Neocloud storage: Cut costs by 70% on AI clusters
Backblaze manages over five exabytes of data while delivering throughput speeds up to 1Tbps with its new B2 Neo platform.
Neocloud providers face a binary choice: build proprietary storage backends or integrate specialized layers. The math favors integration. ABI Research forecasts that inference workloads will comprise 80% of the neocloud sector by 2030. Hoarding infrastructure for a commodity layer makes no sense when the market demands specialized compute. B2 Neo addresses this with a write-through cache design. It captures flash performance without hitting the scalability ceiling of all-flash architectures at multi-petabyte scales.
Integrated object storage removes the latency bottlenecks stalling GPU utilization during AI training and real-time inference. Outsourcing via branded endpoints beats in-house builds. Platforms can provision accounts and manage billing inside existing tools instead of maintaining separate consoles. Leveraging 20 years of accumulated storage expertise lets neoclouds launch full-stack offerings in weeks. This preserves capital for the GPU infrastructure that actually defines their competitive edge.
The Role of Integrated Object Storage in Modern Neocloud Architecture
B2 Neo: Purpose-Built Object Storage for Neocloud Platforms
Backblaze launched B2 Neo on February 23, 2026. It serves as a dedicated object storage layer for neocloud providers. This architecture removes the capital expenditure needed to build proprietary backends. It leverages nearly 20 years of operational history managing over five exabytes of data. The system functions as a native tier. Platforms provision accounts and control billing without separate consoles.
Adoption hits a specific market inflection point. The neocloud sector is projected to expand from $35.22 billion in 2026 to $236.53 billion. A global edge services platform now uses this infrastructure as a core component of its AI and HPC strategies following a rigorous evaluation. The integration captures throughput speeds up to 1Tbps via a write-through cache design with strategically deployed flash layers.
Ceding direct hardware control grants immediate scalability. Neoclouds avoid the engineering drain of maintaining storage fleets. They must, however, rely on external service level agreements for durability guarantees. This dependency shifts the failure domain from local disk arrays to network egress points. Operators need careful bandwidth provisioning to prevent GPU starvation during checkpoint writes. Speed to market comes with a caveat: inheriting a single point of potential congestion outside the physical perimeter.
Solving AI Storage Bottlenecks in All-Flash Neocloud Deployments
Integrated object storage converts a rising 30% line item into a manageable operational expense for all-flash AI clusters. External storage tiers force data egress during training cycles. This stalls GPU utilization and inflates proven compute costs. B2 Neo resolves this friction by embedding high-throughput object storage directly into the neocloud control plane. A substantial global edge services platform adopted this model to native-tier object storage. They avoided the capital drain of building proprietary backends.
The architecture eliminates minimum duration policies found in competitor clouds. Transient model checkpoints reside cost-effectively without penalty fees.
High-Throughput Data Pipelines Powering AI and GPU Utilization
B2 Neo prevents GPU starvation. Its write-through cache design decouples compute velocity from storage cost. Data ingests directly into strategically deployed flash layers. This ensures immediate availability for training pipelines while asynchronously persisting to durable object stores. The architecture captures the performance benefits of flash layers. Operators avoid the capital intensity of local NVMe farms. They maintain the sustained throughput required for large model checkpointing.
The mechanism relies on a strict consistency model. Writes acknowledge only after flushing to both cache and backing store. This approach eliminates the data loss window inherent in write-back schemes during sudden node failures. High aggregate throughput remains stable even as dataset sizes exceed the capacity of local SSD buffers.
| Architecture Mode | Latency Profile | Failure Risk | Cost Driver |
|---|---|---|---|
| Write-Through | Consistent | None | Network Bandwidth |
| Write-Back | Variable | High | Local SSD Count |
| All-Flash Array | Low | Medium | NAND Procurement |
Network dependency creates a hard limit. The cache cannot absorb writes indefinitely if the uplink saturates. Congestion control algorithms must throttle ingestion rates to prevent buffer overflow within the flash tier. The trade-off is strict adherence to network capacity rather than unpredictable local disk exhaustion. Mission and Vision advises monitoring egress quotas closely when scaling beyond initial deployment tiers.
