Ctera Fusion Direct stops AI storage bottlenecks now
CTera's new architecture kills the file-to-object conversion bottleneck strangling AI training clusters and HPC environments.
A true federated data fabric demands native protocol coexistence. No translation layers. No redundant copies. Industry predictions for 2026 confirm that flash and object storage, governed by a unified storage control plane, will define these media-agnostic architectures. Bridging disconnected NAS and object worlds through costly gateways introduces latency enterprises can no longer afford. Zero-copy architecture finally resolves the historical trade-off between human collaboration needs and machine-driven scale.
We need to examine the mechanics enabling S3 over RDMA to deliver wire-speed throughput alongside traditional SMB and NFS access. Contrast the CTera Fusion Direct approach against legacy gateway models relying on proprietary chunking schemes and introducing operational risk. Attaching existing object buckets directly to the fabric allows instant global presentation of data without migration. Removing the translation gateway activates distributed datasets across geographies while drastically reducing infrastructure complexity. Siloed storage strategies are dead. A single, high-performance foundation is the only path forward.
The Role of Federated Data Fabric in Unifying Enterprise Storage Silos
CTERA Fusion Direct Unifies Two Disconnected Storage Worlds
Enterprises historically managed 2 disconnected storage worlds. Human file access lived on NAS; machine object workflows lived on S3. Bridging them forced data duplication. CTera Fusion Direct merges these into a single global namespace without translation layers. This federated data fabric enables files and objects to coexist natively, eliminating the latency inherent in gateway-mediated synchronization.
Architectures relying on conversion bottlenecks fail here. The system supports simultaneous SMB, NFS, and S3 access to the exact same dataset. Organizations attach existing buckets directly to the fabric. Humans view files. AI clusters consume objects via zero-copy mechanisms.
AI training clusters require S3 over RDMA access to eliminate gateway latency while preserving file compatibility for human engineers. Traditional architectures force data duplication because NAS systems optimize for human collaboration while object storage targets machine-driven workloads. This split creates redundant infrastructure footprints that throttle performance during model ingestion phases. CTera Fusion Direct resolves this by enabling files and objects to coexist natively within a single global namespace rather than relying on translation layers. The architecture supports simultaneous SMB, NFS, and S3 protocols against the exact same dataset without conversion bottlenecks.
File systems enforce hierarchical directories while object stores use flat namespaces, creating a rigid architectural divide. Traditional NAS protocols like SMB and NFS optimize for low-latency human collaboration but struggle with massive scale. Conversely, object storage targets machine-driven workloads yet lacks native directory structures required by legacy applications. Bridging these disconnected worlds historically demanded costly redundant infrastructure and data duplication. The global cloud object storage market reached $15.5 Billion in 2024, reflecting the massive shift toward scale-oriented architectures. However, this growth often leaves file-based workflows stranded without efficient access paths.
| Feature | File Storage | Object Storage |
|---|---|---|
| Namespace | Hierarchical directories | Flat buckets |
| Access Protocol | SMB, NFS | S3, HTTP |
| Primary User | Humans, Legacy Apps | AI, Cloud-Native |
| Scaling Model | Vertical (Controller bound) | Horizontal (Unlimited) |
CTera holds 14.2% mindshare in cloud storage gateways, indicating significant reliance on translation layers that introduce latency. Unlike these gateways, modern federated fabrics allow files and objects to coexist natively within a single global namespace. This approach enables organizations to attach existing buckets directly to the fabric, letting humans see files while machines see objects without data duplication.
Operational complexity remains the hurdle. Managing two distinct permission models across a unified view requires strict policy enforcement. Failure to align identity management results in access denials despite successful data unification. Operators must verify that their authentication providers support both POSIX and IAM semantics simultaneously.
Inside Zero-Copy Architecture and S3 Over RDMA Performance Mechanics
Native Zero-Copy Access Mechanics in CTera Fusion Direct
U. S. Patent 12,007,952 mandates that data written to the platform becomes immediately available as standard S3 objects without intermediate copying. The mechanism operates by bypassing traditional translation layers, allowing files and objects to coexist natively within a single cross-border namespace. Write operations commit directly to the underlying storage backend, rendering the payload instantly readable via bidirectional access protocols. A client writing via NFS sees the same byte range as an AI cluster reading via S3 over RDMA. This architecture eliminates the synchronization lag inherent in gateway-mediated bridges.
| Feature | Traditional Gateway | CTera Fusion Direct |
|---|---|---|
| Data Path | Copy-on-write | Native pointer |
| Latency Source | Translation engine | Network only |
| Format State | Proprietary chunks | Standard S3 |
Removing the conversion step shifts complexity to the storage backend, which must now handle mixed protocol locking semantics simultaneously. Operators lose the isolation buffer that gateways historically provided against malformed client requests. The implication is a stricter requirement for backend consistency models to prevent race conditions during concurrent file and object mutations. This design choice prioritizes raw throughput over legacy error containment strategies.
