AI storage: Cut costs 20% with hybrid flash
Scality testing shows their connector delivers 10x faster performance than standard S3 interfaces on similar hardware.
The industry's rush toward all-flash deployments hit an economic wall. NAND prices spiked. Data volumes exploded. The thesis is clear: intelligent software-set tiering is the only viable path for sustainable AI infrastructure. Hybrid flash models use spinning disk drives that remain 4 to 5 times cheaper per GB than SSDs to offset volatile component costs. We dissect the NeuralMesh Connector architecture, specifically how Scality's lightweight interface bypasses the latency of conventional S3 gateways to achieve substantial throughput gains without custom engineering. This analysis contrasts the validated partnership against Ceph alternatives and expensive all-flash arrays, demonstrating how enterprises secure exabyte-scale durability while avoiding the management overhead plaguing community-driven object stores.
The Role of Hybrid Flash and Object Tiering in Modern AI Infrastructure
Defining Hybrid AI Storage Tiering with WEKA NeuralMesh and Scality RING
Active datasets sit on SSDs. Cold data migrates to spinning disk. WEKA operates as a $1.6 billion entity delivering the highspeed file system layer required for training clusters. The NeuralMesh file system targets hardware like Nvidia BlueField-4 DPUs to sustain sub-millisecond latency during model iteration. Inactive data flows automatically to the capacity tier without interrupting compute workflows. Scality RING provides the backend object store with 99.999999999999% durability across exabyte scales. This specific connector design avoids the overhead typical of generic S3 gateways used in legacy hybrid setups. Organizations achieve up to 20% lower infrastructure costs by replacing all-flash arrays with this tiered approach. Shifting bulk data to HDDs drives the economic benefit since spinning media costs a fraction of NAND flash per gigabyte. Pure all-flash competitors lack this native cost-efficiency for petabyte-scale datasets.
Network topology presents a constraint. The tiering mechanism demands high-bandwidth fabric between the flash and object layers to prevent promotion stalls. Operators must validate switch buffer depths before deployment so data moves smoothly. Inadequate interconnect bandwidth creates a bottleneck that negates the flash tier advantage.
Accelerating EDA Workloads with 0.87 Millisecond Operation Response Time
Electronic Design Automation tests recorded 6,310 jobs completing with a 0.87 millisecond Operation Response Time on the flash tier. This metric defines the performance ceiling for active design data before migration to capacity storage occurs. NeuralMesh maintains this sub-millisecond latency to prevent GPU starvation during complex simulation runs. Operators must tier data to object storage once access frequency drops below real-time processing requirements. The blended workload test confirms that flash speed remains dedicated to active jobs while cold datasets move to cheaper media. Moving inactive files to the capacity layer reduces infrastructure spend without impacting simulation throughput.
Purely all-flash architectures struggle to match the economic efficiency of this hybrid model during NAND price volatility. Competing scale-out architectures often force uniform low latency across all data, inflating costs for dormant files. Policy tuning introduces a drawback; aggressive tiering risks pulling data back to flash too frequently, negating cost savings. Network teams must balance retention windows against available SSD capacity to maintain optimal job velocity. This approach isolates high-value compute resources from bulk storage economics.
Cost Efficiency and Performance Gains Versus Traditional S3 Object Integration
Scality RING connector benchmarks show 10x faster performance than conventional S3 interfaces on identical hardware. This architecture replaces expensive all-flash arrays with a tiered model where HDDs provide capacity at a fraction of the cost. Spinning media remains 4x to 5x cheaper per GB than SSDs allowing operators to avoid capital expenditure spikes during NAND shortages. Recent market shifts saw NAND prices jump 33-38% in early 2026, making hybrid approaches financially superior to monolithic flash deployments. Pure Storage FlashBlade alternatives often carry expensive cost implications for enterprises lacking infinite budgets. The joint solution avoids these pitfalls by keeping hot data on NeuralMesh while cold data rests on disk.
Latency consistency conflicts with total cost of ownership in many deployment scenarios. Pure flash guarantees uniform speed but burns budget on idle data. Hybrid tiering introduces potential migration latency but drastically reduces spend on cold datasets. The Scality RING connector mitigates this risk by accelerating object access so tiering does not become a bottleneck. This balance allows organizations to scale AI workloads without proportional infrastructure expense growth. Evaluate data access patterns before committing to single-media architectures.
