Federated storage beats cloud for Italian research data
GARR now operates Europe's first fully functional federated geo-distributed storage system with an initial capacity of 1 petabyte. This deployment proves academic institutions can reclaim data sovereignty without surrendering control to hyperscale vendors or violating ACN regulations. By fragmenting and encrypting files across domestic nodes, the architecture ensures durability against localized outages while strictly adhering to GDPR perimeter requirements.
Technological autonomy is no longer optional. Global storage volumes are predicted to triple by 2027, creating urgent pressure to adopt decentralized models that mitigate single-point failures and reduce dependency on foreign infrastructure. The GARR-Cubbit pilot demonstrates how using existing on-premises hardware creates a cost-effective barrier against vendor lock-in.
We examine the specific mechanics of data fragmentation within the GARR-Cubbit architecture and how it secures high-value research assets. We detail the strategic implementation steps required for universities to join this distributed object storage network and contribute their own resources. Finally, the analysis covers how this model satisfies stringent cybersecurity mandates while maintaining the high-performance connectivity necessary for modern collaboration.
The Role of Federated Geo-Distributed Storage in Research Data Sovereignty
Federated Geo-Distributed Storage vs Centralized Cloud Models
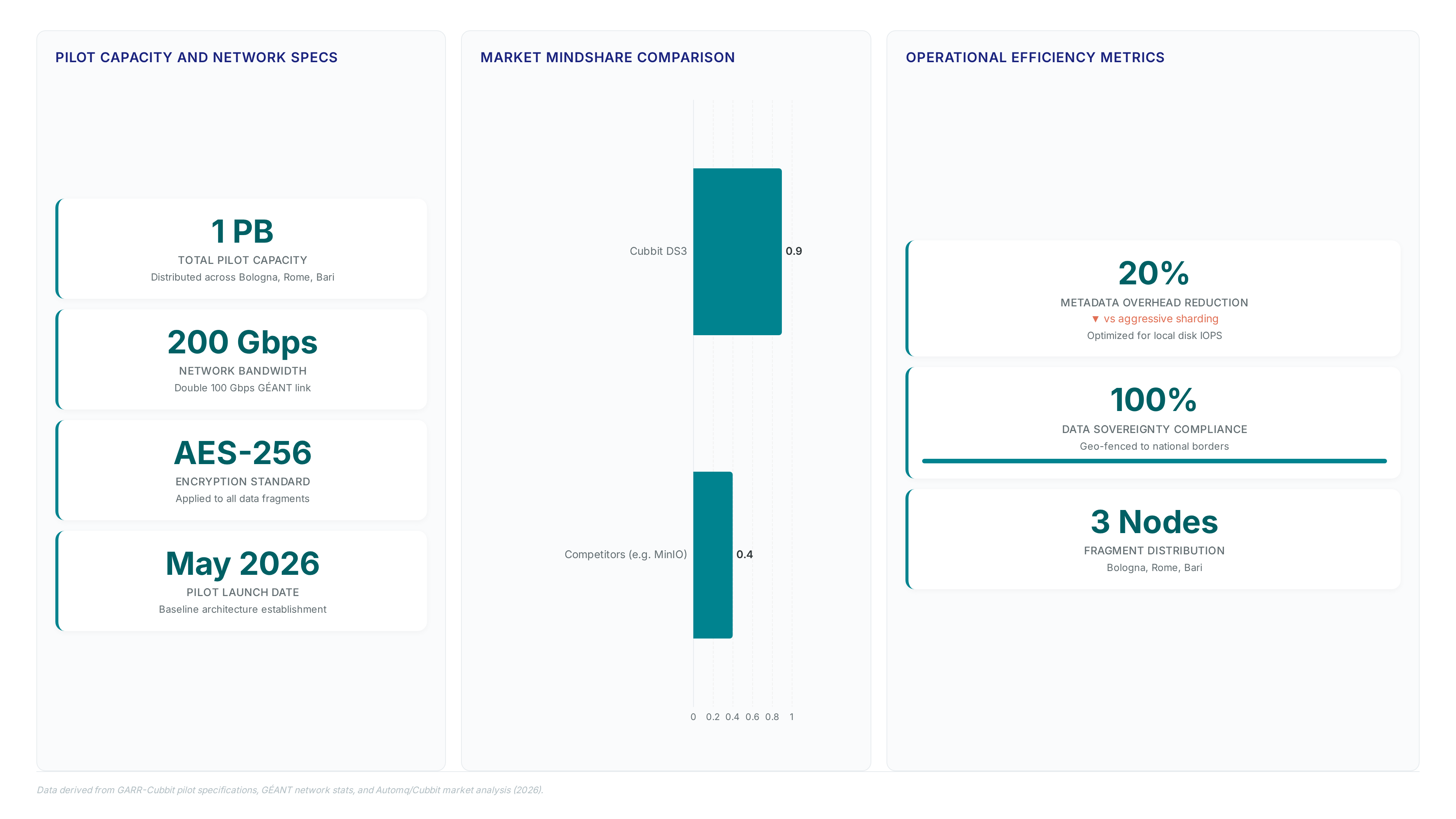
Federated geo-distributed storage fragments data across independent on-premises nodes rather than concentrating it in single-tenant facilities. This architecture went live in April 2026 as the first fully operational system of its kind in Europe for research institutions. Traditional centralized models rely on vendor-managed regions, creating single points of failure and jurisdictional exposure. The GARR and Cubbit pilot uses idle server capacity from home offices to enterprise data centers to build a sovereign perimeter. Physical control remains within national borders, satisfying strict regulatory mandates without external dependency.
