Storage fixes AI bottlenecks now
Global AI infrastructure spending hit $250 billion in 2025. That number forces a hard pivot. We are moving toward unified object storage architectures because the old way is dead. This guide defines AI-ready infrastructure for exascale demands, architects high-throughput layers without virtualization tax, and executes a unified data platform deployment that kills silos.
Disjointed data management is collapsing. Analysts predict that 50% of large enterprises will break down data silos by 2027 as part of a shift toward data-as-a-product architectures. This isn't theory; it's survival. Organizations are drowning in unstructured data. The collaboration between QBO Cloud and MinIO offers a path out. It provides sovereign, scalable operations that traditional public clouds cannot match on price or control.
We skip the marketing hype. We address the tangible requirements of S3-compatible object storage in production. This is a blueprint for engineers mobilizing data across complex environments while maintaining strict governance and cost efficiency.
Defining the Exascale Data Store for AI-Ready Infrastructure
MinIO AIStor is a self-hosted, software-set object store. It is not a public cloud managed service. This architecture defines the exascale data store by delivering sovereign control over storage infrastructure while supporting the throughput modern AI workloads demand. Global AI infrastructure spending exceeded $250 billion in 2025, driving demand for platforms that avoid vendor lock-in. Unlike AWS S3 or Google Cloud Storage, MinIO AIStor operates on bare metal to eliminate per-API call charges. The QBO Cloud platform integrates this storage layer to provide a unified foundation for enterprise AI. Joint customers deploy the solution to accelerate infrastructure readiness without sacrificing data locality.
Accelerating AI-Ready Infrastructure with QBO Cloud Bare Metal
MinIO AIStor delivers 325 GiB/s read throughput on 32-node clusters. That satisfies real-time analytics demands. This performance tier defines AI-ready infrastructure by eliminating the latency penalties inherent in shared public cloud networks. More than a large majority of enterprises will apply AI APIs by 2027, creating urgent pressure for sovereign storage that avoids per-API billing traps like the $0.20/GB vector upload fees charged by hyperscalers. The QBO Cloud bare metal foundation pairs with MinIO to create a unified data plane capable of ingesting massive training datasets without egress throttling. Competitors like Cloudian offer similar on-premises deployments. The specific integration of QBO's agility with MinIO's software-set architecture targets the exascale data store requirements of large language models. This combination allows organizations to centralize industrial data for analysis at twice the density of legacy Hadoop environments.
Self-hosted object storage introduces operational complexity absent in managed services. Operators must manage their own data transfer acceleration since MinIO lacks a native equivalent to the Google Cloud Storage Transfer Service. Avoiding variable API charges brings the burden of maintaining high-availability networking and hardware refresh cycles internally. Network teams must weigh savings from predictable subscription models against the capital expenditure required for a 32-node cluster capable of sustaining 165 GiB/s write speeds. Sovereignty demands this constraint. True data control requires owning the entire stack from bare metal to object layer.
MinIO AIStor replaces per-API billing with a fixed subscription model per node to eliminate variable cost spikes. In contrast, the MinIO AIStor subscription tiers lock operational expenditure regardless of ingestion volume. This architectural shift matters because 75% of enterprises now apply object storage in cloud environments, making fee transparency necessary for budget planning. Self-hosted models require internal staff to manage hardware lifecycle and software updates. Organizations avoid the trap of paying for every PUT request during massive dataset migrations. A financial infrastructure provider previously achieved a 65% reduction in fraud model runtime after migrating from legacy Hadoop systems to this architecture. The case study demonstrates that removing per-call friction accelerates iterative model tuning. Operators gain sovereign control over data locality while sidestepping the egress fees inherent to hyperscaler ecosystems. Evaluate total cost of ownership over three-year horizons rather than initial unit prices.
