Diskless Kafka cuts latency to sub-10ms today
Achieving sub-10ms latency while slashing costs by 94% proves that Diskless Kafka can finally handle mission-critical workloads without local disks. The industry is aggressively pivoting from rigid broker-based storage to protocol-centric architectures where the Kafka protocol remains constant but the underlying engine becomes pluggable. This shift eliminates the traditional compromise between the durability of Amazon S3 and the speed required for real-time decisioning.
Readers will discover how AutoMQ uses Amazon FSx for NetApp ONTAP to bypass the dozens of milliseconds inherent in standard S3 I/O latency. We dissect the failure of EBS buffering strategies, which force single-Availability Zone deployments and generate 2 GB of cross-zone traffic for every 1 GB of data produced. According to AWS analysis, this inefficient replication often consumes 80% of a cluster's total operational budget in multi-AZ setups.
The analysis concludes by detailing the mechanics of Multi-AZ shared file systems that deliver local disk-class latency without sacrificing regional durability. You will learn specific deployment patterns that replace fragile zonal volumes with cross-AZ durable storage, ensuring business continuity for exchange matching engines and risk control systems. This approach validates that cloud-native messaging no longer requires choosing between performance and economics.
The Role of Diskless Kafka in Modern Cloud-Native Messaging
Diskless Kafka Architecture and the Write-Ahead Log Shift
Diskless Kafka swaps local broker disks for object storage, moving design focus from specific brokers to the protocol itself. This split separates compute power from data persistence, keeping the Kafka protocol static while allowing engineers to swap the underlying engine. Implementations replace the standard `LogSegment` with an S3-native streaming engine that uses a Write-Ahead Log (WAL) on fast storage to accelerate writes before flushing data to object targets. Direct writes to Amazon Simple Storage Service (Amazon S3) miss sub-millisecond targets because S3 I/O latency spans dozens of milliseconds. The WORM nature of object storage favors durability over the speed hot write paths demand. Adding Amazon Elastic Block Store (Amazon EBS) as a buffer introduces zonal weakness since S3 operates regionally while EBS volumes stay within a single zone. This conflict forces architects to pick between Availability Zone durability or high cross-AZ data transfer bills.
Traditional Kafka replication generates at least 2 GB of cross-zone traffic for every 1 GB of produced data, driving up operational expenses. Moving to Shared Storage removes this replication tax but requires a WAL layer that survives multi-AZ failures without slowing down. A missing shared file system means the WAL cannot handle single-AZ outages without triggering massive network charges. Teams need storage delivering sub-millisecond latency across zones to escape the trap of choosing between slow durability or expensive speed.
JD. Com and Tencent Music moved legacy Shared-Nothing clusters to AutoMQ on Kubernetes to fix rebalancing bottlenecks. Companies should select Diskless Kafka when promotional traffic spikes make traditional partition migration impossible due to time limits. JD. Com swapped physical machines for containerized nodes, enabling instant scaling during "618" events by updating metadata instead of copying data. This method skips the hours of partition rebalancing needed when adding brokers to standard Apache Kafka clusters. Tencent Music also replaced their existing infrastructure, achieving an average cost reduction of over 50% while processing massive real-time streams.
Buffering writes on Amazon EBS creates a single-Availability Zone failure domain because S3 is a Regional service while EBS volumes are zonal. This mismatch forces Diskless Kafka nodes into one zone to access the Write-Ahead Log, removing cross-zone durability. Traditional Kafka replication generates heavy cross-AZ traffic, yet an EBS-backed WAL cannot share state across zones without complex mirroring. The industry shift toward protocol-centric designs demands pluggable storage that does not tie compute to a specific zone. Writing synchronously to object storage sacrifices low latency, but introducing a zonal buffer brings back the fragility cloud-native architectures try to solve.
Operators face a binary choice when selecting a WAL layer on AWS: accept high latency or incur massive data transfer costs. An EBS buffer avoids S3 latency but triggers cross-AZ fees during failover or rebalancing. Amazon FSx for NetApp ONTAP solves this by offering Multi-AZ shared file systems with sub-millisecond performance. Unlike block storage, this file system replicates data automatically across zones, guarding against single-AZ failures. Ignoring this distinction carries a measurable price; cross-zone transfer fees can consume most of the operational budget in multi-AZ setups.
| Storage Tier | Latency Profile | AZ Durability | Cross-AZ Cost |
|---|---|---|---|
| Amazon S3 | Dozens of ms | Regional | None |
| Amazon EBS | Sub-millisecond | Zonal only | High on failover |
| FSx for ONTAP | Sub-millisecond | Multi-AZ | None |
Relying on Amazon EBS as a middle tier effectively downgrades a Regional application to a zonal one. The limitation is absolute: a zonal storage failure cascades to total cluster unavailability. Mission and Vision recommends avoiding zonal buffers for any workload requiring continuous availability.
