BigQuery agents need strict semantic guardrails
Google Cloud revenue jumped significantly to billions in late 2025, proving AI infrastructure drives the market. Enterprises focusing solely on per-gigabyte pricing ignore the hidden tax of moving data for AI processing.
Readers will examine how conversational analytics and semantic layers reshape query patterns within the Google Data Cloud. We dissect the architecture of managed databases and AI agent orchestration to reveal where latency and cost accumulate. The analysis extends to NoSQL capabilities and BI integration patterns required for heavy enterprise workloads.
Specific attention goes to BigQuery analytics and Looker BI as primary engines for this shift. We explore how Gemini in Looker and Airflow 3.1 features alter pipeline economics. Understanding these mechanics is necessary before committing to large-scale AI in data analytics deployments.
The Role of Conversational Analytics and Semantic Layers in Modern Data Clouds
Defining Conversational Analytics and the Semantic Layer in BigQuery
Stop writing SQL. An intelligent agent now generates, executes, and visualizes answers directly. This shift removes the manual composition bottleneck but introduces a new dependency: the semantic layer. This layer governs interactions so business logic remains consistent across Looker and BigQuery environments. By defining metrics and relationships centrally, you prevent the agent from generating conflicting or unauthorized data views. Generative AI integration within BigQuery serves as the inference engine that interprets user intent against this governed model.
The operational burden shifts from writing code to defining accurate data relationships. Without a strictly set semantic layer, natural language queries risk returning plausible but factually incorrect results. The agent requires rigid guardrails to function reliably in production. Enterprises adopting this approach must prioritize semantic modeling over raw query speed to maintain trust.
Deploying Gemini Agents in Looker Embedded and Data Studio
Organizations reintroducing this tool enable self-service analytics by embedding natural language queries directly into custom dashboards. Teams asking about analytics utility find value when deploying Conversational Analytics inside Looker Embedded environments. This configuration powers natural language experiences within proprietary applications without requiring users to leave their workflow. The mechanism relies on mapping user prompts to governed semantic models.
Open exploration clashes with data governance. Unrestricted access risks inconsistent reporting, yet tight controls stifle adoption. Operators must balance these competing priorities by defining clear boundaries for agent behavior. Performance varies based on model complexity and underlying data volume.
| Feature | Looker Embedded | Data Studio |
|---|---|---|
| Integration | Custom App API | Native Hosting |
| Agent Scope | App-Specific | Workspace-Wide |
| Governance | Semantic Model | Dataset Level |
Complex semantic joins increase response time for natural language requests. Engineers should monitor execution plans to prevent resource contention. Proper sizing of the compute layer remains necessary for consistent user experience. Teams should test query latency under load before general release.
Validating Data Product Foundations for AI Agent Readiness
Validate data products as structured foundations before enabling autonomous agent interaction. Teams asking what is Conversational Analytics must recognize it transforms natural language into executed queries rather than simple text generation.
| Validation Step | Technical Requirement | Risk if Skipped |
|---|---|---|
| Schema Governance | Enforce strict typing on source tables | Agent misinterprets data types |
| Metric Definition | Centralize logic in semantic layer | Conflicting business reports |
| Access Control | Limit dataset scope per agent | Unauthorized data exposure |
Unstructured raw data requires transformation before an agent can safely query it. Storing raw inputs on cost-efficient object storage while maintaining cleaned features in structured repositories is recommended. This separation ensures high-performance retrieval for training while minimizing costs for cold archives. Organizations must prioritize semantic consistency over raw query speed to sustain long-term AI utility. Data engineers often neglect the preprocessing step required for safe agent operation.
Inside the Architecture of Managed Databases and AI Agent Orchestration
BigQuery Graph Mechanics and Pipeline Operations in Firestore
BigQuery Graph is currently available in preview, enabling relationship traversal within the analytics engine. This architecture allows analysts to query deep hierarchical connections without managing separate graph databases or complex ETL pipelines. The system processes pathfinding algorithms to resolve multi-hop queries efficiently. Operators should isolate graph mutation windows from peak analytical read periods to maintain throughput. These capabilities allow filtering on high-cardinality fields without pre-defining every possible access pattern. Migration to enhanced Firestore is advisable when application requirements demand real-time consistency combined with event-driven processing logic.
| Feature | BigQuery Graph | Firestore Pipelines |
|---|---|---|
| Primary Use Case | Relationship analysis | Real-time transactional logic |
| Indexing Strategy | Native adjacency lists | Composite and flexible index types |
| Scaling Model | Decoupled compute/storage | Automatic horizontal scaling |
Deploying S3-compatible object storage alongside these services can help archive historical graph snapshots and pipeline logs cost-effectively. This hybrid approach prevents vendor lock-in while using native cloud performance for active datasets.
