Direct Apache Iceberg query cuts latency now
Direct querying of Apache Iceberg tables now delivers 3x faster performance without moving data into warehouses. The 2026 environment is defined by diskless Kafka and Apache Iceberg, pushing real-time processing directly into the stream rather than batching it for later consumption.
Direct Query and SPICE engines interact with these new table structures to eliminate the latency and cost inherent in legacy OLAP systems. Organizations can bypass intermediate data layers, effectively treating the data lake as the primary computation engine rather than a passive archive. This shift removes the operational drag of maintaining separate data warehouses while preserving the governance required for enterprise-scale decision-making.
Teams using Amazon Quick for agentic AI insights gain a strategic edge. By integrating natural language interaction with native Iceberg support, business users gain immediate access to fresh data without demanding specialized machine learning expertise or complex pipeline orchestration. Visualization and automation coexist on a single, scalable storage foundation.
The Role of Apache Iceberg and S3 Tables in Modern Data Lake Architecture
Amazon S3 Tables function as a managed Apache Iceberg service launched in preview on December 3, 2024. This architecture uses a table bucket abstraction to store data in open format on customer-owned storage. The design eliminates intermediate data layers, allowing direct queries against the lake without replication. Statistics indicate 64.3% of Iceberg users deploy on AWS, validating the demand for native integration. Direct consumption removes pipeline latency yet introduces a dependency on specific metadata generation capabilities. Operators lose the flexibility to customize compaction strategies found in self-managed deployments. The cost is reduced operational overhead versus constrained control over low-level file organization.
Failure domains concentrate when separate warehousing layers disappear to create a single source of truth. A metadata service outage blocks all analytical access since no local cache exists. Teams must weigh the benefit of simplified architecture against the risk of centralized bottlenecks. Performance gains reach 3x faster speeds compared to standard Parquet layouts. Such improvements justify the migration for high-frequency analytics workloads requiring fresh data.
Amazon QuickSight enabled direct data source connectivity for S3 table buckets on May 4, 2026, eliminating intermediate extraction layers. This architecture supports Direct Query for live analysis and SPICE for cached acceleration without duplicating storage. Operators choose Direct Query when transactional freshness outweighs sub-second latency requirements, effectively treating the lake as a central source of truth. Quantitative finance benchmarks published in January 2025 demonstrated 52% faster query performance compared to legacy Hive-backed structures. The 3x faster query performance versus standard Parquet layouts reduces compute costs for ad-hoc exploration notably. Direct Query modes depend entirely on downstream engine optimization rather than local memory caching. High-concurrency dashboards may experience throttling if the underlying Iceberg REST Catalog API cannot sustain request volume. SPICE remains necessary for workloads requiring consistent sub-second response times across hundreds of simultaneous users.
Choosing S3 Tables over a dedicated warehouse avoids egress fees yet shifts complexity to catalog management. Teams lacking Spark fundamentals struggle to tune compaction strategies for optimal read paths. This operational overhead represents a hidden constraint for organizations migrating from fully managed SQL endpoints. Validate query patterns before disabling replication pipelines entirely.
S3 Tables vs Data Warehouse: Cost Reduction and Transaction Throughput
Amazon S3 Tables deliver a 90% potential reduction in S3 storage costs when migrating from Hive to Iceberg formats. Traditional data warehouses rely on proprietary compressed columnar storage managed internally, locking operators into vendor-specific scaling models. The table bucket abstraction preserves customer-owned storage while enabling open format interoperability. This architectural shift eliminates the double-storage penalty common during warehouse migration projects.
Transaction throughput differentiates these platforms notably for high-frequency workloads. S3 Tables support 10x higher transactions per second (TPS) compared to self-managed configurations, addressing concurrency bottlenecks found in legacy lake setups. A competitor migration case study reported a 57% reduction in monthly compute costs from $42,000 to a significantly lower amount by optimizing similar open-format engines. Teams accustomed to traditional SQL warehouses may find the transition easier than mastering Spark-based alternatives requiring extended learning curves. The learning curve for SQL-focused teams varies drastically depending on whether they adopt managed Iceberg services or complex Spark environments. Direct querying removes data movement latency but demands rigorous metadata management to sustain the promised 10x higher transactions per second (TPS). Validate TPS requirements against specific workload patterns before decommissioning legacy warehouse slots.
