Storage bottlenecks kill AI production speed fast
Enterprise AI spending hit $37 billion by 2027, yet storage remains the critical bottleneck. The industry's fixation on GPU acceleration has obscured the reality that data readiness now dictates production success more than raw compute power. Shifting from experimental pilots to production workflows exposes the inefficiency of legacy data hierarchies, where compute budgets historically consumed 80 percent of resources while storage received leftovers. Hybrid computing paradigms, which Gartner predicts will reach 40 percent adoption by 2028, demand a fundamental rearchitecture of how enterprises manage distributed data silos. Eliminating data movement taxes and enforcing governance without crippling inference speeds requires specific technical shifts.
The narrative moves beyond theoretical scaling to address the concrete mechanics of shared object storage and KV cache optimization. Transitioning from narrow, curated datasets to complex, governed enterprise environments reveals why performance discussions must expand beyond interconnects to include data accessibility and trust. Ignoring these storage realities turns potential AI dividends into operational liabilities, regardless of model sophistication.
Data Readiness Defines the New AI Infrastructure Model
Data Readiness as the Primary AI Limiting Factor
Data readiness marks the point where enterprise information becomes accessible, governed, and trusted for immediate model consumption. Early experimental AI projects operated on local, curated datasets, prompting teams to direct roughly 80 percent of budgets toward compute while treating storage as an afterthought. This financial split collapses in production environments where data spans distributed object, file, and block systems across multiple regulatory regimes. The bottleneck shifts from raw model capability to the infrastructure supporting hybrid computing model architectures. Storage dictates which data operators can apply, how fast access occurs, and whether that information carries sufficient trust for business workflows. Delays now originate from identifying the data across silos and enforcing security constraints rather than selecting larger models.
Inefficient data movement acts as a hidden tax on inference pipelines. Organizations relying on naive cloud-API usage without optimized storage face monthly bills exceeding $1 million. The penalty for duplication becomes severe when datasets grow to tens of terabytes for retrieval-augmented generation workloads.
| Early AI Assumption | Enterprise Reality |
|---|---|
| Data is local and disposable | Data is distributed and long-lived |
| Storage is passive persistence | Storage enables active preparation |
| One-off training runs | Continuous inference services |
Adopting shared object access reduces unnecessary copying and aligns with how modern frameworks consume information. Companies like Eli Lilly selected specific infrastructure to support these enterprise AI initiatives, prioritizing data flow over raw GPU count. Increased compute spending yields diminishing returns as pipelines stall waiting for usable data without this architectural shift. Data silos force operators to manually reconcile object, file, and block systems before AI pipelines can ingest training sets. Enterprise data spans these disparate storage tiers across multiple infrastructure generations, creating friction that delays model deployment more than algorithm selection issues. Most enterprise AI delays stem from the work required to make data usable rather than model complexity or hyperparameter tuning.
The operational burden involves identifying the datasets, transforming formats without creating duplicate copies, and enforcing security policies across fragmented environments. Training workloads require high-throughput sequential reads from consolidated pools. Inference demands low-latency random access to shared repositories. This divergence forces architects to choose between copying data for performance or accepting latency penalties to maintain a single source of truth. Adoption of hybrid computing model Evaluation of vendor capabilities often highlights gaps in service support when migrating petabyte-scale archives to modern object stores. Teams resort to custom scripts that increase technical debt and obscure data lineage without a unified namespace. Clean data exists but remains inaccessible to GPU clusters in stalled projects where inefficiency manifests. Storage architectures must evolve from passive persistence layers into active preparation engines that serve both training and inference simultaneously. Underutilized compute resources and inflated operational expenses result from failure to bridge these silos.
The Strategic Cost of Treating Storage as Leftover Infrastructure
Funding storage with leftover dollars creates immediate capacity gaps that stall production AI pipelines despite aggressive budget growth. Historical allocation models assigned compute as the primary investment while treating persistence layers as passive commodities, a strategy incompatible with modern data readiness requirements. As 92% of organizations plan to increase AI spending, continuing to underfund storage architectures invites severe operational friction. Memory market volatility exacerbates this risk, with average DRAM prices projected to surge notably in early 2026 due to supply constraints. Vendors like HPE have amended contract terms to allow price adjustments on orders between quoting and shipment, reflecting the instability of rising memory costs. Operators relying on fixed legacy budgets face immediate shortfalls when hardware expenses escalate unexpectedly.
