Vector workloads need unified S3 storage now
Amazon S3 holds a vast number of objects globally, acting as the backbone of modern data infrastructure. Proven AI deployment now depends on mastering native vector storage and automated table management within this ecosystem. S3 Vectors eliminate external embedding databases, while architectural shifts enable Intelligent-Tiering for S3 Tables. Practical DataSync strategies now provide ransomware durability without complex add-ons.
Global data creation explodes toward 240 zettabytes in 2026, driven largely by unstructured AI workloads. Most organizations still rely on fragmented, legacy storage patterns. Amazon Web Services addressed this at re:Invent 2025 by integrating vector search directly into object storage. Customers like Indeed migrated massive analytics infrastructures without performance penalties. Bolting on separate vector databases is ending; the data foundation must be unified from the start.
This analysis cuts through the marketing noise surrounding the 20th anniversary of S3 to focus on tangible architectural changes. We examine the 35 breakout sessions from Las Vegas to isolate specific patterns for Generative AI and Agentic Workloads. By using S3 Tables with new Replication features, architects achieve the durability and low-latency access required for next-generation applications without inflating costs.
The Role of S3 Vectors and Tables in Modern AI Data Foundations
A unified multi-modal data layer separates compute resources from storage systems for AI tasks. S3 Vectors removes the need for isolated database systems by placing approximate nearest neighbor search directly inside object storage. This design cuts total cost of ownership by up to 90% when compared to dedicated engines like Pinecone. Embeddings exist as native objects instead of external indices. Data movement bottlenecks vanish during Retrieval Augmented Generation scaling. S3 Tables builds on this base with fully managed Apache Iceberg support. Query throughput reaches speeds up to 3x faster than self-managed table setups. Automated compaction and intelligent tiering handle maintenance jobs that usually eat up engineering hours in traditional lakehouse deployments. Integration produces a single source of truth. Vector similarity search and SQL analytics run on identical underlying data without duplication.
| Feature | S3 Vectors | S3 Tables |
|---|---|---|
| Primary Interface | Approximate Nearest Neighbor | SQL / Apache Iceberg |
| Optimization Target | Embedding Retrieval | Analytical Query Throughput |
| Management Overhead | None (Serverless) | Automated Compaction |
Elastic scaling becomes available to operators while fine-grained index tuning found in purpose-built vector databases disappears. The Storage-First method chooses cost efficiency and simplicity over maximum query latency optimization. Large-scale RAG pipelines benefit when budget limits matter more than microsecond response needs. This constraint shapes the modern data foundation for agentic workloads running on Amazon Bedrock. S3 Vectors acts as a native approximate nearest neighbor engine embedded right inside object storage for RAG pipelines. Teams deploy this layer to feed Amazon Bedrock and Agents for Bedrock without pulling embeddings into separate database silos. The service now handles 2 billion vectors per index.
S3 Vectors Economics Versus Specialized Vector Databases
S3 Vectors uses a Storage-First architecture that decouples compute from storage to eliminate specialized database silos. This model shifts economic pressure from high-cost memory residency to low-cost object persistence. Total Cost of Ownership calculations change fundamentally for large-scale retrieval. Operators face strategic tension between latency sensitivity and storage volume when selecting infrastructure.
| Feature | Specialized Databases | S3 Vectors |
|---|---|---|
| Primary Cost Driver | Memory-resident compute | Object storage capacity |
| Scaling Unit | Managed node clusters | Logical index containers |
| Data Locality | External synchronization required | Native object embedding |
Dedicated engines like Pinecone optimize for sub-millisecond response times but incur steep premiums as dataset size expands. A hybrid approach mirrors established data lake strategies by reserving specialized hardware for performance-critical queries while offloading bulk storage. Analysts observe that enterprises increasingly adopt this split to balance operational expenditure against query throughput requirements. Raw lookup speed in pure object storage remains lower than in-memory indices. Consolidation reduces architectural fragility inherent in multi-system data movement. Economic advantage of native storage integration becomes decisive for workloads where ingestion volume outweighs real-time update frequency. Accepting slightly higher latency delivers massive scale reductions in infrastructure complexity.