Cubbit claims a data loss probability of 1 in 1 million billion, notably outperforming the 1 in 100 billion rate of conventional cloud providers. Fragmentation and encryption of objects across a peer-to-peer network ensure that no single node holds a complete file. Durability demands active participation from member institutions to maintain node availability and network health. Operators gain immunity to vendor lock-in but assume the operational burden of managing their own hardware contributions. The shift replaces capital expenditure on new racks with the strategic reuse of underutilized local infrastructure.
GARR's 24,000km Fiber Network Enabling Italian Data Sovereignty
GARR operates 24,000km of fiber connecting 1,000 sites to keep research data inside the Italian perimeter. This on-premises federated architecture replaces vulnerable centralized cloud models by fragmenting storage across trusted institutional nodes rather than foreign regions. The pilot phase launched on April 10, 2026 with 1 petabyte of capacity distributed across Bologna, Rome, and Bari to satisfy ACN compliance mandates. Serving 3 million users, the network uses existing assets to eliminate vendor lock-in while maintaining high-availability during site outages. Institutions contributing hardware gain data sovereignty without sacrificing S3 compatibility or workflow integration.
Adoption requires active participation in resource pooling, shifting operational burden from a single provider to the consortium membership. This constraint ensures that no external entity controls the encryption keys or physical location of sensitive scientific datasets. The model proves that national research communities can achieve durability comparable to hyperscalers using domestic infrastructure alone. Operators evaluating federated storage must weigh the cost of internal coordination against the risk of jurisdictional exposure inherent in commercial clouds. Success depends on consistent policy enforcement across all participating nodes to maintain the integrity of the distributed object store.
