End-to-end data intelligence: Tape beats cloud costs
ISC 2026 Booth D39 hosts a tri-vendor stack uniting Mediaflux, Metadata-Hub, and BDT ORION tape. This collaboration proves that sustainable archive infrastructure now demands tight coupling between active management and cold storage to survive the AI context engineering shift. As Monte Carlo notes, AI agents in 2026 require millisecond access to streaming context, rendering static silos obsolete for serious research.
You will learn how this specific architecture bridges Grau Data's metadata capabilities with Comback's enterprise tape to automate policy-driven movement across petabyte scales. The analysis dissects why enterprise tape infrastructure remains superior to public cloud for long-term retention, specifically regarding energy consumption and cost reduction in EB-scale environments.
Finally, the piece examines how Arcitecta uses this integration to maintain visibility across the entire data lifecycle, directly addressing the struggle to capitalize on massive unstructured datasets. By connecting active tiers with deep archive, organizations can finally extract value from data that would otherwise stagnate, ensuring readiness for the next-generation of high-performance computing demands without breaking the budget.
The Role of End-to-End Data Intelligence in Modern Research Infrastructure
Defining End-to-End Data Intelligence via Metadata-Driven Archives
Strict metadata enforcement binds active management layers to immutable tape archives. End-to-end data intelligence orchestrates lifecycle policies across heterogeneous storage tiers without manual intervention. The mechanism depends on Metadata-Hub to curate contextual attributes that trigger automated movement rules. Content migrates from high-performance disk to BDT ORION This shift ensures long-term preservation at minimal energy cost. Mediaflux acts as the central policy engine and has operated continuously since 2002 to manage these complex transitions for research institutions. A single namespace emerges where policy-driven data movement occurs transparently to the end user. Operators define retention schedules once.
Scaling Unstructured Data for AI and Research Discovery
Unstructured data scalability fails when metadata contexts remain decoupled from physical storage tiers, blocking AI training pipelines. The end-to-end data intelligence model resolves this by binding active compute workflows to immutable archive layers through a unified API. Research institutions like the University of Melbourne use this architecture to exploit massive datasets. Metadata enrichment accelerates discovery speeds without duplicating content. This approach prioritizes scientific data lifecycle states over simple access latency unlike global file systems focused solely on sharing. Adoption becomes necessary when organizations face exponential growth in unstructured assets while budgets remain flat.
Validating Modern Research Infrastructure with Mediaflux and XtreemStore
Validating modern research infrastructure requires binding active workflows to immutable tape tiers using strict metadata predicates. This end-to-end data intelligence model functions by orchestrating policy-driven movement between disk and archive without external database dependencies. The mechanism relies on Metadata-Hub A constraint emerges if organizations skip publishing these upstream lists. The AS path remains unsigned and breaks the chain of custody. Operators should adopt this metadata-driven approach when unstructured data volumes block AI training pipelines due to decoupled storage contexts. The demonstration scheduled for ISC 2026 Mediaflux converges orchestration and multi-protocol access into one platform unlike traditional setups requiring separate server components. Initial rollout demands rigorous policy definition to avoid false-positive rejections of valid research data. This cost is measurable. Mission and Vision recommends verifying that candidate solutions eliminate siloed management tools before committing to petabyte-scale deployments.
Inside the Architecture of Mediaflux and BDT ORION Tape Integration
Mediaflux Universal Data System and Protocol Translation Mechanics
Converging orchestration and storage into one platform instance removes the external database dependencies found in legacy setups. This approach consolidates expenses that traditional architectures split across multiple vendors, effectively eliminating separate server components. Protocol translation allows data ingestion through a single interface while permitting access via entirely different protocols without shifting the underlying bytes.
- Systems maintain a universal namespace across heterogeneous media types including on-premises SSDs, disk, tape, and public cloud object storage.
- Rich metadata curation binds active workflows to immutable archives, ensuring visibility and accessibility throughout the lifecycle.
