Object storage solves 2 Gbps transfer limits
Moving 130 TB of Pi digits required a steady 2 Gbps throughput over two weeks to reach Backblaze B2 Cloud Storage.
Hybrid cloud workflows are no longer optional; they are the only viable strategy for preserving massive computational artifacts. Local labs possess the raw CPU cores and DDR5 memory to generate data, but hosting petabyte-scale results indefinitely destroys economic viability. Relying solely on on-premises storage creates bottlenecks that strangle distribution. Object storage platforms provide the durability and egress capacity serious scientific dissemination demands.
StorageReview offloaded 628 distinct files only after exhausting local Micron 6550 Ion SSDs. The operational shift from local computation on AMD EPYC 9965 processors to permanent cloud residency proves cloud-based storage is the logical endpoint for modern record-breaking datasets.
The Role of Object Storage in Modern Large-Scale Data Preservation
Object Storage Durability and the 130 TB Pi Dataset Scale
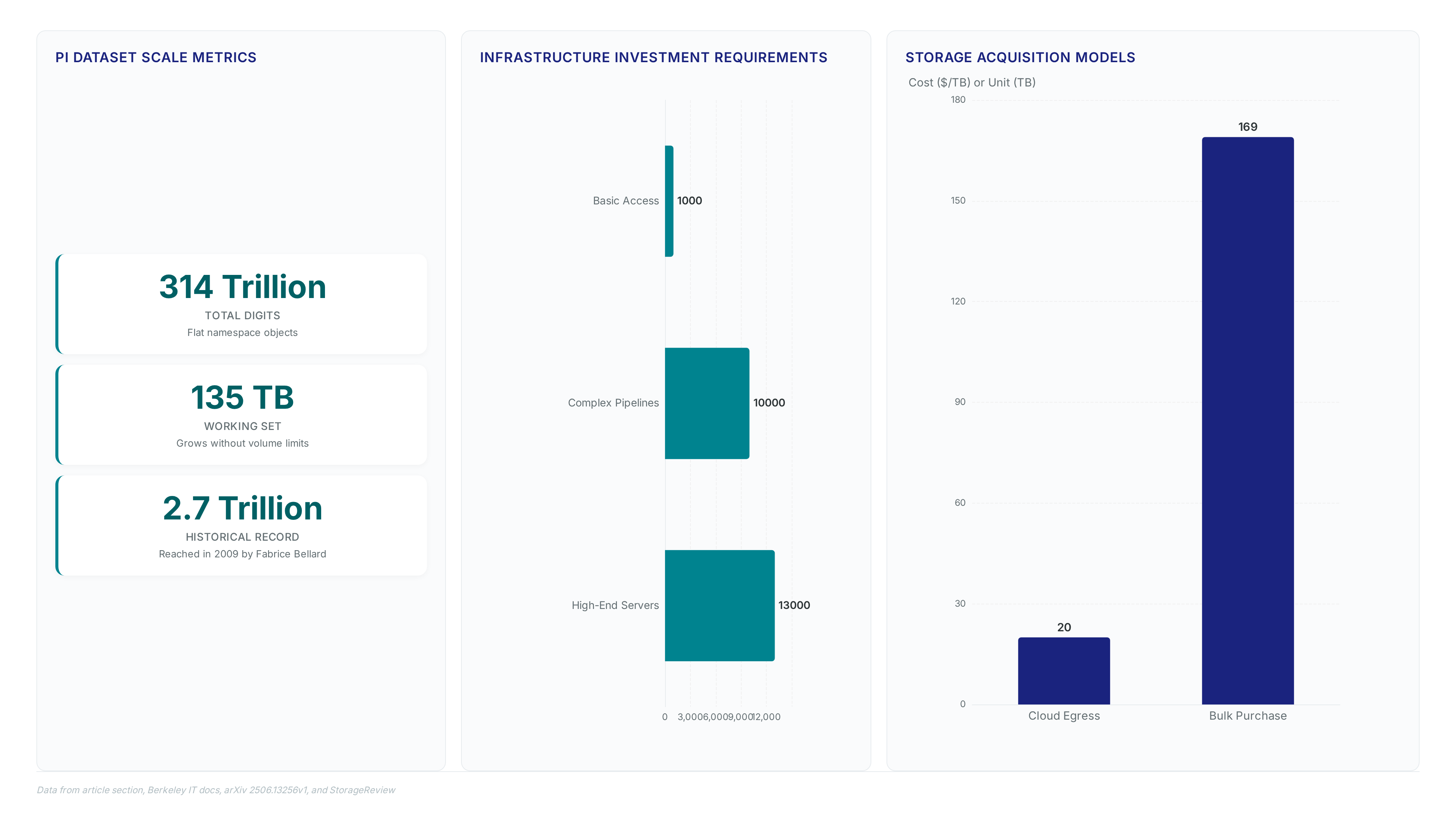
Object storage strips away file hierarchies, storing the 628 files comprising the 130 TB Pi dataset as immutable blobs. Traditional NAS architectures crumble at this scale. Metadata server contention chokes the system when handling thousands of concurrent 206 GB retrievals. Vertical scaling hits walls that horizontal cloud architectures bypass. Backblaze B2 mitigates fragmentation risk with an 11 nines durability guarantee, protecting the record-breaking 314 trillion digit computation artifacts.
