gcsanalyticscore stops sequential read bottlenecks
Global data hitting 240 zettabytes by 2027 proves traditional storage cannot sustain modern analytics demands. The gcs-analytics-core library solves this bottleneck by centralizing I/O optimizations directly within the Apache Iceberg runtime. This open-source Java tool, announced June 3, 2026, by Google Cloud engineers Ajay Yadav and Nivedita Aggarwal, eliminates the need for fragmented, engine-specific tuning across Apache Spark and Trino.
Readers will discover how vectored I/O transforms sequential read patterns into parallel operations, drastically cutting open file latency. We dissect the mechanics of smart Parquet prefetching, which consolidates footer metadata retrieval into single 50KB–100KB chunks to prevent excessive network round-trips. These technical shifts address the specific incompatibility issues that have long plagued multi-engine data lake architectures.
Finally, we analyze quantifiable performance gains derived from TPC-DS benchmarking on Google Cloud Storage. By integrating natively with Iceberg version 1.11.0, this library allows organizations to handle exploding data volumes without rewriting existing pipelines. The result is a unified performance layer that forces legacy on-premise mindsets to adapt or fail in the face of cloud-native scale.
The Role of gcs-analytics-core in Modern Data Lake Architecture
gcs-analytics-core as a Centralized Optimization Layer for GCS Java SDK
Announced on June 3, 2026, gcs-analytics-core functions as a centralized optimization layer intercepting read calls between analytics engines and the GCS Java SDK. Ajay Yadav and Nivedita Aggarwal introduced this open-source Java library to eliminate sequential read latency without requiring framework-specific tuning. The architecture positions the code directly above the underlying GCS Java SDK, allowing it to inject vectored I/O and smart prefetching logic transparently. For Apache Iceberg users, the library integrates into the GCSFileIO implementation starting with version 1.11.0, replacing standard sequential fetches with parallelized strategies. This design specifically targets Parquet footer retrieval, prefetching 50KB to 100KB chunks in single operations to reduce network round trips.
| Feature | Traditional SDK | gcs-analytics-core |
|---|---|---|
| Read Strategy | Sequential | Parallel Vectored |
| Footer Fetch | Multiple seeks | Single chunk |
| Engine Tuning | Required | None |
Tight coupling to the Iceberg runtime is the price of admission; native benefits do not extend to Delta Lake or Hudi without similar specific optimizations. Operators gain immediate scan time reductions, yet must upgrade to Iceberg 1.11.0 or later to access the parallelized strategies. Dependency on a specific table format version creates a migration constraint for environments locked to older releases.
Replacing Sequential Reads with Parallelized Strategies in Apache Iceberg GCSFileIO
Apache Iceberg version 1.11.0 embeds gcs-analytics-core to replace sequential file access with parallelized read vectors. Operators asking whether to use this library over default GCSFileIO face a clear performance divergence based on dataset scale. The integration transforms the standard I/O path by injecting multi-threaded fetch logic directly into the storage layer. This architectural shift yields a 71.51% reduction in scan time for 1 GB datasets compared to the unoptimized baseline. However, the marginal gain compresses as volume increases, dropping to an 18.40% improvement at the 10 TB mark. The limitation stems from network saturation rather than client-side threading bounds.
The decision matrix depends heavily on query patterns rather than raw storage size alone.
The throughput enhancements delivered by gcs-analytics-core integration provide a native advantage for Google Cloud customers that cross-cloud formats lack without specific customization. Delta Lake deployments outside Spark environments frequently encounter complexity when attempting to replicate these low-level I/O improvements. The cost of choosing a Spark-native architecture is reduced portability when operators later adopt Trino or Hive for cost reasons. Select table formats based on long-term engine diversity rather than initial framework preference.
Inside Vectored I/O and Smart Parquet Prefetching Mechanics
Vectored I/O Mechanics: Parallel Range Fetches in Single GCS Operations
Vectored I/O eliminates sequential bottlenecks by fetching multiple data ranges in parallel within a single operation, collapsing numerous network round-trips into one request. Standard sequential logic issues a separate call for each range, inflating the number of operations and driving up open file latency for every request. The gcs-analytics-core library intercepts these patterns to execute threaded fetches, fundamentally altering how the storage layer handles columnar data access.
| Read Strategy | Call Overhead | Latency Profile |
|---|---|---|
| Sequential | High (N calls) | Cumulative delay |
| Vectored I/O | Low (1 call) | Parallelized return |
Footer Prefetching optimizations rely on rapid metadata availability to schedule downstream tasks efficiently. Without parallel execution, the system stalls while waiting for footer completion before initiating data block retrieval. The integration delivers substantial throughput gains specifically for Google Cloud customers, creating a native advantage absent in cross-cloud implementations lacking similar specific tuning.