Architecting High-Performance Object Storage on Bare Metal
MinIO AIStor Data Flow on QBO Cloud Bare Metal
MinIO AIStor bypasses hypervisor I/O scheduling by enabling `MINIO_API_ODIRECT` to force direct disk access on QBO Cloud bare metal. This configuration prevents the OS page cache from absorbing memory during high-throughput vector ingestion, a frequent bottleneck in virtualized environments. The architecture relies on Linux kernel 6.8 or later to sustain the direct disk access required for exascale workloads. Data flow prioritizes deterministic throughput over shared resource contention. Operators manage S3 storage on bare metal by deploying the Apache Iceberg V3 Catalog REST API directly within the storage namespace, removing external metadata dependencies. This integration supports the Warehouse → Namespace → Table hierarchy without requiring separate catalog services.
Peak performance demands strict adherence to hardware compatibility, specifically regarding NVIDIA STX reference architecture. Operational complexity increases as teams lose the abstracted management plane of public clouds in exchange for raw speed. Validate kernel versions before deployment to prevent silent throughput degradation.
Deploying FIPS 140-3 Compliant Storage for AI Workloads
A global bank achieved a 50% deployment time reduction by shifting from appliance-based storage to MinIO AIStor on bare metal. This acceleration stems from eliminating physical provisioning delays while enforcing FIPS 140-3 Compliant Cryptography for all encryption and key management operations. Financial institutions require this specific cryptographic standard to satisfy regulatory auditors without sacrificing the throughput needed for fraud detection models. Synchronizing data across environments becomes deterministic when the Apache Iceberg V3 Catalog REST API replaces legacy metadata databases that often act as single points of failure. The Warehouse → Namespace → Table hierarchy mirrors traditional database mental models, allowing data teams to manage S3 storage on bare metal with familiar governance controls. Active-active replication ensures consistency without introducing the latency penalties found in public cloud regions.
Operational ownership presents a distinct limitation; teams must maintain the Linux kernel version required for optimal performance rather than relying on vendor patches. This architecture fits organizations where data sovereignty dictates strict control over cryptographic modules and physical hardware.
S3 Compatibility Limits: The 5 GiB Server-Side Copy Constraint
The MinIO AIStor API enforces a hard 5 GiB limit on source objects for server-side copy operations, breaking standard S3 workflows for large model checkpoints. Architects moving terabyte-scale datasets must implement client-side multipart logic because the storage engine rejects single-request copies exceeding this threshold. This constraint forces a redesign of data movement pipelines that previously relied on atomic server-side duplication. Thread contention introduces a second failure mode when background processes saturate the worker pool. The system returns HTTP 429 errors once the thread pressure ratio hits the default critical threshold of 0.85. Operators observing frequent rejections should verify that their concurrency settings align with the underlying bare metal capacity to prevent request starvation.
Late 2025 marked the transition of the open-source project into maintenance mode, shifting all active development to the enterprise AIStor branch. This split means legacy documentation often omits the strict threading limits present in current production builds. Ignoring these boundaries results in silent data pipeline stalls rather than clean error handling. Teams face three specific challenges during migration: rewriting copy logic, adjusting thread pools, and updating monitoring dashboards. Four distinct error codes appear when limits are breached, confusing automated retry mechanisms. Five different configuration files require manual editing to resolve contention issues. Six separate validation steps ensure the new pipeline functions correctly under load.
