Unified storage cuts AI data costs by 70% fast
With 70% of enterprises expanding storage for AI in 2024, the unified storage pool is no longer optional infrastructure.
NetApp and Google Cloud have removed the architectural friction that previously forced enterprises into costly rewrites to use existing data for generative AI. Converging file and block protocols into a single service layer bypasses the "lift-and-shift" tax that drains budgets and delays model training. This collaboration attacks the bottleneck where data movement becomes prohibitively complex and slow.
The new Flex Unified Service Level creates a singular architecture capable of handling high-performance computing and VMware workloads across all Google regions simultaneously. NetApp Data Migrator, now generally available, automates multi-cloud transfers without requiring specialized engineering teams. Contrasting Google Cloud NetApp Volumes against native object storage reveals why protocol flexibility remains critical for database integrity and low-latency AI inference. As global data approaches 200 zettabytes by 2027, the ability to access fluid, non-siloed data determines whether an enterprise leads the AI curve or drowns in migration debt.
The Role of Unified File and Block Storage in AI-Ready Cloud Infrastructure
Google Cloud NetApp Volumes as Unified File and Block Storage
Announced April 22, 2026, Google Cloud NetApp Volumes delivers unified file and block storage via the Flex Unified service level. This architecture supports Linux NFS and Windows SMB protocols concurrently on the same volume while adding iSCSI and NVMe/TCP for block workloads through a single storage pool. Data remains accessible to AI services without migration or duplication across siloed environments, sparing enterprises from rearchitecting applications.
AI-ready data demands fluidity, not static repositories. Global storage volumes approaching 200 zettabytes by 2027 create pressure for architectures that eliminate copy operations. Over 70% of enterprises expanding capacity in 2024 seek exactly this type of unified access to train models directly on production datasets. Operators gain the ability to run high-performance computing and electronic design automation workloads alongside database instances without protocol translation layers.
Configuration demands attention. The Flex Unified service level requires explicit setup to enable both iSCSI and NFS on the same endpoint, which some legacy monitoring tools may not recognize as a single logical unit. This duality introduces complexity in capacity planning where file growth rates differ notably from block allocation patterns. Misconfiguration costs measurable wasted provisioned space or performance degradation during peak AI training cycles.
Validate protocol concurrency in non-production environments before migrating critical AI pipelines. Eliminating data movement reduces latency but increases dependency on the underlying network fabric between compute and storage tiers.
Flex Unified delivers 22 GiBps throughput and 750,000 Max IOPS for direct AI training access without migration. This performance tier enables organizations to run databases and high-performance computing workloads on a single storage pool. Operators deploy this architecture to eliminate data silos that typically force costly rearchitecting before analytics ingestion. The General Availability date of April 22, 2026, marks the point when block storage became natively unified with file services across all Google Cloud regions.
Adoption occurs when latency sensitivity prohibits data duplication between separate file and block systems. Healius utilized similar modernization patterns to save up to $10 million in cloud costs by avoiding redundant data movement. AGL Energy achieved AU$2 million in infrastructure savings through consolidated storage management in 2024. Legacy applications requiring exclusive protocol locks may need configuration adjustments to share the unified volume. Direct analytics access removes the delay of ETL pipelines but increases the blast radius of a single storage pool failure. Network teams must implement stricter isolation policies since file and block traffic now contend for the same backend resources. This constraint favors speed over compartmentalization for time-sensitive AI model training.
Unified Architecture Versus Traditional Siloed Data Approaches
Unified storage architecture consolidates file and block protocols into a single pool, eliminating the data movement friction inherent in siloed designs. Moving and managing data across multiple environments in traditional setups is complex, slow, and expensive, often stalling AI initiatives before they begin. Conventional approaches force operators to duplicate datasets for analytics, introducing latency and cost that unified models remove by allowing direct access.
| Feature | Siloed Architecture | Unified Architecture |
|---|---|---|
| Protocol Support | Separate pools for file or block | Concurrent NFS, SMB, iSCSI on one pool |
| Data Mobility | Requires migration for AI access | Direct analysis without duplication |
| Operational Overhead | High management complexity | Simplified single-console control |
| Deployment Speed | Days to rearchitect applications | Immediate workload onboarding |
NetApp has won the Google Cloud Partner of the Year award for storage seven times, validating the operational efficiency of this consolidated approach. Customers can operate enterprise applications and AI workloads without the need to rearchitect or rebuild existing environments, preserving capital while accelerating time-to-value. Legacy applications hard-coded to specific block devices may require minor configuration updates to use the shared storage pool. This architectural shift reduces total cost of ownership by removing the egress fees and engineering hours associated with data shuffling between disparate systems. Evaluate current data gravity to determine if silo removal yields immediate returns.