Network bandwidth saturation, not client-side threading limits, dictates the performance ceiling. As dataset scales expand, the marginal benefit of parallelization compresses because the network pipe becomes the constraining factor instead of request overhead. Operators must balance thread pool sizes against available egress capacity to avoid contention. Excessive parallelism on constrained links can increase packet loss, degrading overall scan stability. Proven deployment requires calibrating concurrency to match the specific network tier provisioned for the cluster.
Smart Parquet Prefetching: Automating 50KB–100KB Footer Chunk Retrieval
Standard engines issue repeated backward seeks for metadata, whereas this library retrieves the footer in a single 50KB–100KB chunk. Analytics platforms typically perform an initial read of the file footer to locate data ranges, a process that triggers multiple network round-trips without optimization. The gcs-analytics-core implementation intercepts this pattern to prefetch metadata immediately upon file access. This approach prevents the latency accumulation seen when systems repeatedly seek backward to fetch structure information.
| Read Pattern | Network Calls | Latency Impact |
|---|---|---|
| Standard Seek | Multiple | Cumulative delay |
| Smart Prefetch | Single | Immediate return |
Network optimization represents the most widespread application of AI in 2026, with systems automatically adjusting resources based on usage patterns. Ignoring this efficiency becomes costly as storage tiers shift; GCS Nearline multi-region pricing rose to $0.015/GB in 2026. Reducing call volume directly mitigates these higher retrieval costs for warmer storage classes. However, the benefit diminishes if the footer size exceeds the prefetch window, forcing a fallback to sequential reads. Operators must verify that their Parquet schema complexity stays within the automated fetch limits to maintain performance gains. This constraint demands careful monitoring of file footers in high-churn environments.
Sequential Versus Parallelized Read Strategies in GCSFileIO Implementation
Parallelized strategies within GCSFileIO replace sequential bottlenecks by executing threaded range fetches in a single operation. Traditional implementations issue discrete network calls for every data segment, compounding open file latency as request volume scales. The library intercepts these patterns to inject Vectored I/O, collapsing numerous round-trips into one consolidated transaction. This architectural shift is mandatory for operators asking when to enable vectored I/O in Iceberg, as sequential logic fails to saturate available bandwidth during complex scans.
| Strategy | Call Pattern | Latency Driver |
|---|---|---|
| Sequential | N discrete calls | Cumulative wait |
| Parallelized | Single aggregated call | Network saturation |
Standard engines repeatedly seek backward to retrieve metadata, whereas the optimized path prefetches footers immediately upon access. This mechanism uses Footer Prefetching to eliminate the multiple network calls that typically occur during metadata discovery. Throughput gains remain substantial specifically for Google Cloud customers because the integration sits natively within the Iceberg 1.11.0 runtime. The Apache Spark engine benefits directly from this unified layer without requiring framework-specific tuning.
Concurrency limits clash with object store rate caps. Aggressive parallelization can trigger throttling if the client exceeds the bucket's request quota, negating latency gains. Operators must balance thread pool sizes against the specific throughput ceiling of their storage tier. The library mitigates this by managing concurrency internally, yet deployment in high-density clusters requires monitoring for saturation signals. Failure to tune these parameters results in diminished returns despite the underlying Smart Parquet prefetching capabilities.
