File streaming kills PBscale data migration now
Suite Studios kills data migration. On February 17, 2026, they enabled zero migration deployment for PB-scale workflows. The industry pivot to cloud-native platforms is done; Gartner predicts 95% of new workloads will reside there by 2027. Clinging to legacy sync models is strategic suicide. This update proves S3 compatible storage can finally serve as the primary compute surface without proprietary translation layers choking creative output.
Byte-range streaming architecture delivers local-disk-like performance by fetching only necessary data chunks. No more mirroring massive files locally. We contrast this single source of truth model against traditional file sync solutions that waste bandwidth duplicating entire datasets across global teams. The analysis covers integration with existing Media Asset Management systems, proving real-time performance does not require ripping out established governance or security policies.
Re-ingesting petabytes for cloud access is dead. By operating natively on object storage, organizations retain full Identity Access Management control while unlocking instant global collaboration. This is the necessary infrastructure shift for studios demanding speed without sacrificing data sovereignty in a cloud-native dominance environment.
The Role of S3 Native File Streaming in Modern Media Infrastructure
S3 Native File Streaming and Byte-Range Request Mechanics
S3 Native File Streaming treats massive media assets as standard objects. No proprietary filesystem layers. No data migration. Announced on February 17, 2026, this architecture eliminates the friction of copying PB-scale datasets by accessing customer-owned storage directly. The mechanism relies on byte-range file streaming to fetch only specific data segments required for immediate playback or editing. This approach delivers predictable and reliable access across varying network conditions while avoiding full file downloads. Traditional mount tools struggle with latency on large files; this method achieves local-disk-like performance through selective data retrieval.
Validate range request tuning against specific codec profiles before scaling to petabyte workloads.
Zero Migration Workflows for PB-Scale Media Datasets
Byte-range file streaming eliminates data copying by enabling direct edits on customer-owned S3 objects. Creative teams establish a single source of truth by accessing existing petabyte-scale datasets stored in any S3 compatible object storage environment without re-ingestion. This architecture prevents version sprawl common in distributed workflows where file duplication creates conflicting edits across global offices. Traditional NAS-to-Cloud migrations often demand weeks of data transfer before production begins. This approach allows immediate operation on live archives. The platform functions as a low-latency access layer, enabling global collaboration while data remains stationary in the chosen storage bucket.
Eliminating migration removes the risk of data corruption during transfer but introduces dependency on network stability for real-time playback. Operators must ensure sufficient bandwidth to sustain byte-range requests during peak editing windows. Fortune 500 companies use this model to maintain governance over petabyte-scale datasets. The cost shifts from storage expenses to network engineering requirements for consistent throughput.
Native S3 Access Versus Proprietary Filesystem Layers
S3 Native File Streaming eliminates proprietary filesystem layers by reading standard objects directly via byte-range requests. Traditional architectures rely on gateways that translate object storage into block protocols, creating latency bottlenecks during large file access. This new approach bypasses those translation costs entirely. Teams achieve zero migration. Legacy methods often require weeks of data transfer before production begins, whereas this model enables immediate workflow initiation. Performance metrics indicate local-disk-like performance.
| Feature | Proprietary Layers | Native S3 Access |
|---|---|---|
| Data Location | Mirrored local cache | Customer-owned object store |
| Startup Time | Days for synchronization | Instant access |
| Storage Cost | Double (local + cloud) | Single (cloud only) |
| Version Control | Manual merge required | Automatic single source |
Scott Millar, CTO of MDLR Technologies, says the innovation removes friction from workflow and lets teams move quicker. The strategic pivot removes the operational burden of managing duplicate datasets. However, reliance on network throughput remains a constraint; poor connectivity degrades byte-range fetch speeds regardless of architecture. Industry forecasts suggest 95% of new digital workloads will reside on cloud-native platforms by 2027. This shift demands storage solutions that scale without forcing data movement.
Inside the Architecture of Byte-Range Streaming and Zero Migration Access
Mechanics: Byte-Range File Streaming Mechanics for Standard S3 Objects
Direct reads of standard S3 objects occur via HTTP GET requests specifying byte offsets, bypassing full-file transfers entirely. Suite functions as a streaming access layer that issues partial content requests to fetch only the data segments required for immediate playback or editing. This mechanism avoids the latency penalties of traditional gateway translations by interacting directly with customer-owned storage buckets. Unlike competitors that impose proprietary metadata layers to virtualize external buckets, this architecture reads/writes standard S3 objects directly without creating intermediate directory structures. The process maintains a single source of truth because edits commit immediately to the underlying object rather than syncing through a separate cache domain.