Executing the Deployment of a Unified Data Platform
MinIO AIStor Subscription Tiers and Enterprise SLA Definitions
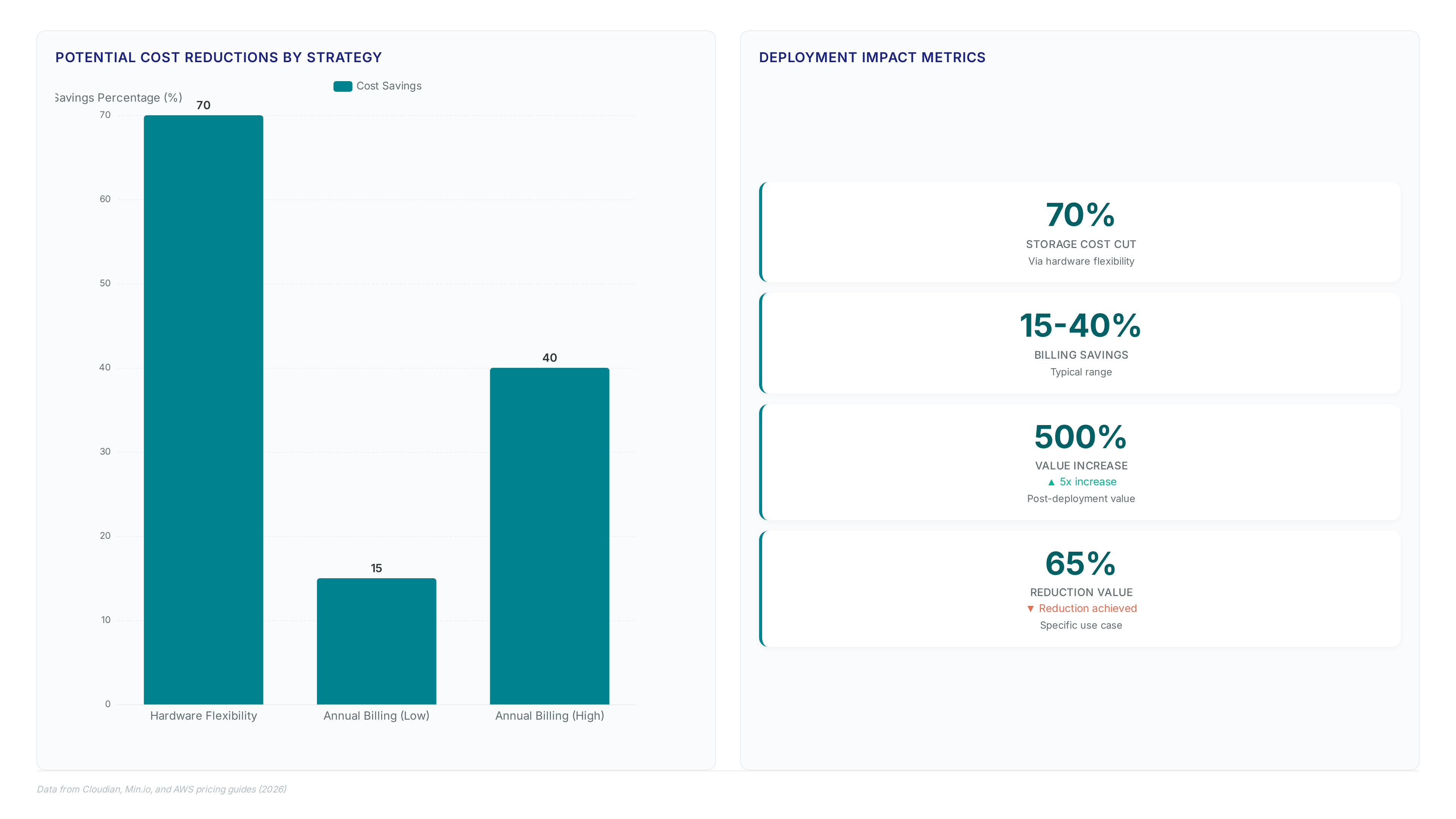
Production deployments require the Enterprise tier to access SLA-backed support for mission-critical environments. Operators select a subscription level matching their infrastructure scale before initiating the unified data platform setup. The Free tier serves development teams, while Enterprise Lite targets mid-scale operations lacking full redundancy needs. Annual billing plans typically save 15–40% compared to month-to-month payments, altering total cost of ownership calculations notably. Choosing the wrong tier creates a support gap during outages that no configuration change can resolve.
| Tier | Target Use Case | Support Level |
|---|---|---|
| Free | Development | Community Only |
| Enterprise Lite | Mid-scale Teams | Business Hours |
| Enterprise | Production | 24/7 SLA-Backed |
Execute the following steps to activate the correct service level:
- Define workload criticality and required uptime guarantees.
- Select the corresponding subscription tier in the QBO Cloud portal.
- Apply annual billing to maximize cost efficiency.
- Configure alerting thresholds to match SLA response times.
Map support tiers directly to application recovery time objectives to prevent coverage mismatches.