The consequence extends beyond simple cost overruns into architectural stagnation. Elevated storage prices are expected to persist through 2027, forcing teams to choose between scaling capacity or maintaining performance tiers. Data movement becomes a prohibitive tax when infrastructure cannot support shared access patterns without duplication. Teams compensating with ad hoc copies increase latency and fracture governance policies. Storage transforms from a utility into a strategic bottleneck that nullifies compute investments. One substantial retailer reported delaying three separate generative AI rollouts because their storage tier could not sustain the required IOPS without tripling costs. Another financial services firm found that 1 out of every 4 GPU hours sat idle waiting for data staging to complete. These inefficiencies compound quickly when scale reaches 4142928 records per second in high-frequency trading models. Budgets allocated in 2026 must account for these realities or risk total project failure by 2027. Eighty percent of failed pilots cite data availability as the root cause rather than model accuracy. A single unoptimized copy job can consume 20 percent of available network bandwidth during peak training windows.
Shared Object Storage Architectures Power Scalable RAG and Inference
Decoupled Inference Architectures via Shared Object Storage
Shared object storage lets inference nodes pull identical datasets without duplicating files on local hosts, breaking the concurrency logjam found in many RAG systems. RAG data sits in place, gets reused, refreshes on schedule, and serves concurrent requests from inference engines that never shut down. This persistence demands infrastructure that acts as a core architectural pillar rather than a passive accessory. Designers must separate training throughput needs from inference latency requirements when building access layers.
| Data Locality | Tightly coupled to GPU host | Decoupled across cluster |
|---|---|---|
| Scaling Model | Vertical ( | Horizontal (add nodes) |
| Duplication Risk | High (copies per pod) | None (single source) |
| Cost Sensitivity | Exposed to DRAM prices volatility | Optimized for capacity |
Tight coupling between compute and storage creates financial pain when memory markets swing, especially since elevated memory costs will remain high through 2027. Separating storage from compute lets teams scale inference capacity without buying more expensive accelerator memory. Data intelligence nodes speed up access to these shared repositories while keeping a single source of truth intact. Shared access does bring latency variance that local disks avoid entirely. Full-stack telemetry data covering compute, network, and storage becomes mandatory to find the right operating environment for each workload. Operators cannot tune access patterns for sub-millisecond retrieval without this visibility. The design choice sacrifices raw locality for scalability, assuming the control plane handles caching aggressively. Mission and Vision suggest using policy-based tiering to keep hot embeddings close to inference engines while moving cold documents to capacity-optimized pools.
Serving Persistent RAG Datasets Across Distributed Clusters
Enterprise RAG systems now serve terabytes to tens of terabytes of unstructured data across distributed inference nodes without staging extra copies. Shared object storage separates data location from compute resources, letting multiple clusters hit identical datasets at once while avoiding duplication taxes. This setup supports continuous refresh cycles where embeddings and metadata evolve with source documents instead of sitting as static snapshots. Operators need data intelligence nodes to speed up access patterns that standard object interfaces cannot handle alone. These intermediaries cache hot subsets and manage intermediate artifacts, bridging the gap between scale-out durability and the low-latency random reads needed for token generation. Balancing central governance with edge performance creates tension; excessive caching rebuilds silos, while insufficient caching introduces unacceptable query delays.