Inside AWS Storage Architecture for Durability and Secure Access
Eleven Nines Durability via Multi-AZ Erasure Coding
Session STG407 details how erasure coding across multiple Availability Zones delivers eleven nines of durability for stored objects. The mechanism shards data into fragments, distributing them so loss of an entire zone triggers reconstruction rather than failure. This routing logic ensures strong consistency even during concurrent write operations spanning distinct physical locations. Operators manage this scale as the platform hosts 50 TB globally without manual sharding intervention. Recent architecture updates increased the S3 maximum object size to 50 TB.
| Attribute | Traditional Replication | Multi-AZ Erasure Coding |
|---|---|---|
| Storage Overhead | Substantial overhead (3x copies) | Minimal overhead (1.33x fragments) |
| Rebuild Time | Hours per volume | Minutes per shard |
| Failure Domain | Single disk or rack | Entire Availability Zone |
Computational latency during fragment reassembly adds milliseconds to read paths compared to local disk access. High-frequency trading systems sensitive to microsecond jitter may find this constraint unacceptable for hot data tiers. Network partitions between zones can temporarily block writes until quorum is re-established, creating a specific availability window risk. Validate routing policies against simulated zone failures before migrating stateful workloads. Bandwidth provisioning between zones must account for background reconstruction traffic spikes.
Operators configure S3 Lifecycle rules to transition infrequent access data to S3 Glacier tiers, achieving up to 95% cost reduction. This mechanism automates movement based on object age, shifting cold data from standard storage to Deep Archive without application changes. The process requires precise alignment with RPO and RTO.
| Storage Class | Retrieval Time | Cost Profile |
|---|---|---|
| S3 Standard | Milliseconds | High |
| S3 Glacier Instant | Milliseconds | Low |
| S3 Glacier Deep Archive | 12+ Hours | Lowest |
Accessing Deep Archive data incurs retrieval latency incompatible with real-time analytics, forcing a choice between savings and availability. Session STG208 details how Intelligent-Tiering mitigates this by monitoring access patterns, yet manual policies remain necessary for compliance-driven retention. Operators must define explicit transition actions to avoid keeping hot data in expensive tiers or locking critical assets in slow retrieval classes.
- Define object age thresholds for transition.
- Select target storage class based on access frequency.
- Configure expiration rules for obsolete data.
- Validate rules against disaster recovery requirements.
Failure to tune these parameters results in either excessive spend or operational friction during restore operations. Rigid time-based triggers cannot predict sudden access spikes without supplemental monitoring tools. Audit lifecycle configurations quarterly to match evolving workload patterns.
Checklist for Private S3 Access via VPC Endpoints
Session STG220 mandates VPC endpoints and S3 Access Points to route browser traffic privately, bypassing the public internet entirely.
- Attach a gateway endpoint to the route table, ensuring the next hop directs S3 prefixes locally.
- Create an Access Point with a policy restricting access to the specific VPC ID.
- Update bucket policies to deny all requests lacking the `aws:SourceVpce` condition key.
- Validate connectivity by attempting access from an EC2 instance without a public IP.
This architecture supports smooth integration for analytics workloads, allowing file system data exposure through S3-compatible interfaces. Operators often overlook that fine-grained access controls within the lakehouse model depend on these private pathways to prevent data exfiltration during AI training.
| Configuration | Public Internet | VPC Endpoint |
|---|---|---|
| Traffic Path | Uncontrolled | Private Fabric |
| Exposure Risk | High | Zero |
| Latency | Variable | Consistent |
Strict dependency on correct IAM resource policies creates a potential failure point; a missing condition block instantly breaks legitimate internal applications. Audit FlowLogs weekly to verify encryption fields for compliance.
Executing Data Migration and Ransomware Protection with DataSync
AWS DataSync Task Configuration and Integrity Verification Protocols

Session STG340 defines agent deployment and task parameters for secure transfers across NFS, SMB, HDFS, and object storage protocols. Operators configure bandwidth throttling limits to prevent saturation of production links during active migration windows. The system validates data integrity by comparing checksums at the source and destination after every file move completes. This verification step guarantees bit-for-bit accuracy regardless of the underlying network conditions or storage backend latency. Hybrid cloud architectures require smooth NAS migration. Task definitions specify filter rules to exclude temporary files, reducing unnecessary compute cycles and transfer duration.
