AL2023 Migration: Stop Manual Gateway Swaps Now
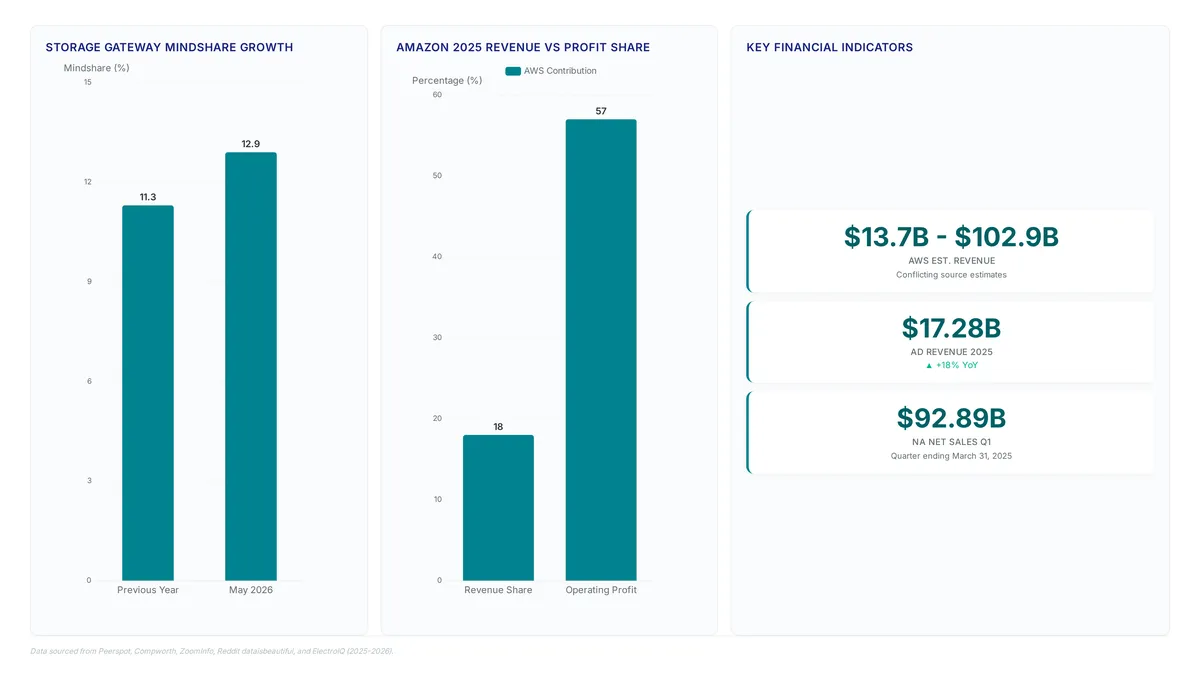
AWS Storage Gateway holds a significant market share as of May 2026, making the AL2023 migration a critical priority for maintaining relevance (Peerspot). This isn't a patch day; it's a rip-and-replace operation. You need a strategic blueprint to abandon legacy patterns, leveraging Terraform modules and Ansible playbooks to orchestrate the transition. The goal is zero-downtime results using Elastic IP and DNS strategies, not hoping your hand-rolled scripts don't drift during the storage gateway migration to AL2023.
Organizations clinging to manual coordination for S3 File Gateway instances invite configuration drift and extended outages. A disciplined automation approach preserves critical gateway IDs and cache disk configurations while eliminating the guesswork of Active Directory rejoin procedures and EBS volume handling.
This guide dissects the technical requirements for maintaining S3 storage classes like S3 Standard-IA and S3 Intelligent-Tiering during the swap. We focus on using Elastic IP addresses to mask underlying instance replacement, ensuring smooth connectivity for end users while the backend transitions to the new Amazon Linux based environment.
The Strategic Necessity of Automating AL2023 Gateway Migration
Defining the AL2 to AL2023 Gateway Migration Deadline
Treat this as a distinct migration event, not an upgrade. The architecture demands a new instance rather than a standard update, forcing a parallel deployment window where old and new gateways coexist. AWS documentation explicitly states that users should replace the gateway with a new instance to respond to migration notifications or improve performance, specifically impacting critical components like the S3 File Gateway.
