Storage costs jumped 234%: Stop buying more flash
Buying another 5 petabytes of storage is no longer a solution; it is a budgetary tumor consuming 234% more of your capital due to NAND flash inflation.
Stop treating storage as an infinite commodity. NAND flash prices have skyrocketed by 234%, turning simple bit retention into a crippling expense. Jensen Huang notes that 90 percent of enterprise information is unstructured. Building larger "reservoirs" for this deluge creates a funding bottleneck that starves core business objectives.
The myth that cheap storage solves data growth is dead. The economics of unlimited storage have collapsed under Memflation. Enterprises must value specific bytes over aggregate volume. Without shifting from capacity purchasing to intelligent lifecycle management, storage costs will consume the entire IT budget.
The Unsustainable Economics of Unstructured Data Growth
Jensen Huang's 90 Percent Unstructured Data Expense Reality
Jensen Huang identifies the bleeding artery: 90 percent of enterprise data exists as unstructured files. This isn't a capacity shortage; it's a capital allocation crisis. Treating every byte with equal importance forces high-cost primary storage to hoard low-value historical assets. Industry analysis confirms unstructured content typically consumes a significant share to 90% of total footprints, yet budget models rarely distinguish between active project files and dormant archives. The storage and memory squeeze of 2026 worsens this flexibility by raising costs precisely when AI initiatives require liquid capital.
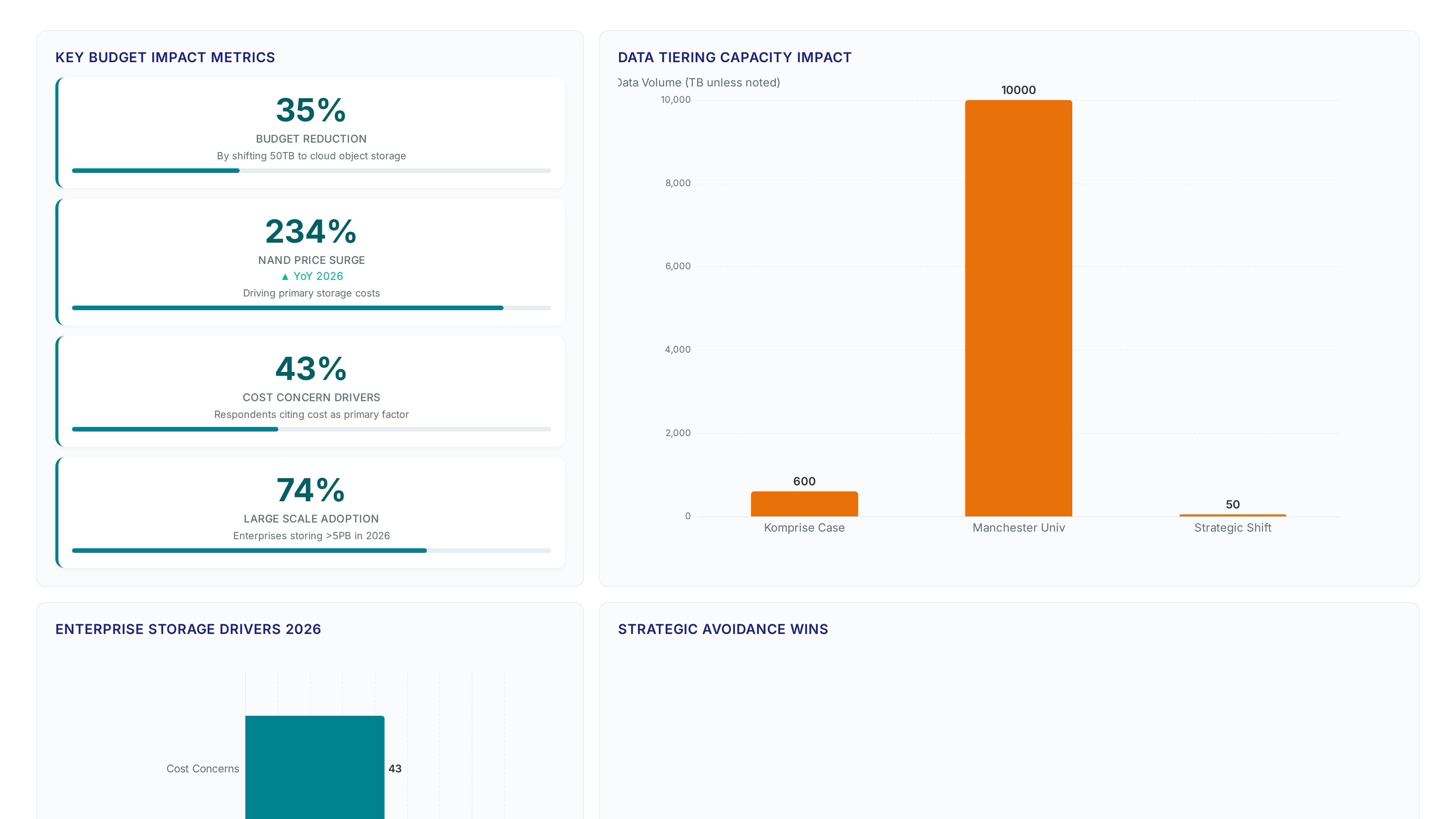
Capital locked in static housekeeping prevents investment in GPU-ready infrastructure. Operational data shows tiering just 600TB of cold data to object storage frees sufficient budget to fund new AI product development lines. The failure mode isn't a lack of space; it's the absence of policy-driven lifecycle rules that match storage cost to data value.