Inside NetApp Data Migrator and Flex Unified Service Architecture
NetApp Data Migrator and XCP Tool Mechanics
NetApp Data Migrator reached General Availability as a simple, multi-cloud service using the NetApp XCP Migration Tool for environment transfers. This architecture bypasses the need for specialized expertise by automating complex data movement tasks that typically stall AI initiatives. Operators initiate transfers through a simplified interface where the underlying engine handles protocol translation and error recovery automatically. The system integrates deeply with Google Cloud services to ensure migrated datasets remain immediately accessible to analytics engines without secondary copying.
Data efficiency drives the operational model during these transfers.
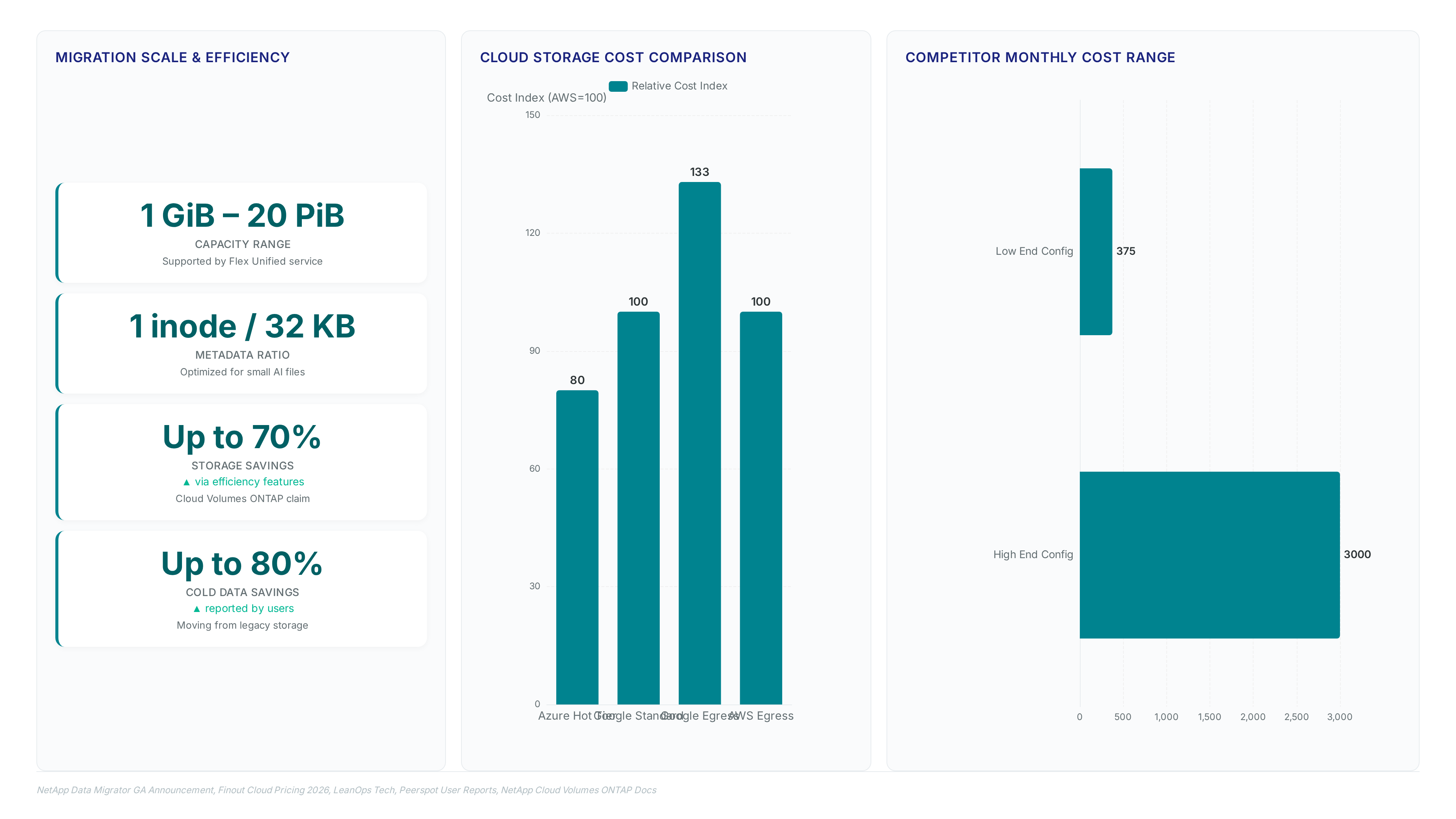
Electronic Design Automation workflows consume capacity ranging from 1 GiB to 20 PiB without requiring volume recreation across distinct silos. Architects map database transaction logs to block LUNs while directing simulation output to file shares within the same storage pool. This configuration eliminates the data movement friction inherent in legacy designs where analytics engines stall waiting for ETL jobs. Throughput scales to meet massive dataset demands, though Premium and Extreme tiers deliver up to 30 GiB/s specifically for large-capacity volumes rather than the base Flex tier.