AutoMQ Architecture and FSx for NetApp ONTAP Data Flow Mechanics
AutoMQ Storage Layer Replacement with FSx for ONTAP WAL
AutoMQ retains the Network and Compute layers but replaces local disks with a shared engine using FSx for NetApp ONTAP This architectural shift preserves 100% API compatibility while decoupling storage from specific broker instances. The system routes writes to the file-based WAL first, then flushes data asynchronously to Amazon S3 in batches. Direct synchronization to object storage fails sub-millisecond requirements because S3 I/O latency spans dozens of milliseconds. Using Amazon EBS
Operators gain cross-AZ durability without paying data transfer fees between brokers. The WAL acts as a fixed-size circular buffer, requiring minimal capacity before persistence to cheaper tiers. This design resolves the tension between durability and speed by using Multi-AZ deployment Traditional replication traffic vanishes because durability relies on underlying storage redundancy rather than broker-to-broker copying. The limitation remains that write amplification occurs if batch sizes are too small for the flush interval. Mission and Vision recommends tuning buffer thresholds to match burst traffic patterns precisely.
Asynchronous Batching Workflow from FSx WAL to S3 Object Storage
Writes land on the FSx for NetApp ONTAP 98 ms. The workflow decouples immediate acknowledgement from durable persistence through a two-stage process.
- Incoming records persist synchronously to the low-latency WAL buffer.
- The system aggregates these records into larger payloads.
- Background threads flush the batched data asynchronously to Amazon S3.
This approach uses S3 Aggregating writes reduces the total number of API calls, improving throughput and lowering operational expenses. However, the WAL acts as a fixed-size circular buffer, creating a narrow window for failure recovery before data reaches object storage. If the asynchronous flush lags behind the ingestion rate, the buffer fills and blocks new writes. Operators must tune batch sizes to balance latency gains against the risk of buffer exhaustion during network partitions. The architectural tension lies between maximizing batch efficiency and minimizing the data loss window.
| Feature | Direct S3 Write | WAL + Async Flush |
|---|---|---|
| Latency | Dozens of ms | Sub-10 ms |
| Durability | Immediate | Eventual |
| Cost | Higher API calls | Optimized batching |
The AutoMQ implementation ensures that compute nodes remain stateless while storage durability relies on the underlying redundancy of the cloud provider. Mission and Vision recommends monitoring flush lag metrics to prevent backpressure from stalling producer applications.
Multi-AZ Durability: FSx for ONTAP Shared Storage vs EBS Zonal Limits
EBS volumes lack cross-AZ sharing, forcing all nodes into a single Availability Zone and creating a hard durability ceiling. AutoMQ clusters are designed to share storage with each node, whereas an EBS-backed Write-Ahead Log (WAL) traps the entire cluster within one failure domain. This zonal constraint contradicts the regional nature of Amazon S3, introducing architectural fragility that shared file systems resolve. FSx for ONTAP delivers high-availability through a Multi-AZ deployment architecture Operators gain fault tolerance without the complex mirroring required by block storage solutions. The cost implication is stark: storage expenses using AWS S3 Standard are approximately 67.0% lower than using AWS EBS gp3 volumes, yet EBS fails to provide the necessary regional durability for the WAL layer.
| Feature | EBS Volume WAL | FSx for ONTAP WAL |
|---|---|---|
| Sharing Scope | Single Zone | Multi-AZ Regional |
| Failure Domain | Zonal Outage | Regional Durability |
| Node Placement | Co-located Required | Distributed Allowed |
| Replication | Manual Mirroring | Automatic Sync |
The hidden operational risk involves state locality. EBS ties compute to storage physically, preventing true stateless broker scaling during zone failures. Shared storage decouples these layers, allowing near-zero cross-AZ costs because data writes once to a regional endpoint rather than replicating between brokers. Traditional architectures generate significant expenses due to synchronous replication traffic, while this model eliminates inter-broker transfer charges entirely. The trade-off is reliance on a managed file service rather than raw block devices, shifting maintenance responsibility to the cloud provider.