- Policy engines automate movement between tiers based on contextual attributes rather than manual migration scripts.
| Feature | Traditional Architecture | Universal Data System |
|---|---|---|
| Database Layer | External SQL required | Integrated metadata engine |
| Protocol Access | Single protocol per tier | Multi-protocol translation |
| Cost Model | Capacity-based scaling | Concurrent user licensing |
Such consolidation introduces a singular point of configuration failure where an error in the unified policy engine disrupts both active and archive tiers at once. Operators gain storage agnosticism yet lose the isolation boundary that previously contained database corruption incidents. The architectural shift means Mediaflux Burst handles flexible expansion, but the entire data path depends on one software stack's stability. Organizations managing large-scale datasets must weigh the operational simplicity of a unified system against the risk of coupled failure domains. Mission and Vision recommends validating failover procedures specifically for the integrated metadata layer before migrating production workloads.
Automating Policy-Driven Data Movement with Livewire and BDT ORION
Policy predicates trigger the Livewire high-speed mover to shift data between active disk and Comback's BDT ORION tape without manual intervention. This mechanism relies on Mediaflux Burst to expand storage capacity dynamically into the cloud, optimizing transfers across wide area networks for live production workflows. DigitalGlobe demonstrated operational stability by managing satellite imagery on AWS with zero crashes over two years using this architecture. Cost efficiency in managing heterogeneous storage carries a constraint: organizations must define strict metadata rules upfront, or risk improper tiering that negates energy savings. This integrated stack maintains a unified view while avoiding the egress fees associated with moving data between cloud tiers in competitor architectures, unlike static tape libraries requiring complex middleware.
Network operators see clear implications here. Automating movement based on file age or project status reduces long-term storage costs notably. Implementing data lifecycle visibility in HPC environments requires binding active workflows to immutable archive layers through a single.
| Feature | Traditional Middleware | Integrated Stack |
|---|---|---|
| Data Mover | Static transfer | Livewire optimized |
| Cloud Bursting | Manual provisioning | Automated via Mediaflux Burst |
| Cost Model | Capacity-based | Concurrent user-based |
The University of Melbourne uses this approach to use metadata for massive datasets, accelerating research speeds without duplicating content. A tension exists between immediate access latency and archive density; prioritizing one often degrades the other unless policy definitions are precise. Future deployments must address the gap where 67% of enterprises have deployed generative AI, yet only 20% express high confidence in their data analysis capabilities. 40% of G2000 roles will soon involve AI agents requiring fresh context availability. Mission and Vision recommend aligning storage tiers with AI agent requirements to ensure fresh context availability.
Validating Scale and Cybersecurity for 10PB+ NAS Deployments
Enterprises must verify scalability from terabytes to exabytes before committing to a single-server architecture for massive datasets. Third-party validation confirms the platform ranks as a TOP 5 Cybersecure solution for 2025-2026 after evaluating over 300 options. The cost model presents a specific tension: concurrent user-based pricing prevents linear expense growth, yet organizations often lack the metadata discipline to enforce the necessary policy predicates.
| Validation Criteria | Architectural Requirement | Operational Risk |
|---|---|---|
| Scale Verification | Single instance managing billions of assets | Metadata hub saturation |
| Security Posture | TOP 5 Cybersecure designation | Unvalidated archive tiers |
| Cost Structure | User-based vs capacity-based | Linear cost escalation |
| AI Readiness | Streaming context support | Static data silos |
Operators should prioritize solutions that fix data accessibility in the archive tier through protocol translation rather than migration. Failure to validate these capabilities early results in stranded assets when generative AI initiatives demand broader data accessibility . Mission and Vision recommends auditing current metadata completeness before deploying tape integration layers.
Strategic Advantages of Tape Versus Cloud for Large-Scale Archives
Concurrent User Pricing vs Capacity-Based Cloud Storage Costs
Tape infrastructure lowers long-term storage expenses by adopting a concurrent user-based pricing model instead of charging per gigabyte. This economic structure separates licensing fees from data volume, letting organizations expand archives to hundreds of petabytes without the linear cost spikes seen in capacity-based metrics. Cloud providers and legacy vendors like IBM Spectrum Archive often link fees directly to terabyte counts, creating expense models that are predictable yet rigid, effectively penalizing data accumulation.