- Deploy the DataSync agent on a hypervisor with direct access to the source file system.
- Define the source location using the specific protocol endpoint and authentication credentials.
- Select the destination as an S3 bucket, EFS file system, or FSx volume.
- Enable encryption in transit and configure task scheduling for off-peak execution.
Rigorous verification introduces measurable latency. Skipping this step risks silent corruption in AI training datasets. Large-scale transfers benefit from the increased 50 TB limit. Validate checksum algorithms against source hardware capabilities before initiating full-scale migration campaigns.
Implementing Ransomware Protection via S3 Object Lock and AWS Backup Policies
Session STG338 mandates enabling S3 Object Lock in governance mode to prevent deletion during the set retention window. Operators must activate versioning before applying retention rules, ensuring every overwrite creates a new immutable copy rather than destroying evidence. This configuration blocks ransomware encryption attempts that rely on modifying or deleting existing objects. The 50 TB limit applies here as well. AWS Backup policies orchestrate recovery point objectives by copying locked data to isolated accounts. Over 140,000 customers apply this central management plane to enforce consistent retention schedules across mixed storage environments. Administrators define lifecycle rules that transition older versions to cold storage tiers while maintaining immutable status for compliance.
- Create a backup vault with immutable retention settings locked for a minimum duration.
- Assign an IAM role granting `backup:StartCopyJob` permissions to the source bucket.
- Configure a daily recovery window that triggers cross-region replication tasks automatically.
- Test restoration procedures quarterly using isolated staging environments to verify RTO metrics.
Maintaining immutability includes storage overhead for multiple versions. This expense pales against total data loss scenarios. Healthcare sectors specifically use these replication features for AI agents requiring secure semantic search of content stores. Limiting access through VPC encryption controls helps. Recovery architectures fail when replication lag exceeds the set RPO, leaving a gap where recent changes remain unprotected. Align retention periods with legal hold requirements to avoid premature expiration of critical backups.
Checklist for Deploying AWS Transfer Family with Active Directory Federation
STG419 mandates federating custom identity providers with Active Directory before enabling multi-protocol listeners for SFTP, FTPS, FTP, or AS2.
- Configure the identity provider to map directory groups to specific IAM roles for least-privilege access.
- Enable AS2 support to replace legacy MFT platforms from vendors like IBM without losing audit logging capabilities.
- Attach EventBridge rules to trigger Lambda functions upon successful file arrival for downstream processing.
- Validate that bandwidth throttling prevents saturation of production links during initial synchronization windows.
| Protocol | Use Case | Security Requirement |
|---|---|---|
| SFTP | General file exchange | SSH Key Authentication |
| AS2 | EDI Trading Partners | MDN Receipt Confirmation |
| FTPS | Legacy Application Lift | TLS 1.2 Encryption |
Enabling multiple protocols on a single server increases the attack surface unless each listener has distinct security group rules. Session STG339 details how event-driven architectures reduce operational overhead by decoupling transfer completion from application logic. Failure to configure precise IAM conditions on the identity provider allows unauthorized lateral movement between directories. Test failover scenarios where the primary directory controller becomes unreachable to verify cached credential validity.