Deploying B2 Neo in Global Edge AI and HPC Strategies
One worldwide edge offerings platform integrates B2 Neo as a core component for AI, HPC, and media strategies. The architecture eliminates GPU underutilization caused by data movement between disjointed storage tiers. Operators avoid the massive capital costs associated with building proprietary backends from scratch. A write-through cache design with strategically deployed flash layers ensures immediate data availability for training jobs. This approach captures performance benefits without the scalability limits of pure all-flash arrays.
| Deployment Model | Time to Market | Capital Focus |
|---|---|---|
| Proprietary Backend | Years | Storage Infrastructure |
| B2 Neo Integration | Weeks | GPU Capacity |
Neoclouds cede low-level storage control to the provider. Engineering teams focus entirely on GPU roadmap differentiation. Financial data shows Q4 2025 revenue reached a substantial amount, fueling the strategic expansion. The solution prevents the diversion of resources away from core compute competencies.
- Ingest data directly into flash layers for low-latency access.
- Persist checkpoints asynchronously to durable object stores.
- Serve training batches without stalling GPU utilization cycles.
Another leader chose Backblaze B2 Overdrive to build high-performance multi-cloud training infrastructure. This confirms the pattern of avoiding in-house storage development. The result is a native service model that scales with demand. Mission and Vision recommend this path for operators facing similar bottleneck constraints.
Weeks Versus Years: B2 Neo Speed to Market Against Custom Builds
Custom storage backends demand years of engineering. B2 Neo enables neoclouds to launch integrated services in weeks. This timeline compression allows operators to prioritize GPU scaling over infrastructure maintenance. Building proprietary systems diverts capital from competitive differentiation toward commoditized storage layers. Neoclouds functioning as specialized delicatessens avoid the inefficiencies of general-purpose hyperscaler models by focusing strictly on compute density.
Financial pressure intensifies. Storage consumes an expanding share of budgets due to NAND flash volatility. External dependencies force data egress during training cycles, stalling utilization and inflating proven costs.
| Deployment Aspect | Custom Build | B2 Neo Integration |
|---|---|---|
| Time to Market | Years | Weeks |
| Engineering Focus | Storage Maintenance | GPU Roadmap |
| Capital Model | High CAPEX | Operational Expense |
| Scalability Limit | Hardware Bound | Elastic |
Operators bypass the multi-year development curve required to achieve five exabytes of managed scale independently. Validated this approach by selecting Backblaze to accelerate its AI and HPC strategies. The appointment of Anuj Kumar as Chief Revenue Officer signals a strategic shift toward rapid go-to-market execution for these partnerships. Relying on internal teams to replicate this throughput introduces unacceptable latency for time-sensitive AI workloads. The opportunity cost of delayed deployment exceeds the operational expense of outsourced storage tiers. Mission and Vision recommend using established platforms to eliminate non-differentiating engineering debt.
