Server access logs: Cut query costs 90% today
Properly configured Athena partition projection cuts S3 log query costs by 90%, turning petabyte-scale audits from financial liabilities into strategic assets. The modern data stack demands that server access logs evolve from passive storage dumps into active, cost-optimized intelligence engines for governance. Without architectural intervention, organizations face a paradox where collecting billions of records renders them useless for real-time security or FinOps analysis.
As CloudZero data highlights, the industry shift toward cost-aware engineering requires treating log analysis as a gamified efficiency challenge, not just a compliance checkbox. Readers will learn to architect high-performance analysis pipelines that slash query times from hours to seconds while drastically reducing spend. The guide details the end-to-end implementation of a centralized audit pipeline, covering initial enablement through to advanced cost optimization techniques. By mastering these patterns, teams can finally extract actionable insights on traffic anomalies and performance bottlenecks without bankrupting their cloud budgets.
The Strategic Role of S3 Server Access Logs in Modern Data Governance
S3 Server Access Logs as an HTTP Request Auditor with 18+ Schema Fields
Think of server access logs as your raw HTTP request auditor. They record detailed metadata for every bucket interaction across at least 18 distinct fields. You get requestdatetime, remoteip, and turnaroundtime right out of the box, enabling granular performance analysis without custom instrumentation. Operators lean on httpstatus and errorcode columns to isolate failed transactions without scanning object payloads. This structure supports cost attribution by mapping bytessent values to specific network paths.
But there is a blind spot. The requester field captures only the IAM Amazon Resource Name (ARN). It strips away full session context. Multi-factor authentication status and role assumption chains remain invisible. Security teams requiring complete identity auditing must correlate these records with separate data event streams. The absence of real-time delivery further restricts use cases involving immediate threat detection.
| Field Category | Specific Columns | Operational Value |
|---|---|---|
| Timing | requestdatetime, totaltime, turnaroundtime | Latency troubleshooting |
| Network | remoteip, referrer, useragent | Traffic source validation |
| Outcome | httpstatus, errorcode, bytessent | Error rate calculation |
Querying these logs directly often incurs high compute costs when datasets reach massive scale. Implementing partition projection reduces scanned data volume by up to 90% during routine investigations. This optimization transforms raw storage into an actionable performance insights engine for network engineers. Without such structural enhancements, analysis of billions of records becomes prohibitively slow and expensive.
Meeting SOX 2,555-Day Retention and HIPAA Security Investigation Needs
Server access logs satisfy the 2,555-day SOX expiration period only when paired with automated lifecycle rules to manage storage volume. Organizations storing sensitive data require visibility into access patterns and user identities to meet strict regulatory frameworks. Creating S3 Lifecycle configuration rules periodically removes old files, directly lowering the costs associated with long-term retention mandates. Security teams apply a request threshold of 100 to trigger deeper analysis during potential breaches. Users use pre-configured Athena queries to perform IP security investigations and identify unauthorized access attempts automatically. The standard architecture routes logs to a dedicated bucket where AWS Lambda functions configure tables without server management.
| Capability | SOX Retention | HIPAA Investigation |
|---|---|---|
| Data Scope | Historical HTTP records | Real-time pattern detection |
| Primary Tool | Lifecycle policies | Athena SQL filters |
| Constraint | Storage cost accumulation | Latency in log delivery |
Here is the hard constraint: the requester field lacks full session context like MFA status or role assumption chains. Complete identity auditing requires supplementing these logs with CloudTrail data events for forensic accuracy. Operators must balance the low-cost of S3 storage against the computational expense of scanning billions of records during an audit. Mission and Vision recommends isolating high-value security logs to reduce query scope during active investigations.