Raw performance clashes with cost predictability when provisioning these resources. Committed use discounts require a minimum spending rate of $11.38/hour to enable heavily discounted capacity prices, creating a high floor for entry. Smaller EDA teams might find this threshold prohibitive compared to pay-as-you-go models, forcing a choice between performance guarantees and budget flexibility. The architecture supports concurrent NVMe/TCP and NFS protocols, yet mixing latency-sensitive database traffic with bursty simulation jobs on one pool risks noisy neighbor effects.
| Workload Type | Protocol Requirement | Risk Factor |
|---|---|---|
| Oracle DB | iSCSI Block | Latency spikes from file I/O |
| SPICE Simulation | NFS File | Throughput starvation from DB |
| Hybrid AI Training | Both | Complex QoS tuning |
Isolate critical transactional systems onto dedicated volumes despite the unified capability. Direct access removes migration delays, but operational isolation remains necessary for strict Service Level Agreements. The single pool simplifies management, yet it does not automatically resolve resource contention without manual quality of service policies. Validating migration success requires a strict checklist comparing pre-migration baselines against post-migration storage consumption metrics.
- Measure total capacity consumed before and after enabling compression features.
- Confirm that cold data tiering to object storage yields the expected 80% cost drop for archival workloads textile company
- Audit network egress charges to ensure no hidden fees offset the storage gains.
Some teams report the process feels like magic due to automation, yet manual validation remains necessary to catch configuration drift. The NetApp XCP Migration Tool automates the move, but it does not automatically enforce post-move policy compliance. Operators who skip the final audit frequently discover that legacy data patterns persist, negating the financial benefits of the new unified pool.
Comparing NetApp Volumes Against Native Google Cloud Storage Options
Defining Native Google Cloud Storage Pricing and Performance Tiers
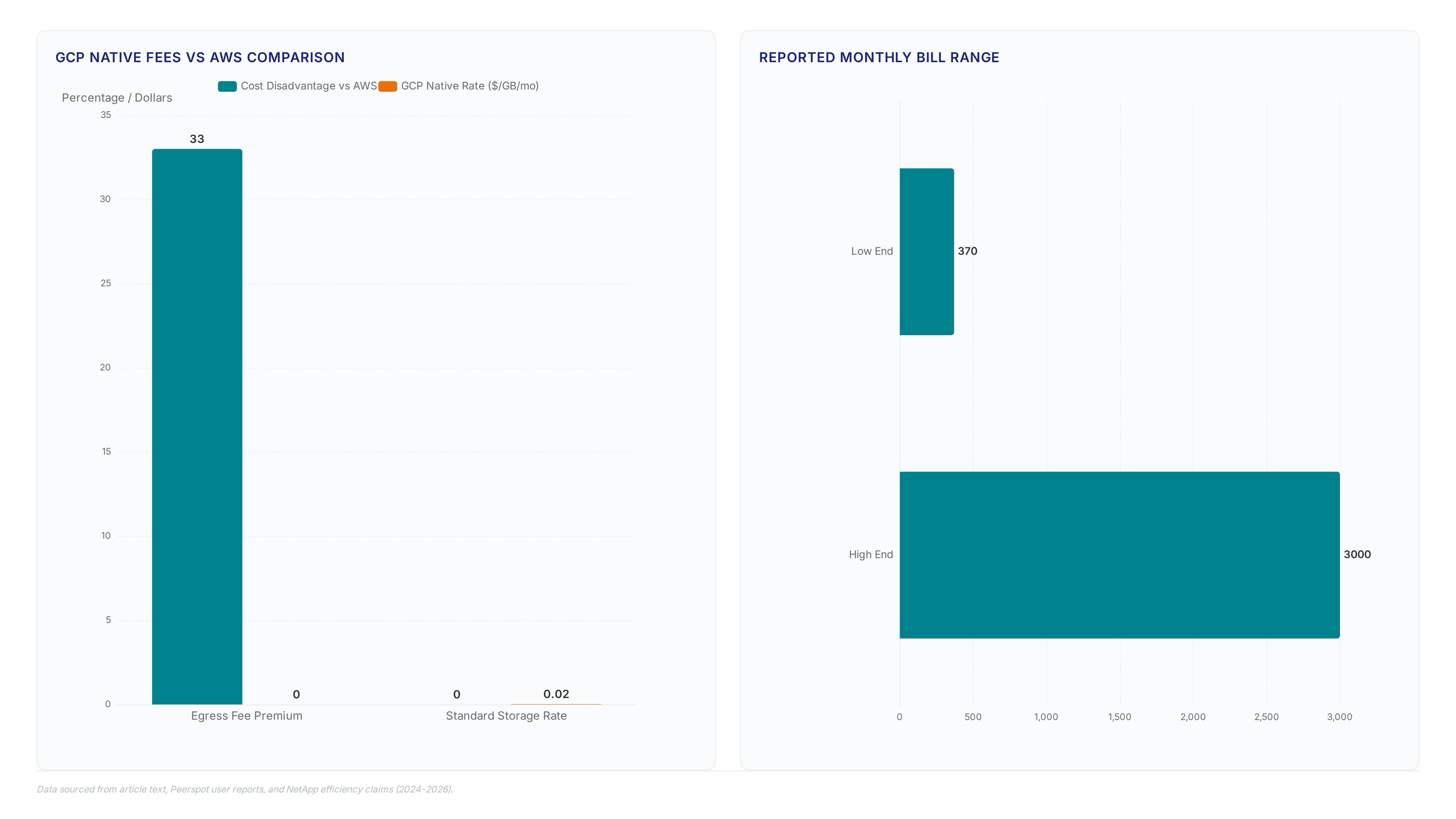
