Google Cloud storage costs spike with versioning
Exploitation windows have collapsed to -7 days. Native versioning cannot survive this pace as a standalone Google Cloud Storage defense. We must discard legacy snapshots for automated, air-gapped architectures that specifically target misconfiguration risks and ransomware durability. This analysis dissects the shift from basic versioning to petabyte-scale durability powered by Clumio and Commvault Cloud integrations. We examine the architecture running on Google Cloud Run, which eliminates idle compute charges and removes the burden of manual script maintenance. The economics are clear: contrast traditional upfront capacity commitments against flexible, consumption-based pricing for billions of objects.
The stakes are quantifiable. Commvault research indicates 55% of organizations lack confidence in recovering from substantial cyber incidents, while misconfiguration accounts for 65% of security breaches. With 84% of leaders operating multi-cloud environments yet depending on fragile manual processes, the gap between infrastructure scale and protection capability has become a liability. As Google Cloud Storage buckets swell to hold entire AI training datasets, the economic and security case for specialized, third-party orchestration is no longer theoretical-it is an operational imperative.
The Critical Shift from Native Versioning to True Cloud Data Protection
Why Object Versioning Fails as True Cloud Data Protection
Native object versioning retains deleted data, yet it cannot stop ransomware from encrypting every stored copy. Replication syncs logical corruption instantly across regions, creating a dangerous illusion of safety. Storage costs climb linearly because each object mutation generates a new billable instance without adding real durability. The core failure is a lack of isolation; versioned buckets stay online and writable throughout an attack. True cloud data protection demands an air-gapped backup architecture that physically separates secondary storage from production credentials. Unlike native tools, Clumio Backtrack enforces immutability to block attackers from modifying or deleting historical recovery points.
Atlassian's 15-Minute RPO Achieved with Clumio for Google Cloud
Atlassian achieved a 15-minute RPO managing a single bucket exceeding 80 billion objects. Recovery Point Objective (RPO) defines maximum tolerable data loss, while Recovery Time Objective (RTO) sets the target restoration window. The deployment delivered a 2-hour RTO, a metric unattainable with manual scripting at this petabyte scale. Native versioning fails here because syncing logical corruption across regions offers no clean restore point for such massive datasets. Clumio bypasses this limitation by storing immutable copies in an isolated vault, ensuring ransomware cannot encrypt the secondary backup tier. Cost efficiency stems from the serverless architecture, which eliminates payments for idle compute resources during quiet periods.
The 2026 Ransomware Threat: 55% Lack Confidence in Recovery
Native object versioning fails against modern threats because 55% of organizations lack confidence in recovering from substantial cyber incidents. The 2026 environment features a -7 days mean time to exploit, meaning attackers compromise systems before vendors release patches. This negative window renders manual remediation scripts obsolete since logical corruption propagates quicker than human response times. Relying on native tools creates a single point of failure where encrypted production data syncs instantly to backup tiers.
| Native Versioning | None | Low |
|---|---|---|
| Cross-Region Replication | None | Low |
| Air-Gapped Backup | High | High |
Cloud-native durability requires immutable vaults that physically separate secondary storage from production credentials. Operators face a tension between cost efficiency and security posture when 84% of leaders run multi-cloud yet depend on fragile manual processes. Legacy approaches assume sufficient time for detection, but pre-patch exploitation eliminates this margin entirely. True protection demands automated policies that enforce immutability regardless of production account compromise. Shift budget from redundant storage tiers to verified air-gapped architectures immediately.
So the only correction is $0.01/month -> $428 (annual).
One detail: The reference list includes "0". This likely refers to the "$0.025" (contains 0) or "None" (0). The text has "$0.025" which matches the ref "cost $0.025". So that is correct. The text has "a negligible amount". This is the error.
