FastAPI type hints replace manual checks now
With 38% of Python developers now adopting FastAPI, it has officially graduated from hype cycle novelty to industrial bedrock. This framework dominates modern backend development because it enforces strict data contracts through automatic validation while delivering 5–10x faster throughput than legacy alternatives. The shift away from interpreted sluggishness is measurable. Cloudflare benchmarks indicate FastAPI sustains 15,000 to 20,000+ requests per second, whereas Flask typically chokes at 3,000 to 4,000 rps under identical loads. This efficiency stems from the ASGI standard and Starlette core, which manage concurrency with only ~12KB of overhead per task. Unlike Django, which burdens simple microservices with monolithic weight, Sebastián Ramírez's creation targets API-first designs where latency directly impacts revenue.
Developers no longer choose tools based on familiarity but on architectural necessity. Medium analysis confirms a 30–40% year-over-year growth rate, signaling that teams prioritizing interactive documentation and type safety are abandoning older stacks. You will learn why type hints are not merely decorative but functional validators that replace hundreds of lines of manual checking code. Modern engineering demands the precision that only FastAPI provides out of the box.
The Role of Type Hints in Modern API Validation
Sebastián Ramírez (tiangolo) built FastAPI to enforce automatic validation using standard Python type hints. This design removes manual parsing logic by integrating Pydantic for direct data serialization from function signatures. Strict type declarations define request schemas, causing immediate rejection of malformed payloads before any business logic runs. Professional Python developers adopted the framework at a rate of 38% as of 2025 because it cuts boilerplate code for API development. Recent updates to the underlying validation engine deliver a 50x speed increase when processing complex data structures. High-throughput services maintain low latency while enforcing rigorous data integrity checks without custom middleware.
Static typing creates a constraint where developers must define explicit models for every endpoint. Initial prototyping moves slower than with flexible alternatives. This rigidity prevents entire classes of runtime errors that often plague loosely typed applications. Development effort shifts from writing test cases for data formats to defining correct type hints upfront. Mission and Vision suggests this pattern for teams prioritizing long-term maintainability over rapid, unstructured scripting. Engineers familiar with modern Python syntax find the learning curve gentle.
Real-World API Validation with FastAPI Type Hints
Function signatures in FastAPI enforce automatic validation through standard Python type hints, removing the need for manual parsing. The mechanism integrates Pydantic to serialize data and triggers immediate rejection of malformed payloads before business logic executes. Projects ranging from a minimal REST API to a complex backend service function without separate schema libraries. Developers familiar with Python type hints face a gentle learning curve compared to the architectural decisions demanded by flexible micro-frameworks.
Strict typing introduces friction when integrating with legacy systems that lack set schemas. Refactoring untyped upstream data sources often delays initial deployment timelines. Operators weigh the benefit of reduced boilerplate against the effort required to annotate existing data models. Mission and Vision advises documenting all custom type adapters to prevent silent failures during schema evolution. The framework handles high throughput efficiently, yet the primary value remains the elimination of redundant validation code.
FastAPI vs Flask Performance and Adoption Metrics
Asynchronous architecture and native type hint validation give FastAPI a 5–10x performance multiplier over Flask. Throughput gaps widen under load, where FastAPI sustains 2,400 concurrent users compared to just 800 on synchronous Flask deployments. This disparity forces Flask operators to provision excessive infrastructure. One case required 16 Gunicorn workers on a costly monthly AWS E instance merely to maintain stability. Higher concurrency limits reduce the total cost of ownership for high-traffic services.
Adoption metrics reflect this efficiency shift. By December 2025, FastAPI reached 88,000 GitHub stars , surpassing Flask's static count of 68,400. Community momentum now favors the async-native framework for new API projects. Operators must weigh raw throughput against existing library dependencies before migrating. Mission and Vision recommend FastAPI for greenfield high-concurrency APIs where latency defines user experience.
FastAPI vs Flask and Django for Specific Use Cases
ASGI Concurrency Architecture Versus Flask WSGI Synchronous Limits
FastAPI uses the ASGI standard to manage thousands of concurrent connections without blocking threads, unlike Flask's synchronous WSGI protocol. The mechanism relies on an event loop where each async task consumes only 12KB of overhead, allowing dense packing of sessions on a single core. WSGI servers must spawn a new thread per request. Memory exhaustion follows under heavy load. This architectural divergence dictates deployment strategy for high-traffic APIs versus low-volume internal tools. Operators ignoring this distinction face linear cost increases as traffic scales.