Quantifiable Performance Gains from TPC-DS Benchmarking
TPC-DS Benchmark Methodology for GCSFileIO and Iceberg
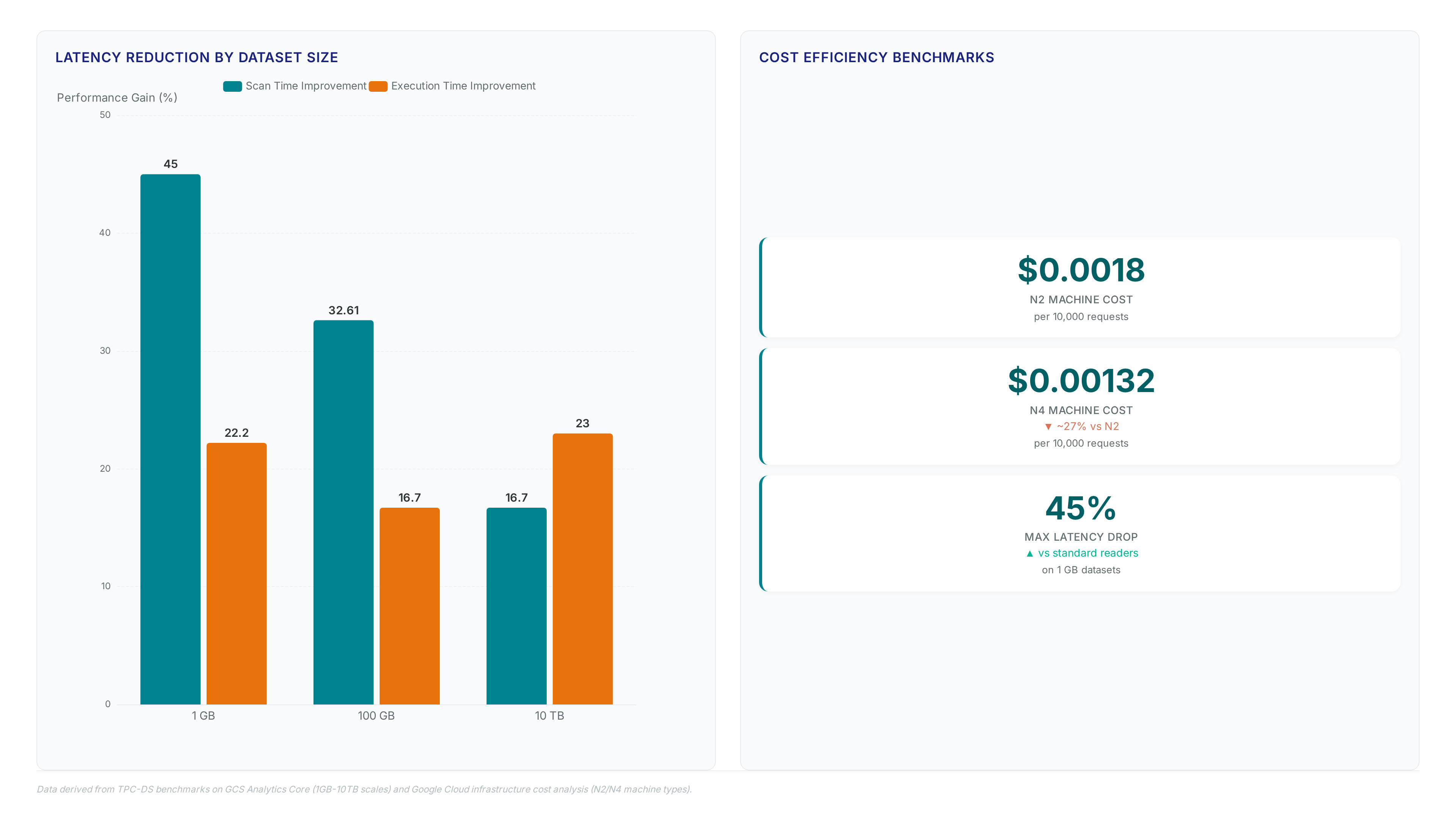
End-to-end validation requires an open-source Apache Spark cluster configured with an Iceberg catalog pointing to GCSFileIO. The framework executes the industry-standard TPC-DS schema across dataset scales from 1 GB up to 10TB. This methodology isolates storage-layer latency by comparing the optimized library against default sequential read patterns. Operators must deploy Apache Iceberg version 1.11.0 or later to access the embedded performance enhancements within the Java runtime. The test use measures scan time and total execution time to quantify the impact of parallelized fetches on complex query joins.
