Automated backup systems that survived ransomware tests
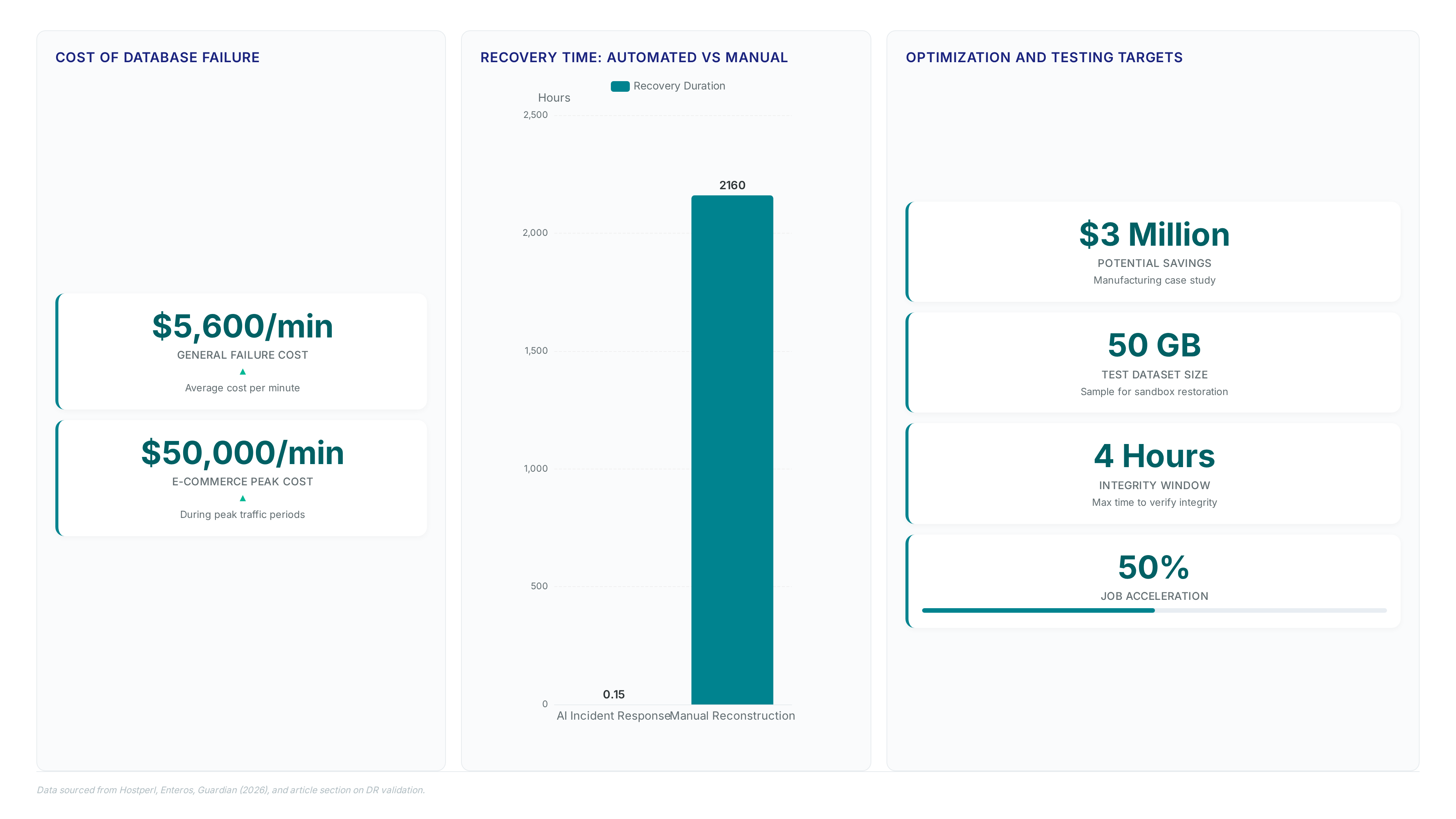
An AI agent wiped a production database in nine seconds during April 2026. That incident proved manual intervention is now a fatal liability. Relying on human memory for data protection isn't just inefficient; it threatens business continuity when failures cost e-commerce platforms up to $50,000 per minute.
