Pass a valid `ArrayBufferView` to the read request, ensuring it is not backed by WebAssembly memory.
- Accept the returned view, which points to potentially different memory than the input buffer.
- Release the lock immediately after processing to prevent `TypeError: Cannot obtain lock` failures in subsequent operations.
Passed buffers become detached per specification requirements. The system returns a new view over transferred memory instead of filling the user-provided slice directly. This transfer-based model creates significant usability pitfalls md) because the original buffer reference dies the moment the stream accepts it. Operators attempting zero-copy architectures with WebAssembly modules face immediate rejection. The detachment model conflicts with shared memory constraints fundamentally.
| Constraint | Default Read | BYOB Read |
|---|---|---|
| Buffer Ownership | Stream allocates | Consumer provides |
| Memory Copy | Required | Eliminated |
| Async Iterator Support | Yes | No |
| WebAssembly Compatible | Yes | No |
Promise allocation overhead in this path exacerbates CPU costs within serverless environments Architectural tension exists between eliminating memory copies and accepting a non-iterable, lock-heavy API that blocks concurrent access. Most production systems bypass this complexity entirely. They revert to standard reads despite the garbage collection penalty because manual buffer management introduces more failure modes than it resolves.
The `tee()` method creates two branches where mismatched read speeds cause data accumulation in internal buffers without limits. This design flaw leaves operators unable to configure backpressure thresholds. Manual intervention becomes necessary when one consumer lags. The only available mitigation involves canceling the slower branch entirely. This disrupts legitimate data flows and complicates error handling logic.
Internal queuing relies on a promise-heavy model Memory pressure worsens during throughput spikes. Unlike async iteration patterns that process items sequentially, this dual-branch architecture holds every unread chunk in RAM indefinitely. The resulting unbounded memory growth poses severe risks for long-running server processes handling variable-rate inputs.
Critics propose replacing this complex locking system with a simpler async iterator approach that eliminates explicit reader management. Such a shift would remove the hidden buffer queues responsible for these leaks while improving developer ergonomics. Current implementations offer no configuration knobs to limit queue size. Prevention becomes impossible without architectural changes.
Operators must monitor heap usage closely when deploying `tee()` in production environments. The lack of native backpressure controls means application logic bears full responsibility for detecting and resolving speed mismatches before system stability degrades.
Performance Gaps Between Web Streams and Node.js Pipelines
Non-Standard Runtime Optimizations in Bun and Cloudflare Workers

Bun implements Direct Streams to bypass standard promise machinery, achieving throughput unattainable under strict WHATWG compliance. Cloudflare Workers deploy an IdentityTransformStream that shortcuts the spec's locking model for pass-through scenarios, reducing latency in edge compute environments. These optimizations address the friction observed when adapting Node. Js byte stream APIs to web-standard interfaces in full-stack frameworks like Next. Js.
| Optimization | Standard Compliance | Primary Benefit | Portability Risk |
|---|---|---|---|
| Bun Direct Streams | Non-standard | Maximal throughput | High |
| IdentityTransformStream | Partial | Low-latency change | Medium |
| Native Web Streams | Full | Cross-runtime consistency | None |
Runtime vendors initially relied on polyfills to bridge compatibility gaps but now transition to native C++ implementations to eliminate overhead. This shift contrasts with browsers that strictly adhere to the specification without such native shortcuts for the standard API implementation. Fragmentation emerges as the price for these gains. Code relying on Direct Streams fails in environments enforcing strict conformance. Developers face a tension between raw speed and cross-platform reliability when selecting streaming primitives. The locking mechanism inherent to the standard creates bottlenecks that only non-standard paths can fully resolve. Operators must weigh immediate performance needs against the long-term maintenance burden of runtime-specific code.
Resource Leakage from Unconsumed Fetch Response Bodies in Node.js
Unconsumed fetch() response bodies trigger connection pool exhaustion in Node. Js applications relying on undici. The ReadableStream returned by the API holds a reference to the underlying socket, preventing reuse until garbage collection occurs or the stream is explicitly canceled. This behavior creates a silent failure mode where high-throughput services deplete available connections without throwing immediate errors. Developers building file upload applications often encounter this complexity when attempting to stream data directly from client to server without full consumption.
Adapting legacy byte stream APIs to web-standard interfaces within full-stack frameworks like Next. Js Overhead compounds across multiple concurrent requests in these setups. Vercel addressed similar performance deficits Strict spec compliance often conflicts with production stability.
| Pattern | Resource Handling | Connection Reuse | Failure Mode |
|---|---|---|---|
| Web Streams | Manual cancel required | Blocked until GC | Pool exhaustion |
| Async Iteration | Auto-drain on exit | Immediate release | Minimal risk |
| Node Pipelines | Explicit destroy | Configurable timeout | Controlled error |
Operators must choose between spec fidelity and operational safety. Ignoring the body without calling `response. Body. Cancel()` leaves the TCP connection in a half-open state. This design forces engineers to wrap every fetch call in try-finally blocks solely for cleanup duties. The cost is measurable in reduced concurrency limits rather than CPU cycles. Mission and Vision recommends adopting async iteration patterns where the runtime handles drainage automatically upon loop completion.
Vercel Promise Elimination vs Native Web Streams Throughput
Vercel's promise elimination strategy targets a 10x improvement factor over native Web Streams by removing deferred execution overhead. Native implementations suffer from excessive object allocation. Every chunk triggers a new JavaScript promise that the garbage collector must eventually reclaim. This allocation pattern creates a bottleneck that standard async iteration cannot bypass without runtime-specific hacks. Cloudflare Workers internal pipelines achieved a 200x reduction in JavaScript promises created. Spec compliance directly inflates compute cycles. The performance.