Cubbit DS3 Cost Reduction and CO2 Savings Against AWS S3
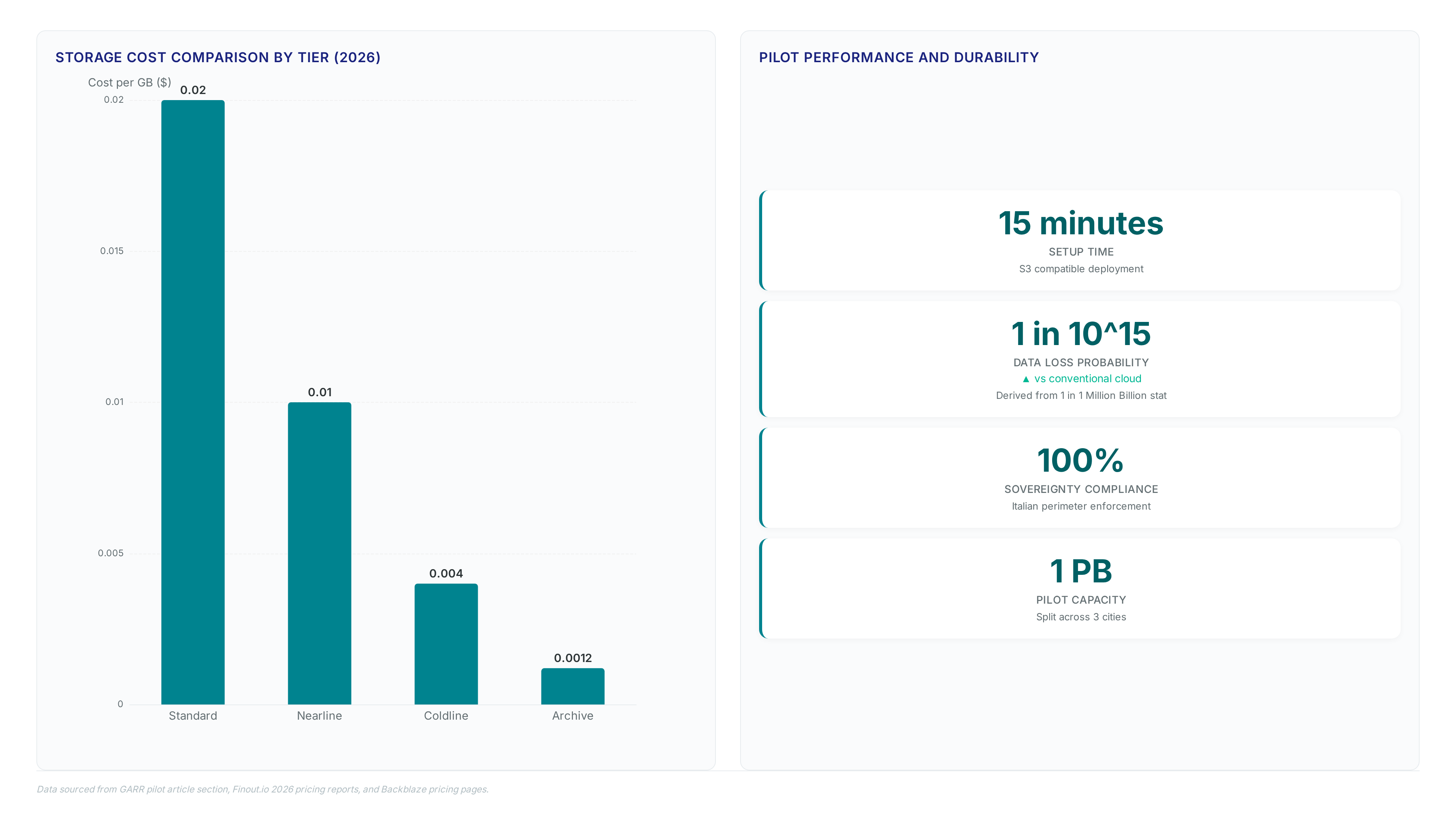
Federated storage delivers an 80% cost reduction versus standard hyperscaler pricing models. Traditional architectures charge roughly $0.03/GB for persistent object storage, creating exponential budget strain as research datasets expand. The GARR and Cubbit deployment avoids these variable fees by using existing institutional hardware instead of renting external capacity. This economic model simultaneously addresses environmental constraints by eliminating the energy overhead of dedicated commercial data centers.
The 40,000 kg of CO2 emissions avoided per petabyte annually demonstrates that sovereign architecture reduces physical waste alongside financial outlay. Hyperscalers optimize for global density, whereas federated nodes use local power grids and idle server cycles. Institutions adopting this model gain budget predictability while satisfying strict carbon neutrality mandates often ignored by public cloud providers. The limitation involves upfront coordination to integrate disparate hardware, yet the long-term savings justify the initial engineering effort. Evaluate total cost of ownership before committing to single-vendor lock-in.
Inside the GARR-Cubbit Architecture and Data Fragmentation Mechanics
DS3 Composer and AES-256 Fragmentation Mechanics
The DS3 Composer engine encrypts inbound objects with AES-256 before slicing them into cryptographically distinct shards. No single node ever hosts a complete file, effectively neutralizing lateral movement attacks during a breach. Software aggregates these fragments across the Swarm cluster, using GARR's fiber backbone to maintain high throughput without exposing raw data planes.
- Ingested data receives military-grade encryption keys at the edge.
- Algorithms fragment the ciphertext into small, non-reconstructible pieces.
