Snowflake catalog federation cuts AWS costs now
Over 20,488 companies using Snowflake now bypass traditional ETL pipelines to access federated data directly. Catalog federation eliminates the architectural tax of data duplication by shifting the industry standard from Extract-Change-Load to load-first ELT patterns. This integration between AWS Glue and Snowflake Horizon proves that modern cloud compute renders stale data movement strategies obsolete.
You will learn how this architecture uses Apache Iceberg formats over REST endpoints to unify governance without copying bytes. The guide details the specific mechanics of connecting AWS Glue Data Catalog to external sources, a capability only expanded to remote catalogs in November 2025. We dissect the configuration of fine-grained access controls via AWS Lake Formation, ensuring security policies persist across platform boundaries.
Finally, the walkthrough demonstrates executing queries on federated tables using Amazon Athena to validate real-time cross-platform analytics. This approach targets operational efficiency by stripping away redundant storage costs and complex synchronization jobs. By adopting this single point of entry, organizations enforce consistent compliance management while accelerating time to insight. The era of siloed warehouses is ending; the future belongs to those who federate rather than migrate.
The Role of Catalog Federation in Modern Cross-Platform Data Governance
Defining Catalog Federation via AWS Glue and Snowflake Horizon
Catalog federation arrived in November 2025 as a REST-based pattern linking the AWS Glue Data Catalog to remote Apache Iceberg repositories without copying data. This architecture treats external metadata stores as native sources so analytics engines resolve table schemas and locations on demand. The Snowflake Horizon Catalog acts as one such remote endpoint by exposing Iceberg tables through standard REST interfaces for cross-platform discovery. Teams query governed datasets directly to skip extract-change-load pipelines that bloat storage bills.
Security and consistency depend on three distinct technical components:
- Authentication flows use OAuth2 credentials from the source principal.
- AWS Lake Formation enforces fine-grained access policies on federated resources.
- Query engines like Amazon Athena retrieve metadata objects via scoped AWS Lambda invocations.
Read operations remain the sole capability within the current integration. Write-back actions to the remote catalog from inside the AWS console are impossible under this model. Organizations must keep separate write paths for data ingestion which complicates bi-directional synchronization work. The January 2026 publication details successful connectivity yet latency grows with network distance between the compute engine and the remote REST endpoint. Metadata retrieval timeouts can stall query planning so client applications need strong retry logic. Storage duplication disappears but network dependency risks appear for every schema resolution event.
Fine-grained access control limits data visibility to specific rows or columns using AWS Lake Formation policies instead of broad database roles. Federated queries against Snowflake Horizon Catalog demand strict perimeter enforcement without moving data. AWS Lake Formation manages these permissions by vending scoped credentials that invoke an AWS Lambda function to retrieve metadata objects securely. Authentication uses the OAuth2 credentials of a Snowflake principal to ensure identity propagation across platforms. Regulatory compliance requiring column-level masking across hybrid environments justifies this architecture. The AWS Glue Data Catalog supports such federated connections Network traffic moves over standard HTTPS connectivity and can sit inside an Amazon VPC for firewall traversal. Query latency rises as policy granularity deepens because inspection rules increase metadata resolution time. Snowflake Open Catalog becomes the preferred target when teams want a managed Apache Polaris service outside their primary compute cluster. Centralizing governance here removes duplicate policy definitions yet creates a single point of configuration failure.
