Whitelabel storage saves neoclouds 18 months
Backblaze claims B2 Neo cuts storage build time from 24 months to weeks for GPU farms chasing the $35.22 billion neocloud market.
Specialized compute providers cannot afford to become storage companies. The thesis is simple: white label storage lets you skip the distraction of building native object layers and focus entirely on scaling GPU density. As liquid cooling adoption surges to handle thermal loads in direct-to-chip designs, pairing high-end silicon with cheap, disk-based tiers is no longer optional-it's mandatory. Backblaze positions B2 Neo as the fix: an S3-compatible backend integrated via Partner API that stops neoclouds from burning two years of engineering runway.
This architecture decouples storage branding from physical infrastructure. Firms like CoreWeave resell capacity under their own names while AI pipelines benefit from free egress and zero transaction fees. These features prevent the latency stalls that plague massive dataset moves between disjointed systems. When you contrast B2 Neo against hyperscaler pricing models, the math is brutal for anyone paying egress charges on high-throughput workloads.
The Role of White Label Storage in Modern Neocloud Infrastructure
B2 Neo as a White Label S3-Compatible Storage Layer for Neoclouds
Launched 23 Feb 2026, B2 Neo functions as a white-label backend allowing GPU farms to rebrand disk storage instantly. Backblaze targets neocloud platforms like CoreWeave that face an 18-month distraction building custom object stores. Operators expose branded endpoints and set partner-controlled pricing without maintaining a separate console or billing stack.
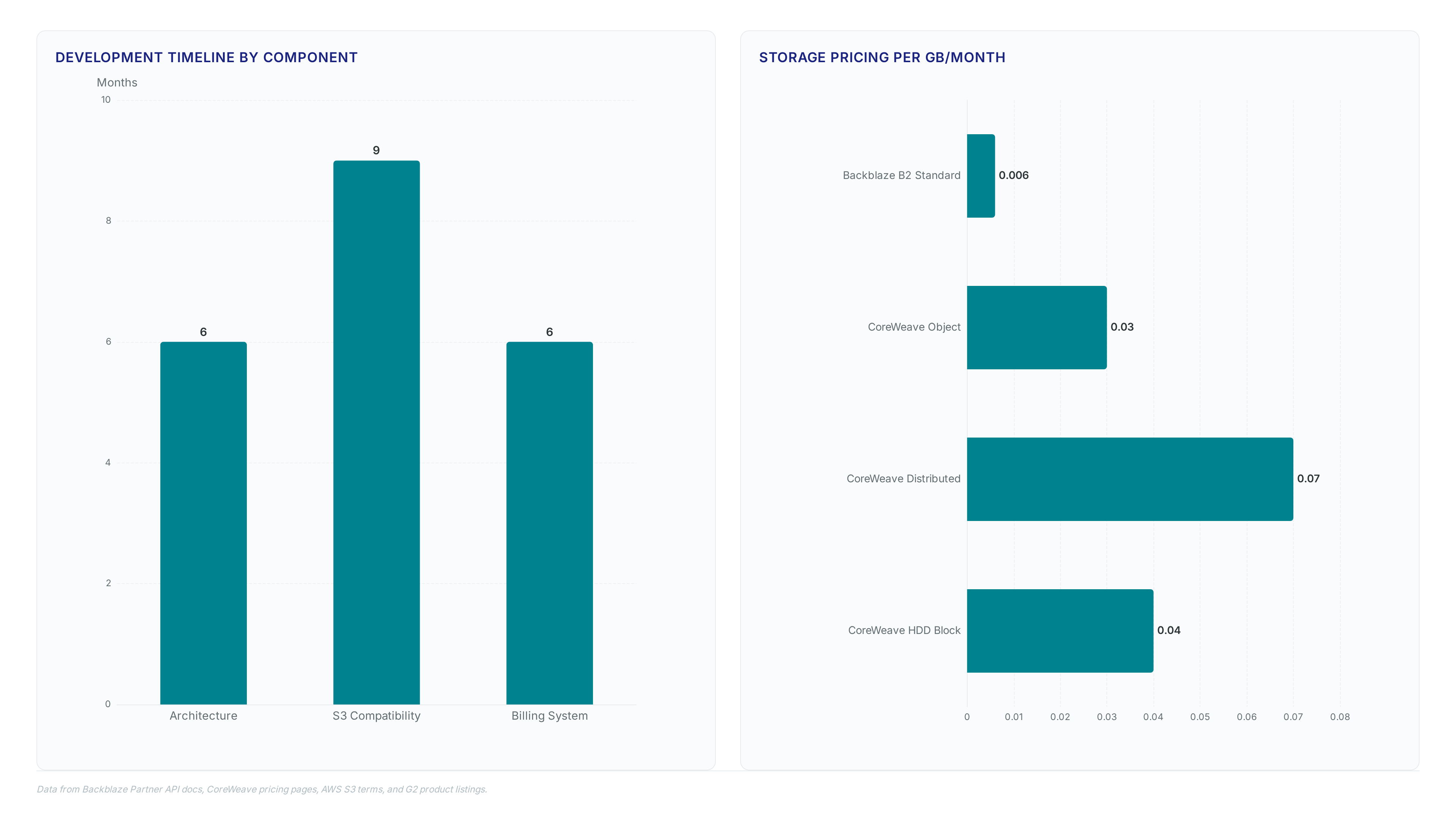
Hyperscaler egress fees destroy margin in AI pipelines where general CSP offerings fail to address specific economic bottlenecks. Competitors charge $0.03/GB for object tiers. The underlying B2 technology operates at $0.006/GB. This gap creates a structural cost advantage for high-volume checkpointing. Decoupling storage engineering from GPU procurement cycles delivers strategic value. A substantial global edge platform selected this backbone to scale AI workloads without capital expenditure on disk arrays.
Surrendering direct visibility into physical disk health metrics is the price of the white-label approach. Operators must rely on the provider's SLA rather than internal telemetry. Speed increases while granular control over replication factors and erasure coding policies disappears.
| Feature | Hyperscaler Native | B2 Neo White-Label |
|---|---|---|
| Time to Launch | 18+ months | Weeks |
| Egress Cost | High | Zero |
| Branding | Vendor Lock-in | Partner Owned |
