NetApp AIDE cuts AI vector storage growth 20x
IDC pegs global AI infrastructure spending at $98 billion for 2026. Yet enterprises still cannot find the data required to fuel their models. NetApp AI Data Engine (AIDE) breaks this logjam by semantically enriching metadata in place. No data movement. No sensitive copies floating around for curation. This directly targets the paralysis hitting the 76% of large companies IDC identifies as actively struggling with AI deployment due to poor data governance.
We need to stop treating data estates like static archives. NetApp AIDE builds a continuously updated global catalog that analyzes file content, ignoring shallow file system attributes. The mechanical integration within the Nvidia STX architecture proves that co-engineering removes traditional latency hurdles. Moving data for transformation is an obsolete practice. It introduces security risks and expense we can no longer afford.
JLL projects nearly 100 GW of new data center capacity coming online between 2026 and 2030. Current data handling methods will not survive this scale. With AI workloads poised to represent half of all data center demand by 2030 according to JLL, shifting toward intelligent data infrastructure is existential. NetApp's strategy, backed by substantial all-flash array revenue last quarter, confirms that disaggregated storage and independent scaling are the only viable paths for true enterprise AI factories.
The Role of NetApp AIDE in Modernizing Enterprise AI Data Estates
NetApp AIDE Architecture and AI Factory Definition
NetApp AI Data Engine (AIDE) is a secure, unified AI data platform stack co-engineered with Nvidia. It defines the AI factory: storage, services, and control planes that expand independently. Vendor lock-in dies here. Syam Nair calls this disaggregated design mandatory for clients needing a mature enterprise-grade data platform built with intelligence from inception. The system performs active file content analysis to semantically enrich metadata in place. You skip the expense of moving data multiple times.
Global AI infrastructure spending reached $98 billion in 2026, yet 76% of large companies report active AI usage stalled by data bottlenecks. AIDE resolves this by executing microservices on data compute nodes integrated with ONTAP storage. No forced migration. The platform supports the Nvidia AI Data Platform reference design while preserving open technology ecosystems for ISV partners. Consider the economics: competitors like Snowflake charge $23 per TB per month. NetApp offers enterprise-grade platform pricing with reported averages of $923,652 annually.
Semantic cataloging demands initial indexing cycles. Agentic workflows cannot use enriched metadata until the engine runs. Operators must weigh immediate ingestion speed against the long-term benefit of governed, searchable data estates.
Semantic Metadata Enrichment and Agentic AI Workflows
NetApp AIDE enhances metadata in place by scrutinizing file content without data relocation. This method removes security risks and egress costs linked to data duplication during preparation phases. The system deploys as microservices on data compute nodes integrated with ONTAP storage to perform core functions. Operators obtain semantic search, data vectorization, and data guardrails directly within the storage layer. Agentic AI support defines the ability for autonomous workflows to query, curate, and govern datasets through these localized services. Multimodal data capabilities become necessary when visual inputs require indexing alongside text for unified model training. The architecture decouples compute from storage, permitting synchronization.
Running analysis microservices on data compute nodes consumes local CPU cycles. Those cycles could otherwise serve application I/O. This constraint creates a potential contention point during peak ingestion windows if node resources lack sizing for concurrent vectorization tasks. Such a drawback necessitates careful capacity planning to avoid latency spikes in production AI pipelines. Network teams must confirm that data compute nodes hold sufficient headroom before enabling full-content semantic enrichment at scale. The result is a shift from pure storage provisioning to balanced compute-storage resource allocation for AI factories.
Data Discovery Bottlenecks Blocking AI Production
Standard file system metadata lacks semantic context. This stalls 42% of AI projects before production due to governance gaps. AI factories demand continuous data curation that traditional storage indices cannot supply. The Metadata Engine addresses this by producing structured, interactive views of the entire estate without data movement. This mechanism enables semantic search directly on unstructured files, bypassing the latency of extraction pipelines. Deploying such intelligence introduces compute overhead on storage nodes that operators frequently underestimate during capacity planning. The financial impact stays severe for organizations failing to govern global data effectively. NetApp Malaysia recently addressed these global data governance hurdles by unveiling engines specifically designed for regional compliance constraints.