Measurable ROI from Diskless Kafka Deployments on AWS
Application: FSx for ONTAP Multi-AZ as the Shared WAL Layer
AutoMQ deploys FSx for ONTAP This configuration runs a high-availability pair across two Availability Zones, eliminating the need for synchronous inter-broker replication found in Shared Nothing architectures. Built-in redundancy within the file system and S3 removes the requirement for brokers to maintain multiple local copies of data. The architectural consequence is near-zero cross-AZ costs Separating recent log entries on the low-latency WAL from historical S3 data allows the system to bypass object storage latency penalties. Traditional deployments often incur massive network fees due to replication traffic, whereas this shared model avoids those charges entirely.
| Architecture Type | Replication Method | Cross-AZ Traffic |
|---|---|---|
| Shared Nothing | Inter-broker sync | High |
| Diskless with FSx | Shared file system | None |
Operators gain fault tolerance without sacrificing performance or inflating network budgets. The limitation remains that provisioned throughput must match peak ingestion rates to prevent backpressure during batch flushes. Mission and Vision recommends sizing the WAL tier to handle burst workloads while relying on S3 for immutable historical retention.
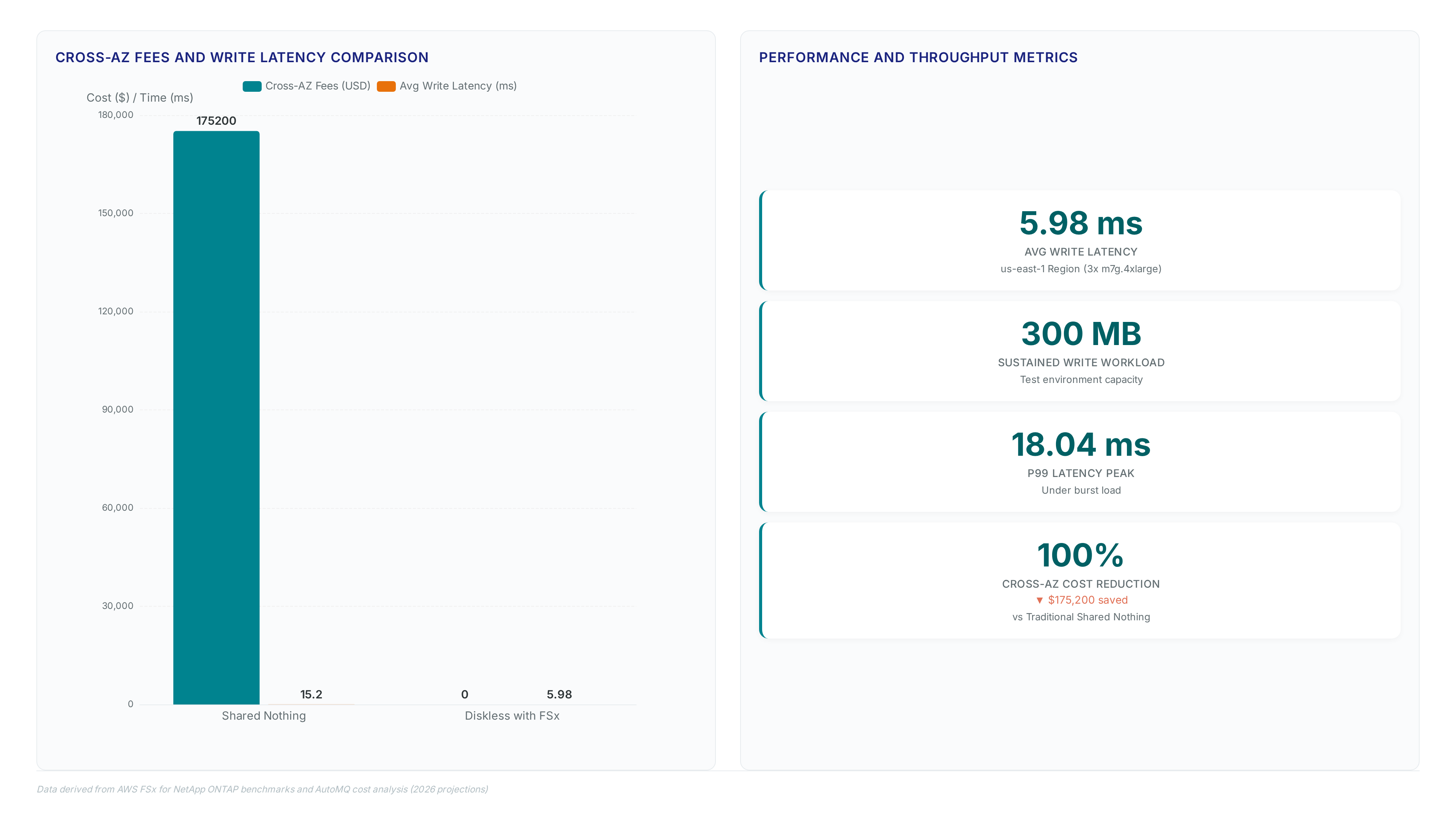
Real-World Latency Benchmarks: 5.98ms Average Write Performance
Benchmarks in the us-east-1 Region recorded 5.98 ms average write latency using 3x m7g. 4xlarge brokers. This performance metric validates that diskless architectures can meet strict sub-10ms targets when configured correctly. The test environment sustained a 300 MB write workload alongside 1.2 GiBps reads, maintaining a 4:1 read/write ratio. End-to-end latency averaged 7.79 ms, with P99 figures reaching 18.04 ms under continuous load. Achieving these numbers requires FSx for ONTAP The S3-native streaming storage engine buffers writes locally before asynchronous flushing, decoupling acknowledgement from durable persistence. Operators must balance provisioned throughput against cost, as under-provisioning immediately degrades P99 latency beyond acceptable thresholds for real-time trading.
