Rapid cloud storage fixes AI training bottlenecks
Google's new Rapid Bucket delivers 15 TB/s bandwidth and cuts GPU blocked time by 50%, directly answering the latency crisis in AI training.
Modern AI models hit a wall not because of compute power, but because storage can't feed the GPUs fast enough. NVMe-based DAS sales are surging 32.1% through 2026 per Technavio data, a clear signal that engineers are desperate to escape network bottlenecks. Google's answer isn't just faster hardware; it's a software-defined shift. Cloud Storage Rapid replaces fragile direct-attached setups with a resilient, high-throughput object layer capable of feeding massive clusters without stalling.
This article dissects how Managed Lustre architecture handles flexible data flow alongside Rapid Cache mechanisms that boost ingest speeds by 2.2x. We analyze the measurable ROI from zero-configuration dashboards, which simplify operations as Google Cloud chases market share against AWS and Azure. With checkpoint writes accelerating 3.2x over traditional regional storage, the focus shifts from mere capacity to intelligent, immediate data availability for PyTorch and JAX workloads.
The Role of Cloud Storage Rapid in Modern AI Infrastructure
Stop treating object storage like a tape archive. Cloud Storage Rapid is a zonal object storage variant delivering over 15 TB/s bandwidth via the Colossus distributed file system. It kills the standard HTTP request cycle, replacing it with a stateful gRPC-based streaming protocol that minimizes authentication overhead per operation. The result? Random read and write latency stays under 1ms, supporting 20 million requests per second within a single zone. This isn't theoretical; the system integrates directly with PyTorch and JAX frameworks to eliminate data loading bottlenecks during model training.
The architecture splits into two distinct components to tackle specific throughput constraints. Rapid Bucket provides the core low-latency interface for frequent I/O patterns. Rapid Cache extends this performance to multi-region deployments by ingesting data on write. When data resides closer to compute resources, combining these layers allows the infrastructure to reach up to 20 Tbps of aggregate throughput.
| Component | Primary Function | Max Aggregate Throughput |
|---|---|---|
| Rapid Bucket | Zonal low-latency access | 15 TB/s |
| Rapid Cache | Multi-region read acceleration | 2.5 TB/s |
Smart Storage annotations define dataset semantics at ingestion time rather than during retrieval. This approach removes the need for separate preprocessing pipelines before training jobs begin. Operators pay to annotate data once, and downstream systems consume those tags immediately for the object lifespan.
Here is the hard trade-off: zonal buckets sacrifice resiliency for raw speed. Regional storage offers better pricing but lacks the sub-millisecond response times required for tight GPU coupling. You must choose between absolute performance in a single zone or broader availability across regions. High-concurrency workloads benefit from the 50% reduction in GPU blocked time, yet failure domains remain confined to the selected zone. Isolate training clusters within specific zones to maximize accelerator utilization, but accept the single-zone failure risk.
Smart Storage Annotations for Automated ML Dataset Selection
Smart Storage annotations embed semantic metadata at ingestion, enabling dataset selection without custom retrieval code. Teams pay to annotate data once at write time, allowing every downstream system to access tags immediately for the object's entire lifecycle. This mechanism eliminates the latency of post-ingest processing pipelines common in traditional workflows.
Deploy Rapid Bucket over regional storage when training jobs require sub-millisecond random access that regional tiers cannot sustain. The optimized data path front-loads authorization checks during stream creation, stripping overhead from subsequent reads.
Inside Google Cloud Managed Lustre Architecture and Data Flow
Managed Lustre Throughput via C4NX VMs and Hyperdisk Exapools
Google Cloud Managed Lustre achieves 10 TBps throughput by pairing C4NX virtual machines with Hyperdisk Exapools to create a unified parallel filesystem. This architecture integrates DDN's Lustre and EXAScaler software stacks directly onto the new VM instances, bypassing traditional network storage gateways. The C4NX platform provides the necessary compute density to saturate the underlying block storage, while Hyperdisk Exapools aggregate capacity across multiple physical disks to eliminate individual spindle bottlenecks.