Neoclouds capture the full integration model revenue stream while avoiding the operational overhead of managing cold storage tiers. Dependency on external API stability for critical data paths remains a constraint. Building minimum viable object storage consumes 18to24 months, diverting engineering resources from GPU cluster expansion. B2 Neo resolves this latency by providing a pre-integrated, white-label backend that neoclouds deploy in weeks. Providers like CoreWeave and Lambda avoid the capital expenditure of constructing disk arrays from scratch. Partners retain full control over branding and pricing while Backblaze manages the underlying infrastructure through an integration model Storage scarcity stalls AI training pipelines and reduces GPU utilization efficiency until this bottleneck clears. Operational burden shifts from hardware maintenance to API orchestration. Neoclouds expose branded endpoints to customers while using a Partner API for provisioning and billing integration. Smaller platforms compete with hyperscalers without matching their R&D spend thanks to the trend toward white-label infrastructure An unnamed global edge platform recently selected this architecture to support scaling AI and HPC strategies after a rigorous technical evaluation.
| Deployment Strategy | Time to Market | Capital Requirement |
|---|---|---|
| Custom Build | 18-to-24 months | High |
| B2 Neo Integration | Weeks | Low |
Relying on a single vendor for the physical storage layer introduces potential supply chain risks. Operators must verify that the S3-compatible interface meets specific throughput requirements for large model checkpoints before migration. Mission and Vision recommends qualifying the backend against existing data movement tools to prevent workflow fragmentation during the transition. Hyperscaler egress taxes consume margin and collapse the financial architecture of AI training clusters. Backblaze eliminates this variable cost through an integration model AWS S3 estimates suggest a 7x multiplier over Wasabi equivalents when factoring in data retrieval. High-churn model checkpoints suffer a structural deficit under such conditions. B2 Neo absorbs these transfer costs. Neoclouds maintain flat pricing regardless of dataset mobility. Dependency on a single upstream vendor for durability guarantees is the limitation. The cost disparity forces a choice between absorbing engineering overhead or accepting third-party backend reliance. High-volume AI workloads generate petabytes of temporary artifacts that vanish after training cycles. Paying premium rates for ephemeral data destroys unit economics. The storage cost advantage allows neoclouds to undercut hyperscalers on total contract value while preserving GPU utilization rates. Mission and Vision recommends evaluating egress profiles before locking into proprietary object stores.