Operators ignoring these bottlenecks face compounding delays as model retraining cycles stall on dirty inputs. Neglecting metadata richness renders even massive infrastructure investments useless for agentic workflows.
Inside the Nvidia STX Architecture and NetApp AIDE Integration Mechanics
Nvidia STX Architecture and BlueField DPU Integration Mechanics
Nvidia STX functions as a modular, rack-scale storage reference architecture built with Nvidia Vera Rubin GPUs and Nvidia BlueField-4 DPUs to centralize intelligent data handling. This design creates a specialized memory tier for KV-cache storage, improving power efficiency and throughput for agentic AI workloads. The mechanism offloads data movement from host CPUs to the DPU, allowing ONTAP microservices to scale independently from compute nodes. Operators gain a high-performance data engine that bridges massive AI compute with unstructured storage without traditional bottlenecks.
Adopting this rack-scale model requires strict hardware homogeneity. That conflicts with heterogeneous brownfield deployments. The cost of replacing existing infrastructure to match STX specifications often exceeds initial software licensing estimates. This limitation forces a choice between greenfield performance gains and brownfield capital preservation.
| Component | Function | Integration Point |
|---|---|---|
| BlueField-4 DPU | Handles data movement and security | Offloads host CPU |
| Vera Rubin GPU | Provides AI compute power | Consumes KV-cache |
| STX Memory Tier | Stores context for agents | Accelerates retrieval |
NetApp AIDE uses this integration system. The implication for network architects is a shift toward storage-centric security policies enforced at the DPU level rather than the host. Validate DPU firmware compatibility before purchasing STX-aligned hardware to prevent orchestration failures.
Deploying Global Metadata Catalogs on RHEL 9.7 and AFF Storage
Operators install the catalog on customer-provided RHEL 9.7 servers or NetApp DCNs to eliminate pipeline latency. This deployment choice dictates whether GPU resources remain dedicated to inference or share cycles with metadata indexing tasks. The software extends directly into existing AFF A-Series.
| Deployment Target | Compute Resource | Storage Integration |
|---|---|---|
| Customer Server | Host CPU/GPU | Network-mounted AFF |
| NetApp DCN | Integrated GPU | Local ONTAP Tier |
Selecting customer hardware avoids vendor lock-in but increases operational overhead for patching and driver compatibility. Conversely, DCN units simplify management yet constrain scaling to predefined rack configurations. The mechanism parses file content in place, transforming raw binaries into searchable vectors within the global metadata catalog. This process prevents the 60% cost surge often seen when replicating datasets for external indexing engines. Operators must balance the immediate throughput gains of local processing against the long-term flexibility of disaggregated compute nodes. Failure to align storage tiering policies with these new microservices creates I/O contention that stalls agentic workflows. The architectural decision ultimately determines whether the AI factory scales linearly or hits a hard ceiling during peak ingestion windows.
TCO Risks of AI Workloads and Unstructured Data Security Gaps
Cloud expenses for AI tasks frequently consume 70% of projected on-premises Total Cost of Ownership, creating immediate budget overruns. Moving unstructured datasets repeatedly to processing centers introduces attack surfaces that static analysis avoids entirely. This approach eliminates the risk of interception during transit while preserving original file permissions. Operators face a tension between rapid model training and strict data sovereignty requirements when selecting infrastructure.
| Factor | In-Place Analysis | Multi-Hop Pipelines |
|---|---|---|
| Security Posture | High | Low |
| Egress Fees | Zero | Significant |
| Latency | Minimal | High |
| Compliance Risk | Reduced | Elevated |
Semantic enrichment occurring at the storage layer prevents the duplication costs associated with traditional Lakehouse models. Shifting data multiple times inflates operational overhead beyond simple storage fees. The financial burden of cloud-based workflows often exceeds expectations due to hidden network charges. Deploy compute directly adjacent to storage arrays to mitigate these variables. Data guardrails function more effectively when applied before any file movement occurs. Delaying security checks until data reaches a central repository leaves organizations exposed during the transfer window. Unstructured data volumes grow quicker than governance tools can track without localized metadata catalogs.