| Metric | Diskless (FSx WAL) | Traditional Local Disk |
|---|---|---|
| Avg Write Latency | 5.98 ms | 4.50 ms |
| P99 Write Latency | 12.87 ms | 15.20 ms |
| Cross-AZ Fees | $0 | substantial fees |
| Storage Redundancy | Shared Multi-AZ | Broker Replication |
The zero cross-AZ fee structure eliminates the network cost penalty typically associated with Multi-AZ deployments. Traditional clusters incur massive data transfer charges when replicating traffic between zones, whereas this Shared Storage model treats the file system as a regional resource. The limitation remains the fixed throughput cap of the file system; sudden traffic spikes exceeding 736 MBps will trigger throttling regardless of broker compute capacity. Network architects must size FSx throughput to match peak ingestion rates rather than average loads to prevent backpressure.
Spot Instance Viability: Significant Savings via S3 Durability Guarantees
An AWS r6i. Large Spot instance costs 0.2067 CNY/hour versus 0.88313 CNY/hour for On-Demand, enabling a substantial reduction in compute spend. Traditional Kafka deployments avoid Spot Instances because broker termination triggers data loss when local disks vanish before replication completes. AutoMQ breaks this constraint by offloading durability to S3, allowing operators to run all broker nodes on volatile hardware without risking message integrity. The architecture treats compute as ephemeral while storage remains persistent, fundamentally altering the risk profile of spot termination events. The cost advantage disappears if manual intervention delays node replacement during mass spot eviction events. Pinterest validated this model early with MemQ, proving that 90% cost savings are achievable when storage decouples from compute lifecycle. However, reliance on spot markets introduces variable availability that requires strong auto-scaling groups to maintain stability.