Operators gain a 10x increase in single-instance performance compared to previous generations, but this design introduces a strict dependency on zonal availability. The system writes and restores checkpoints 2.6x faster than standard offerings, yet the reliance on Hyperdisk Exapools means failure domains align with the zone rather than spanning regions. This limitation favors raw training speed over geographic redundancy, requiring architects to implement application-level replication for disaster recovery. The throughput specification targets AI workloads needing sustained data ingestion without the latency variability of object-based caching. Deploy this tier only when training jobs demand consistent sub-millisecond metadata operations that regional storage cannot guarantee.
Accelerating Checkpoint Restores with Ingest-on-Write Mechanics
Ingest-on-write mechanics enable 2.2x faster restores by pushing data to the cache simultaneously with bucket uploads. This flow eliminates the cold-start penalty where GPUs sit idle waiting for the first read to populate local storage. Operators configure Rapid Cache to ingest data on write, ensuring workloads benefit from an immediate cache hit on the very first access attempt.
The mechanism relies on front-loading authentication and metadata checks during stream creation rather than per-operation. This optimized data path strips overhead from subsequent reads, allowing direct access to the Colossus backend without repeated authorization delays. Traditional caching waits for a read miss before fetching objects, introducing latency spikes that stall training loops.
Avoiding data transfer fees associated with multi-region buckets becomes possible once data resides in the zonal cache, providing a mechanism to mitigate egress costs. The constraint is strict zonal affinity; data ingested into one zone does not automatically replicate to others, requiring explicit deployment strategies for multi-zone training jobs.
Enable this feature for checkpoint-heavy workflows where restore speed dictates iteration velocity. The reduction in GPU blocked time directly correlates to higher accelerator utilization across the cluster. Failure to align cache placement with compute zones reintroduces the network jitter this architecture aims to eliminate.
Lustre Flexible Tier Pricing Versus Standard Object Storage Costs
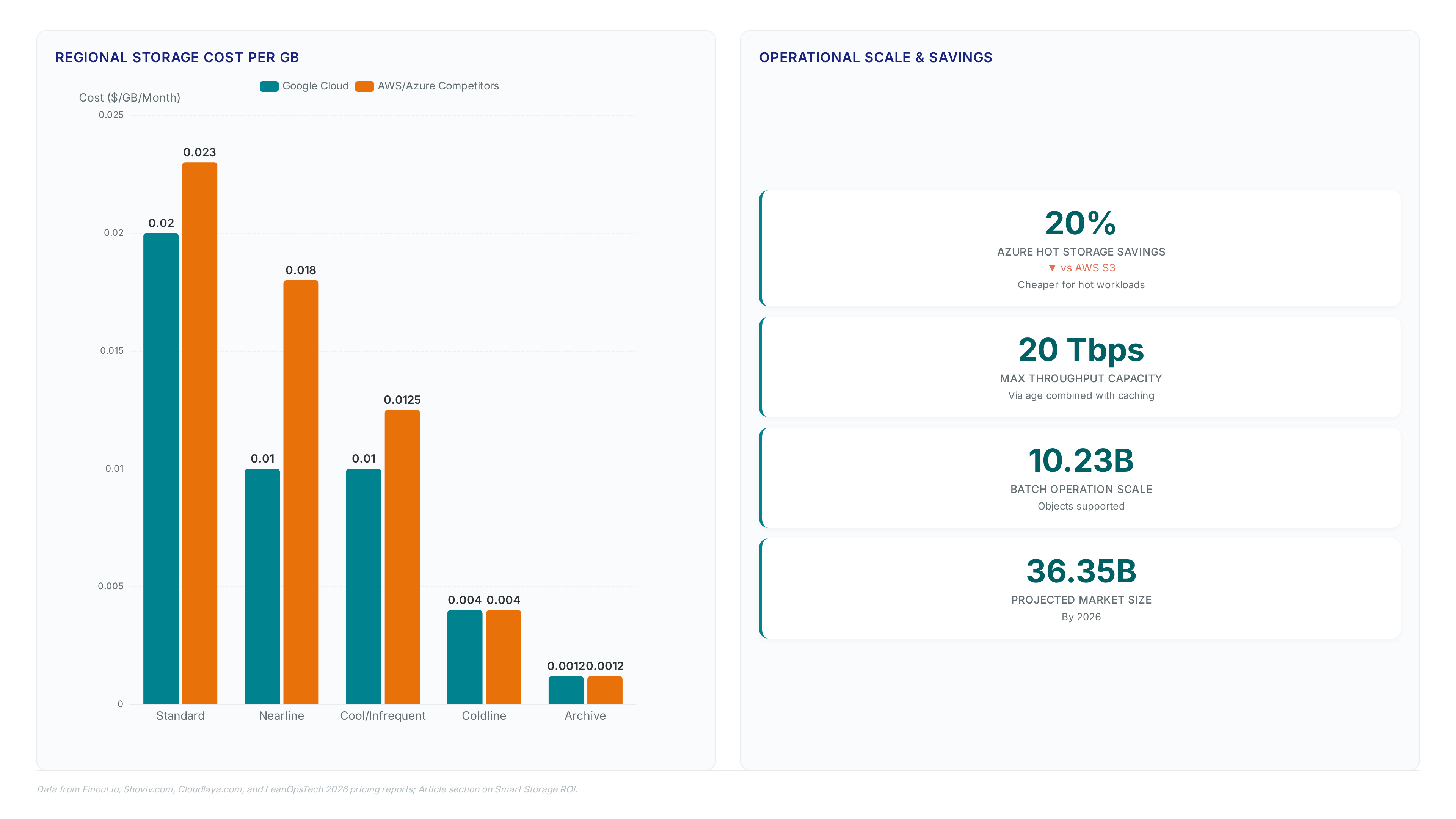