Inside B2 Neo Architecture and Data Flow for AI Pipelines
Branded Endpoints and Partner API Architecture in B2 Neo
Neocloud customers access the storage as a native service through branded endpoints. This architecture decouples the control plane from the data plane, allowing GPU farms to present storage as an internal feature rather than a third-party add-on. The Partner API acts as the orchestration layer, managing provisioning and billing integration without exposing Backblaze infrastructure details to end users.
Security granularity relies on Multi-Bucket Application Keys to restrict tenant access to specific file prefixes. Operators assign these keys during onboarding, ensuring that a single compromised credential cannot traverse the entire dataset. This method enforces strict isolation logic at the API gateway level before any request reaches the disk array.
The operational cost involves surrendering direct visibility into physical drive health metrics. Partners must trust the upstream provider's durability claims while focusing engineering cycles on compute scaling. This separation allows a neocloud to launch services in weeks instead of years, yet it creates a dependency where storage SLAs are only as strong as the partner contract. The OverDrive egress model further complicates capacity planning by tying free transfer limits to monthly storage averages. Operators must monitor these ratios closely to prevent unexpected overage charges when data mobility spikes during model training phases.
Preventing GPU Stalls with 1 Tbitps Throughput and Low-Latency Uploads
1 Tbitps throughput prevents pipeline starvation during massive dataset ingestion for AI training clusters. Storage latency frequently stalls GPU utilization when small file writes block forward progress in distributed training jobs. Q1 2026 testing recorded the lowest average upload time for 256KiB files at 7.08 ms, ensuring rapid checkpoint commits. Larger 5MiB artifacts uploaded in 87.62 ms, sustaining bandwidth without queuing delays that degrade cluster efficiency.
Raw speed cannot compensate for architectural misalignment in the data plane. Operators must configure client-side concurrency to match server capacity, or the OverDrive egress allowance remains underutilized during peak loads. This performance tier transforms storage from a passive archive into an active component of the compute loop. Failure to align upload concurrency with these latency targets results in measurable GPU idle cycles despite available bandwidth. The cost of ignoring these thresholds is reduced return on expensive silicon assets.
OverDrive Free Egress Versus AWS S3 Transfer Limits
OverDrive permits free egress up to 3x the monthly storage average, whereas AWS S3 caps aggregated free transfer at 100GB. AI training pipelines require massive dataset shuffling that instantly exhausts the 100GB hyperscaler allowance, triggering per-gigabyte fees that erode compute margins. The economic impact stems from this structural mismatch: model checkpoint iteration demands terabytes of movement, not gigabytes. Backblaze ties free allowance to stored volume rather than a fixed ceiling, aligning costs with actual AI workload patterns. Operators avoiding this model face a 7x cost multiplier compared to alternative providers when factoring in retrieval charges.
Low-retention workloads storing minimal data receive proportionally small egress buffers despite high churn. High-churn environments must maintain sufficient storage average to maximize the free tier multiplier. This dependency forces architects to balance deletion policies against transfer needs, a constraint absent in fixed-cap models. Neoclouds using unlimited free egress through CDN partners bypass this tension entirely for distribution traffic. Pure compute-focused farms with ephemeral datasets may find the 3x ratio insufficient without deliberate data padding strategies.