- Shards distribute geographically across Bologna, Rome, and Bari nodes.
- Metadata maps shard locations while the original object remains invisible.
| Feature | DS3 Composer Approach | Traditional S3 Replication |
|---|---|---|
| Data State | Always encrypted and fragmented | Often plaintext at rest per zone |
| Failure Domain | Single shard loss is harmless | Zone outage risks full object access |
| Trust Model | Zero-knowledge mathematical guarantee | Vendor-dependent administrative controls |
Fragmentation introduces latency penalties for small-object workloads where round-trip times dominate transfer speeds. Reassembling multiple shards before decryption adds computational overhead that monolithic storage avoids. Operators must tune fragmentation thresholds based on dataset characteristics to balance durability against performance degradation. This architectural choice trades raw sequential speed for extreme durability and sovereign control over physical data placement. Cost is higher for tiny files than for large datasets.
Geo-Fencing Implementation for Immutable Ransomware Backups
Restricting data shards to predetermined geographical areas prevents cross-border legal exposure while enabling immutable backup stores. Architecture enforces strict locality by pinning erasure-coded fragments exclusively to nodes in Bologna, Rome, and Bari, satisfying ACN mandates without sacrificing redundancy. Configuration transforms standard object storage into a ransomware-resistant vault where write-once-read-many policies block encryption attacks at the protocol level. Operators configure disaster recovery by defining retention locks that persist even if administrative credentials are compromised. System mitigates data access issues in distributed environments through automated shard reconstruction, requiring only a subset of nodes to restore full objects.
| Feature | Centralized Cloud | GARR Federated Model |
|---|---|---|
| Data Location | Vendor-selected regions | Italian perimeter only |
| Ransomware Defense | Soft delete windows | Hard immutability flags |
| Recovery Speed | Dependent on egress caps | Local fiber reconstruction |
Strict geo-fencing conflicts with node availability. Limiting shards to three cities reduces the mathematical pool for reconstruction compared to global clouds. However, the high-capacity backbone compensates for few physical sites by accelerating parallel shard retrieval. Design prioritizes regulatory compliance over maximum theoretical dispersion, accepting a smaller failure domain to guarantee sovereignty. Institutions gain data durability against localized outages while maintaining full control over encryption keys and physical storage media.
Validating Federated Storage Node Contributions and Continuity
Operators must validate hardware contributions against the 100% S3-compatible Validation checklist requires verifying local disk integrity, confirming network reachability across the fiber backbone, testing encryption key handshakes before joining the Swarm, and auditing firmware versions. Misaligned storage tiers often occur when legacy hardware lacks the throughput for real-time fragmentation, causing bottlenecks that degrade cluster performance. Institutions should deploy geo-distributed shards when data sovereignty and ransomware durability outweigh the latency penalties of wide-area replication. Traditional backup remains preferable for cold archives requiring single-site retrieval speeds without erasure coding overhead. Neglecting this validation creates a false sense of security where fragmented data becomes unrecoverable despite apparent redundancy.
| Deployment Scenario | Recommended Architecture | Primary Constraint |
|---|---|---|
| Active Research Datasets | Geo-distributed Federation | Network latency |
| Cold Archival Storage | Traditional Local Backup | Retrieval speed |
| Regulatory Compliance | Geo-fenced Federation | Jurisdictional borders |
| Disaster Recovery | Hybrid Multi-site | Bandwidth capacity |
Data loss probability drops notably only when every node meets strict continuity standards. Participating universities must enforce these checks to maintain the integrity of the national research infrastructure. Failure to verify hardware leads to silent data corruption.
Strategic Implementation Steps for Joining the GARR-Cubbit Network
DS3 Composer Integration with GARR's double high-capacity GÉANT Link
Integrating DS3 Composer requires binding the software layer to GARR's double.
- Configure the storage pool to apply the full bandwidth of the GÉANT
- Define geo-fencing policies that restrict AES-256 fragments to the Bologna, Rome, and Bari nodes.
- Validate S3 API compatibility against existing university workflows to prevent application breakage.
- Activate immutable retention locks to secure data against ransomware encryption attempts.