The new Flexible Tier costs $0.06/GB-month, creating a 3x premium over the $0.020/GB baseline for standard regional storage. This price gap reflects the underlying hardware shift from object-based caching to persistent disk serving, which eliminates performance cliffs during high-concurrency AI training loops. Operators pay for guaranteed low-latency access rather than best-effort retrieval, a distinction that matters when GPU idle time exceeds storage savings. The $0.023/GB rate charged by competing hyperscalers for similar standard tiers makes the Google premium relatively smaller in a multi-cloud context, yet the absolute cost remains significant for petabyte-scale datasets. A hidden drawback exists: the single SKU billing simplifies finance operations but removes the ability to manually tier cold data out of the expensive performance lane.
Calculate the break-even point where accelerated iteration cycles offset the tripled storage unit cost. Deploying Google Cloud Managed Lustre for inactive data wastes budget, just as using standard tiers for active training starves accelerators. The decision hinges on whether the workload demands the 4–20x throughput advantage or merely durable capacity.
Measurable ROI from Smart Storage and Zero-Configuration Dashboards
Zero-Configuration Dashboards and DSPM Integration Mechanics
Zero-configuration dashboards ingest bucket activity tables from Insights Datasets to surface cost anomalies without manual SQL queries. This architecture automatically pulls object events and correlates them with Security Command Center Data Security Posture Management signals, flagging public ACLs or unencrypted buckets instantly. Operators avoid building custom monitoring pipelines because the system maps storage class transitions directly to billing line items upon ingestion. The integration addresses a specific gap where high-performance AI workloads often bypass traditional security gates due to speed requirements.
Executing Multi-Bucket Batch Operations for Billions of Objects
Enhanced batch operations simplify acting on billions of objects with new change ACL and storage class capabilities across multiple buckets simultaneously. Operators execute these modifications by targeting specific object contexts set during the August 2026 update, avoiding manual iteration through individual bucket policies. The Cloud Storage MCP server enables this scale by allowing agents to read, write, and analyze data using the standard MCP protocol without custom scripting layers. Operational speed clashes with egress economics when modifying storage classes across regions. Using Rapid Cache helps avoid data transfer fees associated with multi-region buckets on reads once data is ingested, providing a mechanism to mitigate higher costs during bulk transitions.