Snowflake Horizon Catalog vs Snowflake Open Catalog and Apache Polaris
Snowflake Horizon Catalog functions as an internal metadata store while Snowflake Open Catalog delivers a managed instance of the open-source Apache Polaris project. Choices between these options reveal a distinct architectural divergence regarding long-term portability and vendor lock-in. Snowflake Horizon Catalog implements open APIs and offers a direct migration path to the open-source Apache Polaris standard to ensure future interoperability independent of the platform. Competing solutions like Databricks Unity Catalog lack a similar migration path to an open-source catalog which creates a potential dead-end for organizations prioritizing exit strategies. The AWS Glue Data Catalog supports federated connections to both internal Snowflake Horizon instances and external Apache Polaris registries to enable query access without data duplication across these varied topologies. Teams synchronize with Apache Iceberg objects managed by various REST catalogs while maintaining a single governance plane.
| Feature | Snowflake Horizon Catalog | Snowflake Open Catalog |
|---|---|---|
| Hosting Model | Internal to Snowflake | Managed Service |
| Underlying Engine | Proprietary Implementation | Apache Polaris |
| Migration Path | To open-source Polaris | N/A (Already Open) |
| Interoperability | High via REST APIs | Native Standard Compliance |
Control versus convenience drives the strategic implication. Deploying Snowflake Open Catalog removes the abstraction layer and grants direct ownership of the Apache Polaris instance for teams requiring maximum transparency. Sticking with internal Snowflake Horizon simplifies initial setup at the cost of relying on Snowflake-managed interfaces for external engine access. Organizations must weigh the operational overhead of managing an open-source catalog against the flexibility of a fully portable metadata layer.
Inside the Architecture of AWS Glue and Snowflake Horizon Integration
Snowflake PAT Authentication Mechanics for Glue Federation
Programmatic Access Token (PAT) flows skip interactive browser redirects to provide AWS Glue with static credentials for remote catalog access. Snowflake supports three distinct mechanisms: External OAuth, Key-pair authentication, and PAT, yet only the latter two function as custom authentication methods for this specific federation. Operators often conflate OAuth with PAT, but the distinction dictates whether the integration relies on flexible user delegation or fixed service principal identity. The PAT method generates a bearer token via a direct API call to the Snowflake endpoint, embedding the scope and role directly into the request header.
| Mechanism | Type | Refresh Logic |
|---|---|---|
| External OAuth | Delegated | Flexible user session |
| Key-pair | Cryptographic | Signed JWT exchange |
| PAT | Static | Manual rotation |
This approach enables bi-directional interoperability while maintaining a simpler configuration profile than full OAuth exchanges. Operational risk increases because static tokens do not expire automatically. Manual rotation schedules prevent credential leakage. Flexible OAuth flows terminate upon user logout, whereas a compromised PAT grants persistent access until explicitly revoked. Teams must implement external secret management to store these tokens securely. The AWS Glue Data Catalog Failure to rotate the PAT invalidates the federated link immediately. Cross-platform queries halt.
Configuring S3 External Volumes for Snowflake Iceberg Tables
Creating an external volume pointing to the specific S3 bucket establishes the storage foundation required for Snowflake-managed Iceberg tables. This mechanical step binds the logical database object to physical object storage so metadata resolution functions correctly during federation. Operators must execute this before defining schemas. The Iceberg specification mandates explicit volume references for table creation. The process involves four distinct actions: creating the external volume, provisioning a database, generating a schema within that database, and assigning ownership privileges.
| Step | Object Type | Purpose |
|---|---|---|
| 1 | External Volume | Maps S3 bucket path for data files |
| 2 | Database | Logical container for table organization |
| 3 | Schema | Namespace for individual Iceberg tables |
| 4 | Iceberg Table | Final asset linked to external volume |
Snowflake announced increased interoperability with Catalog-Linked Databases at Snowflake Summit 2025, allowing synchronization with Apache Iceberg objects managed by various REST catalogs. This update permits the external volume to serve as a shared resource across multiple compute clusters without data copying. The external volume configuration locks the table to a single AWS region. Cross-region failover requires manual volume recreation rather than automatic redirection. Architects choose between low-latency local access and complex multi-region governance strategies. AWS Glue Data Catalog supports federated connections When a user queries these federated tables, AWS Lake Formation vends scoped credentials that invoke an AWS Lambda Mission and Vision recommends validating S3 bucket policies for cross-account access prior to volume creation to prevent silent authentication failures during initial connectivity tests.
