Local uploads fix global distance for R2 writes
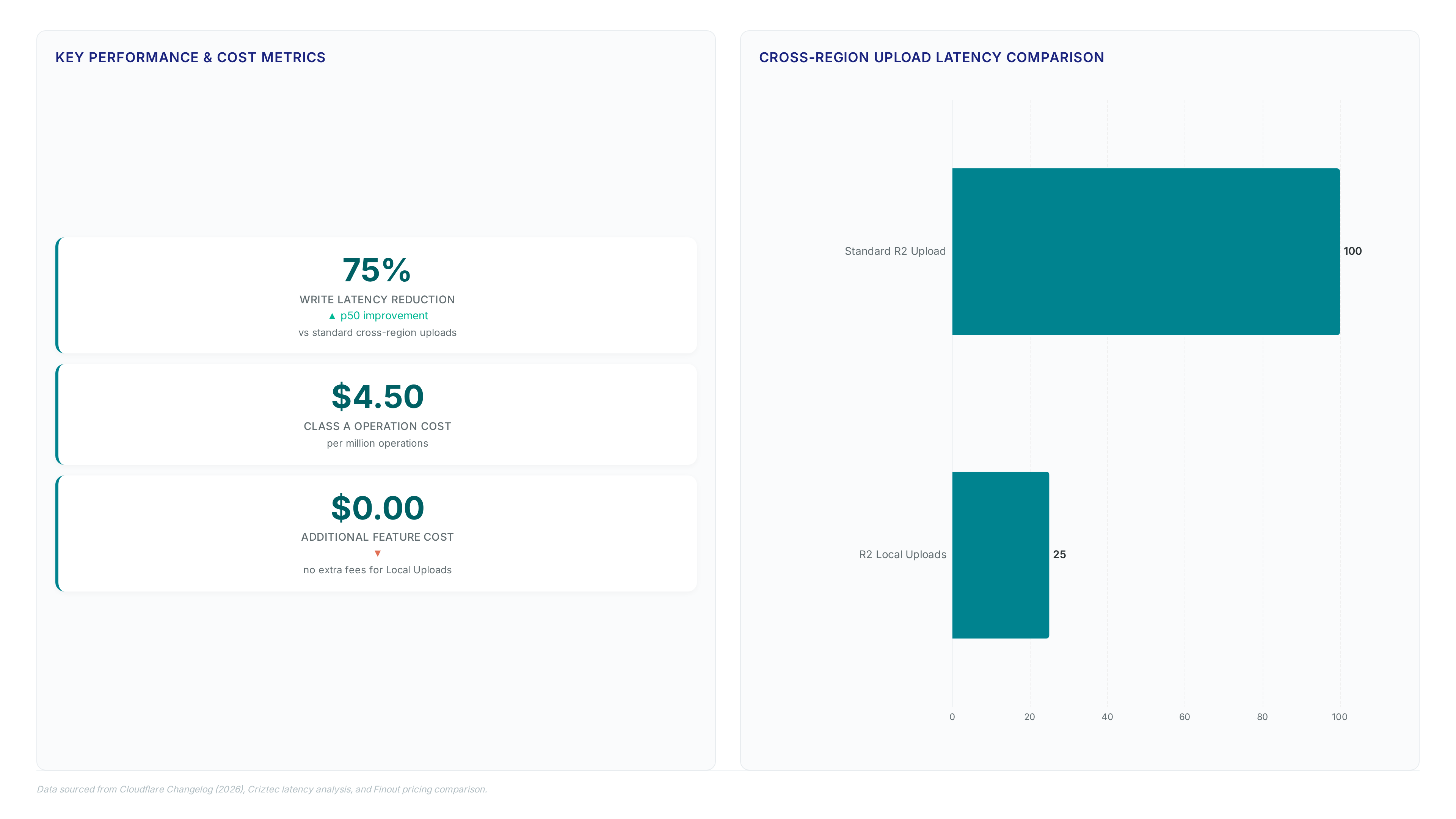
A 75% reduction in upload latency proves Local Uploads finally solves the global distance problem. This feature transforms R2 object storage by decoupling immediate client ingest from asynchronous backend replication, rendering traditional cross-region bottlenecks obsolete for AI and hybrid cloud workflows.