You cannot directly migrate settings or data between differing gateway types, such as from an FSx File Gateway to an S3 File Gateway, without following a structured replacement procedure. The absence of a direct upgrade mechanism means ignoring these constraints leads to manual configuration drift. Teams must prepare to re-join Active Directory and re-map cache disks on fresh EC2 instances to ensure continuity. Understanding this architectural constraint forms the foundation for building a repeatable automation workflow.
Executing Disk Swaps and API Calls for Gateway Migration
The mechanical core of moving from Amazon Linux 2 to the new AL2023 environment is the disk swap procedure. Operators launch fresh instances and initiate specific migration steps to transfer gateway identity and configuration metadata. Infrastructure as code defines the exact state of the new EC2 instance and its attached EBS volumes before any physical change occurs, eliminating the manual timing errors common when engineers attempt to coordinate volume detachment and reattachment sequences by hand.
Perform this sequence during a scheduled maintenance window to ensure no active file locks interfere with the underlying block storage transfer. This approach guarantees that the new gateway matches the security and network configuration of the predecessor exactly. However, rushing the API call before volume stabilization causes attachment failures that require manual rollback. Validating the new instance health status before switching production traffic helps avoid extended downtime events. Speed matters, but not at the expense of stability.
Manual Migration Errors Versus Infrastructure as Code Reliability
Manual coordination of hundreds of gateways across multiple accounts introduces timing errors that corrupt cache states during OS transitions. The mechanism of failure typically involves race conditions where application data writes occur mid-migration, leading to data inconsistencies. Relying on human operators to execute complex disk swaps and API calls across diverse environments creates an unacceptably high surface area for configuration drift.
Teams attempting manual methods often struggle to preserve gateway identity and rejoin Active Directory domains consistently after the OS swap. This inconsistency forces costly remediation cycles that delay project timelines and increase operational expenditure. The cost equation is simple: the initial investment in writing and testing automation scripts versus the recurring expense of human error. Adopting automated workflows helps mitigate these structural risks inherent in large-scale hybrid cloud migrations. Organizations ignoring this shift risk service interruptions as legacy support windows close.
Architectural Mechanics of Terraform and Ansible Orchestration
Terraform Module Variables for AWS Storage Gateway Cloning
Defining the gateway_id variable is the singular requirement for preserving identity during cloning operations. This identifier anchors the new AL2023 instance to existing configurations, ensuring the migration campaign recognizes the replacement as a continuation rather than a new entity. Operators must capture this value from the current deployment before initiating any Terraform plan. Without this specific string, the new gateway cannot inherit the cached metadata or active shares of the predecessor. If the gateway_id is incorrect, the new instance will not assume the role of the old one, forcing a full re-registration.
Network interface mapping requires distinct variable assignment based on the underlying hypervisor. Nitro-based instances use ens5 for primary connectivity, whereas legacy Xen-based platforms rely on eth0. Misidentifying the network device in the Terraform module prevents the gateway from establishing outbound connections to the AWS service endpoints.
| Platform | Interface Variable | Migration Risk |
|---|---|---|
| Nitro | ens5 | High if hardcoded to eth0 |
| Xen | eth0 | Low (default behavior) |
The instance_type variable enables vertical scaling during the upgrade window. Teams often select a newer generation family to handle increased throughput demands post-migration. This approach allows the infrastructure code to address performance bottlenecks simultaneously with the OS upgrade. However, changing instance families may alter available network bandwidth, requiring validation of throughput guarantees before cutover. Automation eliminates the manual error of mismatched configurations but introduces a dependency on accurate variable injection.
Ansible playbooks execute the precise logic required to preserve cache disks and transfer gateway identity without data loss. The automation sequence begins by detaching the existing EBS cache volume from the legacy AL2 instance while strictly preventing any format operations. Subsequent tasks attach this preserved volume to the new AL2023 target, ensuring the local cache remains intact for immediate read acceleration. This approach eliminates the lengthy re-seeding periods typical of manual rebuilds.