Mediaflux aligns expenditures with organizational size rather than raw storage volume through this mechanism. A sharp limitation appears when metadata discipline lapses; absent strict policies, cheap tape storage turns into a data swamp that inflates retrieval latency. Operators must balance the stability of fixed licensing against the flexibility of pay-as-you-go cloud tiers. Protocol translation adds complexity to the decision by enabling cross-tier access without moving bytes. Mission and Vision recommends deploying concurrent pricing for static research datasets where access patterns stay predictable over decades.
Comparison: Scaling Research Data from Terabytes to Exabytes with Mediaflux
Powerhouse Museum manages billions of digital assets on a single server instance, proving single server capability scales from terabytes to exabytes without external database overhead. This architecture removes the siloed metadata layers common in competitor platforms like Hammerspace or Nasuni, which often require separate indexing clusters for similar volumes. The Universal Data System presents one worldview of data across active disk and enterprise tape, yet this consolidation demands rigorous initial metadata schema design to prevent retrieval latency.
Operators facing scalability limits in legacy systems find that decoupling compute from storage introduces unnecessary complexity for research workflows. Cloud object stores offer infinite capacity, yet egress fees and API call costs create financial unpredictability for high-frequency access patterns typical in AI training. The concurrent user-based pricing model stabilizes budgets regardless of whether the archive holds ten petabytes or ten times that amount. Migrating from capacity-based licensing requires a shift in how organizations forecast IT expenditure, moving focus from storage volume to user concurrency.
Mission and Vision recommends validating integration paths with existing business systems before committing to a universal namespace strategy. The constraint for such deep unification is reduced flexibility in mixing vendor hardware without careful policy configuration. Organizations must choose between the operational simplicity of a single managed instance and the fragmented control of multi-vendor stacks.
Automated Policy-Driven Movement Versus Static Cloud Tiers
Static cloud tiers lack the Livewire high-speed data mover required for flexible research data workflows, forcing reliance on rigid capacity buckets. Mediaflux Burst enables automatic expansion into cloud storage only when local tape or disk thresholds trigger, contrasting sharply with manual tiering rules in legacy systems. Competitor architectures often depend on static tape libraries or complex middleware to achieve similar hybrid flexibility, introducing latency during peak ingestion windows.