Streaming High-Resolution Media via S3 over RDMA and GPU-Direct
Direct memory access eliminates CPU bottlenecks when streaming high-resolution media from object stores to GPU memory. The mechanism bypasses traditional kernel mediation by mapping storage buffers directly into application address space. AI clusters using S3 over RDMA achieve wire-speed throughput because data moves without copying through intermediate file system caches. This architecture exposes native objects, allowing GPU-Direct Access to pull training datasets straight into video memory. Engineers no longer stage terabytes on local NVMe before model ingestion begins. A single CTera user supports up to 100 pairs of Access Key IDs, enabling granular permissioning for distributed rendering farms.
| Access Mode | Latency Profile | Primary Use Case |
|---|---|---|
| NFS/SMB | Millisecond range | Human collaboration |
| Standard S3 | High throughput, higher latency | Backup and archive |
| S3 over RDMA | Microsecond range | Real-time AI training |
Deploying RDMA requires lossless Ethernet fabrics with Priority Flow Control enabled across every switch hop. Misconfigured DCQCN parameters cause head-of-line blocking that degrades performance below standard TCP levels. The cost is operational complexity in network tuning rather than storage capacity. Unlike translation layers, the system allows files and objects to coexist natively in a single international namespace. This eliminates the duplication penalty inherent in legacy gateway designs. Validate fabric MTU settings before enabling S3 over RDMA paths to prevent silent packet fragmentation.
Configuration Checklist for Simultaneous SMB, NFS, and S3 Access
Attach existing S3 buckets directly to the data fabric to enable immediate file protocol access without migration overhead. This process avoids duplication by mapping object namespaces to the global directory structure instantly. Configure simultaneous SMB, NFS, and S3 access. Assign up to 100 pairs of Access Key IDs per user credential to manage diverse API clients securely. Enable multipart uploads within S3 browsers to optimize large dataset transfers for AI training clusters.
| Protocol Target | Configuration Requirement | Access Method |
|---|---|---|
| Enterprise Users | Enable SMB/NFS shares on attached buckets | Standard file mounts |