Operational efficiency stems from fetching minimal data chunks instead of mirroring entire assets locally. Teams achieve predictable and reliable access. This approach eliminates the need for data migration, duplication, or re-ingestion before collaboration begins.
| Feature | Proprietary Filesystem Layer | S3 Native Streaming |
|---|---|---|
| Data Path | Gateway translation required | Direct object access |
| Metadata | Separate domain management | Native bucket attributes |
| Deployment | Ingest and sync period | Instant enablement |
The cost of maintaining parallel metadata domains is measurable in both storage fees and synchronization delays. Removing the ingest phase allows operators to use existing Identity Access Management policies without reconfiguring permissions for a new filesystem namespace. However, performance relies heavily on the underlying object store's ability to serve high-frequency range requests without throttling. Validate provider rate limits before deploying PB-scale workflows to avoid unexpected request denials.
Real-World Deployment for Nike and Sabrina Carpenter Music Video Workflows
The Sabrina Carpenter "Tears" music video production validated local-disk-like performance on PB-scale datasets without data migration. Creative teams at brands like Nike bypass traditional ingest bottlenecks by editing directly on customer-owned storage. This deployment model eliminates duplication and syncing, allowing editors in Adobe Premiere Pro to work instantly. The architecture streams only required byte ranges, ensuring global collaboration remains fast regardless of physical location. Productions achieve this efficiency while maintaining a single source of truth across distributed creative groups.
Real-time performance depends entirely on network stability between the editor and the S3 bucket endpoint. A distant region selection introduces latency that byte-range requests cannot fully mask, forcing operators to place compute resources near storage buckets. The cost benefit is measurable, with some productions reporting operations at 50% the expense of competitor hardware logistics. This saving stems from removed egress fees and eliminated local scratch disk purchases.
Global connectivity enables editors to work from anywhere, yet the low-latency access layer requires care. Security teams must balance open collaboration with strict bucket policies to avoid accidental data exposure during high-speed streaming sessions. The complexity shifts to identity management rather than simple network perimeter defense. Operators gain speed but lose the blunt instrument of physical isolation for protecting assets.
Zero Migration Deployment Versus Traditional NAS-to-Cloud Data Copying
Traditional NAS-to-Cloud migrations often require weeks of data copying before creative teams can begin workflows. S3 Native File Streaming eliminates this delay by enabling instant access to existing petabyte-scale datasets. The mechanism bypasses full-file transfers, streaming only required byte ranges directly from customer-owned buckets. This approach maintains a single source of truth and prevents version sprawl across global teams. Operators avoid the latency penalties associated with gateway translation layers.
The cost of traditional copying includes double storage fees during the transition period. Byte-range file streaming delivers local-disk-like performance. However, this model demands strong network connectivity to sustain real-time editing speeds. Poor bandwidth conditions degrade playback quality more visibly than in local NAS setups. Teams must validate upstream throughput before switching production workflows. The elimination of data duplication reduces total storage spend significantly. Verify IAM policies to secure direct object access.
S3 Native Streaming Versus Traditional File Sync and Competitor Solutions
Standard S3 Objects Versus Proprietary Filespaces Domains
Direct access to standard S3 objects avoids the metadata virtualization layer inherent in competitor architectures like LucidLink Connect. The architectural divergence centers on how storage buckets are presented to the client operating system. Suite Studios reads and writes files as standard S3 objects, ensuring that external tools interact with the native data format without translation. In contrast, LucidLink Connect uses APIs to integrate S3 buckets into its own Filespaces domain. This abstraction introduces a dependency where the vendor controls the metadata index, preventing direct access by other applications.
| Dimension | Standard S3 Object Access | Proprietary Filespaces Domain |
|---|---|---|
| Data Format | Native object keys | Virtualized directory entries |
| Tool Interop | Full compatibility | Vendor-locked client required |
| Migration Path | Zero re-ingestion | Mandatory data copy |
| Metadata Control | Customer-owned bucket | Vendor-managed index |
The cost of this abstraction extends beyond performance; it creates a hard lock-in where exiting the platform requires rebuilding the entire file hierarchy. Operators lose the ability to run lifecycle policies or analytics directly on the storage bucket because the vendor's layer owns the truth. Choosing a proprietary filesystem layer trades immediate convenience for long-term operational rigidity. Direct object access preserves the customer's right to manage their own data governance without intermediary gatekeepers.