B2 Neo Versus Hyperscalers on Cost and Egress Efficiency
Defining the Neocloud Storage Bottleneck in AI Workflows
Constructing a minimum viable object storage platform represents an 18-to-24-month distraction that directly competes with the primary mission of scaling GPU capacity. Neocloud operators facing this timeline often lose market share to hyperscalers while engineering teams struggle to replicate basic S3 compatibility. Storage has emerged as a critical bottleneck in AI pipelines, forcing providers to choose between delayed launches or expensive interim solutions. The market opportunity remains massive, with projections indicating growth from $35.22 billion in 2026 to $236.53 billion by 2031 for the neocloud.
| Dimension | In-House Development | B2 Neo Integration |
|---|---|---|
| Time to Market | 18 to 24 months | Weeks |
| Engineering Focus | Storage maintenance | GPU scaling |
| Cost Structure | High CAPEX + OPEX | Variable operational cost |
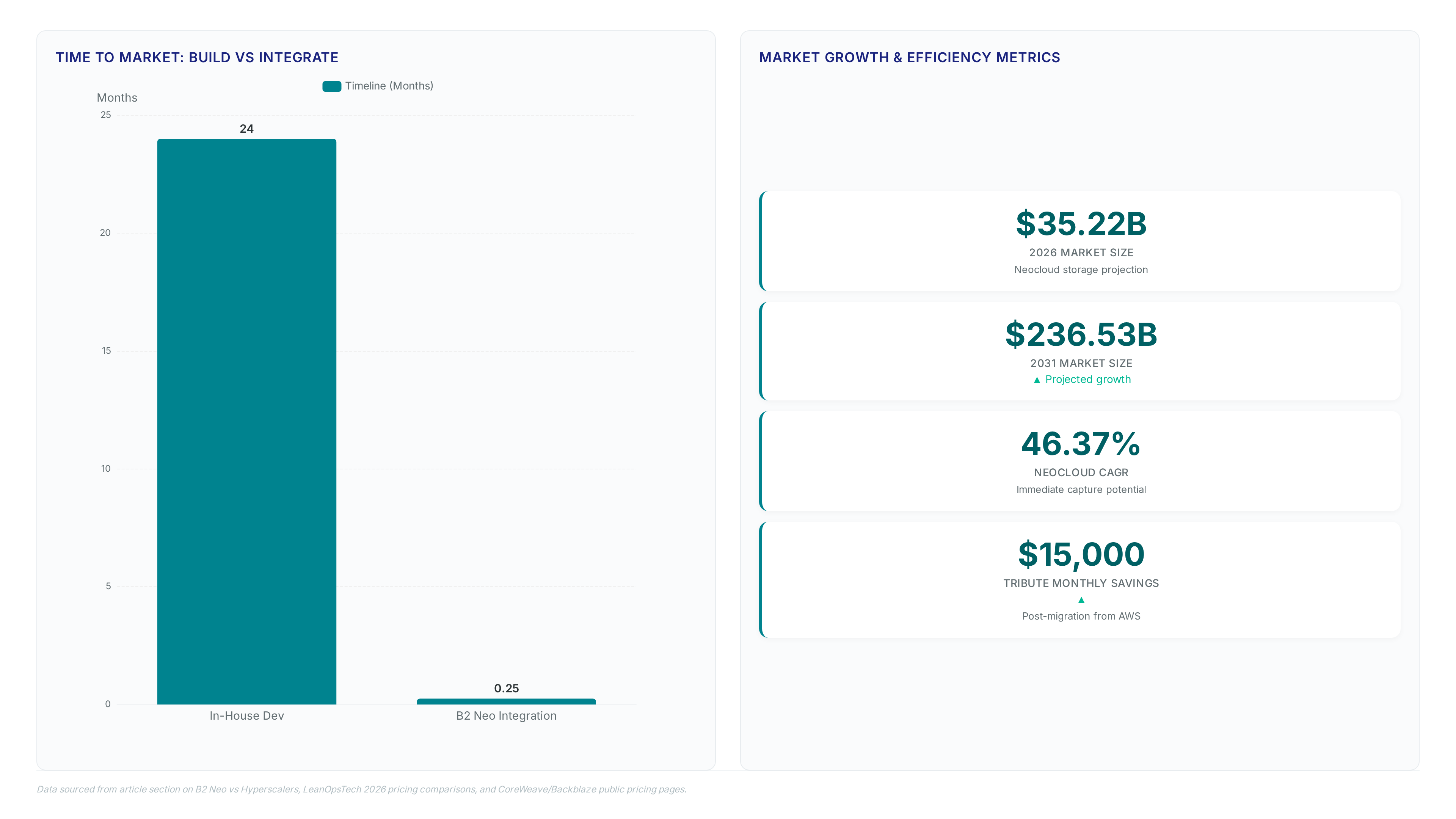
Operators attempting internal builds frequently underestimate the complexity of maintaining durability guarantees alongside high-throughput requirements. This diversion of talent slows the deployment of new GPU clusters, effectively capping revenue potential during periods of explosive demand. A global edge platform. The limitation of white-label solutions lies in reduced visibility into the underlying disk firmware, though this drawback rarely impacts logical performance metrics. Immediate availability allows neoclouds to capture the projected 46.37 percent CAGR without delaying core compute services. Tribute cut monthly expenses by $15,000 after migrating video workflows from AWS S3 to Backblaze B2. This reduction stems from eliminating egress charges that hyperscalers levy on data leaving their networks. Operators enable free egress by configuring OverDrive, which permits outbound traffic up to three times the stored volume without fees. The Tribute migration relied on existing ingest systems and a CDN integration to maintain zero downtime during the switch. Hyperscaler pricing models often obscure total cost of ownership until large-scale data retrieval triggers unexpected bills.