Strategic Advantages of Outsourcing Storage Versus In-House Builds
Defining the TCO Gap: Backblaze B2 Versus AWS S3 Pricing Structures
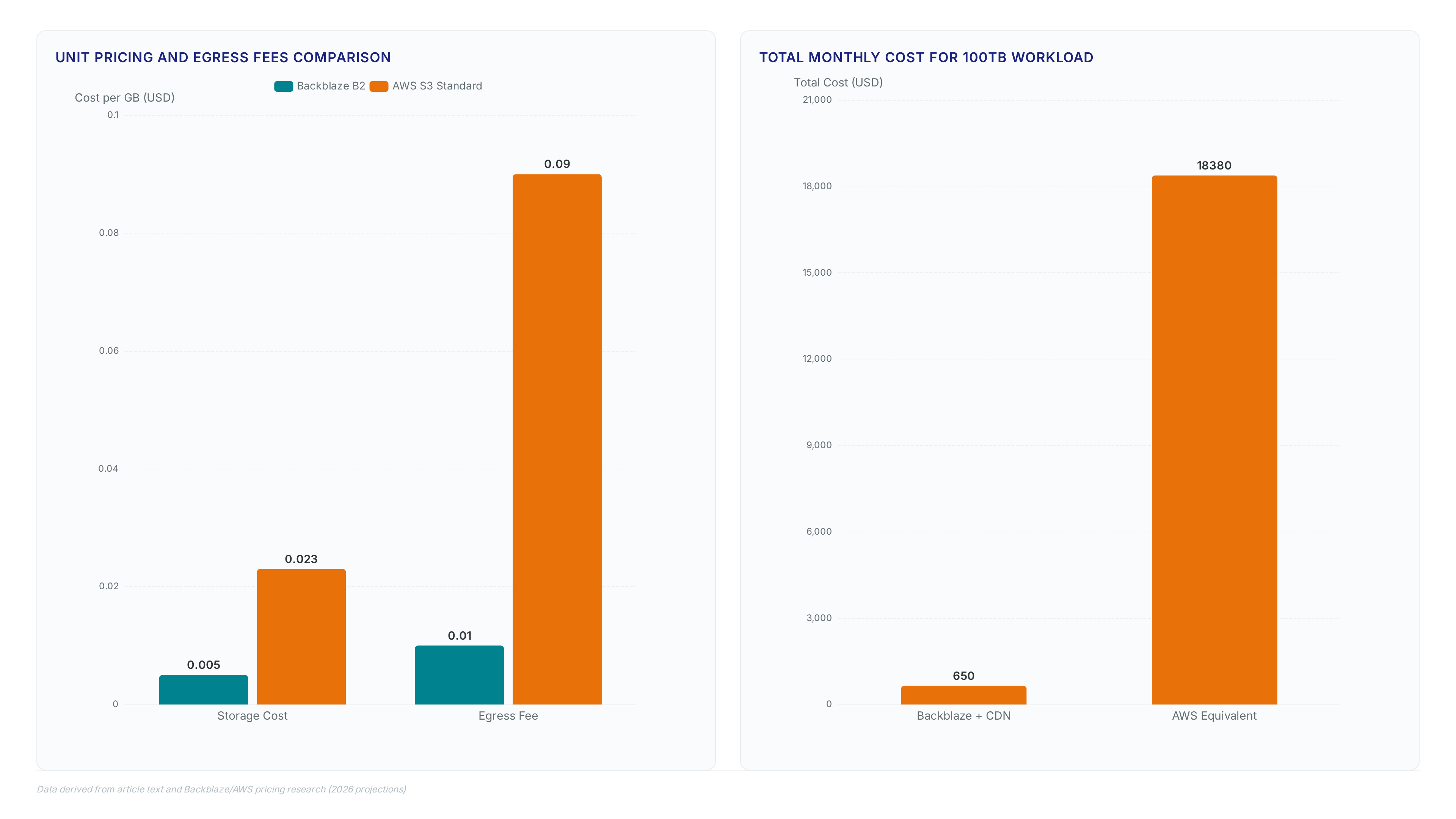
Raw storage costs diverge sharply. Backblaze charges $0.005/GB/month. AWS S3 Standard charges $0.023/GB/month. This 74% differential in unit pricing forms the baseline. Egress fees frequently dominate total expenditure for AI training pipelines. Backblaze permits free egress up to 3x the monthly average volume, charging only $0.01/GB thereafter. Hyperscalers often levy $0.09/GB for similar transfers, compounding the initial storage disparity.
A 100TB workload illustrates the cumulative effect. Pairing Backblaze with a CDN yields a $650 monthly bill. An equivalent AWS configuration reaches a substantially higher cost. The 96% total savings enable neoclouds to redirect capital toward GPU acquisition rather than storage maintenance.
This model assumes high read-to-write ratios typical of inference workloads. Write-heavy ingestion pipelines may see reduced marginal benefits if egress allowances remain unused. The financial structure favors platforms prioritizing data retrieval velocity over archival density. Mission and Vision recommends modeling specific access patterns before committing to a single tier. Static comparisons often miss flexible usage spikes.
