Data readiness beats raw compute for AI scale
HPE's Q2 2026 server revenue hit $5.45 billion, proving AI infrastructure demand now dwarfs early experimental budgets.
Data readiness has officially replaced raw compute power as the primary bottleneck for enterprise AI. While early pilots funneled 80 percent of spending into GPUs, leaving storage to scavenge remaining funds, production realities have inverted this hierarchy. As Jim O'Dorisio notes, the assumption that data is local and curated fails immediately when facing distributed, governed enterprise datasets that are expensive to move and impossible to ignore.
Quicker models do not solve adoption hurdles. Inefficient data pipelines create an unsustainable tax on scaling operations. Data readiness acts as the critical constraint in modern workflows, replacing naive hyperscaler assumptions with rigorous governance. Shared object storage outperforms local disks because hybrid architectures are no longer optional for sustaining high-throughput workloads. With Gartner predicting 40 percent of enterprises will adopt hybrid computing by 2028, understanding these storage dynamics is the difference between a viable AI strategy and a costly failure. (Gartner's cisco systems vs hewlett packard enterprise hpe)
Data Readiness as the Primary Constraint in Enterprise AI
Data Readiness as the New Primary Constraint in Enterprise AI
Data readiness marks the operational state where governed data reaches inference engines without manual staging or duplication. Early AI budgets allocated roughly 80 percent of capital to compute, treating storage as a passive afterthought funded by leftover dollars. This model collapses at production scale. AI's limiting factor is not model capability, but data readiness. Global spending on AI initiatives reached a substantial amount by 2026, yet 79% of enterprises face challenges in adoption due to rigid workflow ownership and fragmented IT control. The shift from experimentation forces operators to confront data distributed across object, file, and block systems that cannot be simply copied or rebuilt for each project.
Eliminating Data Duplication Liabilities in Production AI Pipelines
Data duplication transforms from a temporary staging tactic into a permanent financial liability as pipelines scale to production volumes. Moving datasets between silos without shared access layers incurs massive overhead, turning data movement into a tax that erodes project margins. Operators must identify the assets across distributed environments rather than copying them for each new model iteration. A Tier 1 automotive supplier achieved $4.1 million in annual savings by addressing these specific infrastructure inefficiencies through a targeted investment in consolidated storage architecture. This approach prevents the redundant ingestion of identical records into multiple inference engines.
The Financial Risk of Naive Cloud-API AI and Unchecked Data Movement
Naive cloud-API usage generates monthly bills exceeding $1 million when enterprises treat data movement as free. Assumptions valid for one-off training runs collapse when production pipelines cannot be rebuilt for every project. Data duplication shifts from a temporary staging tactic to a permanent liability that compounds egress fees. Organizations relying on transient compute instances without shared storage layers face unpredictable cost spikes. The financial exposure stems directly from copying datasets across availability zones rather than accessing them in place. Hybrid computing paradigms offer a mitigation path, yet only 8% of leading enterprises currently deploy such architectures into critical workflows. The gap between current adoption and future necessity creates a narrow window for remediation before penalties become unsustainable. Operators must decouple storage from compute to prevent data gravity from dictating budget allocation. Ignoring this architectural shift guarantees that storage inefficiencies will consume capital intended for model innovation.
Storage Mechanics for RAG Systems and KV Cache Optimization
RAG Storage Requirements for Terabyte-Scale Enterprise Datasets
RAG systems commonly operate over datasets ranging from terabytes to tens of terabytes, demanding persistent shared access rather than transient staging. Unlike experimental workloads, this data is stored, reused, refreshed, and accessed concurrently by inference systems that run continuously. Operators must balance high-bandwidth retrieval for embedding lookups against the need for cost-effective capacity as volumes expand toward tens of terabytes. Object storage resolves this by decoupling compute from capacity, allowing multiple inference nodes to access the same dataset without duplication. This architecture prevents the latency spikes observed when local NVMe fills up during long-context processing.
Optimizing KV Cache Persistence to Reduce GPU Utilization Costs
Persisting KV cache to shared object storage eliminates redundant context recomputation across inference nodes, directly cutting GPU cycle waste. The key-value cache stores attention states to accelerate token generation, yet local NVMe fails to scale this state across a cluster. Recomputing context for every request inflates latency and burns expensive accelerator cycles unnecessarily. Operators must shift from disposable local state to a persistent, shared layer that allows multiple inference engines to reuse prior computations. This architectural change transforms storage from a passive bucket into an active performance multiplier. Implementing this persistence requires hardware capable of sustaining concurrent read throughput without becoming a bottleneck.