The pilot phase launched in May 12, 2026 establishes the baseline for this architecture. High throughput enables rapid fragmentation, yet operators face a tension between maximizing replication factors and preserving local disk IOPS for active research datasets. Aggressive sharding improves durability but increases metadata overhead on the control plane. Institutions must balance these variables based on their specific data velocity rather than applying a uniform policy. The resulting system offers a sovereign alternative to commercial clouds while demanding precise tuning of the DS3 Composer engine. Start with lower replication counts for non-critical datasets to measure performance impact before scaling protection levels.
Deploying On-Premises Nodes Across Bologna, Rome, and Bari
The pilot phase initiates with a 1 petabyte capacity distributed across GARR data centres in Bologna, Rome, and Bari. Institutions contribute local hardware to this federated model, transforming passive assets into active storage nodes that maintain full data sovereignty. Operators must install DS3 Composer to integrate existing disks with the wider network while enforcing strict geographic boundaries.
- Verify hardware compatibility with the S3 standard to prevent workflow disruptions during the onboarding process.
- Configure geo-fencing policies that pin all data shards exclusively to the three Italian cities for regulatory compliance.
- Enable AES-256 encryption at the edge before fragments traverse the fiber backbone to ensure zero-trust security. 4.
Hardware validation begins by confirming local disk throughput supports real-time fragmentation before joining the federated geo-distributed storage network. Operators must execute four specific checks to prevent cluster degradation during the onboarding phase.
- Verify S3 API compatibility against existing workflows to avoid application breakage.
- Test network reachability across the fiber backbone to ensure shard distribution.
- Confirm AES-256 encryption key handshakes complete within set latency windows.
- Validate that legacy controllers do not bottleneck the DS3 Composer software layer.
| Component | Requirement | Failure Mode |
|---|---|---|
| Disk Controller | High sequential write | Shard queuing |
| Network Interface | Full duplex | Partition events |
| CPU | AES-NI support | Encryption lag |
| Memory | ECC enabled | Data corruption |
The cost of skipping step three is measurable: weak handshakes force re-transmission of fragments, consuming bandwidth that could serve petabyte-scale archives Most operators overlook the tension between using existing idle servers and meeting the strict throughput demands of erasure coding. Older hardware often passes basic connectivity tests yet fails under the load of simultaneous fragment generation. This specific failure mode creates invisible redundancy gaps where the system reports healthy status while unable to rebuild lost shards quickly enough. Institutions relying on such marginal nodes risk data availability during site outages despite appearing fully joined to the pilot phase. The limitation is clear: contributing hardware requires vailable disk space; it demands verified processing power for cryptographic operations.
Measurable ROI and Durability Gains from On-Premises Federated Storage
Defining Federated Geo-Distributed Storage for Research Autonomy
Institutions should adopt federated storage when regulatory mandates require data to remain strictly within the Italian perimeter. This architecture replaces centralized vulnerability with a resilient mesh where universities contribute local hardware to form a sovereign storage swarm. Unlike traditional clouds, this model fragments and encrypts data at the source, ensuring no single node holds a complete file. Such durability stems from distributing shards across multiple geographic locations rather than relying on redundant disks in a single facility.
Operators gain full data sovereignty by retaining physical control over the infrastructure hosting their information. The trade-off involves active participation; members must maintain their own nodes and manage local network reachability. Passive consumption is impossible in this framework, as the network capacity grows only through direct hardware contributions from the scientific community. This requirement creates a barrier for institutions lacking internal technical staff to manage edge storage devices. Adopt this approach solely for entities capable of sustaining on-premises operational duties while seeking independence from third-party lock-in.
Operationalizing the 1 Petabyte GARR Pilot Across Three Cities
Deployment begins with 1 petabyte of capacity split across Bologna, Rome, and Bari to enforce strict data sovereignty. Institutions enroll by contributing local hardware, transforming passive assets into active nodes within the federated geo-distributed storage network. The platform requires only 15 minutes for setup, using S3 compatibility to bypass complex multi-region configurations typical of hyperscalers. Operators install DS3 Composer to integrate existing disks while maintaining full control over encryption keys and shard placement.