Smart Storage Semantic Criteria Versus Custom Retrieval Pipelines
Smart Storage eliminates custom retrieval pipelines by applying automated annotations during content ingestion. ML teams select training datasets using semantic criteria rather than engineering complex indexing layers. This approach shifts the cost model to a one-time annotation fee at write time, allowing downstream systems to query metadata immediately without reprocessing. Traditional pipelines require separate compute clusters to tag data, introducing latency before model training can begin.
The performance gap widens when considering GPU utilization efficiency. Operators building custom pipelines often overlook the overhead of repeated metadata access, which stalls inference workloads during peak concurrency. Managed Lustre remains preferable for inference workloads requiring shared KV-cache states, yet Smart Storage dominates dataset selection phases. Query flexibility presents a constraint. Semantic criteria rely on predefined tags, whereas custom scripts allow arbitrary regex matching across unstructured blobs. Teams must weigh the speed of automated tagging against the need for ad-hoc data exploration. AI-driven RAG applications increasingly prioritize latency over raw capacity, making pre-annotated objects necessary for real-time retrieval. Enable automated annotations for static training corpora while retaining custom pipelines for experimental data lakes requiring frequent schema changes.
Managed Lustre Versus Competitor Hyperscaler Offerings
Google Cloud Managed Lustre Architecture on DDN and EXAScaler
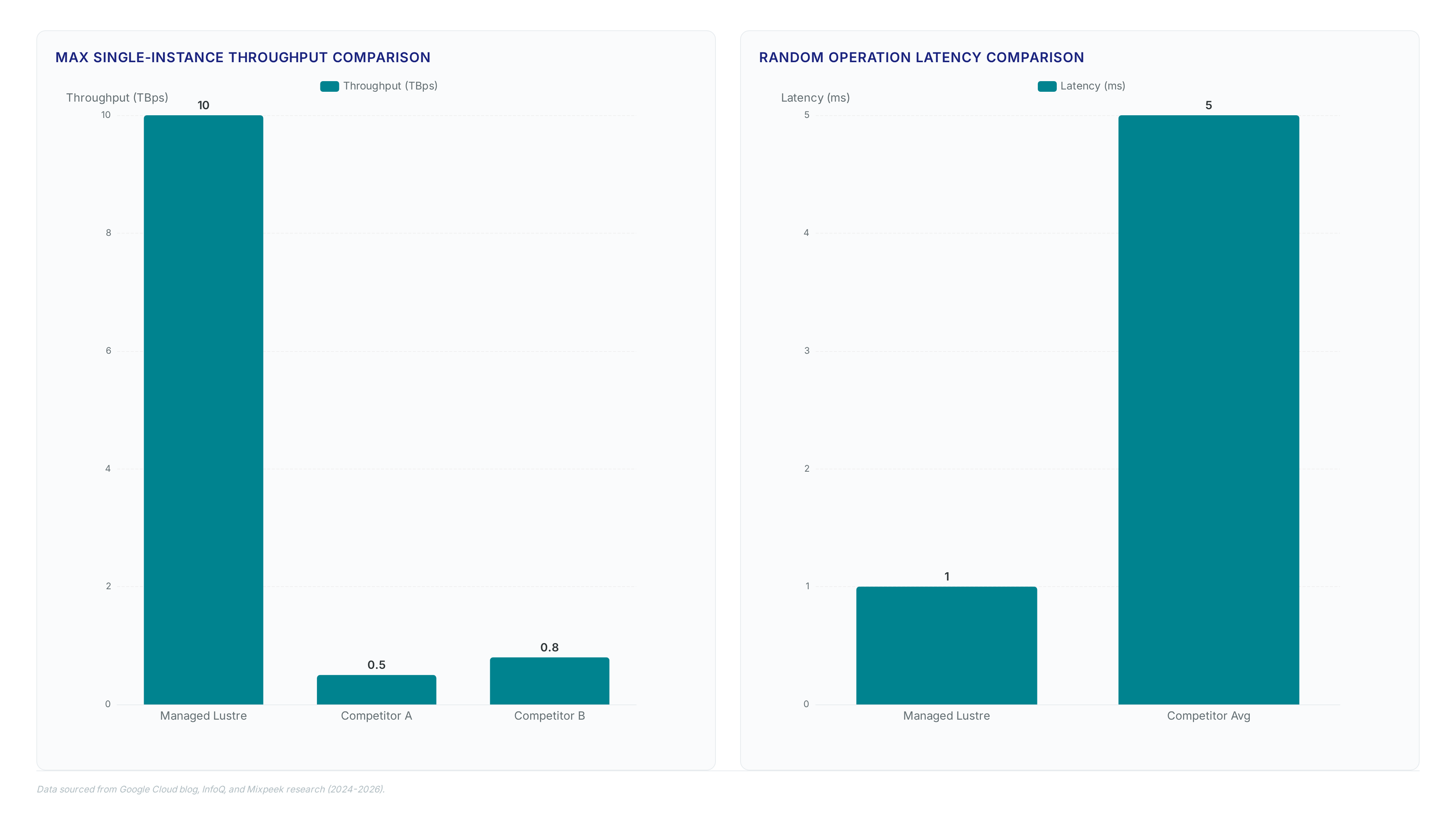
Google Cloud Managed Lustre combines DDN's Lustre and EXAScaler software with C4NX VMs to deliver parallel filesystem performance distinct from object storage. The architecture relies on Hyperdisk Exapools. This foundation supports sub-millisecond latency for random reads and writes, a specification five times lower than competing cloud providers. Operators gain 10 TBps of throughput without managing underlying metadata servers or scaling logic manually.
