AllFlash storage hits 876K IOPS for AI workloads
Huawei's new storage system cuts total cost of ownership by 64% versus hybrid arrays, according to Enterprise Strategy Group validation data. This isn't a theoretical projection; it is a hard metric derived from replacing spinning disk arrays and separate NAS gateways with a single converged all-flash design. Market volatility drives component prices upward, yet this architecture proves durability need not require financial sacrifice.
The SmartMatrix full-mesh topology tolerates the catastrophic failure of seven out of eight controller enclosures without interrupting service. FlashEver cross-gen convergence allows hardware replacement cycles to proceed without downtime or data migration headaches. Native support for blocks, files, and objects within a single parallel architecture sustains over 876,000 IOPS at 32 μs latency in high-concurrency database simulations.
Traditional hybrid models cannot match these efficiency metrics while maintaining end-to-end intelligent protection against ransomware. As AI workloads demand stricter response times, the shift toward NVMe-based systems becomes mandatory. Legacy infrastructure fails to meet modern resiliency standards. Huawei's latest validation results redefine the baseline for enterprise storage expectations in 2026.
Defining Converged All-Flash Storage and the New-Gen OceanStor Dorado Architecture
New-Gen OceanStor Dorado Converged All-Flash Architecture Definition
New-Gen OceanStor Dorado unifies block, file, and object protocols into a single parallel architecture, marking an industry-first convergence for enterprise data. This design eliminates siloed storage pools by processing diverse workloads through a native interface rather than gateway translation layers. The system stores diverse data using native and parallel architecture for blocks, files, and objects, representing an industry-first convergence of these protocols in a single system. AI training clusters require simultaneous access to unstructured datasets and high-speed transactional logs without performance degradation. Operational continuity relies on FlashEver technology to manage hardware refreshes.
High-Concurrency Database Performance with 876,256 IOPS and 32 μs Latency
Simulated high-concurrency database tests confirm the system sustains over 876,256 IOPS with 32 μs latency. This ultra-high-performance threshold validates infrastructure upgrades for AI-driven transactional workloads requiring microsecond response times. Operators facing queue depth saturation must prioritize architectures delivering 50% higher performance than entry-level alternatives to prevent application timeouts. The parallel processing engine eliminates gateway bottlenecks. Storage networks must support lossless Ethernet or Fibre Channel at high-speed minimums to avoid packet drops negating the flash advantage. Most legacy switching fabrics cannot sustain the required throughput without jumbo frame reconfiguration.
Inside SmartMatrix Full-Mesh Architecture and FlashEver Cross-Gen Convergence Mechanics
SmartMatrix Full-Mesh Tolerance for Seven-Out-of-Eight Controller Failures
The SmartMatrix full-mesh architecture tolerates the failure of seven out of eight controller enclosures without service interruptions. Durability stems from a non-blocking interconnect where every controller maintains active paths to all disk shelves, eliminating single points of failure inherent in dual-controller or ring-topology designs. Operators facing storage service interruptions on legacy platforms often require complex multi-array setups to approach similar availability levels.
| Architecture Type | Max Controller Failures Tolerated | Required Sites for Equivalent Durability |
|---|---|---|
| SmartMatrix Full-Mesh | Seven of Eight | Single Site |
| Traditional Dual-Controller | One of Two | Three Sites (with SRDF) |
| Ring Topology | One of N | Two Sites |
Competitor solutions like Dell EMC frequently depend on linking two PowerMax arrays with SRDF and a third site to match this single-system durability. The cost of such external replication involves significant bandwidth overhead and management complexity that a unified mesh avoids. Realizing this tolerance demands strict adherence to cabling standards; a misconfigured cross-link can isolate nodes despite the theoretical mesh redundancy.
This design shifts the operational burden from reactive disaster recovery to proactive component monitoring. A single system achieving such high-availability reduces the need for geographically dispersed active-active pairs for local fault containment. Validate physical layer integrity during installation to ensure the logical mesh functions as specified. The result is a storage foundation capable of sustaining extreme hardware loss while maintaining continuous data access.