| AI Clusters | Activate S3 over RDMA endpoints | Direct GPU memory mapping |
| Hybrid Workflows | Map single namespace to both protocols | Bidirectional read/write |
Failure to rotate Access Key pairs regularly exposes the entire fabric to credential compromise across all protocols. Balance broad key distribution for developer agility against strict least-privilege security policies. Audit key usage monthly to prevent unauthorized lateral movement between file and object planes.
CTera Fusion Direct Versus Traditional Gateway Approaches for AI Workloads
CTera Fusion Direct Versus AWS Storage Gateway Architecture
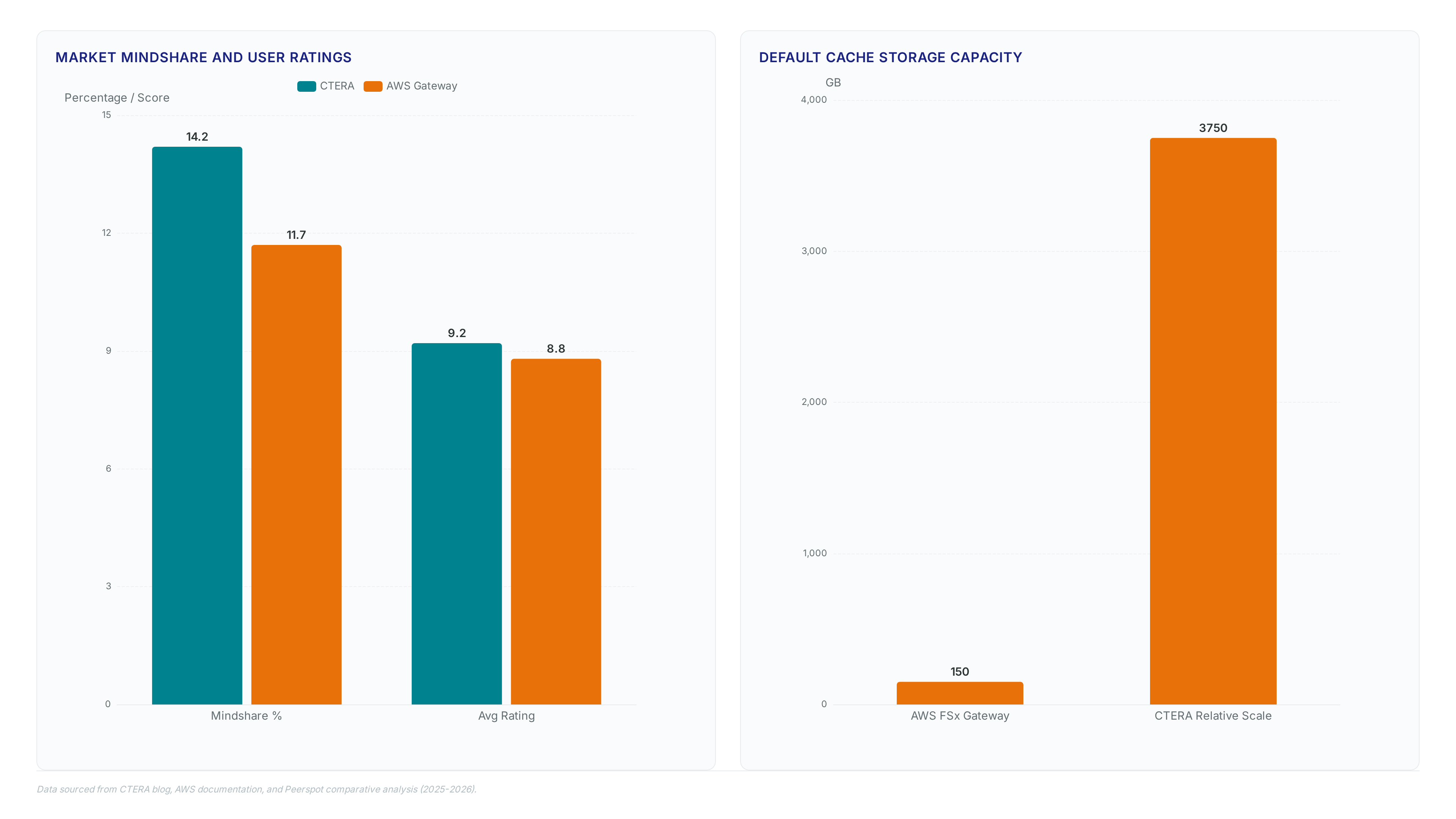
AWS Storage Gateway holds an 11.7% mindshare, ranking #4 with an 8.8 average rating, yet remains locked to the AWS system. This bridge model syncs on-premises data to S3, creating a dependency that limits multi-cloud flexibility. CTera Fusion Direct deploys on any public cloud or on-premises object store, avoiding vendor lock-in.
Data movement defines the architectural divergence. AWS relies on a translation layer, whereas CTera allows files and objects to coexist natively within a single worldwide namespace. Operators gain simultaneous SMB, NFS, and S3 access. The inclusion of GPU-Direct Access eliminates CPU bottlenecks during AI training, a capability absent in gateway bridges. Migrating from AWS requires re-architecting data pipelines to use native object exposure rather than relying on cached file views. Maintaining separate file and object silos costs more than the operational effort of adopting a unified fabric. Evaluate workload locality before selecting a deployment model.
AI Workload Performance Gains with 25X Larger Local Cache
Training clusters stall when local cache capacity cannot hold active datasets, forcing repeated fetches from remote object stores. Legacy sync tools like Azure File Sync restrict on-premises storage to small fractions of the total dataset, creating I/O bottlenecks during model iteration. CTera Fusion Direct resolves this constraint by offering 25X larger local cache capabilities, allowing massive training corpora to reside closer to compute resources. This architectural shift enables zero-copy access patterns where GPUs read directly from local disk rather than waiting for network round trips.