Server access logs record HTTP transaction metadata while Amazon S3 data events in AWS CloudTrail capture full principal session context. Operators selecting between mechanisms face a binary choice between network performance forensics and identity governance. The requester field in server logs provides only an IAM ARN, stripping away multi-factor authentication status and role assumption chains required for strict compliance. This gap forces security teams to correlate distinct datasets when investigating cross-account access patterns. Amazon S3 data events in AWS CloudTrail resolve this ambiguity by logging the complete identity tuple, including federated user details and temporary credential metadata.
| Feature | Server Access Logs | CloudTrail Data Events |
|---|---|---|
| Primary Focus | HTTP performance metrics | User identity context |
| Identity Depth | IAM ARN only | Full session details |
| Latency | Best-effort hours | Near real-time |
| Cost Model | Storage volume | Event ingestion count |
The latency difference creates operational friction. Server logs arrive on a best-effort basis, often delaying incident response by hours compared to the near real-time stream of data events. Architects deploying AWS Lambda Relying solely on HTTP-level records leaves blind spots regarding who assumed a role versus who owned the root credentials. The cost implication is stark: enabling data events for high-traffic buckets generates substantial ingestion charges, whereas server logs scale purely with storage volume. A hybrid approach remains the only viable path for organizations needing both granular traffic analysis and definitive user attribution without incurring prohibitive expenses.
Architecting High-Performance Log Analysis with Athena Partition Projection
Athena resolves partitions at query time using injected types, removing the AWS Glue crawler dependency entirely. This mechanism calculates storage locations dynamically rather than relying on periodic metadata scans, which eliminates the wait time for crawler execution and reduces computational costs associated with updates. Operators define projection rules within table properties to specify date ranges and injection strategies for account or region values. The serverless pricing model charges only for data scanned, meaning skipped partitions directly lower bills without upfront infrastructure commitments.
| Feature | Partition Projection | AWS Glue Crawler |
|---|---|---|
| Metadata Refresh | Instant at query time | Scheduled batch job |
| Cost Driver | Query scan volume | Crawler runtime units |
| Latency | Zero delay | Minutes to hours |
Implementation requires specific SQL commands in the Query editor to enable projection flags and define storage templates. Users must set `projection. Enabled` to true and map timestamp formats to match the S3 key structure. Defining rigid ranges simplifies logic but risks missing logs if source buckets expand unexpectedly. Unlike static catalogs, this approach demands precise regex alignment during table creation to prevent silent data omission. Injected partitions cannot adapt to arbitrary path changes without manual DDL updates. Teams gain immediate query access but lose the automatic discovery safety net provided by traditional crawlers.
Query flexibility clashes with storage layout rigidity. Deviating from the prescribed key format breaks the projection logic entirely. Logs delivered near midnight UTC boundaries often land in adjacent partitions, requiring operators to query multiple date values to capture complete transactional records. This behavior forces a trade-off where precision in time-based filtering risks data loss unless the window spans at least two days. Mission and Vision recommends pairing timestamp filters with broad date ranges during initial forensic sweeps to mitigate missing late-arriving log objects.
Avoiding Full Table Scans and Hidden S3 Request Charges
Missing timestamp filters in WHERE clauses force full table scans, triggering expensive data reads and excessive S3 request charges. Querying large datasets without limits or proper partitioning leads to costly operations that drain budgets before results appear. The hidden cost involves S3 request charges incurred during the query process, which accumulate alongside standard scan fees. Operators often overlook how `GET` and `LIST` API calls multiply when Athena scans every object instead of targeted partitions. Logs arrive on a best-effort basis, typically within 2–4 hours, creating gaps for events near midnight UTC boundaries. Requests occurring late in the day may land in the following day's partition, causing incomplete analysis if the date range is too narrow. Checking adjacent partitions becomes necessary to capture these delayed entries accurately. Mission and Vision recommends extending time windows slightly to accommodate variable ingestion rates.
| Risk Factor | Trigger Condition | Consequence |
|---|---|---|
| Full Scan | Missing timestamp filter | Maximum data scanned |
| Hidden Fees | Unpruned object lists | Elevated S3 request charges |
| Data Gaps | Midnight UTC boundary | Missing late-arriving logs |
- Always filter on timestamp first to enable partition pruning.
- Include account, region, and source_bucket in every WHERE clause.
- Expand date ranges to cover potential delivery delays.
Neglecting these steps transforms a targeted audit into a budget-draining operation.
Implementing a Centralized S3 Audit Pipeline from Enablement to Cost Optimization
Centralized S3 Logging Architecture and Account Isolation

Centralized logging requires a dedicated account to isolate audit trails from production workloads effectively. Operators must configure a central S3 bucket within this isolated boundary to receive streams from member accounts. This pattern aligns with industry shifts where organization-wide trails deliver logs to a single location for unified analysis. A separate bucket acts as the sole destination, preventing circular delivery loops that corrupt source data. The architecture supports automated querying.