Native Google Cloud Storage charges $0.020/GB/month for standard classes while imposing $0.12/GB egress fees that scale linearly with data retrieval volume. Retrieval expenses often exceed storage retention costs in high-throughput AI training loops under this model. Operators analyzing total cost of ownership must note that these egress fees are 33% higher than comparable AWS costs. Such a disparity potentially negates initial storage price advantages during heavy model iteration. Architecture teams face pressure to predict workload spikes accurately before provisioning because performance characteristics vary notably across service tiers. Competing cloud file storage services report monthly bills ranging from $370 to over $3,000 depending on configuration scale and IOPS requirements. Native tiers lack unified file and block support. This gap often necessitates maintaining separate storage pools and increases management overhead. Audit projected data movement patterns before committing to native object storage for active training datasets. Replacing fragmented native storage pools with a unified architecture eliminates redundant data copies during AI model training. Byron Baynham, leading the Cloud and Infrastructure Platform at AGL, validated that consolidating file and block workloads reduced operational overhead notably compared to managing discrete native services.
| Dimension | Native Google Cloud Storage | NetApp Volumes Flex Unified |
|---|---|---|
| Migration Complexity | Requires application refactoring for block access | Supports direct lift-and-shift for existing apps |
| Data Silos | Separate buckets for file and block objects | Single pool for mixed workload types |
| Operational Overhead | High manual configuration for consistency | Automated policy enforcement across protocols |
Teams evaluating whether to use NetApp for cloud data migration must weigh initial service cost against the total expense of application modification. Native options often appear cheaper per gigabyte until engineers account for the development hours needed to rewrite database connectors. Low unit pricing conflicts with high implementation friction. Teams frequently underestimate the labor required to adapt legacy software to cloud-native APIs. This miscalculation erodes projected savings. Audit current application dependencies before selecting a storage tier to avoid costly mid-migration pivots. Direct analytics access without data movement remains the primary driver for these enterprise decisions. A textile company validated this efficiency by moving archival workloads off all-flash arrays to achieve maximum savings. Operators must audit access heatmaps before committing to FabricPool policies. Skipping this step risks performance penalties on frequently retrieved blocks. Model retrieval frequency against egress charges to determine the optimal split between tiered and standard classes.