Inside the NeuralMesh Connector Architecture and Data Flow
REST-Based Object Connector Mechanics in NeuralMesh Architecture
Flash holds hot data while disk accepts cold datasets to resolve speed versus cost conflicts. This mechanism operates through a REST-based interface that replaces standard S3 calls with optimized verbs tailored for AI training loops. NeuralMesh directs active tensors to the SSD tier, then triggers migration once access frequency drops below real-time thresholds. The architecture avoids management overhead by validating interoperability without requiring engineering changes to existing pipelines. Operators gain a hybrid tiering.
| Feature | REST Connector Mode | Conventional S3 Interface |
|---|---|---|
| Protocol Overhead | Minimal verb set | Full HTTP header expansion |
| Target Data State | Cold archival | Mixed hot/cold access |
| Cost Efficiency | High | Moderate |
Maximizing throughput while minimizing latency creates tension during the initial handoff between tiers. The economic advantage of this approach relies on HDD pricing remaining notably lower than NAND flash per gigabyte. Performance gain diminishes if policy thresholds for migration are set too aggressively, causing premature eviction of semi-active data. Tune these policies based on specific job duration rather than static time windows.
Direct GPU Data Feeding via Nvidia BlueField-4 DPUs
NeuralMesh executes on Nvidia BlueField-4 DPUs. This mechanism offloads storage protocol processing from the main compute node, ensuring GPU utilization remains maximized during training cycles. Traditional architectures often starve accelerators while waiting for data movement; placing the file system on the DPU eliminates this latency. Operators avoid capital expenditure spikes by tiering cold data while maintaining flash-speed access for active tensors.
| Architecture Mode | Data Path | CPU Overhead | Cost Profile |
|---|---|---|---|
| Host-Based File System | CPU → Memory → GPU | High | Expensive (All-Flash) |
| DPU-Offloaded NeuralMesh | DPU → GPU Direct | Negligible | Optimized (Tiered) |
Hardware dependency limits this performance profile because specific DPU availability and driver compatibility are mandatory. Competitors like MinIO offer RDMA-enabled object storage. Operators face complex scripting to move data between performance and capacity layers without this integration. The Scality RING connector resolves this by automating migration while preserving the direct feed capability. Validate DPU firmware versions before deployment to prevent handshake failures during initial cluster bring-up.
Mitigating Supply Chain Risks from 52-Week HDD Lead Times
Procurement cycles for high-capacity nearline HDDs now span 52 weeks, forcing architects to decouple active compute from capacity planning. This constraint stalls AI pipeline expansion when organizations rely on uniform all-disk arrays for cost control. The hybrid model resolves this by isolating hot tensors on NeuralMesh flash while using existing disk pools for cold data. Operators avoid waiting for new hardware shipments because the architecture maximizes current spinning media efficiency through a validated object connector. Scality RING provides the necessary durability layer without demanding immediate capacity additions during supply shortages.
| Constraint | Traditional Approach | Hybrid Mitigation |
|---|---|---|
| Lead Time Impact | Project delays due to missing disks | Utilization of installed base |
| Cost Structure | High CapEx for emergency flash buys | Optimized OpEx via tiering |
| Performance | Uniform latency degradation | Flash speed for active jobs |
Reduced flexibility in cold storage expansion persists until supply chains normalize. This strategy allows continuous GPU utilization despite external logistics failures. Prioritize software-set tiering over hardware procurement to bypass these bottlenecks. Extend pipeline life rather than replacing infrastructure entirely.