Real-world scale proves this method works, as EY (Ernst & Young) deployed its EYQ platform to over 300,000 professionals globally, requiring storage that handles governed experimentation across all service lines simultaneously. Investment timing hinges on data volume growth rates and the cost of idle GPU cycles waiting for I/O completion. Shifting to shared architectures becomes mandatory rather than optional once datasets exceed local disk capacity or require multi-region access.
| Pilot | Local-attached NVMe | Capacity limits scaling |
|---|---|---|
| Production | Shared Object Store | Network latency to data |
| Global Scale | Intelligent Edge Caching | Cache coherence overhead |
Organizations ignoring this shift face rising infrastructure costs as memory prices fluctuate, with average DRAM prices expected to stay elevated through 2027. Mission and Vision advises treating storage as a primary design constraint, not an afterthought funded by leftover budget dollars.
Operational Risks of Ad Hoc Storage Solutions in AI Pipelines
Inference systems built on local or tightly coupled storage struggle to scale when demand spikes. Operators trying to bypass shared architectures often deploy ad hoc solutions that fragment data governance and inflate total cost of ownership. This approach forces engineering teams to manually sync datasets across nodes, introducing latency penalties that cancel out accelerator throughput gains. Market volatility complicates these stopgap measures, as price adjustments on server orders now happen between quoting and shipment due to rising memory costs. Relying on local disks creates a fragile dependency where hardware scarcity halts pipeline progress immediately.
The operational burden shifts from model optimization to frantic data reconciliation. Teams lose visibility into data lineage when copies proliferate outside central management planes. Elevated component costs are expected to persist well into 2027, driving the need for flexible contracts rather than reactive hardware purchases. Organizations face compounding risks during failure recovery scenarios without a unified layer.
| Data Consistency | Manual sync required | Automatic convergence |
|---|---|---|
| Cost Predictability | Volatile spot pricing | Stable contract terms |
| Failure Domain | Single host outage | Cluster-wide durability |
Ad hoc fixes turn temporary workarounds into permanent technical debt. Fragmented environments lack centralized telemetry, preventing proactive identification of bottlenecks before they cause outages. Wwt.com/article/what-is- covering compute and storage remains unavailable in these setups, blinding operators to emerging constraints. Mission and Vision recommends decoupling storage immediately to avoid irreversible architectural lock-in.