| Phase | Action | Constraint |
|---|---|---|
| Enrollment | Contact GARR and Cubbit | Hardware must meet throughput specs |
| Configuration | Apply geo-fencing policies | Data stays inside Italian perimeter |
| Validation | Test S3 API compatibility | Legacy apps may need refactoring |
Interested universities can contact GARR and Cubbit This model eliminates vendor lock-in but demands that participants manage their own physical maintenance cycles. Sovereignty requires active participation rather than passive consumption of utility services. This statistical gap defines the durability ceiling for research data requiring decades of integrity. Standard hyperscaler models rely on replication factors that statistically cap durability, whereas the federated mesh fragments and encrypts data across independent nodes to eliminate single points of failure. The shift away from centralized dependency is visible in market mindshare changes, where legacy providers face declining dominance against sovereign alternatives.
| Metric | Federated Model | Traditional Cloud |
|---|---|---|
| Loss Probability | 1 in 1,000,000,000,000,000 | 1 in 100,000,000,000 |
| Data Control | Full local sovereignty | Vendor-managed keys |
| Architecture | Geo-distributed mesh | Centralized regions |
Operators should deploy this geo-distributed architecture when regulatory mandates forbid cross-border data flows or when long-term preservation outweighs low-latency access needs. Traditional backup suits short-term recovery, but scientific datasets demand the immutability provided by fragmented sharding. A critical tension exists between absolute sovereignty and universal accessibility; choosing the federated model sacrifices the global edge network of hyperscalers for guaranteed data residency. This trade-off forces institutions to prioritize compliance and durability over the marginal latency benefits of distant availability zones. The resulting infrastructure eliminates vendor lock-in while providing a mathematically superior guarantee against catastrophic loss.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep technical expertise to the evolving environment of geo-distributed storage. His daily work designing Kubernetes storage architectures and reliable disaster recovery solutions directly aligns with the complexities of federated networks like the new GARR and Cubbit initiative. At Rabata. Io, a specialized S3-compatible object storage provider, Kumar optimizes infrastructure for AI/ML startups and enterprises seeking scalable, cost-effective alternatives to traditional cloud vendors. His hands-on experience managing data center operations across EU and US regions provides unique insights into the challenges of latency, compliance, and data sovereignty inherent in geo-distributed systems. By using his background in eliminating vendor lock-in and enhancing performance, Kumar effectively analyzes how collaborative networks can democratize access to enterprise-grade storage for research institutions while maintaining the transparency and speed required for modern data-intensive workflows.
Conclusion
Scaling this architecture reveals that operational overhead shifts from billing management to physical hardware lifecycle tracking. While software setup takes minutes, the long-term burden of replacing failed drives across distributed sites creates a hidden labor cost that grows linearly with node count. Institutions often underestimate the logistical friction of maintaining a sovereign mesh compared to the invisible reliability of managed services. This model is strictly advisable for archives facing strict data residency laws or projects with retention horizons exceeding ten years, where compliance penalties outweigh operational labor. Do not adopt this for hot storage requiring sub-millisecond global access; the latency penalty remains prohibitive for interactive workloads. The window to establish these networks before the predicted 2026 data volume surge closes rapidly, making immediate planning necessary. Start by auditing your current storage contracts this week to identify datasets subject to cross-border restrictions that justify the migration effort. Execute a pilot deployment on non-critical research data within the next thirty days to validate your team's capacity for hardware maintenance before committing mission-critical archives. Success depends on treating infrastructure as an active stewardship duty rather than a passive utility purchase.
Frequently Asked Questions
Federated storage offers significantly higher durability than conventional options. The system claims a data loss probability of just 1 in 1 million billion, vastly outperforming the 1 in 100 billion rate found in traditional cloud environments.
Institutions can achieve massive savings by utilizing existing hardware resources. Federated storage delivers an 80% cost reduction compared to standard hyperscaler pricing models, allowing researchers to reclaim budget while maintaining full data sovereignty and control.
The network leverages extensive fiber connectivity to serve a massive academic community. GARR currently supports around 3 million users across its connected sites, ensuring high availability and continuity for critical scientific data without external dependency.
Traditional architectures often impose higher recurring fees for standard storage tiers. Conventional models charge roughly $0.03 per GB, whereas the federated approach reduces this burden by leveraging underutilized local infrastructure instead of expensive commercial cloud regions.
No, the model specifically encourages reusing current assets rather than buying new racks. Institutions contribute their own existing hardware to the pool, transforming idle server capacity into a resilient, sovereign storage perimeter without significant capital expenditure.