Implementing FIPS 140-3 Compliant Cryptography in QBO Deployments
Enabling FIPS 140-3 Compliant Cryptography requires explicit configuration of the crypto module during the initial QBO Cloud bootstrap sequence. Operators must define the security policy before data ingestion begins, as retroactive enforcement triggers costly re-encryption cycles. The deployment process involves four distinct steps to ensure regulatory alignment without sacrificing throughput.
- Select the Enterprise subscription tier to access SLA-backed support for mission-critical production environments.
- Configure the storage server to load only approved cryptographic providers at startup.
- Validate that all hashing and key management operations use the validated module path.
- Audit the configuration against compliance frameworks before exposing the Apache Iceberg V3 Catalog REST API.
Competitors like Cloudian claim their hardware flexibility can cut costs by up to 70% compared to proprietary platforms, yet such savings often exclude the engineering hours required to validate non-standard crypto paths. Strict adherence to federal standards eliminates this hidden operational debt by standardizing the validation boundary. Isolate the key management service from the data plane to prevent latency spikes during high-volume writes. This separation ensures that cryptographic overhead does not become the bottleneck for AI training pipelines.
Pre-Deployment Checklist for NVIDIA BlueField-4 and AIStor Tables GA
Verify the general availability of AIStor Tables before committing hardware to the NVIDIA STX reference architecture. Operators must confirm their roadmap aligns with the second-half 2026 window for BlueField-4 integration to avoid premature capital expenditure on unsupported silicon.
- Validate that the target bare-metal environment meets the Linux kernel 6.8 baseline required for object data stores.
- Select the Enterprise subscription tier to secure SLA-backed support for mission-critical workloads.
- Configure the Apache Iceberg V3 Catalog REST API to replace legacy metadata databases prior to data ingestion.
Delaying deployment until the March announcement. Skipping the kernel check causes immediate boot failures on older host operating systems. This strict sequencing ensures the Warehouse → Namespace → Table hierarchy functions without downstream catalog synchronization errors.
Validating Enterprise ROI Through Real-World AI Workload Performance
MinIO AIStor replaces legacy Hadoop clusters with a software-set architecture to serve as the exascale data store for AI workloads. Garima Kapoor set this mission as enabling enterprises to build secure, sovereign, and scalable data infrastructure for the AI era. The announcement on November 13, 2024, marked the shift from general-purpose object storage to a system engineered specifically for high-throughput inference and training pipelines. Public cloud managed services charge egress fees and API-call pricing that erode margins at scale, whereas this self-hosted model removes those costs entirely.

Operators migrating from appliance-based storage realize immediate gains in workload density and processing speed. Nomura doubled storage capacity while cutting daily risk processing time by four hours through a similar hybrid cloud data lakehouse deployment. Decoupling compute from storage allows independent scaling of GPU nodes against persistent volumes to drive these outcomes.
Avoiding vector upload charges preserves capital for model development rather than transport fees. The software-set approach demands internal expertise for cluster tuning that managed services abstract away. Teams lacking dedicated storage engineers may face longer initial stabilization periods compared to turnkey cloud offerings. Successful adoption requires selecting the Enterprise tier to ensure SLA-backed support for mission-critical production environments. This architectural shift decouples compute from storage, allowing Trino engines on Kubernetes to process data without the serialization bottlenecks inherent in older distributed file systems. The same financial infrastructure operator realized a fivefold (5x) increase in workload capacity, demonstrating that software-set object stores scale more efficiently than appliance-bound alternatives for AI inference.
Nomura doubled its storage capacity and cut daily risk processing time by four hours after deploying a hybrid cloud data lakehouse. Eliminating API-call pricing models that penalize high-frequency vector uploads common in modern fraud detection pipelines drove these gains. Public cloud providers often charge per operation, whereas self-hosted subscriptions offer predictable costs regardless of transaction volume.