| Storage Tier | Typical Cost Profile | Data Value Alignment |
|---|---|---|
| Primary NVMe | Highest | Active, high-value assets only |
| Cloud Object | Lowest | Dormant, compliance, or backup data |
Flat storage architectures inflate the cyber threat surface without returning business utility. Every additional petabyte stored on expensive media increases the AI-ready infrastructure funding gap. Implement automated tiering immediately to convert fixed storage overhead into variable innovation capital.
Treating all bytes as fungible rainwater ignores that a sales headline holds vastly more value than a cleaning contract sub-item. The rainwater reservoir analogy collapses because data lacks uniform worth. Active deal files require flash performance; dormant logs belong in cold archives. This distinction drives the shift toward software-set storage controls, where the market now manages over 2 Zettabytes of enterprise assets through intelligent policy engines rather than static hardware pools.
Operators frequently misclassify high-value assets as bulk content, inflating primary storage costs without improving access speeds. An insurance carrier recently moved 600TB. Such moves illustrate that short-term retention strategies must separate operational urgency from long-term regulatory holds. Freezing old data fails when critical historical context remains buried in deep archives. Re-evaluate data age versus content relevance.
| Storage Tier | Data Value Trigger | Retention Logic |
|---|---|---|
| Primary Flash | Active transactional heat | Age plus access frequency |
| Hybrid Object | Compliance or audit need | Legal hold status |
| Deep Archive | Zero business utility | Destruction policy date |
New standalone solutions like Enterprise Vault ignoring non-fungibility leaves organizations paying premium rates for worthless bits while starving high-priority workloads of necessary IOPS. Classify incoming streams at ingestion to prevent value decay before archival policies can engage.
Capital Drain When Housekeeping Costs Block AI Innovation Funding
Excessive housekeeping spend on basic storage directly reduces capital available for AI development.
Organizations facing the storage and memory squeeze find that rising operational costs consume budgets meant for innovation. When $29.3 million sits trapped in expensive primary tiers for dormant files, that liquidity cannot fund GPU clusters. This expense problem forces IT leaders to choose between maintaining legacy archives and building the AI-ready infrastructure required for 2026 competitiveness. Surging demand for high-performance systems pressures teams to prioritize data frameworks over raw capacity, yet unchecked growth blocks this shift.
| Cost Center | Impact on Innovation |
|---|---|
| Primary Storage Over-provisioning | Delays GPU cluster procurement |
| Manual Tiering Operations | Consumes engineering headcount |
| Unmanaged Cold Data | Inflates backup licensing fees |
Failure to tier data logically results in a funding bottleneck where housekeeping blocks transformation. Komprise case studies demonstrate that moving vast data volumes from premium tiers to cloud object storage notably cuts operational expenses. Without this reduction, the storage budget acts as a tumor, expanding until it chokes investment in core business objectives. The inability to reallocate funds from low-value bytes leaves enterprises unable to support the very AI models their data should power. Enforce policy immediately to halt this capital drain.
Hidden Risks of Expanding Storage Without Governance
Defining the Expanding Cyber Threat Surface in Unmanaged Storage
Every additional petabyte of stored data directly expands the cyber threat surface while inflating governance overhead and compliance complexity. This proliferation creates an unmanageable risk profile where dormant files become latent entry points for ransomware actors targeting weak permissions. Gartner's 2026 Strategic Roadmap for Storage mandates the adoption (Gartner's alternatives) com/2025/12/02/gartners-storage-sermon-for-2026-2028) of cyber-storage and autonomous management to counter these malware threats through strict SLA outcomes. Without precise data classification, operators cannot identify cold assets suitable for tiering, leaving high-value attack surfaces exposed on expensive primary arrays.