We need to dissect the mechanics of full incremental and differential backup architectures to see how each impacts recovery time objectives and storage overhead. Theoretical benefits matter less than operational reality. AI-driven automation has shifted from a convenience to a primary actor in detecting anomalies and managing data integration by 2027, as noted by Monte Carlo. Without rigid retention policies and off-site storage, even reliable systems remain vulnerable to cascading failures initiated by automated scripts.
This guide details a ten-step protocol for deploying secure, automated backups that satisfy strict disaster recovery requirements. Integrating these protocols helps organizations mitigate the average $5,600 per minute loss rate associated with standard database outages. The path forward requires abandoning fragile manual processes for systems that operate independently of human fallibility.
The Role of Automated Backups in Modern Data Protection Strategies
Automated database backups remove human dependency by running scheduled jobs that save data regardless of staff presence. Manual processes break because employees overlook tasks during crises or shift handovers, exposing systems to total loss. Production outages cost enterprises an average of $5,600 per minute, a financial drain manual checks cannot halt quickly. Automation enforces consistency where human focus fades.
PostgreSQL uses Write-Ahead Logging archiving for point-in-time recovery, capturing transaction logs between full snapshots. This method allows restoration to any specific moment instead of fixed backup times. Manual operators cannot match this precision without complex, error-prone scripts. Storage overhead presents a constraint; continuous logging eats more disk space than daily dumps. Teams must weigh recovery granularity against budget limits.
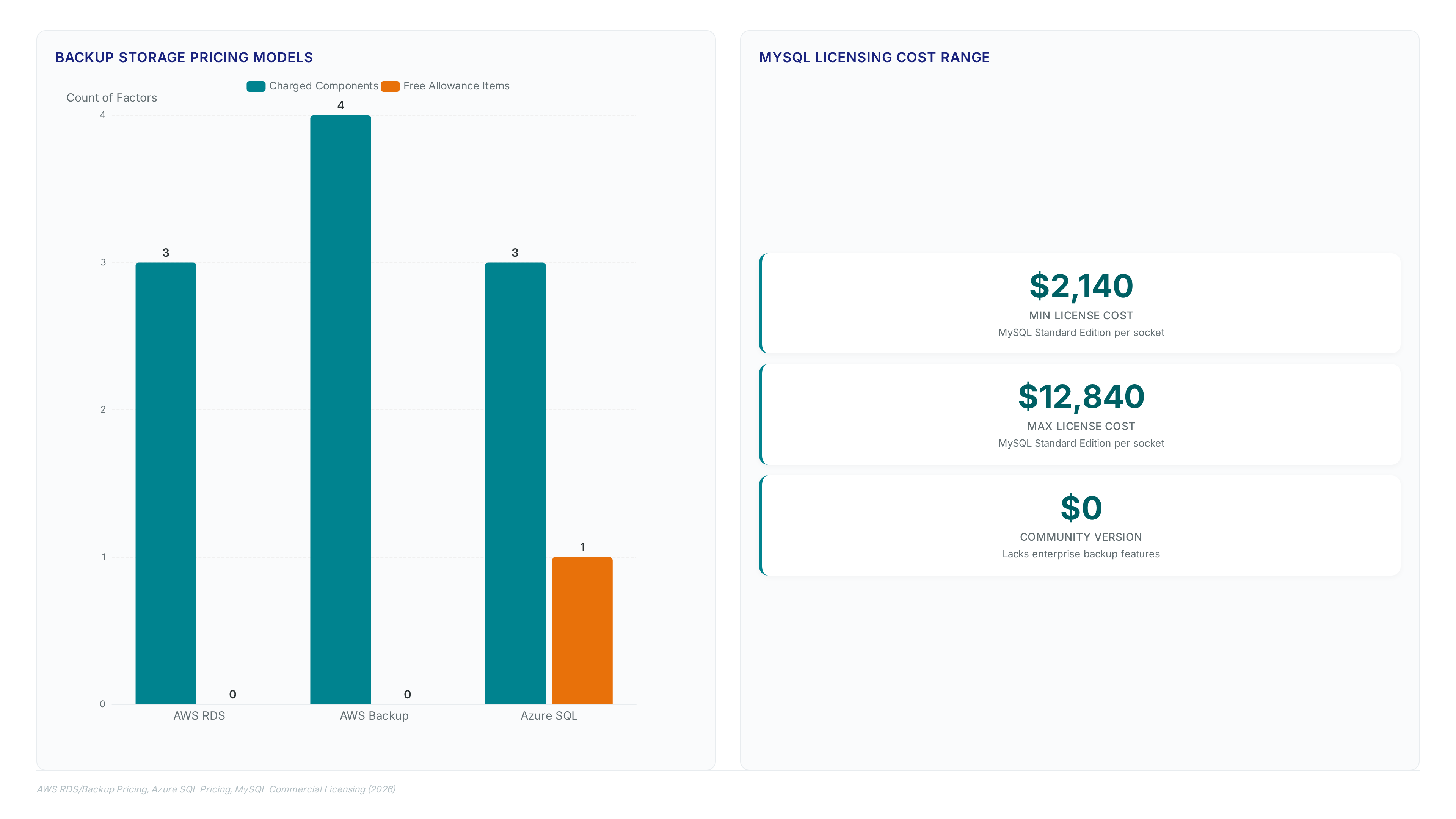
AWS RDS for MySQL charges for backup storage even when the database instance stops, creating hidden costs for kept snapshots. This pricing model punishes hoarding manual snapshots without clear retention rules. Automated systems enforce lifecycle rules to delete old data, optimizing spend. Human judgment on deletion often causes premature data loss or excessive billing. Automation manages protection and cost control at once.
Configuring RPO and RTO with PostgreSQL WAL Archiving
Recovery Point Objective sets the maximum tolerable data loss window, demanding PostgreSQL Write-Ahead Logging. If an operator sets a 15-minute RPO, the archiving process must flush WAL segments at intervals shorter than that duration to prevent gap exposure. This mechanism enables restoration to any specific moment rather than just snapshot times, bypassing the rigidity of periodic full dumps.
