Databricks on-prem data: Cut storage costs 40%
Databricks hit a $5.4 billion run-rate in February 2026, yet most enterprise data remains trapped on-premises. MinIO's new AIStor Table Sharing solves this by enabling direct, zero-copy access to local datasets from the cloud without risky replication. This architecture finally decouples compute from storage while respecting the physical reality of data gravity.
You will learn how embedding Delta Sharing into the object store eliminates the need for fragile ETL pipelines and duplicate cloud storage costs. We dissect the underlying Apache Iceberg v3-native foundation that allows MinIO to manage table catalogs and governance policies internally, removing external dependencies. Finally, the guide details the specific steps to enable secure federation between on-premises MinIO clusters and Databricks workspaces.
With Databricks growing 65% year-over-year according to Sacra, the pressure to connect static local assets to elastic cloud compute has never been higher. MinIO reports that this integration allows businesses to publish table shares directly from storage, bypassing traditional bottlenecks. The result is immediate analytics on live data, stripping away the operational risk and latency inherent in moving petabytes of information just to run a query.
The Role of AIStor Table Sharing in Solving Data Gravity
AIStor Table Sharing and the Delta Sharing Protocol Architecture
Launched March 3, 2026, AIStor Table Sharing embeds the Delta Sharing protocol directly into the object store binary. This move kills data gravity by letting Databricks query on-premises datasets without replication. You get a native storage layer implementation that replaces fragile ETL pipelines. The system acts as a governed distribution point for structured tables, removing the operational overhead of separate sharing servers often required by legacy SFTP or custom API solutions.
Administrators can share both Delta and Iceberg-formatted data from a single MinIO AIStor bucket thanks to support for the Delta Universal Format. This dual-format capability prevents vendor lock-in while maintaining strict local administrative control over sensitive industrial data. Operators gain immediate access to live datasets, reducing the latency inherent in batch synchronization processes.
| Feature | Legacy ETL | AIStor Table Sharing |
|---|---|---|
| Data Movement | Full replication | Zero-copy federation |
| Format Support | Proprietary | Delta and Iceberg |
| Infrastructure | Separate servers | Embedded binary |
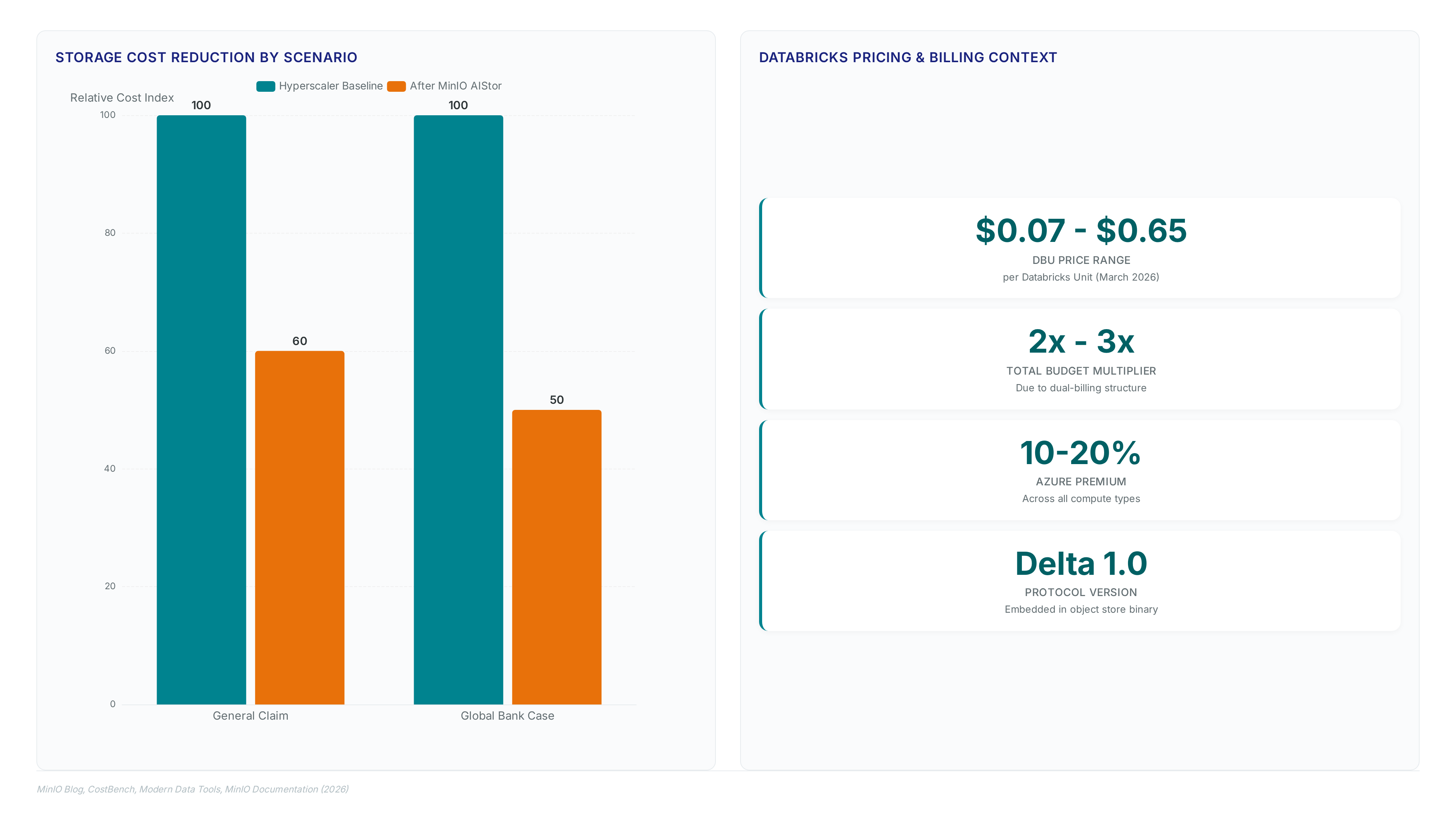
The math is clear: organizations can analyze 2-3 times more industrial data for the same expense compared to hyperscaler-controlled table services. But there is a catch. While storage costs drop by up to 40%, the network egress burden shifts entirely to the WAN link between the data center and the cloud analytics engine. Network engineers must provision sufficient bandwidth to handle interactive query loads. The protocol moves compute to the data but pulls result sets across the wire. Fail to optimize this path, and you negate the latency advantages of in-place analytics.