Frank Chen's February 2026 announcement details a architecture where data writes to a proximate location before syncing to the primary bucket, maintaining strong consistency without sacrificing speed. Synthetic benchmarks from Cloudflare demonstrate that Time to Last Byte drops from two seconds to roughly 500ms when clients upload from Western North America to an Asia-Pacific bucket. (Cloudflare's r2 local uploads) This shift directly addresses the durability and cost governance demands defining 2026 storage strategies, offering a distinct advantage over AWS S3 Transfer Acceleration which often layers complex pricing onto global transfers.
Readers will examine the specific role of local uploads within global object storage, dissect the asynchronous replication workflow driving these performance gains, and compare this beta feature against standard R2 configurations and competitor solutions. By using the R2 Gateway Worker and Durable Object Metadata Service, organizations can now achieve truly global write speeds without the egress fees or architectural friction that have long plagued distributed data ingestion.
The Role of Local Uploads in Global Object Storage Architecture
R2 Local Uploads: Decoupling Ingest from Replication
Frank Chen announced this open beta on 3 Feb 2026 to solve the distance problem affecting global AI workloads. Local Uploads terminates writes at the nearest edge node before asynchronous replication to the home bucket region. The mechanism decouples ingest from replication, allowing object data to become immediately accessible despite pending background transfers. Time to Last Byte drops by 75% when clients upload from regions distinct from the bucket location. Strong consistency persists because the metadata service commits the object state upon local write completion, not after cross-region copy finishes. This architectural shift eliminates the variabilities inherent in long-haul TCP streams during the initial data push. Operators gain write performance without relocating buckets or paying cross-region transfer fees. The cost is asynchronous durability; data resides temporarily in the edge region before reaching the primary storage infrastructure. Applications requiring immediate geographic redundancy at the moment of write completion must account for this replication lag window. Standard S3 API calls function without modification, masking the underlying complexity of distributed storage coordination.
AI training pipelines frequently ingest telemetry from globally distributed sensors, making the distance problem a primary bottleneck for model speed. Standard flows force every byte to traverse the full path to the home bucket region before acknowledgment, introducing variability that stalls upstream processing. The R2 Gateway Worker accepts the stream locally, commits metadata immediately, and queues asynchronous replication tasks for background completion. This architectural shift delivers measurable gains for applications requiring rapid iteration on large datasets without moving the primary bucket location. Unlike AWS S3 Transfer Acceleration, which often layers additional complexity and costs onto cross-region transfers, R2 Local Uploads optimizes the workflow without extra fees beyond standard operations. The mechanism supports existing S3 API clients and Workers Bindings with zero code modification, preserving operational continuity during migration.
Downstream consumers require specific design patterns to handle objects logically committed but physically local to the ingest region during the sync window. Strong consistency applies only to the metadata state while the physical data remains in transit until the replication task finishes. This limitation favors ingestion velocity over immediate global durability, a constraint acceptable for most AI logging workloads but potentially risky for financial ledgers requiring instant multi-region redundancy. Global applications gain significant performance headroom by decoupling the write acknowledgment from the physical data placement.
Direct regional writes stream encrypted bytes to the home bucket region after R2 Gateway Worker authentication. Standard flows introduce latency variability when clients and buckets occupy distinct geographic zones, forcing traffic across long-haul links before acknowledgment. The R2 Gateway Worker routes these requests globally, yet data travels the full distance to the storage infrastructure where the bucket resides. This architecture contrasts with Local Uploads, which terminates the write at the nearest edge node to eliminate cross-region lag during ingestion.
| Feature | Direct Regional Write | Local Uploads Flow |
|---|---|---|
| Write Path | Client to Home Region | Client to Nearest Edge |
| Replication | Synchronous (Blocking) | Asynchronous (Background) |
| Latency Driver | Physical Distance | Edge Proximity |
| Consistency Model | Strong (Immediate) | Strong (Immediate) |
Operators gain immediate readability while background tasks handle data movement to the home region. AWS S3 Transfer Acceleration optimizes routing but still uploads to a central bucket, whereas R2 avoids this bottleneck by decoupling ingest from storage location. This distinction eliminates the need for complex acceleration configurations or extra fees beyond standard operations. The constraint involves jurisdictional restrictions, as buckets with specific data residency requirements cannot apply this edge-terminated workflow. Network architects must verify bucket policies before enabling edge writes to avoid compliance violations in regulated environments.