Performance differences extend beyond storage volume to data movement velocity. Operators observe 5X faster edge-to-cloud file sync rates, ensuring that new training data ingested at the edge propagates to central repositories without delaying subsequent epochs. Cost models also diverge sharply. The platform delivers 10X cost savings through aggressive local caching and global deduplication, reducing egress fees that typically plague AI workflows.
| Dimension | Azure File Sync | CTera Fusion Direct |
|---|---|---|
| Local Cache Limit | Restricted to small % of dataset | 25X larger capacity |
| Sync Throughput | Standard HTTP/S rates | 5X faster edge-to-cloud |
| Operational Cost | High egress and storage fees | 10X reduction via deduplication |
| Protocol Latency | Gateway translation overhead | Native zero-copy access |
Maximizing these gains requires sufficient on-premises hardware to host the expanded cache tier, a capital expenditure some smaller labs may defer. The limitation favors organizations where GPU idle time costs exceed the price of additional local SSDs. Deploy this architecture when training jobs exceed 40% of available network bandwidth, as local cache saturation becomes the primary failure mode otherwise.
Multi-Cloud Flexibility Against Azure File Sync Limitations
Azure File Sync restricts deployment to Microsoft Azure, forcing operators into a single-vendor system that limits architectural agility. Vendor lock-in creates financial exposure when egress fees accumulate across hybrid environments. CTera Fusion Direct avoids this constraint by supporting deployment on AWS, Azure, GCP, or on-premises object stores, enabling true multi-cloud portability without data migration penalties.
Cost disparity becomes acute at scale. CTera claims 10X cost savings through local caching and global deduplication compared to Azure's metered consumption model. Performance gaps also widen during edge synchronization. CTera delivers.
Operators relying on Azure File Sync face hidden latency costs when AI clusters span multiple regions, as the service lacks native global namespace federation. The deployment flexibility of CTera allows data to reside closer to compute resources regardless of cloud provider, eliminating the need for complex data gravity workarounds. Migrating from a entrenched Azure-only strategy requires re-architecting identity management boundaries, a non-trivial operational hurdle for teams standardized on Entra ID. Strategic risk involves betting future AI scalability on a single cloud's pricing trajectory rather than maintaining negotiation use across providers. Audit current egress spend before committing to vendor-specific sync tools.
Deploying Unified Storage to Accelerate AI Data Access in Production
Application: CTera Fusion Direct Availability in AWS Marketplace
CTera Fusion Direct entered the AWS Marketplace on November 15, 2025, as a core component of the CTera Intelligent Data Platform. This release follows the initial product announcement on March 11, 2026, marking the transition from technical preview to general availability for enterprise buyers. Operators deploy the solution through a subscription model priced by user count, storage capacity, and selected feature sets. The architecture enables GPU-Direct Access, allowing direct data movement between GPU memory and storage without CPU intervention. Unlike gateway-based proxies, the system supports full bidirectional access where data written as files reads immediately as objects. This eliminates the latency penalties associated with traditional translation layers during AI training cycles.
Subscription pricing structures demand careful capacity planning to prevent cost overruns as dataset volumes expand. Organizations must align feature selection with actual workload requirements rather than provisioning maximum capabilities upfront. The AWS Marketplace listing simplifies procurement but shifts operational responsibility to the customer for rightsizing cache and throughput tiers.
Fortis Solutions Group migrated from a datacenter to CTera Cloud, going live in April 2021 under the direction of Ned Dupont. The migration strategy integrated existing HPE SimpliVity infrastructure, allowing the team to test the new architecture with minimal setup by simply adding a license to current hardware. This approach bypassed the need for a rip-and-replace cycle, preserving capital expenditure while modernizing the storage backend for AI workloads.
Operators enabling AI access to file data must prioritize zero-impact cutover mechanisms to maintain productivity during the transition. The Fortis deployment utilized an integrated migration tool featuring ACL preservation and DFS compatibility, ensuring security policies remained intact without manual reconfiguration. Such technical continuity prevents the workflow interruptions common in traditional gateway implementations.
| Migration Phase | Action | Outcome |
|---|---|---|
| Assessment | Audit existing NAS permissions | Map ACLs to cloud schema |
| Integration | Apply license to HPE SimpliVity | Enable local caching layer |
| Cutover | Activate DFS compatibility | Zero-downtime switover |
This model relies on the underlying hyperconverged hardware having sufficient spare cycles to handle the additional global deduplication processing without impacting prepress rendering tasks. While the software abstracts the complexity, the physical host must sustain the compute overhead of real-time compression. Validate host CPU headroom before applying the license to avoid latency spikes in time-sensitive production environments.