Executing Enterprise Data Migration and AI Service Integration
NetApp Data Migrator General Availability and Multi-Cloud Scope
NetApp Data Migrator reached General Availability on April 22, 2026, enabling direct enterprise data transfer to Google Cloud without specialized scripting. This service deploys the NetApp XCP Migration Tool to handle high-throughput file moves that standard utilities often stall on during large-scale relocations. Operators initiate the process by configuring source and target endpoints, then executing a parallelized copy job that preserves metadata integrity across hybrid environments.
- Define the source NAS path and the destination Google Cloud NetApp Volumes mount point.
- Enable data deduplication flags within the transfer profile to reduce target capacity consumption.
- Execute the migration job and monitor throughput via the centralized dashboard.
Provisioning the Flex Unified service level requires selecting a single pool that supports concurrent NFS protocols for mixed database and EDA traffic. Operators define capacity between 1 GiB and 20 PiB to accommodate massive design datasets without architectural changes.
- Create a storage pool specifying the Flex Unified service level to enable unified access.
- Configure volume exports for Linux clients using NFS while enabling block LUNs for Windows hosts.
- Apply Customer-Managed Encryption Keys to satisfy security compliance for sensitive intellectual property.
- Mount the volume on compute instances to begin direct analytics processing immediately.
The architecture allocates one inode for every 32 KB of capacity, optimizing metadata handling for small AI training files.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing scalable, S3-compatible storage solutions directly informs his perspective on the evolving environment of unified storage pools. As enterprises increasingly struggle with data fragmentation across hybrid environments, Kumar's expertise in eliminating vendor lock-in and optimizing infrastructure costs provides critical insight into why unified approaches are necessary. At Rabata. Io, a provider focused on democratizing enterprise-grade object storage for AI and ML workloads, he routinely addresses the challenges of moving data efficiently without rearchitecting existing systems. This practical experience allows him to evaluate new collaborations, such as NetApp's integration with Google Cloud, through the lens of real-world performance and financial efficiency. His background ensures a factual analysis of how unified storage strategies can simplify complex data management for modern enterprises.
Conclusion
Scaling unified storage pools reveals a critical friction point: aggressive deduplication directly competes with the low-latency requirements of generative AI training. While archival tiers deliver predictable savings, real-time model ingestion suffers when background compression throttles controller CPU, creating hidden performance debt that erodes initial cost gains. The economic model shifts dangerously once compute clusters starve for IOPS while waiting for metadata resolution, turning a theoretical 38% saving into an operational bottleneck. Organizations must treat storage efficiency as a variable constraint, not a static setting, especially as 2024 capacity expansions target massive unstructured datasets.
Deploy unified pooling immediately for cold data migration, but defer inline deduplication on active AI training volumes until Q4 2027, when next-generation controller architectures improved isolate metadata overhead from data planes. Do not apply a single efficiency policy across mixed workloads; segment hot and cold tiers strictly to preserve throughput guarantees. This staggered approach prevents paying full price for redundant blocks without sacrificing model iteration speed.
Start by auditing your current IOPS latency during peak ingestion windows this week before enabling any new compression features. Measure the delta between logical allocation and physical write speeds to establish a baseline performance threshold. Only after quantifying this overhead should you adjust service levels, ensuring your modernization effort reduces spend without stalling innovation.
Frequently Asked Questions
Companies like Healius saved up to $10 million by eliminating redundant data transfers. AGL Energy also achieved AU$2 million in infrastructure savings through consolidated storage management in 2024.
Over 70% of enterprises expanding capacity in 2024 seek unified access to train models directly on production datasets. This trend drives the urgent need for fluid, non-siloed data architectures.
Customers can run enterprise applications and databases without rearchitecting or rebuilding their existing environments. This approach removes major sources of cost, delay, and complexity often found in AI adoption.
The NetApp Data Migrator moves data across environments without requiring specialized expertise or engineering teams. This simplifies the process for organizations tapping into AI benefits using Google Cloud services.
AGL Energy achieved AU$2 million in infrastructure savings through consolidated storage management in 2024. This validates the economic impact of efficient storage patterns that eliminate copy operations.