For environments using SMB shares, the playbook configures the user_data variable to specify the Active Directory DNS server during initialization. This specific configuration allows the new instance to rejoin the domain automatically upon first boot. Operators can reference the official procedure for replacing your existing S3 File Gateway to validate the step order. Failure to inject these DNS settings results in authentication failures that block client access entirely.
The primary limitation of this orchestration model is its strict dependency on the source instance remaining online until the volume handoff completes. If the legacy gateway crashes mid-playbook execution, the automation cannot retrieve the necessary volume identifiers to proceed. Teams must ensure network connectivity between the control node and both EC2 instances throughout the window.
This migration method requires 1, 2 hours of downtime per gateway during the maintenance window. Operators must plan for this outage because the new AL2023 gateway instance receives a new private IP address upon provisioning. Without Elastic IP re-association or immediate DNS updates, client applications lose connectivity to their storage mounts. The private IP address shift forces a remount operation across all connected hosts if network abstraction layers are absent. Terraform automation mitigates risk by scripting the exact sequence of resource creation and network re-binding. Configuring the gateway_id variable ensures the new instance inherits the correct identity metadata from the legacy system.
| Strategy | Client Impact | Implementation Complexity |
|---|---|---|
| Static IP | High (Remount required) | Low |
| Elastic IP | None (Transparent) | Medium |
| DNS Update | Low (TTL dependent) | Low |
Rabata.io recommends using Elastic IPs to maintain continuous share availability throughout the upgrade cycle. Failure to abstract the underlying IP address results in fragmented access patterns during the transition phase. The downtime window expands if manual intervention is needed to reconfigure individual client mount points. Automation reduces the probability of human error when swapping network attachments between the old and new instances. Precise orchestration ensures the cache volume attaches correctly before the gateway service starts.
Executing Zero-Downtime Migration with Elastic IP and DNS Strategies
Defining Elastic IP Reassociation and DNS Propagation in Gateway Migration
A fresh AL2023 gateway instance arrives with a distinct private IP, demanding swift network adjustments to sustain connectivity. Administrators detach the Elastic IP from the legacy Amazon Linux 2 unit and bind it to the new AL2023 target. Relying exclusively on DNS propagation creates variable lag times that depend entirely on set Time-To-Live values.
| Feature | Elastic IP Reassociation | DNS Record Update |
|---|---|---|
| Propagation Speed | Immediate | Dependent on TTL |
| Client Impact | Transparent reconnect | Potential caching delay |
| Failure Mode | IP conflict if misapplied | Stale resolution |
| Best Use Case | Fixed endpoint requirements | Flexible architecture |
Immediate IP reassignment offers speed while DNS updates provide administrative ease. This strategy removes uncertainty regarding cache expiration across varied client networks. Correct sequencing keeps the storage gateway reachable during the entire operating system upgrade.
Executing Terraform Init Plan and Apply for Storage Gateway Migration
This order checks module configuration against the target state prior to committing infrastructure changes. Resulting Terraform outputs supply identifiers needed for the next automation stage. These IDs serve as the single source of truth linking compute resources to storage volumes.
The script uses the generated instance ID to attach preserved EBS cache disks and rejoin the gateway to its domain. Data synchronization checks drive execution duration rather than network latency.
| Step | Command/Action | Primary Output |
|---|---|---|
| Initialization | `terraform init` | Provider plugins installed |
| Validation | `terraform plan` | Execution preview |
| Provisioning | `terraform apply` | `new_gateway_instance_id` |
| Configuration | Ansible playbook | Active gateway status |
Re-associating the Elastic IP lets clients keep connections without remounting shares, unlike DNS updates suffering propagation delays. Teams must verify gateway status in the console before shutting down the legacy Amazon Linux 2 host. Such a methodical process stops the configuration drift often seen in manual upgrades.