Orchestrating AI Agents with Managed Airflow MCP and Declarative YAML
State declaration now replaces imperative scripting as the primary orchestration method, allowing models to plan complex problem-solving sequences autonomously. Operators define dag parameters and dependency graphs in YAML, which the server translates into executable workflows for BigQuery and Cloud SQL interactions. This constraint means teams must version-control their YAML specifications with the same rigor applied to application code to prevent orchestration failures.
| Feature | Legacy Airflow | Managed Airflow MCP |
|---|---|---|
| Configuration | Python-based DAGs | Declarative YAML |
| AI Integration | Custom Hooks | Native MCP Server |
| Database Scope | Limited Connectors | Multi-DB Remote Support |
Network operators see reduced custom connector maintenance because the managed service handles protocol translation for supported engines. Reliance on managed control planes introduces a dependency on provider availability during region-wide outages. Teams building conversational analytics agents must therefore implement local fallback logic for critical data paths. Pairing these declarative pipelines with cost-monitoring hooks helps prevent runaway agent loops from inflating compute bills. Unstructured data now represents 80% of global enterprise data, making efficient orchestration vital for AI readiness. The limitation is reduced granular control over executor scaling in exchange for simplified deployment topology. Operators gain speed but lose fine-tuned resource allocation per task instance.
Validating Connectivity for Google-built ODBC and Agent Integration
Engineers must verify ODBC driver versioning against the latest preview windows to ensure compatibility with BigQuery features. Operators should confirm SQL Server alignment before enabling centralized management to prevent authentication loops.
| Feature | Google-built ODBC | Legacy JDBC Bridge |
|---|---|---|
| Development | In-house Preview | External Maintenance |
| Graph Support | Native Pathfinding | Manual Join Logic |
| Agent Ready | Yes | No |
Resolving Airflow agent integration issues requires validating that the MCP server exposes the correct database capabilities to the conversational interface. A critical tension exists between rapid agent deployment and strict schema validation; rushing the latter causes runtime failures in declarative pipelines. Documentation emphasizes that accelerating data delivery reduces total cost of ownership for training cycles. Neglecting this network precondition results in agents stalling during complex relationship traversal. Proper configuration ensures the conversational agent interprets graph depth correctly without timing out.
Comparing NoSQL Capabilities and BI Integration Patterns for Enterprise Workloads
Firestore Pipeline Operations vs Bigtable SSD Clusters
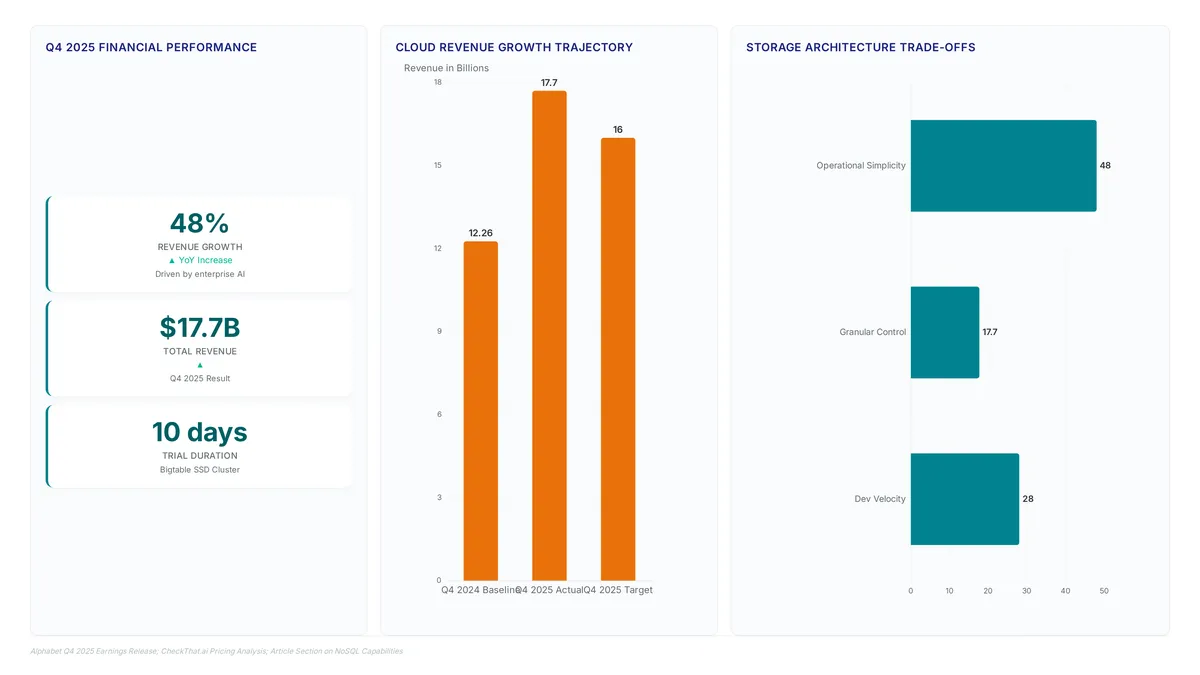
Flexible querying patterns define Firestore pipeline operations, allowing ad-hoc filtering without rigid schema constraints. Bigtable architecture targets high-throughput workloads instead. Performance scales with provisioned resources in Bigtable clusters. Firestore Enterprise removes infrastructure management tasks entirely. Operators choosing between these paths face a distinct trade-off between operational simplicity and granular control over storage tiers. A free trial for Bigtable is available, offering a 10-day trial with a 1 node SSD cluster. Featur sets differ notably based on these fundamental designs.