Comparing NetApp AIDE Against Traditional Data Platforms and Competitors
NetApp AIDE Versus Traditional Data Platform Architectures
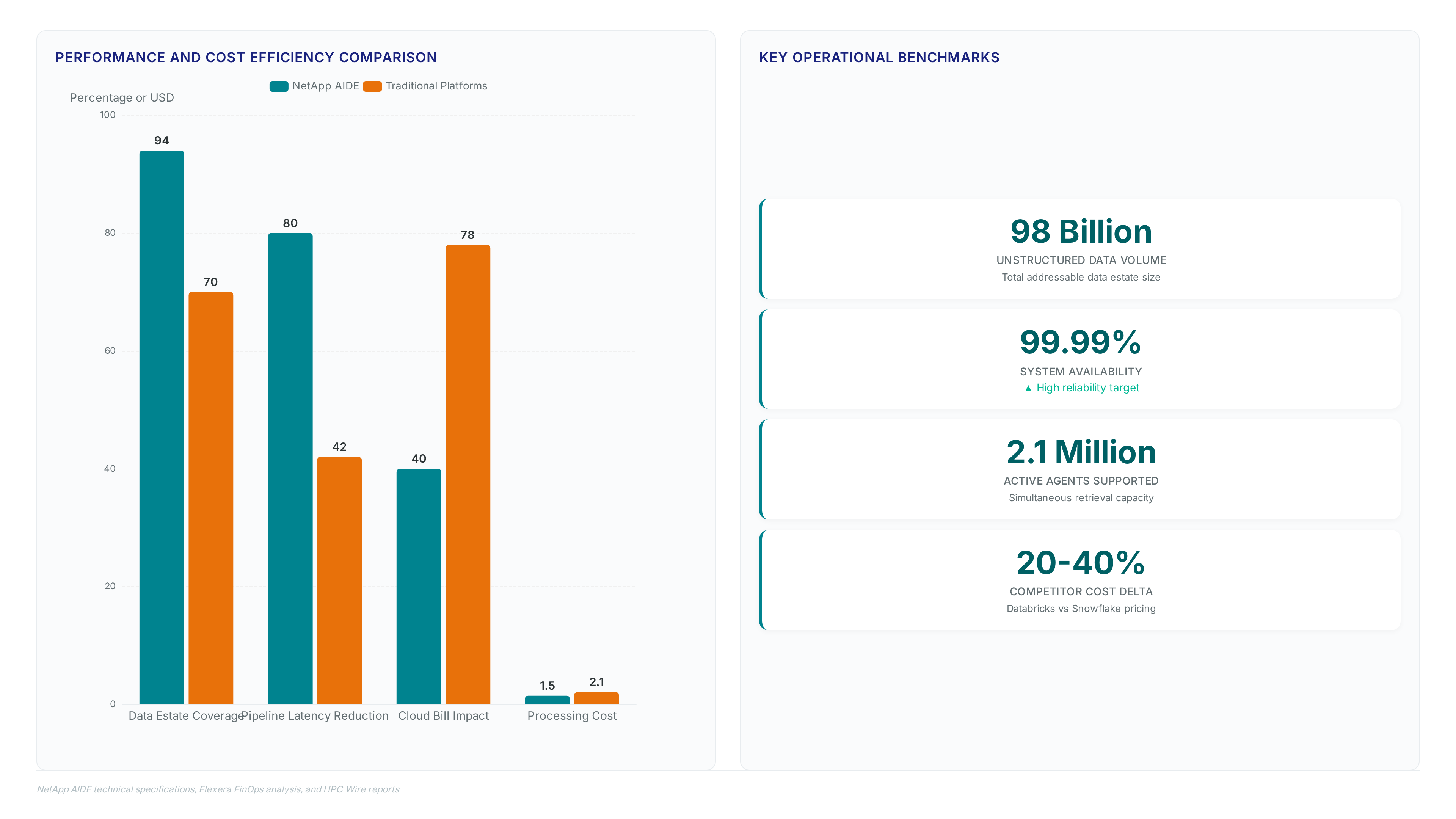
Traditional monolithic platforms force coupled scaling of storage and services. NetApp AIDE decouples these layers to prevent vendor lock-in.