Validating CachePercentDirty Metric and S3 Upload Completion Before Migration
The CachePercentDirty metric must hit zero before any migration attempt starts. This specific threshold confirms all cached data has fully uploaded to Amazon S3, preventing data loss during transition. Operators also update the existing AL2 gateway to the latest software version to meet compatibility needs for the AL2023 target environment.
| Pre-flight Check | Required State | Consequence of Failure |
|---|---|---|
| CachePercentDirty | None | Data loss on volume detachment |
| S3 Upload Status | Complete | Missing objects in new gateway |
| Software Version | Latest Available | Migration campaign rejection |
Ence of Failure : : : CachePercentDirty None Data loss on volume detachment S3 Uploa.
Skipping these validations forces a choice between extended downtime for manual verification or accepting potential data inconsistency. This approach shifts validation from a manual post-deployment task to an automated gatekeeper function. The cost is a strictly enforced pause in the pipeline until the source system reaches a quiescent state.
Resolving Common Migration Failures and Volume Attachment Errors
Defining Volume Attachment Failures and API Call Errors
EC2 instances fail to mount EBS volumes when Availability Zone mismatches block the attachment path or incomplete detachment sequences leave locks in place. Automation scripts frequently trigger lookup errors because they cannot resolve the correct target identifier during the gateway swap. Missing permissions or absent utilities required to parse API responses often cause these specific lookup failures.
A primary mechanical failure mode involves attempting to attach a volume to a new AL2023 instance located in a different Availability Zone than the source cache disk. AWS enforces strict locality rules where EBS volumes must reside in the same zone as the attaching compute resource.
- Manual intervention increases the risk of selecting incorrect zone identifiers during high-pressure recovery scenarios.
- Scripts lacking explicit zone validation logic will silently fail or attach storage to non-existent instances.
- Permission gaps prevent the orchestration layer from verifying the current state before issuing attachment commands.
- Rapid automation attempts often bypass regional constraints, guaranteeing a failed migration if zone affinity is not validated first.
Speeding up the process without validating zone affinity guarantees a failed migration. Ignoring these dependency checks forces a complete restart of the provisioning workflow, extending the maintenance window notably. Validating zone alignment before executing attachment commands prevents cascading API call errors that complicate rollback procedures. The new instance cannot reclaim the original identity without precise gateway ID preservation, leaving connected clients unable to reach their data endpoints.
Executing Recovery Steps for Cache Disk Mismatches and Dirty Data
Non-zero CachePercentDirty values mandate a waiting period for data upload to Amazon S3 before proceeding. If CachePercentDirty is not 0, users must wait for data upload to Amazon S3. Operators often attempt immediate volume reattachment, triggering irreversible data loss if the gateway flushes incomplete write buffers. This race condition creates a tension between migration speed and data integrity that automation must resolve through polling logic.
Block-level cache consistency depends on strict sequencing that manual intervention often disrupts. When cache disk counts mismatch, the root cause typically involves missing EBS volume attachments on the new AL2023 instance. Verification requires confirming that all original cache volumes are physically attached to the replacement EC2 instance within the same Availability Zone. A failed migration API call frequently results from attempting this attachment while the source gateway remains active, locking the underlying block devices.
- Pause the migration workflow until CachePercentDirty reaches zero.
- Validate that every original cache volume appears in the new instance configuration.
- Re-execute the attachment command only after confirming source gateway shutdown.
- Implement exponential backoff in automation playbooks to handle synchronization windows gracefully.
- Monitor transfer progress instead of troubleshooting preventable state conflicts.
Time spent troubleshooting preventable state conflicts represents a hidden cost rather than productive monitoring. Ignoring the dirty data status forces a choice between corrupted caches and extended downtime, neither of which serves production workloads well.
Preventing Data Loss from Premature Terraform Destroy and Resource Termination
Running `terraform destroy` immediately after a successful migration deletes the new Storage Gateway instance and orphanates attached data volumes. Users should not run terraform destroy after success as it deletes the new gateway. This catastrophic sequence error occurs when operators conflate infrastructure cleanup with legacy decommissioning, effectively reversing the migration outcome. The mechanical failure stems from Terraform's state file tracking the newly provisioned AL2023 resources as the primary managed objects. Destroying these resources triggers the API call to terminate the EC2 instance before the old environment is safely retired.
Operators must execute a strict termination sequence to prevent accidental data loss and optimize costs without compromising the new environment.