Deployment strategy follows architectural divergence. Variable user-facing workloads run well on Firestore. Predictable, high-volume ingestion patterns suit Bigtable improved. Migrating legacy key-value stores often requires application-level refactoring to align with modern pipeline configurations. This friction point means teams must weigh immediate development velocity against long-term operational overhead. Selecting the wrong storage primitive early can notably inflate costs as data volumes expand. Matching specific latency requirements to the appropriate storage tier under sustained load presents the real limitation. Engineers must align database selection with specific query patterns rather than general availability claims. Strategic alignment prevents costly re-architecture phases during peak growth periods.
Embedding Conversational Analytics in Looker and Data Studio
Natural language experiences in custom applications emerge from Conversational Analytics capabilities using advanced AI models to interpret data queries. Stakeholder interaction shifts from writing SQL queries to asking direct questions about underlying data models. Notebook environments host these data apps, bridging the gap between raw analytical tables and intuitive visual exploration. Each tool handles the semantic layer differently before generating responses. Managed BI environments often rely on governed semantic models to constrain agent answers. Direct database integration frequently requires custom prompt engineering to achieve similar guardrails.
Embedding these agents introduces a latency dependency on the semantic resolution step before query execution. Strict schema definitions prevent agents from misinterpreting column intent, which leads to inaccurate business insights. Cost implications involve not compute but the engineering hours required to maintain accurate metadata descriptions. Organizations can offload historical logs to reduce the active dataset size these agents scan. This approach optimizes performance by ensuring the conversational layer queries only the, high-value data segments. Reduced flexibility for ad-hoc joins across cold storage tiers is the cost.
Apache Iceberg Lakehouse Tables vs Duplicate Data Pipelines
Maintaining duplicate data pipelines and complex synchronization logic between analytical engines and open-source formats creates unnecessary overhead. Teams previously relied on custom ETL jobs to keep transactional systems aligned with analytical stores, a process prone to latency and failure. Unified table formats enable native multi-engine read/write interoperability. Spark, Trino, and analytical engines can all access the same physical files simultaneously.
Isolated silos offer immediate comfort but create long-term drag through data fragmentation. Legacy approaches provide clear failure boundaries yet introduce significant storage bloat and compute waste during synchronization windows. Operational maturity determines success here. Migrating to a shared format requires strict governance to prevent conflicting writes from corrupting the transaction log. Background tasks like automated compaction and expiration now handle file optimization, removing the need for manual maintenance scripts.
Time-to-insight drops dramatically for AI/ML training data and media streaming workloads under this convergence. Startups avoid building fragile bridges between disparate systems by adopting a single source of truth early. Evaluating the transition cost against the compounding efficiency gains of a unified storage layer remains necessary. Storage intelligence replaces manual data movement in modern architectures.