Applying B2 Neo to Accelerate GPU Capacity Scaling for Neoclouds
Neoclouds bypass multi-year storage builds by integrating B2 Neo. They focus engineering resources on GPU capacity scaling. Building proprietary backends diverts capital from the specialized delicatessen model that defines competitive advantage against general-purpose hyperscalers. Storage costs now consume a disproportionate share of budgets. Operators outsource rather than engineer commodity layers.
Decart selected Backblaze B2 Overdrive to construct high-performance multi-cloud training infrastructure without internal R&D overhead. Grass Network integrated the platform as a primary provider after proof-of-concept testing confirmed superior speed and S3 compatibility.
Reliance on external SLAs for durability guarantees during peak training cycles poses a limitation. Operators trading control for speed must validate egress policies against their specific data gravity profiles. Mission and Vision recommends auditing workload patterns before committing to fully managed tiers.
Strategic Trade-offs: In-House Storage Development Versus B2 Neo Integration
Engineering teams divert resources from GPU scaling when constructing custom backends. This extends time-to-market by years rather than weeks. The opportunity cost manifests as delayed revenue capture. Competitors deploy single-tier solution architectures immediately. In-house builds incur hidden operational overheads that erode the margin advantages sought through vertical integration.
| Decision Factor | In-House Build | B2 Neo Integration |
|---|---|---|
| Deployment Timeline | 18–24 months | Weeks |
| Capital Expenditure | High (NAND flash surges) | Operational Expense |
| Engineering Focus | Commodity Storage | GPU Roadmap |
| Cost Structure | Unpredictable TCO | Fixed $5/TB/month |
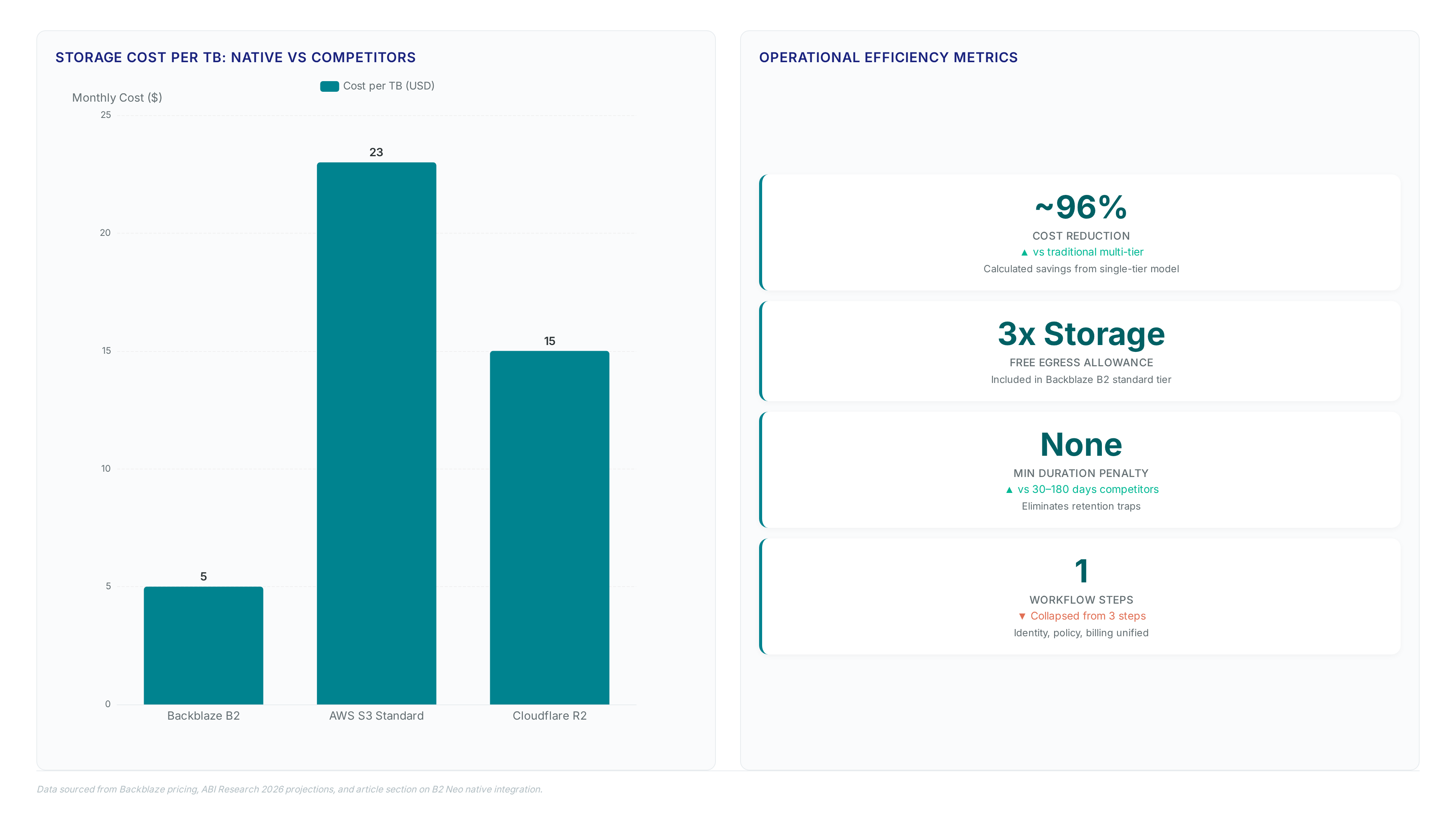
Internal development exposes operators to volatile NAND flash pricing. Outsourced models lock in predictable unit economics. Operators avoiding proprietary stacks achieve a 75% reduction in storage spend. They redirect funds toward compute density improvements. Leadership with NetApp expertise drives this shift. Storage differentiation yields diminishing returns compared to AI specialization. Vendor lock-in remains a strategic limitation. Yet the speed advantage outweighs control concerns for most neocloud entrants. Mission and Vision advise prioritizing core competencies over commodity infrastructure ownership.
Deploying Native Storage Services Through Platform Tools
Native Storage Service Model via Branded Endpoints