Real-World Federated Analytics Deployments at Nomura and Orange Group
Nomura eliminated four hours of daily risk processing by executing federated queries on local MinIO AIStor instances. This deployment validates Delta Sharing as a mechanism for financial institutions to bypass traditional ETL latency while maintaining strict data sovereignty. The architecture allows Databricks clusters to read on-premises tables directly, removing the need for cloud replication layers that often introduce security gaps.
An Orange Group subsidiary reported a 300% productivity increase after shifting compliance workflows to this shared storage model. Query times dropped from hours to minutes because the system avoids network-bound data movement entirely. Here lies the hard choice: organizations must pick between the operational simplicity of centralized cloud lakes and the performance gains of localized compute. Ignore this trade-off, and teams end up managing duplicate datasets, inflating storage costs and complicating governance policies.
Adopting open data sharing standards becomes mandatory when regulatory constraints prevent full cloud migration yet analytics demand remains high. Modern data platforms must prioritize direct access protocols over brittle integration scripts. If you leave sharing logic outside the storage binary, your enterprise remains dependent on custom APIs that scale poorly under heavy load.
Legacy ETL Pipelines Versus Live Data Access Without Replication
Traditional analytics rely on complex ETL pipelines that duplicate datasets. AIStor Table Sharing enables direct live access instead. Legacy architectures force organizations to copy on-premises data into cloud storage before Databricks can process it. This approach creates significant operational risks and maintenance burdens compared to embedded protocols. Historical methods using SFTP or custom APIs demand costly management overhead that scales poorly with data volume. In contrast, the new architecture requires no replication or cloud migration to connect analytics platforms to local storage. Eliminating these intermediate steps removes the latency inherent in batch-oriented data movement.
| Feature | Legacy ETL / SFTP | AIStor Live Access |
|---|---|---|
| Data Location | Duplicated in Cloud | Stays On-Premises |
| Protocol Type | Custom API or File Transfer | Delta Sharing 1.0 |
| Management Overhead | High (Separate Servers) | None (Embedded Binary) |
| Cost Structure | Egress Fees + Storage | Local Storage Only |
Avoiding hyperscaler-controlled table services delivers measurable financial impact. This efficiency stems from embedding the sharing protocol directly into the storage layer binary rather than deploying separate middleware. Removing data duplication also eliminates egress charges associated with moving terabytes for every analytic run. However, this model requires strict network connectivity between the on-premises cluster and the cloud workspace. Teams must verify firewall rules allow direct table metadata exchange without tunneling bottlenecks. Audit current bandwidth capacity before decommissioning existing batch pipelines.