| Dimension | Managed Lustre | Competitor File Services | Standard Object Storage |
|---|---|---|---|
| Throughput | 10 TBps | 0.5–2.5 TBps | 15 TB/s (zonal only) |
| Latency | <1 ms random | 2–5 ms random | 10–50 ms random |
| Protocol | POSIX | NFSv3/SMB | HTTP/S3 API |
| Checkpoint Restore | 2.6x faster | Baseline | 5x slower than Rapid |
The Flexible Tier eliminates performance cliffs by serving data directly from persistent disk rather than relying on object-based caching mechanisms. A tangible operational constraint emerges when mapping this architecture to cost-sensitive inference workloads; the premium for guaranteed low-latency access exceeds standard regional storage pricing by a factor of three. Teams must weigh the 75 percent inference throughput gain against the increased unit cost per gigabyte. Missing this calculation leads to over-provisioning high-performance tiers for workloads that tolerate higher latency. Reserve this tier strictly for active training loops where GPU idle time costs exceed storage premiums.
Throughput Performance Gap: 4–20x Advantage Over AWS and Azure
Google Cloud Managed Lustre delivers up to 10 TBps of single-instance throughput, exceeding competitor managed offerings by a factor of 4–20x. This performance differential stems from the underlying C4NX VMs paired with Hyperdisk Exapools, which provide the highest aggregate block storage capacity per AI cluster among hyperscalers. In contrast, AWS S3 relies on massive concurrency rather than single-stream speed, while Azure Blob targets line-rate performance only on well-designed applications. The latency specification confirms sub-millisecond random reads, a fivefold improvement over rival platforms that struggle with metadata bottlenecks at scale.