- Verify the new gateway is active and serving traffic.
- Manually terminate the legacy AL2 root volume and instance via the console.
- Remove old resource definitions from the codebase before applying further changes.
- Isolate legacy resource management in a separate state file to prevent accidental deletion of production assets.
- Retain the old AL2 instance briefly to allow for forensic analysis if the new gateway exhibits unexpected behavior.
Automating legacy cleanup conflicts with preserving the safety net required for rollback operations. The old AL2 instance incurs hourly costs, yet retaining it briefly allows for forensic analysis if the new gateway exhibits unexpected behavior. Prematurely destroying the new environment eliminates this diagnostic window entirely. Isolating legacy resource management in a separate state file prevents accidental deletion of production assets. This architectural separation ensures that cleanup operations target only the intended obsolete components. The cost of a brief overlap in billing cycles is negligible compared to the operational impact of reconstructing a lost gateway configuration.
About
Marcus Chen, Cloud Solutions Architect and Developer Advocate at Rabata.io, brings critical expertise to the complex challenge of AWS Storage Gateway migrations. Specializing in S3-compatible infrastructure and cloud cost optimization, Chen daily engineers scalable storage architectures for AI/ML enterprises, giving him direct insight into the operational risks of manual upgrades. His work at Rabata.io, a provider of high-performance S3-compatible object storage, involves rigorous benchmarking and migration planning where infrastructure as code is non-negotiable. This article's focus on automating the AL2023 transition via Terraform and Ansible mirrors Chen's production experience, where preserving gateway IDs and cache disks during upgrades prevents costly downtime. As organizations seek to eliminate vendor lock-in while managing hybrid cloud gateways, Chen's analysis bridges the gap between legacy AWS dependencies and modern, automated storage strategies. His background ensures this guide addresses the precise technical hurdles DevOps teams face when upgrading EC2 storage gateways without disrupting active directory configurations or data integrity.
Conclusion
Scaling this migration approach reveals that the 1, 2 hours of downtime per gateway becomes a compounding operational bottleneck when managing fleets rather than single instances. The critical failure point is not the migration duration itself, but the reliance on manual verification of CachePercentDirty metrics before detachment. If this value is not strictly zero, detaching volumes triggers immediate data loss, rendering the S3 upload process incomplete and corrupting the target state. As market penetration grows, the complexity of coordinating these narrow maintenance windows across multiple gateways increases the likelihood of human error during the cutover phase.
Organizations must mandate a pre-migration validation step that automates the polling of dirty cache metrics before any shutdown sequence initiates. Do not proceed with legacy instance termination until the monitoring stack confirms a sustained zero percent dirty cache status for at least fifteen minutes. This specific condition prevents the race condition where data remains in flight during volume detachment.
Start by scripting a pre-check command that queries the gateway metrics API and blocks further Terraform execution if the cache is not fully flushed. This single safeguard ensures that the transition from legacy AL2 instances to the new environment maintains data integrity without requiring extended forensic analysis windows.
Frequently Asked Questions
AWS Storage Gateway holds a a portion [market share](https://www.peerspot.com/products/aws-storage-gateway-reviews) as of May 2026, demanding automation to maintain relevance. Organizations ignoring this shift face operational risks and configuration drift during the critical transition from legacy Amazon Linux environments.
Manual coordination introduces timing errors that corrupt cache states during OS transitions. This human-dependent process creates a high surface area for configuration drift, often forcing costly remediation cycles that significantly delay project timelines and increase overall operational expenses.
Direct migration of settings between differing gateway types remains impossible without a structured replacement procedure. Operators must provision entirely new instances and re-join Active Directory domains to ensure continuity rather than attempting an in-place software update.
Infrastructure as code defines the exact state of new EC2 instances before any physical change occurs. This disciplined approach eliminates manual timing errors during disk swaps, ensuring every migration step executes with identical parameters regardless of scale.
Users must wait for data upload to Amazon S3 if CachePercentDirty is not zero. Proceeding prematurely causes data loss on volume detachment, making it mandatory to verify this metric before initiating any disk swap procedures.