Implementing Scalable Read Pools and Secure Identity Integration for Cloud SQL
Cloud SQL Autoscaling Read Pools and Single Endpoint Architecture
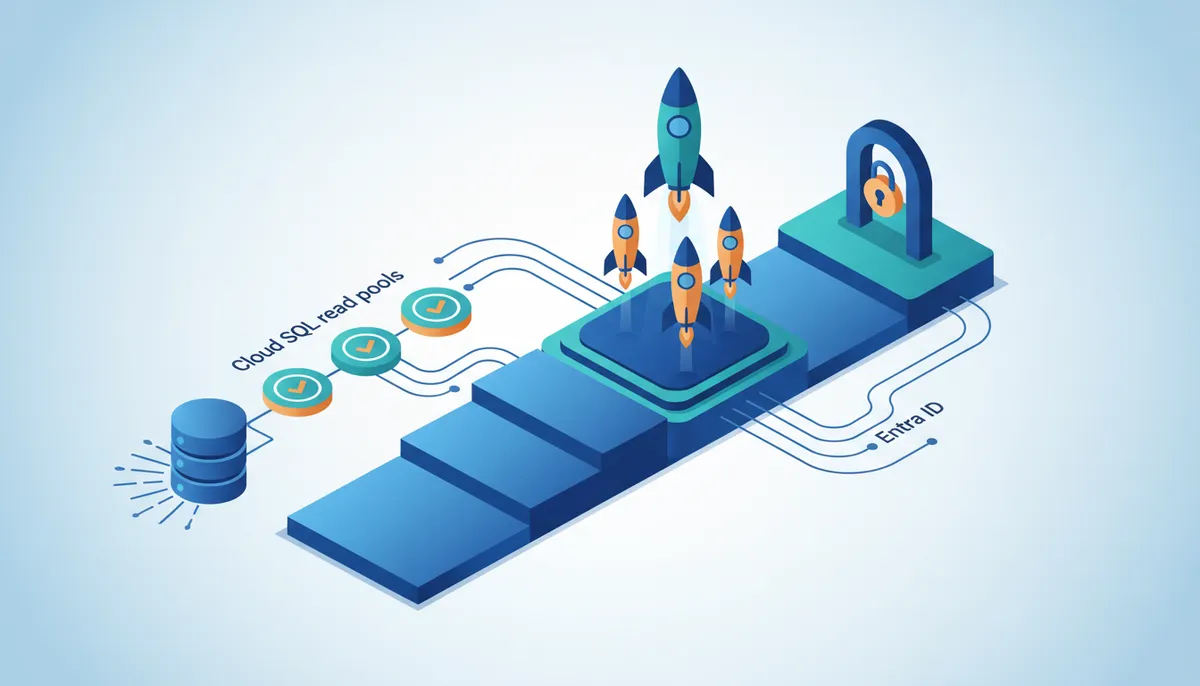
Provisioning multiple read replicas occurs through a single endpoint to eliminate manual scaling intervention. This architecture, highlighted between March 23 and March 27, allows operators to define a target read load while the system dynamically adjusts replica counts. The mechanism relies on a single endpoint that abstracts the underlying pool of read-only instances from the application layer. When traffic spikes, the service automatically provisions additional replicas to maintain latency targets without reconfiguring connection strings.
- Enable the autoscaling feature within the Cloud SQL instance configuration panel.
- Define the minimum and maximum number of read replicas required for your baseline and peak loads.
- Configure the single endpoint DNS record to route application traffic to the managed pool.
- Set performance thresholds that trigger scale-out or scale-in events based on CPU or connection metrics.
The trade-off is that write operations must still target the primary instance, requiring application logic to separate read-write traffic effectively. Unlike static provisioning, this approach prevents over-provisioning during idle periods while ensuring capacity exists for sudden surges. The result is a resilient data layer that adapts to workload variance without constant operator oversight.
Integrating Microsoft Entra ID for Secure Cloud SQL Identity Management
Integrating Microsoft Entra ID with Cloud SQL requires enabling the Azure AD plugin within the instance flags before configuring server-level logins. This process replaces static password authentication with token-based exchanges that validate user identity against centralized directory policies. Operators must map specific Entra ID groups to database roles to enforce least-privilege access without managing individual SQL accounts. The configuration demands precise alignment between cloud identity providers and database permission sets to prevent lockout scenarios during rollout.
- Navigate to the Cloud SQL instance settings and add the `cloudsql_azure_ad_plugin` flag to enable the integration module.
- Create corresponding logins in the master database using the `FROM EXTERNAL PROVIDER` syntax to link SQL identities to Entra objects.
- Assign database roles to these external logins to grant specific data access permissions based on organizational function.