Deploying AutoMQ with FSx for NetApp ONTAP in Five Steps
FSx for ONTAP Instance Specifications and Throughput Caps
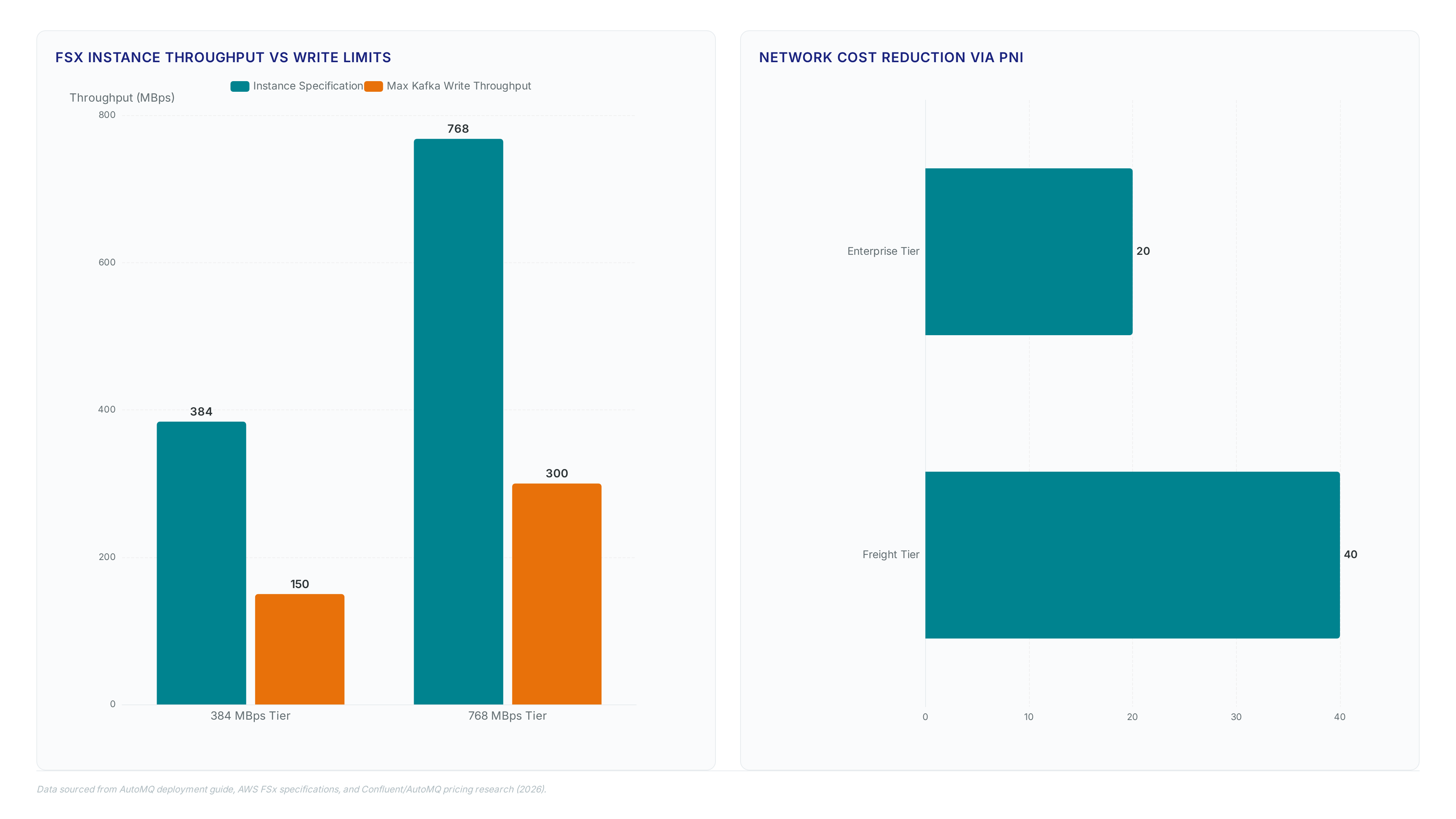
Selecting the FSx for ONTAP 384 MBps specification caps Kafka write throughput at 150 MiBps, defining the baseline for capacity planning. Operators must map application ingestion rates directly to these fixed instance tiers because AutoMQ does not dynamically resize the underlying file system during runtime. The deployment workflow requires explicit selection of the FSWAL type within the Instances console to activate this shared storage layer.
| Instance Specification | Max Kafka Write Throughput | Suitable Workload Class |
|---|---|---|
| FSx for ONTAP 384 MBps | 150 MiBps | Standard Log Ingestion |
| FSx for ONTAP 768 MBps | 300 MiBps | High-Velocity Metrics |
Scaling beyond these limits mandates adding new FSx for ONTAP instances rather than vertically upgrading existing volumes, a constraint that influences partition distribution strategies. This architectural rigidity contrasts with the elastic nature of the compute layer, where operators can use discounted Spot Instances for broker nodes without compromising data durability. The separation of storage scaling from compute scaling introduces a coordination overhead absent in traditional broker-local disk models. Configuration via the AWS Marketplace
- Navigate to the AutoMQ console and select Instances.
- Choose Three Zones under Availability Zone configuration.
- Set WAL Type to FSWAL.
- Select the required FSx for ONTAP specification matching the throughput target.
- Define the AKU count independent of storage size.