- Elevated insurance premiums due to unquantified risk exposure
- Increased manual labor for forensic audits during breach investigations
- Regulatory fines stemming from inability to locate protected records
- Wasted flash capacity consuming budget needed for security tooling
Critics argue that aggressive tiering introduces latency penalties that alter business continuity for unexpected data recalls. Modern platforms like Datadobi's StorageMAP apply a metadata scanning engine (mDSE) to classify access patterns without impacting production workloads. This approach enables policy-driven workflows that automatically relocate stale data to cheaper object storage, shrinking the active attack surface. Ignoring this shift leaves organizations vulnerable to both cyber extortion and capital exhaustion as storage budgets consume funds assigned for innovation.
Applying Flexible Data Classification to Reduce Data Protection Burden
Measuring access rates enables operators to migrate dormant assets off expensive primary tiers, directly shrinking the protected attack surface. Michael Jack argues suppliers must evolve into data storage lifecycle suppliers rather than pushing the next 5 petabytes of raw capacity. This shift mirrors the virtualization transition where initial hardware revenue dips yielded long-term system growth through Jevons paradox.
Operators face hidden costs when retaining stale data on high-performance arrays:
- Inflated backup windows consuming network bandwidth
- Unnecessary replication of low-value objects across regions
- Expanded ransomware exposure on accessible file shares
- Compliance audits failing due to unclassified sensitive content
Critics claim automated tiering introduces latency risks for unpredictable workloads. Real-world deployments counter this fear; an unnamed insurer tiered over 600TB. Similarly, Datadobi's StorageMAP uses a metadata scanning engine (mDSE) to move 400TB in specific customer migrations, proving large-scale shifts remain non-disruptive. The limitation lies in initial metadata indexing overhead, which delays immediate cost savings until the metadata query language (mDQL) completes its first full estate scan.
Protecting unclassified data blindly wastes capital that could fund durability initiatives. Without this gatekeeping, the cyber threat surface expands linearly with every added petabyte, regardless of actual business value.
The Unsustainable Risk of Buying On-Premises Storage Without Governance
Purchasing expensive on-premises capacity without governance creates an unsustainable financial burden that ignores rising AI filtering demands.
Blindly adding petabytes inflates the cyber threat surface while failing to address the root cause of storage inefficiency. This approach forces administrators to filter access across vast, unclassified datasets, drastically increasing the computational load required for AI selection processes. The surge in NAND flash prices makes primary storage significantly costlier, driving urgent need for tools that tier data to cheaper object stores. Komprise case studies demonstrate that moving dormant data reduces operational expenses, yet many operators continue buying hardware instead of implementing policy controls.
Hidden costs of unmanaged expansion include:
- Escalating license fees for backup software covering useless data
- Increased power and cooling for arrays holding stale files
- Slower threat detection scans across bloated file systems
- Higher compliance audit failure rates due to unknown data locations
Simply buying more space treats a symptom while the disease of unclassified data grows. Without a metadata scanning engine, operators cannot distinguish high-value assets from digital waste, leaving critical budgets locked in low-return infrastructure. Datadobi's StorageMAP deploys as a Linux VM to scan environments without hardware appliances, enabling immediate visibility into access patterns. This architecture allows firms to shift from capacity hoarding to value-based tiering, directly countering the expense problem. Classify incoming data at ingestion to prevent future accumulation of ungoverned assets.
Mechanics of Policy-Driven Data Lifecycle Orchestration
Defining the Intelligence Layer for Unstructured Data Orchestration

A new category of software is needed to serve as the intelligence and orchestration layer for unstructured data, replacing manual tiering scripts with automated policy enforcement. This architecture discovers fragmented assets across hybrid clouds, aligns them with business value, and operationalizes movement without human intervention. Unlike hardware vendors selling integrated appliances, this approach relies on a software-only, vendor-neutral layer to prevent system lock-in while managing heterogeneous environments.
| Traditional Model | Intelligence Layer |
|---|---|
| Sells raw capacity units | Classifies data at ingestion |
| Reacts to full disks | Predicts tiering needs |
| Ignores file content | Analyzes semantic value |
| Increases attack surface | Shrinks risk profile |
Operators must classify data continuously because a byte of data has a different value than another byte based on age or content. Experts predict that in 2026, unstructured data will emerge as the definitive backbone of AI innovation, making ingestion-time classification mandatory for model training efficiency. The limitation lies in legacy silos; without a unified view, policies fail to execute across disjointed namespaces. A global leader in this space provides the necessary orchestration to bridge these gaps, ensuring metadata travels with the payload during migration.