| Architecture Type | Scaling Model | Data Movement | Governance Scope |
|---|---|---|---|
| Monolithic Platform | Coupled | High | Siloed |
| NetApp AIDE | Disaggregated | Zero | Global |
Legacy systems require copying datasets to processing centers. This introduces latency and security gaps that in-place analysis avoids. The co-engineered stack eliminates the egress fees and interception risks inherent in multi-hop pipelines used by SQL-first warehouses. Operators gain the ability to scale compute nodes independently from storage arrays, a flexibility absent in rigid legacy designs. However, this disaggregation demands precise network tuning to maintain low-latency access for the metadata catalog. Traditional platforms often bottleneck at the storage controller when multiple AI agents request simultaneous retrieval. NetApp AIDE distributes this load across microservices, ensuring consistent throughput during peak inference windows. The cost of ignoring this architectural shift is measurable in stalled production deployments and inflated cloud bills.
Accelerating AI Factories with FlexPod and Nvidia STX Integration
FlexPod AI integrates NetApp AIDE with Nvidia STX reference architecture to execute data processing at the storage edge. This configuration uses Nvidia Vera Rubin. The mechanism eliminates pipeline latency by keeping semantic enrichment local to ONTAP arrays rather than shuttling datasets to centralized clusters. Achieving this low-latency state requires strict alignment between rack-scale power density and existing facility cooling limits. Operators deploying this stack gain immediate throughput gains but face rigid hardware dependencies that limit future component swaps.
| Feature | FlexPod + AIDE | Traditional ETL Pipeline |
|---|---|---|
| Data Movement | Zero | High |
| Compute Location | Storage Edge | Centralized Cluster |
| Security Surface | Minimal | Expanded |
The primary workload focus remains strictly on ingestion and guardrails, distinguishing it from broader analytics platforms. Adopting this architecture answers whether operators should deploy NetApp AIDE for enterprise AI by validating the need for in-place analysis. You lose flexibility in hardware selection compared to software-only deployments on commodity servers. This path suits organizations prioritizing latency reduction over component modularity. Moving data repeatedly to public clouds introduces security gaps that in-place processing eliminates entirely. This approach preserves original file permissions while removing egress fees from the operational budget. Hybrid models offer flexibility but incur significant latency when shuttling large datasets between edge and core environments.
| Deployment Model | Data Movement | Security Risk | Cost Profile |
|---|---|---|---|
| On-Premises | Zero | Low | Fixed Capital |
| Hybrid Cloud | High | Moderate | Variable OpEx |
| Pure Cloud | Maximum | High | Escalating |
Operators must balance the agility of third-party cloud platforms against the predictability of local hardware resources. Pure cloud strategies often fail to account for the cumulative expense of transferring unstructured data for every inference cycle. Evaluate workload sensitivity before selecting a hybrid topology. Organizations handling regulated data benefit most from the disaggregated architecture that keeps control planes separate from storage layers. This configuration prevents vendor lock-in while maintaining high throughput for agentic AI workflows. The limitation remains the upfront capital requirement for rack-scale infrastructure compared to pay-as-you-go cloud billing.
