Account regional namespaces fix S3 name clashes
After 18 years of global constraints, AWS shattered the single namespace monopoly on March 12, 2026. This update shifts S3 architecture from a scarce, globally contested resource to a predictable, isolated model governed by account regional namespaces. You no longer fight unrelated tenants for generic names like "prod-data." You now own your naming convention within your specific region.
This namespace isolation directly supports the top 2026 storage trends identified by TechTarget, enabling rigid cost governance and resilient hybrid cloud strategies through deterministic naming. We provide concrete implementation strategies for the AWS Console, CLI, and CloudFormation, demonstrating how to enforce these standards using the new `s3:x-amz-bucket-namespace` condition key in IAM policies.
Over 75% of enterprises already rely on object storage. The previous global bottleneck created unnecessary operational friction for scaling teams. Amazon Web Services has decoupled naming availability from global luck, ensuring your bucket creation workflow never stalls due to external collisions. This is a critical infrastructure correction for mature cloud environments demanding strict resource control.
The Role of Account Regional Namespaces in Modern S3 Architecture
Account Regional Namespace Definition and Global Constraint Shift
The account regional namespace ends 18 years of global uniqueness constraints by appending account IDs and regions to bucket names. Announced on 12 Mar 2026, this architecture moves S3 from a shared global pool to isolated scopes. Operators previously faced blocking scenarios where unrelated accounts claimed generic names like "prod-data" globally, disrupting general enterprise migration plans. The new format constructs names as `prefix-account-id-region-an`, such as `mybucket-123456789012-us-east-1-an`. This structure guarantees name availability within an account boundary while maintaining DNS compatibility.
The model applies exclusively to general purpose buckets. S3 table buckets and vector buckets already operate in account-level namespaces, while directory buckets use zonal scopes.
Existing global buckets cannot be renamed to adopt the new suffix format. Migration requires creating new resources and copying data rather than updating metadata. This constraint forces a dual-namespace environment during transition periods. Operators must manage both legacy global names and new regionalized identifiers simultaneously. The cost is increased operational complexity in automation scripts that handle mixed bucket types.
S3 Namespace Architecture Versus Google Cloud and Azure Models
Competitor models inherent scoping; AWS previously forced global uniqueness. The new account regional namespace isolates S3 general purpose buckets to specific account and region pairs, ending global uniqueness requirements. Google Cloud Storage uses a project-based namespace, while Azure Blob Storage relies on storage account containers to provide scoped namespaces without global checks. The new AWS suffix pattern `{prefix}-{account-id}-{region}-an` mimics these isolated scopes for general purpose buckets only. Other S3 types operate differently: table buckets and vector buckets use an account-level namespace, whereas directory buckets exist in a zonal namespace.
| Platform | Namespace Scope | Uniqueness Constraint |
|---|---|---|
| AWS S3 (General) | Account + Region | Global DNS hostname |
| AWS S3 (Directory) | Zone | Account + Zone |
| Google Cloud Storage | Project | Project + Bucket |
| Azure Blob Storage | Storage Account | Account + Container |
Pricing models reflect these structural differences. Azure Blob Hot tier lists at $0.018/GB/month, while Google Cloud Storage Standard tier costs $0.020/GB/month. AWS charges no extra fee for the namespace feature itself, though standard storage rates apply.
Migration paths create the real friction. Existing global buckets cannot be renamed to use the new suffix format. Operators must create new resources and migrate data, unlike the smooth project scoping found in GCP from inception. This fragmentation means infrastructure as code templates require distinct logic for legacy versus modern S3 buckets, complicating uniform governance policies across mixed environments.