| Dimension | Google Cloud Managed Lustre | AWS Managed Lustre | Azure HPC Cache |
|---|---|---|---|
| Max Single-Instance Throughput | 10 TBps | ~a moderate throughput | ~a higher moderate throughput |
| Checkpoint Restore Speed | 2.6x faster | Baseline | Baseline |
| Architecture Basis | EXAScaler on DDN | Open-source Lustre | Proprietary Cache |
Operators must weigh this raw throughput against cost complexity, as the Flexible Tier eliminates performance cliffs but introduces a distinct pricing model compared to standard object storage. The throughput performance of Rapid Bucket complements this by offering 15 TB/s aggregate bandwidth, yet Managed Lustre remains superior for strict POSIX requirements in AI training loops. A hidden constraint emerges when scaling beyond a single instance; network fabric limits may cap total cluster bandwidth before storage limits are reached. Validate fabric headroom before committing to multi-node deployments to avoid artificial throttling. This architecture supports the majority of enterprises expanding capacity for AI workloads while avoiding the complexity of manual tiering policies.
Deploy this tier specifically for active checkpointing intervals where sub-millisecond latency prevents GPU starvation. The strategic consequence involves shifting budget from compute idle time to higher storage unit costs, optimizing total training duration rather than infrastructure spend alone.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep practical expertise to the evolving environment of cloud storage performance. His daily work designing Kubernetes storage architectures and optimizing disaster recovery strategies for AI-driven applications directly mirrors the industry shift toward quicker, smarter data delivery highlighted in Google's recent announcements. At Rabata. Io, a specialized S3-compatible object storage provider, Kumar engineers solutions that prioritize the exact high-performance throughput and cost efficiency required by modern AI/ML startups. His background as a former SRE managing high-traffic platforms ensures a grounded perspective on how infrastructure upgrades impact real-world data management and batch operations. By connecting theoretical advancements in metadata automation and agent connectivity to tangible deployment scenarios, Kumar bridges the gap between vendor innovations and the practical needs of enterprises seeking scalable, vendor-lock-in-free storage alternatives in a competitive global market.
Conclusion
Scaling AI storage reveals a critical fracture point where network fabric saturation caps cluster bandwidth long before storage throughput limits are reached. As NVMe-based Direct-Attached Storage sales surge by 32.1% through 2026 to meet AI optimization demands, the industry shifts toward minimizing data travel distance rather than maximizing remote bucket speed. The 3x premium on flexible tiers becomes unsustainable for long-term retention, forcing an architectural pivot where hot data resides locally while cold assets sink to object stores. Treat high-throughput cloud filesystems as ephemeral accelerators, not permanent data lakes, to prevent operational costs from eroding model economics.
Adopt a hybrid topology by Q4 2027 that pairs local NVMe bursts with cloud tiers only for active checkpointing windows. Do not commit to fully managed Lustre deployments unless your training loops strictly require POSIX semantics for the vast majority of the dataset; otherwise, the latency gains do not justify the unit cost. Start by auditing your current GPU idle time logs this week to quantify exactly how many hours are lost to I/O wait states. Use this baseline to calculate the maximum justifiable storage premium before approving any Flexible Tier migration. This data-driven approach ensures you pay for performance only when it directly reduces total training duration, avoiding the trap of over-provisioning bandwidth for workloads that cannot saturate.
Frequently Asked Questions
The new Dynamic Tier costs $0.06 per GB monthly for low-latency performance. This single SKU eliminates hidden complexity by serving data directly from persistent disk rather than relying on object-based caching mechanisms.
Rapid Bucket delivers more than 15 TB of bandwidth within a single zonal bucket. This extreme throughput supports 20 million requests per second with sub-millisecond latency for frequent I/O patterns.
Rapid Bucket reduces GPU blocked time by 50% compared to standard regional storage options. This significant improvement increases accelerator utilization for multi-modal training while enabling 2.5x faster data loading speeds.
Rapid Cache accelerates bandwidth with an aggregate read throughput of 2.5 TB per second for existing buckets. This feature requires no code changes and supports ingest-on-write for immediate cache hits.
Managed Lustre delivers up to 10 TB of throughput, which is 4–20x higher than competitor offerings. This performance stems from new C4NX VMs and Hyperdisk Exapools architecture designed for massive scale.