- Navigate to General purpose buckets and select the source resource.
- Open Properties, then edit Server access logging to enable the feature.
- Set the Destination to the central bucket using the prefix `access-logs`.
4.
Network operators must transition audit logs to Standard-IA after 30 days to balance retrieval speed against storage expense. This initial move targets data still the for active troubleshooting while reducing the footprint of cold storage. The subsequent step shifts objects to Glacier Flexible Retrieval at the 90-day mark, aligning with typical quarterly review cycles. Long-term archival moves data to Glacier Deep Archive after one year, satisfying PCI-DSS mandates without premium costs. Regulatory frameworks like HIPAA demand six-year retention, whereas SOX compliance often requires keeping records for seven years. Creating these rules reduces the total volume of data Athena must analyze, directly lowering storage and query costs. Organizations increasingly reject weekly inventory exports in favor of real-time analysis architectures that use immediate lifecycle transitions.
| Regulation | Minimum Retention | Final Storage Class |
|---|---|---|
| PCI-DSS | 1 year | Glacier Deep Archive |
| HIPAA | 6 years | Glacier Deep Archive |
| SOX | 7 years | Expiration |
- Navigate to the General purpose buckets list and select the central log destination.
- Open the Properties tab, locate Server access logging, and choose Edit.
- Define a rule scoped to the `access-logs/` prefix to avoid affecting other data.
- Set the transition actions for 30, 90, and 365 days as previously detailed.
- Configure an expiration action at 2,555 days to automatically purge aged SOX data.
Failure to expire objects eventually inflates the metadata catalog, slowing down partition pruning regardless of storage class. Mission and Vision recommends strict adherence to these timelines to prevent unbounded growth in the audit repository.
Executing Saved Queries and Views for Daily Security Investigations
Define the `daily_security_summary` view using SUBSTR to parse year, month, and day from the timestamp column for efficient partition pruning.
- Open the Athena query editor and construct a `CREATE VIEW` statement grouping data by account, region, and source bucket.