Internal Mechanics of Namespace Isolation and Request Validation
The s3:x-amz-bucket-namespace Condition Key Mechanics
Security teams use the s3:x-amz-bucket-namespace condition key to validate the `x-amz-bucket-namespace` header against the caller's account ID and region during bucket creation. This mechanism lives within AWS IAM policies to mandate that employees strictly adopt the account area-based namespace. The API implementation requires specifying the `account-regional` value in the CreateBucket call or via the BucketNamePrefix property in infrastructure templates. This validation step prevents legacy global naming collisions by rejecting any request lacking the correct suffix format.
| Policy Element | Enforcement Scope | Validation Target |
|---|---|---|
| Condition Key | Organization-wide | Request Header |
| Resource ARN | Single Account | Bucket Prefix |
| SCP Rule | Root/OU Level | Namespace Type |
Operators must embed this logic into Service Control Policies to block non-compliant bucket creations at the organization level. This key only functions for general purpose buckets, leaving directory or table buckets unaffected by this specific check. Enforcing this condition creates a hard dependency on application code updates to include the required header. Failure to update the CreateBucket API calls results in immediate access denied errors for legacy deployment pipelines. Strict validation ensures consistent naming hygiene but demands coordinated rollouts across all automation tooling.
Validating x-amz-bucket-namespace Headers in API Requests
The CreateBucket API rejects requests where the x-amz-bucket-namespace header value mismatches the suffix embedded in the bucket name string. Operators must append the exact `-123456789012-us-east-1-an` suffix to their prefix before sending the `account-regional` header. The S3 control plane parses the incoming string to verify that the account ID and region segments match the caller's credentials. A failure occurs if the suffix is missing, malformed, or belongs to a different identity. This validation logic enforces strict isolation without requiring global uniqueness checks across the entire platform.
Infrastructure teams automate this pattern using `CloudFormation` templates that inject pseudo parameters for flexible suffix generation. Manual creation via CLI demands precise string construction, as the system does not auto-complete the suffix if the header is present but the name is incomplete.
| Request Component | Valid State | Invalid State |
|---|---|---|
| Header Value | `account-regional` | `global` or missing |
| Bucket Name | Ends with `-an` | Ends with random chars |
| Account ID | Matches caller | Matches different account |