Durability at this magnitude demands distributing data across independent failure domains, not relying on local RAID groups. The cost factor of persistent disks often forces operators to choose between performance and longevity. Object storage resolves this through erasure coding. Keeping the full 130 TB on-premises consumes power and cooling resources disproportionate to the infrequent access patterns of archival research data. Data durability metrics assume proper bucket configuration and API usage, not raw disk redundancy. Moving 130 TB requires careful bandwidth planning; even a strong 2 Gb uplink extends transfer windows into multi-day operations. The architectural shift prioritizes global availability over local low-latency access. This limitation is necessary for preserving computational history.
Hybrid Workflow Solutions for 2 Gbps WAN Bottlenecks
A hybrid workflow offloads distribution from constrained local WAN links to scalable cloud endpoints, bypassing the 2 Gbps ceiling. StorageReview rejected BitTorrent for the Pi dataset because client requirements create unacceptable user friction. Direct cloud hosting eliminates this barrier while sustaining high throughput. Transferring the full archive consumed 90.9 TB of monthly WAN data, saturating the uplink during the initial migration window. This volume confirms local infrastructure cannot sustain public access for massive artifacts without choking internal operations.
Hybrid workflows decouple compute location from delivery mechanisms. The constraint is cost; persistent object storage incurs higher long-term expenses than ephemeral peer seeding. Operators must weigh immediate accessibility against recurring egress fees when selecting a distribution tier. Cloud offloading makes sense only when dataset value justifies the premium over self-hosted alternatives.
Cloud Object Storage Versus On-Premises NAS for 132 TB Buckets
The confirmed 132,210.5 GB bucket size exposes the physical limits of locally mounted storage arrays. Keeping such volumes permanently attached to on-premises hardware proves impractical due to rigid capacity ceilings and shared bandwidth constraints. Local NAS architectures force vertical scaling, requiring expensive hardware refreshes to accommodate growth beyond initial provisioning. Cloud buckets expand elastically without physical intervention or downtime.
Storage costs dominate the total cost of ownership for massive archives. Persistent disk purchases are financially inefficient compared to object tiers. Berkeley IT demonstrates an alternative model by offering large-scale purchases in 169 TB increments to cap five-year availability costs. This approach contrasts sharply with the linear expense of expanding local SAN fabrics. The economic reality favors decoupled storage where compute and capacity scale independently. Operators avoid over-provisioning static arrays for transient or expanding datasets. The operational penalty of local hosting includes complex maintenance cycles and single-site failure risks. Cloud migration transforms fixed assets into variable operational expenses aligned with actual usage. Evaluate total lifecycle costs rather than initial hardware price tags alone.
Inside the Hybrid Architecture Supporting 130 TB Data Transfers
S3-Compatible API Mechanics in the Rclone to UDM Pro Max Pipeline
Rclone translates local file operations into S3-compatible API calls that traverse the UDM Pro Max gateway without protocol translation overhead. The tool maps standard POSIX commands to HTTP verbs, allowing the lab NAS to treat remote object storage buckets as mounted endpoints. This abstraction layer enables the sustained 2 Gbps upload rate observed during the transfer. Operators configure the backend using simple key-value pairs rather than custom drivers, reducing friction in hybrid deployments.
| Component | Function | Protocol Layer |
|---|---|---|
| Rclone | Command-line sync utility | Application |
| UDM Pro Max | Stateful packet inspection | Network Edge |
| B2 Endpoint | Object ingestion target | Storage Service |
Signature v4 authentication validates every request before data leaves the local network. A single misconfigured secret key halts the entire stream, creating a hard failure mode distinct from TCP packet loss. This strictness prevents partial uploads but demands precise credential management. The architecture eliminates the need for specialized gateways or protocol converters between on-premises compute and cloud distribution.