| Cost Factor | Hyperscaler Model | B2 Neo Model |
|---|---|---|
| Egress Allowance | 100GB aggregated cap | 3x storage average |
| Transaction Fees | Per-request charges | Zero fees |
| Price Variance | ~7x higher total cost | Baseline efficiency |
Independent analysis suggests AWS S3 costs are nearly 7x higher than alternative providers for identical workloads when including transfer fees. The constraint of this approach involves dependency on the partner's API for billing abstraction rather than direct carrier relationships. Large customer ARR grew significantly year-over-year in Q1 2026, indicating strong market adoption of decoupled storage architectures. Network engineers must calculate break-even points where saved egress costs outweigh any potential latency introduced by indirect routing. The financial benefit remains clear for data-intensive pipelines that move terabytes daily. This differential fundamentally alters total cost of ownership for AI datasets exceeding petabyte scale.
Launching a Branded Storage Service in Weeks Not Years
Application: B2 Neo Partner API Architecture for White-Label Billing
The Partner API provisions buckets and enforces billing logic through Multi-Bucket Application Keys without exposing backend infrastructure. Neocloud operators invoke API version v4 to generate credentials restricted to specific bucket IDs, isolating tenant data while presenting a unified branded endpoint. This architectural choice prevents cross-tenant leakage at the authentication layer rather than relying on network segmentation alone. Backblaze documentation details how API version v4 handles these granular permissions for multi-tenancy. A global edge services platform
| Control Layer | Standard S3 Key | Neo Partner Key |
|---|---|---|
| Scope | Single Bucket | Multiple Buckets |
| Branding | Vendor Console | Partner Endpoint |
| Billing | Direct Charge | Aggregated Invoice |
Operators avoid the 18-to-24-month distraction of building custom storage by delegating disk management to Backblaze while retaining control over partner-controlled pricing. The limitation involves strict adherence to the white-label boundary; any direct customer access to native Backblaze consoles breaks the service abstraction. This constraint forces neoclouds to build their own user interfaces for account management. The implication is a clear division of labor: the provider owns the storage plane, while the neocloud owns the presentation and billing planes. Mission and Vision recommends integrating these APIs immediately to capture market share before hyperscalers adjust their egress models.
Executing the Weeks-Not-Years Deployment Strategy for GPU Farms
Integrating the Partner API bypasses the 18-to-24-month build cycle by enabling white-label storage provisioning in weeks rather than years. Operators configure Multi-Bucket Application Keys to isolate tenant data while presenting a unified branded endpoint, preventing cross-tenant leakage at the authentication layer. Without this integration, moving massive datasets causes latency that stalls GPU utilization and inflates operational expenses. The mechanism relies on OverDrive egress policies to eliminate transfer fees that typically cripple AI training pipelines during checkpoint retrieval. However, the cost advantage depends on selecting the correct storage tier for the workload intensity. CoreWeave lists distributed file storage at $0.070/GB/month for high-performance needs, whereas standard object tiers sit lower. Motion achieved a 70% reduction in cloud storage costs by shifting to this model, validating the economic thesis for bulk dataset retention.