Optimizing KV Cache and Data Pipelines Reduces Inference Latency
KV Cache as an Enterprise Data Management Problem
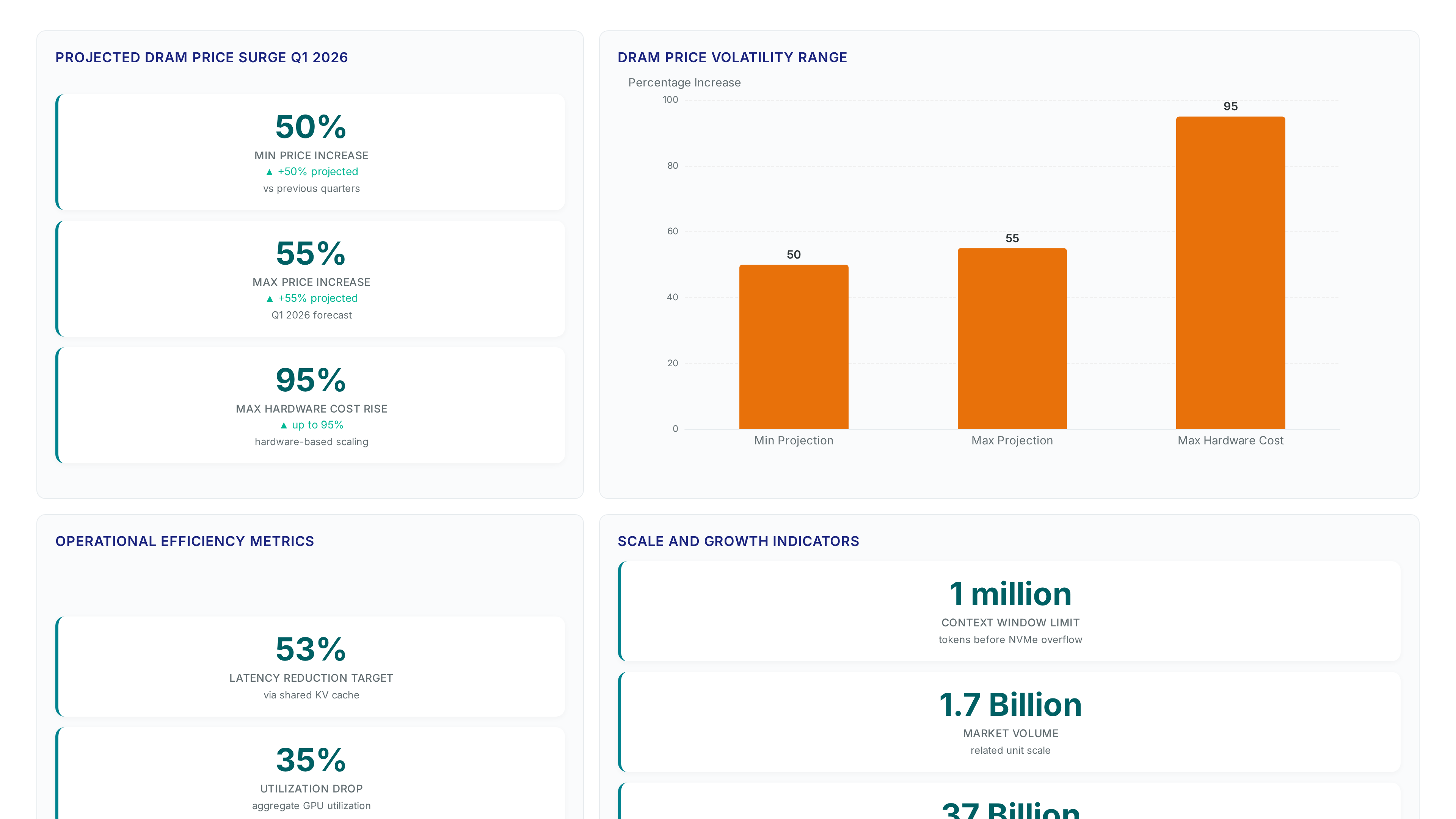
Treating KV cache as transient GPU memory fails when context windows exceed local NVMe capacity across distributed nodes. Recomputing attention matrices for every request wastes cycles, yet persisting and sharing these states transforms latency profiles for long-context workloads. The shift requires viewing cache not as a scratchpad but as a shared dataset requiring durable, concurrent access patterns similar to object storage systems. Memory market volatility further penalizes architectures dependent on expanding local DRAM pools for cache retention. Average DRAM prices were projected to rise 50% to 55% in Q1 2026, making hardware-based scaling prohibitively expensive compared to storage-tier offloading. Operators must decouple cache lifetime from GPU session duration to avoid paying premium rates for volatile memory that sits idle between requests.
| Constraint | Local GPU Memory | Shared Storage Tier |
|---|---|---|
| Scalability | Limited by host RAM | Elastic across cluster |
| Cost Basis | High per-GB DRAM rates | Lower object storage rates |
| Persistence | Lost on node failure | Durable across restarts |
Shared KV cache layers enable multiple inference engines to reuse computed context, drastically lowering aggregate GPU utilization. However, this introduces a coordination overhead where cache invalidation logic must match document update frequencies to prevent stale completions. The architectural tension lies between the speed of local access and the economic necessity of shared persistence. Ignoring this balance forces teams into reactive spending cycles as memory costs fluctuate unpredictably.
Aligning Storage Architectures with Enterprise AI Operations
Proven storage systems must serve multiple access methods without copying data to sustain inference throughput. Persistent KV cache management transforms latency profiles by avoiding expensive context recomputation across distributed nodes. Architectures relying on local NVMe fail to scale because state cannot migrate between GPU hosts during demand spikes. Shared object storage decouples data locality from compute, allowing clusters to access identical datasets concurrently. This alignment prevents teams from deploying fragile ad hoc solutions that fragment governance and inflate operational risk. Market volatility complicates infrastructure planning, as price adjustments on server orders now occur between quoting and shipment dates.