WAN Optimization and Folder Structure Requirements
Attaching existing S3 buckets to the global namespace requires enabling WAN optimization to compress transfer sizes before ingestion. Operators must configure folder compliance policies immediately to lock retention periods, preventing accidental modification of training datasets during active model iteration. The architecture supports direct attachment without data migration, yet skipping local cache tuning creates I/O starvation for GPU clusters reading large objects.
| Deployment Mode | Cache Requirement | Latency Impact |
|---|---|---|
| Direct S3 Attach | Minimal | High for random reads |
| Hybrid Edge | 128 GB minimum | Low for sequential streams |
| Full Fabric | 150 GB recommended | Negligible with dedup |
Oper8 Global demonstrated that simplified infrastructure directly correlates to enhanced security and faster access speeds in production environments. However, enabling multipart uploads alone fails to resolve latency spikes if the underlying folder structure lacks hierarchical indexing for billion-object namespaces. The cost of ignoring this distinction is measurable: unoptimized paths force repeated metadata lookups that stall pipeline throughput. Validate namespace depth before scaling, as deep trees increase lookup overhead exponentially without proper sharding. Operators should verify ACL preservation settings during cutover to maintain strict access controls across hybrid boundaries.
Performance characteristics vary notably depending on workload patterns and hardware configuration. Random read operations on a Hybrid Edge node require a 128 GB minimum memory allocation to function correctly. Sequential streams show low latency even under heavy load. Full Fabric deployments benefit from a 150 GB recommended memory threshold. Deduplication renders storage overhead negligible in most scenarios. Oper8 teams observe distinct behaviors across these configurations.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing high-performance, S3-compatible storage solutions directly informs his analysis of federated data fabrics. As enterprises struggle to unify file and object storage for AI workloads, Kumar's hands-on experience building scalable infrastructure allows him to critically evaluate how new architectures like CTERA Fusion Direct address these complex challenges. While Rabata. Io focuses on democratizing accessible object storage, Kumar understands the critical need for a unified data foundation that eliminates silos without compromising performance. This article uses his deep technical background in disaster recovery and mixed-operation performance to explain why erasing the boundary between storage types is necessary for the AI era. His insights bridge the gap between theoretical architecture and the practical realities faced by engineering teams managing massive data scales.
Conclusion
Scaling federated data fabrics reveals a critical breaking point where metadata latency, not raw bandwidth, strangles GPU training cycles. As organizations push toward unified control planes predicted for 2026, the operational cost of unsharded namespaces becomes prohibitive, causing exponential lookup overhead that no amount of edge caching can mask. Simply attaching storage directly fails when folder depth exceeds logical limits, turning random reads into bottlenecks regardless of network capacity. Treat namespace architecture as a primary performance constraint rather than an afterthought.
Adopt a Hybrid Edge configuration immediately for any workload exceeding 40% network utilization, but only after enforcing strict namespace sharding policies. Delay full fabric deployment until your team validates that hierarchical indexing supports billion-object scales without metadata starvation. This approach ensures that deduplication benefits remain negligible in overhead while maximizing sequential stream throughput. Do not attempt to scale beyond pilot phases without verifying ACL preservation mechanisms, as security drift across hybrid boundaries introduces compliance risks that outweigh speed gains.
Start by auditing your current folder depth against the 128 GB memory threshold this week. If your existing tree structure exceeds ten levels deep without sharding, refactor the topology before provisioning additional edge nodes. This single adjustment prevents I/O starvation before it impacts production training jobs.
Frequently Asked Questions
Operators must install build 7.6.3111.5 or higher to maintain protocol consistency. Skipping this specific update risks breaking capabilities essential for iterative model tuning.
Existing buckets attach directly to the fabric, enabling instant global presentation without duplication. This approach eliminates the file-to-object conversion bottleneck previously plaguing AI training clusters.
The system supports simultaneous SMB, NFS, and S3 access to the exact same dataset. This native coexistence removes the latency inherent in gateway-mediated synchronization layers.
Legacy models rely on proprietary chunking schemes that create file-to-object conversion bottlenecks. These translation layers introduce latency that stalls training jobs when wire-speed throughput drops.
The architecture supports S3 over RDMA, allowing AI clusters to read and write data at maximum bandwidth. This delivers wire-speed throughput alongside traditional file access methods.