Edge router latency spikes can trigger client-side timeouts even when bandwidth remains sufficient. Rclone defaults to aggressive retry logic, which may mask underlying network instability rather than resolving it. Network engineers must tune timeout values specifically for high-latency, high-throughput paths to avoid stall conditions. Ignoring this tuning step risks leaving large objects in incomplete states indefinitely.
Achieving 2.27 Gbps Peak Throughput on a 2 Gbps WAN Link
UniFi network dashboard logs recorded a peak upload rate of 2.27 Gb, momentarily exceeding the nominal 2 Gb circuit capacity through burst buffering.
Per-minute transfer samples displayed bars consistently reaching between 15 and 16 gigabytes, indicating near-total saturation of the available uplink without packet loss. This performance contrasts sharply with peer-to-peer alternatives. BitTorrent systems suffer from instability and fluctuation based on peer population rather than maintaining steady pipe utilization. The Rclone configuration routed through the UDM Pro Max gateway sustained this velocity by maximizing TCP window scaling while avoiding head-of-line blocking common in congested queues.
| Metric | Dedicated Cloud Pipe | Peer-to-Peer Mesh |
|---|---|---|
| Stability | High (steady state) | Low (peer-dependent) |
| Throughput | Maximized single stream | Fragmented across peers |
| User Friction | None (direct HTTP) | High (client required) |
Dedicated pipes outperform decentralized swarms for single-source large dataset ingestion. The constraint here is financial: sustaining maximum bandwidth for ten days consumes significant monthly data allowances, yet avoids the retrieval costs often exceeding $20/TB on academic platforms. Configure QoS policies to prioritize these bulk transfers during off-peak hours to prevent contention with daily lab operations.
BitTorrent distribution failed the accessibility test because client requirements introduce unacceptable user friction compared to direct cloud pipes. Facebook's Murder deployment tool from 2010 optimized internal uplink utilization but relied on volatile peer populations that cause throughput fluctuation. Such instability creates unpredictable download windows for external researchers, whereas Backblaze B2 Cloud Storage guarantees a steady 2 Gbps stream independent of swarming dynamics. Decentralized methods remain useful for mass server provisioning, yet they demand specific software literacy that blocks casual academic access.
| Attribute | BitTorrent Swarm | Direct B2 Upload |
|---|---|---|
| Throughput Stability | Fluctuates with peer count | Consistent pipe saturation |
| Client Requirement | Mandatory specialist software | Standard HTTP/S tools |
| Scaling Logic | Parallel server distribution | Linear single-stream flow |
Teams must weigh parallel speed against universal reach when configuring hybrid compute-storage workflow. P2P traffic volumes show no decline over long-term measurements, suggesting decentralized methods stay relevant. The friction cost outweighs bandwidth gains for public datasets. The chosen linear transfer strategy sacrifices massive parallelism to eliminate barriers for non-technical users. This cost buys data availability over raw distribution velocity. Reserve B2 Overdrive for scenarios requiring terabit-scale egress where client installation is feasible. Use direct object storage for any dataset targeting broad scientific collaboration rather than internal fleet updates.
Executing High-Volume Cloud Uploads with Rclone and Direct Access
Rclone Configuration Syntax for Backblaze B2 S3 Endpoints

Connect Rclone to the `s3. Us-west-004. Backblazeb2. Com` endpoint by defining a specific remote type that overrides default AWS parameters.
- Initialize a new remote using the `s3` backend instead of the native `b2` driver to use standard API compatibility.
- Set the `endpoint` value explicitly to the regional URL, ensuring traffic bypasses generic AWS routing tables.
- Disable `use_accelerate_endpoint` to prevent redirection latency during large object transfers.
This syntax treats the storage bucket as a flat namespace where every file remains individually addressable without traditional volume limits. Operators gain programmatic access to full directory listings, avoiding the hierarchy constraints of POSIX systems. The configuration supports sustained throughput rates that match the 2 Gbps limit. Centralized retrieval via this endpoint eliminates the peer-dependency instability found in decentralized BitTorrent. A hard limitation exists: misconfigured endpoints force authentication failures against AWS servers rather than the intended B2 infrastructure. Network teams must verify the `provider` flag sits at `Other` to maintain valid signature generation. Validate connectivity with a small test object before initiating bulk transfers.
Routing 132 TB Transfers Through UDM Pro Max Gateway
The UDM Pro Max gateway sustained a continuous 10 days of transfer time to move the full pi-314-trillion bucket contents without manual intervention.
- Configure the Rclone backend to target the specific S3-compatible endpoint, bypassing generic AWS routing tables that introduce latency.