Validating Snowflake Roles for External Engine Access
Creating a dedicated Snowflake role for external engine access prevents authentication failures by isolating federation permissions from user accounts. Operators must verify this principal exists before generating tokens. Missing roles trigger immediate rejections during the AWS Glue Data Catalog The validation process requires five specific checks to ensure governance boundaries hold.
- Confirm the role possesses USAGE privileges on the target database and schema.
- Verify SELECT permissions apply strictly to the intended Iceberg tables.
- Ensure no broader account-level roles are granted to this service principal.
- Test connectivity using a sample token before production deployment.
Skipping step three exposes the entire catalog to unauthorized queries. Risk increases when bi-directional interoperability features are active. External engine principals cannot inherit permissions dynamically unlike standard user roles. Explicit grants for every new object become necessary. This rigidity prevents privilege escalation but increases operational overhead during schema evolution. A misconfigured role often manifests as a silent token generation success followed by immediate access denial. Confusion arises when operators assume credential validity equals data access. The published January 2026 guidance Mission and Vision recommend auditing these roles quarterly to detect permission drift.
Step-by-Step Implementation of Glue Catalog Federation with Snowflake
IAM Role Requirements for AWS Lake Formation Data Lake Administrators

Registering Amazon S3 locations demands an IAM principal assigned as a Lake Formation data lake administrator. This specific identity possesses the exclusive capability to register storage paths, access the Data Catalog, grant permissions to other users, and view AWS CloudTrail logs. Standard IAM roles lack these elevated privileges, causing immediate federation failures if operators attempt to use them for catalog registration. The required role must explicitly include access to AWS IAM, AWS Secrets Manager, Amazon VPC, AWS Glue, AWS Lake Formation, Amazon Athena, and AWS KMS.
Network isolation configurations require specific VPC permissions within this same role definition. Federated catalogs apply standard HTTPS connectivity, yet optional support for Amazon VPC remains necessary for strict network isolation and firewall traversal. Without these specific network permissions, the Glue Connection cannot reach remote Iceberg catalogs even with valid credentials.
- Assign the Lake Formation data lake administrator status to the principal.
- Attach policies granting access to AWS Secrets Manager for token retrieval.
- Enable AWS KMS decryption rights for metadata encryption handling.
- Configure Amazon VPC permissions to allow private endpoint resolution.
The cost implication involves the AWS Glue Data Catalog pricing tier, which allows storage of the first 1 million metadata objects for free. Subsequent objects incur charges of $1.00 per 100,000 objects, making precise permission scoping a financial necessity alongside a security.
Executing AWS CLI Commands to Store Snowflake Horizon Bearer Tokens
Operators must execute the `aws secretsmanager create-secret` command with the specific JSON key `BEARER_TOKEN` to enable catalog federation. This step binds the logical access credential to the physical secret store, preventing the Glue connector from failing during the initial REST handshake with the remote Iceberg endpoint. The mechanism requires exact syntax adherence, as malformed JSON strings trigger immediate `InvalidParameter` exceptions that halt the federation setup process.
- Replace `your-access-token` with the Programmatic Access Token generated in the previous Snowflake configuration step.
- Substitute `your-region` with the specific AWS region hosting the target Glue Data Catalog.
- Verify the IAM principal holds `secretsmanager:CreateSecret` permissions before execution to avoid authorization denials.
The limitation of this approach lies in the static nature of the stored token; unlike flexible OAuth flows, a Programmatic Access Token does not auto-rotate, forcing operators to implement external monitoring for expiration dates. This creates a tension between operational simplicity and security hygiene, as manual rotation introduces windows of vulnerability if the token expires during peak query loads. Successful storage enables the Glue service to retrieve credentials securely, establishing the trust anchor required for Snowflake Horizon Catalog Failure to encrypt this secret using AWS KMS leaves the bearer token visible in plaintext to any principal with read access, violating standard data governance policies.