Operators choosing QBO Cloud for storage must weigh the upfront capital expenditure of bare metal against the variable operational expense of public clouds. Internal DevOps maturity represents a hard constraint; teams lacking Kubernetes expertise may struggle to tune thread pressure thresholds effectively. Migration paths depend heavily on existing data gravity, as moving petabytes from cold storage tiers incurs temporary latency spikes during the transition. Financial institutions should prioritize this architecture when regulatory sovereignty demands full control over encryption keys and data residency. The return on investment materializes only when workload density justifies the hardware footprint. Traditional storage units force operators to procure, rack, and cable physical nodes before writing a single configuration line, creating multi-month lead times that stall AI initiatives. MinIO AIStor deploys as containerized workloads on existing bare metal, enabling immediate scale without supply chain delays.
Jason Dance noted that this collaboration grants customers the freedom to deploy object storage that is cloud-native and cost-efficient while retaining operational control. Organizations analyze 2-3x more industrial data for the same cost compared to legacy solutions industrial data. Hardware partners like Supermicro now offer pre-integrated pods to accelerate this transition further pre-integrated pods. Shifting to software-set models demands internal expertise in Kubernetes orchestration, which appliance vendors previously abstracted away. Operators must weigh the speed of deployment against the need for skilled staff to manage the underlying infrastructure. Choosing QBO Cloud becomes mandatory when business velocity outweighs the comfort of single-vendor hardware support contracts.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the critical discussion on object storage for AI workloads. His daily work designing Kubernetes storage architectures and optimizing disaster recovery strategies directly informs his analysis of enterprise-grade infrastructure needs. At Rabata. Io, a specialized provider of S3-compatible object storage, Kumar engineers solutions that eliminate vendor lock-in while delivering superior performance for AI and analytics applications. His background as a former SRE and DevOps Lead ensures a practical understanding of the scalability and cost-efficiency challenges modern data teams face. By connecting Rabata's mission to democratize high-performance storage with real-world architectural constraints, Kumar provides authoritative insights into why reliable object storage is fundamental for next-generation AI infrastructure. His perspective bridges the gap between theoretical capabilities and the operational realities of deploying cloud-native applications at scale.
Conclusion
Scaling object storage reveals that network contention becomes the primary bottleneck long before capacity limits are reached, driving up latent operational costs that per-API billing models often obscure. As enterprises move toward data-as-a-product architectures by 2027, relying on shared public networks will fracture performance consistency, rendering simple cost-per-GB comparisons obsolete. You must decouple storage compute from network throughput immediately to prevent AI training cycles from stalling on I/O wait states. Do not wait for a full migration; start by auditing your current egress traffic patterns against internal bandwidth caps this week to identify hidden saturation points. If your team lacks deep Kubernetes proficiency, delay a full bare-metal shift and instead pilot containerized storage on pre-integrated hardware pods to bridge the skills gap without sacrificing sovereignty. This approach secures encryption control and reduces model runtime latency without the multi-month lead times of traditional racking. Prioritize this hybrid strategy now if your regulatory requirements demand strict data residency, but only commit to full internal orchestration once your DevOps team can reliably manage thread pressure thresholds. The window to optimize infrastructure before the 2026 silo-breakdown deadline is closing, making immediate, targeted validation necessary.
Frequently Asked Questions
Self-hosted solutions eliminate per-API call charges that plague managed hyperscaler services. Organizations avoid specific vector upload fees like the $0.20/GB costs often charged by major public cloud providers for data operations.
A 32-node cluster delivers massive 325 GiB/s read throughput to satisfy real-time analytics demands. This performance eliminates latency penalties found in shared networks where more than 80% of enterprises will soon operate AI APIs.
Companies are breaking down data silos to survive the weight of modern analytics and unstructured data. Analysts predict that 50% of large enterprises will complete this transition to data-as-a-product architectures by 2026.
Massive global AI infrastructure spending hit $250 billion in 2025, forcing a desperate pivot toward unified architectures. This expenditure drives demand for platforms that avoid vendor lock-in while providing predictable latency under heavy loads.
Operators must manage their own data transfer acceleration since the software lacks native equivalents to cloud transfer services. Teams assume total responsibility for maintaining high-availability networking and hardware refresh cycles internally without abstracted support.