The cost of inaction is measurable: expanding storage without governance results in an AI access filtering and selection increase that throttles compute resources. Stop treating storage as a passive bucket. Manage it as an active, value-aware asset.
Operationalizing Automated Tiering with StorageMAP and DobiMigrate
StorageMAP version 7.3 introduced policy-driven workflows to automate moving stale data without disrupting compliance. Operators deploy the unstructured data workflow engine to scan file systems, measuring access rates against set thresholds. This process identifies dormant assets suitable for migration to cheaper public cloud tiers.
The execution phase relies on the unstructured data mobility engine to transfer identified objects while preserving metadata integrity. Successful deployments have migrated 400TB of data, proving scalability for large enterprises. Datadobi positions this software-only approach as a vendor-neutral alternative to hardware-bound appliances.
| Component | Function | Output |
|---|---|---|
| Discovery Module | Scans namespaces | Access rate heatmaps |
| Policy Engine | Evaluates rules | Migration job queues |
| Mobility Core | Executes transfers | Verified cloud objects |
Aggressive tiering policies risk breaking legacy applications expecting low-latency local access. False positives involve manual remediation and potential service disruption during peak hours.
Validate policies against a shadow dataset before enabling automatic deletion or archiving. This precaution prevents accidental loss of semi-active data that sporadic access patterns might obscure. The operational shift reduces primary array pressure but increases dependency on cloud egress bandwidth management.
Storage suppliers resist lifecycle orchestration because immediate capacity sales drop when operators tier dormant data to cheaper archives. Michael Jack likens this friction to early server vendor suspicion of VMware, where a single virtualization license canceled ten hardware orders. Initial revenue dips frighten vendors, yet the Jevons paradox dictates that efficiency ultimately expands total consumption.
| Virtualization Era | Lifecycle Storage Era |
|---|---|
| VM density reduced server count | Tiering reduces primary array volume |
| Vendors feared lost transactions | Suppliers fear lost petabyte sales |
| Long-term compute demand surged | Long-term data value access grows |
Automated tiering triggers only after policies measure access rates, determining exactly when to move data to cheaper storage based on age rather than instinct. This shift requires suppliers to embrace autonomous storage mandates that prioritize SLA outcomes over raw capacity units. The limitation remains economic: some vendors charge per TB for migration actions, creating a disincentive to move large datasets to cold tiers.
Ignore short-term vendor revenue anxiety. Enforce strict data lifecycle policies immediately. The consequence of inaction is a bloated attack surface where every extra petabyte increases compliance complexity without adding business value. Suppliers who enable this transition secure deeper relationships than those clinging to transactional volume.
Strategic Implementation for Reducing Storage Budgets
Defining the Data Lifecycle Supplier Model Shift
Investing in data classification software becomes mandatory when raw capacity purchases fail to align costs with actual data value. Michael Jack argues that large consultancies, specifically Gartner, Arthur Anderson, and Price Waterhouse, currently misunderstand the necessity of ending the endless buy-more-capacity mindset. The strategic pivot requires suppliers to act as data lifecycle partners rather than mere hardware vendors. This shift transforms the vendor relationship from transactional sales into enduring collaborations focused on changing data value.
- Deploy software to scan existing estates and classify unstructured assets by age and access frequency.
- Establish policies that automatically tier dormant data to cheaper storage, preventing budget bloating.
- Measure success by reduced operational expenses rather than total petabytes sold.
Operators face a tension between immediate revenue loss from reduced capacity sales and long-term customer retention through cost optimization. Unlike hardware-centric models, this approach relies on a software-only layer to manage heterogeneous environments without vendor lock-in. Real-world evidence supports this transition; Komprise case studies show that tiering over 600TB of data significantly cuts capacity needs. The SDS market now manages vast data volumes, signaling a move toward software-centric control confirmed by enterprise partners. Embrace this model to avoid the fiscal toxicity of unmanaged growth.
Executing the Manchester University 10 PB Avoidance Strategy
Manchester University avoided a 10 PB PowerScale purchase by migrating stale assets to public cloud storage using Datadobi tools.
- Scan the existing estate to classify unstructured assets by age and access frequency.
- Execute the migration workflow to move identified files while preserving metadata integrity.
This approach prevents capital expenditure on hardware that merely houses low-value bits. The University of Manchester picked this platform to change its storage optimization strategy, proving that software orchestration beats raw capacity buys. Every extra petabyte stored increases the cyber threat surface and compliance complexity without adding business value. Moving data off fast, expensive storage frees budget for higher priority needs like AI innovation.