Comparative Advantages of NeuralMesh Over All-Flash and Ceph Alternatives
Scality RING and VAST Data Market Mindshare Dynamics
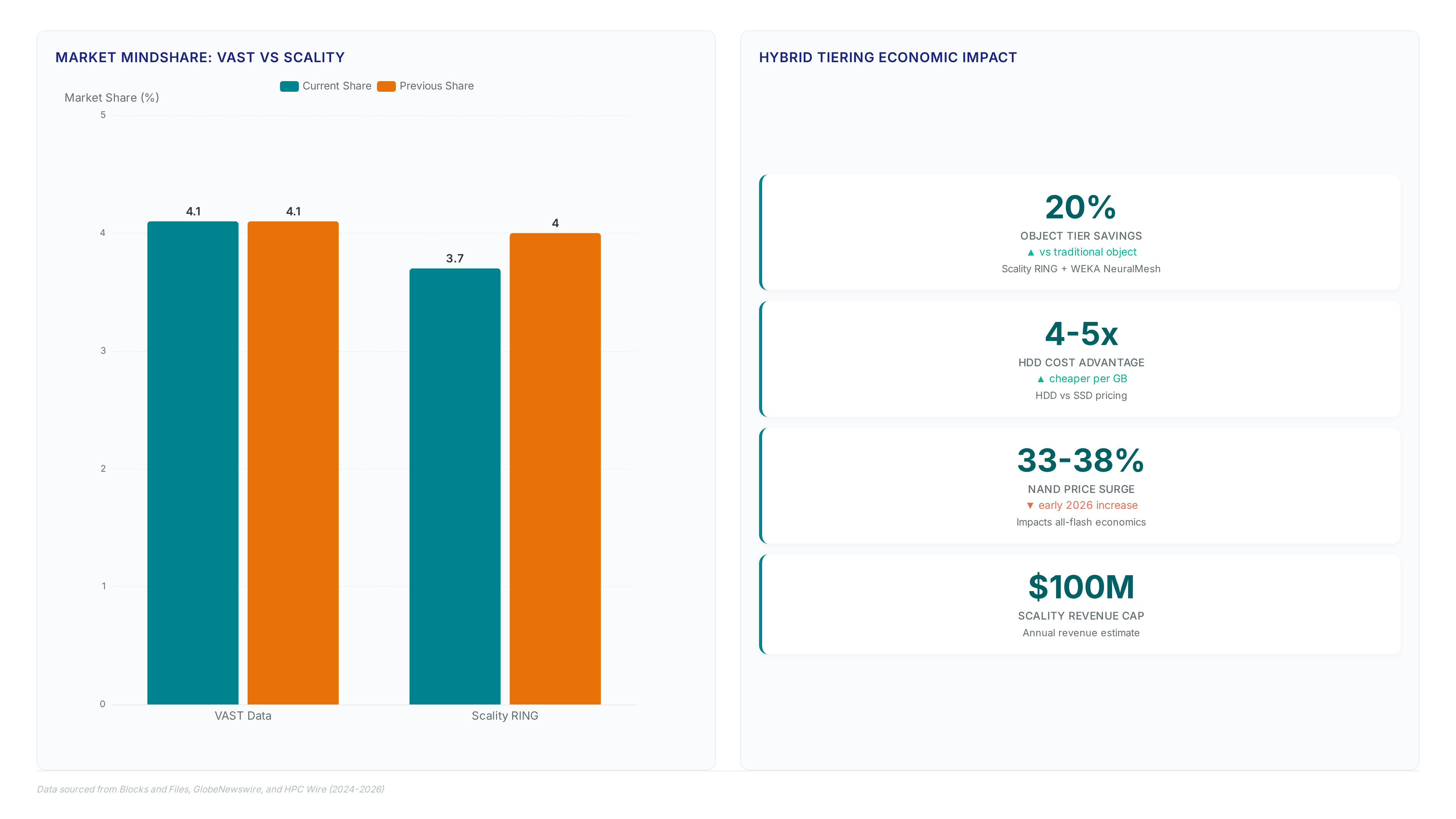
VAST Data commands 4.1% market mindshare against Scality's 3.7%, yet volatile NAND pricing shifts operator preference toward hybrid architectures. Scality generates between a modest sum and $100 million annually, positioning the vendor to capitalize on flash cost spikes that plague all-flash competitors. Operators facing a significant surge in component costs find this approach superior to the rigid economics of Pure Storage or VAST Data deployments.