FlashEver Cross-Gen Convergence for Zero-Downtime Hardware Replacement
FlashEver enables cross-gen convergence by allowing new-generation and legacy hardware to coexist in the same storage pool and cluster. This architectural capability eliminates service interruptions during storage replacement while supporting online device upgrades without manual data migration. Operators configure active-active failover by grouping mixed-generation controllers into a single logical domain, ensuring I/O paths remain available even as specific nodes undergo firmware or hardware refreshes.
| Upgrade Phase | Legacy Node Status | New Node Status | Service Impact |
|---|---|---|---|
| Pre-Migration | Active | Standby | None |
| Data Rebalance | Active | Active | Latency spike |
| Cutover | Offline | Active | Zero downtime |
The process requires precise sequencing to avoid performance degradation during the data rebalance window.
- Initialize the new controller within the existing SmartMatrix mesh.
- Enable cross-gen convergence.
- Migrate LUN ownership gradually to distribute load evenly.
Mixing generations introduces a measurable tension: older drives may become bottlenecks if the rebalance algorithm prioritizes capacity over throughput matching. Aggregate pool performance temporarily aligns with the slowest component until migration completes. Schedule these operations during non-peak hours to mitigate the risk of application timeouts caused by transient latency spikes.
Dell PowerStore holds 14.7% market mindshare, yet its requirement to reserve CPUs for file services at install time prevents flexible workload redistribution without full system resets. The cost of this rigidity manifests as elevated operational overhead when AI training clusters shift between data types rapidly. Native parallel execution allows immediate resource reallocation, contrasting sharply with the static partitioning found in competing arrays. Complex multi-array setups increase the probability of configuration drift during failover events, introducing human error vectors that single-system designs avoid. Migrating from entrenched competitor ecosystems demands upfront planning to restructure data placement policies. Evaluate total path latency rather than raw IOPS when selecting storage for real-time inference workloads.