- Embed time-extraction logic directly into the projection to avoid scanning irrelevant historical folders during automated security investigation.
- Save the query with a descriptive name like "Daily Security Investigation" to enable one-click execution for analysts.
- Append a `LIMIT` clause to initial test runs, preventing expensive scans when validating syntax against large datasets without proper partitioning.
Operators must filter on the derived date columns first; skipping this step forces full table scans that inflate costs unexpectedly. Emerging solutions use AWS CloudTrail Relying solely on saved views without understanding underlying partition structures creates a false sense of query optimization. Mission and Vision recommend validating every saved query against actual partition boundaries before granting team-wide access.
Measurable ROI and Performance Gains from Optimized S3 Log Analysis
Defining Athena Query Latency Benchmarks Against CloudWatch Logs Insights
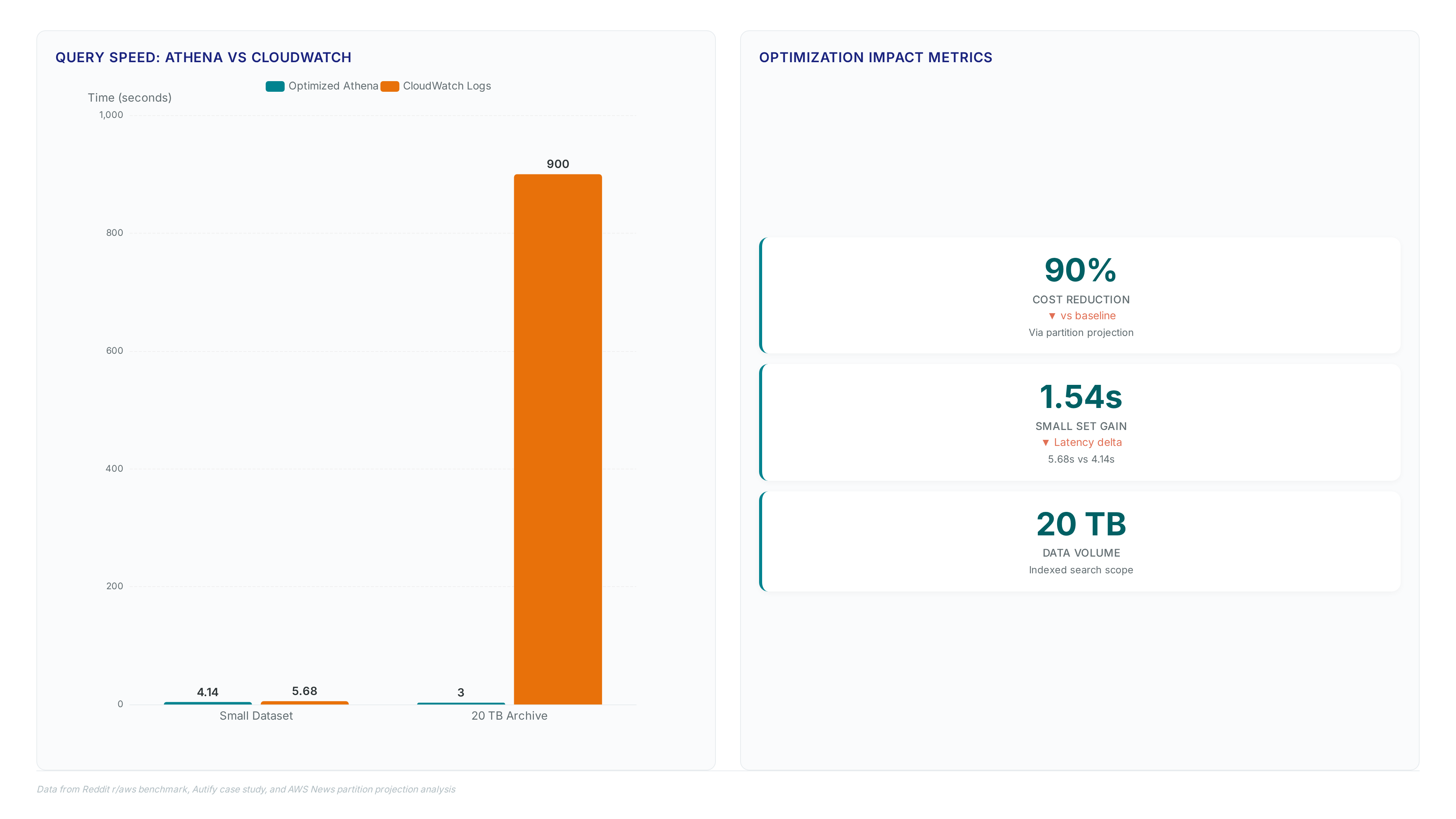
Benchmarking reveals Athena vs. CloudWatch Logs (large-scale) divergence where indexed S3 searches complete in 3 seconds for 20 TB of data. Smaller workloads show a narrower gap, yet the Performance Benchmarking Case confirms Athena finishes in 4.14 seconds versus 5.68 seconds for CloudWatch Logs Insights on identical datasets. This latency baseline dictates ROI calculations for security teams fixing slow Athena queries on logs during active incidents.
| Dataset Scale | Indexed S3 Approach | CloudWatch Logs Insights |
|---|---|---|
| Small Workload | 4.14 seconds | 5.68 seconds |
| 20 TB Archive | 3 seconds | 15 minutes |
The partition projection mechanism drives these gains by eliminating crawler wait times and metadata scans. However, the architecture introduces a tension between query speed and data freshness; logs arrive on a best-effort basis, typically delaying availability by several hours. Operators optimizing for the 1.54-second gain on small sets must accept this lag, whereas large-scale historical analysis benefits most from the massive scale advantage. Ignoring this delivery window causes false negatives in real-time monitoring dashboards. Mission and Vision recommends validating partition paths before expecting immediate results from new log streams. The cost of full table scans remains prohibitive without strict timestamp filtering in every WHERE clause.