Inside the Asynchronous Replication Workflow and Performance Gains
Atomic Metadata Publishing with Durable Objects and Replica Keys
Three atomic operations execute when publishing metadata: storing object details, creating a pending replica key, and marking the replication task. The pending replica key holds the full replication plan, including the count of required transfers, ensuring the system tracks every outstanding copy job. This mechanism allows the Durable Object Metadata Service to commit the object state immediately after the local write finishes, decoupling ingest from the physical movement of bytes. Data becomes immediately accessible even while background processes handle the asynchronous transfer to the home bucket region. Cloudflare Queues manage the resulting replication markers, pulling tasks based on timestamp keys to regulate flow across the global network. This pull-based pipeline prevents head-of-line blocking that typically stalls synchronous writes during cross-region transit. Operators gain consistent acknowledgment times regardless of physical distance between the client and the storage tier.
| Operation | Function | Consistency Guarantee |
|---|---|---|
| Store Metadata | Records object key and checksum | Strong (Synchronous) |
| Pending Replica Key | Tracks required replication count | Durable (Atomic) |
| Task Marker | Keys replication job by timestamp | Ordered (Queued) |
However, this architecture introduces a transient state where data exists locally before reaching the primary bucket. Network engineers must account for this brief window when designing audit trails or compliance checks that rely on data presence in the home region. The R2 Gateway Worker abstracts this complexity, yet the underlying replication lag remains a variable for dependent systems polling the origin bucket directly.
Simulating Cross-Region Workflows: Western North America to Asia-Pacific
Synthetic tests measured the impact by simulating a cross-region upload workflow where a test client was deployed in Western North America and an R2 bucket was configured with a location hint for Asia-Pacific. The client performed around 20 PutObject requests per second, generating sustained load to validate throughput under realistic conditions. Cloudflare Queues serve as the asynchronous processing component, allowing control over the processing rate and providing built-in failure handling like retries and dead letter queues. This setup isolates the replication task from the initial write commitment, ensuring the foreground operation completes without waiting for background transfers.
R2 shards replication tasks across multiple queues per storage region to manage load without blocking the initial upload response. Operators must verify that background copying functions independently from the foreground write path to prevent latency regression. Validation requires confirming that the R2 Gateway returns a 200 response before the remote transfer initiates, ensuring the client experiences only local write times. Failure to shard these tasks correctly concentrates load on single queues, creating bottlenecks that negate the architectural benefits of edge-native ingestion.
| Validation Step | Expected Behavior | Failure Symptom |
|---|---|---|
| Queue Distribution | Tasks spread across regional shards | Single queue backlog spikes |
| Response Timing | 200 OK precedes remote copy | Client waits for cross-region RTT |
| Task Visibility | Replication marker visible in queue | Missing pending replica keys |
Developers should inspect the pending replica key to confirm the system tracks every outstanding copy job accurately. This mechanism allows the Durable Object Metadata Service to commit object state immediately after the local write finishes. The asynchronous processing component handles retries and dead-letter logic without impacting user-facing latency. If the initial upload response delays, the replication task likely executed synchronously due to misconfiguration or queue exhaustion. Such blocking behavior reintroduces the distance penalty that Local Uploads aims to eliminate.
Comparing Local Uploads Against Standard R2 and Competitor Solutions
Local Uploads vs Standard R2 Upload Request Flows
Standard R2 writes pause until cross-region storage confirms receipt, while Local Uploads finish the write at the nearest edge node instantly. This architectural change separates data ingestion from final bucket replication, letting the R2 Gateway send a success signal before the object reaches its home region. Turning on this optimization adds no additional cost beyond normal operation fees, keeping billing predictable for high-volume ingest patterns. Requests still pay standard Class A operation costs, so the pricing model stays consistent no matter which write path gets selected.