Failure to adopt shared architectures forces engineering teams to manually sync datasets, introducing latency penalties that negate accelerator throughput. The cost of ignoring this shift exceeds hardware expenses through wasted GPU cycles on redundant data preparation tasks.
Application: Operational Costs of Ad Hoc Solutions in AI Pipelines
Ad hoc storage patches fail to share KV cache states across nodes, forcing expensive context recomputation during inference spikes. Teams bypassing shared architectures face volatile hardware economics where flexible pricing clauses adjust server costs between quote and shipment. Local NVMe solutions cannot migrate state during demand surges, creating hard ceilings on throughput that software workarounds cannot fix. Operators attempting to fix high latency in AI inference often deploy fragmented caches that duplicate data across silos. This duplication inflates memory requirements precisely when memory costs are rising sharply due to supply constraints. The resulting architecture increases operational risk by scattering governance controls and preventing unified monitoring of data readiness.
| Failure Mode | Technical Consequence | Operational Impact |
|---|---|---|
| Local State Assumption | Context recomputation on every miss | Wasted GPU cycles |
| Manual Data Sync | Stale embeddings in cache | Degraded model accuracy |
| Fragmented Governance | Inconsistent access policies | Compliance violations |
How to optimize KV cache storage requires shifting from disposable scratchpads to persistent, shared datasets accessible via standard APIs. Relying on temporary local disks ignores the reality that inference workloads run continuously rather than in isolated batches. The NTT DATA agentic services model demonstrates how software-set infrastructure lowers these costs through centralized durability. Mission and Vision recommend decoupling storage from compute to eliminate the latency penalties inherent in tightly coupled designs.
Implementing Shared Object Storage for Enterprise AI Workloads
Defining Data Intelligence Nodes for Shared Object Access

Data intelligence nodes accelerate shared object access by caching metadata and intermediate artifacts closer to inference clusters than standard gateways allow.
- Deploy nodes to intercept vector-search retrieval requests before they traverse the wide-area network to central storage pools. This architecture prevents latency spikes when foundation models query tens of terabytes of enterprise records simultaneously. Standard gateways often bottleneck under concurrent load, whereas dedicated nodes maintain throughput by localizing hot data segments.
- Configure the node to persist KV cache states locally while referencing the canonical object store for version control. The HPE Alletra Storage MP X10000 platform illustrates this pattern by separating compute-intensive indexing from durable object persistence.
- Align procurement contracts with multi-year pricing volatility to prevent budget overruns during deployment scaling. Memory costs remain elevated through 2027, necessitating flexible terms that accommodate price adjustments between quoting and shipment dates. Ignoring these financial realities forces operators to overspecify local NVMe as a hedge against future expense.
Decoupling data readiness from raw compute power prevents fragile single-purpose silos. Most implementations fail because they treat storage as passive capacity rather than an active data fabric component. Investment becomes necessary when inference latency exceeds service-level agreements despite adequate GPU allocation.
Configuring HPE Alletra Storage MP X10000 for KV Cache Patterns
Operators must enable S3 API endpoints on the HPE Alletra Storage MP X10000 before binding inference clusters to shared buckets.
- Provision a dedicated bucket with lifecycle policies disabled to prevent accidental eviction of persistent KV cache objects during long-running inference sessions.
- Attach HPE's Data Fabric Software to the cluster to unify namespace access across geographically dispersed data intelligence nodes without copying underlying blocks.
- Tune the metadata server pool size to handle high-frequency small-object writes typical of context window updates in generative models.
- Enable telemetry streaming to HPE InfoSight for predictive adjustment of IOPS limits based on learned workload patterns.
Contract volatility introduces a hidden operational risk for scaling these configurations. HPE amended terms to allow price adjustments on orders between quoting and shipment due to rising memory costs. This policy shift forces operators to lock in capacity planning earlier than typical hardware refresh cycles allow. Aggressive cache sizing today risks budget overruns tomorrow if component markets remain unstable through 2027. Shared object access decouples state from compute, yet the cost model remains tied to physical DRAM availability. Teams ignoring this tension face scenarios where optimal technical configurations become fiscally unsustainable mid-deployment. Successful implementation requires balancing immediate latency gains against long-term procurement flexibility.
