
Cloud storage pricing: Stop egress fees from inflating bills
Egress fees hit $0.12 per GB, often exceeding base storage costs. Learn how hidden charges distort cloud budgets and where real savings hide.
Egress fees hit $0.12 per GB, often exceeding base storage costs. Learn how hidden charges distort cloud budgets and where real savings hide.
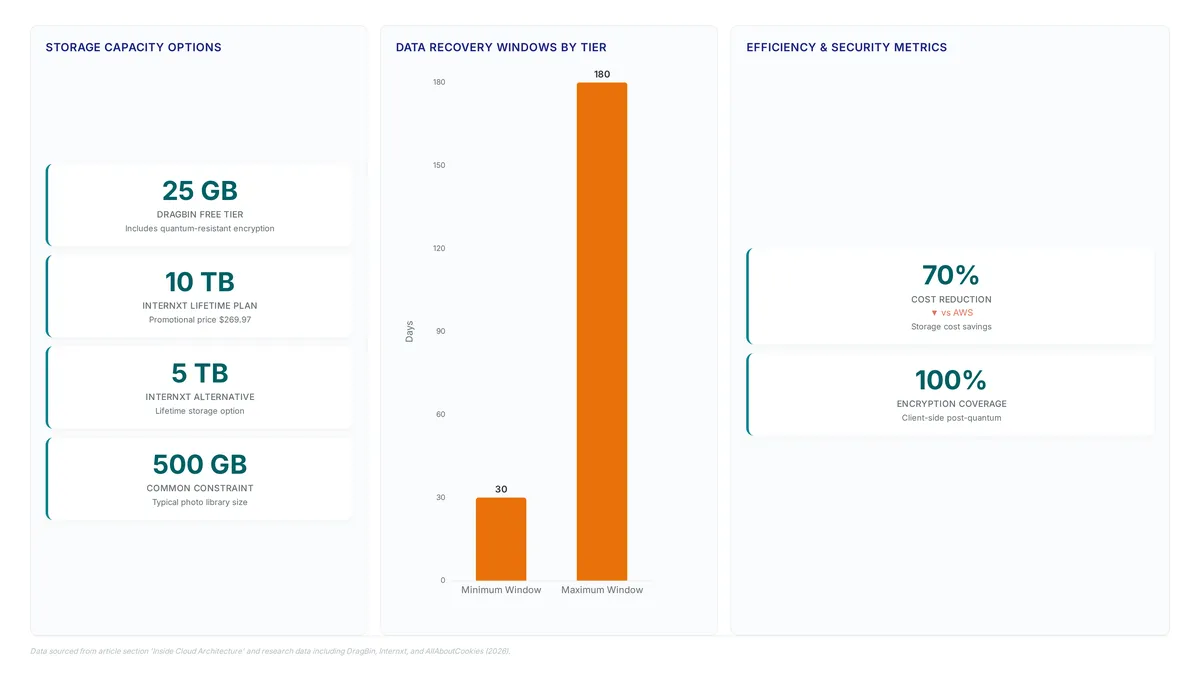
MEGA Cloud hands out 20 GB of free space, the largest entry-level capacity for privacy-focused users.
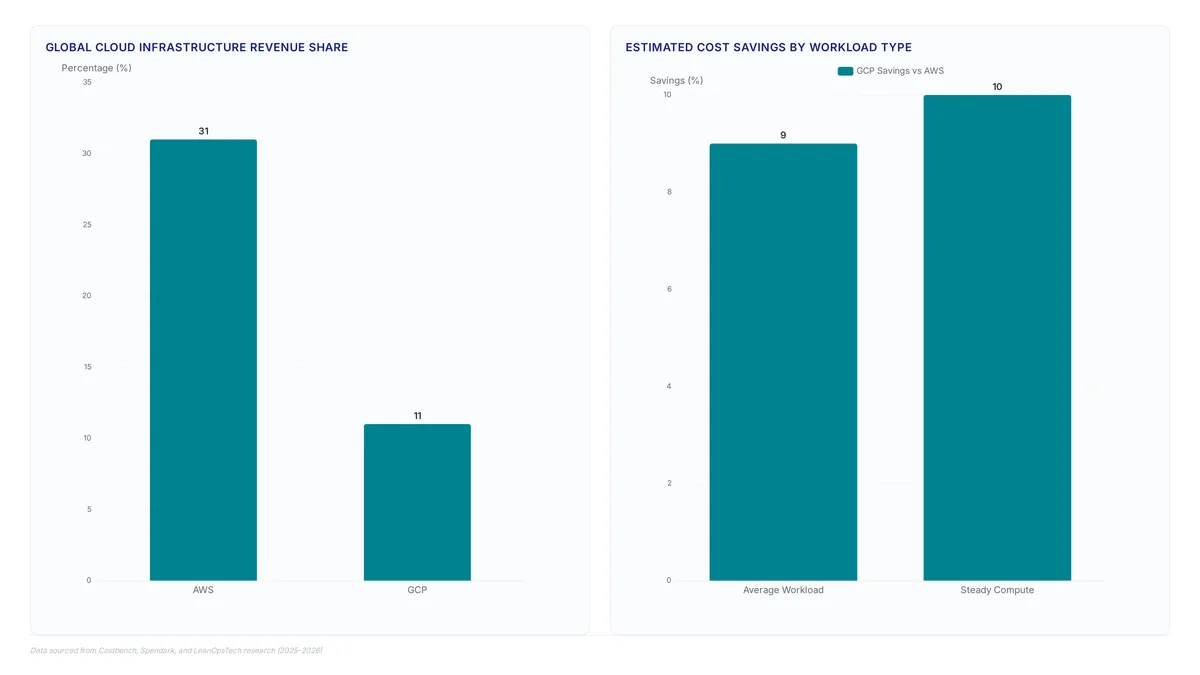
Google Cloud often undercuts AWS by 5-20% on compute, yet AWS dominates with 31% of global revenue.

Stop risking single points of failure. Laravel Backup v2.0 enables parallel uploads to S3 and Google Drive, securing your data across multiple clouds instantly.

Stop paying the lift-and-shift tax. Unified storage lets 70% of enterprises train AI models directly on production data without costly rewrites.

Google's new Rapid Bucket cuts GPU blocked time by 50% with 15 TB/s bandwidth, solving the latency crisis in modern AI training workflows.

Native versioning fails when 65% of breaches stem from misconfiguration. Learn why AI teams need air-gapped architectures for true durability.