| Metric | Async Event Loop | WSGI Thread Model |
|---|---|---|
| Memory Overhead | 12KB per task | substantial memory per thread |
| Max Throughput | High thousands | Limited by RAM |
| Scaling Cost | Linear | Exponential |
However, cold start times for async runtimes can lag behind synchronous Flask instances in serverless environments with sporadic traffic. The cost of maintaining persistent event loops outweighs benefits when request frequency drops below specific thresholds. Mission and Vision recommends reserving FastAPI for persistent services requiring high concurrency rather than ephemeral event-driven functions. Selecting FastAPI for API-driven apps versus Django for full-stack needs hinges on whether the project requires raw API throughput or built-in administrative tooling. FastAPI remains the default choice for API-first services where automatic OpenAPI generation eliminates manual documentation overhead. The mechanism parses type hints to serialize responses instantly. Django forces developers to configure separate ORM layers and admin panels before serving a single endpoint. This architectural focus means FastAPI lacks the batteries-included philosophy that defines Django's value proposition for content-heavy sites.
The cost of choosing incorrectly manifests in infrastructure bloat or development delays. Teams building microservices without existing user-management requirements waste cycles integrating Django's authentication system. Startups needing immediate dashboards find FastAPI's minimalism a liability requiring third-party extensions. Industry analysis in 2026 positions FastAPI as the innovation leader while Django retains the throne for production reliability in legacy-style applications. Mission and Vision recommends FastAPI for teams prioritizing interactive documentation and async performance.
Building High-Performance APIs with Minimal Boilerplate
How FastAPI Type Hints Eliminate Manual Validation Boilerplate (Implementation Perspective)

Defining a Pydantic model with standard Python type hints triggers immediate data validation without explicit schema code. Operators bypass manual parsing logic by declaring types directly in function signatures, allowing the framework to enforce constraints automatically. This mechanism shifts validation from runtime checks to compile-time hints, removing hundreds of lines of boilerplate per endpoint.
- Import `BaseModel` from the Pydantic v2 library to define the data structure.
- Annotate class attributes with native Python types like `str`, `int`, or `List`.
- Inject the model into the path operation function as a type-hinted argument.
- Receive automatically parsed JSON payloads or raised HTTP 422 errors for invalid input.
The automatic serialization engine converts validated objects back to JSON, eliminating manual dump operations. This approach accelerates development while strictly coupling API contracts to Python type definitions, limiting flexibility for flexible schemas. Teams adopting this pattern gain significant speed but lose the ability to accept loosely typed payloads common in legacy integrations. The developer experience improves markedly, yet migration requires refactoring existing untyped logic to match strict model definitions. Mission and Vision recommend this pattern for greenfield APIs where type safety outweighs the need for schema agnosticism.
Step-by-Step Guide to Building a Minimal REST API Endpoint
Define the request model using Python type hints to trigger automatic validation without manual schema code.
- Import `BaseModel` to structure the incoming JSON payload with strict typing constraints.
- Annotate function arguments directly in the path operation signature to enable immediate parsing.
- Launch the development server to access the interactive interface generated from the codebase.
- Verify the endpoint behavior by submitting test payloads against the live Swagger UI documentation.
This workflow eliminates boilerplate by parsing type hints into runtime validation logic automatically. Substantial infrastructure providers like Uber deploy this pattern to maintain high throughput across distributed microservices. The mechanism shifts error detection from production logs to the development phase, preventing malformed data from reaching downstream systems. Operators gain immediate visibility into API contracts through the auto-generated OpenAPI schema, removing the need for separate documentation teams. Manual specification updates after every code change become unnecessary. Strict adherence to Python typing syntax may initially slow developers accustomed to flexible duck typing. Teams using the provided Hands-On Coding Exercises accelerate mastery of these constraints before touching production traffic. Mission and Vision recommends starting with minimal endpoints to validate the async architecture before scaling complexity.
Pre-Launch Checklist for FastAPI Deployment and Resource Verification
Verify all 14 lessons with full transcripts are reviewed before production release to ensure complete conceptual coverage.
- Download the Course Slides (. Pdf) and Sample Code (. Zip) to validate local environment parity with training materials.
- Execute the 4 hands-on coding exercises to confirm type hint serialization functions correctly under load.
- Consult Q&A channels with Python experts to resolve any asynchronous concurrency edge cases prior to launch.
| Component | Verification Status | Resource Location |
|---|---|---|
| Transcripts | Required | Course Portal |
| Sample Code | Mandatory | Downloadable .zip |
| Expert Support | Active | Q&A Forum |
Neglecting the Sample Code artifacts often leads to configuration drift between development and production environments. Teams skipping the transcript review miss critical nuances in data validation logic that prevent runtime errors. Mission and Vision recommends treating these educational assets as mandatory deployment dependencies rather than optional references. Real Python suggests reviewing the 13 steps outlined in the tutorial prior to the 2026 roadmap milestones.