Hardcoding identifiers leads to immediate deployment failures when pipelines migrate between environments. Scripts must dynamically resolve the caller identity to construct valid names on every run. This constraint prevents static configuration files from working across multiple accounts without modification.
Legacy global namespace collisions allow applications to access incorrect buckets if object owners differ, necessitating the bucket owner condition feature alongside account area-based namespaces. Applications relying on simple prefixes risk retrieving data from unrelated accounts when names match in the old global scope. AWS explicitly recommends enabling the bucket owner condition to validate that the caller owns the target resource before fulfilling read or write operations. This check acts as a secondary guardrail because namespace isolation alone does not prevent an application from successfully addressing a bucket owned by a different entity if the name string happens to align.
Practical Implementation Strategies for Console CLI and CloudFormation
Account Local Namespace Character Limits and CLI Header Syntax
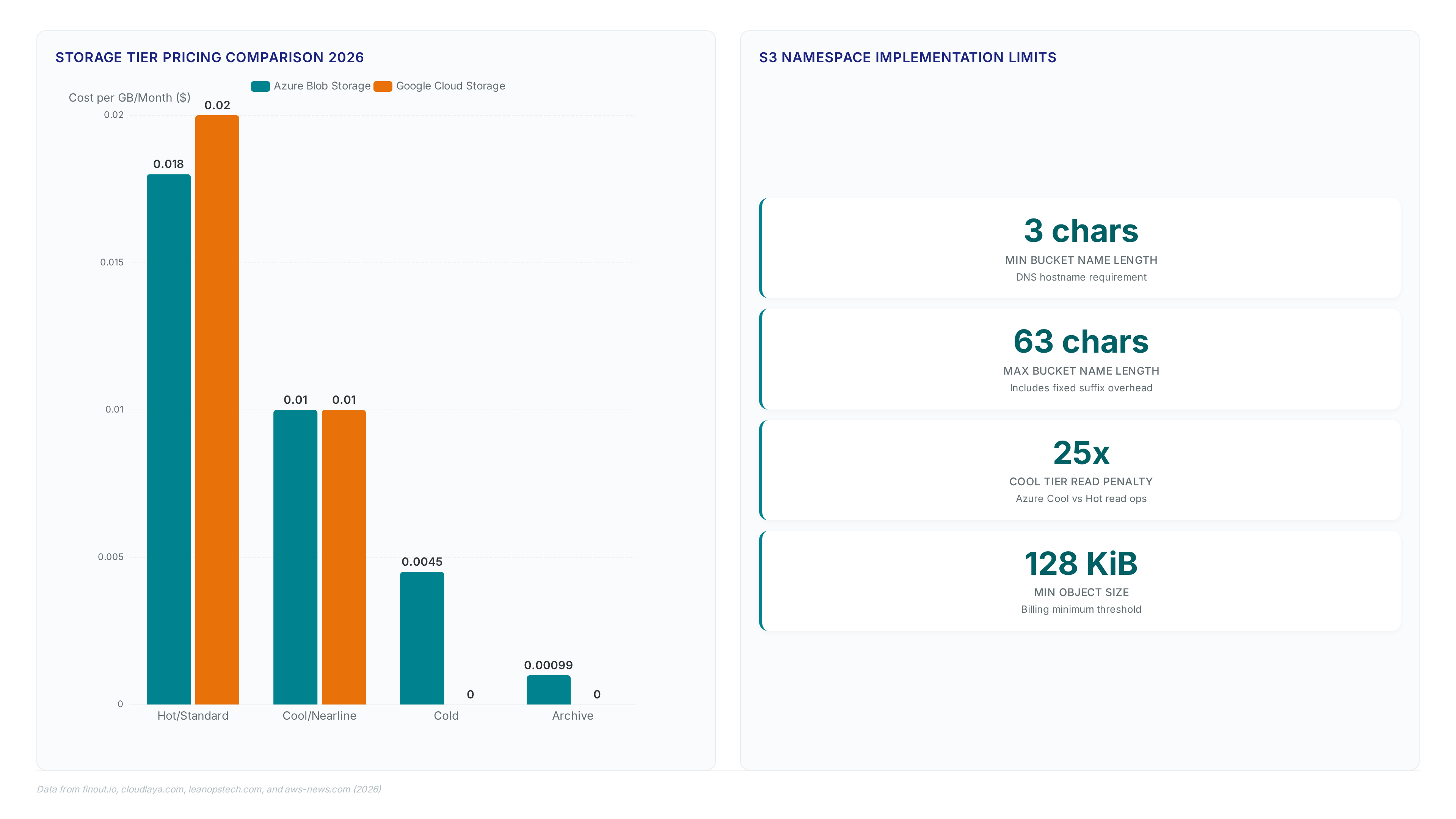
Bucket name prefixes combined with account regional suffixes must strictly fall between 3 and 63 characters. This limit persists because bucket names remain integral to the DNS hostname, capping individual sections regardless of the new scoping logic. The CreateBucket API rejects any request where the header value mismatches the embedded suffix segments.
Maximizing prefix descriptiveness risks exceeding the 63-character DNS limit when the mandatory suffix is appended. Teams must treat the suffix as a fixed overhead rather than an optional tag, forcing shorter application identifiers in environments with long account IDs or region names. Failure to align the x-amz-bucket-namespace header with the actual name structure results in immediate validation errors, blocking infrastructure-as-code pipelines that assume legacy global rules.
Executing S3 Console and CLI Commands for Regional Bucket Creation
Selecting Account zone-based namespace in the Create bucket wizard isolates the new resource to the caller's identity and region. Operators navigating the console must explicitly toggle this setting to bypass global uniqueness constraints that previously blocked common prefixes. This action permits any name unique within the specific account scope, eliminating cross-tenant collisions for standard identifiers. Command-line automation requires injecting the `x-amz-bucket-namespace:account-regional` header to trigger the same logic programmatically.
- Resolve the current account ID and target region variables.