The primary benefit involves enforcing Multi-Factor Authentication at the identity provider level, ensuring that database access inherits corporate security postures automatically. A significant limitation exists where application connection strings must be updated to support Azure AD token acquisition rather than standard password authentication. This shift introduces complexity for legacy applications that lack native support for interactive token flows or managed identity contexts. Consequently, teams often face a trade-off between enhanced security posture and the immediate operational burden of refactoring database clients. While the architecture supports strong governance, the dependency on network connectivity to the identity provider means that directory outages can block legitimate database access entirely. Organizations adopting this model should verify that their critical path applications can handle token refresh cycles gracefully. For those evaluating broader enterprise capabilities, a webinar discusses strategy alignment.
Checklist for Deploying Google-built JDBC and ODBC Drivers in Preview.
Meanwhile, the Google-built JDBC Driver for BigQuery entered Preview from January 12 to January 16, enabling direct Java application connectivity. Operators must validate specific configuration flags to avoid connection timeouts during this preview window. This deployment phase requires rigorous testing of token expiration handling before production reliance.
- Verify the driver version matches the preview release notes for compatibility.
- Configure the connection string to include explicit project ID parameters.
- Test failover scenarios by simulating network interruptions during active queries.
A critical tension exists between using preview drivers for early feature access and maintaining stability in production environments. The limitation is that preview software may lack the backward compatibility guarantees found in general availability releases. Teams should isolate these connections in non-critical paths until general availability is declared.
Rabata.io recommends deploying these drivers within isolated VPC networks to limit blast radius during evaluation. This approach allows teams to benchmark performance gains without exposing core data assets to potential instabilities inherent in preview software.
About
Alex Kumar, a Senior Platform Engineer and Infrastructure Architect at Rabata.io, brings critical expertise to the discussion on Google Data Cloud economics. Specializing in Kubernetes storage architecture and cost optimization, Alex daily manages high-volume data pipelines where egress fees often overshadow base storage costs. His hands-on experience with S3-compatible object storage at Rabata.io directly informs this analysis, as he routinely architects solutions that eliminate vendor lock-in and reduce total cost of ownership for AI/ML workloads. At Rabata.io, a provider focused on transparent pricing and GDPR-compliant data centers, Alex helps enterprises navigate complex cloud billing structures similar to those found in BigQuery and Looker ecosystems. By using his background in infrastructure-as-code and persistent storage, Alex provides an authoritative perspective on how organizations can optimize their AI data bills through strategic storage choices and a clear understanding of data movement costs across hybrid and multi-cloud environments.
Conclusion
Scaling unstructured data workloads reveals that network dependency on identity providers creates a single point of failure, where directory outages immediately sever database access. This architectural fragility demands that teams treat token expiration handling as a primary reliability constraint rather than a secondary configuration detail. While the 10-day trial for Bigtable offers a low-risk entry point, relying on preview JDBC drivers for critical paths introduces unacceptable volatility due to missing backward compatibility guarantees. Organizations must isolate these connections within VPC networks to contain potential blast radius during evaluation.
Adopt a strict policy of deploying preview drivers only in non-production environments until general availability is declared. This separation ensures that early feature access does not compromise core data assets or destabilize active queries. Teams should prioritize testing failover scenarios by simulating network interruptions to validate durability before any broader rollout.
Start this week by configuring your current connection string to include explicit project ID parameters and verifying that your Java applications gracefully handle simulated token refresh cycles. This immediate validation step prevents future access blocks without requiring new infrastructure investments. By focusing on isolation and rigorous testing now, you build a foundation that supports reliable governance while navigating the transition from preview to production readiness.
Frequently Asked Questions
Egress fees dictate the true expense of moving data for AI processing. Companies ignoring this hidden tax face unexpected bills despite low per-gigabyte storage rates. Focus on data movement costs to avoid financial surprises in modern operations.
A semantic layer prevents agents from generating conflicting or unauthorized data views. Without this rigid guardrail, natural language queries risk returning plausible but factually incorrect results to end users. Centralizing logic ensures consistent business reporting across environments.
Operators must define clear boundaries for agent behavior to balance open exploration with governance. Unrestricted access risks inconsistent reporting while tight controls stifle adoption. Mapping prompts to governed semantic models enables safe, embedded natural language experiences.
Enforcing strict typing on source tables prevents agents from misinterpreting data types during query execution. Skipping schema governance leads to critical errors where raw inputs remain untransformed. Structured foundations are required before enabling autonomous agent interaction safely.
BigQuery Graph enables relationship traversal directly within the analytics engine during its preview phase. This architecture allows analysts to query complex connections without external processing. It represents a shift toward integrated graph mechanics for deeper data insights.
References