Architectural Failure Modes When Data Locality Assumptions Break at Scale
KV cache exposure reveals the hard limits of architectures assuming disposable state as inference deployments scale beyond single nodes. Engineering teams deploy ad hoc solutions that spike operational risk when storage cannot sustain high-bandwidth access without copying data. This compensation strategy triggers a feedback loop where temporary fixes become permanent technical debt. Hardware vendors now enforce flexible pricing on memory components between order and shipment dates existing orders. A 26 quarteroverquarter price increase of 55% for highbandwidth memory turns provisio architecture decisions into budget disasters Q1 2026 QoQ Increase. Supply constraints drive these record costs, forcing operators to choose between performance and fiscal stability strong demand Local NVMe fails to share context across the cluster, making recomputation the default behavior for distributed inference engines. The resulting latency violates service-level agreements for real-time applications relying on RAG systems. Operators must migrate from local disk to shared object layers to prevent context thrashing.
Shared Object Storage Versus Local Disks for Inference Workloads
Decoupled Inference Architectures and Object Storage Fundamentals
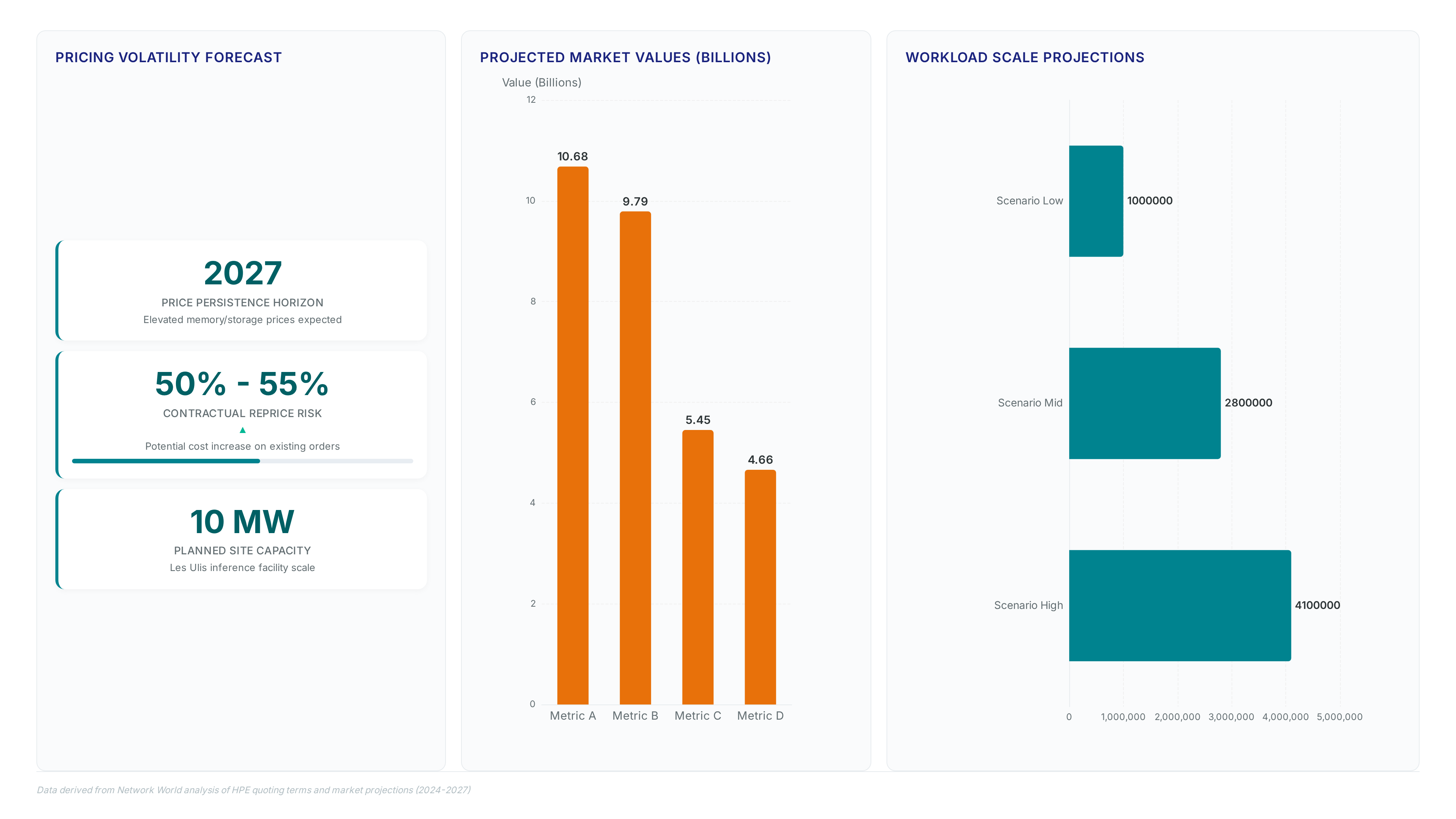
Distributed GPU clusters demand shared object storage to prevent data silos from fracturing inference pipelines. Local disks compel teams to duplicate datasets whenever multiple nodes require identical files, creating a liability that grows alongside cluster size. Object storage evolves from a supporting utility into a core architectural component by enabling systems decoupled from individual hosts. This transition sustains persistent data intelligence nodes that manage intermediate artifacts without sacrificing shared access benefits. Hardware cost volatility demands careful planning, as vendors now reserve rights to reprice existing orders for memory components prior to shipment. Market analysts project these elevated prices will persist well into 2027, rendering static local capacity a significant financial risk. New facilities like the planned 10 MW inference site at Les Ulis demonstrate the massive scale required for modern deployment.