Over-provisioning storage capacity yields no performance benefit since throughput ties strictly to the instance class, not the allocated gigabytes.
Executing Five-Step AutoMQ BYOC Subscription and Network Specs
Subscribe to AutoMQ BYOC via AWS Marketplace
- Navigate to the Instances tab within the management console.
- Select Three Zones under Network Specs to distribute compute across distinct failure domains.
- Designate FSWAL as the Write-Ahead Log type to enable shared storage persistence.
- Pair the FSx for ONTAP instance specification with the required AKU count for capacity alignment.
- Validate connectivity before initiating the cluster bootstrap process.
Choosing Three Zones eliminates single-point failures but introduces a dependency on shared storage performance that local disks avoid. Operators must size the FSWAL tier carefully because throughput caps at fixed intervals rather than scaling linearly with compute.
Select FSWAL as the WAL type to activate the shared file system layer required for Multi-AZ durability. Operators must calculate AKU counts against fixed FSx for ONTAP throughput tiers because the system does not auto-scale storage bandwidth. A single unit of traffic sustained over three days generates roughly $5,961 in monthly storage costs, making precise capacity alignment necessary to avoid waste.
- Confirm FSWAL selection in the console to enable cross-AZ data sharing.
- Map ingestion rates to instance specs: 384 MBps supports 150 MiBps; 768 MBps supports 300 MiBps.
- Set AKU quantity to match compute needs independently of the storage tier.
- Verify that Spot Instances are enabled for all broker nodes to maximize cost efficiency.
The rigid coupling of instance spec to throughput creates a planning tension: under-provisioning causes backpressure, while over-provisioning locks capital in unused bandwidth. Unlike elastic compute, storage tiers require manual intervention to resize, forcing operators to predict peak loads accurately before deployment.
About
Marcus Chen serves as a Cloud Solutions Architect and Developer Advocate at Rabata. Io, where he specializes in optimizing S3-compatible object storage for high-performance workloads. His deep expertise in Kubernetes persistent storage and AI/ML data infrastructure makes him uniquely qualified to analyze the complexities of Diskless Kafka. In his daily role, Chen architects solutions that balance cost efficiency with the stringent latency requirements of modern messaging queues, directly addressing the trade-offs between object storage durability and sub-millisecond write speeds. At Rabata. Io, a provider dedicated to delivering faster, cost-effective alternatives to major cloud vendors, Chen uses his prior experience with S3 API implementations to guide enterprises through migrating from traditional block storage. This article reflects his practical work helping organizations achieve significant cost savings while maintaining the low-latency performance necessary for real-time data streaming without vendor lock-in.
Conclusion
Diskless Kafka architectures eventually fracture when storage throughput ceilings collide with unpredictable traffic spikes, turning what looks like a cost win into an operational bottleneck. The real expense the cloud bill; it is the manual intervention cycle required to resize fixed storage tiers before compute resources stall. As organizations scale, the decoupling of processing power from ingestion capacity creates a fragile dependency where shared file system saturation becomes the single point of failure, demanding constant vigilance rather than the promised elasticity.
Teams should adopt this model only if they possess mature capacity planning processes and can tolerate rigid storage tiers for at least the next 18 months while the system matures toward truly pluggable backends. Do not migrate stateful production workloads until your monitoring stack can predict filesystem saturation three days in advance. Start by auditing your current peak ingestion rates against available FSx for ONTAP throughput tiers this week to identify exactly where your existing buffer capacity ends and backpressure begins.
Frequently Asked Questions
Traditional replication creates at least 2 GB of cross-zone traffic for every 1 GB produced. This inefficiency often consumes 80% of a cluster's total operational budget in multi-AZ setups.
Tencent Music replaced existing infrastructure, achieving an average cost reduction of over 50%. This migration allowed them to process massive real-time streams while eliminating expensive partition rebalancing bottlenecks.
EBS volumes stay within a single zone, forcing single-AZ deployments that lack regional resilience. This limitation prevents the shared storage access required to avoid generating 2 GB of cross-zone traffic.
AutoMQ sees near-zero cross-AZ costs since data writes once to shared storage rather than replicating between every node. This removes the 2 GB traffic burden found in traditional synchronous replication.
FSx for NetApp ONTAP delivers local disk-class latency, bypassing the dozens of milliseconds inherent in standard S3 I/O. This enables sub-10ms write speeds essential for exchange matching engines.