The pending replica key monitors outstanding transfers to maintain strong consistency even as bytes move asynchronously in the background. Operators see substantial speed gains for global clients but must accept that physical data movement happens after the client gets an acknowledgment. This design creates a short window where data sits at the edge yet has not landed in primary storage infrastructure. Such a constraint favors applications needing low-latency writes over those requiring immediate physical durability in the home region. The replication task marker ensures eventual delivery without stopping the foreground transaction. Teams should activate this mode if users span continents while the bucket stays fixed in one region, like Western North America clients writing to Asia-Pacific storage. Architecture separates ingest from replication, turning multi-second commits into sub-second operations while keeping strong consistency intact. This method solves the distance problem found in edge-native AI workloads where latency reduction acts as a primary bottleneck for real-time data ingestion. Standard R2 writes wait for round-trip confirmation to the home region, whereas Local Uploads terminate at the nearest edge node.
| Dimension | Standard R2 Upload | Local Uploads Enabled |
|---|---|---|
| Write Path | Direct to home region storage | Nearest edge PoP then async copy |
| Latency Profile | High variability based on distance | Consistent sub-second response times |
| Cost Structure | Standard Class A fees only | Standard Class A fees only |
| Consistency Model | Strong immediately | Strong immediately |
Enabling the feature incurs no additional cost beyond standard operation pricing, making it viable for high-volume telemetry or media ingestion pipelines. Jurisdiction-restricted buckets cannot use this optimization because data sovereignty constraints demand immediate home-region writes. Teams must verify that asynchronous replication queues handle burst traffic without exhausting retry limits during network partitions. Mission and Vision recommends enabling this setting for any bucket serving a global user base where upload speed directly impacts user retention.
R2 Zero-Egress Pricing vs AWS S3 and Azure Blob Costs
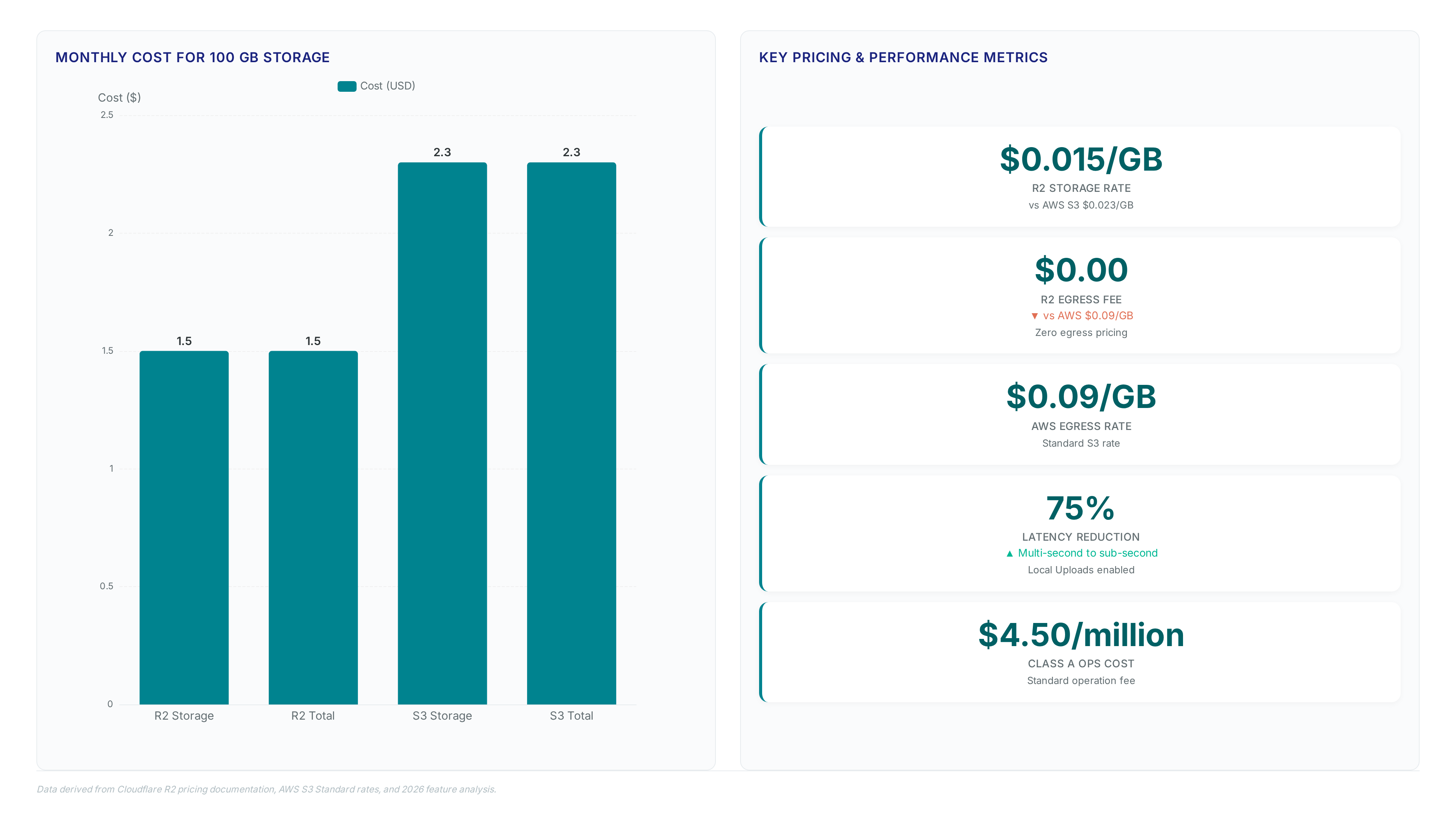
Cloudflare R2 storage costs $0.015 per GB per month with zero egress fees, contrasting sharply with AWS S3 Standard rates of $0.023 per GB plus $0.09 per GB for data egress. This pricing structure removes the variable cost penalty operators face when retrieving large datasets from cross-region buckets. A hypothetical monthly bill for 100 GB of storage on Amazon S3 Standard would be roughly $2.30 for storage alone, but adding typical egress fees could push total costs notably higher compared to R2's flat $1.50 storage cost with no egress fees. Google Cloud Storage charges up to $0.12 per GB for egress, the highest among substantial providers, creating severe financial friction for analytics workloads requiring frequent data movement. AWS S3 Transfer Acceleration and Azure Geo-Redundant Storage introduce additional complexity and costs for cross-region transfers, whereas R2 Local Uploads aims to optimize this without extra fees beyond standard operations. The limitation is that R2 lacks the granular storage class tiers of AWS, forcing cold data into the same pricing bucket as hot data. Operators must weigh the simplicity of flat-rate billing against the potential savings of archiving rarely accessed objects on hyperscalers. Mission and Vision recommends calculating total cost of ownership based on actual egress patterns rather than advertised storage rates.
Implementing Local Uploads Configuration and Monitoring Strategies
Implementation: Wrangler CLI Configuration for Local Uploads and Replication Tasks
Execute `npx wrangler r2 bucket local-uploads enable [BUCKET]` to activate edge ingestion without manual queue provisioning.
- Run the command targeting the specific bucket name to trigger metadata updates.
- Verify the CLI returns a success status indicating the pending replica key creation.
- Confirm the system generates a replication task marker keyed by timestamp for background processing.
The CLI interaction creates atomic operations that store object metadata while deferring physical data movement. This configuration uses Cloudflare Queues to manage asynchronous copying, ensuring the foreground write path remains unblocked by cross-region latency.
- Navigate to the specific R2 bucket settings within the dashboard interface.
- Select the Metrics tab to expose the Request Distribution by Region visualization.
- Correlate high-latency write spikes with source regions lacking local write endpoints.
- Enable Local Uploads via the settings panel or Wrangler CLI to activate edge ingestion.
- Monitor Cloudflare Queues depth to ensure replication tasks process without backlog accumulation.
The system shards replication work across multiple queues per storage region to manage load effectively. A tension exists between immediate write acknowledgment and final consistency; while data is accessible instantly, the background copy job introduces a window where durability depends on the source edge node. Operators must verify that queue consumers successfully dispatch jobs to the Gateway Worker before considering the replication cycle complete. Failure to monitor these queues risks silent data loss if edge nodes fail prior to asynchronous copy completion. This architectural dependency means visibility into queue health is as vital as observing the initial write success rate.