Operational flexibility often conflicts with raw access speed. Local storage provides low latency yet fails catastrophically when workloads exceed single-node capacity. Shared infrastructure introduces network hops but prevents the exponential cost growth associated with duplicated datasets. Mission and Vision recommends treating storage as an active engine rather than a passive bucket. Concurrent inference across clusters stalls when local disks force data duplication instead of enabling shared access. Multiple nodes accessing identical datasets on local storage creates a liability where capacity requirements scale linearly with node count rather than data volume. Object storage resolves this tension by decoupling compute from capacity, allowing frameworks to consume data via APIs and metadata without traditional locality constraints. This alignment prevents the operational risk of ad hoc copying solutions that spike costs when hardware vendors reprice existing orders due to memory shortages.
Latency sensitivity remains a constraint, as raw object retrieval cannot match local NVMe speeds for every operation. Architects mitigate this gap by deploying data intelligence nodes that cache hot paths while retaining the single source of truth in shared storage. Sovereign AI initiatives further complicate deployment by demanding localized, compliant infrastructure over centralized models multi-billion dollar opportunities. HPE GreenLake delivers these resources as a service to secure colocations, bypassing the need for permanent on-premise capital expenditure. HPE InfoSight uses full-stack telemetry to optimize these environments, matching workload performance to infrastructure capability. Operators must prioritize architectures that treat storage as a core layer rather than a passive accessory.
Local Disk Limits Versus Shared Object Storage Economics
Local NVMe fails to scale KV cache across nodes, forcing expensive context recomputation for every inference request. Tightly coupled storage architectures assume data locality, a premise that collapses when RAG systems access tens of terabytes concurrently. Operators attempting to mirror datasets on every GPU host incur a capacity tax where storage costs rise linearly with cluster size. This duplication creates a liability, as ad hoc synchronization scripts introduce fragility into production pipelines. When teams compensate for poor storage performance with manual copying, they increase operational risk while burning accelerator cycles on idle wait states.
Shared object storage decouples compute from capacity, allowing multiple inference engines to access identical datasets without replication. This model aligns with how modern frameworks consume data via APIs rather than block-level locality. However, the economic advantage depends on avoiding hardware procurement traps where vendors reprice existing orders HPE executives expect elevated component prices to persist well into 2027, making fixed-cost consumption models vital for budget stability. Deployments using HPE InfoSight apply full-stack telemetry to predict these bottlenecks before they impact latency.
Raw throughput often clashes with data readiness requirements. Local disks offer low latency for single tenants but fail the multi-tenant reuse test required for enterprise scale. A shift to shared infrastructure eliminates the need to rebuild pipelines for each project, transforming storage into an active efficiency layer. Operators adopting data intelligence nodes can accelerate access to intermediate artifacts while maintaining a single source of truth. This approach prevents the scenario where temporary fixes become permanent technical debt, ensuring that storage economics support rather than hinder AI scalability.