Inside the Architecture of In-Place Analytics with Apache Iceberg
Native Apache Iceberg v3 REST Catalog and Sub-Millisecond Metadata
MinIO AIStor Tables embed the native Apache Iceberg REST Catalog directly into the object storage binary. This removes external dependencies like Hive Metastore or AWS Glue. The design consolidates metadata operations, enabling atomic multi-table transactions without intermediary services. Schema evolution happens instantly within the storage layer, erasing the synchronization lag found in decoupled catalog systems.
| Component | Legacy Architecture | AIStor Tables Architecture |
|---|---|---|
| Metadata Store | External (Hive, Glue) | Embedded Object Store |
| Transaction Scope | Single Table | Atomic Multi-Table |
| Latency | Network-bound | Sub-millisecond |
| Dependency | High | Zero |
A unified REST API gives operators direct control over table definitions while handling both data and metadata requests. The system delivers sub-millisecond metadata performance compatible with Spark and Trino query engines. Compute clusters resolve partition states almost instantaneously during federated analytics workflows. Tight coupling between storage versioning and metadata consistency emerges when embedding the catalog. Upgrading the storage binary requires coordinated validation of table schemas to prevent state divergence. Governance policies apply uniformly across structured and unstructured data under this simplified operational model. Eliminating the external catalog layer reduces the attack surface for metadata spoofing while accelerating query planning. Validate transaction logs during initial deployment to confirm atomicity guarantees under high concurrency.
Direct access to on-premises data via Delta Sharing stops the cost inflation typical of cloud migrations. A standard $1,000/month DBU quote often expands into a $2,000 to $3,000 total budget due to hidden infrastructure and egress fees inherent in the dual-billing structure. Financial leakage occurs because legacy architectures force data replication before analytics can begin. MinIO AIStor embeds the sharing protocol directly into the object store binary, making the storage layer itself a secure, governed distribution point without separate servers.
| Cost Component | Legacy Replication Model | AIStor In-Place Model |
|---|---|---|
| Data Movement | High Egress Fees | Zero Transfer Cost |
| Storage Bill | Duplicate Cloud Copy | Single On-Prem Copy |
| Management | Separate Sharing Server | Embedded Protocol |
Eliminating replication does not automatically resolve network latency if the underlying WAN link is saturated. The Delta Sharing 1.0 implementation boosts compatibility but relies on sufficient bandwidth between the data center and the cloud workspace. Hybrid deployments frequently fail to account for this transport constraint, assuming protocol efficiency negates physical distance. True cost avoidance requires validating that the on-premises network path can sustain the throughput demanded by Databricks clusters. Ignoring this physical layer reality turns a theoretical saving into an operational bottleneck. The architecture shifts expense from storage duplication to network capacity planning.
Delta Versus Apache Iceberg Table Support to Prevent Framework Lock-In
Supporting both Delta and Apache Iceberg formats within a single binary prevents proprietary sharing methods from dictating long-term architecture. The Delta Universal Format allows organizations to scale analytics workloads while avoiding the vendor lock-in inherent in single-format ecosystems through this dual-format capability.
| Feature | Single-Format Strategy | Multi-Format Strategy |
|---|---|---|
| Protocol Flexibility | Restricted to one standard | Supports Delta and Iceberg |
| Migration Path | Requires full data rewrite | Enables gradual format adoption |
| Binary Consistency | Often requires separate stacks | Shared core architecture |
The native Apache Iceberg REST Catalog implementation supports atomic multi-table transactions and schema evolution without external dependencies like Hive or Nessie. Teams adopt Apache Iceberg v3 for new projects while maintaining legacy Delta assets, ensuring continuity during technology transitions. Operational complexity in metadata governance arises when adopting a multi-format approach that single-format shops avoid. Operators must manage two sets of table properties and versioning rules within the same namespace. This constraint secures use against future protocol deprecation or licensing changes by any single foundation. Validate both format readers in staging environments before production rollout to ensure query engine compatibility.
Steps to Enable Delta Sharing and Integrate Databricks
Delta Sharing 1.0 Integration Mechanics in MinIO AIStor
MinIO AIStor embeds the Delta Sharing 1.0 protocol directly into the object store binary, eliminating the need for a separate sharing server. This architectural choice transforms the storage layer itself into a governed distribution point for structured tables. Operators enable this capability by configuring the native Delta Universal.