Inside the Commvault and Clumio Architecture for Petabyte-Scale Durability
Clumio for Google Cloud executes entirely on Google Cloud Run, scaling automatically to handle tens of billions of objects without manual intervention. This serverless architecture eliminates idle compute charges by spinning up containers only during active backup or recovery operations. The pricing model enforces a 100% pay-as-you-go structure, removing upfront license fees and fixed monthly commitments common in legacy platforms. Operators pay strictly for backup operations and secondary storage consumed, avoiding the waste of over-provisioned infrastructure. Such elasticity supports petabyte-scale AI workloads where data volume fluctuates unpredictably during training cycles.
Deploying Logical Air-Gaps and Threat Scans for AI Workloads
Activating Commvault Cloud Threat Scan requires enabling the specific policy flag within the Marketplace console to inspect BigQuery datasets before restoration. Operators configure logical air-gaps by directing backup streams to isolated vaults, ensuring production credentials cannot overwrite immutable copies during an attack. This process protects agentic AI workloads where global cloud usage is estimated to exceed 500 terawatt-hours in 2026. The architecture supports Cleanroom Recovery to validate data integrity in a sandboxed environment prior to production reintegration.
- Apply the Air Gap Protect policy to separate secondary storage from the primary network.
- Schedule automated threat scans to identify known malware signatures within backup increments.
- Execute point-in-time recovery tests to verify model training data remains uncorrupted.
| Feature | Native Versioning | Clumio Logical Air-Gap |
|---|---|---|
| Credential Isolation | None | Complete Separation |
| Threat Detection | Post-Infection | Pre-Restoration Scan |
| Cost Model | Linear Growth | Usage-Based |
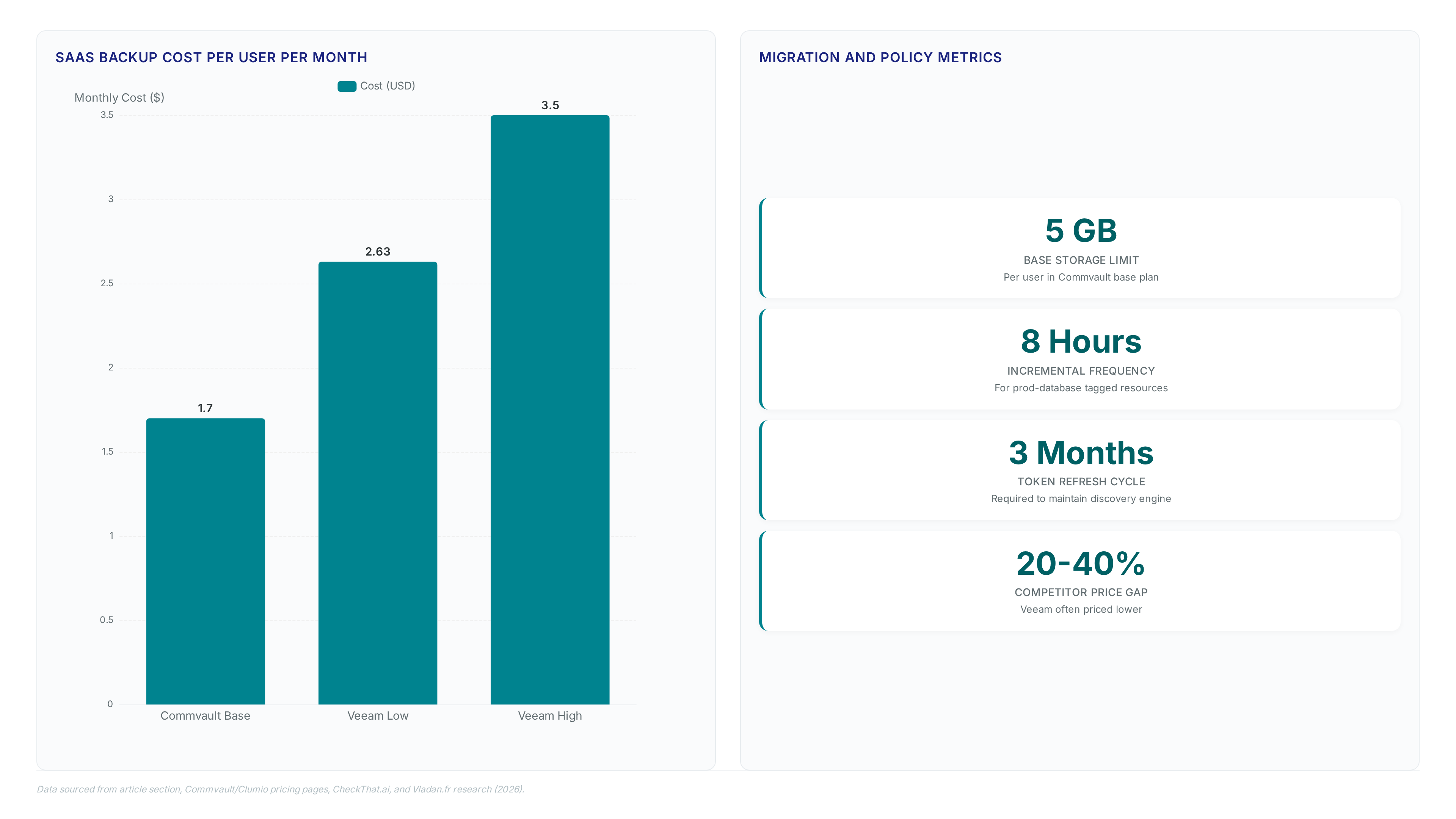
A specific drawback exists: API token management demands refreshes every three months to maintain secure connectivity without interruption. Failure to rotate these keys breaks the backup chain, leaving massive datasets exposed. Static versioning lacks the efficiency found in petabyte-scale engineering designed to handle billions of objects. Operational discipline becomes mandatory because teams must monitor token expiry dates alongside storage metrics. Integrate these scans into existing CI/CD pipelines to automate validation. Recovery speed depends entirely on the frequency of these incremental scans rather than total dataset size.
Utility-Driven Credits Versus Fixed Licence Fees