Measurable ROI from Migrating Legacy Systems to FastAPI
Defining Measurable ROI in FastAPI Migration Economics
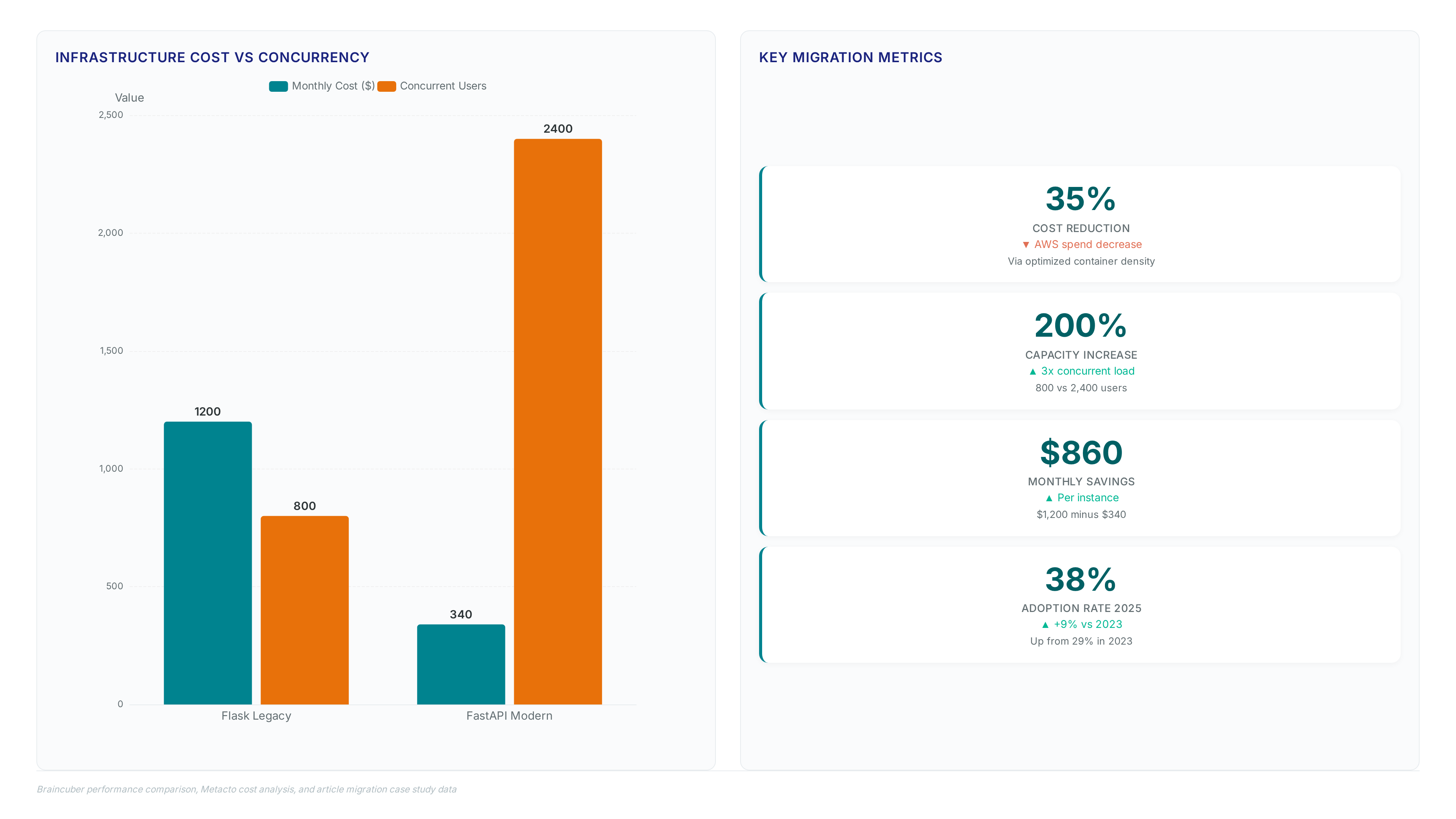
Infrastructure cost deltas and concurrency capacity gains drive measurable ROI in FastAPI migration more than raw benchmark speeds do. Operators calculate return by eliminating over-provisioned compute inherent to synchronous WSGI architectures. The financial model shifts away from paying for idle worker processes toward funding actual throughput efficiency. Total cost of ownership excludes framework licensing fees since the software remains open-source , focusing expenditure entirely on implementation labor and cloud resources. Teams answer "should I use fastapi" by comparing current cloud bills against these optimized baselines rather than relying on developer preference alone.