| Dimension | Scality/WEKA Hybrid | VAST Data All-Flash | Pure Storage FlashBlade |
|---|---|---|---|
| Media Strategy | Flash + HDD Tiering | Uniform NAND | Uniform NAND |
| Cost Volatility | Hedged against spikes | Fully exposed | Fully exposed |
| Cold Data Cost | Low (Disk-based) | High (Flash-based) | High (Flash-based) |
| Scalability Limit | Exabyte-scale object | Capacity-constrained | Capacity-constrained |
Pure reliance on NAND creates a single point of financial failure during supply shocks. The surge in flash pricing demands evaluating tiering flexibility over raw throughput benchmarks when procuring storage for long-running training jobs. This strategic divergence allows Scality RING to capture workloads that all-flash vendors cannot serve profitably during inflationary cycles. Market dynamics favor architectures that decouple performance from capacity purchasing decisions. Isolating hot tensors on NeuralMesh while parking cold datasets on disk hedges against these spikes. This strategy avoids the capital exposure inherent in uniform scale-out arrays during supply crunches. Operators facing such volatility must weigh performance consistency against rigid procurement budgets.
| Metric | All-Flash Array | Hybrid NeuralMesh + RING |
|---|---|---|
| Cost Sensitivity | High exposure to NAND spikes | Low; disk absorbs cold data |
| Capacity Scale | Limited by flash budget | Exabyte-scale via object tier |
| Procurement Risk | High ( | Mitigated via existing HDD pools |
Deploying this architecture requires explicit policy definitions for data temperature thresholds. Blindly migrating data creates latency jitter that stalls GPU pipelines. However, misconfigured thresholds can force frequent re-hydration of cold data, negating savings. Audit access patterns weekly to tune these boundaries dynamically. Financial risk mitigation now outweighs raw throughput as the primary design constraint for AI storage.
All-Flash Scale-Out Versus Scality WEKA Hybrid Cost Models
Uniform all-flash arrays from Pure Storage and VAST Data expose operators to unchecked capital risk when NAND prices surge. The Scality and WEKA partnership mitigates this volatility by tiering cold data to disk rather than forcing expensive flash for every byte. Competitors relying on uniform media lack this financial buffer, making their total cost of ownership highly sensitive to component market fluctuations. Blocksandfiles. Operators achieve a targeted cost reduction by avoiding the procurement of unnecessary high-speed capacity for dormant files.
| Feature | All-Flash Scale-Out | Scality + WEKA Hybrid |
|---|---|---|
| Media Strategy | Uniform NAND Flash | Flash Tier + HDD Object |
| Cost Volatility | High Exposure | Hedged via Disk Tier |
| Cold Data Cost | Expensive | Economical |
The limitation of the all-flash model becomes acute when supply chains tighten and component costs rise unexpectedly. Hybrid architectures absorb these shocks by decoupling performance requirements from capacity planning. Use this split-tier design for organizations prioritizing long-term budget stability over uniform low latency. Financial durability often outweighs marginal latency gains for cold datasets in large-scale AI training environments.
Deploying Enterprise-Grade AI Storage with Scality and WEKA Integration
Implementation: Scality RING and NeuralMesh Connector Architecture for Hybrid Tiering
The jointly validated solution bridges WEKA flash tiers with Scality RING capacity via a dedicated object connector.
- Deploy NeuralMesh on NVMe nodes to handle active AI training datasets requiring low latency.
- Configure the Scality connector to map cold data paths directly to the hybrid tiering model.
- Enable automatic data migration policies based on access frequency to maintain flash efficiency.
This architecture diverges from competitors by avoiding uniform all-flash commits that expose budgets to volatile component pricing. The protocol flexibility gap remains a constraint; operators must manage file and object interfaces separately rather than exploiting a unified namespace export. Validate network throughput between tiers before enabling auto-migration to prevent bottlenecks during peak inference loads. Separating control planes for flash and disk introduces operational complexity that uniform arrays abstract away, demanding higher staff expertise for initial tuning.
Deploying the Validated Solution to Achieve 76.9% Faster Backup Cycles
A police service customer achieved a 76.9% reduction in backup times by implementing this specific hybrid architecture.
- Initialize NeuralMesh on NVMe nodes to ingest active AI training datasets requiring low latency.
- Configure the lightweight connector to map cold data paths directly to Scality RING capacity using spinning disks.
- Automate migration policies based on access frequency to maintain flash residency only for hot tensors.