Quantifying TCO Reduction and Performance Gains Against Traditional Hybrid Storage
Defining the 64% TCO Reduction Mechanism in All-Flash vs Hybrid Storage
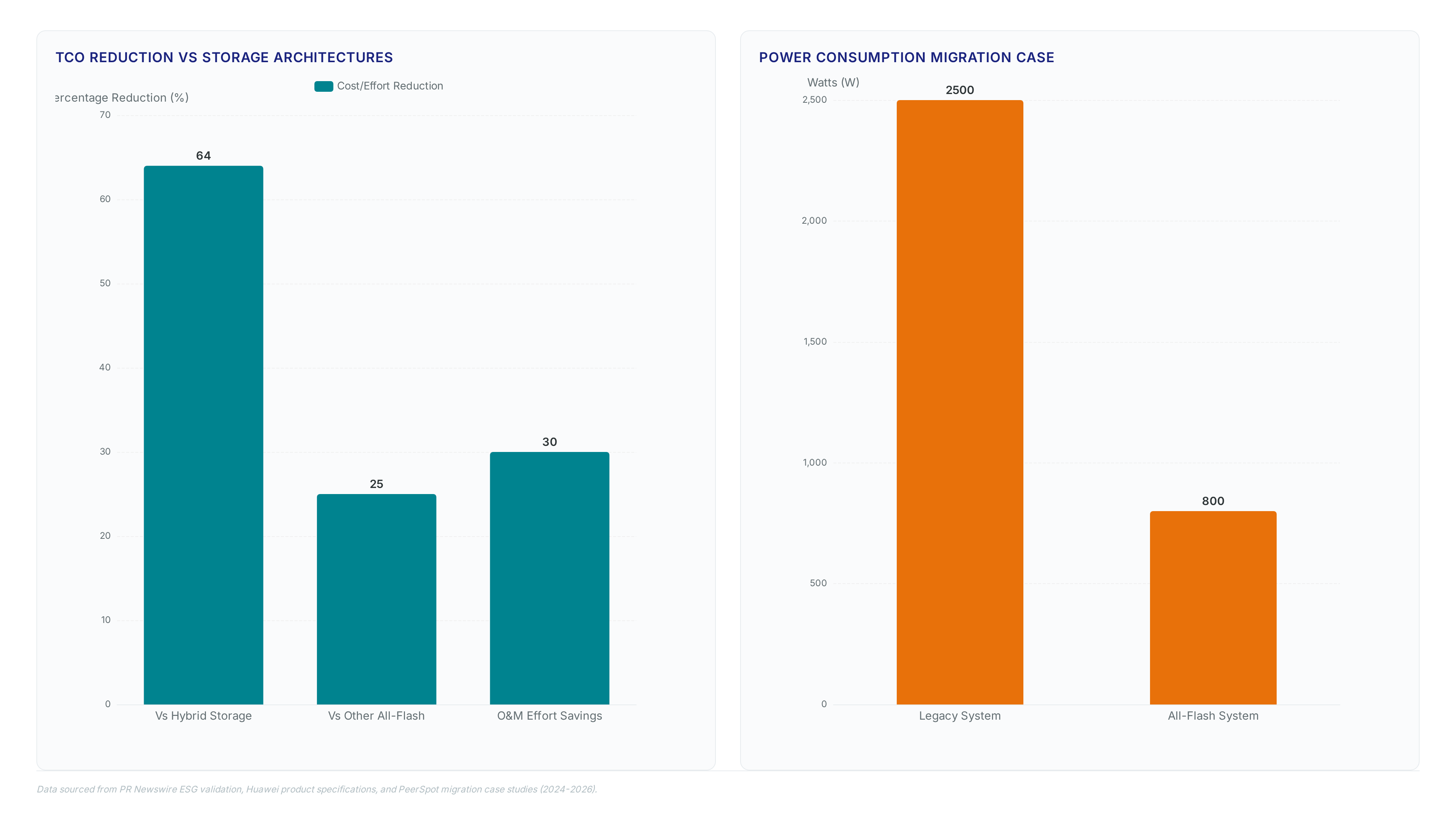
Procurement savings drive the initial 64% reduction against hybrid storage by eliminating spinning disk arrays and separate NAS gateways. Energy costs drop further because the OceanStor Pacific 9928 consumes only 0.25 W/TB, a figure impossible for mechanical media to match. Operational expenditure shrinks as automated health checks replace manual tiering policies that plague mixed-media environments.
Retiring legacy HDD pools entirely remains a prerequisite for capturing these gains, a constraint that delays ROI for sites with archival cold data mandates. The 25% lower TCO versus other all-flash benchmarks stems from protocol convergence rather than raw capacity density alone. A hospital deployment linked to Tsinghua University confirmed a 30% saving in O&M efforts after migrating from hybrid tiers. Operators must weigh this efficiency against the upfront capital outlay required to replace functional spinning disks before end-of-life. FlashEver technology mitigates this risk by allowing mixed-generation hardware coexistence within the same cluster. The net result shifts total cost ownership from ongoing power and floor leases to a one-time hardware purchase. Audit current watt-per-terabyte metrics before approving budget reallocations.
Applying DataMaster AI Agents for Proactive Maintenance and Fault Location
The DataMaster agent within iMaster DME executes automatic health assessment and locates faults in minutes, shifting operations from reactive to predictive. This capability addresses a specific gap where competitors prioritize static efficiency over flexible durability. Pure Storage users often cite superior data compression ratios, while Dell PowerStore focuses on VMware integration, yet neither emphasizes minute-level fault localization to the same degree. Huawei operators accept a steeper learning curve.