Strategic Trade-offs Between S3 and FSx for Database Workloads
Architectural Divergence: S3 Object Storage vs FSx File Systems
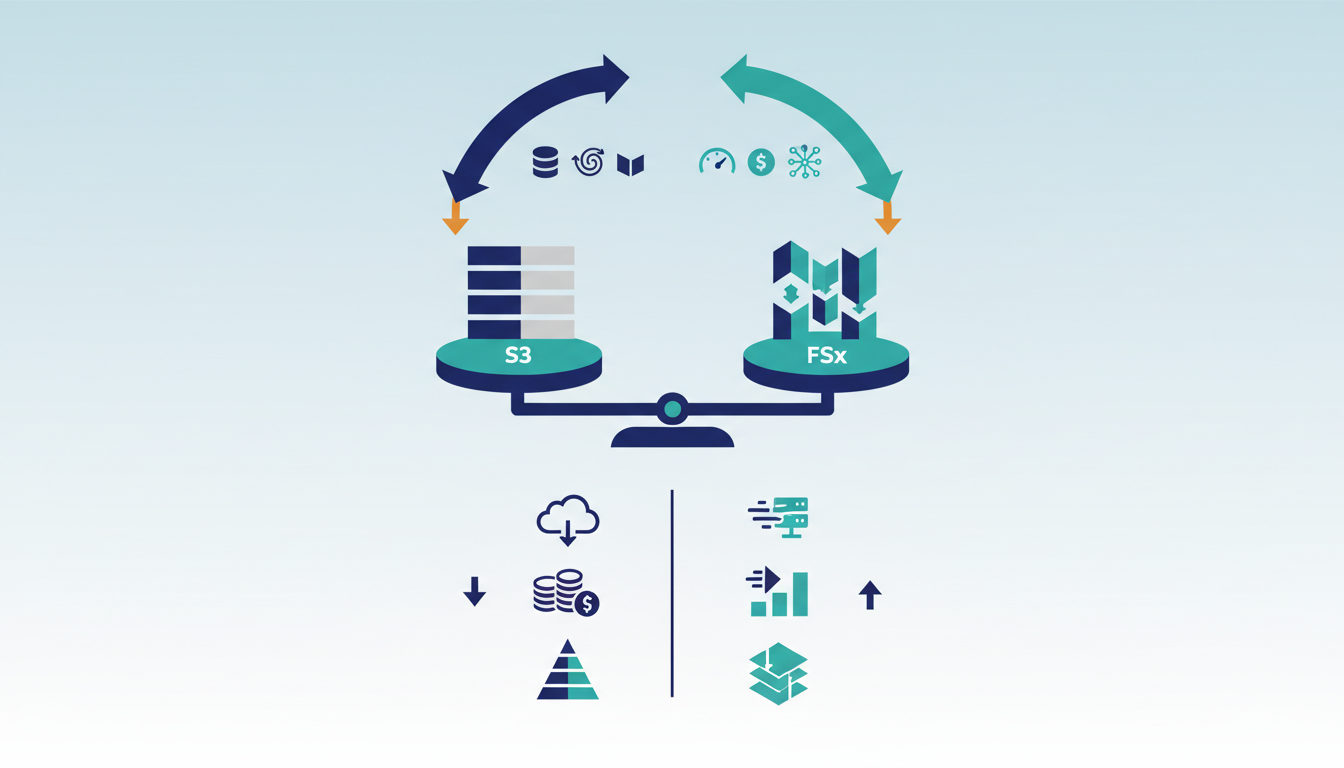
S3 routes requests via a flat namespace while FSx enforces hierarchical directory structures for POSIX compliance. This fundamental split dictates database compatibility more than raw throughput metrics ever could. S3 eliminates sharding for massive datasets by supporting objects up to 50 TB, whereas FSx requires traditional file splitting to maintain inode efficiency within its tree.
| Feature | Amazon S3 | Amazon FSx |
|---|---|---|
| Namespace | Flat with prefixes | Hierarchical directories |
| Consistency Model | Strong global consistency | Localized file locking |
| Max Object Size | 50 TB | File system volume limits |
| Best Fit | Data lakes, AI training | Oracle, SQL Server backends |
Session STG407 details how S3 achieves eleven nines of durability through distributed routing logic that bypasses traditional file locks entirely. Operators attempting to mount S3 as a drive for transactional databases often encounter high latency because the object store lacks native file append capabilities. Conversely, FSx for NetApp ONTAP provides the low-latency IOPS required by legacy ERP systems but incurs higher costs for petabyte-scale archives.
Choosing the wrong layer creates unfixable performance bottlenecks that no amount of caching can resolve. Architects must align the access pattern with the storage primitive before provisioning begins. The architectural divergence creates a hard boundary for database planners. While S3 Vectors offers a Storage-First architecture decoupling compute from storage for AI embeddings, relational engines stall without direct file system mounts. Attempting to run transactional logs on S3 introduces unacceptable write amplification during commit phases. Some organizations adopt a hybrid approach. This split prevents the latency penalties associated with emulating file systems over object APIs. The cost of misalignment manifests as query timeouts rather than storage exhaustion. Audit application I/O patterns before selecting the storage backend to avoid costly re-architecture later.