Validation Checklist for Scaling Inference Across Clusters
Verify shared object storage connectivity before enabling multi-node inference to prevent data duplication.
- Confirm all inference nodes mount the same namespace without local caching layers that fragment KV cache states.
- Validate that HPE's Data Fabric Software unifies access paths so teams avoid rebuilding pipelines for each project.
- Measure egress traffic between nodes; significant movement indicates failed adoption of foundation models accessing central pools.
- Ensure lifecycle policies disable automatic eviction for persistent RAG datasets ranging into tens of terabytes.
| Storage Mode | Data Duplication | Cluster Scalability | Cost Impact |
|---|---|---|---|
| Local NVMe | High | Limited | Volatile |
| Shared Object | None | Linear | Controlled |
Operators ignoring this validation face implementation bills exceeding a substantial sum during failed pilot phases. Fragmented architectures force expensive context recomputation when demand spikes shift workloads between hosts. Low-latency local access conflicts with the necessity of shared state for continuous operations. Teams choosing local speed sacrifice the ability to scale beyond single rack constraints. Mission and Vision recommends prioritizing namespace consistency over raw throughput metrics during initial deployment.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing disaster recovery strategies and managing persistent storage for high-traffic platforms uniquely qualifies him to analyze why storage systems have become the critical bottleneck in enterprise AI adoption. While early AI narratives prioritized compute power, Kumar's hands-on experience scaling infrastructure reveals that data readiness is now the limiting factor for production environments. At Rabata. Io, a provider of S3-compatible object storage tailored for AI startups, he directly addresses the challenges of vendor lock-in and egress fees that hinder scalable machine learning operations. This practical expertise allows him to articulate how modern, high-performance storage is no longer just a backend utility but a strategic asset necessary for unlocking the full potential of generative AI in the enterprise.
Conclusion
Scaling inference workloads reveals a critical breaking point where hardware price volatility dismantles static capacity plans. As component costs surge toward 95%, relying solely on physical expansion creates an operational debt that outpaces performance gains. The real bottleneck shifts from raw throughput to data mobility efficiency, where fragmented state management forces expensive recomputation cycles during demand spikes. Organizations clinging to local-only architectures will find their unit economics collapsing once cluster size exceeds single-rack boundaries, regardless of initial latency advantages.
Adopt a hybrid computing model by Q4 2026 if your AI spend exceeds a significant share of total IT budget. This transition is not merely architectural but fiscal, ensuring that namespace consistency dictates infrastructure choices rather than transient speed metrics. Delaying this shift locks teams into rigid procurement cycles that cannot absorb the projected market shocks of 2027. The window to negotiate flexible egress terms before widespread adoption drives up standard rates is closing rapidly.
Start by auditing inter-node egress traffic on your primary inference cluster this week to quantify hidden duplication costs. Identify any workflow where context reloads exceed 5% of total compute time and flag these for immediate shared-object migration. This specific metric reveals whether your current topology can survive the next scaling phase or requires fundamental re-architecture before capital commitments deepen.
Frequently Asked Questions
Naive cloud strategies cause massive costs due to unoptimized data movement taxes. Organizations relying on these inefficient methods without shared object access face monthly bills exceeding $1 million for their operations.
Early projects wrongly treated storage as disposable while prioritizing compute spending heavily. This approach allocated roughly 80 percent of resources to compute, leaving storage underfunded and unable to support enterprise data readiness needs.
Delays stem from identifying data across silos and enforcing security constraints manually. These preparation tasks create friction that stalls pipelines far more than algorithm selection or hyperparameter tuning issues ever do.
Shared object access reduces unnecessary copying by aligning with modern framework consumption patterns. This architecture prevents the severe financial penalties incurred when datasets grow to tens of terabytes for retrieval workloads.
Storage dictates data accessibility and trust, becoming the primary limiting factor for success. Without ready data, increased compute spending yields diminishing returns as pipelines stall waiting for usable information to process.