This configuration isolates performance-sensitive workloads while using cheap disk for archival data. The police service modernization case study demonstrates that such tiering yields $2 million CAD in savings alongside quicker recovery windows. Operators must balance the complexity of managing two distinct storage pools against the capital avoidance of all-flash arrays. A single misconfigured threshold can force cold data onto expensive NVMe, eroding the economic benefit entirely. Failure to tune these parameters results in suboptimal GPU utilization and wasted expenditure on unnecessary flash capacity.
Pre-Deployment Validation Checklist for HumanX 2026 Ready Infrastructure
Verify hardware compatibility for the NeuralMesh connector before the HumanX 2026 showcase in San Francisco.
- Confirm NVMe node availability to support flash-tier ingestion without supply chain delays.
- Validate that spinning disk arrays meet the durability requirements for the Scality RING capacity tier.
- Test the object connector.
- Ensure firmware versions align with the jointly validated solution released on 9 Mar 2026.
| Component | Validation Target | Risk Signal |
|---|---|---|
| NVMe Nodes | Throughput saturation | GPU starvation |
| HDD Arrays | Write consistency | Tiering failure |
| Network Switch | Jitter tolerance | Packet loss |
Operators skipping this step face silent data misalignment during peak training cycles. Globenewswire. Html) disappears if the underlying fabric cannot sustain the required handoff speeds. Isolate test traffic to avoid contaminating live telemetry. Failure to validate leaves the deployment vulnerable to the same bottlenecks plaguing all-flash alternatives.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in optimizing S3-compatible storage for AI and machine learning workloads. His deep expertise in cloud storage architecture makes him uniquely qualified to analyze the complexities of AI storage tiering. In his daily role, Chen designs scalable data infrastructures that balance high-performance compute needs with cost-efficient capacity, directly mirroring the challenges addressed by the Scality and WEKA partnership. He routinely helps enterprises navigate the trade-offs between flash-speed performance and durable object storage, ensuring smooth integration for AI/ML data pipelines. At Rabata. Io, a provider focused on democratizing enterprise-grade storage, Chen uses his background to validate how hybrid solutions can eliminate vendor lock-in while reducing costs. His practical experience implementing Kubernetes persistent storage and optimizing S3 API workflows provides the technical foundation necessary to evaluate emerging tiering strategies for modern AI infrastructure.
Conclusion
Scaling AI storage beyond the pilot phase exposes a critical fragility: manual tiering policies collapse when data velocity outpaces human intervention. As NAND volatility continues to alter capital planning, relying on static thresholds creates immediate operational drag, forcing hot data onto cold media or vice versa. The shift toward five-to-seven tier environments in 2026 demands that organizations treat data placement as a flexible, software-set function rather than a set-and-forget configuration. Do not attempt to expand your AI cluster without first integrating neural-driven placement logic; otherwise, you are simply building a larger, more expensive bottleneck. The window to secure cost-efficient exabyte scales closes as hardware prices stabilize and competitors lock in superior architectures.
Start this week by auditing your current tiering thresholds against actual access logs from the last 48 hours. Identify any cold datasets currently residing on NVMe tiers and calculate the immediate capital waste, then use this data to justify the budget for an intelligent orchestration layer before your next hardware refresh cycle.
Frequently Asked Questions
Organizations achieve up to 20% lower infrastructure costs by replacing all-flash arrays. This specific economic benefit arises from shifting bulk data to cheaper spinning disk drives while maintaining high performance.
Scality RING provides the backend object store with 99.999999999999% durability across exabyte scales. This ensures long-term data resilience for large datasets without forcing customers into expensive, uniform all-flash deployments.
WEKA operates as a $1.6 billion entity delivering the highspeed file system layer. This substantial market presence ensures they can sustain the high-performance software foundation modern AI pipelines require to run optimally.
The solution offers simplified tiering with proven interoperability validated by WEKA requiring no engineering changes. This allows enterprises to extend their AI data pipelines more economically while avoiding complex management overhead.
Scality testing shows their connector delivers 10x faster performance than standard S3 interfaces on similar hardware. This speed ensures active data remains accessible at flash speeds, preventing compute stalls during model iteration.