Inside the Direct Query Engine and SPICE Performance Dynamics
Direct Query Mode Mechanics for S3 Table Buckets
Direct Query mode executes SQL against the Iceberg REST Catalog API without extracting data into memory. This architecture bypasses the SPICE in-memory engine, forcing every visual interaction to hit the storage layer directly. Operators gain immediate consistency but accept higher latency per request compared to cached alternatives. The solution relies on four core layers to maintain transactional integrity across streaming inputs.
| Feature | Direct Query Mode | SPICE Engine |
|---|---|---|
| Data Location | Remote table bucket | Local in-memory cache |
| Freshness | Real-time | Scheduled refresh |
| Latency | Network-dependent | Sub-second |
| Cost Model | Compute-per-query | Capacity-reserved |
Queries traverse the Iceberg REST Catalog API to resolve metadata pointers before fetching columnar segments. This path requires valid AWS Signature Version 4 credentials for every downstream call to the storage endpoint. Policy documents attached to the resource cannot exceed 20 KB, restricting complex rule sets for granular access control. Administrators must configure IAM-based authorization to unify permissions across the catalog and query interfaces.
Compute efficiency battles data staleness here. Direct Query prevents stale dashboard artifacts yet spikes CPU usage on the coordinating cluster during peak concurrency. Reserve this mode for fraud detection workflows where seconds matter more than cost. Cached acceleration remains superior for static historical reporting where sub-second response times define user experience.
Visualizing Real-Time Kinesis Streams via Firehose to Iceberg
Transaction events flow from point-of-sale terminals through Amazon Kinesis Data Streams into S3 Tables without batch delays. This pipeline ingests mobile app signals and IoT payment data directly into the lake storage layer. Amazon Data Firehose formats these streams as Apache Iceberg commits, enabling immediate visibility for downstream consumers. Operators visualize this live feed by connecting Quick directly to the table bucket, bypassing intermediate warehousing layers. The architecture supports natural language queries against fresh data, allowing users to identify fraud patterns within minutes of occurrence.
- Stream transaction logs from distributed gateways into the ingestion layer.
- Convert raw bytes into Iceberg snapshots using the delivery service.
3.
SPICE acceleration risks exponential cost inflation when operators rely on default auto-compaction routines instead of manual tuning. Reported expenses for automated maintenance reach a 50x multiplier compared to hand-configured schedules, draining budgets on background file merging. The engine ingests data into memory to bypass network latency, yet this speed assumes storage efficiency that automatic processes often destroy. Blind trust in automated maintenance creates a hidden tax on high-frequency write workloads.
| Configuration Mode | Operational Overhead | Relative Cost Impact |
|---|---|---|
| Default Auto-Compaction | Zero | 50x baseline |
| Manual Scheduling | High | 1x baseline |
| Hybrid Policy | Medium | Variable |
Engineers must disable native compaction for volatile datasets to prevent financial leakage. The system performs continual merging of small objects, which benefits read-heavy archives but penalizes streaming ingestion pipes. Operators face a binary choice: accept the performance hit of manual file management or pay a massive premium for convenience. This tension defines the economic viability of SPICE for real-time fraud detection use cases. Unchecked background processes turn a performance feature into a budgetary liability.