Real-Time Byte-Range Streaming for Active Editing and Rendering
Active editing demands local-disk-like performance. Suite Studios targets real-time byte-range streaming specifically for active workflows like rendering, whereas AWS DataSync focuses on high-speed bulk data migration rather than interactive access. This distinction dictates operational adoption: teams should deploy native streaming when editors require instant random access to massive files without waiting for full downloads. Bulk sync utilities fail here because they replicate entire datasets before use, introducing unacceptable latency for frame-accurate scrubbing.
| Feature | S3 Native Streaming | Bulk Transfer Tools |
|---|---|---|
| Primary Use Case | Active editing and rendering | Data migration and backup |
| Data Access Method | Byte-range requests | Full file replication |
| Latency Impact | Negligible during playback | High until sync completes |
| Storage Overhead | Zero duplication | Requires local cache copy |
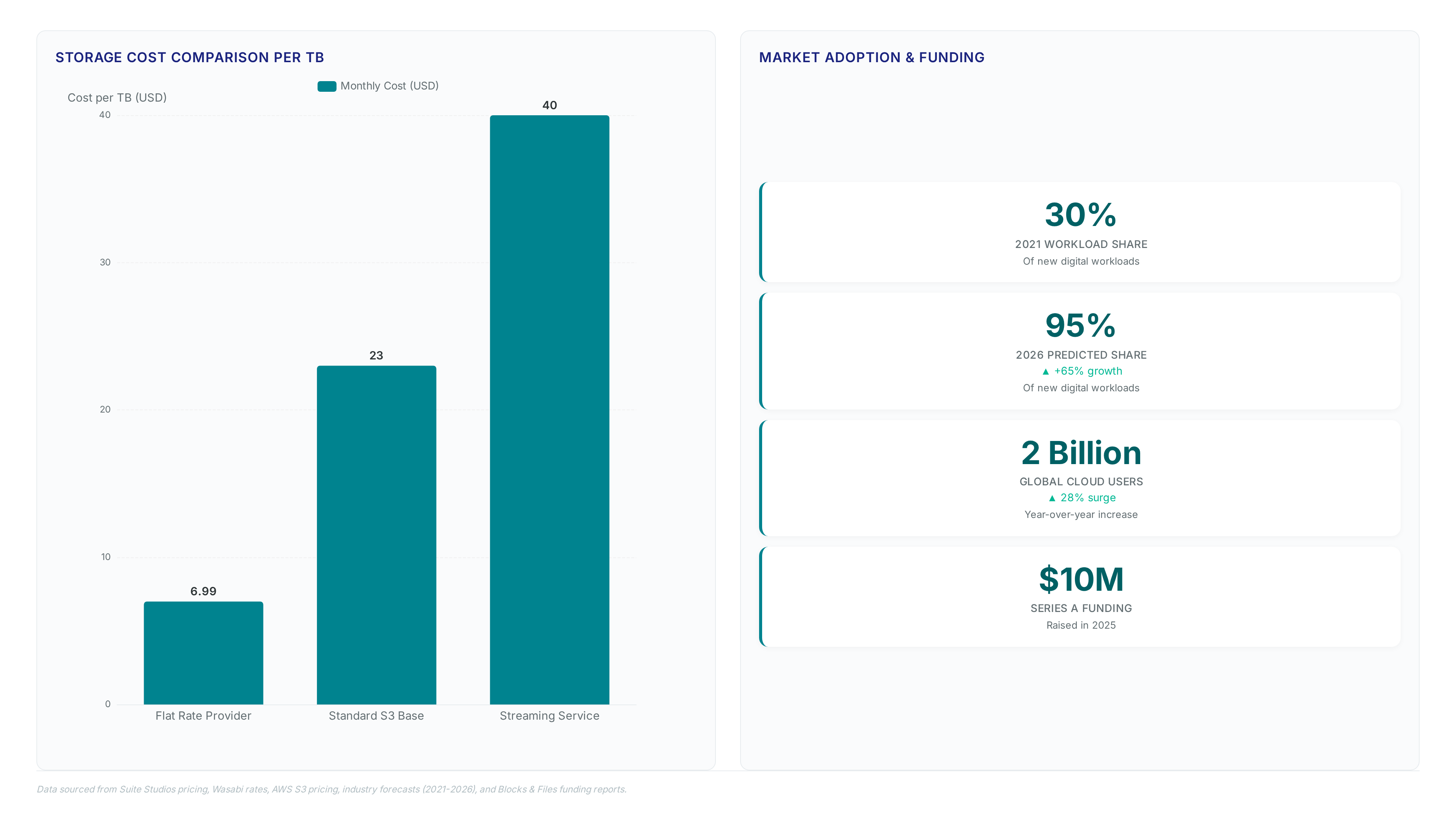
The cost implication involves trading per-gigabyte transfer fees for a managed service model starting at $40 per TB per month. While raw object storage costs less, this fee includes the streaming layer necessary for real-time collaboration. Operators must weigh the expense against the friction of maintaining dual storage tiers for active and archived data. Adoption makes sense when workflow velocity outweighs the marginal savings of DIY infrastructure. The limitation remains that organizations lacking S3-compatible backends must first migrate assets before using these byte-range requests. Evaluate current latency bottlenecks before committing to a streaming architecture.