Sequential Workflow for Creating Snowflake-Managed Iceberg Tables on S3
Operators must create an external volume pointing to Amazon S3 before defining any database or schema objects. This strict ordering prevents metadata resolution failures because the Iceberg specification mandates explicit storage binding prior to logical object creation. The workflow proceeds through four mandatory stages to establish a valid catalog federation
- Provision the external volume targeting the specific bucket path.
- Instantiate the database container within the Snowflake environment.
- Generate a schema inside that database to hold table definitions.
- Execute the table creation command referencing the pre-built volume.
Skipping step one causes immediate rejection during the metadata retrieval phase, as the remote endpoint cannot resolve physical locations for logical identifiers. This dependency creates a rigid deployment constraint where schema design cannot precede storage configuration.
| Order | Action | Critical Dependency |
|---|---|---|
| 1 | Create External Volume | None |
| 2 | Create Database | Volume Existence |
| 3 | Create Schema | Database Existence |
| 4 | Create Iceberg Table | Schema and Volume |
Mission and Vision recommends validating volume paths against Iceberg table metadata limits before proceeding to avoid silent truncation errors.
Measurable ROI and Strategic Value from Federated Data Access
Operational Efficiency Metrics in Federated Data Access
Catalog federation eliminates Extract Change Load workloads by enabling direct queries across AWS and Snowflake environments without data duplication. This architectural shift replaces traditional batch movement with an ELT model where transformation occurs inside the warehouse after loading. Operators measure success through reduced storage consumption and quicker time-to-insight rather than pipeline throughput counts. Amazon. Querying data across these platforms improves decision-making speed because analysts access fresh records immediately upon commit.
Network latency and remote catalog availability create new dependencies when physical data copies disappear. Failed REST handshakes due to token expiration halt entire analytical jobs until credentials rotate. Snowflake Horizon Catalog provides bi-directional interoperability for AI workloads, yet AWS Glue focuses strictly on federated read access via the Iceberg REST standard. Write operations still require native Snowflake sessions, limiting full ELT flexibility for some use cases. Organizations targeting cost optimization must balance reduced storage bills against potential compute overhead from cross-region queries.