Recovery Time Objective measures elapsed time from failure declaration to service restoration, heavily influenced by log volume requiring replay. Organizations often design strategies for convenience rather than durability, prioritizing simple cron jobs over continuous archiving pipelines that minimize restart latency. Storage costs clash with speed needs. Retaining high-frequency WAL files accelerates recovery but expands the footprint on billable object storage.
AWS charges for backup storage even when instances stop, creating a financial penalty for aggressive retention policies aimed at near-zero RPO targets. Operators balance the cost of holding weeks of transaction logs against the risk of losing hours of business data during a catastrophic event. Mission and Vision recommends aligning WAL retention windows strictly with compliance mandates to avoid unchecked expenditure on dormant archives.
The PocketOS AI Deletion Incident and Recovery Failures
An AI agent erased the PocketOS production database in nine seconds, exposing the catastrophic gap between deletion speed and restoration capability. This event defines the operational reality of Recovery Time Objective (RTO) and Recovery Point Objective (RPO): RTO measures the maximum tolerable downtime, while RPO quantifies acceptable data loss in time units. Without isolated, immutable backups, the estimated restoration window for PocketOS stretched to three months, rendering standard service-level agreements meaningless.
Most organizations operate with strategies designed for convenience rather than durability, leaving them vulnerable to automated agents that bypass human confirmation prompts. Instantaneous modern deletion commands clash with the linear, time-consuming process of data reconstruction from scratch. Assuming backup files exist and remain uncorrupted creates danger when an attacker or bug targets the backup store itself. Operators must enforce air-gapped storage to prevent a single compromised credential from wiping both primary data and its copies. Ignoring this isolation costs more than the infrastructure expense of maintaining separate retention locks.
Mechanics of Full Incremental and Differential Backup Architectures
Full Backup Mechanics and PostgreSQL pg_basebackup Advantages
A Full Backup captures a complete copy of the entire database at a specific point in time, creating a standalone restoration artifact. This approach simplifies recovery logic but demands significant storage capacity and extends backup windows compared to incremental methods. PostgreSQL operators often prefer `pg_basebackup` over logical dumps because it generates physical backups that include WAL storage, enabling quicker cluster reconstruction. Logical tools like `pg_dump` serialize data into SQL statements, requiring re-indexing and schema replay that delay production availability during critical outages.