Deploying NetApp AIDE with Nvidia GPUs for Scalable AI Factory Workflows
NetApp AIDE Deployment Modes on DCN and RHEL 9.7 Servers
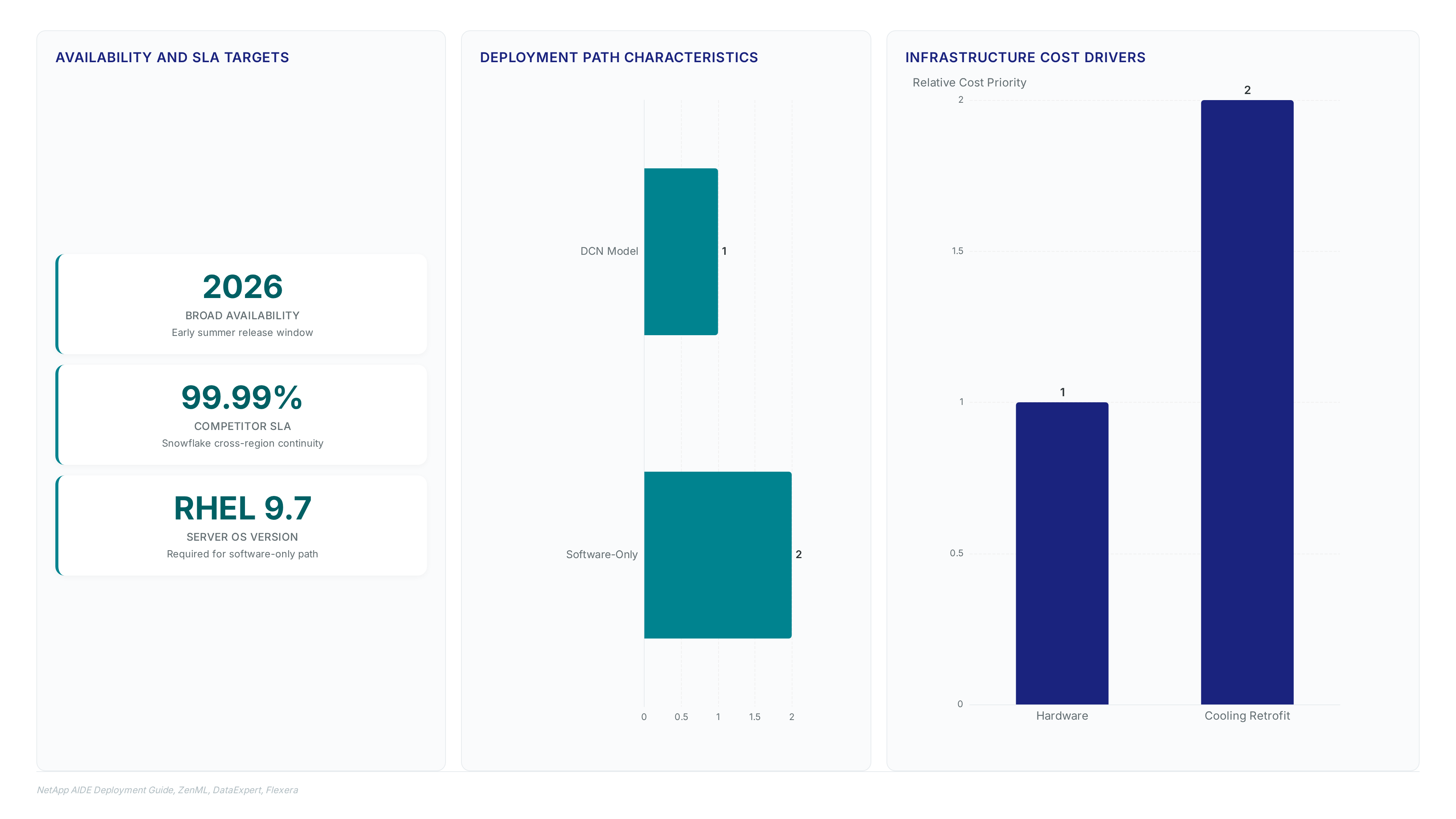
Operators initiate NetApp AIDE via two distinct paths: NetApp-provided Data Compute Nodes with integrated GPUs or customer-owned RHEL 9.7 servers. The hardware-centric DCN model simplifies validation but locks capacity to vendor refresh cycles. The software-only approach demands manual driver alignment for Nvidia RTX PRO accelerators. Storage backends span AFF A-Series, AFF C-Series, and FAS arrays, requiring specific ONTAP versions to sustain metadata indexing throughput.
- Select the deployment target based on existing GPU inventory and support contracts.
- Configure the semantic metadata engine to point at the assigned ONTAP volume.
- Validate network connectivity between compute nodes and storage controllers before enabling microservices.