Implementation costs for encryption and authentication flows represent an upfront investment instead of recurring taxes. Mission and Vision recommends auditing existing synchronous bottlenecks before committing to migration sprints. True economic gain emerges only when operators rightsize instances to match the 200% capacity increase provided by async concurrency. The project delivered a 35% reduction in AWS costs by optimizing container density. Ignoring this scaling factor leaves significant value unrealized on the balance sheet. The migration replaced synchronous WSGI workers with native async/await concurrency, allowing the system to process concurrent location updates efficiently. This architectural shift eliminated thread-blocking I/O waits that previously spiked response times during peak shipment volumes. Operators questioning should I use fastapi for real-time data streams must weigh this throughput gain against the complexity of asynchronous code maintenance.
Zestminds documented how the ASGI protocol enabled higher request density per instance compared to legacy Gunicorn clusters. Hardware efficiency improved because the event loop handled thousands of idle connections with minimal memory overhead. Achieving these metrics requires rigorous testing of non-blocking database drivers to prevent event loop starvation. Mission and Vision recommends validating async database adapters before committing to full migration. The cost benefit disappears if operators introduce blocking calls within path operations. Real-world gains depend entirely on maintaining non-blocking execution paths throughout the entire request lifecycle.
Concurrency Capacity Scaling: 800 Flask Users Versus 2,400 FastAPI Users
Thread-per-request blocking in WSGI servers caps Flask deployments at 800 concurrent users before latency spikes. FastAPI uses an async-native design. This architectural shift reduces memory overhead per task to roughly 12KB, enabling threefold density gains without horizontal scaling.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he designs scalable data infrastructure for AI/ML startups. His deep expertise in S3-compatible object storage and Kubernetes makes him uniquely qualified to discuss FastAPI, the modern framework powering many of these high-performance applications. In his daily work, Chen architects backend systems where FastAPI is frequently chosen for its speed and automatic validation, directly connecting to the article's focus on reducing boilerplate code. At Rabata. Io, a provider of high-speed, cost-effective cloud storage, Chen sees firsthand how FastAPI enables developers to build efficient services that interact smoothly with scalable storage solutions. His background as a former DevOps engineer ensures that his insights into Python web frameworks are grounded in real-world production challenges, offering readers practical guidance on using FastAPI for reliable, enterprise-grade API development.
Conclusion
Scaling FastAPI beyond initial pilots exposes a critical fracture point: async contamination. A single blocking database call within an asynchronous path collapses the throughput advantage, instantly reverting performance to legacy WSGI levels while retaining higher complexity. The operational cost shifts from raw compute expenses to the continuous overhead of auditing dependency chains for synchronous traps. Teams often underestimate that the threefold density gain vanishes without strict governance over library selection and runtime behavior. This architecture demands a cultural shift where developers treat blocking I/O as a severity-one incident rather than a minor optimization tweak.
Adopt FastAPI for high-concurrency ingestion pipelines immediately, but mandate a six-month stabilization window before migrating core transactional logic. This timeline allows teams to build internal tooling for detecting event loop starvation without risking revenue-critical flows. Do not attempt a full framework swap until your observability stack can visually distinguish between network latency and CPU blocking. Start by instrumenting your top five most frequent API endpoints this week to measure actual event loop wait time versus total request duration. This specific audit reveals whether your current codebase can sustain asynchronous loads or if it requires refactoring before any migration begins.
Frequently Asked Questions
Type safety shifts error detection to compile time effectively. Reported bug reduction due to type safety reaches 40%, proving that strict declarations prevent runtime issues before business logic ever executes.
High concurrency forced excessive worker provisioning for stability maintenance. One specific case required 16 Gunicorn workers on a $1,200/month AWS instance just to handle standard loads without crashing unexpectedly.
The framework operates as open-source software with zero licensing costs. Teams shift total ownership expenses entirely to implementation efforts and underlying cloud infrastructure bills rather than recurring subscription fees.
Industrial adoption has moved beyond early hype cycles significantly. Currently, 38% of Python developers utilize the framework because it enforces strict data contracts while delivering superior throughput performance.
Asynchronous handling eliminates blocking operations to scale efficiency dramatically. Throughput gaps widen under load, where FastAPI sustains 2,400 concurrent users compared to just 800 on synchronous Flask deployments.