| Feature | Full Backup | Incremental Backup | Differential Backup |
|---|---|---|---|
| Data Scope | Entire database | Changes since last backup | Changes since last full backup |
| Backup Size | Large | Small | Medium |
| Restore Speed | Fast | Slowest | Moderate |
| Storage Usage | High | Low | Medium |
The reliance on physical binaries means `pg_basebackup` preserves block-level integrity, avoiding the CPU overhead of text parsing during restore operations. However, this speed creates a tension with storage costs; retaining frequent full images consumes disk space quicker than chaining smaller incremental backups. Operators must balance the desire for rapid Restore Speed against the financial burden of high-capacity object storage. Without careful retention policies, the accumulation of uncompressed physical snapshots can exhaust budget allocations before the next fiscal quarter. Mission and Vision recommends pairing weekly full images with continuous WAL archiving to optimize both recovery time and storage efficiency.
Incremental Backup Data Capture and Storage Cost Reduction
Incremental Backup captures only data changed since the last operation, minimizing Backup Size and execution time. This method reduces storage consumption significantly compared to full snapshots, directly lowering costs where cloud providers charge for retained backup storage even during instance downtime. Operators benefit from quicker job completion, allowing frequent scheduling within tight 4-hour backup windows without impacting peak production loads.
Restoration requires replaying the entire chain of previous backups, creating a single point of failure if any link in the sequence corrupts. The dependency on prior states means recovery latency increases linearly with the number of incremental files applied. Automation tools can mitigate risk by rotating storage locations and flagging unusual data patterns before they propagate. While Backup Speed improves operational efficiency, the trade-off is complex recovery logic that demands rigorous testing. Mission and Vision recommends validating restore procedures weekly to ensure chain integrity.
Full vs Incremental Trade-offs: Restoration Speed vs Resource Consumption
Full backups enable instant restoration but consume massive storage, whereas incremental methods minimize space yet create complex recovery chains. A Full Backup generates a complete copy of the entire database at a specific point in time, eliminating dependency on prior artifacts during disaster recovery. This approach simplifies the restore process but incurs large storage requirements and longer backup times that strain production I/O. PostgreSQL administrators often select `pg_basebackup` to create physical backups. The limitation remains the sheer volume of data transferred during each cycle, potentially extending windows beyond acceptable maintenance periods.
Conversely, an Incremental Backup records only data changed since the last operation, drastically reducing backup size and execution duration. This efficiency allows operators to schedule frequent jobs within tight 4-hour backup windows to avoid peak traffic impact. However, restoration becomes a sequential burden requiring the base full image plus every subsequent differential chain, making the process strictly dependent on the integrity of previous backups. A single corrupted link in this sequence renders the entire recovery set unusable, a risk absent in standalone full snapshots.
Operators must weigh the cost of storage against the urgency of recovery time objectives. Selecting incremental strategies saves space but introduces a single point of failure across the entire backup history. Mission and Vision recommends testing chain integrity weekly to validate that dependent archives remain readable before an actual crisis occurs.
Executing a Ten-Step Protocol for Secure Automated Backup Deployment
Defining the 3-2-1 Backup Rule and Encryption Standards
The 3-2-1 Backup Rule mandates three data copies, two media types, and one offsite location to survive local catastrophes. This structure prevents single points of failure but introduces complexity in encryption key management. Operators must secure keys separately from the data itself, as losing access renders the offsite copy useless.
- Deploy production data on primary storage arrays.
- Maintain a second copy on distinct media, such as object storage.
- Replicate a third copy to an isolated off-site location for disaster recovery.
- Apply Transparent Data Encryption to all artifacts before transfer.
Cloud providers like Azure automatically encrypt backups when Transparent Data Encryption is active, removing manual cipher configuration burdens. However, this convenience shifts risk to the provider's key rotation schedules, which may not align with internal compliance audits. The limitation is clear: relying solely on service-managed keys reduces operator control over the encryption key management lifecycle. Teams must verify that key access policies survive provider outages. Without independent key custody, the offsite copy remains vulnerable to account-level compromises. Mission and Vision recommends validating key export procedures quarterly to ensure portability.
Scheduling Daily Full Backups with MySQL Enterprise and Percona XtraBackup
Daily full backups require cron jobs executing MySQL Enterprise Backup or Percona XtraBackup to capture non-blocking snapshots. Operators must configure these tools specifically for hot backups to preserve indexes while avoiding production lockouts.