Adopting all-flash storage for AI workloads requires more than raw throughput; it demands intelligent management to prevent bottlenecks before they impact training jobs. Traditional hybrid storage struggles here because mechanical tiering cannot match the speed of automatic system health assessment. Teams lacking dedicated storage engineers may find the advanced feature set overwhelming without the thorough deployment assistance Huawei provides. Evaluate management overhead alongside raw performance metrics during vendor selection. Weigh the immediate productivity dip against long-term stability gains. Relying on manual monitoring in high-concurrency environments introduces unacceptable risk when performance trend prediction can automate the response. The decision hinges on whether an organization values incremental compression gains or total operational continuity.
Architecture Flexibility: Huawei Protocol Support Versus Dell PowerStore File Service Constraints
Dell PowerStore mandates a permanent File Services decision at install time, forcing a complete wipe to change protocols later. This rigid design contrasts with Huawei's parallel architecture, which supports block, file, and object data simultaneously without resetting the system. Operators facing shifting AI workloads find the competitor's siloed approach creates operational friction when data types evolve post-deployment. Huawei's 3D scaling capability allows performance, capacity, and functions to expand independently, avoiding the over-provisioning penalties common in rigid arrays. Hybrid storage struggles with mixed-protocol latency, yet all-flash convergence eliminates the gateway bottlenecks that plague traditional setups.
Choosing a fixed NAS configuration locks capital into a specific use case, whereas flexible support preserves asset utility across changing enterprise demands. The cost of re-architecting storage due to initial protocol errors often exceeds the price premium of a converged system. Prioritize platforms that allow online protocol modification to safeguard against unpredictable data growth patterns.
Deploying Intelligent Management and Ransomware Protection for Enterprise Durability
iMaster DME DataMaster Agent Capabilities for AI-Driven Health Assessment
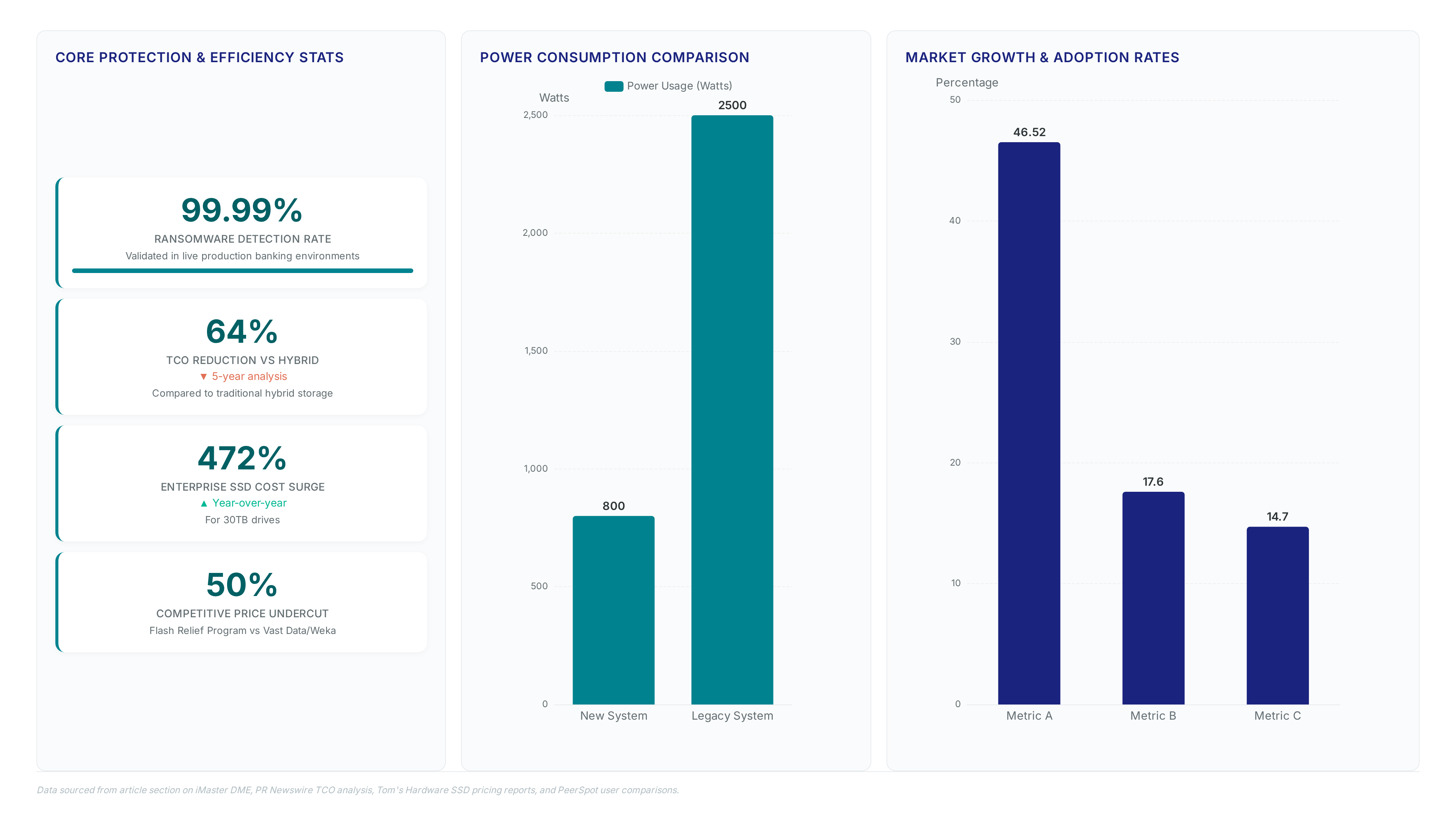
The DataMaster agent executes automatic health assessment and locates faults within minutes using AI-driven analysis. Operators implement intelligent storage management by deploying the agent to shift from reactive repairs to predictive maintenance strategies. This approach contrasts with competitors prioritizing static efficiency over flexible durability, as Pure Storage users often cite superior data compression ratios while Dell PowerStore focuses on VMware integration. Neither competitor emphasizes minute-level fault localization to the same degree found in the iMaster DME platform.