Implementing a Scalable Shared Storage Architecture for AI
Data Intelligence Nodes and Decoupled Inference Architecture
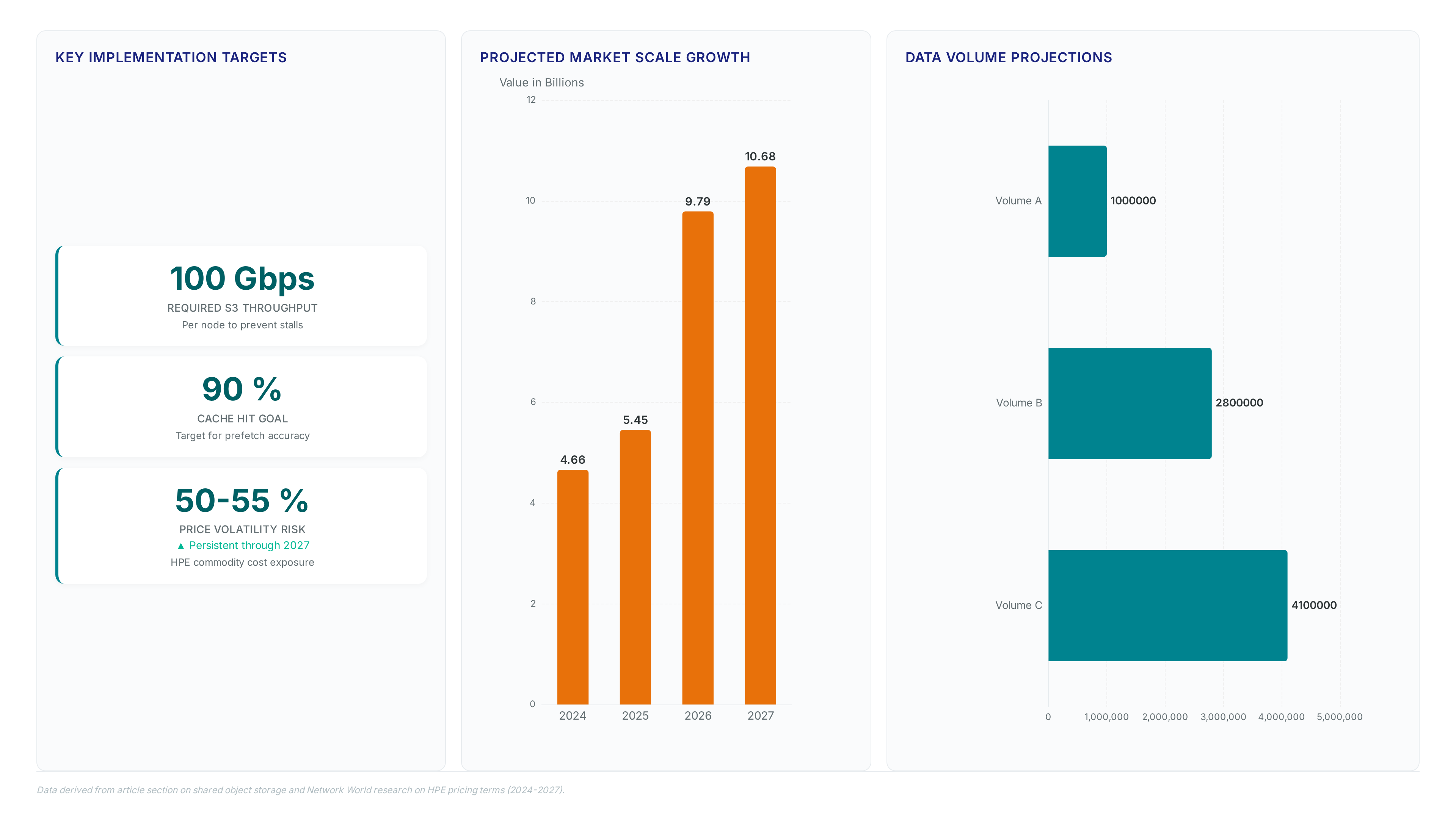
Implementing shared object storage begins by deploying data intelligence nodes that cache hot datasets locally while maintaining a single source of truth.
- Configure the storage cluster to expose high-performance S3-compatible endpoints for direct accelerator access.
- Enable telemetry-driven policies using HPE InfoSight to predict access patterns and pre-fetch embedding vectors before inference requests arrive.
- Map persistent KV cache volumes to the object layer, allowing multiple GPU hosts to read identical context windows without local duplication.