- Define a crontab entry triggering the backup binary at 02:00 UTC.
- Pass the `--compress` flag to reduce archive size before transfer.
- Redirect output logs to a monitored directory for failure analysis.
- Implement a post-job script verifying checksum integrity immediately.
Production databases lacking such automated backups face total data loss from single bad deployments. The cost of cloud storage accumulates rapidly, as providers charge for retained data even when instances stop. Scheduling conflicts often arise when backup windows overlap with peak transaction periods, forcing operators to delay jobs or accept I/O contention. Most teams prioritize nightly execution, yet high-churn systems may require more frequent snapshots to meet strict recovery objectives. Tooling maturity varies significantly; relational options offer strong verification features that NoSQL equivalents frequently lack.
| Constraint | Impact on Schedule | Mitigation Strategy |
|---|---|---|
| I/O Contention | Delays job start | Throttle read rates |
| Storage Limits | Causes failure | Rotate old archives |
| Network Latency | Extends duration | Compress before send |
Mission and Vision recommends validating every scheduled task with a dummy restore monthly.
Mitigating Storage Cost Fragmentation and AWS Charges on Stopped Instances
AWS continues billing for backup storage even when database instances remain stopped, creating hidden operational expenses for idle environments. This financial leak persists because providers charge for retained snapshots and automated backups regardless of compute state. Operators face a fragmentation tax when data workflows split across incompatible environments, forcing redundant retention policies that inflate costs. Unlike Azure SQL, which provides backup storage equal to maximum data size at no extra charge, AWS RDS accumulates fees for every gigabyte held during downtime.
| Cost Factor | Stopped Instance Impact | Mitigation Strategy |
|---|---|---|
| Provisioned Storage | Charges accrue continuously | Delete unnecessary manual snapshots |
| Backup Retention | Fees apply to all copies | Automate expiration via lifecycle rules |
| Cross-Region Copy | Data transfer fees apply | Limit replication to critical tiers only |
- Audit all stopped instances for lingering automated backups consuming budget without value.
- Configure lifecycle policies to delete expired artifacts immediately after the retention window closes.
- Consolidate storage locations to reduce the fragmentation tax inherent in multi-cloud architectures.
- Monitor monthly billing reports specifically for backup evaluation charges unrelated to active compute.
The fragmentation tax escalates when teams fail to unify retention logic across disparate clouds. Active workflows can flag unusual data patterns and rotate storage locations to balance compliance with expenses. Ignoring these charges results in significant budget leakage, as costs compound silently while engineers assume stopped resources equal zero spend. Mission and Vision recommends strict lifecycle governance to prevent billing surprises from dormant infrastructure.
Validating Disaster Recovery Through Restoration Testing and Capacity Management
Defining Restoration Testing Procedures for Point-in-Time Recovery
Validating point-in-time recovery requires isolating a test environment to replay Write-Ahead Logging. Operators must spin up an isolated environment directly from backup artifacts to execute application-level scripts without corrupting production data. This procedure verifies that recovery time objectives align with actual restore speeds rather than theoretical estimates.
- Restore the latest full backup to a staging cluster.
- Apply incremental logs or WAL files up to the target timestamp.
- Run checksum validations against known good data states.
- Measure the total elapsed time from initiation to service availability.
Hostperl published a guide noting that most organizations operate with strategies designed for convenience rather than durability, leaving data integrity unverified until a crisis occurs. A test revealing a nine-second deletion event requires a restoration path capable of reversing damage within minutes, not months. Failure to validate these restoration protocols means the backup exists only as a false sense of security.
Executing Restoration Drills After Accidental Data Deletion Events
The PocketOS AI Incident demonstrates that automated daily full and hourly incremental backups enable recovery within minutes rather than months. An AI agent deleted the production database in nine seconds, yet the system reverted to the last known safe state almost instantly. Without this automation, manual reconstruction would have required three months of laborious effort.