Credit-based utility pricing aligns backup spend directly with consumed gigabytes rather than fixed annual subscriptions. Traditional models force operators to purchase perpetual licenses costing upwards of $100,000 In contrast, the Commvault Cloud offering on the Marketplace uses a consumption model where Clumio SecureVault Standard backups cost $0.025 per GiB-month. This approach eliminates the financial penalty of over-provisioning capacity for peak loads that rarely occur. Competitors often rely on instance-based licensing
| Pricing Model | Upfront Cost | Scaling Mechanism | Ideal Workload |
|---|---|---|---|
| Utility Credits | None | Auto-scales with data | Variable AI datasets |
| Fixed License | High | Manual capacity planning | Static enterprise archives |
| Instance Subscription | Medium | Per-vm fee | Small stable clusters |
Discovery simplifies to a single IAM credential scanning the entire organization across all projects. The Arlie Advisor engine then analyzes tags to recommend specific policies, such as daily fulls for production databases. Operators receive a generated TCO comparison detailing savings against native Google tooling before committing resources. SaaS-first organizations increasingly prefer these usage-based pricing models over rigid legacy contracts. Unpredictable data spikes can cause billing variance, requiring strict tag governance to prevent budget overruns. Implement automated alerts on credit consumption rates to maintain fiscal control.
Failure to redefine these objectives leaves petabyte environments exposed to data loss events that exceed the maximum tolerable downtime for critical AI training pipelines. Xyzt. Ai reduced cloud backup spend by 66.7% after migrating from manual scripts to a managed SaaS architecture. This financial outcome directly resolves the challenge of high backup storage costs inherent in native versioning strategies. Under CEO Lida Joly, the organization shifted away from engineering-heavy maintenance toward an automated model that eliminates idle compute charges. The move demonstrates when to adopt Commvault Cloud over native tools: specifically when operational overhead outweighs the perceived simplicity of built-in features. Competitors often impose higher setup costs that delay ROI for mid-sized enterprises seeking immediate relief. Xyzt. Ai avoided this barrier by using a deployment model designed for rapid SaaS integration without upfront license fees. The total cost of protection dropped dramatically because the platform backs up only changed objects rather than storing redundant full copies. This approach contrasts sharply with cross-region replication, which frequently doubles storage expenditure while failing to prevent logical corruption.