| Capability | Function | Operational Impact |
|---|---|---|
| Health Assessment | Continuous AI scanning | Prevents latent failures |
| Trend Prediction | Performance forecasting | Enables capacity planning |
| Fault Location | Root cause isolation | Reduces mean time to repair |
Relying solely on automated alerts without human verification creates a tension where false positives may trigger unnecessary failovers in sensitive environments. The cost of this rigorous monitoring is the operational overhead required to interpret complex predictive data streams accurately. Integrate these agents into existing NOC workflows to balance automation with expert oversight.
Deploying Built-In Ransomware Detection to Secure SAN and NAS Environments
Activation of built-in ransomware detection across SAN and NAS volumes requires enabling the intelligent protection module within the storage OS configuration. Operators configure the system to scan I/O patterns for encryption signatures, a process validated by a banking client migration that achieved a detection rate of 99.99% in live production environments. The mechanism functions by analyzing write amplification and entropy changes at the block level before data commits to flash media. This approach secures both file and block protocols simultaneously without requiring external security gateways or additional hardware appliances.
| Environment | Protection Scope | Detection Trigger |
|---|---|---|
| SAN | Block-level I/O | Entropy spike |
| NAS | File-level operations | Mass rename events |
Continuous scanning introduces a measurable latency penalty during peak transaction windows if thresholds remain set to maximum sensitivity. The cost is observable in high-concurrency database workloads where aggressive pattern matching competes for controller CPU cycles. Network teams must tune detection policies to balance security posture against the strict response time requirements of AI education clusters. Failure to adjust these parameters risks throttling throughput during legitimate bulk data ingestion phases.
Cyber threats demand active policy tuning rather than static default configurations. While competitors like Pure Storage rely on immutable snapshots for recovery, this system prevents the initial write operation through real-time analysis. Deploying end-to-end intelligent protection ensures data integrity remains intact even as attack vectors evolve beyond simple file encryption techniques. Operators gain a proactive defense layer that complements existing backup strategies without duplicating infrastructure spend.