Troubleshooting Failed Replication Tasks and Dead Letter Queue Inspection
Replication stalls often stem from misconfigured queue sharding or atomic metadata publishing failures.
- Verify Cloudflare Queues sharding matches the destination storage region to prevent backpressure.
- Inspect the dead letter queue for tasks where the pending replica key failed atomic commitment.
- Confirm the replication task marker timestamp allows immediate processing by the polling service.
| Failure Mode | Diagnostic Signal | Resolution Action |
|---|---|---|
| Queue Backpressure | Rising consumer lag metrics | Increase shard count per region |
| Atomic Commit Fail | Missing pending replica key | Retry metadata publish operation |
| DLQ Accumulation | Repeated retry exhaustion | Inspect payload for corruption |
Background copies stall when the pull-based replication pipeline cannot consume tasks quicker than they arrive. Operators must distinguish between network transit delays and genuine processing failures within the asynchronous copying workflow. A common oversight involves ignoring the Request Distribution by Region graph, which reveals if traffic spikes exceed queue throughput limits. Unlike synchronous writes, failed background jobs do not block client acknowledgments, creating a silent consistency risk if unmonitored. The Cloudflare Dashboard provides visibility into these deferred operations, yet many teams skip correlating DLQ growth with specific geographic ingress points. Mission and Vision recommends automating alerts on DLQ depth rather than relying on manual inspection during incident response. This strategy prevents data accumulation in edge locations while the primary bucket remains unaware of incomplete synchronization.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to the discussion on R2 Local Uploads. His daily work designing disaster recovery systems and scaling infrastructure for AI/ML startups directly aligns with the critical need to solve the "distance problem" in global object storage. At Rabata. Io, a specialized S3-compatible provider focused on democratizing enterprise storage, Kumar routinely addresses the latency bottlenecks that hinder high-performance data ingestion. This practical experience makes him uniquely qualified to analyze how decoupling ingest from replication transforms upload speeds for distributed teams. By using his background in optimizing cloud-native applications, he connects the technical mechanics of R2's new beta feature to real-world performance gains. His insights bridge the gap between theoretical network improvements and the tangible requirements of modern AI workloads demanding fast, consistent, and globally accessible data storage without vendor lock-in.
Conclusion
Scaling distributed ingestion reveals that queue backpressure becomes the primary bottleneck long before storage capacity limits are reached. As asynchronous replication volumes grow, the operational cost shifts from simple per-GB fees to the engineering hours required to debug silent consistency gaps across regions. While R2 eliminates egress charges, relying solely on cost savings without reliable dead letter queue monitoring invites data integrity risks that compound over time. Teams must treat replication lag as a critical service level indicator rather than an acceptable side effect of edge architecture.
Adopt a hybrid multi-cloud strategy by Q3 2026 only if your current observability stack can correlate geographic ingress spikes with specific queue shard failures in real-time. Do not migrate legacy monolithic workloads until you have validated that your atomic metadata publishing can sustain peak throughput without stalling background copies. The window for naive "lift-and-shift" migrations to edge storage is closing as AI-driven data gravity demands stricter consistency guarantees.
Start by auditing your current DLQ depth trends against regional traffic maps this week to identify hidden synchronization failures before they impact downstream analytics pipelines.
Frequently Asked Questions
Upload speeds improve significantly with a 75% reduction in total request duration. This performance gain occurs because data writes locally before asynchronous replication to the home bucket region completes.
The synthetic benchmarks measured performance using objects of 5 MB size uploaded continuously. These tests confirmed the 75% latency drop when clients upload from regions distinct from the bucket.
No code changes are needed since standard S3 API calls function without modification. The R2 Gateway Worker handles the complex distributed storage coordination automatically behind the scenes for developers.
Yes, data becomes immediately accessible and stays strongly consistent upon local write completion. The metadata service commits the object state instantly while physical data replicates asynchronously in the background.
You can enable this feature in the Cloudflare Dashboard settings or via a single Wrangler command. This activates the architecture where data writes close to the client first.