Strategic Advantages of S3 Tables Over Traditional Data Warehouses
S3 Table Bucket Abstraction vs Proprietary Columnar Storage
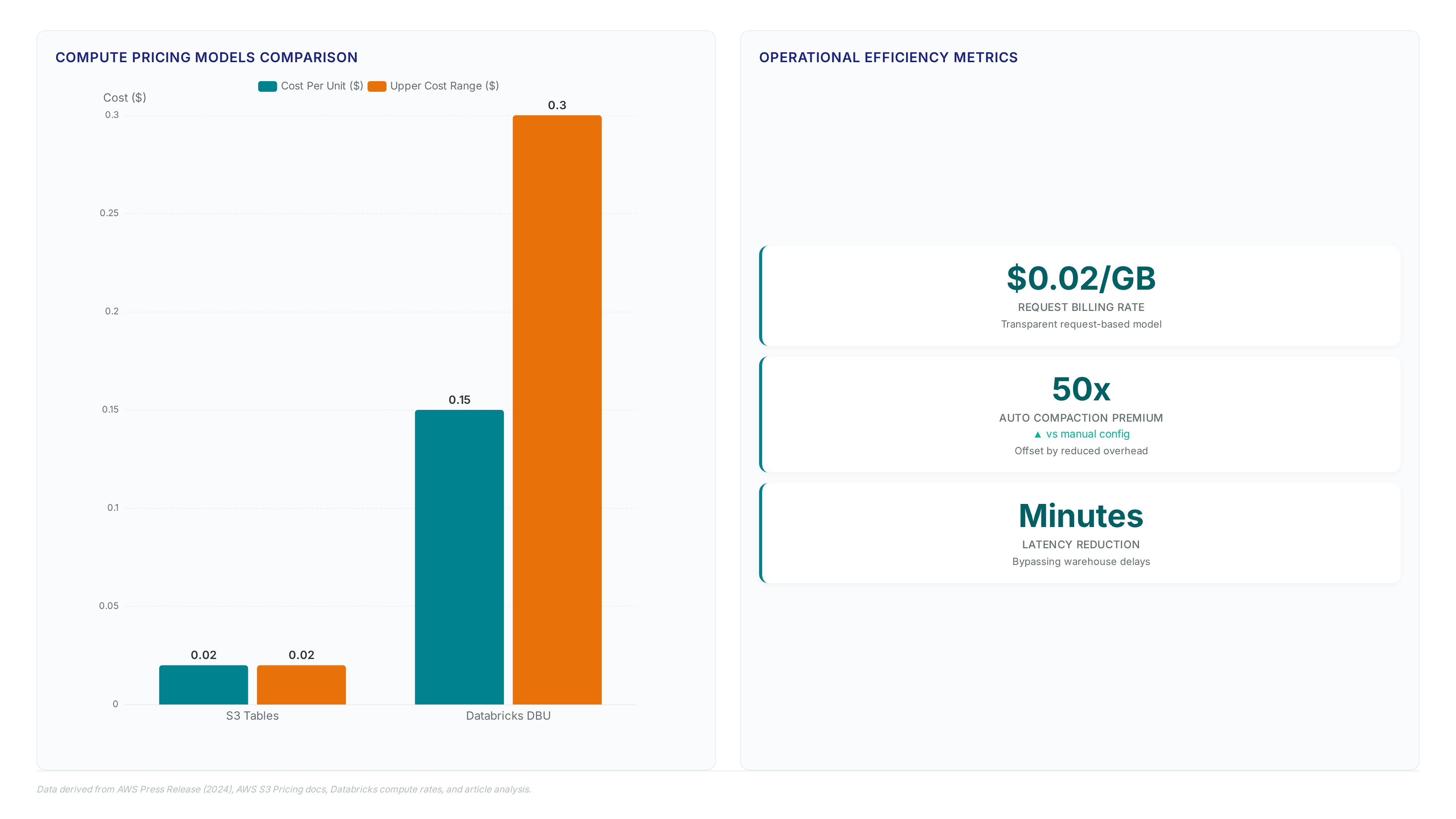
S3 Tables apply a table bucket abstraction on customer-owned storage rather than locking data into vendor-managed silos. Snowflake relies on proprietary compressed columnar storage that obscures physical file access, whereas the table bucket model keeps Apache Iceberg files visible and portable. This distinction shifts cost control from opaque credits to transparent requestbased billing at $0.02/GB. Operators avoid the egress penalties typical of moving data out of closed warehouse formats.