- Construct the bucket string by appending the account ID, region, and `-an` suffix.
- Execute the command with the `--bucket-namespace` flag set to `account-regional`.
Developers using the AWS SDK for Python (Boto3) often face naming conflicts when migrating legacy infrastructure. The shift to scoped namespaces resolves this by tying availability strictly to the requester's credentials rather than global first-come-first-served rules. However, the combined character count for the prefix and system-generated suffix must remain between 3 and 63 characters. Exceeding this limit causes immediate API failure regardless of namespace selection. This constraint forces operators to shorten logical prefixes when adopting the new model for long account IDs.
Verifying Region Availability and Cost Implications for S3 Deployment
Deployment fails immediately if the target zone lacks support, restricting Account territorial namespace creation to 37 AWS Regions including China and GovCloud.
- Confirm region eligibility before templating, as global namespaces do not apply to unsupported zones.
- Validate that AWS CloudFormation stacks use `BucketNamePrefix` rather than hard-coded suffixes to ensure portability.
- Compare egress fees against competitors, noting AWS charges $0.09/GB while Google Cloud Storage levies $0.12/GB.
The namespace feature itself carries no premium, yet total cost of ownership shifts based on data movement patterns. Regional isolation increases cross-zone transfer frequency when applications span multiple availability zones. Balance naming convenience against potential network spend increases. Hard-coding account identifiers breaks deployment pipelines during account migrations or multi-account strategies. Audit existing templates for static bucket names that prevent automated regional scaling. The `BucketNamePrefix` property automates suffix attachment, reducing human error in name construction. Failure to adopt this pattern locks environments into legacy global constraints, reintroducing collision risks the feature aims to eliminate.
Strategic Governance and Operational Benefits for Enterprise Teams
Enforcing Account Local Namespaces via IAM and SCPs
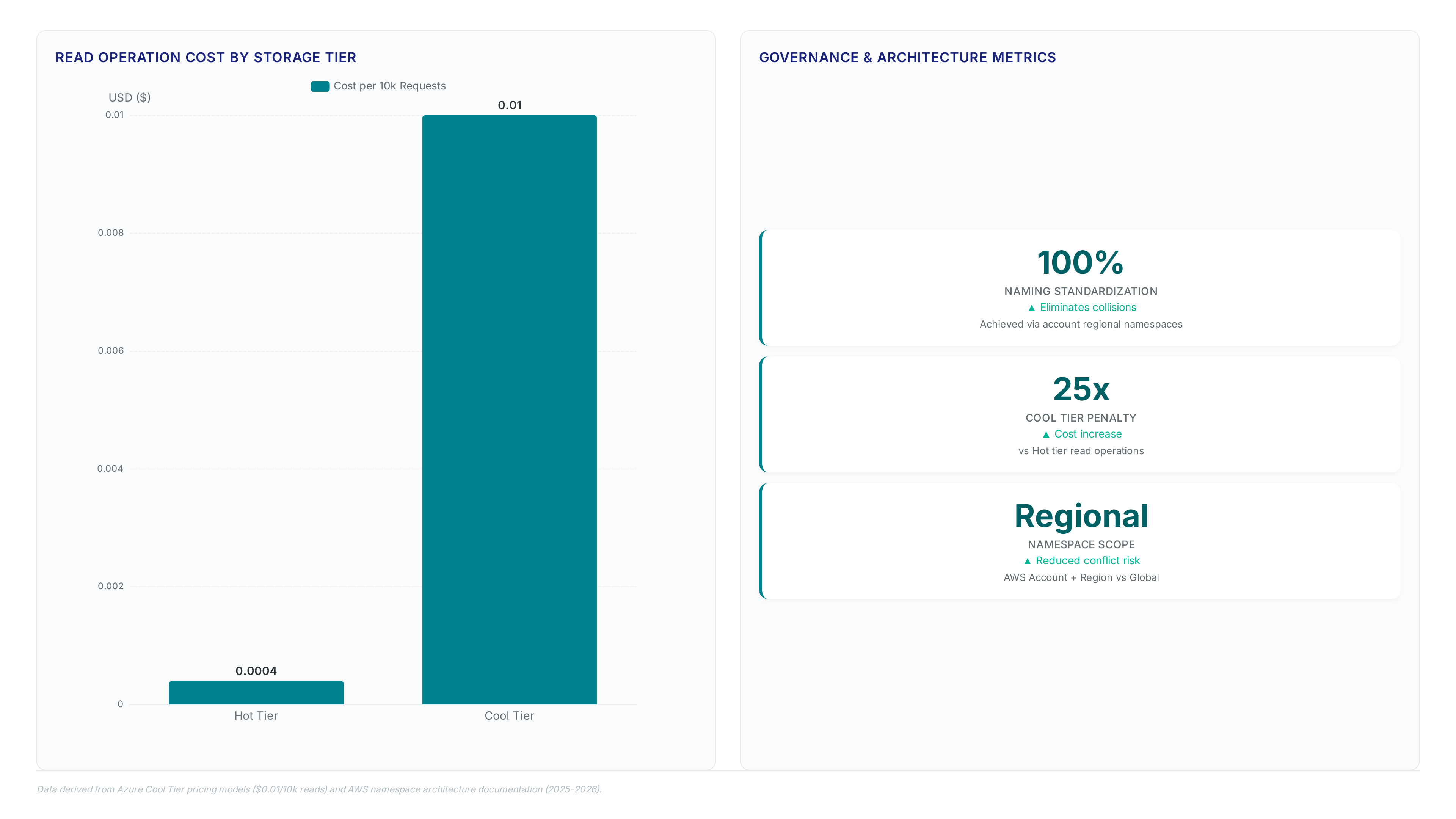