Validate Nvidia STX rack-scale configurations by confirming BlueField-4 DPU firmware matches the Vera Rubin GPU driver stack before powering on. Operators must verify physical connectivity between Cisco UCS compute nodes and NetApp storage fabrics to sustain agentic AI throughput.
- Inspect PCIe topology to ensure direct attachment of RTX PRO accelerators without intermediate switching latency.
- Confirm ONTAP cluster settings allow high-throughput metadata indexing from local Data Compute Nodes.
- Test asynchronous ONTAP REST API calls to validate semantic catalog updates under load.
- Audit network segmentation rules protecting the semantic metadata plane from general traffic bursts.
This failure mode bypasses standard monitoring tools, requiring deep packet inspection to detect.
| Component | Validation Target | Failure Symptom |
|---|---|---|
| BlueField-4 DPU | Offload State | Host CPU saturation |
| Vera Rubin GPU | PCIe Link Width | Reduced training throughput |
| ONTAP Cluster | API Latency | Stale metadata indexes |
| Cisco Fabric | Jumbo Frames | Silent vector drops |
Broad availability arrives in early summer 2026, but early adopters face strict power density constraints in legacy colocation facilities. The cost of retrofitting cooling infrastructure often exceeds initial hardware procurement budgets for smaller deployments.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the discussion of NetApp's AI Data Engine (AIDE). His daily work designing Kubernetes storage architectures and optimizing disaster recovery strategies for AI/ML startups directly aligns with the challenges AIDE aims to solve. At Rabata. Io, a specialized S3-compatible object storage provider, Kumar focuses on eliminating vendor lock-in and delivering high-performance data infrastructure necessary for scaling artificial intelligence workloads. This practical experience in managing cost-effective, scalable storage for data-intensive applications positions him to critically evaluate how NetApp's co-engineered solution with Nvidia removes roadblocks for enterprise AI innovation. By bridging the gap between theoretical platform capabilities and real-world deployment constraints, Kumar offers valuable insights into how unified data platforms like AIDE can accelerate momentum in the rapidly evolving AI environment.
Conclusion
Scaling AI infrastructure reveals that power density limits, not software licensing, become the primary bottleneck as organizations move from pilot to production. The projected doubling of global data center capacity by 2030 creates a fierce competition for high-wattage rack space, rendering legacy colocation strategies ineffective for dense GPU clusters like FlexPod AI. Operational expenses will increasingly shift from storage fees to cooling retrofits and energy provisioning, demanding a fundamental reevaluation of site readiness before hardware deployment. Teams should commit to a hybrid architecture strategy by Q4 2026, reserving on-premises resources strictly for low-latency inference while offloading heavy training bursts to cloud providers with available power headroom. This approach prevents capital traps where retrofit costs eclipse the value of the AI workload itself. Start this week by auditing your current facility's kW per rack availability against the specific thermal requirements of the Nvidia STX reference architecture. Identify any gaps exceeding a significant margin immediately, as securing upgraded power contracts often requires lead times that exceed hardware delivery schedules. Ignoring these physical constraints guarantees project stalls regardless of software optimization or metadata catalog sophistication.
Frequently Asked Questions
Poor data governance stalls seventy-six percent of large company initiatives before production. Metadata lacking semantic context creates bottlenecks that prevent models from accessing the correct fuel for transformative artificial intelligence workflows.
Analyzing file content in place avoids the expense of moving data multiple times for transformation. This approach eliminates security risks and egress costs linked to data duplication during critical preparation phases.
NetApp Enterprise plans average $923,652 annually while Snowflake charges $23 per TB monthly. This pricing structure offers an enterprise-grade platform alternative to competitors charging per credit or storage unit.
The engine runs microservices on data compute nodes integrated with ONTAP storage alongside Nvidia GPUs. This co-engineered architecture supports Blackwell Server Edition GPUs to scale storage and services independently.
It actively analyzes file content to semantically enrich metadata rather than relying on shallow attributes. This creates a continuously updated global catalog enabling autonomous agentic workflows to query and govern datasets.