Query engine flexibility remains a decisive factor for multi-tool environments. The Iceberg REST Catalog API exposes metadata to Spark, Trino, and Athena simultaneously without data duplication. Snowflake performs optimally only when data resides within its managed Storage Architecture, limiting cross-engine utility. Choosing S3 Tables prioritizes long-term format stability over single-vendor performance tuning. This approach suits organizations requiring frequent engine swaps or strict data sovereignty controls.
Real-Time Fraud Detection Architecture for AnyCompany Corp
AnyCompany Corp. Deploys Direct Query mode to ingest POS and mobile streams into S3 Tables for immediate fraud analysis. Streaming data moves directly into the lake, bypassing warehouse latency that delays threat detection by minutes. This architecture treats the data lake as a central source of truth, eliminating redundant ETL pipelines. Operators choose Direct Query over SPICE when sub-second freshness outweighs the need for cached speed.
Direct Query ensures every visual interaction hits the storage layer, reflecting transactions the moment they occur. The alternative SPICE engine introduces lag during refresh cycles, creating blind spots for rapidly evolving fraud rings. Teams migrating from traditional SQL warehouses find this shift easier than mastering Spark-based learning curves associated with Databricks. Real-time dashboards now display distribution center status and employee productivity without batch delays, similar to improvements seen in Coca-Cola Andina operations. The 2026 streaming environment favors diskless architectures where analytics run directly on the stream. High-frequency writes increase request counts, demanding careful policy tuning to avoid budget spikes. Operators must balance the need for instant visibility against the cumulative cost of millions of small queries. Use Direct Query for fraud use cases where seconds determine financial loss.
DBU Compute Pricing Versus All-In-One Credit Systems
Databricks charges $0.15–$0.30 per DBU for compute, creating a granular cost model distinct from the all-in-one credit system used by Snowflake. The cost model favors workloads with high storage-to-compute ratios, whereas credit-based systems often penalize idle capacity or data sharing. The migration complexity for SQL-focused staff often outweighs initial compute savings if skill gaps remain unaddressed. Conversely, S3 Tables preserve existing tool