The `s3:x-amz-bucket-namespace` condition key serves as the technical anchor for mandating regional isolation across enterprise accounts. Security teams embed this specific string within IAM policies and Service Control Policies to reject any `CreateBucket` request lacking the account-regional header. This mechanism forces compliance at the API level. Developers cannot accidentally provision resources in the legacy global scope where naming collisions occur.
Enforcement logic requires explicit denial of global namespace usage while permitting only the suffixed format. S3 table buckets and vector buckets already operate in an account-level namespace. This reality makes the specific condition key redundant for those resource types. Operators must scope their policies and filters strictly to general purpose buckets to avoid logic errors in denial rules. Different bucket classes require separate validation paths. Audit existing SCPs so the new condition key does not inadvertently block legitimate legacy migrations. The architectural shift mirrors Google Cloud Storage project scoping. AWS administrators must provide more granular policy syntax.
Application: Preventing Cross-Account Collisions with Bucket Owner Conditions
Legacy global naming rules allowed external accounts to claim identical prefixes. Applications accessed wrong data stores through unintentional interactions. The bucket owner condition header mitigates this risk by requiring PutObject requests to match the bucket owner's account ID explicitly. This validation layer operates independently of namespace scoping. A second failsafe protects against misconfigured clients or typos in script logic.
Teams migrating from monolithic architectures frequently encounter naming conflicts. Account regional suffixes alone do not prevent errors if an application hardcodes a full bucket string belonging to another tenant. Operational complexity increases. Developers must update SDK calls to include the `x-amz-expected-bucket-owner` parameter. Code verbosity grows.
| Failure Mode | Namespace Only | Namespace + Owner Condition |
|---|---|---|
| Typo in Account ID | Allowed | Rejected |
| Cross-Tenant Read | Possible | Blocked |
| Script Copy-Paste Error | Possible | Blocked |
A script pointing to `prod-data-12345-us-east-1-an` could write to a competitor's bucket if the suffix guessing logic succeeds without this header. Enforce this condition via IAM policies to guarantee data isolation regardless of naming conventions. Validation checks add latency. The security gain outweighs the millisecond delay for critical workloads.