| Metric | Traditional ETL | Federated Access |
|---|---|---|
| Data Movement | High (Full Copy) | None |
| Storage Cost | Duplicate | Single Source |
| Latency | Batch Delay | Real-time |
| Governance | Siloed | Unified |
Mission and Vision recommends auditing crawler frequency to avoid unnecessary charges while maintaining metadata freshness.
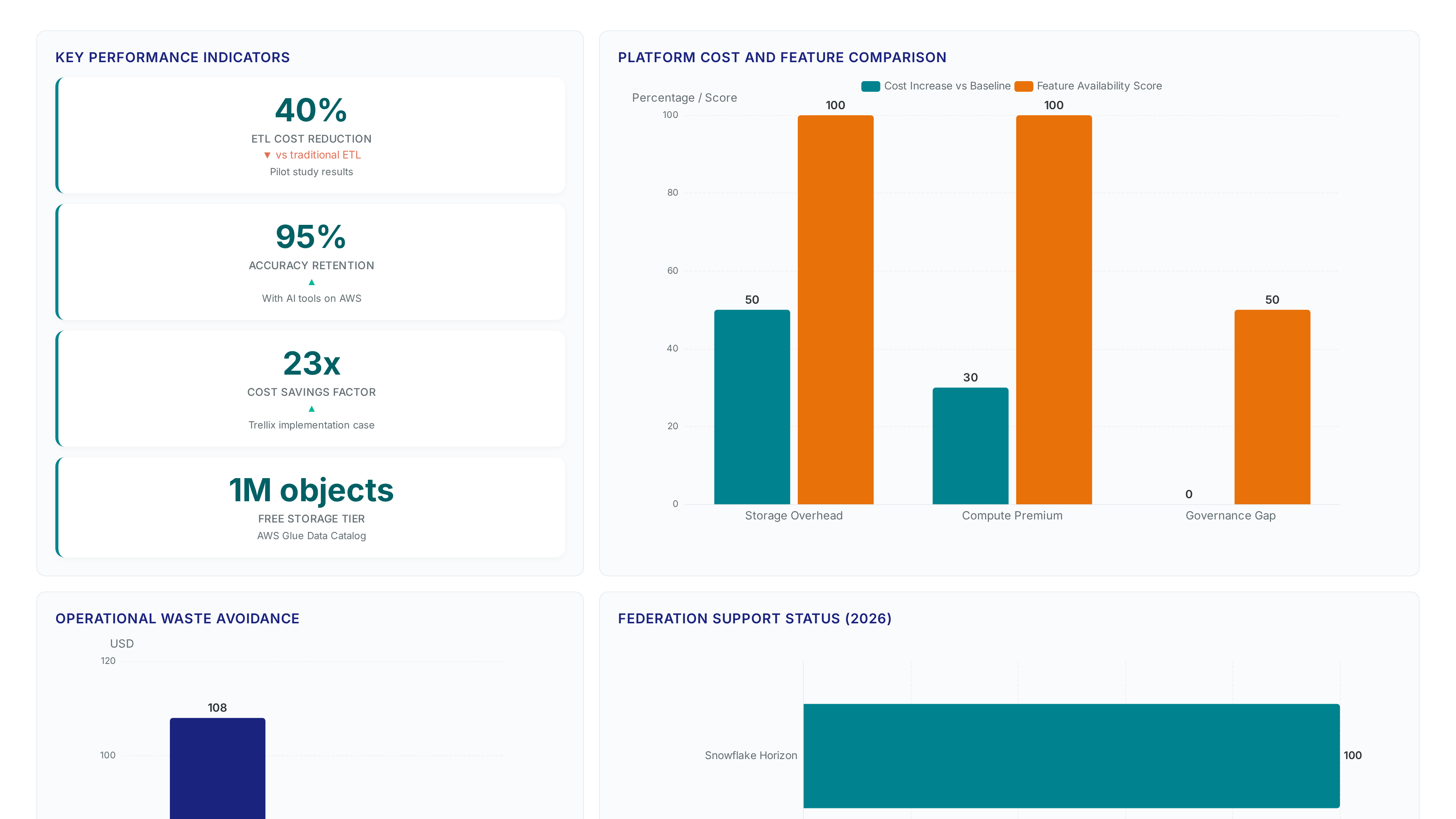
Trellix and Illumina Cost Reduction Case Studies
Trellix achieved 23x cost savings while maintaining 95% accuracy by implementing AI tools on AWS. Federated access to Apache Iceberg tables eliminates the storage overhead traditionally required for cross-platform analytics. The organization saved thousands of hours of manual effort by removing data duplication steps inherent in legacy ETL pipelines. Illumina utilized AWS to globally scale DNA sequencing technologies, successfully driving down costs by a factor of 100X. Such massive reduction factors rely on direct query access rather than moving petabytes of genomic data between environments. Operators executing Athena queries on Snowflake data avoid the modest monthly waste associated with unnecessary crawler frequency.
Immediate query latency competes against long-term storage expenditure in these architectures. Direct federation introduces slight network overhead compared to local materialization, yet the elimination of redundant copies yields superior total cost of ownership. Most large-scale deployments prioritize storage efficiency over marginal latency gains when handling immutable historical datasets.
| Organization | Primary Gain | Operational Shift |
|---|---|---|
| Trellix | 23x cost reduction | Manual effort elimination |
| Illumina | 100X cost factor | Global scaling capability |
Mission and Vision recommends validating fine-grained permissions before enabling broad catalog federation access. Security teams must verify that AWS Lake Formation policies correctly propagate to the remote Iceberg endpoint to prevent unauthorized data exposure. The architectural benefit remains clear: governed cross-platform analytics proceed without duplicating sensitive records.