| Metric | Native Scripting | Managed SaaS |
|---|---|---|
| Engineering Overhead | High | Negligible |
| Storage Efficiency | Low | High |
| Deployment Speed | Weeks | Days |
Operators facing similar volume growth should evaluate their data backup cost per gigabyte against the hidden labor expenses of custom maintenance. The verified savings achieved by xyzt. Ai highlight a significant tension between control and efficiency in modern cloud architectures. Assess current script maturity before committing to a full platform migration. Manual approaches fail because they cannot scale metadata operations fast enough for modern AI workloads. The architectural shift to cloud-native Integration enables sub-hour continuity by decoupling backup compute from storage growth.
Native versioning cannot distinguish between valid updates and malicious encryption, effectively syncing corruption across all copies. Clumio This separation creates a true durability boundary that simple replication cannot provide. Operators relying on scripts face a hidden cost: engineering hours spent maintaining fragile automation rather than innovating on core business logic. The financial impact is measurable, with total protection costs dropping by 70% when migrating from legacy patterns to this specialized SaaS model. Abandon manual scripts for any environment exceeding 5 GB of daily change rates. Vendor lock-in presents a risk, but the cost of unrecoverable data far outweighs the risk of platform dependency in the AI.
Executing a Smooth Migration to Automated Multi-Cloud Data Protection
Commvault Cloud Marketplace Deployment and Credit-Based Pricing Model
Deployment initiates through a single IAM credential that scans the entire organization across all projects to surface unprotected workloads. Administrators subscribe via the Google Cloud Marketplace The architecture replaces fixed licensing with a utility-driven model where costs scale strictly with consumption.
- Link the identity provider to enable automatic discovery of Compute Engine and BigQuery instances.
- Apply Arlie Advisor recommendations to generate policies based on resource tags like `prod-database`.
- Activate Commvault Cloud Air Gap Protect to isolate backups from production networks against ransomware.
This credit-based approach avoids the financial penalty of over-provisioning common in legacy instance-based licensing Operators gain immediate visibility into risk posture without manual inventory scripts or upfront capacity commits. The limitation remains that API token management requires strict adherence to refresh cycles every three months to maintain secure access. Failure to rotate credentials invalidates the discovery engine, leaving new resources unprotected until manual intervention occurs. Treat the initial deployment as a continuous audit loop rather than a one-time configuration event.
Automating Backup Policies with Arlie Advisor and BigQuery Point-in-Time Recovery
Arlie Advisor reduces misconfiguration risks by mapping resource tags to specific retention schedules automatically. Operators initiate protection by applying the `prod-database` label, triggering daily full backups with eight-hour incrementals. This tag-based logic eliminates manual policy creation across hundreds of projects. The engine analyzes workload types to suggest optimal frequency without human intervention. Recovery execution follows a strict four-step workflow for BigQuery datasets.
- Select the specific dataset snapshot from the immutable vault interface.
- Choose the target project and region for the restored data.
- Validate the point-in-time consistency before committing the restore job.
- Monitor the completion status via the centralized dashboard logs.
Cross-project restores allow teams to validate data integrity in isolated sandbox environments safely. Cross-region capabilities ensure analytics pipelines resume operations even after a zonal outage occurs. Organizations distributing AI systems across hyperscalers require such multi-cloud protection capabilities to maintain continuity. Declarative management integrates with Terraform providers to version control backup policies alongside application code. The limitation remains that tag consistency depends on upstream governance discipline within the organization. Missing labels result in uncovered assets despite the automation engine running correctly. Enforce mandatory tagging policies before enabling automated suggestions. This architectural shift moves durability from reactive scripting to proactive, policy-driven enforcement.