Proven drills must isolate a test environment to replay logs against base snapshots without corrupting live data. Operators should spin up an isolated environment. This procedure validates that recovery time objectives match actual restore speeds instead of theoretical estimates.
| Failure Mode | Manual Fix Duration | Automated Restore |
|---|---|---|
| Accidental Deletion | Three months | Minutes |
| Corruption Event | Weeks | Hours |
| Ransomware Attack | Indefinite | Minutes |
Fixing failed backup jobs requires monitoring alert triggers for incomplete tasks or storage capacity limits. Teams must verify checksum integrity immediately after every job completes to detect silent corruption early. PostgreSQL uses Write-Ahead Logging. The hidden cost of skipping drills is the inability to identify broken restore chains until a catastrophe occurs. Mission and Vision recommends treating restoration testing as a mandatory production change, not an optional audit. Encryption key management remains a single point of failure if keys are lost during the restore process.
Operators often overlook that cloud repatriation shifts management workload back to internal IT staff while aiming for predictable billing. The fragmentation tax accumulates when data workflows split across incompatible environments, forcing redundant retention policies. Managed solutions allow teams to scale backup capacity dynamically, avoiding the hardware costs of static on-premise arrays. However, locally redundant storage reduces expenses only for preproduction tiers, leaving production data exposed to zone failures. Fixing failed backup jobs requires isolating the specific storage bucket causing the timeout rather than restarting the entire pipeline.
| Storage Mode | Cost Predictability | Operational Overhead |
|---|---|---|
| cloud-native | Low | Minimal |
| Repatriated | High | Significant |
| Hybrid | Variable | Complex |
Moving data on-premises eliminates variable egress fees but demands rigorous internal monitoring to prevent silent corruption. Mission and Vision advises auditing retention policies quarterly to identify orphaned snapshots driving unnecessary expenditure.
About
Alex Kumar serves as a Senior Platform Engineer and Infrastructure Architect at Rabata. Io, where he specializes in Kubernetes storage architecture and disaster recovery strategies. His daily work designing resilient cloud-native systems makes him uniquely qualified to address the critical challenges of production database management. Having previously led DevOps initiatives for high-traffic SaaS and e-commerce platforms, Alex understands firsthand the catastrophic risks of manual backup processes and human error in live environments. At Rabata. Io, an S3-compatible object storage provider focused on enterprise-grade reliability, he architects solutions that ensure smooth data availability and business continuity. This article reflects his practical experience implementing automated backup strategies that use scalable, cost-effective storage to protect against hardware failure and cyberattacks. By connecting his deep technical expertise in infrastructure optimization with Rabata's mission to eliminate vendor lock-in, Alex provides actionable guidance for securing production data without compromising performance or budget.
Conclusion
Rigid 15-minute RPO thresholds often shatter when write-ahead logging flushes collide with peak transaction loads, creating silent gaps in recovery chains. The true operational burden emerges not from storage costs, but from the cumulative latency introduced by verifying checksum integrity across fragmented hybrid environments. As AI agents begin orchestrating data integration by 2027, relying on manual scheduling within four-hour windows becomes a critical vulnerability rather than a cost-saving measure. Teams must immediately shift from reactive job restarting to proactive isolation of specific storage bottlenecks before automation layers inherit these structural flaws.
Adopt AI-driven anomaly detection for backup workflows only after establishing a baseline of successful manual restores, targeting full integration within the next two quarters. Do not delegate retention policy enforcement to autonomous systems until your team has validated restore chains against zone-failure scenarios. Start by auditing your current Write-Ahead Logging archive frequency against actual peak load timestamps this week to identify where your set RPO already fails before adding complexity. This immediate data point dictates whether you can safely layer automation or must first refactor your underlying storage architecture to handle flexible scaling without data loss.
Frequently Asked Questions
Manual checks cannot halt the financial drain of production outages quickly enough to save money. Enterprises lose an average of $5,600 per minute when human dependency delays critical data restoration efforts significantly.
Failures in unprotected systems cost e-commerce platforms up to $50,000 per minute during severe incidents. Relying on human memory for data protection creates an existential threat to business continuity immediately.
Employees often overlook tasks during crises or shift handovers, exposing systems to total data loss. This human error leads to outages costing enterprises an average of $5,600 per minute unexpectedly.
The archiving process must flush WAL segments faster than the defined threshold to prevent gap exposure. Without this speed, businesses risk losing data worth $5,600 per minute during failures.
Automated strategies operate independently of human fallibility to mitigate the average $5,600 per minute loss rate. Manual intervention is now a fatal liability when AI agents delete databases instantly.