investments by supporting standard Iceberg engines without proprietary locks. This financial shift occurs because storage architecture decouples file access from processing power, eliminating the premium charged for vendor-managed silos. Operators must weigh the learning curve against long-term total cost of ownership before selecting a platform. The constraint is that granular billing demands tighter monitoring to prevent request spikes from inflating bills unexpectedly. Audit current query patterns against these rate cards before committing to a single vendor system.
Implementing End-to-End AI Analytics with S3 Tables in Five Steps
IAM-Based Authorization for S3 Table Buckets
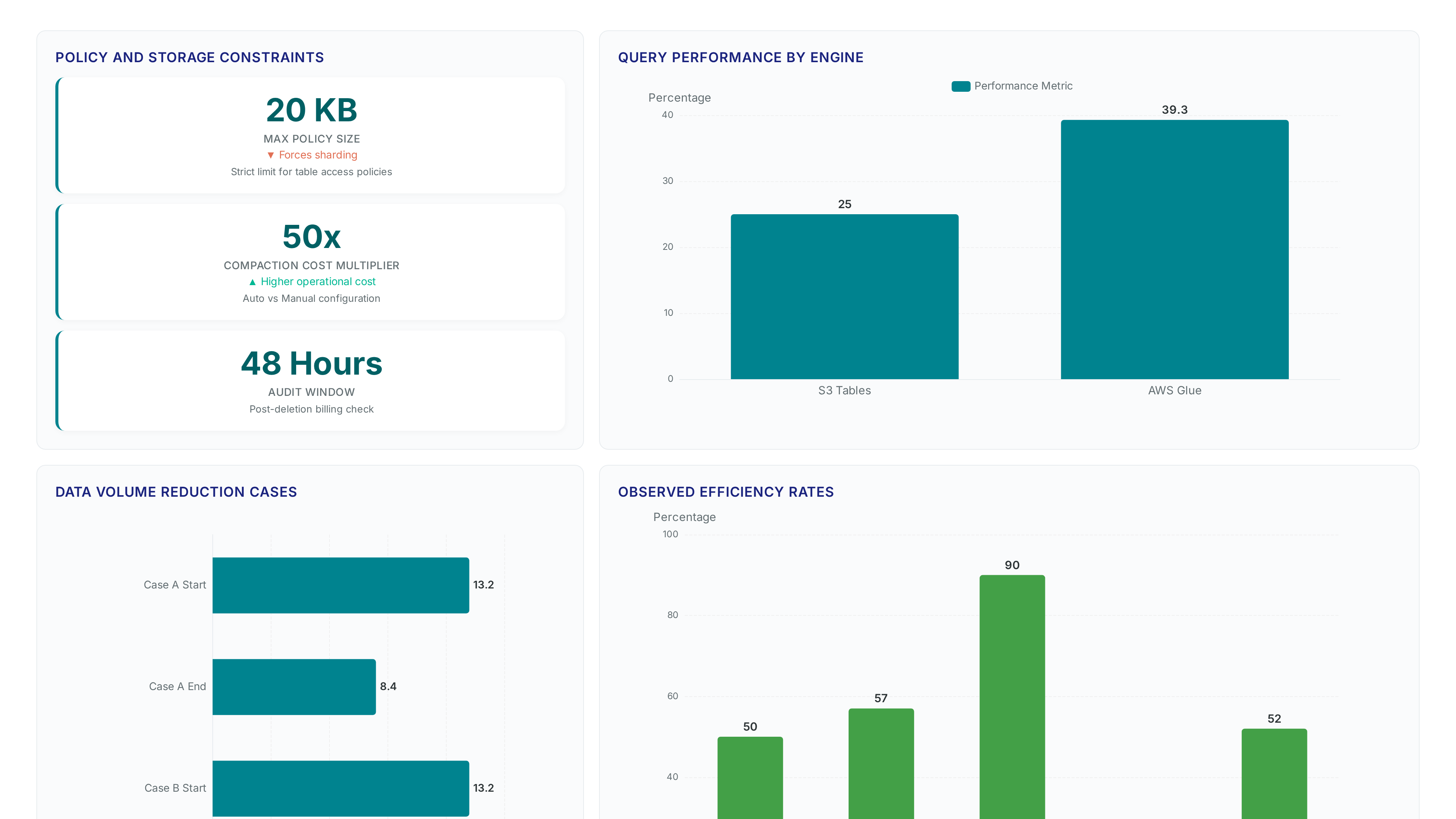
The March 17, 2026 update to the AWS Glue Data Catalog Operators previously managed disjointed policies, but this mechanism consolidates permissions for Apache Iceberg tables under a single identity framework. The change eliminates the need for separate resource policies when granting Amazon Quick access to specific table buckets. However, the underlying table access policies remain strictly limited to 20 KB, forcing large-scale deployments to shard permissions across multiple IAM roles rather than using a single monolithic document. This constraint creates operational friction for enterprises managing thousands of distinct datasets within a single bucket. Administrators must adopt a modular role strategy to avoid hitting the size ceiling during policy attachment. The shift reduces administrative overhead but introduces a new failure mode where oversized policy documents silently fail to apply.
- Navigate to the AWS Glue console and select the target Data Catalog.
- Enable IAM-based authorization in the settings menu for S3 Tables.
- Attach the generated service-linked role to the Amazon Quick service account.
- Verify access using AWS Signature Version 4 signed REST API calls.
- Audit policy sizes to ensure they stay below the hard 20 KB limit.
Audit existing policy structures before migration to prevent authorization gaps.
Configuring Auto-Discovery for s3table-datasamples Bucket
Enabling auto-discovery for the s3table-datasamples bucket requires selecting specific S3 table resources within the Amazon Quick account permissions.
- Navigate to Manage account, then Permissions and AWS Resources.
- Choose Select S3 table buckets and pick the s3table-datasamples entry.
- Verify the Amazon S3 option is active before saving changes.