- Enable stateful packet inspection on the edge device to maintain TCP window scaling during sustained saturation events.
- Monitor per-minute throughput samples to verify consistent data flow between 15 and 16 gigabytes before validating checksums.
Direct cloud pipes provide deterministic performance that decentralized swarms cannot guarantee for academic distribution. This architecture avoids the volatility seen in BitTorrent systems. The approach also sidesteps the massive 100 Gb egress requirements typical of Google Cloud native architectures, which demand specialized drivers to handle similar I/O loads. Operators achieve global availability without provisioning expensive dedicated interconnects or managing complex distributed file systems.
| Constraint | Direct Upload | Distributed Swarm |
|---|---|---|
| Client Requirement | None | Mandatory |
| Throughput Stability | High | Variable |
| User Friction | Low | High |
Commodity edge hardware can saturate available WAN circuits when properly tuned. The 2.27 Gb peak rate observed confirms this capability. However, this method locks the upload path to a single physical location, creating a dependency on local power and network uptime that multi-region clouds abstract away. Validate local circuit stability before initiating transfers exceeding 50 TB.
Validating Sustained 2.27 Gbps Throughput on UniFi Dashboards
UniFi dashboards must display sustained 2.27 Gbps upload rates with zero packet loss events to confirm transfer integrity.
- Verify per-minute throughput bars consistently reach qualitative maximums, indicating full saturation of the 2 Gbps uplink.
- Confirm the connection remained stable with no significant packet loss events throughout the 10 days of continuous operation.
- Cross-reference cumulative byte charts against the 90.9 TB monthly WAN usage log to detect any unexplained gaps.
Steady pipe utilization contrasts sharply with decentralized methods, where BitTorrent systems fluctuate wildly. Direct cloud pipes avoid this volatility by maintaining constant line rates independent of swarming dynamics.
| Metric | Stable Cloud Upload | Peer-to-Peer Swarm |
|---|---|---|
| Consistency | High | Low |
| Dependencies | Bandwidth | Peer Count |
| Client Need | None | Required |
Configure Rclone to target the specific S3 endpoint, ensuring traffic bypasses generic routing tables that introduce latency. This setup treats the storage bucket as a flat namespace where every file remains individually addressable. Missing even one validation step risks undetected checksum failures during the extended transfer window.
Optimizing Global Data Distribution Through Direct HTTPS and Torrent Alternatives
S3-Compatible Endpoint Mechanics for the pi-314-trillion Bucket
The `s3. Us-west-004. Backblazeb2. Com` endpoint exposes the pi-314-trillion bucket as a flat namespace containing 628 individually addressable objects. This configuration eliminates traditional file system hierarchies, allowing scripts to retrieve full listings programmatically without traversing directory trees. Unlike decentralized models where peer populations fluctuate, this offers stability. The trade-off is a reliance on single-stream bandwidth limits rather than aggregate peer uplinks, yet the stability supports rigorous academic verification. Facebook's historical Murder deployment tool optimized internal distribution but introduced volatility unsuitable for public research datasets requiring deterministic retrieval windows.
Configure Rclone to override default AWS routing tables, ensuring traffic targets the specific regional URL directly.
| Feature | Flat Object Namespace | POSIX Hierarchy |
|---|---|---|
| Access Model | Programmatic Key Lookup | Directory Traversal |
| Scaling Limit | Billions of Objects | Inode Constraints |
| Latency Source | API Request Overhead | Filesystem Metadata |
Use this direct HTTPS approach for hosting large datasets where auditability outweighs the need for peer-assisted acceleration. The absence of volume limits means the 135 TB working set grows without requiring partition management or mount point reconfiguration. This mechanical simplicity reduces operational friction for researchers who lack specialized torrent client literacy. Previous attempts stalled at shorter lengths; Kleber executed searches through d=7, while Fabrice Bellard reached 2.7 trillion digits in 2009 without extending to d=11. Accessing this volume for verification typically demands infrastructure investments between $10,000 and $100,000, effectively gatekeeping complex processing pipelines for most academic groups. Even basic entry points often require minimum capital commitments starting at $1,000, creating a financial barrier that excludes independent researchers from meaningful large dataset analysis. The pi-314-trillion bucket removes this friction by hosting the full artifact on Backblaze, allowing direct HTTPS retrieval without peer dependency.
| Access Model | Cost Barrier | Stability Factor |
|---|---|---|
| Traditional HPC | High (a substantial sum+) | Variable |
| P2P Distribution | Low | Unpredictable |
| Direct Object Storage | Minimal | Deterministic |
Decentralized methods maintain relevance, yet peer-to-peer traffic carries risks. A single missing chunk in a torrent swarm halts the entire verification process, whereas object storage guarantees individual file addressability. Operators must weigh the zero-marginal cost of P2P against the deterministic latency required for iterative search algorithms. Kleber's work depends on rapid, random access to specific offsets rather than sequential streaming. The architecture prioritizes availability over aggregate throughput, ensuring that a single researcher can replicate findings without coordinating a swarm. This shift enables broader participation in number theory by decoupling compute power from data ownership.