B2 Neo delivers storage as a native tier through branded endpoints. This architecture transforms general-purpose providers into specialized delicatessens focused strictly on GPU-heavy compute rather than sprawling service catalogs. Operators avoid the capital drain of building proprietary backends. They use existing platform tools for account provisioning, permission management, and billing consolidation. Eliminating a separate administrative console reduces operational friction during rapid scaling phases.
- Configure the S3-compatible gateway to map internal tenant IDs to upstream B2 Neo buckets.
- Enable pass-through billing APIs to charge end-users directly without manual reconciliation.
- Set retention policies to zero days, avoiding the minimum duration penalties found in competitor tiers.
The single-tier solution removes the architectural tension between performance and cost. Operators no longer manage multiple storage classes. However, relying on external storage introduces a dependency on network path stability. In-house racks do not face this issue. Latency spikes during peak training windows can stall GPU utilization if the interconnect lacks sufficient bandwidth provisioning. This cost requires operators to prioritize high-throughput peering over redundant local disk arrays. The model shifts risk from hardware obsolescence to service-level agreement enforcement.
Provisioning Accounts and Permissions via Platform Tools
Engineering teams execute account provisioning through existing platform tools. This integration collapses the traditional three-step workflow of identity creation, policy attachment, and billing configuration into a single automated pipeline. Operators define branded endpoints that mask the underlying storage layer while retaining full control over access policies. The system relies on S3-compatible APIs to ensure smooth migration for workloads dependent on standard tooling.
- Map internal identity providers to external bucket policies using standard IAM roles.
- Configure billing meters to track consumption against partner-controlled pricing tiers.
- Deploy write-through cache settings to optimize throughput for AI training datasets.
- Validate endpoint latency across multiple geographic regions before customer exposure.
Businesswire. Strict adherence to the partner's permission schema limits custom policy granularity compared to direct hyperscaler access. This constraint forces operators to standardize permission models across their entire customer base rather than accommodating edge-case requests. Mission and Vision recommends auditing all legacy access scripts before migration to prevent authentication failures during the cutover. Direct integration eliminates manual setup errors but requires rigorous testing of the billing.