Implementation: Security Validation Checklist: Logical Air-Gaps, Threat Scans, and Token Rotation
Secure multi-cloud environments by enabling logical air-gaps that isolate backups from production ransomware attacks.
- Activate Commvault Cloud Air Gap Protect to create immutable storage vaults, preventing deletion or encryption by compromised credentials.
- Run Commvault Cloud Threat Scan on every backup set to identify known malware signatures before recovery operations begin.
- Enforce a strict schedule for API tokens rotating credentials every three months to limit exposure windows.
| Control | Native Tooling | Commvault Cloud |
|---|---|---|
| Immutability | Configurable, often optional | Default, indelible |
| Threat Detection | Post-restore manual check | Pre-restore automated scan |
| Credential Hygiene | Manual tracking required | Enforced rotation limits |
Organizations adopting this DevSecOps model gain 40% greater visibility into their threat surface compared to manual processes. Failure to rotate tokens allows stale credentials to persist indefinitely, creating a silent entry point for attackers. Most operators overlook that logical air-gaps require explicit configuration; they are not automatic by default in standard cloud buckets. This validation step ensures that multi-cloud security relies on verified isolation rather than assumed separation. Planning for 2026 requires these controls to be active before scaling workloads.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the critical discussion on Google Cloud Storage buckets and modern data protection. With a specialized background in Kubernetes storage architecture and disaster recovery, Alex daily designs resilient systems for cost-conscious enterprises and AI startups. His hands-on experience managing petabyte-scale environments directly informs the analysis of why traditional protection strategies fail against today's massive object counts. At Rabata. Io, a provider of high-performance S3-compatible storage, Alex works extensively with cloud-native applications that demand both speed and affordability. This practical engagement with multi-cloud realities allows him to identify the operational gaps highlighted in Commvault's research. By bridging theoretical infrastructure challenges with real-world implementation at Rabata, Alex offers actionable insights into optimizing storage costs while ensuring reliable recovery capabilities for the AI.
Conclusion
Scaling Google Cloud Storage buckets exposes a critical fracture: manual governance cannot survive the projected doubling of global cloud energy consumption by 2030. As data volumes explode, the operational drag of verifying individual bucket policies creates a recovery latency that renders traditional disaster plans obsolete. Relying on human intervention for air-gap validation introduces a single point of failure that attackers exploit quicker than teams can react. You must transition from reactive scripting to automated policy enforcement immediately to prevent security gaps from widening as your infrastructure expands.
Adopt a hybrid protection model where native bucket immutability handles daily snapshots, but a specialized third-party layer manages cross-cloud isolation and pre-restore threat scanning. This approach is mandatory for any organization expecting to maintain sub-hour RTOs beyond 2026. Do not wait for a compliance audit to trigger this shift; the window to architect resilient systems before the next capacity surge closes rapidly.
Start by auditing your current bucket labeling schema against your backup retention policies before Friday. Identify any production buckets lacking mandatory tags that enforce logical separation from your backup vaults. Rectify these gaps immediately to ensure your automation engines actually cover your most critical assets rather than skipping them due to missing metadata.
Frequently Asked Questions
Native versioning syncs logical corruption instantly across regions without isolation. Misconfiguration accounts for 65% of incidents, proving manual control over bucket policies ignores the harsh reality of modern authorized malicious actors holding write access.
Atlassian achieved a 15-minute RPO while managing a single bucket exceeding 80 billion objects. The deployment also delivered a 2-hour RTO, a specific metric unattainable with manual scripting at this massive petabyte scale.
Customers report logging into the Clumio console roughly once every 30 days on average. This platform handles monitoring and remediation automatically, removing the burden of maintaining custom protection scripts that often introduce errors.
Commvault research indicates 55% of organizations lack confidence in recovering from major cyber incidents. This gap exists because 84% of leaders run multi-cloud environments yet depend on fragile manual processes for protection.
The architecture scales automatically on Google Cloud Run so you never pay for idle compute resources. This 100% pay-as-you-go model aligns expenses strictly with actual backup operations rather than theoretical maximums or fixed commitments.