The limitation involves licensing models where migration features often require separate add-ons beyond core analytics functionality. Final costs for such deployments are determined via a discovery conversation rather than a fixed public price list, creating budget uncertainty for initial planning. This contrasts with traditional hardware purchases where unit costs remain transparent upfront. Storage suppliers will have stronger relationships if they embrace this lifecycle viewpoint instead of pushing the next transaction. The software-only layer prevents system lock-in while managing heterogeneous environments effectively. Classify data so storage costs reflect changing data value.
Refuting the Zero-Sum Game Myth in Storage Migration
Avoiding a 10 PB PowerScale purchase at Manchester University initially appeared as a revenue loss for Dell but actually secured long-term vendor relevance. Michael Jack rejects the zero-sum conclusion, arguing that helping customers classify data creates stronger, more enduring relationships than simply selling capacity. Early skepticism toward VMware mirrors current storage vendor fears, where efficiency gains were mistaken for total market contraction.
| Vendor Fear | Actual Outcome |
|---|---|
| Reduced hardware unit sales | Expanded total addressable market |
| Lost immediate transaction | Gained lifecycle management role |
| Static capacity metrics | Flexible value-based pricing |
Operators must execute specific steps to realize these mutual benefits without disrupting production workflows.
- Deploy software-only intelligence layers to scan heterogeneous environments without vendor lock-in.
- Configure policies that migrate dormant files to public cloud tiers while keeping active data on-premises.
- Use discovery conversations to determine licensing costs rather than relying on fixed price lists.
The Hybrid Cloud Storage market demonstrates that software orchestration drives hardware refresh cycles rather than eliminating them. Moving data off expensive primary arrays frees capital for higher-priority AI initiatives, indirectly fueling demand for next-generation GPU-ready storage systems. Vendors resisting this shift risk obsolescence as operators prioritize changing data value over raw terabyte counts. Embrace the data lifecycle supplier model to align vendor success with customer financial health.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing scalable, S3-compatible storage solutions directly addresses the article's thesis that continually increasing data capacity is financially unsustainable. Having previously led DevOps initiatives at high-traffic SaaS and e-commerce platforms, Kumar possesses firsthand experience managing the explosive growth of unstructured data that burdens enterprise budgets. At Rabata. Io, a provider focused on eliminating vendor lock-in and reducing storage expenses, he engineers systems that balance performance with fiscal responsibility. This practical background in mitigating storage costs while ensuring disaster recovery readiness makes him uniquely qualified to analyze the economic risks of unchecked data accumulation and propose viable architectural alternatives for modern enterprises.
Conclusion
Scaling unstructured data architectures inevitably breaks when static capacity planning collides with flexible access patterns, causing operational expenses to silently cannibalize innovation budgets. The real friction point is not storage volume but the latency of insight; without continuous metadata analysis, organizations cannot distinguish between cold liabilities and hot assets until a crisis forces a costly recall. This inefficiency creates a hidden tax on every AI initiative, as funds meant for model training instead subsidize dormant archives on premium tiers.
Mandate a quarterly data valuation audit starting immediately, tying storage tiering directly to project ROI rather than arbitrary retention schedules. Do not wait for the next hardware refresh cycle to address this imbalance; the window to reclaim trapped capital before the next fiscal planning phase is closing. Renegotiate vendor partnerships to prioritize software-set orchestration over raw disk procurement, ensuring that infrastructure scales with actual business value rather than accumulated hoarding.
Start this week by deploying a non-intrusive metadata scanner across your top three most expensive storage pools to identify files untouched for over 18 months. Use this baseline to project immediate savings and fund a pilot migration to cold object storage within 30 days, proving the financial viability of intelligent lifecycle management before expanding scope.
Frequently Asked Questions
Buying more capacity creates a budgetary tumor that starves innovation funds. NAND flash prices have surged 234%, making endless expansion financially unsustainable for enterprises facing continuous data deluges.
Unstructured files constitute 90 percent of total enterprise data, creating a massive expense problem. Treating these low-value bits like high-value assets forces organizations to overspend on expensive primary storage media.
Tiering just 600TB of cold data to object storage frees sufficient budget for new AI product lines. This specific volume demonstrates how moving dormant assets unlocks capital for critical business innovation.
Yes, unstructured content typically consumes 70% to 90% of total storage footprints across modern enterprises. Yet budget models rarely distinguish between active project files and dormant archives within this massive volume.
The storage budget slice grows like a tumor, preventing spending on other important organizational needs. This funding bottleneck restricts investment in core business objectives while housing low-value historical digital assets.