Strategic Validation Steps for Snowflake Horizon Catalog Adoption
Validate the REST endpoint connectivity before attempting Athena queries on Snowflake data to prevent immediate handshake failures. Operators must confirm that the Apache Iceberg specification compliance extends to bi-directional interoperability rather than simple read-only access. This distinction dictates whether downstream analytics can push predicates or merely scan full partitions.
| Validation Step | Critical Configuration | Failure Mode |
|---|---|---|
| OAuth2 Token Binding | Secrets Manager BEARER_TOKEN | InvalidParameter exception |
| Lake Formation Grants | IAM Principal ARN mapping | AccessDenied on S3 GetObject |
| Volume Registration | External S3 path prefix | Metadata resolution timeout |
Market context supports this architectural shift, as AWS revenue growth Relying solely on fine-grained permissions without testing cross-account role assumption creates a hidden governance gap. Most deployments stall because teams skip verifying the external volume pointer against actual bucket policies. A successful proof-of-concept requires toggling between Snowflake Horizon Catalog and native Glue tables to measure latency variance. Neglecting this step leaves organizations unable to distinguish network bottlenecks from catalog serialization delays.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to the discussion on catalog federation. While the article details AWS and Snowflake integration, Kumar's daily work designing S3-compatible storage solutions for AI/ML startups provides a critical infrastructure perspective. At Rabata. Io, a provider focused on eliminating vendor lock-in and delivering high-performance object storage, he understands how federated catalogs rely on underlying storage interoperability and efficient data access patterns. His background in disaster recovery and cloud-native applications ensures a practical understanding of how unified data discovery impacts enterprise scalability. By connecting theoretical federation capabilities with real-world storage infrastructure challenges, Kumar highlights why open standards and transparent pricing models are necessary for organizations adopting multi-cloud data strategies without compromising performance or budget.
Conclusion
Scaling catalog federation reveals that metadata serialization latency often outweighs storage savings once object counts exceed specific thresholds, turning initial efficiency gains into operational drag. The industry-wide pivot from ETL to ELT architectures demands that teams treat the catalog not as a static inventory but as a flexible compute layer where every unoptimized query directly inflates warehouse credit consumption. You must implement predicate pushdown validation within the next quarter to ensure your federation layer actually filters data before ingestion rather than scanning full partitions. Relying on default configurations without measuring bi-directional interoperability will inevitably cause governance gaps as cross-account role assumptions multiply. Start by auditing your external volume pointers against actual bucket policies this week to identify any mismatches that could trigger silent AccessDenied errors during peak load. This specific check prevents the common failure mode where metadata resolves correctly but data retrieval stalls due to misaligned IAM principal mappings. Only after confirming these fundamental permissions should you expand access to broader analytical groups, ensuring that governed cross-platform analytics remain performant rather than becoming a bottleneck for downstream decision-making.
Frequently Asked Questions
Storage costs one dollar per every one hundred thousand objects after the first million. Subsequent objects incur charges of $1.00 per 100,000 objects, making precise permission management essential for budget control.
Teams avoid one hundred eight dollars in monthly waste by skipping unnecessary crawl operations. Athena queries on Snowflake data avoid the $108 per month waste associated with unnecessary crawl jobs in federated architectures.
Organizations achieved twenty-three times cost savings while maintaining high accuracy levels. Teams received 23x cost savings while maintaining 95% accuracy by implementing AI tools on AWS alongside their federated data strategies.
Premium tiers typically cost thirty to fifty percent more per database unit than standard options. Databricks Premium tier, which includes Unity Catalog, typically costs 30-50% more per DBU compared to the Standard tier.
Teams routinely pay three to four times more than necessary for identical workloads. Teams running production pipelines on Databricks All-Purpose clusters instead of Jobs Compute are routinely paying 3 to 4 times more.