The economic advantage stems from avoiding egress fees associated with moving data between cold and hot tiers in competitor architectures. Operational complexity is the drawback: defining precise policies requires deep understanding of data lifecycles, or the system defaults to safe but costly retention on high-performance media. Theoretical savings of hybrid cloud vanish under unplanned access patterns without this discipline. Mission and Vision recommends aligning policy definitions with research grant cycles to maximize cost efficiency.
Deploying Scalable Data Archives with Automated Retention Policies
Mediaflux Universal Data System and Metadata-Driven Retention Architecture
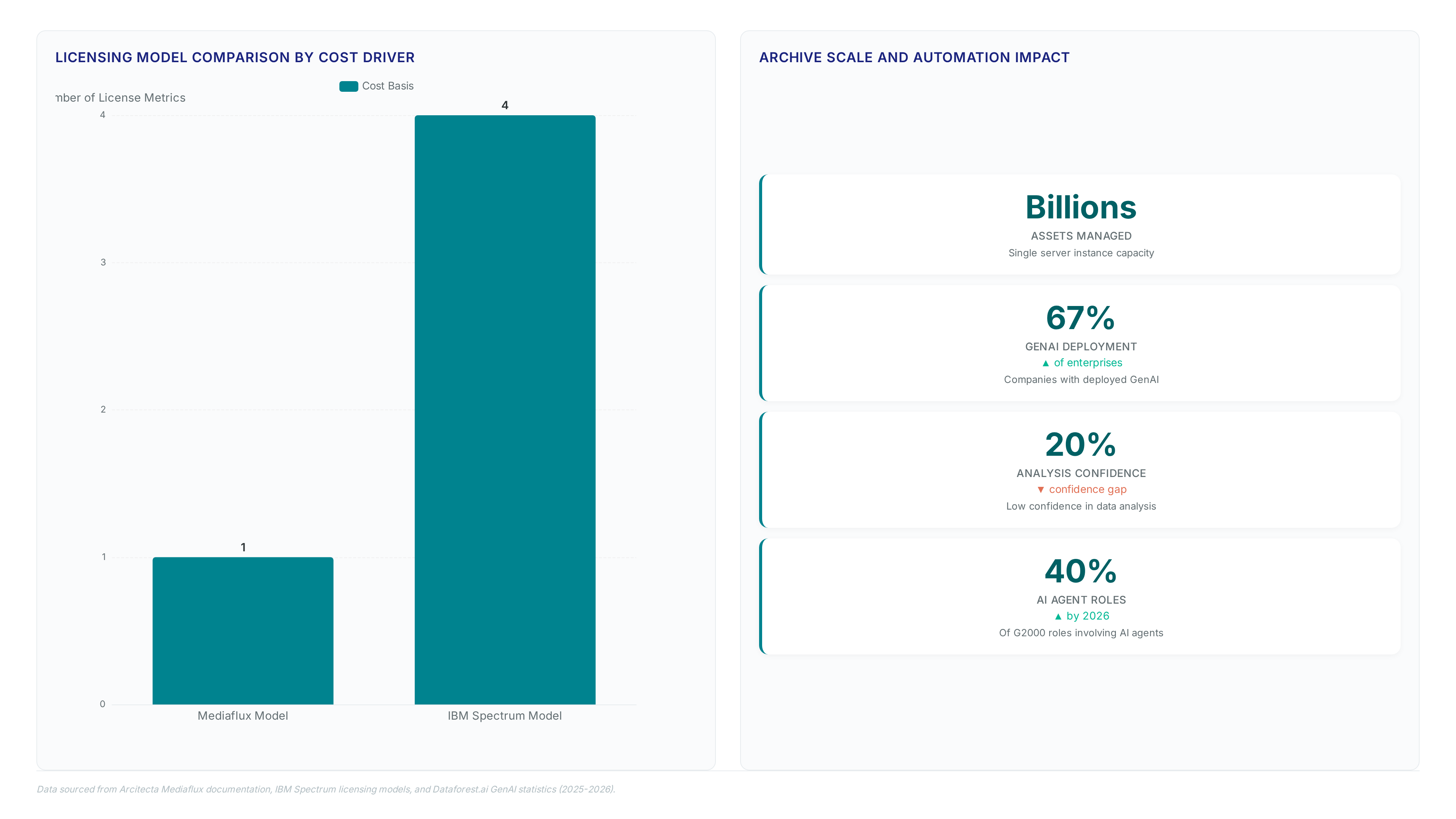
Eliminating external databases allows a single instance to manage billions of assets through the Universal Data System architecture. This design converges data management and orchestration, removing the latency penalties associated with separate indexing clusters found in traditional setups. Operators gain single server capability that scales from terabytes to exabytes without middleware fragmentation. The mechanism relies on rich metadata curation to enforce retention rules across active disk and enterprise tape tiers simultaneously. By embedding policy logic directly into the asset descriptor, the system automates movement without manual intervention or third-party schedulers. This approach ensures visibility and accessibility regardless of the underlying storage protocol.
Automation begins by binding retention rules to metadata tags rather than static directory paths.
- Define lifecycle policies within the Universal Data System that trigger on specific asset attributes like project completion dates.
- Configure the Livewire high-speed data mover to execute transfers once policy thresholds are met.
- Direct aged datasets to Comback's BDT ORION
- Enable Mediaflux Burst to dynamically overflow active tiers into cloud storage during ingestion spikes without manual reconfiguration.
This architecture eliminates external database dependencies, allowing a single server instance to orchestrate billions of assets across heterogeneous storage mediums. The mechanism relies on embedded metadata logic to maintain visibility while physically separating hot and cold data. However, flexible tiering introduces complexity in network bandwidth provisioning; sudden policy triggers can saturate WAN links if throughput limits are not explicitly set in the mover configuration. Organizations must balance aggressive archival schedules against available transfer capacities to avoid impacting active research workflows. Mission and Vision recommends aligning policy granularity with business value to prevent unnecessary data churn.