- Activate the Table Sharing service within the MinIO console to initialize the sharing endpoint.
- Define share objects that map specific AIStor buckets to external recipients.
- Generate time-limited credentials using the embedded architecture to enforce least-privilege access.
- Paste the resulting share URL into the Databricks workspace to mount tables as native sources.
Write operations remain blocked for external query engines to preserve data integrity. This constraint prevents accidental corruption but requires source-system updates to flow through the primary AIStor cluster. Validate read-only S3 access policies before exposing production tables to external clouds.
Configuring In-Place Analytics to Eliminate Data Replication
Embedding the Delta Sharing 1.0 protocol directly into the object store binary removes the requirement for external catalog services during hybrid integration.
- Initialize the sharing endpoint within the MinIO console to activate the native distribution layer.
- Define access policies using AWS IAM syntax to restrict read operations while blocking writes.
- Connect the Databricks workspace to the on-premises endpoint using the generated share URL.
- Query the remote tables as native objects without triggering data movement or ingestion jobs.
This configuration bypasses the dual-billing structure inherent in legacy cloud migrations. A standard DBU quote often expands notably due to hidden infrastructure and egress fees found in traditional data sharing architecture. Cost inflation occurs because older models force replication before analytics can begin, whereas this approach keeps data local. Operators gain immediate query access while maintaining strict sovereignty controls over the physical storage media. Write operations are strictly prohibited on shared tables to ensure data integrity across the federation. Read-only constraints prevent accidental schema drift but require separate pipelines for any upstream data updates. Validate network latency between the Databricks control plane and the on-premises AIStor cluster before production rollout.
Validation Checklist for Hybrid Table Sharing Security and Compliance
Verify token expiration limits against the one-year maximum enforced by new open sharing recipient tokens before exposing any table to external workspaces.
- Confirm the Delta Sharing 1.0 service is active within the binary to eliminate separate sharing server vulnerabilities.
- Audit Policy-Based Access Control rules to ensure read-only S3 access blocks all write operations from remote clusters.
- Validate that multi-format support covers both Delta and Apache Iceberg tables to prevent protocol translation errors during federation.
Failure to align token lifecycles with internal compliance windows creates a gap where stale credentials remain valid beyond audit periods. The architecture embeds governance directly into the storage layer, yet operators must still manually verify that expiration policies match corporate data retention mandates.
| Check Item | Legacy Method | AIStor Native |
|---|---|---|
| Token Limit | Custom Scripting | Enforced One-Year Max |
| Policy Scope | External Gateway | Embedded PBAC |
| Format Risk | High Translation | Zero Overhead |
Treat the storage binary as the primary enforcement point rather than relying on downstream compute permissions.
Measurable ROI and Strategic Fit for Enterprise Hybrid Analytics
Defining In-Place Analytics via Delta Sharing 1.0 Protocol

Direct access to on-premises datasets through the Delta Sharing 1.0 protocol eliminates the latency and cost penalties associated with traditional ETL ingestion pipelines. This architectural approach embeds the sharing logic directly into the object store binary, transforming the storage layer into a secure, governed distribution point without requiring a separate sharing server. Operators use this mechanism to maintain strict data sovereignty while granting Databricks clusters immediate visibility into live operational tables.
Regulatory constraints often prohibit data movement across jurisdictional boundaries. Keeping data local while enabling access through an open sharing protocol allows businesses to uphold existing compliance and auditing requirements simultaneously. This model shifts the performance burden to the wide-area network. Insufficient bandwidth between the on-premises MinIO cluster and the cloud analytics engine will degrade query throughput regardless of protocol efficiency. Adoption of open data sharing standards becomes mandatory when the cost of maintaining custom APIs or legacy SFTP transfers exceeds the operational overhead of configuring standardized endpoints. Deploy this architecture only when data gravity prevents economical migration of petabyte-scale history to public cloud environments.
Scaling Hybrid Analytics Across Manufacturing and Financial Services
Manufacturing and financial firms adopt AIStor Table Sharing to bypass ETL costs while satisfying strict data sovereignty mandates. Regulated industries require analytics on live operational data without moving assets across jurisdictional boundaries. A global bank reduced deployment time by 50% after migrating from appliance-based storage to MinIO AIStor, proving the model for latency-sensitive workloads. The architecture supports three subscription tiers: Free, Enterprise Lite, and Enterprise, allowing teams to start with limited capacity and expand features as query volumes increase. All editions share the same binary, meaning scaling from a pilot to full production involves only a license key change rather than a disruptive re-architecture.