| Deployment Phase | Custom Build Timeline | B2 Neo Integration |
|---|---|---|
| Architecture Design | 6 months | 1 week |
| S3 Compatibility | 9 months | Native |
| Billing System | 6 months | API Automated |
The limitation remains that high-frequency random access workloads may still require local NVMe caching before hitting the object layer. Performance benchmarks show average upload times of 87.62 ms for 5MiB files, which suits checkpointing but not real-time inference shuffling. Operators must architect their data pipelines to buffer writes locally before asynchronous flushes to the backend. This approach prevents the storage subsystem from becoming the throttle point for the 2.7 million GPUs projected for 2026 deployment.
Validation Checklist for S3-Compatible Storage Integration
Confirming 1 Tbitps throughput capacity prevents AI pipeline stalls during massive dataset ingestion. Operators must verify that backend links sustain this bandwidth before branding the service for production GPU farms. A failure here creates a bottleneck that nullifies the compute investment regardless of storage cost savings. The white-label model allows operators to capture this spread without building physical infrastructure. However, relying on free egress alone fails if the storage tier cannot match the read intensity of inference workloads. Market data indicates a significant growth trajectory for cloud storage, suggesting demand will outpace supply for slow disks. The limitation remains that performance tuning becomes the operator's responsibility once the white-label layer is active. Mission and Vision recommends validating disk IOPS separately from network throughput to ensure consistent low-latency access.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the evolving environment of B2 Neo cloud storage. His daily work designing Kubernetes storage architectures and optimizing costs for cloud-native applications directly aligns with the challenges GPU server farms face when integrating scalable, S3-compatible layers. Having previously served as an SRE for high-traffic platforms, Kumar understands the critical need for disaster recovery and predictable pricing without hidden egress fees. At Rabata. Io, a specialized provider of S3-compatible object storage for AI and ML startups, he engineers solutions that eliminate vendor lock-in while delivering superior performance. This practical experience makes him uniquely qualified to analyze how services like Backblaze's B2 Neo empower neoclouds. His insights bridge the gap between theoretical infrastructure design and the real-world demands of GPU-intensive workloads, offering a grounded perspective on cost-effective storage strategies for modern compute providers.
Conclusion
Scaling AI infrastructure reveals that thermal density, not just storage cost, becomes the primary constraint as GPU clusters expand. Liquid cooling adoption is accelerating, yet many operators still underestimate how heat management impacts adjacent storage networking gear. If your facility relies on legacy air-cooled designs, the projected 2026 GPU surge will force premature hardware refreshes that erase any margin gained from cheap object tiers. The structural advantage of B2 Neo only holds if the surrounding physical plant supports sustained high-throughput without thermal throttling.
Deploy white-label storage immediately only if your data center roadmap includes direct-to-chip cooling upgrades within the next six months. Do not commit to long-term contracts for facilities stuck in air-cooled architectures, as their capacity to handle 1 Tbitps aggregates will degrade rapidly under load. The window to align physical infrastructure with logical storage economics closes before late 2025.
Start by auditing your current server room's cooling capacity against the thermal output of your planned GPU density this week. Compare these figures against the manufacturer specifications for direct-to-chip retrofitting to determine if your site can sustain the required throughput without creating a new bottleneck.
Frequently Asked Questions
B2 Neo operates at just $0.006 per GB for underlying storage technology. Competitors like CoreWeave charge significantly higher rates of $0.03 per GB for their standard object storage tiers.
The service supports up to 1 Tb of throughput to prevent pipeline starvation during massive data transfers. This high bandwidth ensures rapid checkpoint commits without queuing delays for large artifacts.
Providers can launch a branded storage service in weeks instead of waiting years. Building a custom minimum viable object storage solution typically consumes eighteen to twenty-four months of engineering time.
Hyperscalers charge high egress fees that destroy margins, whereas B2 Neo offers zero transaction fees. Competitors often charge $0.03 per GB, creating a structural cost disadvantage for high-volume AI workloads.
The neocloud market is expanding rapidly from $35.22 billion currently toward $236.53 billion by 2031. This explosive growth forces GPU farms to bypass storage construction distractions to scale faster.