| Dataset Scale | Scan Time Delta | Execution Time Delta |
|---|---|---|
| Small (1 GB) | Massive reduction | Moderate gain |
| Medium (100 GB) | Significant drop | Noticeable lift |
| Large (10 TB) | Measurable cut | Marginal shift |
Strict version alignment is the cost of this validation, as earlier Iceberg releases lack the native hooks for GCS Analytics Core Smaller datasets show disproportionate gains because fixed network overhead dominates total runtime more than data volume does. Large-scale runs reveal diminishing returns on execution time as CPU-bound processing becomes the primary bottleneck rather than I/O wait. Enable vectorized I/O flags explicitly to ensure the benchmark captures the full throughput potential of the storage layer. This metric reflects the elimination of per-range call overhead when fetching Parquet footers and data blocks concurrently. Execution time drops by 32.61% because the compute engine spends less cycle time waiting on network responses.
Sequential reads force compute engines into idle states while awaiting network responses for each Parquet row group. GCSFileIO with gcs-analytics-core shifts this flexible by fetching multiple data ranges in parallel, converting network wait time into active processing cycles. This architectural change reduces the number of discrete operations required to assemble a complete data frame. Without optimization, every range request incurs a new handshake, compounding latency across thousands of files. The library collapses these into single threaded transactions, saturating available bandwidth immediately.
| Read Mode | Operation Count | Engine State |
|---|---|---|
| Sequential | High | Waiting |
| Parallelized | Low | Processing |
Operators optimizing parquet reads on GCS must recognize that reduced scan time directly lowers total query cost. Lower request counts translate to cheaper infrastructure usage, as seen in benchmarking price performance $0.00132 per 10,000 requests on N4 machine types. GCS provides free inter-region reads within multi-regions, amplifying savings when parallel strategies minimize cross-zone chatter. Increased memory pressure on the executor during the initial prefetch phase is the trade-off. Large footers fetched simultaneously can spike heap usage if not tuned correctly. Monitor executor overflow metrics when enabling vectorized I/O for the first time.
Implementing gcs-analytics-core in Spark and Iceberg Environments
Defining gcs-analytics-core Configuration Flags for Apache Iceberg 1.11.0

Activating gcs-analytics-core in Apache Iceberg 1.11.0 requires setting two specific Boolean flags within the Spark catalog configuration. Operators must first declare the optimization layer by assigning `spark. Sql. Catalog. $CATALOG_NAME. Gcs. Analytics-core. Enabled=true`. This setting binds the runtime to the centralized logic embedded in the Apache Iceberg Java distribution. Second, parallel fetches demand `spark. Sql. Iceberg. Vectorization. Enabled=true` to override default sequential read patterns. Without this second flag, the library intercepts calls but cannot execute multi-range requests effectively.
- Load the `iceberg-gcp-bundle` matching the runtime version.
- Point the `io-impl` class to `org. Apache. Iceberg. Gcp. Gcs. GCSFileIO`.
- Apply the analytics-core and vectorization properties to the catalog namespace.
Misconfiguration here creates a silent failure mode where Vectored I/O remains inactive despite the library being present on the classpath. The library architecture Enabling both flags transforms read behavior from discrete operations into consolidated transactions. Neglecting the vectorization property leaves the system vulnerable to the same latency penalties observed in unoptimized deployments.
Constructing spark-submit Commands with iceberg-gcp-bundle 1.11.0 Dependencies
Operationalizing gcs-analytics-core demands precise package coordinates within the `spark-submit` entry point to activate vectored I/O.
- Declare the Apache Iceberg Spark runtime and iceberg-gcp-bundle artifacts using the `--packages` flag.
- Set the catalog implementation to `org. Apache. Iceberg. Spark. SparkCatalog` via `--conf`.
- Explicitly bind the IO layer to GCSFileIO to intercept read calls before they reach the SDK.
- Enable the analytics core flag and vectorization switch to enable parallel fetch strategies. The library functions as a centralized layer between engines and the storage SDK, requiring no code changes within the application logic itself. Developers can inspect the underlying implementation details in the GoogleCloudPlatform/gcs-analytics-core repository to verify thread pool sizing. Compatibility extends beyond Spark to include Trino and Hive, provided the IO implementation points to the updated GCS connector. New users testing this configuration on non-production clusters may apply the standard $300 credit Missing the vectorization flag leaves the prefetcher idle, creating a silent failure mode where latency remains unchanged despite correct library loading.