Deployment Validation Checklist for 10PB+ Cybersecure NAS and Tape Integration
Validate cybersecure configurations against the DCIG TOP 5 benchmark criteria for 10PB+ NAS solutions before production traffic ingestion.
- Audit immutable WORM settings on Comback BDT ORION tape drives to enforce physical air-gapping.
- Verify concurrent user-based pricing logic aligns costs with organizational size rather than escalating with data volume.
- Test protocol translation fidelity between S3 active tiers and tape archives to prevent metadata stripping.
- Confirm Livewire throughput sustains required ingestion rates without throttling during peak burst windows.
| Validation Target | Success Metric | Failure Mode |
|---|---|---|
| Tape Infrastructure | WORM lock active | Mutable backup stream |
| Licensing Model | Cost flat vs. Volume | Linear per-TB escalation |
| Data Mover | Zero packet loss | Throttled transfer rates |
Operators often overlook that capacity-based models from competitors like IBM Spectrum Archive create financial penalties as datasets expand, whereas this architecture decouples cost from volume. The concurrent user pricing structure Addressing the gap where most enterprises lack confidence in data analysis despite high AI deployment rates requires such accessible, unified storage foundations. Mission and Vision recommends validating these parameters quarterly to maintain cybersecure posture.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the discussion of end-to-end data intelligence solutions. His daily work designing Kubernetes storage architectures and optimizing disaster recovery strategies directly aligns with the complex integration challenges highlighted in the article. Having previously led DevOps teams at high-scale organizations, Kumar understands the critical need for smooth interoperability between metadata management, object storage, and archive tiers. At Rabata. Io, a provider of high-performance S3-compatible object storage, he engineers infrastructure that demands the exact type of cohesive data flow demonstrated by the Arcitecta, Grau Data, and Comback partnership. His experience ensuring cost-effective, vendor-neutral storage for AI and enterprise workloads provides a practical lens for evaluating how unified data intelligence platforms solve real-world scalability issues. This background makes him uniquely qualified to analyze the technical merits of integrating diverse data management layers into a single, efficient operational framework.
Conclusion
Scaling beyond 10PB exposes a critical fracture where metadata latency begins to strangle AI training pipelines, regardless of raw storage throughput. While the market expands rapidly, the operational reality is that unverified tape integration creates silent data corruption risks that undermine the very models enterprises seek to build. You cannot sustain high-confidence AI agents on a foundation where archive retrieval times fluctuate unpredictably or where licensing costs spike linearly with data growth. The gap between deployment and trust widens when financial models penalize scale rather than enabling.
Organizations must migrate to user-based pricing architectures and enforce immutable WORM locks on all tape targets before Q3 production cycles begin. Relying on capacity-based billing for exabyte-scale archives is a fiscal error that compounds as data volumes inevitably swell. Do not wait for a compliance audit to reveal gaps in your air-gap strategy; the window to secure these foundations before 40% of your workforce relies on compromised data agents is closing.
Start by auditing your current concurrent user licensing logic against your last three months of data growth this week. If your costs increased proportionally with your terabytes rather than remaining flat, you must renegotiate your contract or migrate your data mover immediately to prevent budget overruns from crippling future expansion.
Frequently Asked Questions
It avoids linear cost increases by pricing on users, not data volume. This model supports scaling to hundreds of petabytes while the broader market grows from $11.35 billion toward $74.0 billion by 2033.
Strict metadata enforcement binds active layers to immutable tape archives automatically. This ensures visibility across the lifecycle, helping organizations capitalize on growth projected from $11.35 billion to $74.0 billion by 2033.
Tape infrastructure offers superior energy consumption and cost reduction for EB-scale environments. This efficiency is vital as the sector expands from $11.35 billion to $74.0 billion, demanding sustainable archive solutions for long-term data preservation.
Mediaflux acts as the central policy engine to trigger automated movement rules. This manages the surge in data expected as the market rises from $11.35 billion to $74.0 billion by 2033 efficiently.
Metadata enrichment accelerates discovery speeds without requiring content duplication across tiers. This capability is essential for entities aiming to succeed as the industry expands from $11.35 billion to $74.0 billion by 2033.