Deploying S3 Native Streaming for Enterprise MAM and DAM Integration
Defining Gateway-Free S3 Integration for MAM and DAM Systems

Gateway-free integration requires connecting MAM systems directly to standard S3 objects without proprietary filesystem overlays. Operators must configure their media pipelines to bypass traditional NFS gateways that lock data into specific cloud vendor silos. This architectural shift eliminates the translation layers found in managed services like Google Filestore, which force datasets to reside within a single provider's infrastructure. True neutrality emerges when the streaming layer operates as an access mechanism atop any compatible bucket rather than a walled garden.
- Identify existing object storage buckets holding active media assets across AWS, Backblaze, or Cloudflare environments.
- Private Beta access began mid-February 2026, requiring direct registration before the General Availability window in April.
Operators must configure render nodes to mount the streaming layer without altering existing bucket permissions or object structures. This approach maintains a No Migration Architecture. Teams targeting petabyte workloads should prepare for volume-based pricing models designed specifically for massive scale rather than standard per-terabyte rates. The limitation here involves latency sensitivity; render farms located far from storage regions may experience slower initial frame loads despite byte-range efficiency.
- Register for beta access to obtain the client installer and license keys.
- Configure the render farm agents to point directly at existing S3 bucket endpoints.
- Validate byte-range requests by opening a large media file without full local caching.
Test failover scenarios where the streaming layer disconnects, ensuring render jobs pause gracefully rather than failing corruptly. The operational risk lies in assuming network stability equals storage availability; the streaming client adds a dependency that requires distinct monitoring separate from raw bucket health checks.
Evaluating Object Storage Costs: Wasabi Hot Storage Versus AWS Standard
Selecting backend storage requires balancing raw capacity fees against egress penalties for PB-scale media assets.
- Calculate baseline expenses using the $23.55/TB rate for AWS Standard, then add variable data transfer costs that inflate total ownership.
- Compare this flat fee structure against providers offering no egress fees, which stabilizes budgets for render-heavy workflows with unpredictable output volumes.
- Verify network performance metrics, as some free-tier options deliver a 28ms median Time to First Byte suitable for interactive editing sessions.
Deploying a gateway-free layer enables direct reads from standard S3 objects regardless of the underlying vendor. This flexibility lets engineers optimize for cost per access rather than cost per gigabyte stored. Prioritize egress models over raw storage rates for active creative pipelines. Teams must audit their access patterns before committing to a single provider for long-term deployments.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to the discussion on S3 native file streaming. His daily work designing scalable, disaster-resilient infrastructure for enterprise clients directly informs the technical realities of handling PB-scale datasets without proprietary filesystem layers. At Rabata. Io, a specialized provider of high-performance S3-compatible object storage, Kumar engineers solutions that eliminate vendor lock-in while maximizing throughput for AI/ML workflows. This article reflects his hands-on experience bridging the gap between raw object storage and real-time media collaboration tools. By using Rabata's GDPR-compliant data centers and transparent pricing models, Kumar demonstrates how modern platforms can stream massive files natively, removing the need for costly data migration. His background ensures the analysis remains grounded in practical infrastructure challenges faced by global creative teams today.
Conclusion
Scaling direct object access reveals that network jitter, not storage throughput, becomes the primary bottleneck for large-scale render farms. As teams expand beyond single-region deployments, the assumption that cloud reliability equals application stability fails; the streaming client introduces a distinct failure domain that requires dedicated health checks separate from standard bucket metrics. Operational costs will silently inflate if engineers optimize solely for per-terabyte rates while ignoring the cumulative impact of retry logic on compute billable hours. Teams must shift their evaluation criteria from static storage pricing to flexible access economics immediately.
Organizations should commit to a hybrid storage strategy by Q3, reserving low-cost hot storage for active assets while maintaining high-performance tiers for latency-sensitive scratch data. Do not migrate entire archives until you have validated failover behavior under simulated packet loss. Start by instrumenting your current pipeline this week to measure Time to First Byte across different geographic zones before signing any new vendor contracts. Real cost savings emerge from matching access patterns to storage classes, not from chasing the lowest advertised headline rate.
Frequently Asked Questions
No, the solution enables zero migration deployment by accessing data directly. Teams avoid re-ingestion entirely while working on standard objects within their current S3 compatible storage environments.
It fetches only necessary data chunks rather than mirroring massive files locally. This selective retrieval delivers local-disk-like performance without wasting bandwidth on duplicating entire datasets across global teams.
Yes, it integrates with existing MAM and DAM systems without requiring proprietary translation layers. The platform fits into established pipelines while maintaining full Identity Access Management control for IT teams.
The upcoming feature will utilize volume-based pricing specifically designed for large scales. Exact per-TB rates remain undisclosed until the general availability release scheduled for April 2026.
Planned support includes AWS, Backblaze, Cloudflare, IBM, Azure, GCP, Wasabi, and on-premises deployments. This broad compatibility allows teams to connect instantly to existing buckets regardless of vendor choice.