Performance and Cost Trade-offs: S3 Tables Query Speed vs FSx Latency
Indeed migrated to Amazon S3 Tables to reduce operational overhead while accepting higher query latency than FSx provides for transactional workloads. Object storage delivers throughput scaling that file systems cannot match, yet single-digit millisecond response times remain exclusive to block and file protocols. Operators analyzing billions of prefixes gain visibility through S3 Storage Lens exports directly into table formats, enabling cost optimization without moving data. The limitation is absolute: S3 cannot satisfy sub-millisecond locking requirements for high-frequency trading or active Oracle RAC clusters.
This strategy mirrors existing data lake deployments where performance-critical queries bypass object stores entirely. Session STG210 confirms that Indeed achieved significant query speed improvements over self-managed Iceberg implementations, though absolute latency exceeds FSx capabilities. The cost benefit drives adoption for batch processing, but real-time applications still demand file system semantics.
Architecture teams must reject the notion that one service replaces the other. S3 Tables excel at scanning petabytes for pattern recognition, whereas FSx sustains the rigid consistency needed for database journals. Attempting to force analytical workloads onto FSx inflates costs unnecessarily, while pushing transactional loads to S3 introduces unacceptable failure risks. The decision matrix relies strictly on latency tolerance rather than raw capacity. Map workload SLAs before selecting storage tiers to avoid costly refactoring later.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing disaster recovery strategies and managing scalable persistent storage makes him uniquely qualified to analyze the latest Amazon S3 innovations announced at re:Invent 2025. As Rabata. Io builds the fastest S3-compatible alternative to AWS, Alex directly evaluates how new features like S3 Vectors and Intelligent-Tiering impact enterprise AI/ML workloads and data portability. His experience migrating high-traffic systems allows him to critically assess vendor lock-in risks versus the benefits of true API compatibility. By connecting AWS's evolving system to Rabata. Io's mission of democratizing object storage, Alex provides actionable insights for organizations seeking high-performance, transparent pricing without sacrificing the reliable capabilities set by the S3 standard.
Conclusion
Scaling unstructured data to the forecasted 240 zettabytes by 2027 exposes a critical fracture in static storage architectures: rebuild times for erasure-coded fragments become the primary bottleneck, not raw capacity. As AI datasets swell beyond 50 TB thresholds, the operational tax of managing massive storage overhead for hot tiers renders traditional replication strategies financially unsustainable. Organizations must shift from viewing S3 as a passive dump to treating it as an active compute boundary where data placement dictates query economics. Relying on generic tiering rules without specific latency SLAs will inevitably inflate egress costs and stall model training pipelines.
Adopt a strict latency-first segmentation policy by Q2 2026: mandate S3 Tables exclusively for workloads tolerant of second-level retrieval, while reserving provisioned file systems for sub-millisecond transactional locks. Do not attempt to bridge these domains with complex caching layers that obscure failure modes. Start by auditing your top ten largest prefixes this week to identify any transactional metadata currently sitting in object storage; migrate these specific paths to a file protocol immediately to prevent consistency errors during peak load. This targeted isolation ensures your infrastructure scales with data volume rather than collapsing under rebuild latency.
Frequently Asked Questions
S3 Vectors reduces total cost of ownership by up to 90% versus dedicated engines. This storage-first architecture eliminates expensive memory residency by placing embeddings directly into native object storage containers.
The service now handles up to 2 billion vectors per individual index container. This massive scale allows enterprises to fit huge knowledge bases inside single logical units for agentic workloads.
Real-world validation shows semantic search serving over 27 million users through metadata-aware querying. This proves the platform handles high-volume consumer applications without requiring separate database silos for embeddings.
Ingestion metrics recorded 40 billion vectors entering the system across a five-month period. This throughput demonstrates suitability for large-scale agentic training loops and massive enterprise knowledge base updates.
Query throughput reaches speeds up to 3x faster than self-managed table setups. Automated compaction and intelligent tiering handle maintenance jobs that usually consume significant engineering hours in traditional deployments.