This architecture separates compute scaling from capacity growth, eliminating the linear cost penalty of mirroring terabytes on every node. However, decoupling introduces latency variance if the intelligence layer fails to predict cache misses accurately. Operators must balance aggressive prefetching against network saturation, a tension that depends heavily on workload burstiness. The financial stakes rise because commodity pricing remains volatile; vendors now retain rights to adjust costs for existing orders based on memory market fluctuations. Ignoring this contractual exposure while over-provisioning local NVMe creates a double liability of wasted capital and rigid infrastructure. Decoupled inference succeeds only when the storage fabric absorbs data movement complexity, letting accelerators focus purely on matrix multiplication.
Integrating HPE Data Fabric Software for Unified AI Data Access
Deploying HPE's Data Fabric Software requires configuring unified namespaces that bridge on-premises silos with HPE GreenLake services to eliminate data stalling.
- Instantiate a global namespace that aggregates disparate file and object repositories without moving underlying physical data.
- Apply policy-based tiering rules to automatically migrate cold embedding vectors to cost-effective capacity layers while keeping hot datasets local.
- Enable S3-compatible gateways on the fabric edge to allow inference clusters to retrieve context windows directly from the unified layer.
This architecture prevents the linear cost explosion seen when teams mirror tens of terabytes across every GPU node.
Verify S3 endpoint throughput exceeds high bandwidth per node to prevent inference stalls during concurrent RAG access.
- Confirm the storage cluster serves multiple access protocols simultaneously without creating duplicate data copies across tiers.
- Enable telemetry-driven prefetching using full-stack telemetry to predict embedding vector usage before GPU requests arrive.
- Validate that KV cache persists on the object layer, allowing shared context windows without local NVMe mirroring.
- Audit pricing clauses for commodity cost increases to avoid margin erosion when memory markets tighten through 2027.
| Validation Step | Pass Criteria | Failure Mode |
|---|---|---|
| Protocol Concurrency | File and Object active | Data silos reform |
| Cache Persistence | Shared read/write access | Context recomputation |
| Cost Protection | Fixed pricing until shipment | Post-order repricing |
Teams ignoring these checks face ad hoc scripts that fragment the data layer and spike operational risk. The limitation is strict: storage must decouple capacity from compute scaling to avoid linear cost growth.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing S3-compatible object storage solutions for AI startups and enterprises directly informs his perspective on how artificial intelligence is reshaping infrastructure demands. As organizations struggle with the massive data volumes required for AI training, Kumar's hands-on experience building scalable, vendor-neutral storage systems provides critical insights into overcoming traditional bottlenecks. At Rabata. Io, a provider dedicated to democratizing enterprise-grade object storage, he actively engineers alternatives to legacy cloud providers that eliminate hidden egress fees. This practical background allows him to articulate why modern object storage must evolve from a backend utility into a strategic asset, ensuring that high-performance data access remains accessible and affordable for the next-generation of AI-driven innovation.
Conclusion
Scalability fractures when data movement latency outpaces GPU clock cycles, turning storage into a bottleneck that throttles ROI regardless of compute power. As hybrid architectures swell to 40% adoption by 2028, the hidden tax of maintaining disjointed data copies will erode margins quicker than hardware depreciation. Organizations must shift from reactive capacity planning to proactive data locality strategies immediately, or face compounding inefficiencies that manual scripting cannot resolve. The window to lock in fixed pricing before market volatility hits in 2027 is closing; delaying this architectural consolidation guarantees exposure to unpredictable repricing clauses.
Commit to a full storage protocol audit by Q4 2027 to identify where duplicate data copies inflate your baseline costs. Do not wait for the next budget cycle to address these structural debts. Start this week by measuring the ratio of data transferred versus data processed across your current inference pipelines to quantify the specific bandwidth tax your team pays for fragmented access. This single metric reveals whether your infrastructure supports scale or actively sabotages.
Frequently Asked Questions
Most companies fail because data readiness, not model power, is the real bottleneck. Global spending hit $184 billion, yet 79% of enterprises face adoption challenges due to fragmented data controls.
Ignoring necessary architectural changes causes unexpected cost spikes driven by unplanned data movement taxes. Organizations risking this shift face a 30% rise in underestimated infrastructure expenses that erode project margins quickly.
Addressing infrastructure inefficiencies through consolidated storage architecture eliminates redundant data copies effectively. A Tier 1 automotive supplier achieved $4.1 million in annual savings by stopping the duplicate ingestion of records.
Centralizing copies is now physically impossible because most data originates outside traditional facilities. With 75% of enterprise data projected to come from external sources, copying creates massive logistical and financial barriers.
Early projects treated storage as a passive afterthought funded only by leftover dollars. These budgets allocated roughly 80 percent of capital to compute, a model that collapses at production scale today.