User Friction and Client Dependencies in BitTorrent Distribution
BitTorrent distribution for the 130 TB dataset fails immediately because it mandates specific client software installation, creating an insurmountable barrier for casual academic access. Unlike direct HTTPS retrieval via Rclone, peer-to-peer methods force users to manage local swarm participation rather than simply fetching objects from the pi-314-trillion bucket. Historical datacenter deployments like Facebook's Murder deployment tool optimized internal uplink utilization but introduced complexity unsuitable for external researchers. Measurement studies confirm that BitTorrent systems struggle with consistency. While P2P traffic volume remains significant according to long-term measurements, the operational consequence is clear: requiring a dedicated client reduces the potential user base to only those with advanced networking skills.
Direct cloud pipes provide steady throughput without depending on the unpredictable behavior of external peers. Centralized object storage eliminates these friction points entirely. Decentralized models shift the burden of availability from the provider to the community, a risk unacceptable for unique computational records. Stability outweighs theoretical bandwidth aggregation when the goal is universal data access.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in scalable storage architecture and cost optimization for cloud-native environments. His daily work designing Kubernetes persistent storage solutions and disaster recovery strategies directly aligns with the challenges of managing massive datasets like the recent 130 TB Pi record. Having previously served as an SRE for high-traffic platforms, Kumar understands the critical need for high-performance, S3-compatible object storage when handling extreme data volumes. At Rabata. Io, a specialized provider offering GDPR-compliant regions and transparent pricing, he architects systems that eliminate vendor lock-in while delivering superior speed compared to traditional providers. This article uses his practical experience in balancing infrastructure limits with economic efficiency, providing readers with actionable insights on deploying enterprise-grade storage for AI/ML workloads and large-scale computational projects without compromising on performance or budget.
Conclusion
Scaling immutable blob storage reveals that bandwidth saturation becomes the primary bottleneck long before capacity limits are reached. When retrieving massive datasets, the physical ceiling of local uplinks forces transfer windows into impractical durations, rendering traditional single-endpoint architectures ineffective for high-concurrency academic workloads. The operational cost here is not merely monetary but measured in research velocity, as waiting weeks for data retrieval stalls computational progress entirely. Organizations must recognize that preserving petabyte-scale artifacts requires decoupling storage location from retrieval mechanics to bypass these inherent network constraints.
Adopt a multi-cloud egress strategy within the next six months if your dataset exceeds 50 TB and serves more than ten concurrent users. Relying on a single provider's pipe guarantees congestion during peak demand, whereas distributing read replicas across geographically diverse endpoints ensures consistent throughput regardless of local infrastructure limits. This approach shifts the architectural focus from simple durability to active availability, ensuring that critical scientific records remain accessible without demanding advanced networking expertise from every researcher.
Start by auditing your current egress patterns this week to identify specific timeframes where uplink utilization hits near-capacity levels or higher. Use this baseline to model the required bandwidth multiplier needed to support your projected user growth over the next year, then provision additional read endpoints accordingly before the next substantial dataset release.
Frequently Asked Questions
Retrieving data from certain academic cloud services can cost $20 per TB or more. This high fee contrasts sharply with the efficient distribution of the 130 TB Pi dataset hosted on Backblaze B2 Cloud Storage.
Transferring the full archive consumed 90.9 TB of monthly WAN data during the upload window. This massive volume saturated the uplink while moving the 628 files comprising the complete Pi computation artifact.
Metadata contention occurs when handling thousands of concurrent 206 GB retrievals on traditional systems. Object storage avoids this by decoupling data from file hierarchies to store immutable blobs efficiently for global access.
The confirmed 132,210.5 GB bucket size exposes the physical limits of locally mounted storage arrays. Keeping such volumes permanently attached to on-premises hardware proves impractical due to rigid capacity ceilings.
Moving more than 130 TB of results was completed in under two weeks. The transfer maintained a steady 2 Gbps throughput for much of the process despite bandwidth being the limiting factor.