This sequence attaches the necessary role permissions for direct Iceberg table access. All REST API interactions subsequently demand AWS Signature Version 4 to authenticate requests securely. Operators often overlook that background synchronization triggers separate data access charges, where importing data incurs write fees while exporting modifications generates read costs. The architecture supports both Direct.
Validate policy sizes immediately, as complex permission sets frequently exceed the strict 20 KB limit enforced by the platform. Exceeding this threshold causes silent failures during dataset creation, forcing operators to shard policies or reduce scope. The tension between granular access control and policy size constraints dictates whether a deployment succeeds or stalls at the ingestion layer.
Resource Cleanup Checklist to Avoid Ongoing Costs
Deleting all Amazon Quick resources and unsubscribing from the account stops immediate billing cycles for unused analytics capacity.
- Remove every dataset pointing to the s3table-datasamples bucket to halt direct query compute charges.
- Revoke the auto-discovery permissions granted to Amazon S3 Tables within the account management console.
- Empty the underlying table bucket to prevent persistent storage fees from accumulating on idle Apache Iceberg files.
- Terminate the Amazon Quick Enterprise subscription to eliminate the fixed monthly service cost.
Background synchronization operations often continue invisibly, where importing data onto high-performance storage incurs write charges even after user activity ceases.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His deep expertise in S3-compatible object storage makes him uniquely qualified to analyze the evolution of data lakes through Amazon S3 Tables. In his daily work, Alex designs scalable infrastructure for AI and ML startups, directly addressing the challenges of managing open table formats like Apache Iceberg that this article explores. By using Rabata. Io's high-performance, GDPR-compliant storage solutions, he helps enterprises eliminate vendor lock-in while maintaining the agility required for modern analytics. This practical experience allows him to critically evaluate how new data sources integrate with unified analytics services like Amazon QuickSight. His insights bridge the gap between theoretical architecture and real-world implementation, offering readers a grounded perspective on building AI-ready data foundations without compromising on performance or budget.
Conclusion
Scaling S3 Tables reveals a hidden friction point: metadata explosion eventually degrades query planning performance as table versions accumulate, a bottleneck distinct from storage volume. While upfront savings are strong, the operational tax of managing Iceberg compaction cycles and snapshot expiration policies grows linearly with data velocity. Organizations ignoring this maintenance debt will see their initial 57% compute gains erode within eighteen months as background vacuuming jobs compete for cluster resources.
Adopt this architecture only if your team possesses dedicated data platform engineering capacity to automate file lifecycle management; otherwise, stick to managed warehouse solutions until Q3 2026 when serverless compaction matures. The window for manual intervention is closing rapidly as real-time analytics shift toward diskless streaming patterns that bypass static table structures entirely. Delaying migration past this tipping point risks locking your stack into a high-maintenance legacy model before it fully stabilizes.
Start by auditing your current snapshot retention policies this week to identify tables exceeding fifty versions, then script an automated expiration rule to run before next month's billing cycle. This immediate reduction in metadata overhead prevents the silent performance decay that typically ambushes teams after the initial proof-of-concept phase.
Frequently Asked Questions
Migrating to S3 Tables delivers a ninety percent potential reduction in storage costs. This massive saving occurs because the architecture eliminates intermediate data layers and proprietary compression requirements found in traditional warehouse systems.
Benchmarks demonstrate fifty-two percent faster query performance compared to legacy Hive-backed structures. This speed increase allows financial teams to analyze fresh transaction data without waiting for batch processing cycles to complete.
Statistics indicate that sixty-four point three percent of Iceberg users deploy on AWS today. This high adoption rate validates the strong market demand for native integration between open table formats and cloud storage.
No, the architecture removes the need for separate data warehouses or OLAP layers entirely. Users can directly query Apache Iceberg tables in the data lake, treating it as a central source of truth.
The solution minimizes data movement and pipeline dependencies to ensure dashboards reflect current data. This streamlined approach enables near real-time insights by querying large-scale datasets directly from the Amazon S3 table bucket.