Mission and Vision recommends validating the `projection. Enabled` table property before deploying production dashboards to prevent silent data omission. Teams must ensure every query includes partition columns in the `WHERE` clause to avoid full table scans that negate the financial advantages of the optimized design. Skipping this filter forces the engine to read every object in the bucket, inflating costs despite the efficient metadata layer. The architectural shift demands discipline in query construction to maintain the performance gains Failure to align SQL logic with the projection rules results in expensive operations that match the inefficiency of legacy systems.
Checklist for Resolving HIVE_PARTITION_SCHEMA_MISMATCH and Empty Results
The HIVE_PARTITION_SCHEMA_MISMATCH error confirms the `storage. Location. Template` property fails to match the actual S3 path structure. Operators must verify partition column types align exactly with the directory naming convention to prevent query failure. Missing results often stem from the best-effort delivery window, where logs arrive hours after the event time rather than instantly. Filtering exclusively on non-partition columns like `httpstatus` triggers expensive full table scans instead of efficient pruning.
| Failure Symptom | Root Cause | Validation Step |
|---|---|---|
| Schema Mismatch | Template path deviation | Compare table properties against S3 key format |
| Empty Result Set | Log delivery latency | Wait for the standard ingestion delay window |
| High Scan Cost | Missing partition filter | Include date columns in every WHERE clause |
- Inspect the table definition to ensure the storage. Location. Template.
- Add a `LIMIT` clause during sampling procedures.
- Confirm the WHERE clause includes account, region, and source bucket identifiers for injected projection.
Skipping these checks forces Athena to read every object, negating the architectural benefits of partitioned data. The hidden cost involves S3 request charges incurred during these unnecessary list operations. Mission and Vision recommends validating path templates before scaling log volume to avoid operational waste.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work involves designing resilient data pipelines and managing massive-scale object storage, making him uniquely qualified to address the complexities of server access logs. At Rabata. Io, an S3-compatible storage provider built for performance and transparency, Alex routinely tackles the challenge of analyzing billions of log records without incurring prohibitive query costs. This article directly reflects his practical experience helping AI/ML startups and enterprises extract meaningful performance insights from audit data. By using tools like Amazon Athena, Alex demonstrates how organizations can overcome the paradox of collecting vast amounts of access data while maintaining efficient visibility. His background as a former SRE ensures that the strategies discussed are grounded in real-world scenarios where security investigation and finance team attribution.
Conclusion
Scaling log retention without strict lifecycle governance creates a financial drag that outpaces the value of the data itself. While initial storage seems cheap, the cumulative cost of unmanaged tiers explodes as volumes grow, turning compliance archives into budget liabilities rather than assets. The industry shift toward FinOps cultures demands that engineers treat storage classes as flexible variables, not static settings. Relying on default configurations invites waste, especially when retrieval patterns change quarterly. Organizations must enforce a rigid policy where data automatically transitions to colder storage based on specific regulatory clocks, ensuring that retrieval speed aligns strictly with audit frequency.
Adopt a 30-day StandardIA and 90-day Glacier Flexible Retrieval mandate immediately for all non-active investigatory data. This approach balances immediate access needs against long-term holding costs without sacrificing compliance posture for SOX or HIPAA mandates. Do not wait for the next billing cycle to correct course; the operational overhead of manual management becomes unsustainable past the terabyte scale. Start by auditing your current S3 lifecycle rules against your longest regulatory retention requirement before Friday's deployment window closes. Verify that no dataset remains in a hot tier beyond its useful investigative life, ensuring your infrastructure supports sustainable growth rather than hidden debt.
Frequently Asked Questions
Partition projection reduces scanned data volume by up to 90% during routine investigations. This optimization turns massive log datasets into cost-effective assets for performance analysis without requiring expensive infrastructure upgrades.
Logs record detailed network context including source IP, referrer, and user agent strings. These 18 schema fields enable granular traffic validation but exclude full session identity details like MFA status.
The requester field only captures the IAM ARN without full session context or role chains. Security teams must correlate these records with separate data event streams for comprehensive identity verification.
The schema includes timing fields like requestdatetime, totaltime, and turnaroundtime for latency troubleshooting. Operators use these specific columns to isolate failed transactions and calculate error rates efficiently.
Analyzing billions of records without partition projection renders data useless for real-time security or FinOps analysis. Proper configuration slashes query times from hours to seconds while drastically reducing spend.