Nomura replaced Hadoop with a hybrid cloud data lakehouse powered by MinIO, cutting daily risk processing time by four hours while doubling storage capacity. This performance gain stems from eliminating the data movement layer that traditionally bottlenecks hybrid queries. Organizations frequently underestimate the operational drag of maintaining separate governance policies for replicated cloud copies versus single-source truth systems. The constraint remains that network bandwidth between the on-premises object store and cloud compute must sustain peak query loads, as no local cache exists within the Databricks cluster for shared tables. Teams should validate WAN throughput before committing to large-scale table sharing across geographic regions.
Application: Delta Versus Apache Iceberg Table Support to Prevent Framework Lock-In
Supporting both Delta and Apache Iceberg tables prevents enterprise lock-in to a single lakehouse framework or proprietary sharing method. Organizations generating massive operational data on-premises face regulations and latency challenges that make full cloud migration impractical. Min. This dual-support strategy contrasts sharply with hyperscaler-controlled services often limited to specific table types.
Adopting this flexibility avoids the hidden costs of format migration when analytics requirements shift. A September 2025 tech preview introduced Apache Iceberg V3 Catalog REST API support, signaling a move toward universal compatibility. Operational complexity presents a drawback. Managing two format specifications requires stricter governance policies than single-format environments. Teams must validate schema evolution rules across both standards to prevent query failures during federation. Strategic fit depends on whether the organization prioritizes immediate Databricks integration or long-term format agnosticism.
About
Alex Kumar, Senior Platform Engineer and Infrastructure Architect at Rabata. Io, brings deep expertise in Kubernetes storage architecture and cost optimization to the discussion on AIStor Table Sharing. His daily work designing scalable, S3-compatible infrastructure for AI/ML startups directly aligns with the challenges of enabling smooth data access without costly replication. Having previously served as an SRE for high-traffic platforms, Kumar understands the critical need for eliminating vendor lock-in while maintaining high-performance. At Rabata. Io, a provider dedicated to democratizing enterprise-grade object storage, he architects solutions that prioritize transparency and speed, mirroring the efficiency goals of MinIO's new Delta Sharing integration. This background makes him uniquely qualified to analyze how direct on-premises access transforms Databricks workflows, ensuring organizations can use explosive AI growth without compromising on data sovereignty or inflating egress costs.
Conclusion
Scaling AIStor table sharing reveals a critical fracture point: network egress costs often the savings from reduced storage, turning a lean architecture into a budget liability as query volume grows. While Databricks accelerates its market dominance with 65% year-over-year growth, relying solely on proprietary integration creates a fragile dependency that limits future negotiation power. The operational reality demands that teams treat bandwidth capacity as a primary constraint, not an afterthought, because peak load performance collapses without sufficient WAN throughput validation. Organizations must stop viewing format support as a feature check-box and start treating it as a risk mitigation strategy against vendor lock-in.
Adopt a dual-format governance model immediately if your data residency requirements prevent full cloud migration, but enforce this transition within the next two quarters before technical debt solidifies. Do not wait for a crisis to audit your cross-region data movement; the window to optimize infrastructure spend before scaling further is narrowing. Start by running a localized bandwidth stress test on your most critical shared table this week to measure actual latency under load, ensuring your current network backbone can sustain the proposed architecture before signing any long-term contracts.
Frequently Asked Questions
Storage costs drop by up to 40% when using this architecture. However, the network egress burden shifts entirely to the WAN link between the data center and the cloud analytics engine.
An Orange Group subsidiary reported a 300% productivity increase after shifting compliance workflows. Query times dropped from hours to minutes because the system avoids network-bound data movement entirely.
A standard quote often expands due to hidden infrastructure costs in the dual-billing structure. While storage costs drop by up to 40%, the network egress burden shifts entirely to the WAN link.
It enables direct, zero-copy access to local datasets from the cloud without risky replication. This approach allows organizations to analyze significantly more industrial data for the same expense compared to hyperscaler services.
Databricks is growing 65% year-over-year, increasing pressure to connect static local assets to elastic cloud compute. This growth makes decoupling compute from storage while respecting physical data gravity essential for enterprises.