Production clusters may apply the standard $300 credithttps://cloud.google.com/blog/products/data-analytics/data-analytics-innovations-at-next25 to test these dependencies before broad rollout. Teams should verify that the bundled artifact matches version 1.11.0 exactly to avoid classpath conflicts during initialization.
Validating GCSFileIO Implementation and Catalog Settings in SparkCatalog
Confirm the catalog references `org. Apache. Iceberg. Gcp. Gcs. GCSFileIO` to activate the centralized optimization.
- Verify `spark. Sql. Catalog. $CATALOG_NAME. Io-impl` matches the native GCP implementation exactly.
- Set `spark. Sql. Catalog. $CATALOG_NAME. Gcs. Analytics-core. Enabled=true` to intercept read calls.
- Enable `spark. Sql. Iceberg. Vectorization. Enabled=true` for parallel data range fetching.
- Confirm dependencies include `iceberg-gcp-bundle` 1.11.0+ to access native throughput gains.
Operators frequently omit the vectorization flag, causing the library to intercept requests without executing multi-range fetches. This configuration error forces the engine back into sequential patterns, negating potential latency reductions. The Apache Spark engine will not automatically parallelize reads unless both boolean flags evaluate to true simultaneously. Validation requires checking the active Spark UI for concurrent connection spikes during footer prefetching operations. Missing the bundle artifact results in silent fallback to standard I/O paths. Administrators must inspect logs for the specific 05 release marker to confirm correct loading. Failure to see the 1110 build number indicates an outdated jar file. Systems running version 0 lack the necessary hooks entirely.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to the discussion on gcs-analytics-core. His daily work designing high-performance, S3-compatible storage solutions for AI/ML startups directly aligns with the challenges of accelerating data lakes on object storage. At Rabata. Io, a provider focused on eliminating vendor lock-in through true API compatibility, Alex routinely engineers infrastructure that demands the exact type of engine-agnostic performance this new library promises. His background as a former SRE managing high-traffic data platforms gives him unique insight into the friction data engineers face when balancing compatibility across multiple analytics engines. By connecting Google's open-source advancements with practical deployment strategies, Alex illustrates how tools like gcs-analytics-core enable organizations to maximize throughput on cost-effective storage tiers without sacrificing speed or flexibility.
Conclusion
Performance gains from GCS Analytics Core diminish sharply as datasets cross the 10 TB threshold, proving that network saturation eventually overrides local compute optimizations. While initial benchmarks show dramatic speedups, relying solely on client-side tuning ignores the escalating egress costs driven by the 2026 pricing shifts to $0.015/GB for Nearline multiregion access. The architecture breaks not because the code fails, but because the operational expense of massive parallel fetches outweighs the time saved when volume scales to zettabytes. Teams must pivot from pure latency reduction to a cost-per-query model that balances concurrency limits against billing realities.
Adopt this hybrid approach immediately for any workload exceeding large-scale storage thresholds: enforce strict data locality policies where hot datasets reside in single-region buckets to cap network overhead, while reserving multiregion setups only for disaster recovery. Do not wait for the next billing cycle to audit these configurations; the window to optimize before global data volumes hit 240 zettabytes closes rapidly. Start by auditing your current Spark UI logs this week to identify jobs triggering sequential fallbacks due to missing vectorization flags, then enforce the `iceberg-gcp-bundle` 1.11.0 dependency across all production clusters before Friday's deployment window.
Frequently Asked Questions
Scan time reduces by 71.51% for 1 GB datasets compared to unoptimized baselines. This massive gain occurs because parallelized strategies replace sequential reads effectively on smaller data volumes.
Performance gains drop significantly to an 18.40% improvement at the 10 TB mark. Network saturation limits further scaling benefits despite the continued use of parallelized read vectors.
Total execution time drops by 32.61% because the compute engine spends less time waiting on storage I/O operations. This efficiency allows resources to focus on actual data processing tasks.
Users must upgrade to Apache Iceberg version 1.11.0 or later to access native gcs-analytics-core integration. Older releases lack the embedded GCSFileIO improvements needed for vectored I/O.
The library consolidates footer metadata retrieval into single 50KB–100KB chunks to prevent excessive network round-trips. This approach eliminates multiple seeks required by traditional sequential read patterns.