Migration Risks: Immutable Global Buckets and Namespace Limits
Existing cross-border buckets cannot be renamed to the new format. Legacy infrastructure naming conventions face a hard break. This immutability creates a permanent bifurcation. Old resources remain trapped in the global namespace constraints while new deployments adopt regional scoping.
Operators must recognize that S3 table buckets and vector buckets already apply an account-level namespace. The new general-purpose feature remains irrelevant for these specialized workloads. S3 directory buckets operate strictly within a zonal namespace. Governance policies face another layer of fragmentation. Teams attempting to unify naming standards maintain parallel logic for legacy versus modern resources. Migration paths require enabling S3 Versioning on source buckets to support replication into the new structure. This prerequisite blocks immutable archives. Strategic planning must account for this dual-namespace reality. A smooth upgrade path is impossible. Audit all current bucket types before enforcing new IAM policies. Valid directory or table bucket creation must not be blocked. The number 12345 appears in example identifiers. Single digit 1 marks the start of many suffixes. The year 2026 defines the publication context for these changes.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to this analysis of AWS's new account zone-based namespaces. Having previously managed high-traffic SaaS platforms where global bucket naming constraints often complicated multi-region deployments, Alex understands the operational friction this update resolves. At Rabata. Io, a specialized S3-compatible object storage provider, his daily work involves designing scalable data solutions for AI/ML startups that require smooth interoperability with AWS standards. This architectural shift directly impacts how engineers like Alex plan disaster recovery strategies and manage cloud-native applications across distributed environments. By using his experience with vendor lock-in challenges, Alex provides a practical perspective on how simplified namespace management enhances infrastructure flexibility for enterprises seeking transparent pricing and high-performance alternatives in the evolving object storage environment.
Conclusion
Scaling this dual-namespace architecture reveals a hidden operational tax: the cognitive load of maintaining parallel governance logic for legacy global buckets versus new regional scopes. As your inventory grows, the risk of misconfigured IAM policies increases exponentially because teams must constantly distinguish between immutable legacy identifiers and modern regional constraints. This fragmentation prevents true infrastructure-as-code standardization, forcing engineers to write conditional logic that degrades deployment velocity. The cost of this complexity eventually outweighs the minor savings from avoided naming collisions.
Adopt a strict "new workloads only" policy for regional namespaces starting immediately, with a hard deadline of Q3 2026 to freeze all legacy bucket creations. Do not attempt a lift-and-shift migration for existing archives; the technical debt of refactoring immutable global identifiers creates unacceptable downtime risks. Instead, treat the old global namespace as a deprecated zone destined for gradual attrition through natural data lifecycle expiration.
Run an audit script this week to tag every bucket lacking a region suffix in your inventory. Use these tags to automatically block non-critical applications from accessing global-scoped resources by next Friday, forcing new development teams to engage with the regional model exclusively. This immediate containment stops the bleeding of architectural consistency before the bifurcation becomes unmanageable.
Frequently Asked Questions
No, AWS charges no extra fee for using the new account regional namespaces feature. This update benefits the 75% of enterprises relying on object storage by removing global naming conflicts without adding financial burden to operations.
No, existing global buckets cannot be renamed to adopt the new suffix format directly. You must create new resources and copy data, a necessary step for the 75% of enterprises utilizing object storage to fully transition.
The combined prefix and mandatory suffix must fit within the strict 3 to 63 character limit. Long descriptive names often fail this check, forcing teams to abbreviate prefixes to accommodate the fixed-length structure required for valid creation.
Security teams enforce adoption using IAM policies with the s3:x-amz-bucket-namespace condition key. This ensures only valid regional names are created, supporting the 75% of enterprises that need rigid cost governance and resilient hybrid cloud strategies.
No, S3 table buckets use an account-level namespace while directory buckets remain zonal in scope. Only general purpose buckets utilize the new account regional namespace, leaving other bucket types unchanged under their existing architectural constraints.