S3 Compatibility and Single-Tier Migration Checklist
Migration validation begins by confirming API Compatibility. Existing toolchains must function without code refactoring. Operators verify that the target environment accepts standard S3 commands while bypassing the complex tiering logic of legacy providers.
- Execute `s3api head-bucket` commands against the new endpoint to validate authentication handshakes.
- Confirm the absence of minimum storage duration fees by auditing billing reports for early deletion charges.
- Test large-object multipart uploads to verify throughput stability across the write-through cache.
The single-tier solution prevents unexpected cost spikes when AI training jobs delete temporary checkpoints ahead of schedule.
| Feature | B2 Neo | Competitor IA Tiers |
|---|---|---|
| Min Duration | None | 30–180 days |
| API Standard | S3-compatible | S3-compatible |
| Delete Penalty | No fee | Pro-rated fees |
Multi-tier systems introduce operational friction. Data lifecycle policies accidentally trigger financial penalties. The billing configuration remains predictable because access frequency does not dictate storage class placement. Mission and Vision recommends disabling automatic tiering rules during the initial cutover phase to maintain cost visibility.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and cost optimization for cloud-native applications. His daily work designing scalable, S3-compatible storage solutions for AI and machine learning startups directly aligns with the industry shifts highlighted by Backblaze's launch of B2 Neo. Having previously managed infrastructure for high-traffic SaaS platforms, Kumar possesses deep practical insight into the challenges neocloud providers face when building storage backends from scratch. At Rabata. Io, a company dedicated to democratizing enterprise-grade object storage through transparent pricing and high-performance, he evaluates emerging market offerings to ensure optimal data strategies for clients. This expertise allows him to critically analyze how purpose-built solutions like B2 Neo empower platforms to deliver full-stack experiences without prohibitive capital costs, bridging the gap between theoretical product announcements and real-world infrastructure implementation.
Conclusion
Scaling AI inference workloads exposes the fragility of legacy storage economics. Unpredictable access patterns trigger punitive early-deletion fees that erode thin margins. As inference demands consume 80% of the neocloud market by 2030, the operational overhead of managing complex tiering logic becomes a critical bottleneck. Organizations cannot afford architectural debt that penalizes agility. The shift from capital expenditure to variable operational cost requires a storage backend that decouples performance from billing complexity. Adopt single-tier architectures immediately for any generative AI pipeline entering production before Q3 2026 to prevent margin compression during scale-up phases.
The window to optimize infrastructure costs closes as volume spikes. Delayed migration threatens profitability. Teams must prioritize throughput consistency over theoretical savings from cold storage tiers. These savings rarely materialize in flexible AI workflows. Audit your current lifecycle policies this week. Identify any rules enforcing minimum retention periods greater than zero days. Disable them before your next model training cycle begins. This specific configuration change eliminates hidden liability. It aligns your storage layer with the erratic read/write demands of real-time inference. Controlling the variable cost base now ensures that revenue growth translates directly to bottom-line gains rather than funding inefficient data management.
Frequently Asked Questions
B2 Neo lets neoclouds launch storage offerings in weeks instead of years. This speed allows teams to focus on GPU roadmaps while the market grows at a 46.37% CAGR through 2031.
The platform delivers throughput speeds up to 1Tb via a write-through cache design. This performance prevents GPU starvation during checkpoint writes for inference workloads projected to reach 80% of the sector.
Integrated object storage converts a rising 30% line item into a manageable operational expense. This shift eliminates latency bottlenecks that stall GPU utilization during critical AI training and real-time inference cycles.
Outsourcing avoids diverting engineering resources from GPU infrastructure that defines competitive advantage. Neocloud revenues exceeding $25 billion reflect a 223% year-over-year increase, proving focus on core compute drives growth.
The neocloud sector expands from $35.22 billion in 2026 to $236.53 billion by 2031. Adopting native storage now ensures platforms scale efficiently to capture this massive incoming demand without technical debt.