Validation Checklist for Active-Active Failover Across Blocks Files and Objects
Administrators must verify smooth failover coordination across block, file, and object protocols before production cutover.
- Confirm SmartMatrix mesh links replicate state between sites without manual intervention.
- Validate built-in ransomware detection.
- Test failover latency during peak concurrency to ensure business continuity thresholds remain intact.
| Protocol | Failover Trigger | Recovery Target |
|---|---|---|
| Block | Controller loss | Secondary site LUN |
| File | Network partition | Remote namespace |
| Object | Site outage | Bucket replica |
Skipping the ransomware scan validation leaves SAN and NAS environments exposed to latent encryption attacks during transition states. The active-active design prevents data loss, yet operators frequently overlook verifying detection logic across all three protocol stacks simultaneously. A failure to test object storage failover specifically risks breaking AI training pipelines that depend on continuous bucket access. Isolate each protocol stack during dry runs to identify synchronization gaps hidden by successful block-level tests. This granular approach exposes configuration drift that aggregate health checks miss.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in designing scalable S3-compatible storage infrastructures for AI and machine learning workloads. His deep expertise in cloud storage architecture and data infrastructure optimization makes him uniquely qualified to analyze the technical validation of Huawei's New-Gen OceanStor Dorado. As enterprises increasingly demand high-performance, resilient storage to manage exploding data volumes in the AI era, Chen's daily work involves evaluating how converged all-flash systems integrate with modern cloud-native environments. At Rabata. Io, a provider focused on cost-effective, high-speed object storage, he constantly assesses industry benchmarks to ensure interoperability and performance for startup and enterprise clients. This article uses his practical experience in bridging on-premise flash innovation with scalable cloud strategies, offering readers a grounded perspective on how new storage validations impact real-world AI data operations and architectural decision-making.
Conclusion
Scaling converged storage often reveals hidden friction where protocol-specific latency spikes degrade AI training pipelines, regardless of raw throughput claims. The operational reality shifts from mere capacity planning to managing the complexity of simultaneous failover logic across disparate data types. While procurement savings offer immediate relief, the long-term viability of these systems depends on sustaining sub-millisecond response times as NVMe traffic volumes expand by a steady annual rate. Organizations that treat this architecture as a static purchase rather than a flexible fabric will face diminishing returns within eighteen months as workload concurrency outpaces legacy tuning methods.
Deploy this platform only if your environment demands unified protocol management for mixed workloads and you can commit to quarterly cross-protocol stress testing. Do not migrate cold archival data to these high-performance tiers unless specific latency SLAs mandate it, as this dilutes the economic advantage. The window to use this efficiency gap before market standardization closes is narrow, likely ending by late next year.
Start by auditing your current failover scripts this week to ensure they explicitly validate object bucket replication alongside traditional LUN and namespace checks. Most existing automation suites ignore object state during site transitions, creating a silent single point of failure that undermines the entire active-active investment.
Frequently Asked Questions
Organizations reduce five-year total cost of ownership by up to 64% versus traditional hybrid storage. This significant saving covers procurement, operations, and energy consumption while maintaining high performance for AI workloads.
The single system reliability is rated at 99.99999%, ensuring seven-nines uptime even during controller failures. This full-mesh topology tolerates catastrophic enclosure loss without interrupting active business services or data access.
The architecture delivers 20% higher performance compared to the general industry benchmark for all-flash storage solutions. This margin prevents bottlenecks that typically stall model training pipelines in modern artificial intelligence clusters.
Storage networks must support lossless Ethernet or Fibre Channel at 32 Gbps minimums to avoid packet drops negating flash advantages. Legacy switching fabrics often fail to sustain this required throughput without reconfiguration.
Operators facing queue depth saturation must prioritize architectures delivering 50% higher performance than entry-level alternatives to prevent application timeouts. This capacity ensures AI training clusters do not suffer from stalled processing.