Strict adherence exacts a measurable latency toll. Developers trading portability for speed often adopt non-standard primitives that break cross-runtime compatibility. A proportional increase Mission and Vision recommends evaluating promise overhead before selecting a streaming primitive for production use. Optimized paths frequently require abandoning the WHATWG standard entirely. Operators must choose between consistent behavior across runtimes or raw throughput within a single environment. No middle ground exists in the current specification.
Implementing Efficient Stream Processing with Async Iteration
Explicit Reader Locks and the Value-Done Protocol
Calling `getReader()` grabs an exclusive lock that blocks every other access point until `releaseLock()` runs. This mechanism forces developers to manually await promises and parse the `{ value, done }` protocol for every single chunk, creating substantial boilerplate. The standard demands managing `ReadableStream`, `WritableStream`, and `TransformStream` objects with explicit controllers, generating significant cognitive load compared to simpler models. Critics propose replacing these complex objects with a basic async iterator interface to eliminate locking entirely.
Buffers accumulate indefinitely if one consumer lags behind the others. Direct iteration allows concurrent reads, yet the lock prevents this capability or external cancellation logic, often causing permanent stream failure if `releaseLock()` is omitted. Legacy constraints shaped this design choice rather than modern JavaScript capabilities.
| Pattern | Lock Required | Memory Risk | Boilerplate |
|---|---|---|---|
| Manual Reader | Yes | High | Extreme |
| Async Iteration | No | Moderate | Low |
| Direct Iterator | No | None | Minimal |
Operators must recognize that `for await... Of` syntax merely hides the underlying locking complexity without removing it. Features like BYOB reads remain inaccessible through standard iteration, forcing a return to verbose manual management. High-throughput environments necessitate careful selection of consumption patterns due to the tension between spec compliance and performance.
Replacing Boilerplate with For Await Of Loops
Manual lock management via `getReader()` and `releaseLock()` creates fragile code paths where a single missed call permanently breaks the stream. The `for await... Of` syntax automates this lifecycle, hiding the exclusive lock acquisition behind a cleaner interface that iterates until completion. This pattern reduces the cognitive load required to manage `ReadableStream` objects, effectively shrinking the API surface to a simple iteration loop. Async iteration was retrofitted onto an architecture not designed for it, leaving underlying complexity like the `{ value, done }` protocol hidden rather than eliminated. Developers attempting BYOB reads find these optimizations inaccessible through standard iteration, forcing a revert to verbose manual locking for memory-efficient operations.
Connection Pool Exhaustion from Unconsumed Fetch Bodies
Silent connection pool exhaustion occurs in Node. Js when `fetch()` responses skip body consumption, locking underlying sockets indefinitely. The ReadableStream body retains a hard reference to the network socket, preventing the HTTP agent from recycling the connection for subsequent requests. This leakage scales linearly with request volume, eventually starving the application of available handles without triggering explicit error codes. Infrastructure costs rise sharply as memory pressure forces provisioning of larger instances to accommodate unbounded memory growth caused by stalled branches in `tee()` operations. Matteo Collina notes that cloning streams via `Request.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in optimizing S3-compatible object storage for high-performance data workflows. His deep expertise in cloud storage architecture and AI/ML infrastructure makes him uniquely qualified to analyze the Web Streams API. In his daily work designing scalable data pipelines, Chen uses streaming protocols to manage massive datasets efficiently, directly mirroring the API's core function of handling continuous data flow. As Rabata. Io builds faster, cost-effective alternatives to traditional cloud storage for enterprise and AI clients, understanding modern streaming standards is critical for minimizing latency and maximizing throughput. Chen's practical experience implementing these patterns across Kubernetes environments allows him to bridge theoretical standards with real-world application, offering readers actionable insights into how the Web Streams API can revolutionize data handling in next-generation storage solutions.
Conclusion
Scaling stream processing exposes a hard ceiling where garbage collection latency spikes disproportionately once memory pressure exceeds 50% of the available heap. While raw throughput metrics impress, the operational reality involves managing socket starvation when backpressure mechanisms fail to propagate up the chain. Edge environments with strict 128 MB caps do not tolerate the assumption that idle streams consume zero resources; instead, they accumulate hidden references that block connection recycling. This architectural debt compounds silently until the system hits a throughput cliff, where adding more load reduces overall output rather than increasing it. Teams must shift focus from maximum bandwidth to deterministic resource release strategies immediately. Adopt a policy requiring explicit `body. Cancel()` calls in all error paths and timeout handlers by the next sprint cycle. Do not rely on finalizers or scope exit to clean up network handles, as the event loop cannot guarantee timely execution under heavy load. Start by auditing your `fetch()` wrappers this week to identify any code paths that return responses without consuming or explicitly cancelling the body stream. This single inspection prevents the slow leak that eventually exhausts your connection pool during peak traffic.
Frequently Asked Questions
Streaming prevents out-of-memory errors by managing data flow efficiently. Cloudflare Workers enforce a strict 128 MB memory limit, making this approach mandatory to avoid request failures during large file processing tasks.
Native Web Stream pipeThrough throughput hits significant bottlenecks during processing. Benchmarks show it reaches only 630 MB/s with 1KB chunks, creating severe latency for high-volume server-side data applications.
Excessive promise allocations trigger heavy garbage collection cycles that slow performance. Minimal Garbage collection consumes 50% of available CPU resources, directly increasing infrastructure costs in serverless environments billed by compute duration.
Alternative implementations leverage modern language primitives to drastically reduce processing time. Benchmarks show these solutions running up to 120x faster than the current Web Streams API across major runtimes like Node.js and Deno.
The specification mandates immediate rejection of buffers backed by WebAssembly memory. This constraint exists because the buffer detachment model invalidates shared memory views, breaking zero-copy guarantees needed for high-performance computing pipelines.
